I dag gjør vi tilgjengelig en ny funksjon av AWS Lim Datakatalog som gjør det mulig å generere statistikk på kolonnenivå for AWS Glue-tabeller. Denne statistikken er nå integrert med de kostnadsbaserte optimalisere (CBO) til Amazonas Athena og Amazon Rødforskyvningsspektrum, noe som resulterer i forbedret søkeytelse og potensielle kostnadsbesparelser.
Datainnsjøer er designet for å lagre store mengder rå, ustrukturert eller semistrukturert data til en lav kostnad, og organisasjoner deler disse datasettene på tvers av flere avdelinger og team. Spørringene på disse store datasettene leser enorme mengder data og kan utføre komplekse sammenføyningsoperasjoner på flere datasett. Da vi snakket med kundene våre, lærte vi at et av de utfordrende aspektene ved datainnsjøytelse er hvordan man kan optimalisere disse analysesøkene for å utføres raskere.
Optimalisering av datainnsjøytelse er spesielt viktig for spørringer med flere sammenføyninger, og det er der kostnadsbaserte optimerere hjelper mest. For at CBO skal fungere, må kolonnestatistikk samles inn og oppdateres basert på endringer i dataene. Vi lanserer muligheten for å generere statistikk på kolonnenivå som antall distinkte, antall null, maks og min på filer som Parquet, ORC, JSON, Amazon ION, CSV, XML på AWS Glue-tabeller. Med denne lanseringen har kundene nå integrert ende-til-ende-opplevelse der statistikk om Glue-tabeller samles inn og lagres i AWS Glue Catalog, og gjøres tilgjengelig for analysetjenester for forbedret spørringsplanlegging og -utførelse.
Ved å bruke denne statistikken forbedrer kostnadsbaserte optimerere spørringskjøringsplaner og øker ytelsen til spørringer som kjøres i Amazon Athena og Amazon Redshift Spectrum. For eksempel kan CBO bruke kolonnestatistikk som antall distinkte verdier og antall null for å forbedre radprediksjonen. Radprediksjon er antall rader fra en tabell som vil bli returnert av et bestemt trinn under spørringsplanleggingsstadiet. Jo mer nøyaktige radprediksjonene er, desto mer effektive er utføringstrinnene for spørringer. Dette fører til raskere utførelse av spørringer og potensielt reduserte kostnader. Noen av de spesifikke optimaliseringene som CBO kan bruke, inkluderer sammenføyningsreordning og nedtrykking av aggregeringer basert på statistikken som er tilgjengelig for hver tabell og kolonne.
For kunder som bruker datanett med AWS Lake formasjon tillatelser, tabeller fra ulike dataprodusenter er katalogisert i de sentraliserte styringsregnskapene. Når de genererer statistikk om tabeller i sentralisert katalog og deler disse tabellene med forbrukere, vil spørringer på disse tabellene i forbrukerkontoer automatisk se forbedringer i søkeytelsen. I dette innlegget vil vi demonstrere evnen til AWS Glue Data Catalog for å generere kolonnestatistikk for eksempeltabellene våre.
Løsningsoversikt
For å demonstrere effektiviteten til denne evnen bruker vi industristandarden TPC-DS 3 TB datasett lagret i en Amazon Simple Storage Service (Amazon S3) offentlig bøtte. Vi vil sammenligne søkeytelsen før og etter generering av kolonnestatistikk for tabellene, ved å kjøre spørringer i Amazon Athena og Amazon Redshift Spectrum. Vi gir spørsmål som vi brukte i dette innlegget, og vi oppfordrer til å prøve ut dine egne søk etter arbeidsflyten som illustrert i følgende detaljer.
Arbeidsflyten består av følgende trinn på høyt nivå:
- Katalogisering av Amazon S3 bøtte: Bruk AWS Glue Crawler til å gjennomsøke den angitte Amazon S3-bøtten, trekke ut metadata og sømløst lagre dem i AWS Glue-datakatalogen. Vi spør etter disse tabellene ved å bruke Amazon Athena og Amazon Redshift Spectrum.
- Generer kolonnestatistikk: Bruk de forbedrede egenskapene til AWS Glue Data Catalog for å generere omfattende kolonnestatistikk for de gjennomsøkte dataene, og dermed gi verdifull innsikt i datasettet.
- Spørre med Amazon Athena og Amazon Redshift Spectrum: Evaluer virkningen av kolonnestatistikk på søkeytelse ved å bruke Amazon Athena og Amazon Redshift Spectrum for å utføre spørringer på datasettet.
Følgende diagram illustrerer løsningsarkitekturen.
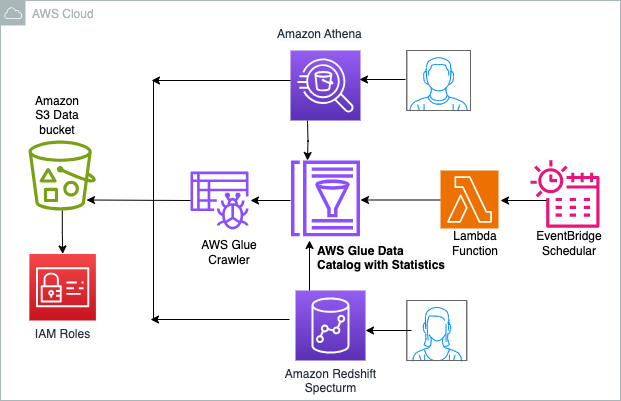
walkthrough
For å implementere løsningen fullfører vi følgende trinn:
- Sett opp ressurser med AWS skyformasjon.
- Kjør AWS Glue Crawler på offentlig Amazon S3-bøtte for å liste opp 3TB TPC-DS-datasettet.
- Kjør spørringer på Amazon Athena og Amazon Redshift og noter søkevarigheten
- Generer statistikk for AWS Glue Data Catalog-tabeller
- Kjør spørringer på Amazon Athena og Amazon Redshift og sammenlign spørringens varighet med forrige kjøring
- Valgfritt: Planlegg AWS Lim kolonnestatistikkjobber ved hjelp av AWS Lambda og Amazon EventBridge Scheduler
Sett opp ressurser med AWS CloudFormation
Dette innlegget inkluderer en AWS skyformasjon mal for et raskt oppsett. Du kan se gjennom og tilpasse den for å passe dine behov. Malen genererer følgende ressurser:
- En Amazon Virtual Private Cloud (Amazon VPC), offentlig undernett, private undernett og rutetabeller.
- En Amazon Redshift Serverless arbeidsgruppe og navneområde.
- En AWS Glue-crawler for å gjennomsøke den offentlige Amazon S3-bøtten og lage en tabell for Glue Data Catalog for TPC-DS-datasettet
- AWS Glue katalogdatabaser og tabeller
- En Amazon S3-bøtte for å lagre athena-resultater.
- AWS identitets- og tilgangsadministrasjon (AWS IAM) brukere og retningslinjer.
- AWS Lambda og Amazon Event Bridge planlegger for å planlegge AWS Glue Column-statistikken
For å starte AWS CloudFormation-stakken, fullfør følgende trinn:
Merknader: AWS Glue-datakatalogtabellene genereres ved hjelp av den offentlige bøtten s3://blogpost-sparkoneks-us-east-1/blog/BLOG_TPCDS-TEST-3T-partitioned/, vert i us-east-1 region. Hvis du har tenkt å distribuere denne AWS CloudFormation-malen i en annen region, er det nødvendig å enten kopiere dataene til den tilsvarende regionen eller dele dataene innenfor din distribuerte region for at de skal være tilgjengelige fra Amazon Redshift.
- Logg deg inn på AWS-administrasjonskonsoll som AWS Identity and Access Management (AWS IAM) administrator.
- Velg Launch Stack for å distribuere en AWS CloudFormation-mal.

- Velg neste.
- På neste side, behold alle alternativene som standard eller gjør passende endringer basert på ditt valg neste.
- Gå gjennom detaljene på den siste siden og velg Jeg erkjenner at AWS CloudFormation kan skape IAM-ressurser.
- Velg Opprett.
Denne stabelen kan ta rundt 10 minutter å fullføre, hvoretter du kan se den distribuerte stabelen på AWS CloudFormation-konsollen.
Kjør AWS Glue Crawlers opprettet av AWS CloudFormation-stakken
For å kjøre søkerobotene dine, fullfør følgende trinn:
- På AWS Lim-konsollen til AWS limkonsoll, velg Crawlers under Data Catalog i navigasjonsruten.
- Finn og kjør to robotsøkeprogrammer
tpcdsdb-without-statsogtpcdsdb-with-stats. Det kan ta noen minutter å fullføre.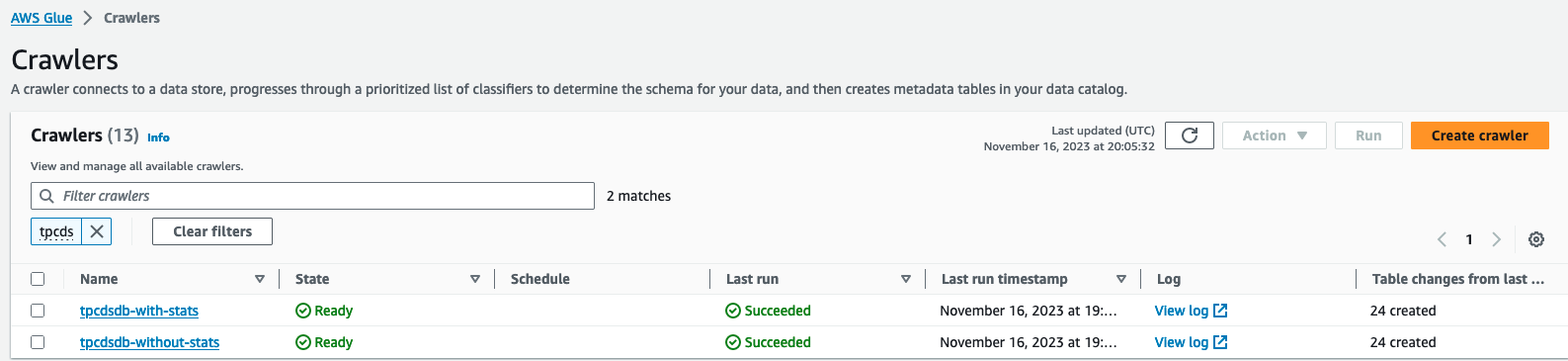
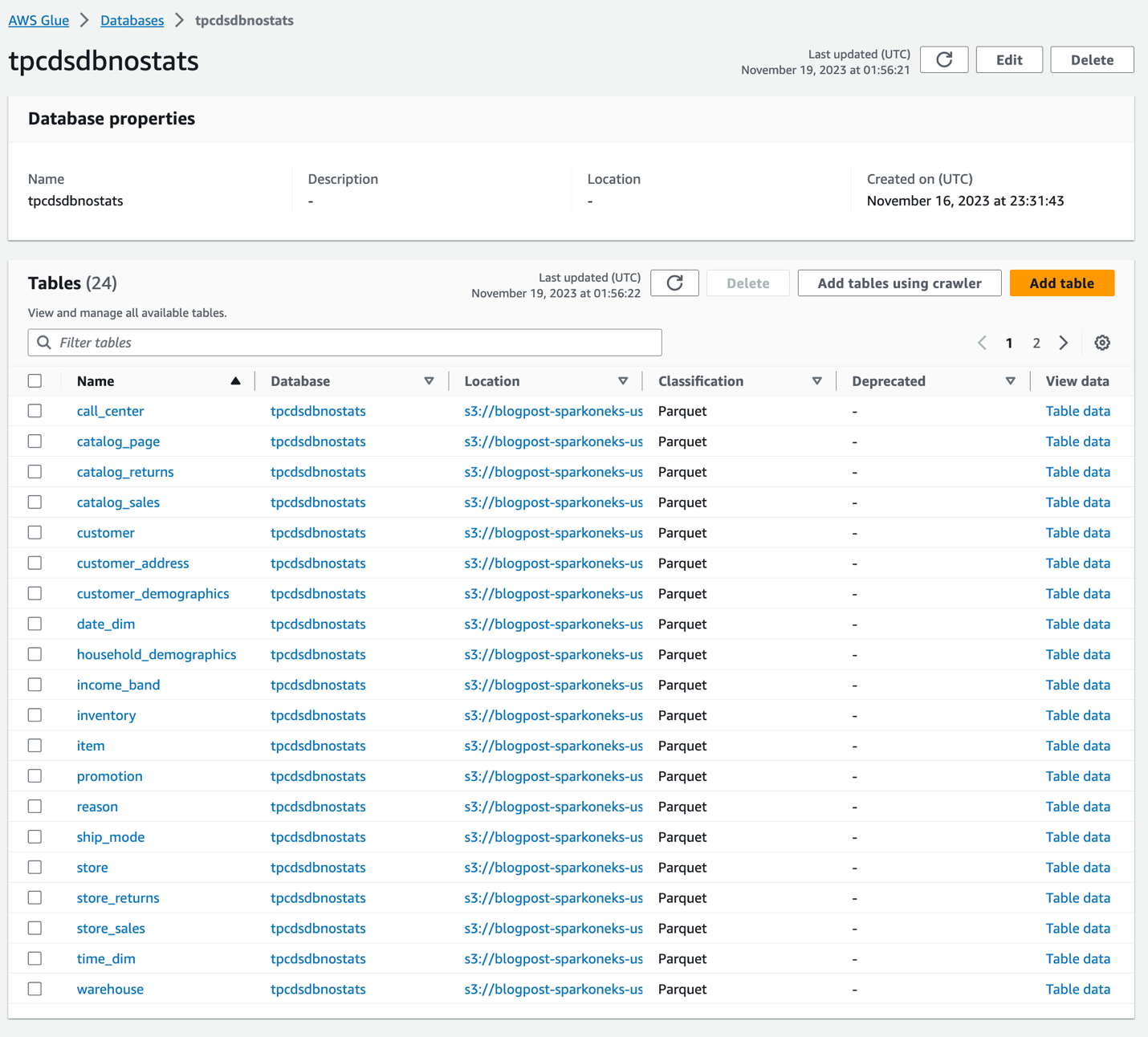
Når robotsøkeprogrammet er fullført, vil det opprette to identiske databaser tpcdsdbnostats og tpcdsdbwithstats. Bordene i tpcdsdbnostats vil ha Ingen statistikk, og vi vil bruke dem som referanse. Vi genererer statistikk på tabeller i tpcdsdbwithstats. Kontroller at du har disse to databasene og de underliggende tabellene fra AWS Glue Console. tpcdsdbnostats-databasen vil se ut som nedenfor. For øyeblikket er det ingen statistikk generert på disse tabellene.
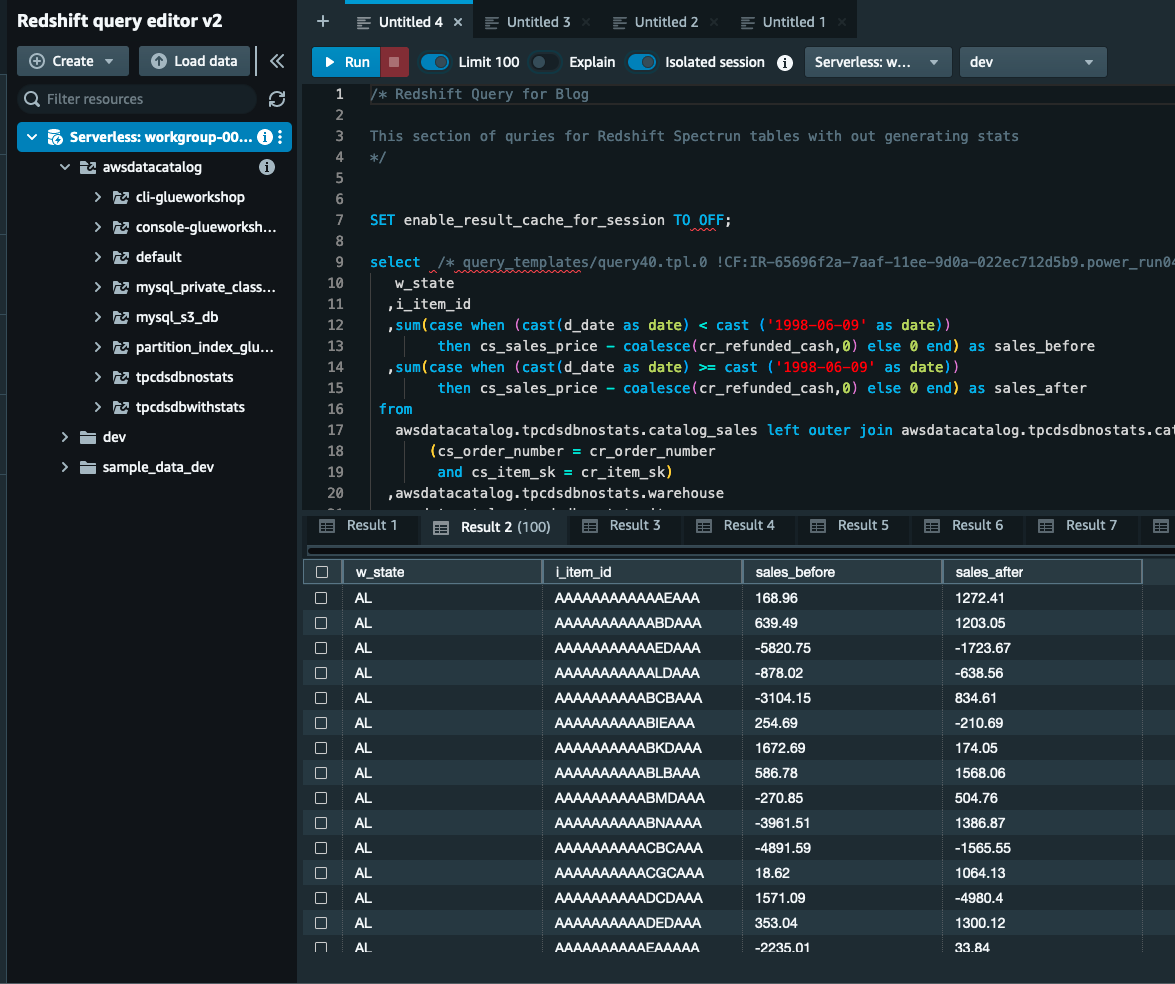
Kjør oppgitt spørring ved å bruke Amazon Athena på tabeller uten statistikk
For å kjøre søket ditt i Amazon Athena på tabeller uten statistikk, fullfør følgende trinn:
- Last ned athena-spørsmålene fra her.
- På Amazonas Athena-konsollen, velg den angitte spørringen én om gangen for tabeller i databasen
tpcdsdbnostats. - Kjør spørringen og noter ned Kjøretid for hvert søk.

Kjør oppgitt spørring ved å bruke Amazon Redshift Spectrum på tabeller uten statistikk
For å kjøre søket ditt i Amazon Redshift, fullfør følgende trinn:
- Last ned Amazon Redshift-spørsmålene fra her..
- På Redshift spørringsredigering v2, utfør Redshift Query for tabeller uten statistikk delen fra nedlastet spørring.
- Kjør spørringen og noter utføringen av spørringen for hver spørring.
Generer statistikk om AWS Glue Catalog-tabeller
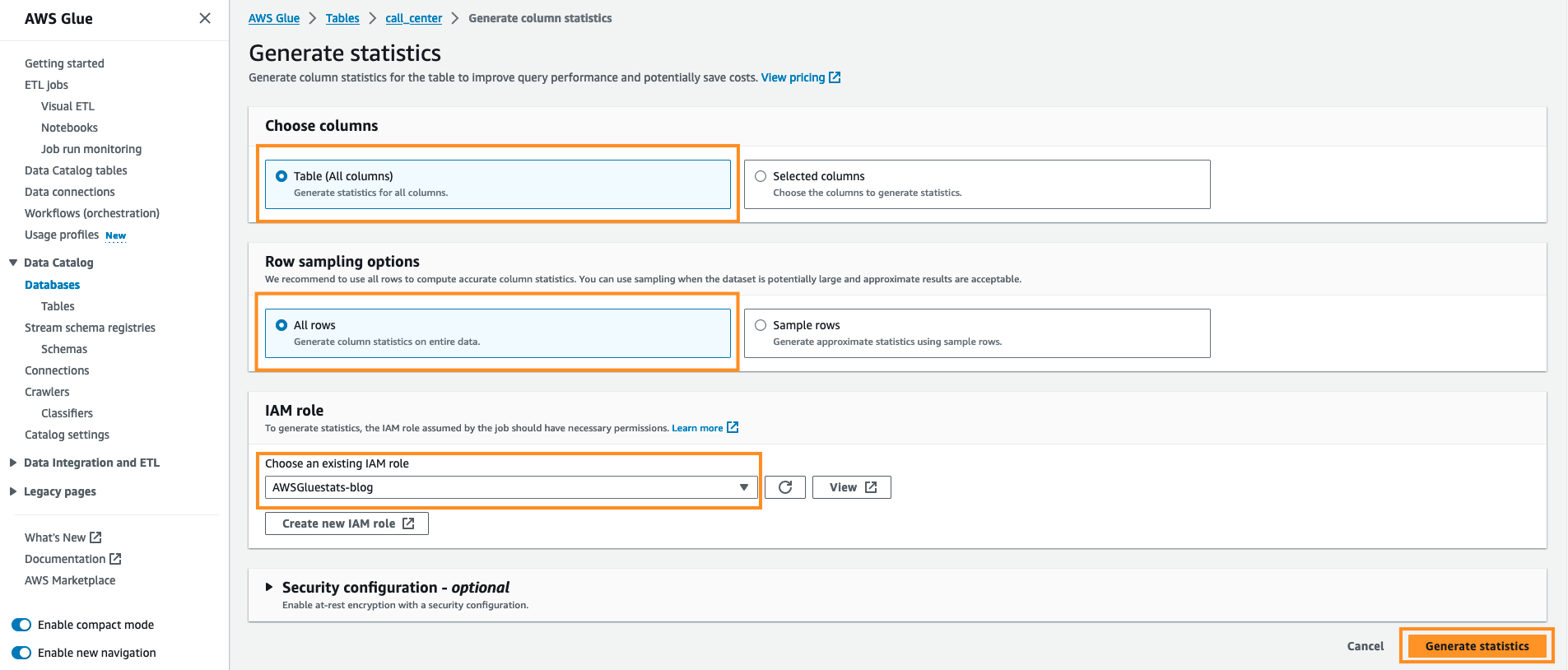
For å generere statistikk om AWS Glue Catalog-tabeller, fullfør følgende trinn:
- Naviger til AWS limkonsoll og velg databasene under Datakatalog.
- Klikk på
tpcdsdbwithstatsdatabasen, og den vil vise alle tilgjengelige tabeller. - Velg en av disse tabellene (f.eks.
call_center). - Gå til Kolonnestatistikk – ny fanen og velg Generer statistikk.
- Behold standardalternativet. Under Velg kolonner держать Tabell (alle kolonner) og Under Alternativer for radprøvetaking Hold Alle rader, under IAM rolle velge AWSGluestats-blogg og velg Generer statistikk.
Du vil kunne se status for statistikkgenereringen som er vist i følgende illustrasjon:

Etter å ha generert statistikk om AWS Glue Catalog-tabeller, bør du kunne se detaljert kolonnestatistikk for den tabellen:
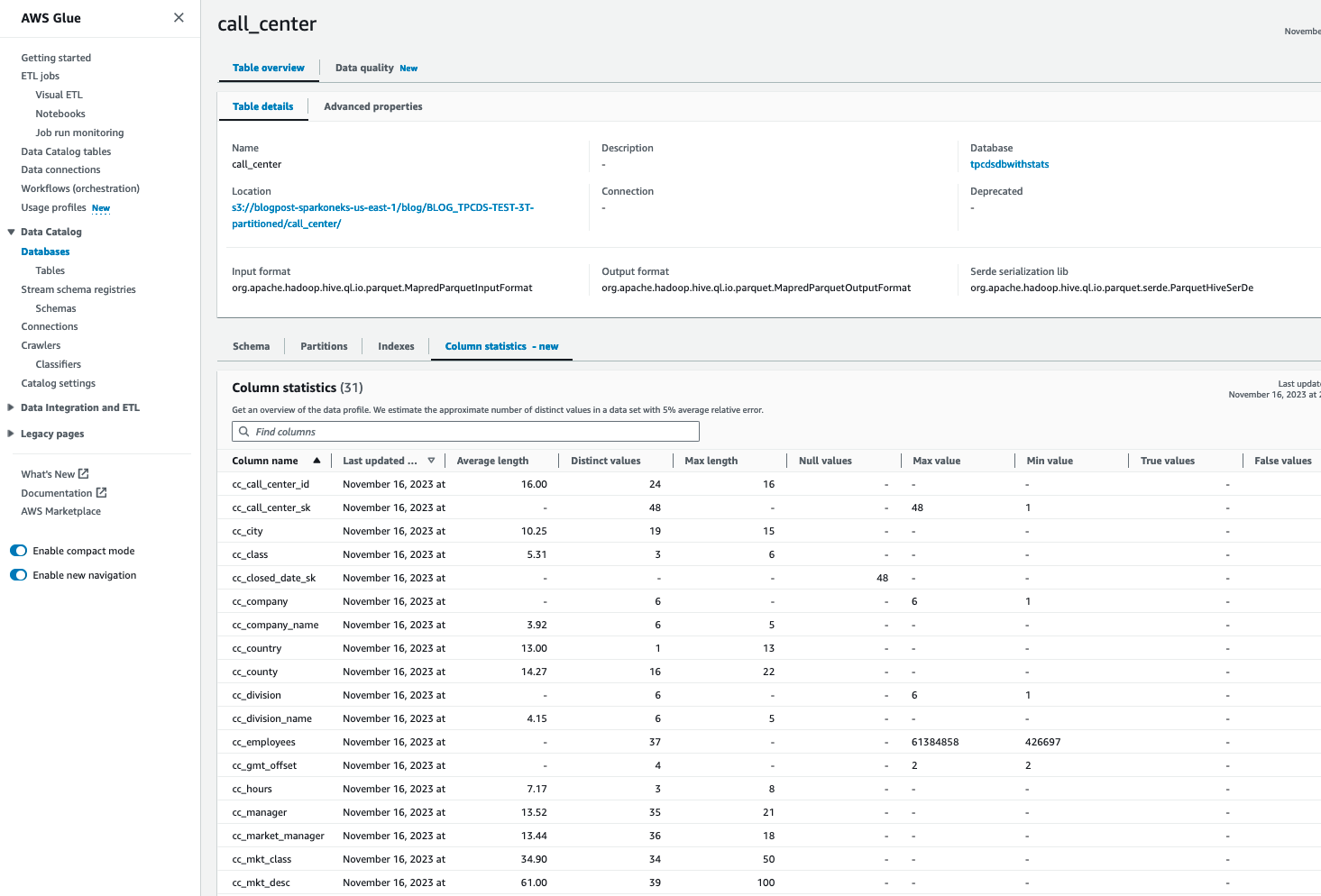
Gjenta trinn 2–5 for å generere statistikk for alle nødvendige tabeller, som f.eks catalog_sales, catalog_returns, warehouse, item, date_dim, store_sales, customer, customer_address, web_sales, time_dim, ship_mode, web_site, web_returns. Alternativt kan du følge "Planlegg AWS Glue Statistics Runs”-delen nær slutten av denne bloggen for å generere statistikk for alle tabeller. Når det er gjort, vurderer du søkeytelsen for hvert søk.
Kjør oppgitt spørring ved å bruke Athena Console på statistikktabeller
- På Amazonas Athena-konsoll, utfør Athena Query for tabeller med statistikk delen fra nedlastet spørring.
- Kjør og noter spørringskjøringen for hver spørring.
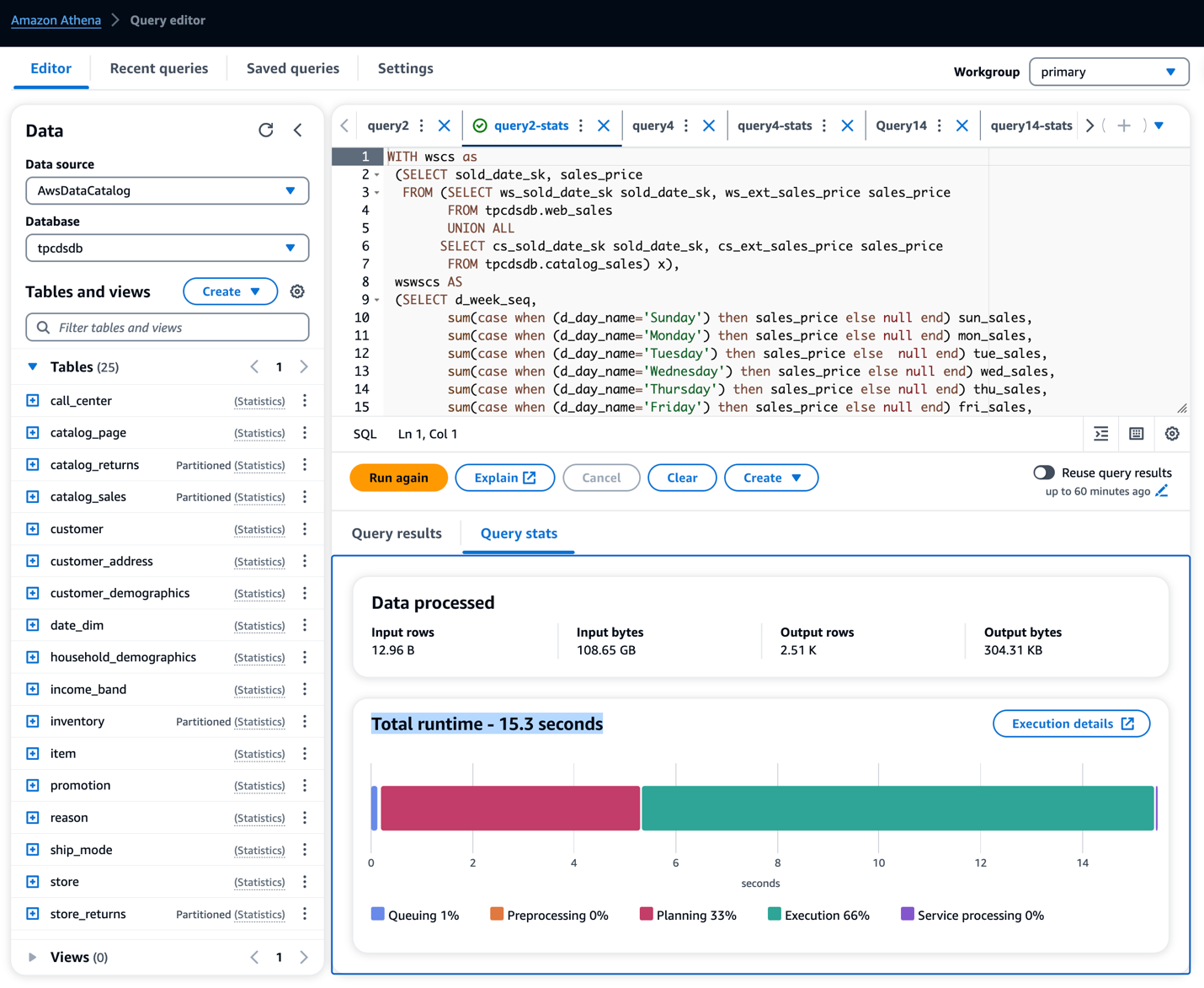
I vår prøvekjøring av spørringene i tabellene observerte vi utføringstiden for spørringen i henhold til tabellen nedenfor. Vi så klar forbedring i søkeytelsen, fra 13 til 55 %.
Forbedring av Athena spørretid
| TPC-DS 3T-spørringer | uten limstatistikk (sek) | med limstatistikk (sek) | ytelsesforbedring (%) |
| Spørring 2 | 33.62 | 15.17 | 55% |
| Spørring 4 | 132.11 | 72.94 | 45% |
| Spørring 14 | 134.77 | 91.48 | 32% |
| Spørring 28 | 55.99 | 39.36 | 30% |
| Spørring 38 | 29.32 | 25.58 | 13% |
Kjør den oppgitte spørringen ved å bruke Amazon Redshift Spectrum på statistikktabeller
- På Amazonas Redshift spørringsredigering v2, utfør Redshift Query for tabeller med statistikk delen fra nedlastet spørring.
- Kjør spørringen og noter utføringen av spørringen for hver spørring.
I vår prøvekjøring av spørringene i tabellene observerte vi utføringstiden for spørringen i henhold til tabellen nedenfor. Vi så klar forbedring i søkeytelsen, fra 13 til 89 %.
Amazon Redshift Spectrum forbedring av spørretiden
| TPC-DS 3T-spørringer | uten limstatistikk (sek) | med limstatistikk (sek) | ytelsesforbedring (%) |
| Spørring 40 | 124.156 | 13.12 | 89% |
| Spørring 60 | 29.52 | 16.97 | 42% |
| Spørring 66 | 18.914 | 16.39 | 13% |
| Spørring 95 | 308.806 | 200 | 35% |
| Spørring 99 | 20.064 | 16 | 20% |
Planlegg AWS limstatistikk Kjører
I dette segmentet av innlegget vil vi veilede deg gjennom trinnene for å planlegge AWS Glue-kolonnestatistikkkjøringer med AWS Lambda og Amazon EventBridge Planlegger. For å strømlinjeforme denne prosessen ble en AWS Lambda-funksjon og en Amazon EventBridge-planlegger opprettet som en del av CloudFormation-stack-distribusjonen.
- AWS Lambda funksjon oppsett:
Til å begynne med bruker vi en AWS Lambda-funksjon for å utløse utførelsen av AWS Glue-kolonnestatistikkjobben. AWS Lambda-funksjonen påkaller start_column_statistics_task_run API gjennom boto3 (AWS SDK for Python) biblioteket. Dette legger grunnlaget for å automatisere oppdateringen av kolonnestatistikken.
La oss utforske AWS Lambda-funksjonen:
-
- Gå til AWS Lim Lambda-konsoll.
- Plukke ut Funksjoner og finn
GlueTableStatisticsFunctionv1. - For en klarere forståelse av AWS Lambda-funksjonen, anbefaler vi å se gjennom koden i Kode seksjon og undersøke miljøvariablene under Konfigurasjon.
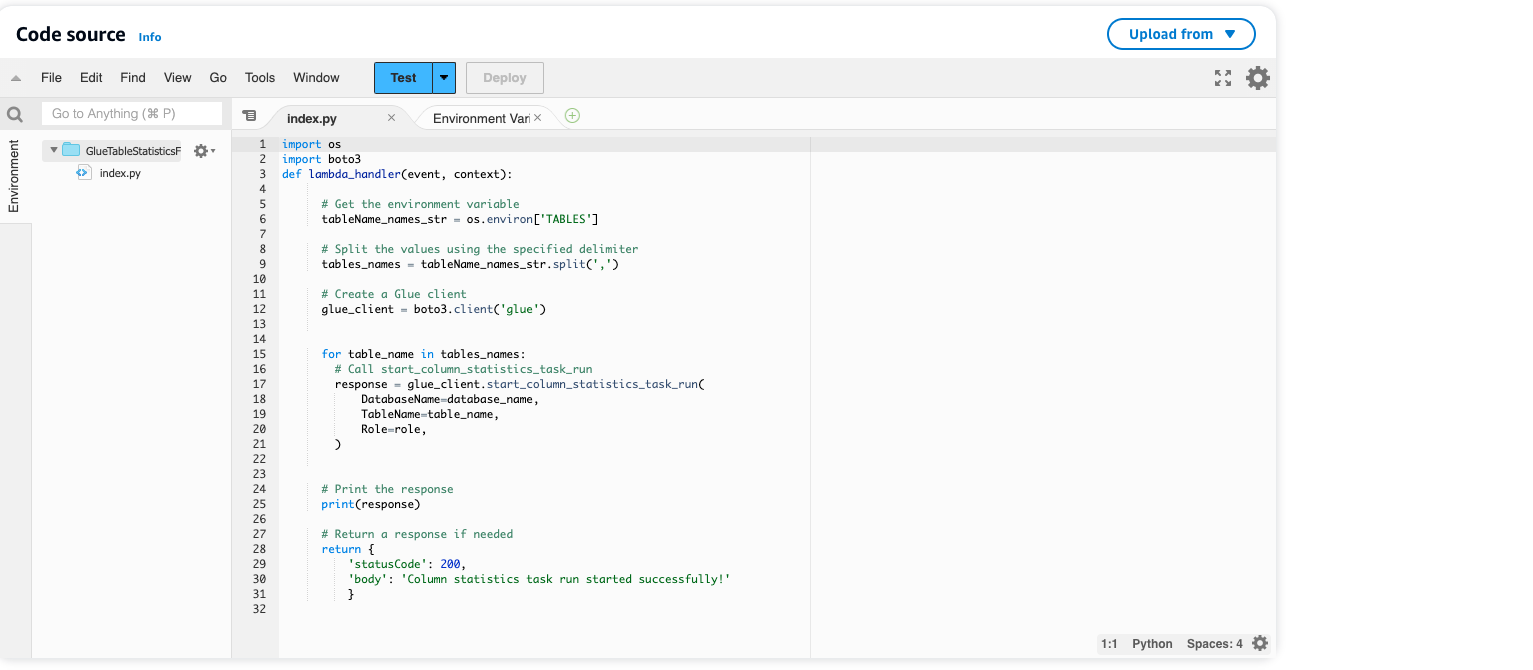
- Amazon EventBridge-planleggerkonfigurasjon
Det neste trinnet innebærer å planlegge AWS Lambda-funksjonen ved å bruke Amazon EventBridge-planlegger. Planleggeren er konfigurert til å utløse AWS Lambda-funksjonen daglig på et bestemt tidspunkt – i dette tilfellet 08:00. Dette sikrer at AWS Glue-kolonnestatistikkjobben kjører på en regelmessig og forutsigbar basis.
La oss nå utforske hvordan du kan oppdatere timeplanen:
Rydder opp
For å unngå uønskede belastninger på AWS-kontoen din, slett AWS-ressursene:
- Logg på AWS CloudFormation-konsollen som AWS IAM-administratoren som ble brukt til å lage AWS CloudFormation-stakken.
- Slett AWS CloudFormation-stakken du opprettet.
konklusjonen
I dette innlegget viste vi deg hvordan du kan bruke AWS Lim Data Catalog å generere statistikk på kolonnenivå for AWS Lim tabeller. Denne statistikken er nå integrert med kostnadsbasert optimizer fra Amazonas Athena og Amazon Rødforskyvningsspektrum, noe som resulterer i forbedret søkeytelse og potensielle kostnadsbesparelser. Referere til Dokumenter for støtte for Glue Catalog Statistics på tvers av ulike AWS-analysetjenester.
Hvis du har spørsmål eller forslag, send dem inn i kommentarfeltet.
Om forfatterne
 Sandeep Adwankar er senior teknisk produktsjef i AWS. Basert i California Bay Area jobber han med kunder over hele verden for å oversette forretningsmessige og tekniske krav til produkter som gjør det mulig for kundene å forbedre hvordan de administrerer, sikrer og får tilgang til data.
Sandeep Adwankar er senior teknisk produktsjef i AWS. Basert i California Bay Area jobber han med kunder over hele verden for å oversette forretningsmessige og tekniske krav til produkter som gjør det mulig for kundene å forbedre hvordan de administrerer, sikrer og får tilgang til data.
 Navnit Shukla fungerer som AWS spesialistløsningsarkitekt med fokus på Analytics. Han har en sterk entusiasme for å hjelpe klienter med å oppdage verdifull innsikt fra deres data. Gjennom sin ekspertise konstruerer han innovative løsninger som gir bedrifter mulighet til å komme frem til informerte, datadrevne valg. Navnit Shukla er den dyktige forfatteren av boken med tittelen Data Wrangling on AWS. Han kan nås via Linkedin.
Navnit Shukla fungerer som AWS spesialistløsningsarkitekt med fokus på Analytics. Han har en sterk entusiasme for å hjelpe klienter med å oppdage verdifull innsikt fra deres data. Gjennom sin ekspertise konstruerer han innovative løsninger som gir bedrifter mulighet til å komme frem til informerte, datadrevne valg. Navnit Shukla er den dyktige forfatteren av boken med tittelen Data Wrangling on AWS. Han kan nås via Linkedin.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/enhance-query-performance-using-aws-glue-data-catalog-column-level-statistics/
- :er
- :hvor
- $OPP
- 08
- 1
- 10
- 100
- 13
- 264
- 30
- a
- I stand
- adgang
- tilgangsstyring
- tilgjengelig
- oppnådd
- Logg inn
- kontoer
- nøyaktig
- anerkjenne
- tvers
- Etter
- Alle
- tillater
- Amazon
- Amazonas Athena
- Amazon Web Services
- beløp
- an
- Analytisk
- analytics
- og
- noen
- api
- hensiktsmessig
- arkitektur
- ER
- AREA
- rundt
- AS
- aspektet
- vurdere
- bistå
- At
- forfatter
- automatisk
- Automatisere
- tilgjengelig
- unngå
- AWS
- AWS skyformasjon
- AWS Lim
- AWS Lambda
- basert
- basis
- bukt
- BE
- før du
- begynne
- under
- Blogg
- bok
- øker
- BRO
- virksomhet
- bedrifter
- by
- california
- CAN
- evner
- evne
- saken
- katalog
- sentralisert
- viss
- utfordrende
- Endringer
- avgifter
- valg
- Velg
- fjerne
- tydeligere
- klienter
- Cloud
- kode
- Kolonne
- kolonner
- kommentarer
- sammenligne
- fullføre
- Fullfører
- komplekse
- omfattende
- konfigurert
- består
- Konsoll
- forbruker
- Forbrukere
- Tilsvarende
- Kostnad
- kostnadsbesparelser
- Kostnader
- crawler
- skape
- opprettet
- Opprette
- Kunder
- tilpasse
- daglig
- dato
- Data Lake
- data-drevet
- Database
- databaser
- datasett
- Misligholde
- demonstrere
- avdelinger
- utplassere
- utplassert
- distribusjon
- utpekt
- designet
- detaljert
- detaljer
- forskjellig
- oppdage
- distinkt
- gjort
- ned
- varighet
- under
- e
- hver enkelt
- redaktør
- effektivitet
- effektiv
- enten
- bemyndige
- muliggjøre
- oppmuntre
- slutt
- ende til ende
- forbedre
- forbedret
- sikrer
- entusiasme
- Miljø
- spesielt
- Eter (ETH)
- evaluere
- Event
- undersøke
- eksempel
- henrette
- gjennomføring
- erfaring
- ekspertise
- utforske
- raskere
- Noen få
- Filer
- slutt~~POS=TRUNC
- Fokus
- følge
- etter
- Til
- fra
- funksjon
- generere
- generert
- genererer
- genererer
- generasjonen
- globus
- styresett
- grunnarbeid
- veilede
- Ha
- he
- hjelper
- Høy
- hans
- vert
- Hvordan
- Hvordan
- HTML
- http
- HTTPS
- IAM
- identiske
- Identitet
- styring av identitet og tilgang
- if
- illustrerer
- Påvirkning
- iverksette
- viktig
- forbedre
- forbedret
- forbedring
- forbedringer
- forbedrer
- in
- inkludere
- inkluderer
- informert
- innovative
- innsikt
- integrert
- hensikt
- inn
- påkaller
- innebærer
- IT
- Jobb
- Jobb
- bli medlem
- tiltrer
- jpg
- JSON
- Hold
- innsjø
- innsjøer
- stor
- lansere
- lansere
- Fører
- lært
- Nivå
- Bibliotek
- i likhet med
- Liste
- Se
- ser ut som
- Lav
- laget
- gjøre
- Making
- administrer
- ledelse
- leder
- max
- Kan..
- metadata
- kunne
- minutter
- minutter
- mer
- mer effektivt
- mest
- flere
- Navigasjon
- Nær
- nødvendig
- Trenger
- behov
- Ny
- neste
- Nei.
- spesielt
- note
- nå
- Antall
- observerte
- of
- on
- gang
- ONE
- Drift
- optimalisering
- Optimalisere
- Alternativ
- or
- rekkefølge
- organisasjoner
- vår
- ut
- egen
- side
- brød
- del
- for
- utføre
- ytelse
- tillatelser
- planlegging
- planer
- plato
- Platon Data Intelligence
- PlatonData
- vær så snill
- pm
- Politikk
- besitter
- Post
- potensiell
- potensielt
- Forutsigbar
- prediksjon
- Spådommer
- forrige
- privat
- prosess
- Produsentene
- Produkt
- Produktsjef
- Produkter
- forutsatt
- gi
- offentlig
- Python
- spørsmål
- spørsmål
- Rask
- spenner
- Raw
- nådd
- Lese
- anbefaler
- Redusert
- referere
- referanse
- region
- regelmessig
- behov
- Krav
- Ressurser
- resultere
- resulterende
- anmeldelse
- gjennomgå
- Rolle
- Rute
- RAD
- Kjør
- rennende
- går
- Besparelser
- så
- planlegge
- planlegging
- SDK
- sømløst
- SEK
- Seksjon
- sikre
- se
- segmentet
- velg
- senior
- server~~POS=TRUNC
- serverer
- tjeneste
- Tjenester
- sett
- oppsett
- Del
- bør
- viste
- vist
- Enkelt
- løsning
- Solutions
- noen
- spesialist
- spesifikk
- Spectrum
- SQL
- stable
- Scene
- statistikk
- stats
- status
- Trinn
- Steps
- lagring
- oppbevare
- lagret
- effektivisere
- sterk
- send
- subnett
- subnett
- vellykket
- slik
- Dress
- støtte
- bord
- Ta
- snakker
- lag
- Teknisk
- mal
- Det
- De
- deres
- Dem
- Der.
- derved
- Disse
- de
- denne
- De
- Gjennom
- tid
- tittelen
- til
- oversette
- utløse
- prøve
- to
- etter
- underliggende
- forståelse
- uønsket
- Oppdater
- oppdatert
- bruke
- brukt
- Brukere
- ved hjelp av
- bruke
- utnytte
- Verdifull
- Verdier
- ulike
- enorme
- verifisere
- Se
- virtuelle
- we
- web
- webtjenester
- var
- når
- hvilken
- vil
- med
- innenfor
- uten
- Arbeid
- arbeidsflyt
- arbeidsgruppe
- virker
- ville
- XML
- yaml
- du
- Din
- zephyrnet