Som praktisk talt alle kunder, ønsker du å bruke så lite som mulig samtidig som du får best mulig ytelse. Dette betyr at du må være oppmerksom på pris-ytelse. Med Amazon RedShift, du kan ha kaken din og spise den også! Amazon Redshift leverer opptil 4.9 ganger lavere kostnad per bruker og opptil 7.9 ganger bedre prisytelse enn andre skydatavarehus på virkelige arbeidsbelastninger ved bruk av avanserte teknikker som samtidighetsskalering for å støtte hundrevis av samtidige brukere, forbedret strengkoding for raskere søkeytelse , og Amazon Redshift Serverløs ytelsesforbedringer. Les videre for å forstå hvorfor pris-ytelse betyr noe og hvordan Amazon Redshift-pris-ytelse er et mål på hvor mye det koster å få et bestemt nivå av arbeidsbelastningsytelse, nemlig ytelses-ROI (avkastning på investering).
Fordi både pris og ytelse kommer inn i pris-ytelse-beregningen, er det to måter å tenke pris-ytelse på. Den første måten er å holde prisen konstant: hvis du har $1 å bruke, hvor mye ytelse får du fra datavarehuset ditt? En database med bedre prisytelse vil gi bedre ytelse for hver $1 brukt. Derfor, når du holder prisen konstant når du sammenligner to datavarehus som koster det samme, vil databasen med bedre prisytelse kjøre søkene dine raskere. Den andre måten å se på pris-ytelse på er å holde ytelsen konstant: hvis du trenger at arbeidsmengden er ferdig på 10 minutter, hva vil det koste? En database med bedre prisytelse vil kjøre arbeidsmengden din på 10 minutter til en lavere kostnad. Derfor, når du holder ytelsen konstant når du sammenligner to datavarehus som er dimensjonert for å levere samme ytelse, vil databasen med bedre prisytelse koste mindre og spare deg penger.
Til slutt, et annet viktig aspekt ved prisytelse er forutsigbarhet. Å vite hvor mye datavarehuset ditt kommer til å koste etter hvert som antallet datavarehusbrukere vokser, er avgjørende for planleggingen. Det skal ikke bare levere den beste prisytelsen i dag, men også skalere forutsigbart og levere den beste prisytelsen etter hvert som flere brukere og arbeidsmengder legges til. Et ideelt datavarehus bør ha lineær skala– Å skalere datavarehuset til å levere dobbelt så høy spørringsgjennomstrømning bør ideelt sett koste dobbelt så mye (eller mindre).
I dette innlegget deler vi ytelsesresultater for å illustrere hvordan Amazon Redshift leverer betydelig bedre prisytelse sammenlignet med ledende alternative skydatavarehus. Dette betyr at hvis du bruker samme beløp på Amazon Redshift som du ville gjort på et av disse andre datavarehusene, vil du få bedre ytelse med Amazon Redshift. Alternativt, hvis du dimensjonerer Redshift-klyngen for å levere samme ytelse, vil du se lavere kostnader sammenlignet med disse alternativene.
Prisytelse for arbeidsbelastninger i den virkelige verden
Du kan bruke Amazon Redshift til å drive et svært bredt spekter av arbeidsbelastninger, fra batch-behandling av komplekse uttrekk, transformasjon og belastning (ETL)-baserte rapporter, og sanntids streaminganalyse til dashbord for business intelligence (BI) med lav ventetid som trenger å betjene hundrevis eller til og med tusenvis av brukere på samme tid med sekundære responstider, og alt i mellom. En av måtene vi kontinuerlig forbedrer prisytelse for kundene våre på, er å kontinuerlig gjennomgå programvare- og maskinvareytelsestelemetrien fra Redshift-flåten, på jakt etter muligheter og kundebrukstilfeller der vi kan forbedre Amazon Redshift-ytelsen ytterligere.
Noen nyere eksempler på ytelsesoptimaliseringer drevet av flåtetelemetri inkluderer:
- Optimalisering av strengsøk – Ved å analysere hvordan Amazon Redshift behandlet forskjellige datatyper i Redshift-flåten, fant vi ut at optimalisering av strengtunge spørringer ville gi betydelige fordeler for kundenes arbeidsbelastning. (Vi diskuterer dette mer detaljert senere i dette innlegget.)
- Automatiserte materialiserte visninger – Vi fant ut at Amazon Redshift-kunder ofte kjører mange spørringer som har vanlige underspørringsmønstre. For eksempel kan flere forskjellige spørringer slå sammen de samme tre tabellene ved å bruke samme sammenføyningsbetingelse. Amazon Redshift er nå i stand til å automatisk opprette og vedlikeholde materialiserte visninger og deretter transparent omskrive spørringer for å bruke de materialiserte visningene ved hjelp av maskinlærte automatisert materialisert visning autonomics-funksjon i Amazon Redshift. Når den er aktivert, kan automatiserte materialiserte visninger på en transparent måte øke søkeytelsen for repeterende spørringer uten brukerintervensjon. (Merk at automatiserte materialiserte visninger ikke ble brukt i noen av referanseresultatene diskutert i dette innlegget).
- Arbeidsbelastninger med høy samtidighet – En økende brukssak vi ser er å bruke Amazon Redshift for å betjene dashbordlignende arbeidsbelastninger. Disse arbeidsbelastningene er preget av ønskede spørringssvartider på ensifrede sekunder eller mindre, med titalls eller hundrevis av samtidige brukere som kjører spørringer samtidig med et piggete og ofte uforutsigbart bruksmønster. Det prototypiske eksempelet på dette er et Amazon Redshift-støttet BI-dashbord som har en økning i trafikken mandag morgen når et stort antall brukere starter uken.
Spesielt høy samtidige arbeidsbelastninger har svært bred anvendelighet: de fleste datavarehusarbeidsbelastninger opererer samtidig, og det er ikke uvanlig at hundrevis eller til og med tusenvis av brukere kjører spørringer på Amazon Redshift samtidig. Amazon Redshift ble designet for å holde spørringssvarstider forutsigbare og raske. Redshift Serverless gjør dette automatisk for deg ved å legge til og fjerne databehandling etter behov for å holde spørringssvarstider raske og forutsigbare. Dette betyr at et Redshift Serverless-støttet dashbord som lastes raskt når det blir åpnet av en eller to brukere, vil fortsette å laste raskt selv når mange brukere laster det samtidig.
For å simulere denne typen arbeidsbelastning brukte vi en benchmark avledet fra TPC-DS med et 100 GB datasett. TPC-DS er en industristandard benchmark som inkluderer en rekke typiske datavarehusspørringer. På denne relativt lille skalaen på 100 GB kjører spørringer i denne referansen på Redshift Serverless i gjennomsnitt på noen få sekunder, noe som er representativt for hva brukere som laster et interaktivt BI-dashbord ville forvente. Vi kjørte mellom 1–200 samtidige tester av denne referansen, og simulerte mellom 1–200 brukere som prøvde å laste et dashbord samtidig. Vi gjentok også testen mot flere populære alternative skydatavarehus som også støtter utskalering automatisk (hvis du er kjent med innlegget Amazon Redshift fortsetter sin ledelse i pris-ytelse, vi inkluderte ikke konkurrent A fordi den ikke støtter automatisk oppskalering). Vi målte gjennomsnittlig responstid for spørringer, som betyr hvor lenge en bruker vil vente på at søkene fullføres (eller dashbordet lastes inn). Resultatene er vist i følgende diagram.
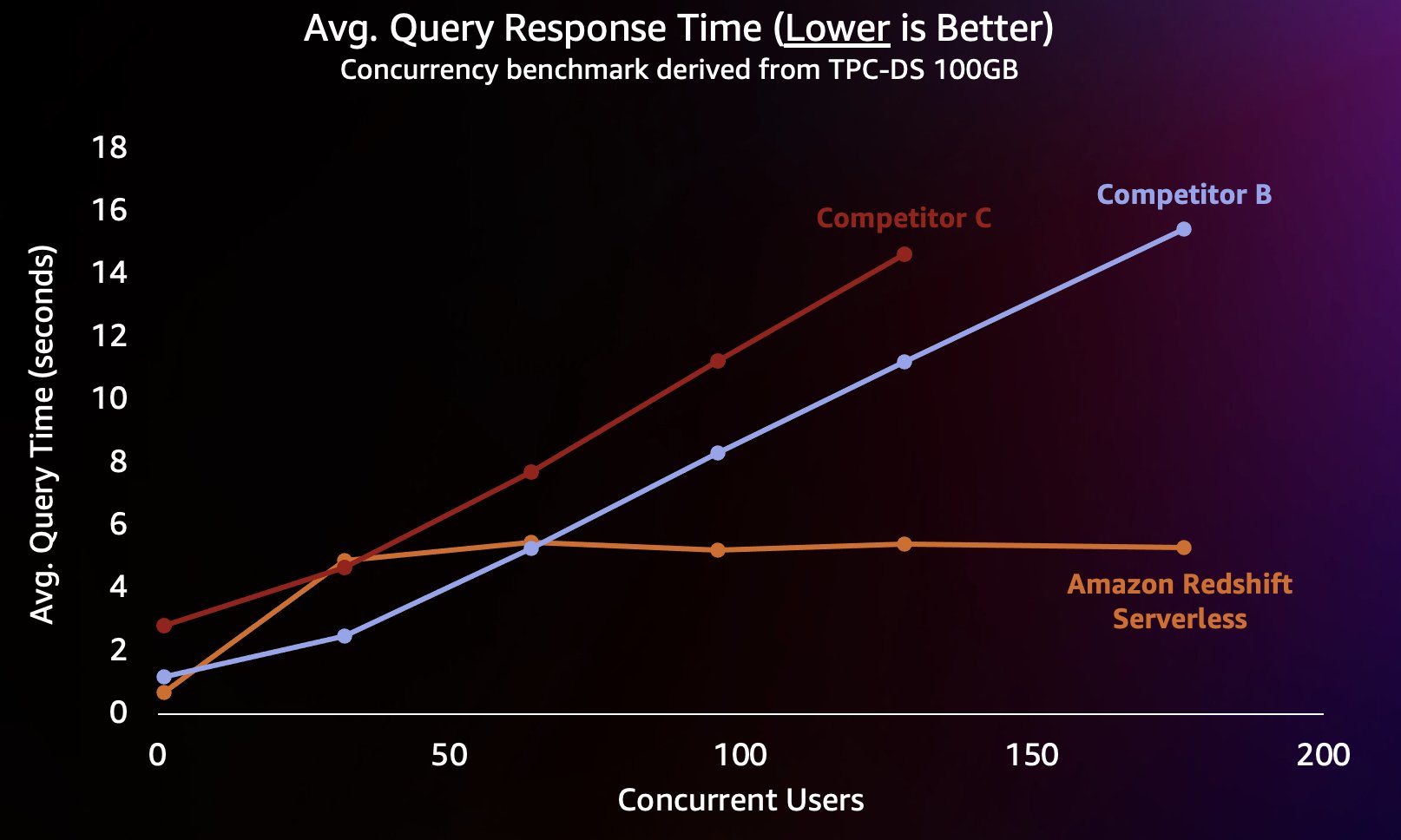
Konkurrent B skalerer godt til rundt 64 samtidige spørringer, på hvilket tidspunkt den ikke er i stand til å gi ytterligere beregning og spørringer begynner å stå i kø, noe som fører til økte svartider for spørringene. Selv om konkurrent C er i stand til å skalere automatisk, skalerer den til lavere søkegjennomstrømning enn både Amazon Redshift og konkurrent B og er ikke i stand til å holde spørringskjøringen lav. I tillegg støtter den ikke køspørringer når den går tom for databehandling, noe som hindrer den i å skalere utover rundt 128 samtidige brukere. Innsending av ytterligere forespørsler utover dette avvises av systemet.
Her er Redshift Serverless i stand til å holde spørringssvartiden relativt konsistent på rundt 5 sekunder selv når hundrevis av brukere kjører spørringer samtidig. Gjennomsnittlig responstid for spørringer for konkurrentene B og C øker jevnt og trutt ettersom belastningen på varehusene øker, noe som resulterer i at brukere må vente lenger (opptil 16 sekunder) på at spørringene skal returnere når datavarehuset er opptatt. Dette betyr at hvis en bruker prøver å oppdatere et dashbord (som til og med kan sende inn flere samtidige forespørsler når det lastes på nytt), vil Amazon Redshift være i stand til å holde dashbordets lastetider langt mer konsekvente selv om dashbordet lastes inn av titalls eller hundrevis av andre brukere samtidig.
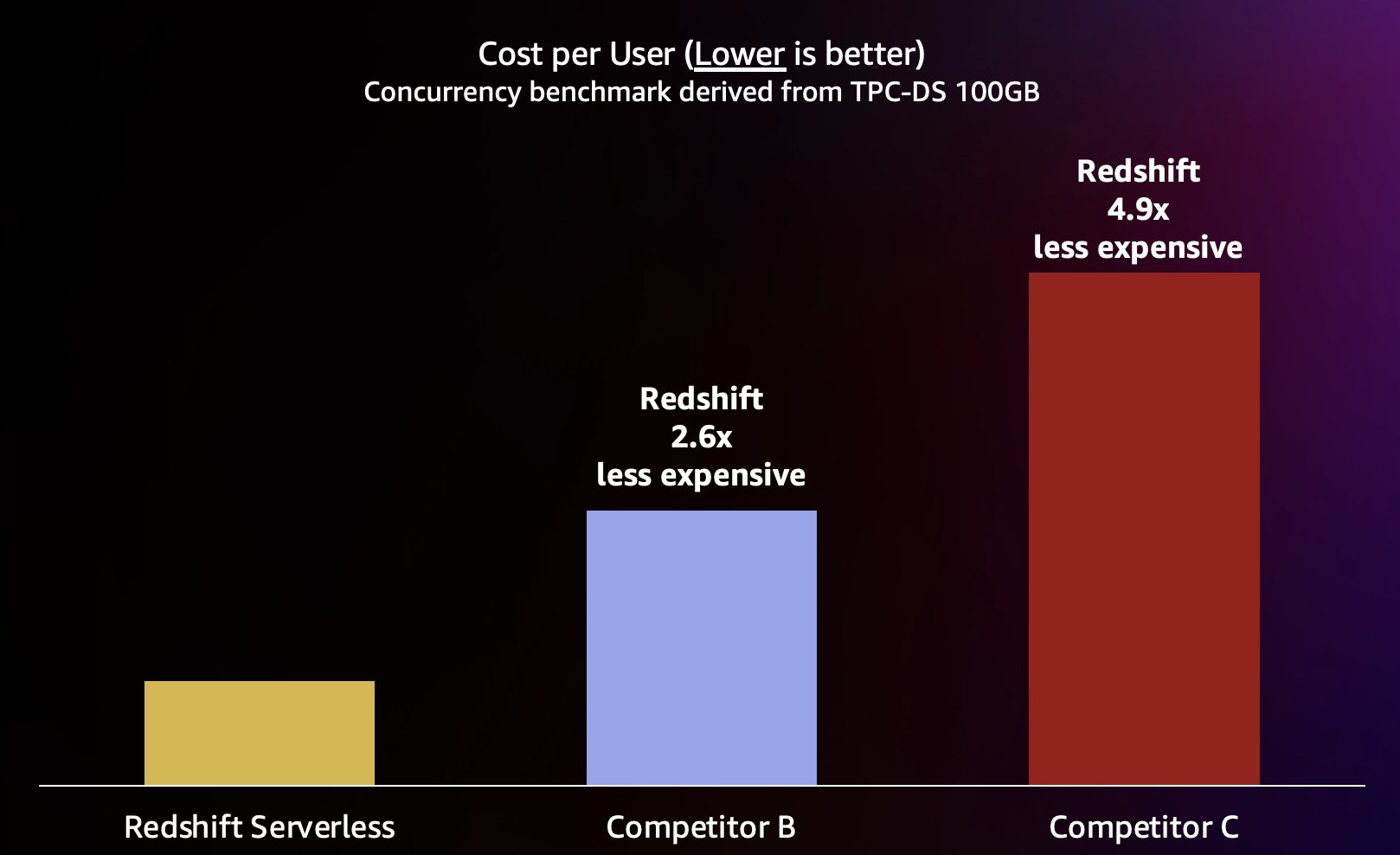
Fordi Amazon Redshift er i stand til å levere svært høy søkegjennomstrømning for korte søk (som vi skrev om i Amazon Redshift fortsetter sin ledelse i pris-ytelse), er den også i stand til å håndtere disse høyere samtidighetene når den skaleres ut mer effektivt og derfor til en betydelig lavere kostnad. For å kvantifisere dette ser vi på pris-ytelse ved å bruke publisert on-demand-priser for hvert av varehusene i den foregående testen, vist i følgende diagram. Det er verdt å merke seg at bruk Reserverte forekomster (RIer), spesielt 3-års RI-er kjøpt med forhåndsbetalingsalternativet, har den laveste kostnaden for å kjøre Amazon Redshift på Provisioned-klynger, noe som resulterer i den beste relative prisytelsen sammenlignet med on-demand eller andre RI-alternativer.

Så ikke bare er Amazon Redshift i stand til å levere bedre ytelse ved høyere samtidigheter, det er i stand til å gjøre det til betydelig lavere kostnader. Hvert datapunkt i pris-ytelse-diagrammet tilsvarer kostnaden for å kjøre referanseindeksen ved den angitte samtidigheten. Fordi prisytelsen er lineær, kan vi dele kostnadene for å kjøre referanseindeksen ved enhver samtidighet med samtidigheten (antall samtidige brukere i dette diagrammet) for å fortelle oss hvor mye det koster å legge til hver ny bruker for denne spesifikke referansen.
De foregående resultatene er enkle å gjenskape. Alle forespørsler som brukes i benchmark er tilgjengelige i vår GitHub repository og ytelsen måles ved å starte et datavarehus, aktivere Concurrency Scaling på Amazon Redshift (eller den tilsvarende automatiske skaleringsfunksjonen på andre varehus), laste dataene ut av esken (ingen manuell justering eller databasespesifikt oppsett), og deretter kjøre en samtidig strøm av spørringer ved samtidigheter fra 1–200 i trinn på 32 på hvert datavarehus. Den samme GitHub-repoen refererer til forhåndsgenererte (og umodifiserte) TPC-DS-data i Amazon enkel lagringstjeneste (Amazon S3) i forskjellige skalaer ved å bruke det offisielle TPC-DS-datagenereringssettet.
Optimalisering av strengtunge arbeidsbelastninger
Som nevnt tidligere, leter Amazon Redshift-teamet kontinuerlig etter nye muligheter for å levere enda bedre prisytelse for kundene våre. En forbedring vi nylig lanserte som betydelig forbedret ytelse er en optimalisering som akselererer ytelsen til spørringer over strengdata. Det kan for eksempel være lurt å finne den totale inntekten generert fra butikker i New York City med et søk som SELECT sum(price) FROM sales WHERE city = ‘New York’. Denne spørringen bruker et predikat over strengdata (city = ‘New York’). Som du kan forestille deg, er strengdatabehandling allestedsnærværende i datavarehusapplikasjoner.
For å kvantifisere hvor ofte kundenes arbeidsbelastning får tilgang til strenger, utførte vi en detaljert analyse av bruken av strengdatatyper ved å bruke flåtetelemetri til titusenvis av kundeklynger administrert av Amazon Redshift. Vår analyse indikerer at i 90 % av klyngene utgjør strengkolonner minst 30 % av alle kolonnene, og i 50 % av klyngene utgjør strengkolonner minst 50 % av alle kolonnene. Dessuten kjører et flertall av alle forespørsler på Amazon Redshift cloud data warehouse-plattformen tilgang til minst én strengkolonne. En annen viktig faktor er at strengdata svært ofte har lav kardinalitet, noe som betyr at kolonnene inneholder et relativt lite sett med unike verdier. For eksempel, selv om en orders tabell som representerer salgsdata kan inneholde milliarder av rader, en order_status kolonne i den tabellen kan inneholde bare noen få unike verdier på tvers av disse milliarder av rader, for eksempel pending, in processog completed.
Når dette skrives, er de fleste strengkolonner i Amazon Redshift komprimert med LZO or ZSTD algoritmer. Dette er gode generelle komprimeringsalgoritmer, men de er ikke laget for å dra nytte av strengdata med lav kardinalitet. Spesielt krever de at data dekomprimeres før de betjenes, og er mindre effektive i bruken av maskinvareminnebåndbredde. For data med lav kardinalitet er det en annen type koding som kan være mer optimal: BYTEDICT. Denne kodingen bruker et ordbokkodingsskjema som lar databasemotoren operere direkte over komprimerte data uten å måtte dekomprimere dem først.
For ytterligere å forbedre prisytelsen for strengtunge arbeidsbelastninger, introduserer Amazon Redshift nå ytterligere ytelsesforbedringer som øker hastigheten på skanninger og predikatevalueringer, over strengkolonner med lav kardinalitet som er kodet som BYTEDICT, mellom 5–63 ganger raskere (se resultater i neste avsnitt) sammenlignet med alternative komprimeringskodinger som LZO eller ZSTD. Amazon Redshift oppnår denne ytelsesforbedringen ved å vektorisere skanninger over lette, CPU-effektive, BYTEDICT-kodede strengkolonner med lav kardinalitet. Disse strengbehandlingsoptimaliseringene gjør effektiv bruk av minnebåndbredde som tilbys av moderne maskinvare, og muliggjør sanntidsanalyse over strengdata. Disse nylig introduserte ytelsesmulighetene er optimale for strengkolonner med lav kardinalitet (opptil noen hundre unike strengverdier).
Du kan automatisk dra nytte av denne nye strengforbedringen med høy ytelse ved å aktivere automatisk tabelloptimalisering i ditt Amazon Redshift-datavarehus. Hvis du ikke har automatisk tabelloptimalisering aktivert på tabellene dine, kan du motta anbefalinger fra Amazon Redshift Advisor i Amazon Redshift-konsollen på en strengkolonnes egnethet for BYTEDICT-koding. Du kan også definere nye tabeller som har strengkolonner med lav kardinalitet med BYTEDICT-koding. Strengeforbedringer i Amazon Redshift er nå tilgjengelig i alle AWS-regioner hvor Amazon Redshift er tilgjengelig.
Ytelsesresultater
For å måle ytelseseffekten av strengforbedringene våre genererte vi et 10TB (Tera Byte) datasett som besto av strengdata med lav kardinalitet. Vi genererte tre versjoner av dataene ved å bruke korte, middels og lange strenger, tilsvarende den 25., 50. og 75. persentilen av strenglengder fra Amazon Redshift-flåtetelemetri. Vi lastet disse dataene inn i Amazon Redshift to ganger, og kodet dem i ett tilfelle ved å bruke LZO-komprimering og i et annet ved å bruke BYTEDICT-komprimering. Til slutt målte vi ytelsen til skanningstunge søk som returnerer mange rader (90 % av tabellen), et middels antall rader (50 % av tabellen) og noen få rader (1 % av tabellen) over disse lave -kardinalitetsstrengdatasett. Resultatresultatene er oppsummert i følgende diagram.

Spørringer med predikater som samsvarer med en høy prosentandel av rader, så forbedringer på 5–30 ganger med den nye vektoriserte BYTEDICT-kodingen sammenlignet med LZO, mens søk med predikater som samsvarer med en lav prosentandel rader så forbedringer på 10–63 ganger i denne interne referansen.
Redshift Serverløs pris-ytelse
I tillegg til ytelsesresultatene med høy samtidighet som presenteres i dette innlegget, brukte vi også TPC-DS-avledet Cloud Data Warehouse-benchmark for å sammenligne prisytelsen til Redshift Serverless med andre datavarehus som bruker et større 3TB-datasett. Vi valgte datavarehus som ble priset på samme måte, i dette tilfellet innenfor 10 % av $32 per time ved å bruke offentlig tilgjengelige on-demand-priser. Disse resultatene viser at i likhet med Amazon Redshift RA3-forekomster, leverer Redshift Serverless bedre prisytelse sammenlignet med andre ledende skydatavarehus. Som alltid kan disse resultatene replikeres ved å bruke våre SQL-skript i vår GitHub repository.

Vi oppfordrer deg til å prøve Amazon Redshift med din egen proof of concept arbeidsbelastninger som den beste måten å se hvordan Amazon Redshift kan møte dine behov for dataanalyse.
Finn den beste prisytelsen for arbeidsmengdene dine
Referansene som brukes i dette innlegget er avledet fra industristandarden TPC-DS-referansen, og har følgende egenskaper:
- Skjemaet og dataene brukes uendret fra TPC-DS.
- Spørringene genereres ved hjelp av det offisielle TPC-DS-settet med spørringsparametere generert ved bruk av standard tilfeldig frø til TPC-DS-settet. TPC-godkjente spørringsvarianter brukes for et lager hvis lageret ikke støtter SQL-dialekten til standard TPC-DS-spørringen.
- Testen inkluderer de 99 TPC-DS SELECT-spørringene. Det inkluderer ikke vedlikeholds- og gjennomstrømningstrinn.
- For den enkle 3TB samtidighetstesten ble det kjørt tre strømkjøringer, og den beste kjøringen er tatt for hvert datavarehus.
- Pris-ytelse for TPC-DS-spørringene beregnes som kostnad per time (USD) ganger referansekjøretiden i timer, som tilsvarer kostnaden for å kjøre referanseindeksen. Den siste publiserte on-demand-prisene brukes for alle datavarehus og ikke reserverte forekomster som nevnt tidligere.
Vi kaller dette Cloud Data Warehouse benchmark, og du kan enkelt reprodusere de foregående benchmarkresultatene ved å bruke skriptene, spørringene og dataene som er tilgjengelige i vår GitHub repository. Det er avledet fra TPC-DS-standardene som beskrevet i dette innlegget, og kan som sådan ikke sammenlignes med publiserte TPC-DS-resultater, fordi resultatene av testene våre ikke samsvarer med den offisielle spesifikasjonen.
konklusjonen
Amazon Redshift er forpliktet til å levere bransjens beste prisytelse for det bredeste utvalget av arbeidsbelastninger. Redshift Serverless skalerer lineært med den beste (laveste) prisytelsen, og støtter hundrevis av samtidige brukere samtidig som de opprettholder konsistente spørringssvartider. Basert på testresultater diskutert i dette innlegget, har Amazon Redshift opptil 2.6 ganger bedre pris-ytelse på samme nivå av samtidighet sammenlignet med nærmeste konkurrent (konkurrent B). Som nevnt tidligere, gir bruk av reserverte forekomster med 3-års all upfront-alternativet deg den laveste kostnaden for å kjøre Amazon Redshift, noe som resulterer i enda bedre relativ prisytelse sammenlignet med on-demand forekomstpriser som vi brukte i dette innlegget. Vår tilnærming til kontinuerlig ytelsesforbedring innebærer en unik kombinasjon av kundebesatthet for å forstå kundetilfeller og deres tilknyttede skalerbarhetsflaskehalser kombinert med kontinuerlig flåtedataanalyse for å identifisere muligheter for å gjøre betydelige ytelsesoptimaliseringer.
Hver arbeidsmengde har unike egenskaper, så hvis du akkurat har begynt, a proof of concept er den beste måten å forstå hvordan Amazon Redshift kan senke kostnadene dine og samtidig levere bedre ytelse. Når du kjører ditt eget proof of concept, er det viktig å fokusere på de riktige beregningene – søkegjennomstrømning (antall søk per time), responstid og prisytelse. Du kan ta en datadrevet beslutning ved å kjøre et proof of concept på egen hånd eller med bistand fra AWS eller a systemintegrasjon og konsulentpartner.
For å holde deg oppdatert med den siste utviklingen i Amazon Redshift, følg Hva er nytt i Amazon Redshift mate.
Om forfatterne
 Stefan Gromoll er en senior ytelsesingeniør med Amazon Redshift-teamet hvor han er ansvarlig for å måle og forbedre Redshift-ytelsen. På fritiden liker han å lage mat, leke med de tre guttene sine og hogge ved.
Stefan Gromoll er en senior ytelsesingeniør med Amazon Redshift-teamet hvor han er ansvarlig for å måle og forbedre Redshift-ytelsen. På fritiden liker han å lage mat, leke med de tre guttene sine og hogge ved.
 Ravi Animi er en Senior Product Management-leder i Amazon Redshift-teamet og administrerer flere funksjonelle områder av Amazon Redshift skydatavarehustjeneste, inkludert ytelse, romlig analyse, streaming-inntak og migreringsstrategier. Han har erfaring med relasjonsdatabaser, flerdimensjonale databaser, IoT-teknologier, lagrings- og datainfrastrukturtjenester og nylig som oppstartsgründer med bruk av AI/dyplæring, datasyn og robotikk.
Ravi Animi er en Senior Product Management-leder i Amazon Redshift-teamet og administrerer flere funksjonelle områder av Amazon Redshift skydatavarehustjeneste, inkludert ytelse, romlig analyse, streaming-inntak og migreringsstrategier. Han har erfaring med relasjonsdatabaser, flerdimensjonale databaser, IoT-teknologier, lagrings- og datainfrastrukturtjenester og nylig som oppstartsgründer med bruk av AI/dyplæring, datasyn og robotikk.
 Aamer Shah er senioringeniør i Amazon Redshift Service-teamet.
Aamer Shah er senioringeniør i Amazon Redshift Service-teamet.
 Sanket Hase er en programvareutviklingssjef i Amazon Redshift Service-teamet.
Sanket Hase er en programvareutviklingssjef i Amazon Redshift Service-teamet.
 Orestis Polychroniou er hovedingeniør i Amazon Redshift Service-teamet.
Orestis Polychroniou er hovedingeniør i Amazon Redshift Service-teamet.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 10
- 100
- 16
- 32
- 7
- 9
- a
- I stand
- Om oss
- akselererer
- adgang
- aksesseres
- oppnår
- tvers
- la til
- legge
- tillegg
- Ytterligere
- avansert
- Fordel
- råd til
- mot
- algoritmer
- Alle
- tillater
- også
- alternativ
- alternativer
- Selv
- alltid
- Amazon
- Amazon Web Services
- beløp
- an
- analyse
- analytics
- analyserer
- og
- En annen
- noen
- søknader
- påføring
- tilnærming
- ER
- områder
- rundt
- AS
- aspektet
- assosiert
- At
- oppmerksomhet
- auto
- Automatisert
- Automatisk
- automatisk
- tilgjengelig
- gjennomsnittlig
- AWS
- b
- Båndbredde
- basert
- BE
- fordi
- før du
- begynne
- være
- benchmark
- benchmarks
- nytte
- BEST
- Bedre
- mellom
- Beyond
- milliarder
- både
- flaskehalser
- Eske
- bringe
- bred
- virksomhet
- business intelligence
- opptatt
- men
- by
- KAKE
- beregnet
- beregningen
- ring
- CAN
- evner
- saken
- saker
- egenskaper
- karakterisert
- Figur
- hakking
- valgte
- City
- Cloud
- Cluster
- Kolonne
- kolonner
- kombinasjon
- forpliktet
- Felles
- sammenlign
- sammenligne
- sammenlignet
- sammenligne
- konkurrent
- konkurrenter
- komplekse
- overholde
- Beregn
- datamaskin
- Datamaskin syn
- konsept
- samtidig
- tilstand
- gjennomført
- konsistent
- Konsoll
- konstant
- stadig
- utgjør
- konsulent
- inneholde
- kontinuerlig
- fortsette
- fortsetter
- kontinuerlig
- kontinuerlig
- matlaging
- Tilsvarende
- Kostnad
- Kostnader
- kombinert
- skape
- avgjørende
- kunde
- Kunder
- dashbord
- oversikter
- dato
- dataanalyse
- Data Analytics
- databehandling
- datasett
- datalager
- datavarehus
- data-drevet
- Database
- databaser
- datasett
- Dato
- avgjørelse
- Misligholde
- definere
- leverer
- levere
- leverer
- Avledet
- beskrevet
- designet
- ønsket
- detalj
- detaljert
- Utvikling
- utviklingen
- forskjellig
- direkte
- diskutere
- diskutert
- Mangfold
- dele
- do
- gjør
- ikke
- ikke
- drevet
- hver enkelt
- Tidligere
- lett
- spise
- Effektiv
- effektiv
- effektivt
- aktivert
- muliggjør
- oppmuntre
- Motor
- ingeniør
- forbedret
- ekstrautstyr
- forbedringer
- Enter
- Tilsvarende
- spesielt
- Eter (ETH)
- evalueringer
- Selv
- alt
- eksempel
- eksempler
- forvente
- erfaring
- trekke ut
- faktor
- kjent
- langt
- FAST
- raskere
- Trekk
- Noen få
- Endelig
- Finn
- ferdig
- Først
- FLÅTE
- Fokus
- følge
- etter
- Til
- funnet
- Grunnleggeren
- fra
- funksjonelle
- videre
- generell
- generert
- generasjonen
- få
- få
- GitHub
- gir
- skal
- god
- Økende
- Vokser
- håndtere
- maskinvare
- Ha
- å ha
- he
- Høy
- høyere
- hans
- hold
- holder
- time
- TIMER
- Hvordan
- HTML
- http
- HTTPS
- hundre
- Hundrevis
- ideell
- ideelt sett
- identifisere
- if
- illustrere
- forestille
- Påvirkning
- viktig
- viktig aspekt
- forbedre
- forbedret
- forbedring
- forbedringer
- bedre
- in
- inkludere
- inkluderer
- Inkludert
- Øke
- økt
- øker
- indikerer
- industriens
- Infrastruktur
- f.eks
- forekomster
- integrering
- Intelligens
- interaktiv
- intern
- intervensjon
- inn
- introdusert
- innføre
- investering
- innebærer
- IOT
- IT
- DET ER
- bli medlem
- jpg
- bare
- Hold
- kit
- Knowing
- stor
- større
- seinere
- siste
- siste utvikling
- lansert
- lansere
- leder
- ledende
- læring
- minst
- mindre
- Nivå
- lettvekt
- i likhet med
- lite
- laste
- lasting
- laster
- ligger
- Lang
- lenger
- Se
- ser
- Lav
- lavere
- lavest
- vedlikeholde
- opprettholde
- vedlikehold
- Flertall
- gjøre
- fikk til
- ledelse
- leder
- forvalter
- håndbok
- mange
- Match
- Saker
- Kan..
- betyr
- midler
- måle
- målte
- måling
- medium
- Møt
- Minne
- nevnt
- kunne
- migrasjon
- minutter
- Moderne
- mandag
- penger
- mer
- Videre
- mest
- mye
- nemlig
- Trenger
- nødvendig
- behov
- Ny
- New York
- New York City
- nylig
- neste
- Nei.
- note
- bemerket
- merke seg
- nå
- Antall
- of
- offisiell
- ofte
- on
- På etterspørsel
- ONE
- bare
- betjene
- operert
- Muligheter
- optimal
- optimalisering
- optimalisere
- Alternativ
- alternativer
- or
- Annen
- vår
- ut
- enn
- egen
- parametere
- Spesielt
- Mønster
- mønstre
- Betale
- betaling
- for
- prosent
- ytelse
- planlegging
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- Point
- Populær
- mulig
- Post
- makt
- Forutsigbar
- presentert
- forhindrer
- pris
- prising
- Principal
- behandlet
- prosessering
- Produkt
- produktledelse
- bevis
- proof of concept
- gi
- offentlig
- publisert
- kjøpt
- spørsmål
- raskt
- tilfeldig
- Lese
- virkelige verden
- sanntids
- motta
- nylig
- nylig
- anbefalinger
- referanser
- regioner
- Avvist..
- slektning
- relativt
- fjerne
- gjentatt
- repeterende
- replikert
- Rapporter
- representant
- representerer
- krever
- reservert
- svar
- ansvarlig
- resulterende
- Resultater
- detaljhandel
- retur
- inntekter
- anmeldelse
- ikke sant
- robotikk
- ROI
- Kjør
- rennende
- går
- salg
- samme
- Spar
- så
- skalerbarhet
- Skala
- vekter
- skalering
- skanner
- ordningen
- skript
- Sekund
- sekunder
- Seksjon
- se
- seed
- senior
- betjene
- server~~POS=TRUNC
- tjeneste
- Tjenester
- sett
- oppsett
- flere
- Del
- Kort
- bør
- Vis
- vist
- signifikant
- betydelig
- på samme måte
- Enkelt
- samtidig
- enkelt
- Størrelse
- størrelse
- liten
- So
- Software
- programvareutvikling
- romlig
- spesifikasjon
- spesifisert
- fart
- bruke
- brukt
- spike
- SQL
- Begynn
- startet
- oppstart
- opphold
- stadig
- Steps
- lagring
- butikker
- rett fram
- strategier
- stream
- streaming
- String
- send
- slik
- egnethet
- støtte
- Støtte
- system
- bord
- Ta
- tatt
- lag
- teknikker
- Technologies
- fortelle
- titus
- test
- tester
- enn
- Det
- De
- deres
- deretter
- Der.
- derfor
- Disse
- de
- tror
- denne
- De
- tusener
- tre
- gjennomstrømning
- tid
- ganger
- til
- i dag
- Totalt
- trafikk
- Transform
- transparent
- prøve
- prøver
- To ganger
- to
- typen
- typer
- typisk
- allestedsnærværende
- ute av stand
- Uvanlig
- forstå
- unik
- uforutsigbare
- til
- us
- bruk
- USD
- bruke
- bruk sak
- brukt
- Bruker
- Brukere
- bruker
- ved hjelp av
- Verdier
- variasjon
- ulike
- veldig
- visninger
- nesten
- syn
- vente
- ønsker
- Warehouse
- var
- Vei..
- måter
- we
- web
- webtjenester
- uke
- VI VIL
- var
- Hva
- når
- mens
- hvilken
- mens
- hvorfor
- bred
- vil
- med
- innenfor
- uten
- verdt
- ville
- skriving
- skrev
- york
- du
- Din
- zephyrnet