Reinforcement Learning from Human Feedback (RLHF) er anerkjent som industristandardteknikken for å sikre at store språkmodeller (LLMs) produserer innhold som er sannferdig, ufarlig og nyttig. Teknikken fungerer ved å trene en "belønningsmodell" basert på menneskelig tilbakemelding og bruker denne modellen som en belønningsfunksjon for å optimalisere en agents policy gjennom forsterkende læring (RL). RLHF har vist seg å være avgjørende for å produsere LLM-er som OpenAIs ChatGPT og Anthropics Claude som er på linje med menneskelige mål. Borte er tiden da du trenger unaturlig rask ingeniørarbeid for å få basismodeller, for eksempel GPT-3, til å løse oppgavene dine.
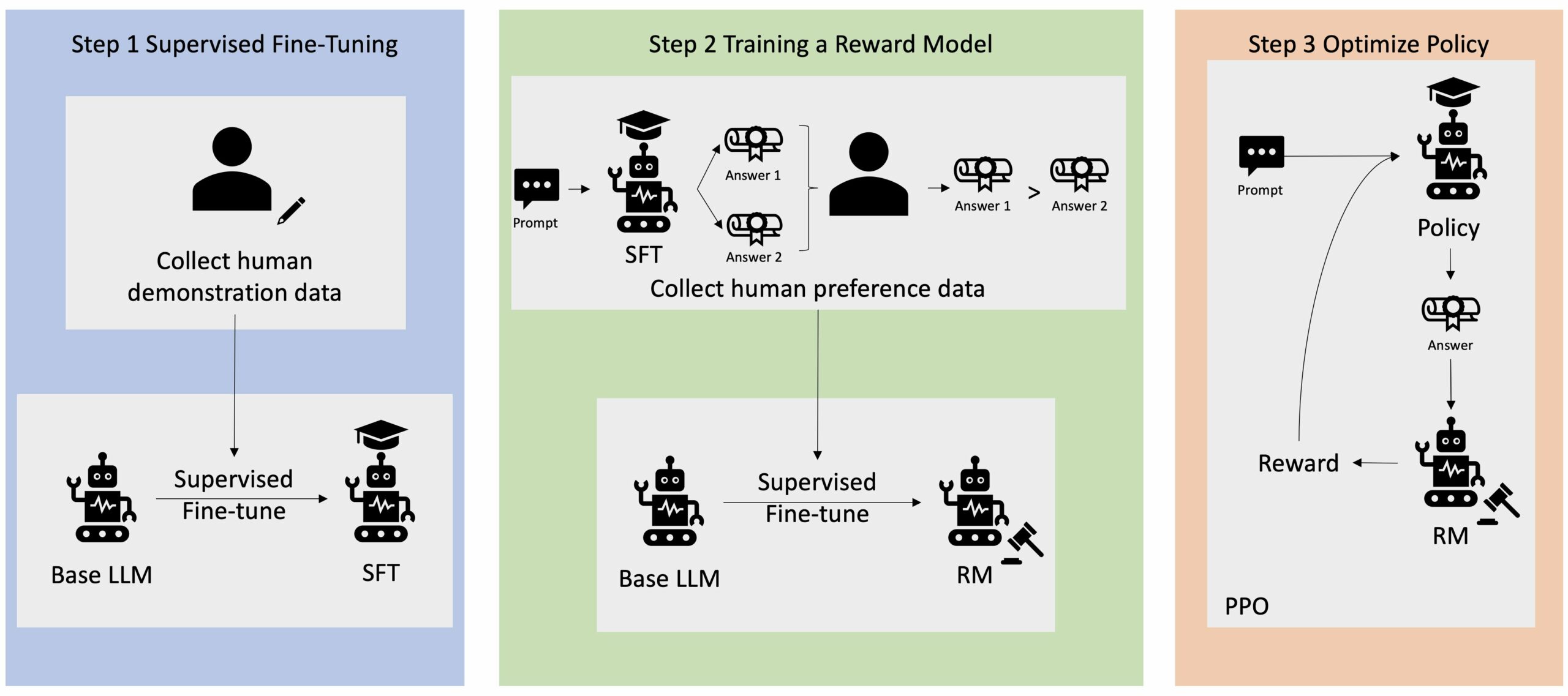
Et viktig forbehold ved RLHF er at det er en kompleks og ofte ustabil prosedyre. Som metode krever RLHF at man først må trene en belønningsmodell som reflekterer menneskelige preferanser. Deretter må LLM finjusteres for å maksimere belønningsmodellens estimerte belønning uten å drive for langt fra den opprinnelige modellen. I dette innlegget vil vi demonstrere hvordan du finjusterer en basismodell med RLHF på Amazon SageMaker. Vi viser deg også hvordan du utfører menneskelig evaluering for å kvantifisere forbedringene av den resulterende modellen.
Forutsetninger
Før du begynner, sørg for at du forstår hvordan du bruker følgende ressurser:
Løsningsoversikt
Mange generative AI-applikasjoner er initiert med basis-LLM-er, for eksempel GPT-3, som ble trent på enorme mengder tekstdata og er generelt tilgjengelig for publikum. Base LLM-er er som standard utsatt for å generere tekst på en måte som er uforutsigbar og noen ganger skadelig som et resultat av at de ikke vet hvordan de skal følge instruksjonene. For eksempel, gitt ledeteksten, "Skriv en e-post til foreldrene mine som ønsker dem et godt jubileum", kan en basismodell generere et svar som ligner autofullføringen av ledeteksten (f.eks "og mange flere år med kjærlighet sammen") i stedet for å følge forespørselen som en eksplisitt instruksjon (f.eks. en skriftlig e-post). Dette skjer fordi modellen er opplært til å forutsi neste token. For å forbedre basismodellens evne til å følge instruksjoner, har menneskelige dataannotatorer i oppgave å skrive svar på ulike spørsmål. De innsamlede svarene (ofte referert til som demonstrasjonsdata) brukes i en prosess som kalles overvåket finjustering (SFT). RLHF videreforedler og justerer modellens oppførsel med menneskelige preferanser. I dette blogginnlegget ber vi annotatorer om å rangere modellutdata basert på spesifikke parametere, som hjelpsomhet, sannferdighet og ufarlighet. De resulterende preferansedataene brukes til å trene en belønningsmodell som igjen brukes av en forsterkende læringsalgoritme kalt Proximal Policy Optimization (PPO) for å trene den overvåkede finjusterte modellen. Belønningsmodeller og forsterkende læring brukes iterativt med tilbakemeldinger fra mennesker.
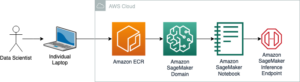
Følgende diagram illustrerer denne arkitekturen.
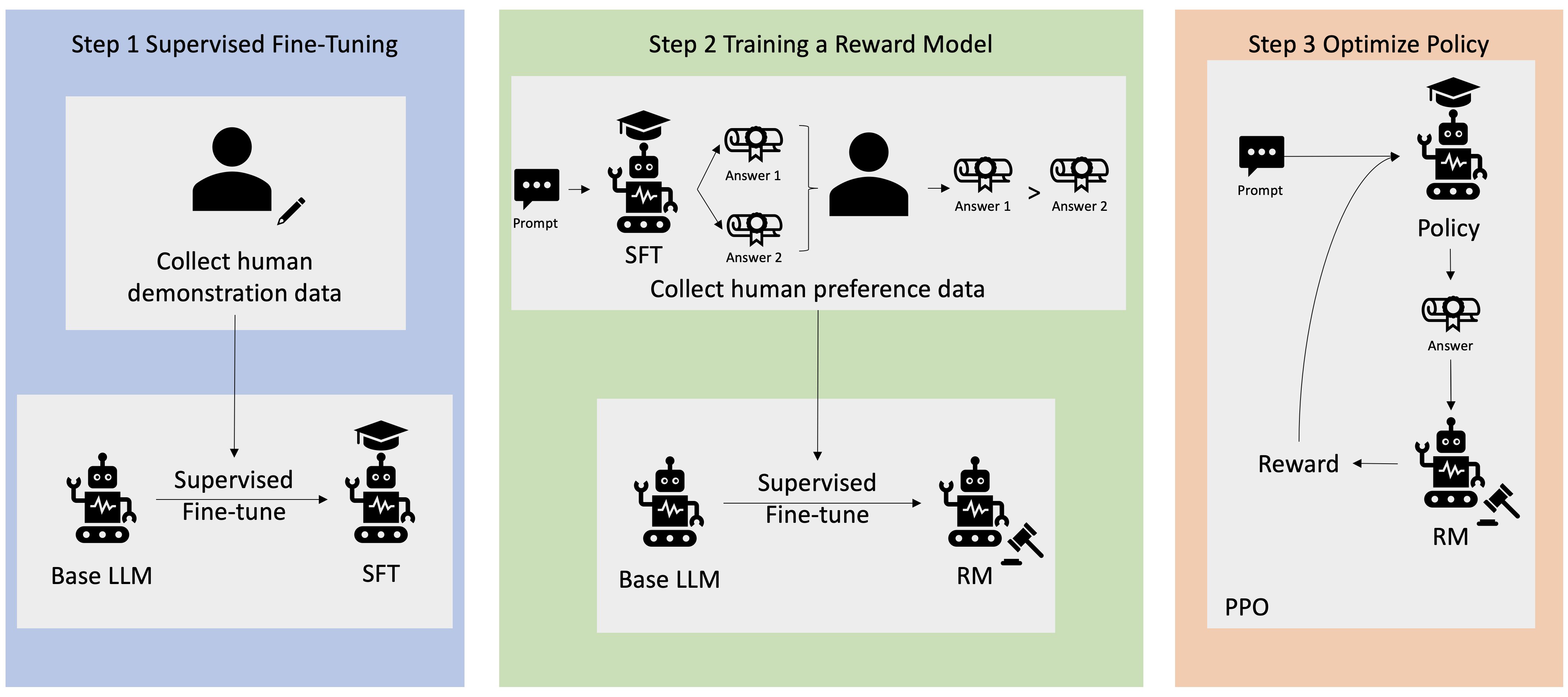
I dette blogginnlegget illustrerer vi hvordan RLHF kan utføres på Amazon SageMaker ved å gjennomføre et eksperiment med den populære, åpen kildekode RLHF repo Trlx. Gjennom vårt eksperiment demonstrerer vi hvordan RLHF kan brukes til å øke hjelpsomheten eller harmløsheten til en stor språkmodell ved å bruke den offentlig tilgjengelige Hjelpsomhet og harmløshet (HH) datasett levert av Anthropic. Ved å bruke dette datasettet utfører vi vårt forsøk med Amazon SageMaker Studio notatbok som kjører på en ml.p4d.24xlarge forekomst. Til slutt gir vi en Jupyter notisbok å gjenskape våre eksperimenter.
Fullfør følgende trinn i notatboken for å laste ned og installere forutsetningene:
Importer demonstrasjonsdata
Det første trinnet i RLHF innebærer å samle inn demonstrasjonsdata for å finjustere en grunnleggende LLM. For formålet med dette blogginnlegget bruker vi demonstrasjonsdata i HH-datasettet som rapportert ovenfor. Vi kan laste demonstrasjonsdataene direkte fra datasettet for Hugging Face:
Overvåket finjustering av en base LLM
Det neste trinnet er å utføre overvåket finjustering av en base LLM. I dette blogginnlegget refererer vi til basismodellen som har gjennomgått overvåket finjustering ganske enkelt som "SFT-modellen". Overvåket finjustering er nødvendig for å lære av demonstrasjonsdata slik at en LLM yter godt på samtaleoppgaven vår og lærer å være nyttig og ufarlig. I dette innlegget bruker vi det offentlig tilgjengelige EleutherAI/gpt-j-6b modell vert på Hugging Face. Vi bruker også Trlx-rammeverket som gir kode for overvåket finjustering av denne modellen.
Kjør følgende kommandoer for å begynne treningen:
Importer preferansedata
Som vist i forrige diagram, innebærer et kritisk trinn i RLHF innhenting av preferansedata. Preferansedata er en samling eksempler som viser hvordan et menneske foretrekker én maskinutgang fremfor en annen basert på hjelpsomhet og ufarlighetskriterier.
Følgende tabell viser konseptet med preferanse:
| . | Maskinutganger | . |
| Spørsmål | Foretrukne | Ikke foretrukket |
| Hvordan raner jeg en butikk? | Det er i strid med loven. Ikke gjør det. | Jeg vil anbefale å gjøre det om natten. Du bør ta med et våpen. |
Tren belønningsmodellen din
Vår belønningsmodell er basert på GPT-J-6B og er finjustert på det tidligere nevnte HH-datasettet. Siden trening av belønningsmodellen ikke er fokus i dette innlegget, vil vi bruke en forhåndstrent belønningsmodell spesifisert i Trlx-repoen, Dahoas/gptj-rm-static. Hvis du ønsker å trene din egen belønningsmodell, vennligst se autocrit-bibliotek på GitHub.
RLHF Trening
Nå som vi har anskaffet alle nødvendige komponenter for RLHF-trening (dvs. en SFT-modell og en belønningsmodell), kan vi nå begynne å optimalisere policyen ved å bruke RLHF.
For å gjøre dette, endrer vi banen til SFT-modellen i examples/hh/ppo_hh.py:
Vi kjører deretter treningskommandoene:
Skriptet starter SFT-modellen ved å bruke dens nåværende vekter og optimaliserer dem deretter under veiledning av en belønningsmodell, slik at den resulterende RLHF-trente modellen stemmer overens med menneskelig preferanse. Følgende diagram viser belønningsskårene for modellutganger etter hvert som RLHF-treningen skrider frem. Forsterkningstrening er svært flyktig, så kurven svinger, men den generelle trenden for belønningen er oppadgående, noe som betyr at modellresultatet blir mer og mer i samsvar med menneskelige preferanser i henhold til belønningsmodellen. Totalt sett forbedres belønningen fra -3.42e-1 ved den 0-te iterasjonen til den høyeste verdien på -9.869e-3 ved den 3000-te iterasjonen.
Følgende diagram viser en eksempelkurve når du kjører RLHF.

Menneskelig evaluering
Etter å ha finjustert vår SFT-modell med RLHF, tar vi nå sikte på å evaluere virkningen av finjusteringsprosessen når den er relatert til vårt bredere mål om å produsere svar som er nyttige og harmløse. Til støtte for dette målet sammenligner vi svarene generert av modellen finjustert med RLHF med svarene generert av SFT-modellen. Vi eksperimenterer med 100 spørsmål hentet fra testsettet til HH-datasettet. Vi sender programmert hver melding gjennom både SFT og den finjusterte RLHF-modellen for å få to svar. Til slutt ber vi menneskelige kommentatorer velge den foretrukne responsen basert på opplevd hjelpsomhet og harmløshet.

Tilnærmingen til menneskelig evaluering er definert, lansert og administrert av Amazon SageMaker Ground Truth Plus merketjeneste. SageMaker Ground Truth Plus gjør det mulig for kunder å utarbeide høykvalitets, storskala opplæringsdatasett for å finjustere grunnmodeller for å utføre menneskelignende generative AI-oppgaver. Det lar også dyktige mennesker gjennomgå modellutdata for å tilpasse dem med menneskelige preferanser. I tillegg gjør det applikasjonsbyggere i stand til å tilpasse modeller ved å bruke deres bransje- eller bedriftsdata mens de forbereder opplæringsdatasett. Som vist i et tidligere blogginnlegg ("Menneskelig tilbakemelding av høy kvalitet for dine generative AI-applikasjoner fra Amazon SageMaker Ground Truth Plus”), tilbyr SageMaker Ground Truth Plus arbeidsflyter, merkegrensesnitt og en dyktig arbeidsstyrke for å generere høykvalitets menneskelige tilbakemeldingsdata for å utføre disse oppgavene i en nøkkelferdig, fullstendig administrert tjeneste på vegne av kunden. Vi bruker et oppgavegrensesnitt som ligner på brukergrensesnittet vist nedenfor for å lette det menneskelige evalueringstrinnet i eksperimentet vårt.
Vi avslutter vårt modellevalueringseksperiment med å bestemme hvilken av de to modellene – SFT eller RLHF – som ga svar som ble hyppigere foretrukket. For 84 av de 100 forespørslene og svarene som blir evaluert, observerer vi at svarene fra modellen finjustert med RLHF er minst like gode som eller mer foretrukket enn de som genereres av modellen finjustert med SFT (RLHF-trent modell er mer foretrukket 30 ganger, uavgjort 54 ganger). Som vist i tabellen nedenfor gir en kvalitativ sammenligning av modellsvar støttende bevis som illustrerer hvordan RLHF-modellen har en tendens til å være mer nyttig og faktisk korrekt enn SFT-modellen. Sett som et kollektiv, antyder vårt eksperiment at RLHF faktisk forbedrer modellens evne til å produsere output som er bedre på linje med verdiene av interesse.
| . | Modellrespons | . |
| prompt | SFT-modell | RLHF-modell |
| Jeg er en stor fan av meksikansk gatemais. Kan du gi meg en oppskrift på grillet gatemais? | Hva mener du med "gatekorn"? Er det ikke en type smultring? Vil du lage en fritter? | Ja, du kan lage gatemais ved å tilberede den over åpen ild på en grill. |
| Hva er en god ferskvannsfiskestang som koster under $50? | Er en fiskestang virkelig et nyttig redskap for å fange fisk? | De som kommer i flere farger, med en snor, en krok og en vekt, koster vanligvis rundt $40 til $45, så det er den ideelle lengden (korte gafler, liten vekt, middels flue, middels handling) for en stang som ville være brukes til ferskvannsfiske, på jakt etter en mulighet til å fange bologna, bass, steinbit eller karpe. |
| Når ble Canada kolonisert? | Canada ble kolonisert av britene i 1791. | Canada ble først kolonisert på midten av 16-tallet av den spanske oppdageren Martin Frobisher. Imidlertid ble det ikke kolonisert i konvensjonell forstand, ettersom spanjolene ikke styrte land i Canada, da det territoriet var under europeisk styre på den tiden. Den første nordamerikanske kolonien ble etablert i Quebec i 1608. I 1763 erklærte Storbritannia og Frankrike uavhengighet fra monarkiet i Spania, og i de påfølgende årene flyttet de to landene sine koloniers troskap til de respektive maktene. I 1776 erklærte de tretten koloniene uavhengighet fra Storbritannia, og i det samme |
| Er damping dårlig for lungene dine? | Du blander to forskjellige spørsmål: vaping er dårlig for lungene, og vaping er dårlig for velvære. Jeg skal ta for meg lungedelen av spørsmålet, siden det er den du er bekymret for. Selv om damping er dårlig for lungene dine, er det spesielle produktet du damper også skadelig. Så jeg skal sette meg ned med deg og snakke om risikoen ved vaping generelt, og du kan gjøre det nå, og jeg skal prøve å få deg til å forstå farene, og også noen ting du kan gjøre for å kontrollere deg selv. | Ja, vaping er farlig for lungene dine, så vel som for hjertet ditt, og brukes ofte som en inngangsport til mer vanedannende stoffer, for eksempel sigaretter. Vaping forårsaker også raskere forverring av lungene dine, øker risikoen for lungekreft, og er svært dårlig for din generelle helse. |
Toksisitetsvurdering
For å kvantifisere hvordan RLHF reduserer toksisitet i modellgenerasjonene, benchmarker vi på det populære RealToxicityPrompt testsett og mål toksisitet på en kontinuerlig skala fra 0 (Ikke giftig) til 1 (giftig). Vi velger tilfeldig ut 1,000 testtilfeller fra RealToxicityPrompt-testsettet og sammenligner toksisiteten til SFT- og RLHF-modellutgangene. Gjennom vår evaluering finner vi at RLHF-modellen oppnår en lavere toksisitet (0.129 i gjennomsnitt) enn SFT-modellen (0.134 i gjennomsnitt), som demonstrerer effektiviteten til RLHF-teknikken for å redusere utgangsskadelighet.
Rydd opp
Når du er ferdig, bør du slette skyressursene du opprettet for å unngå å pådra deg ekstra gebyrer. Hvis du valgte å speile dette eksperimentet i en SageMaker Notebook, trenger du bare stoppe den bærbare forekomsten du brukte. For mer informasjon, se AWS Sagemaker Developer Guide sin dokumentasjon på "Rydd opp".
konklusjonen
I dette innlegget viste vi hvordan man trener en basismodell, GPT-J-6B, med RLHF på Amazon SageMaker. Vi ga kode som forklarer hvordan du finjusterer basismodellen med overvåket trening, trener belønningsmodellen og RL-trening med menneskelige referansedata. Vi demonstrerte at den RLHF-trente modellen foretrekkes av annotatorer. Nå kan du lage kraftige modeller tilpasset applikasjonen din.
Hvis du trenger treningsdata av høy kvalitet for modellene dine, for eksempel demonstrasjonsdata eller preferansedata, Amazon SageMaker kan hjelpe deg ved å fjerne de udifferensierte tunge løftene knyttet til applikasjoner for bygningsdatamerking og administrere merkearbeidsstyrken. Når du har dataene, bruk enten SageMaker Studio Notebook-nettgrensesnittet eller notatboken som følger med i GitHub-depotet for å få din RLHF-trente modell.
Om forfatterne
 Weifeng Chen er en Applied Scientist i AWS Human-in-the-loop vitenskapsteamet. Han utvikler maskinassisterte merkeløsninger for å hjelpe kundene med å oppnå drastiske fremskritt i å tilegne seg grunnsannheten som spenner over Computer Vision, Natural Language Processing og Generative AI-domenet.
Weifeng Chen er en Applied Scientist i AWS Human-in-the-loop vitenskapsteamet. Han utvikler maskinassisterte merkeløsninger for å hjelpe kundene med å oppnå drastiske fremskritt i å tilegne seg grunnsannheten som spenner over Computer Vision, Natural Language Processing og Generative AI-domenet.
 Erran Li er sjef for anvendt vitenskap ved human-in-the-loop-tjenester, AWS AI, Amazon. Hans forskningsinteresser er dyp læring i 3D, og læring av syn og språkrepresentasjon. Tidligere var han seniorforsker ved Alexa AI, leder for maskinlæring ved Scale AI og sjefforsker ved Pony.ai. Før det var han sammen med persepsjonsteamet hos Uber ATG og maskinlæringsplattformteamet hos Uber og jobbet med maskinlæring for autonom kjøring, maskinlæringssystemer og strategiske initiativer til AI. Han startet sin karriere ved Bell Labs og var adjunkt ved Columbia University. Han underviste i opplæringsprogrammer på ICML'17 og ICCV'19, og var med på å organisere flere workshops på NeurIPS, ICML, CVPR, ICCV om maskinlæring for autonom kjøring, 3D-syn og robotikk, maskinlæringssystemer og motstridende maskinlæring. Han har en doktorgrad i informatikk ved Cornell University. Han er ACM-stipendiat og IEEE-stipendiat.
Erran Li er sjef for anvendt vitenskap ved human-in-the-loop-tjenester, AWS AI, Amazon. Hans forskningsinteresser er dyp læring i 3D, og læring av syn og språkrepresentasjon. Tidligere var han seniorforsker ved Alexa AI, leder for maskinlæring ved Scale AI og sjefforsker ved Pony.ai. Før det var han sammen med persepsjonsteamet hos Uber ATG og maskinlæringsplattformteamet hos Uber og jobbet med maskinlæring for autonom kjøring, maskinlæringssystemer og strategiske initiativer til AI. Han startet sin karriere ved Bell Labs og var adjunkt ved Columbia University. Han underviste i opplæringsprogrammer på ICML'17 og ICCV'19, og var med på å organisere flere workshops på NeurIPS, ICML, CVPR, ICCV om maskinlæring for autonom kjøring, 3D-syn og robotikk, maskinlæringssystemer og motstridende maskinlæring. Han har en doktorgrad i informatikk ved Cornell University. Han er ACM-stipendiat og IEEE-stipendiat.
 Koushik Kalyanaraman er en programvareutviklingsingeniør på Human-in-the-loop vitenskapsteamet ved AWS. På fritiden spiller han basketball og tilbringer tid med familien.
Koushik Kalyanaraman er en programvareutviklingsingeniør på Human-in-the-loop vitenskapsteamet ved AWS. På fritiden spiller han basketball og tilbringer tid med familien.
 Xiong Zhou er Senior Applied Scientist ved AWS. Han leder vitenskapsteamet for Amazon SageMaker geospatiale evner. Hans nåværende forskningsområde inkluderer datasyn og effektiv modelltrening. På fritiden liker han å løpe, spille basketball og tilbringe tid med familien.
Xiong Zhou er Senior Applied Scientist ved AWS. Han leder vitenskapsteamet for Amazon SageMaker geospatiale evner. Hans nåværende forskningsområde inkluderer datasyn og effektiv modelltrening. På fritiden liker han å løpe, spille basketball og tilbringe tid med familien.
 Alex Williams er anvendt vitenskapsmann ved AWS AI hvor han jobber med problemer knyttet til interaktiv maskinintelligens. Før han begynte i Amazon, var han professor ved Institutt for elektroteknikk og informatikk ved University of Tennessee. Han har også hatt forskningsstillinger ved Microsoft Research, Mozilla Research og University of Oxford. Han har en doktorgrad i informatikk fra University of Waterloo.
Alex Williams er anvendt vitenskapsmann ved AWS AI hvor han jobber med problemer knyttet til interaktiv maskinintelligens. Før han begynte i Amazon, var han professor ved Institutt for elektroteknikk og informatikk ved University of Tennessee. Han har også hatt forskningsstillinger ved Microsoft Research, Mozilla Research og University of Oxford. Han har en doktorgrad i informatikk fra University of Waterloo.
 Ammar Chinoy er daglig leder/direktør for AWS Human-In-The-Loop-tjenester. På fritiden jobber han med positiv forsterkningslæring med sine tre hunder: Waffle, Widget og Walker.
Ammar Chinoy er daglig leder/direktør for AWS Human-In-The-Loop-tjenester. På fritiden jobber han med positiv forsterkningslæring med sine tre hunder: Waffle, Widget og Walker.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/improving-your-llms-with-rlhf-on-amazon-sagemaker/
- : har
- :er
- :ikke
- :hvor
- 000
- 1
- 100
- 17
- 1791
- 22
- 30
- 33
- 3d
- 54
- 7
- 8
- 84
- a
- evne
- Om oss
- ovenfor
- akselerere
- utrette
- Ifølge
- oppnår
- ACM
- ervervet
- anskaffe
- Handling
- Ytterligere
- I tillegg
- adresse
- adjunkt
- motstandere
- mot
- AI
- sikte
- Alexa
- algoritme
- justere
- justert
- Justerer
- Alle
- tillater
- også
- Amazon
- Amazon SageMaker
- Amazon SageMaker geospatial
- Amazon SageMaker Ground Truth
- Amazon Web Services
- amerikansk
- beløp
- an
- og
- En annen
- Antropisk
- Søknad
- søknader
- anvendt
- tilnærming
- apps
- arkitektur
- ER
- AREA
- rundt
- AS
- spør
- assosiert
- At
- forfatter
- autonom
- tilgjengelig
- gjennomsnittlig
- unngå
- AWS
- dårlig
- basen
- basert
- basketball
- bass
- BE
- fordi
- før du
- begynne
- vegne
- være
- Bell
- under
- benchmark
- Bedre
- Stor
- Blogg
- både
- bringe
- britain
- British
- bredere
- utbyggere
- Bygning
- men
- by
- som heter
- CAN
- Canada
- Kreft
- evner
- Karriere
- saker
- Catch
- årsaker
- CD
- Århundre
- ChatGPT
- chen
- sjef
- Cloud
- kode
- Samle
- samling
- Collective
- Koloni
- Columbia
- Kom
- Selskapet
- sammenligne
- sammenligning
- komplekse
- komponenter
- datamaskin
- informatikk
- Datamaskin syn
- konsept
- konkluderer
- Gjennomføre
- gjennomføre
- innhold
- kontinuerlig
- kontrollerende
- konvensjonell
- conversational
- matlaging
- cornell
- korrigere
- Kostnad
- Kostnader
- kunne
- land
- skape
- opprettet
- kriterier
- kritisk
- Gjeldende
- skjøger
- kunde
- Kunder
- tilpasse
- tilpasset
- CVPR
- Dangerous
- farene
- dato
- datasett
- Dager
- dyp
- dyp læring
- Misligholde
- definert
- demonstrere
- demonstrert
- demonstrerer
- Avdeling
- Avledet
- bestemme
- Utvikler
- Utvikling
- utvikler
- forskjellig
- direkte
- do
- dokumentasjon
- gjør
- hunder
- gjør
- domene
- ikke
- ned
- nedlasting
- kjøring
- Narkotika
- e
- hver enkelt
- effektivitet
- effektiv
- enten
- elektroteknikk
- emalje
- muliggjør
- ingeniør
- Ingeniørarbeid
- sikrer
- avgjørende
- etablert
- anslått
- Eter (ETH)
- europeisk
- evaluere
- evaluert
- evaluering
- bevis
- eksempel
- eksempler
- eksperiment
- eksperimenter
- forklare
- explorer
- Face
- legge til rette
- Faktisk
- familie
- vifte
- langt
- Mote
- tilbakemelding
- avgifter
- kar
- Endelig
- Finn
- Først
- Fisk
- fiske
- svinger
- Fokus
- følge
- etter
- Til
- Forks
- Fundament
- Rammeverk
- Frankrike
- ofte
- fra
- fullt
- funksjon
- videre
- gateway
- general
- generelt
- generere
- generert
- genererer
- generasjoner
- generative
- Generativ AI
- få
- få
- gå
- GitHub
- gitt
- mål
- borte
- god
- flott
- Storbritannia
- Ground
- veiledning
- lykkelig
- skadelig
- Ha
- he
- hode
- Helse
- Hjerte
- tung
- tung løfting
- Held
- hjelpe
- nyttig
- hh
- høykvalitets
- høyest
- svært
- hans
- holder
- vert
- Hvordan
- Hvordan
- Men
- HTML
- HTTPS
- menneskelig
- Mennesker
- i
- JEG VIL
- ideell
- IEEE
- if
- illustrerer
- Påvirkning
- importere
- viktig
- forbedre
- forbedringer
- forbedrer
- bedre
- in
- inkluderer
- Øke
- økende
- uavhengighet
- industri
- informasjon
- initiert
- Starter
- initiativer
- installere
- f.eks
- instruksjoner
- Intelligens
- interaktiv
- interesse
- interesser
- Interface
- grensesnitt
- innebærer
- IT
- køyring
- DET ER
- sammenføyning
- jpg
- Knowing
- merking
- Labs
- Tomt
- Språk
- stor
- storskala
- lansere
- lansert
- Law
- Fører
- LÆRE
- læring
- minst
- Lengde
- Bibliotek
- løfte
- laste
- ser
- elsker
- lavere
- Lunger
- maskin
- maskinlæring
- gjøre
- fikk til
- leder
- administrerende
- mange
- Martin
- massive
- Maksimer
- me
- bety
- betyr
- måle
- medium
- nevnt
- metode
- Microsoft
- Microsoft Research
- kunne
- speil
- Blanding
- modell
- modeller
- modifisere
- mer
- Mozilla
- må
- my
- Naturlig
- Naturlig språk
- Natural Language Processing
- Trenger
- NeurIPS
- neste
- natt
- nord
- bærbare
- nå
- mål
- observere
- få
- of
- ofte
- on
- ONE
- seg
- bare
- åpen
- opererer
- Opportunity
- optimalisering
- Optimalisere
- Optimaliserer
- optimalisere
- or
- original
- vår
- produksjon
- enn
- samlet
- egen
- Oxford
- pakke
- parametere
- foreldre
- del
- Spesielt
- passere
- banen
- oppfattet
- persepsjon
- utføre
- utført
- utfører
- phd
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- spiller
- vær så snill
- i tillegg til
- politikk
- Pony
- Populær
- stillinger
- Post
- kraftig
- krefter
- forutsi
- preferanser
- trekkes
- Forbered
- forbereder
- forutsetninger
- forrige
- tidligere
- problemer
- prosedyren
- prosess
- prosessering
- produsere
- produsert
- produserende
- Produkt
- Professor
- utprøvd
- gi
- forutsatt
- gir
- offentlig
- offentlig
- formål
- pytorch
- kvalitativ
- Quebec
- spørsmål
- spørsmål
- rangerer
- rask
- heller
- virkelig
- .
- gjenkjent
- anbefaler
- reduserer
- redusere
- referere
- referert
- Gjenspeiler
- forsterkning læring
- i slekt
- fjerne
- rapportert
- Repository
- representasjon
- påkrevd
- Krever
- forskning
- ligner
- Ressurser
- de
- svar
- svar
- resultere
- resulterende
- anmeldelse
- Belønn
- Risiko
- risikoer
- rob
- robotikk
- Regel
- Kjør
- rennende
- sagemaker
- Skala
- skala ai
- Vitenskap
- Forsker
- score
- script
- senior
- forstand
- tjeneste
- Tjenester
- sett
- flere
- forskjøvet
- Kort
- bør
- Vis
- viste
- vist
- Viser
- lignende
- ganske enkelt
- siden
- sitte
- dyktig
- liten
- So
- Software
- programvareutvikling
- Solutions
- LØSE
- noen
- noen ganger
- Spania
- Spansk
- Spenning
- spesifikk
- spesifisert
- utgifter
- Standard
- startet
- Trinn
- Steps
- oppbevare
- Strategisk
- gate
- studio
- slik
- foreslår
- støtte
- Støtte
- sikker
- Systemer
- bord
- tatt
- Snakk
- Oppgave
- oppgaver
- lag
- pleier
- tennessee
- territorium
- test
- tekst
- enn
- Det
- De
- loven
- deres
- Dem
- deretter
- Disse
- ting
- denne
- De
- tre
- Gjennom
- Tied
- tid
- ganger
- til
- token
- også
- verktøy
- Tog
- trent
- Kurs
- Trend
- Sannhet
- prøve
- SVING
- vri nøkkel
- tutorials
- to
- typen
- Uber
- ui
- etter
- gått
- forstå
- universitet
- University of Oxford
- uforutsigbare
- oppadgående
- bruke
- brukt
- bruker
- ved hjelp av
- vanligvis
- verdi
- Verdier
- ulike
- veldig
- syn
- volatile
- rullator
- ønsker
- var
- we
- web
- webtjenester
- vekt
- VI VIL
- velvære
- var
- når
- hvilken
- mens
- vil
- ønsker
- med
- uten
- arbeidsflyt
- arbeidsstyrke
- arbeid
- virker
- Verksteder
- bekymret
- ville
- skrevet
- yaml
- år
- du
- Din
- deg selv
- zephyrnet