ABBYY er et globalt teknologiselskap som leverer løsninger for dokumentbehandling, datafangst og språkbaserte teknologier. Det ble grunnlagt i 1989 av en gruppe lingvister og ingeniører fra Moscow State University. Selskapets navn er et akronym for "Advanced Business Computer Systems."
ABBYYs første produkter var ordbøker og språklig programvare for forskjellige markeder. På 1990-tallet utvidet ABBYY sin produktlinje til å omfatte apper for optisk tegngjenkjenning (OCR) og dokumentskanning. ABBYYs PDF-produkter er noen av de mest populære på markedet. Mer enn 100 millioner mennesker bruker ABBYY PDF-produkter hver dag. Selskapet streber etter å tilby nøyaktige, pålitelige og brukervennlige løsninger som alle kan bruke, fra enkeltpersoner til store organisasjoner.
Dette blogginnlegget vil gi en oversikt over deres produktlinje og noen fordeler/ulemper ved å jobbe sammen. Vi vil også sammenligne noen av produktene deres med de som tilbys av andre førsteklasses selskaper i denne bransjen, slik at du kan avgjøre om de passer for dine behov.
La oss dykke inn.
Hvilke løsninger tilbyr ABBYY?
ABBYY tilbyr et komplett utvalg OCR- og PDF-konvertering og redigeringsprogramvare som er enkel å bruke og pålitelig. Produktene deres lar brukere konvertere dokumenter til søkbare PDF-er, redigere PDF-er og trekke ut data fra skjemaer og tabeller. Selskapet tilbyr også en mobilapp for iOS- og Android-enheter som lar brukere skanne og konvertere papirdokumenter til digitale formater. I denne delen vil vi utforske de forskjellige tjenestene de tilbyr.
ABBYY Vantage
ABBYY Vantage er en dokumenthåndteringsløsning som lar deg automatisere forretningsprosessene dine ved hjelp av smarte algoritmer og kunstig intelligens. Du kan forbedre effektiviteten til arbeidsflyten din ved å bruke dette verktøyet til å konvertere, kommentere, behandle og trekke ut data fra ulike dokumenter. Dette verktøyet lar deg også bruke OCR-teknologi til ulike formål som dokumentklassifisering, indeksering og søk. ABBYY Vantage tilbyr også dataanalysefunksjoner for å hjelpe bedrifter med å spore trender og få ny innsikt om virksomheten deres.
ABBYY tidslinje
ABBYY Timeline er et program for å visualisere historiske hendelser fra ustrukturerte tekstdokumenter som nyhetsartikler eller e-poster. Verktøyet lar brukere se hvordan konsepter utvikler seg og identifisere mønstre i trender over tid. Først og fremst bruker denne applikasjonen naturlig språkbehandlingsteknikker for å identifisere hendelser fra tekstdokumenter og grupperer deretter hendelsene i tidslinjer basert på typen hendelse.
ABBYY FlexiCapture
ABBYY FlexiCapture er en programvarepakke som hjelper organisasjoner automatisk å fange nøkkelfelt fra papirskjemaer til databasene eller CRM-systemene deres. Dette verktøyet kan enkelt trekke ut data fra ulike skjemaer, inkludert fakturaer, innkjøpsordrer, kontoutskrifter, forsikringskrav, etc.
ABBYY FlexiCapture for fakturaer
ABBYY FlexiCapture for Invoices er utviklet for å hjelpe bedrifter å strømlinjeforme fakturahåndteringsprosessene ved å automatisere fakturabehandlingsoppgaver. Denne løsningen lar deg spare tid ved automatisk å trekke ut, standardisere og berike data fra fakturaer med tilleggsinformasjon fra dine interne databaser og lage tilpassede rapporter basert på dine behov.
ABBYY FineReader Server
ABBYY FineReader Server er en løsning for automatisert dokumentkonvertering, indeksering og henting på serversiden. Den konverterer skannede dokumenter til redigerbare formater i sanntid ved hjelp av OCR-teknologi (optisk tegngjenkjenning), og lar dermed brukere redigere og gjenbruke dem etter behov. Løsningen tilbyr også avanserte funksjoner som finmasket indeksering for søkbarhet og forbedret dokumentanalyse for en bedre forståelse av blant annet innholdsstrukturen.
Enterprise-løsningene fra ABBYY er tilgjengelige for integrering med forskjellige systemer gjennom SDK-er og utviklerverktøy.
ABBYY FlexiCapture og ABBYY FineReader er de to mest populære tjenestene som tilbys av ABBYY. La oss ta en nærmere titt.
ABBYY FlexiCapture har mange funksjoner til felles med ABBYY FineReader Server (tidligere merket som Recognition Server). Hvert produkt er imidlertid designet med unike funksjoner, som bedrifter må vurdere når de vurderer løsninger for dokumentfangst og OCR-krav. For å hjelpe deg å sammenligne produktene enklere, har vi satt sammen en liste over brukstilfeller som lar deg vurdere mellom ABBYY FlexiCapture og FineReader Server.
Leter du etter en intelligent tekstgjenkjenningsløsning? Gå over til Nanonetter og bruk løsningen med nøyaktighet over 95%.
Hva er tilfellene for forretningsbruk av ABBYY Finereader OCR?
ABBYY FineReader Server er et dokumentkonverteringsprogram som brukes til å konvertere dokumenter og bilder til søkbare formater. Programmet opererer på en server, og muliggjør storskala konvertering av dokumenter innenfor en bedrifts behandlingstidsramme. Det kan også være en kostnadseffektiv måte for bedrifter å fange opp og manuelt indeksere dokumenter på tvers av bedriften, enten gjennom å skanne papirdokumenter eller behandle elektroniske filer og bilder. En ulempe er imidlertid at den ikke gir mulighet for konvertering av håndskrift eller hakeverdier [1].
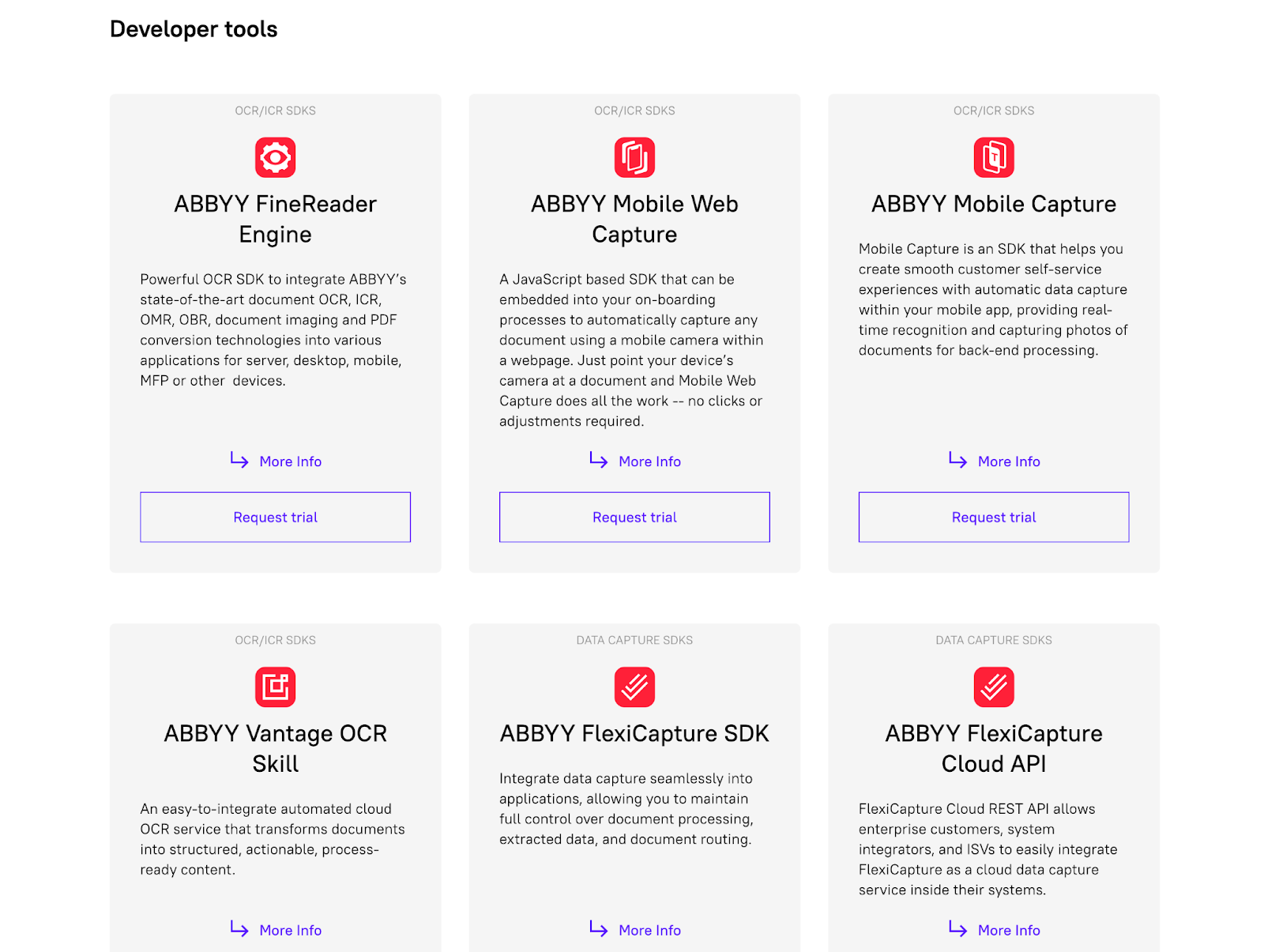
På bildet nedenfor kan du se forholdet mellom komponentene til FineReader-serveren.
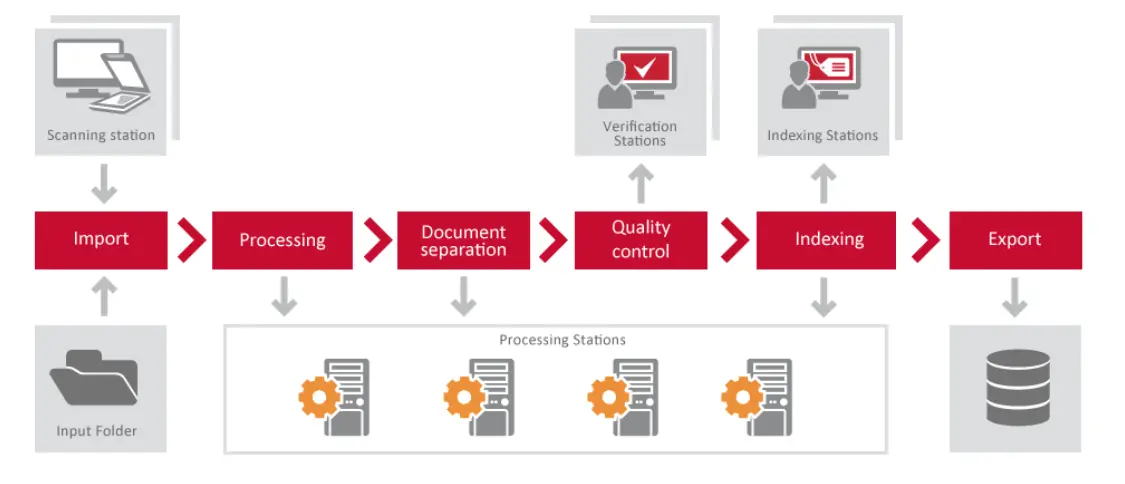
Noen vanlige brukstilfeller
Massebehandling
Overvåk delte mapper på et nettverk og foreta bilde-til-tekst PDF-konverteringer fra bilder eller dokumenter. Når en ny fil legges til i en mappe, konverteres den til en tekstsøkbar versjon og flyttes deretter til den tilsvarende eksportmappen mens den opprinnelige undermappebetegnelsen opprettholdes. Eksportfilen vil opprettholde den juridiske integriteten til den originale bildefilen mens den legger til et søkbart tekstlag bak bildet i PDF-filen i eksportmappene.
Dokumentskanning
Når du skanner dokumenter til et digitalt format, får du den ekstra fordelen av å kunne kopiere og lime inn tekst fra disse dokumentene i andre dokumenter. Du må imidlertid skrive inn teksten manuelt hvis ingen OCR-programvare er tilgjengelig. Tiden det tar å gjøre dette kan være betydelig. FineReader OCR lar brukere raskt konvertere skannede bilder til redigerbare tekstfiler som lett kan åpnes og manipuleres i andre applikasjoner, for eksempel Word eller Excel. Det samme gjelder fakser, som ofte mottas i TIFF-format og ikke støtter redigering eller manipulering. Ved å bruke FineReader OCR kan disse faksene konverteres til redigerbare PDF-filer eller til og med word-dokumenter med noen få klikk.
Digitalisering av dokumenter (bilder til tekst)
ABBYY tilbyr en dataekstraksjonsløsning som kan brukes til å konvertere bilder av trykt eller håndskrevet tekst til et redigerbart format. Dette er et viktig verktøy for bedrifter og organisasjoner som trenger å digitalisere store mengder dokumenter, for eksempel økonomiske, juridiske eller medisinske. Datautvinningsprosessen kan automatisk trekke ut tekst fra bilder, som deretter kan lagres i en database eller konverteres til en søkbar PDF eller et annet dokumentformat. Denne løsningen kan spare bedrifter og organisasjoner for betydelig tid og penger ved å redusere behovet for manuell inntasting av data. I tillegg kan datautvinningsprosessen brukes til å forbedre nøyaktigheten av dataregistrering ved å tilby en konsistent og nøyaktig metode for å konvertere papirdokumenter til digitalt format.
Maskinoversettelse
ABBYY FineReader OCR kan brukes som et maskinoversettelsesverktøy ved å konvertere et bilde til tekst på et annet språk (maskinoversettelse). Dette kan være nyttig hvis du ønsker å tilby oversettelsestjenester uten å måtte vedlikeholde menneskelige oversettere på stedet, men fortsatt ønsker å tilby kvalitetsoversettelser til kundene dine (eller rett og slett ikke vil kaste bort tid på å oversette noe selv).
Tabellutvinning er en prosess for å trekke ut data fra PDF-er eller bilder av tabelldokumenter ved bruk av optisk tegngjenkjenning (OCR). Det brukes ofte til å konvertere skannede papirdokumenter, for eksempel kvitteringer, til et digitalt format slik at dataene kan behandles, analyseres og lagres mer effektivt. Ulike OCR-programvare er tilgjengelig på markedet, men ABBYY FineReader er et av de mest populære valgene. Teknologien kan gjenkjenne linjer og celler, og den kan også oppdage topptekster og bunntekster. Det er mulig å behandle flersidige dokumenter samtidig, noe som sparer tid. I tillegg støtter ABBYY FineReader et bredt spekter av språk, noe som gjør den ideell for å trekke ut data fra dokumenter på forskjellige språk.
Vil du automatisere dataregistrering fra dokumenter? Nanonets 'AI-baserte OCR-løsning kan hjelpe til med å hente nøkkelinformasjon fra strukturerte / ustrukturerte dokumenter og sette prosessen på autopilot!
Hva er tilfellene for forretningsbruk av Flexicapture OCR?
ABBYY FlexiCapture er først og fremst en dataekstraksjonsprogramvare på bedriftsnivå som gir funksjoner for optisk tegngjenkjenning (OCR). FlexiCapture gir en måte å automatisk trekke ut informasjon fra dokumenter basert på å etablere regler, inkludert nøkkelord og plasseringen av dataene på en side. FlexiCapture er for tiden tilgjengelig i spesielle, kjøreklare løsningspakker som FlexiCapture for Invoices og FlexiCapture for Mailrooms. Selv om løsningen i stor grad er avhengig av bruken av den samme OCR-teknologien som finnes i FineReader Server, og den kan eksportere en tekstsøkbar versjon av et dokument om nødvendig, er kjernefunksjonene som følger:
- Klassifisering av dokumenter (bestemme deres type)
- Matching av disse dokumentklassene til de tilsvarende datauttrekksreglene
- Eksportere dataene et sted som en database, XML-fil eller Microsoft Excel.
FlexiCaptures dokumentklassifiseringsfunksjoner kan brukes til å trekke ut og deretter sammenligne feltverdier fra dokumentsett. For eksempel kan en lånesøknad inneholde et halvt dusin dokumenter, hvorav noen inneholder et SSN. En regel kan enkelt konfigureres for å sammenligne SSN-ene fra hvert dokument som inneholder en verdi for dette feltet og deretter presentere eventuelle feil for operatøren under dokumentverifiseringsfasen.
På bildet nedenfor kan du se forholdet mellom komponentene til FlexiCapture Server.
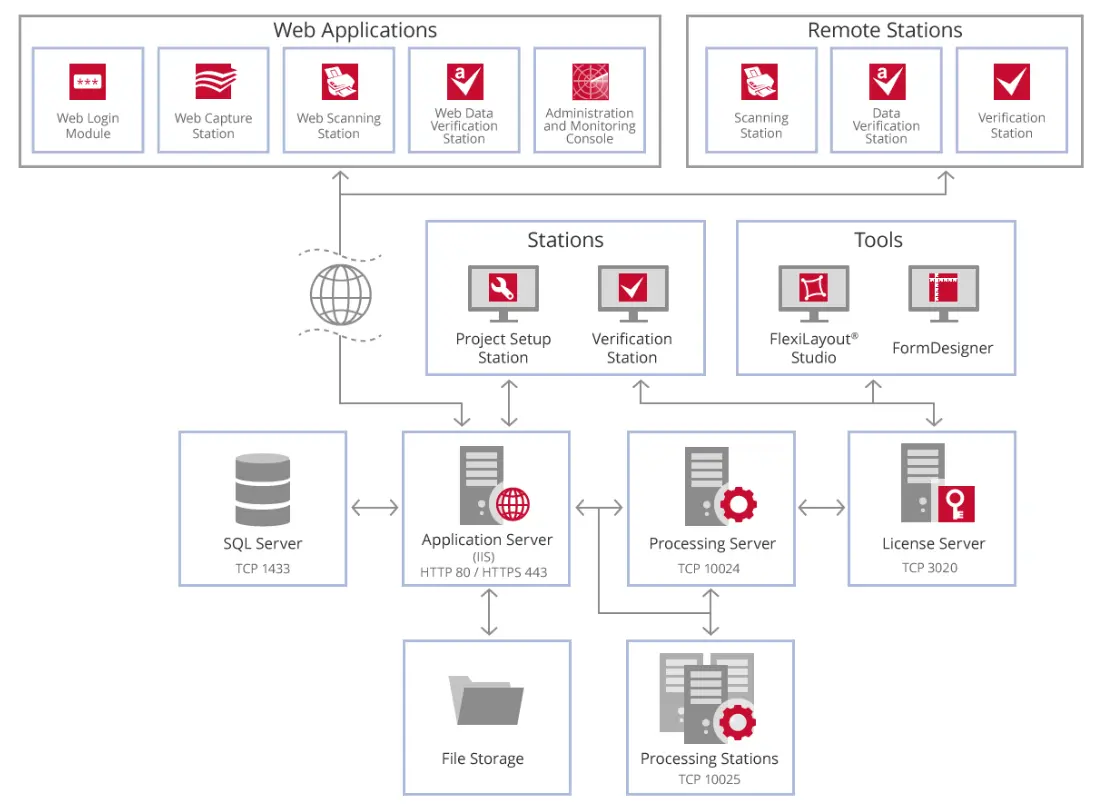
Noen vanlige brukstilfeller
2-veis matching
ABBYY FineReader har funksjoner som kan hjelpe leverandørreskontroavdelingen din til å fungere jevnere. Dette inkluderer:
- Automatisk uttrekk av fakturadata fra papir- og elektroniske dokumenter
- 2-veis matching av fakturalinjer mot tilsvarende kjøp i ERP-systemet
- Søke gjennom tekstsøkbare fakturaer
- Godkjenne betalinger etter dollarbeløp eller andre regler
- Automatisert behandling av innkommende innkjøpsordrer
Dokumentklassifisering
- Klassifiser innkommende dokumenter etter type og trekk ut dataene fra dokumentene ved å bruke regler som er forhåndskonfigurert.
- Eksporter en tekstsøkbar PDF-versjon av dokumentet til et innholdsstyringssystem og fyll ut felt med data hentet fra dokumentet.
- Gi brukerne et middel til å korrigere de utpakkede dataene sammen med køer for å administrere unntak fra forhåndsprogrammerte regler i dokumentarbeidsflytprosessen.
Toppalternativer for ABBYY-løsninger

Amazon Textract er en tjeneste som automatisk trekker ut tekst og data fra skannede dokumenter. Det går utover enkel optisk tegngjenkjenning (OCR) å også identifisere innholdet i felt i skjemaer og informasjon som er lagret i tabeller.
Amazon AWS Textract er et nyere verktøy som vokser i popularitet, takket være lave kostnader og brukervennlighet. Den er ideell for å skanne et stort antall dokumenter, selv om nøyaktighetsnivåene ikke er fullt så høye som ABBYY [2].
Hovedforskjellen mellom ABBYY og Amazon Textract er at mens ABBYY tilbyr en frittstående løsning for å trekke ut tekst fra bilder ved hjelp av Optical Character Recognition (OCR), gir Amazon kundene sine en API de kan integrere i sine egne applikasjoner. De tilbyr til og med forskjellige SDK-er, noe som gjør det enklere for utviklere å integrere denne funksjonen i produktene sine; Dette krever imidlertid ytterligere kunnskap om programmeringsspråk som Java eller Python.
Videre, i motsetning til AWS Textract, gir ABBYY absolutt kontroll over alle aspekter av OCR-prosessen din (det lar deg for eksempel tilpasse ordsegmentering).
Både ABBYY og AWS Textract fungerer veldig bra når det gjelder nøyaktighet og hastighet i de fleste tilfeller.
Fordeler med Textract
- Du kan bruke AWS Textract med alle tekstbehandlingsapplikasjoner med en SDK.
- AWS Textract støtter mer enn 25 språk i 200 land og territorier. Du kan bruke den til å oversette bildefilene dine i sanntid og lage flerspråklige behandlingsrørledninger.
- Dette verktøyet er kostnadseffektivt. Det koster bare $0.0025 per 100,000 XNUMX behandlede tegn – mindre enn halvparten av kostnadene for andre løsninger!
- AWS Textract er skalerbar, noe som betyr at du kan bruke den i stor eller liten skala, avhengig av dine behov.
Ulemper med Textract
- AWS Textract krever mye tid og ressurser for å trene med dataene dine før du kan bruke dem i produksjon.
- Moderne programvare for optisk tegngjenkjenning (OCR) kan identifisere om et opplastet dokument er originalt eller en forfalskning ved å validere datoer, finne pikselerte områder og andre metoder. AWS Textract har ikke denne muligheten; den kan bare trekke ut tekst fra et opplastet dokument.
- Textract tillater ikke enkelt integrasjoner med oppstrøms- og nedstrømsleverandører. Det kan for eksempel hende vi må bygge en RPA-rørledning med en tredjepartstjeneste. Det ville være vanskelig å finne passende plugins som passer Textract.
ABBYY mot Tesseract

Tesseract OCR ble designet for å gjenkjenne et bredt spekter av språk skrevet i ren C++-kode. Den kan også kompileres for bruk på mobile enheter som Android- og iOS-plattformer. Programvaren bruker avanserte funksjoner som vertikal tekstlayoutgjenkjenning, slik at brukere kan lese tekst fra ulike vinkler uten å miste nøyaktigheten.
ABBYY og Tesseract leverer OCR-løsninger og har høye nøyaktighetsgrader og støtter en rekke språk. Det er imidlertid noen kritiske forskjeller mellom de to. ABBYY tilbyr et mer brukervennlig grensesnitt, noe som gjør det ideelt for de som er nye til OCR. Det gir også flere funksjoner, for eksempel eksport av flere formater og utførelse av bilderedigering. På den annen side er Tesseract åpen kildekode og derfor gratis å bruke. Den har også en mer nøyaktig motor, noe som gjør den til det bedre valget for de som trenger høyest mulig nøyaktighetsnivå.
Fordeler med Tesseract
- Det fungerer med forskjellige språk i forskjellige fonter, inkludert romersk, kyrillisk, han-ideografisk skrift, hebraisk, arabisk og thai.
- Kildekoden er tilgjengelig under en Apache-lisens, så den er gratis å bruke og endre. Den har også et lavt minneavtrykk sammenlignet med andre OCR-motorer, så det tar ikke for mye plass på datamaskinen eller smarttelefonen.
- Tesseract er allsidig og kan brukes til ulike oppgaver, fra enkel Optical Character Recognition (OCR) til mer komplekse oppgaver som Machine Learning (ML).
Ulemper med Tesseract
- Tesseract gir ikke alltid perfekte resultater, spesielt med kompleks eller håndskrevet tekst.
- Tesseracts bildebehandling er rudimentær; derfor må du bruke en forprosessor eller et bilde som allerede er behandlet for å oppnå de beste resultatene [8].
ABBYY vs. Ephesoft

Ephesoft er et annet dokumentgjenkjenningsverktøy som bruker optisk tegngjenkjenningsteknologi (OCR) for å konvertere bilder til tekstfiler. Denne programvaren er utviklet spesielt for bedrifter som trenger en løsning for å håndtere store mengder papirdokumenter som fakturaer eller kvitteringer. I likhet med ABBYYs produkter kan Ephesoft brukes på tvers av flere bransjer, inkludert helsevesen, myndigheter, finans og produksjon.
Begge programvarepakkene tilbyr et omfattende utvalg funksjoner og fordeler, men det er noen kritiske forskjeller mellom dem. For eksempel anses ABBYY generelt som mer nøyaktig enn Ephesoft [6]t, spesielt når man gjenkjenner tekst i dokumenter med komplekse oppsett. Imidlertid er Ephesoft vanligvis raskere enn ABBYY, noe som gjør det til et godt valg for organisasjoner som må behandle et stort volum dokumenter daglig. Når det gjelder pris, er ABBYY vanligvis dyrere enn Ephesoft, selv om begge selskapene tilbyr rabatter for volumlisensiering. Til syvende og sist vil den beste OCR-programvaren for virksomheten din avhenge av dine spesifikke behov og budsjett.
Fordeler med Ephesoft
- Systemet har sporingsfunksjonalitet som hjelper til med å spore brukerdokumentendringer. Dette kan være nyttig for å forhindre svindel og holde et øye med hvem som har gjort endringer når flere brukere jobber med et dokument.
- Ephesoft bruker teknikker for forbedring av bildekvalitet for å trekke ut data fra bilder, for eksempel OCR (Optical Character Recognition), strekkodegjenkjenning og tegngjenkjenning. Dette øker datautvinningsnøyaktigheten betydelig sammenlignet med manuelle metoder, der dataene kanskje ikke er helt nøyaktige eller fullstendige på grunn av dårlig bildekvalitet eller andre faktorer.
- Støtter dokumenter på flere språk, for eksempel engelsk, spansk, fransk, etc., noe som gjør den egnet på tvers av bransjer med ulike kundebaser som bruker forskjellige språk som sin primære kommunikasjonsmåte/dokumentasjon.
Ulemper med Ephesoft
- Den trenger skikkelig opplæring før du bruker den. Hvis du ikke har tidligere erfaring med å jobbe med denne typen programvare, kan det hende du synes det er vanskelig å bruke den effektivt. Men når du først har blitt vant til det, vil det bli veldig enkelt for deg å bruke dette produktet effektivt i virksomheten din.
- Ephesoft-programvare koster mer enn andre lignende produkter på markedet. Den første investeringen som kreves for å kjøpe Ephesoft kan være høy, men kostnadene kan reduseres ved å velge en skyversjon [7].
ABBYY vs. hypervitenskap

Hypersciences proprietære maskinlæringsmodeller og kraftig optisk tegngjenkjenningsteknologi (OCR) gir uovertruffen datautvinningsevne for håndskrevne skjemaer, sammen med andre strukturerte og semistrukturerte dokumenter. Plattformen kan skryte av overlegen ytelsesrapportering, innebygd kvalitetssikring og utvinning på høyt nivå for nøyaktig – og rask – dokumentfangst og analyse.
Både ABBYY og Hyperscience tilbyr skrivebords- og skybaserte OCR-løsninger. Hvis du trenger å OCR et stort volum av dokumenter, kan ABBYY være et bedre alternativ, siden du vil kunne behandle dem i grupper ved hjelp av skrivebordsapplikasjonen.
ABBYYs OCR-motor er basert på kunstig intelligens (AI), mens Hypersciences OCR-motor er basert på maskinlæring (ML). Dette betyr at ABBYY kan lære og forbedre seg over tid, mens Hyperscience alltid vil produsere resultater i samsvar med treningsdataene. Så hvis du trenger et OCR-verktøy som kan tilpasse seg skiftende forhold (f.eks. forskjellige fonter, bilder av dårlig kvalitet, etc.), kan ABBYY være et bedre valg. Men hvis du trenger et OCR-verktøy som alltid vil produsere samme høye nøyaktighetsnivå, uavhengig av inndatadokumentet, kan Hyperscience være et bedre alternativ.
ABBYY vs. Read

Readiris er en kraftig og nøyaktig OCR-motor som kan brukes til å konvertere skannede dokumenter og bilder til redigerbar og søkbar tekst. Den tilbyr et bredt spekter av funksjoner og alternativer, noe som gjør den til en allsidig og kraftig OCR-løsning for ulike behov.
Readiris er et av de populære alternativene til ABBYY FineReader. Det er også et OCR-program med et bredt spekter av funksjoner og mange brukere.
Fordeler med Readiris
- 20 % raskere dokumentbehandling
- Rediger tekster som er innebygd i bildene dine med OCR
- Konverter Microsoft Office-dokumenter til PDF
- Kommenter og kommenter
- Beskytt og signer PDF-er
- Integrasjon med skrivere (Twain-skannere) [3]
Ulemper med Readiris
- Prissetting kan være dyrt når du arbeider med enorme data.
- Nøyaktigheten kan være lav når du arbeider med ustrukturerte data sammenlignet med andre verktøy [4]
ABBYY vs. Google Cloud Vision

Google Cloud Vision OCR er en skybasert tekstgjenkjennings- og bildeanalyseløsning. Tjenesten bruker dyplæringsalgoritmer for å behandle bilder og videoer, gjenkjenne objekter, scener og ansikter, samt oppdage tekst på mer enn 100 språk.
Fordeler med Google Cloud Vision
- Resultatene er nøyaktige og pålitelige – Google bruker dyplæringsmodeller for sin OCR-tjeneste, noe som betyr at den lærer mer om hvordan det spesifikke dokumentet ditt formateres etter hvert, og forbedrer nøyaktigheten over tid.
- Den er kompatibel med de fleste filtyper – Google Cloud Vision OCR fungerer med JPEG, PNG, BMP, TIFF, PDF-filer og animerte GIF-er! Du kan til og med konvertere HTML-sider til ren tekst ved hjelp av Google Cloud Vision OCR (selv om ikke all formatering vil bli bevart).
- Det er enkelt å bruke – alt du trenger å gjøre er å laste opp et bilde som inneholder teksten du vil konvertere, og klikk på "Opprett tekst" i Google Cloud Vision-konsollen. Du trenger ikke å installere noen programvare eller laste ned noen programvarebibliotek.
- Gir API-grensesnitt for å integrere med tilpasset programvare.
Ulemper med Google Cloud Vision
- Det krever en internettforbindelse (som betyr at du ikke kan bruke det offline).
- Det er tregt å behandle store datamengder. Du kan bruke den til små til mellomstore mengder tekst, men hvis du ønsker å gjøre store mengder tekstbehandling i batch-modus, er det ikke sikkert at denne løsningen er rask nok for dine behov.
- I noen tilfeller som tabellekstraksjon, er nøyaktigheten til Google Cloud Vision OCR ikke like høy som andre verktøy [5].
Vil du automatisere dataregistrering fra dokumenter? Nanonets 'AI-baserte OCR-løsning kan hjelpe til med å hente nøkkelinformasjon fra strukturerte / ustrukturerte dokumenter og sette prosessen på autopilot!
ABBYY vs. Nanonets

Nanonets er en AI-basert OCR-programvare som automatiserer datafangst forum intelligent dokumentbehandling av fakturaer, kvitteringer, ID-kort og mer. Nanonetter bruker avansert OCR, maskinlæring bildebehandling, og Deep Learning for å trekke ut relevant informasjon fra ustrukturerte data. Den er rask, nøyaktig, enkel å bruke, lar brukere bygge tilpassede OCR-modeller fra bunnen av, og har noen pene Zapier-integrasjoner. Digitaliser dokumenter, trekk ut datafelter og integrer med hverdagsappene dine via APIer i et enkelt, intuitivt grensesnitt.
Fordeler med nanonetter
- moderne UI
- Håndterer store mengder dokumenter
- Fornuftig priset
- Brukervennlighet
- Kognitiv fangst av data – som resulterer i minimal intervensjon
- Krever ingen internt team av utviklere
- Algoritme / modeller kan trenes / omskoleres
- Stor dokumentasjon og støtte
- Mange tilpasningsalternativer
- Stort utvalg av integrasjonsalternativer
- Fungerer med ikke-engelsk eller flere språk
- Nesten ingen etterbehandling er nødvendig
- Sømløs 2-veis integrasjon med flere regnskapsprogrammer
- Flott OCR API for utviklere
Ulemper med nanonetter
- Tåler ikke veldig høye volumpigger
- Brukergrensesnittet for tabellfangst kan bli bedre.
Sammenlign og se gjennom ABBYY-priser
|
Tool |
Språkstøtte |
Demo |
Priser |
|
|
Adobe Acrobat Pro DC |
100+ språk |
7-dag |
Fra 14.99 $/måned |
Cloud |
|
Les IRIS |
130+ språk |
30-dag |
Fra 129 $/måned |
Windows og Mac |
|
ABBY FineReader |
198+ språk |
7-dag |
$ 117 / år |
Windows, iOS, Android og Mac. |
|
Google Cloud Vision |
130+ språk |
Gratis |
GRATIS versjon $1.5 per 1000 enheter |
Cloud, API |
|
Nanonetter |
100+ språk |
GRATIS |
GRATIS versjon Pro: $499 / måned |
Cloud, Windows og Mac |
|
Tesseract |
120+ språk |
GRATIS |
GRATIS |
Windows |
Hvorfor velge Nanonets fremfor ABBYY?
Nanonets er en OCR-programvare som bruker kunstig intelligens for å automatisere utvinningen av tabeller fra PDF-dokumenter, bilder og skannede filer. I motsetning til andre løsninger, krever det ikke separate regler og maler for hver nye dokumenttype. I stedet er den avhengig av kognitiv intelligens for å håndtere semistrukturerte og usynlige dokumenter mens den forbedres over tid. Du kan også tilpasse utdataene til kun å trekke ut tabeller eller dataoppføringer av din interesse.
Den er rask, nøyaktig, enkel å bruke, lar brukere bygge tilpassede OCR-modeller fra bunnen av, og har noen pene Zapier-integrasjoner. Digitaliser dokumenter, trekk ut tabeller eller datafelt, og integrer med hverdagsappene dine via APIer i et enkelt, intuitivt grensesnitt.
Hvorfor er nanonetter den beste OCR?
- Nanonetter kan trekke ut data på siden mens kommandolinje-PDF-parsere bare trekker ut objekter, overskrifter og metadata som (tittel, sider, krypteringsstatus, etc.)
- Nanonets PDF-parsingsteknologi er ikke malbasert. Bortsett fra å tilby forhåndsopplærte modeller for populære bruksområder, kan Nanonets PDF-analyseringsalgoritme også håndtere usynlige dokumenttyper!
- Bortsett fra å håndtere opprinnelige PDF-dokumenter, lar Nanonets innebygde OCR-funksjoner også håndtere skannede dokumenter og bilder!
- Robuste automatiseringsfunksjoner med AI- og ML-funksjoner.
- Nanonetter håndterer ustrukturerte data, vanlige databegrensninger, flersidige PDF-dokumenter, tabeller og flere linjer med letthet.
- Nanonets er et verktøy uten kode som kontinuerlig kan lære seg og trene seg på egendefinerte data for å gi utdata som ikke krever etterbehandling.
Automatisert fakturaparsing med Nanonets – skaper fullstendig berøringsfrie fakturabehandlingsarbeidsflyter.
Integrer dine eksisterende verktøy med Nanonets og automatiser datainnsamling, eksportlagring og bokføring.
Nanonetter kan også hjelpe med å automatisere arbeidsflyter for fakturaparsing ved å:
- Importere og konsolidere fakturadata fra flere kilder – e-post, skannede dokumenter, digitale filer/bilder, skylagring, ERP, API, etc.
- Fange og trekke ut fakturadata på en intelligent måte fra fakturaer, kvitteringer, regninger og andre økonomiske dokumenter.
- Kategorisering og koding av transaksjoner basert på forretningsregler.
- Sette opp automatiserte godkjenningsarbeidsflyter for å få interne godkjenninger og administrere unntak.
- Avstemming av alle transaksjoner.
- Integrerer sømløst med ERP-er eller regnskapsprogramvare som Quickbooks, Sage, Xero, Netsuite og mer.
Referanser
[1] Kan jeg gjenkjenne håndskrevet tekst i ABBYY FineReader? - Hjelpesenter
[2] ABBYY FineReader VS Amazon Textract – sammenligne forskjeller og anmeldelser?
[3] 7 beste OCR-programvare i 2022 (gratis og BETALT)
[4] Topp 10 OCR-programvare i 2022 | Beste OCR-løsninger
[6] Ephesoft vs. FineReader PDF for Windows og Mac 2022 | G2
[7] 21 beste OCR-programvare i 2022
[8] Tesseract OCR i Python med Pytesseract og OpenCV
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://nanonets.com/blog/abbyy-reviews-compare-competitors-alternatives/
- 000
- 1
- 10
- 100
- 2022
- 7
- 95%
- a
- I stand
- Om oss
- ovenfor
- Absolute
- aksesseres
- Regnskap og administrasjon
- regnskapsprogram
- kontoer
- leverandørgjeld
- nøyaktighet
- nøyaktig
- tvers
- tilpasse
- la til
- tillegg
- Ytterligere
- Tilleggsinformasjon
- avansert
- mot
- AI
- algoritme
- algoritmer
- Alle
- Alle transaksjoner
- tillate
- tillater
- allerede
- alternativer
- Selv
- alltid
- Amazon
- amazontekst
- blant
- beløp
- beløp
- analyse
- analytics
- og
- android
- En annen
- Apache
- hverandre
- api
- APIer
- app
- Søknad
- søknader
- hensiktsmessig
- godkjenning
- apps
- artikler
- kunstig
- kunstig intelligens
- Kunstig intelligens (AI)
- aspektet
- forsikring
- automatisere
- Automatisert
- automatiserer
- automatisk
- Automatisere
- Automatisering
- tilgjengelig
- AWS
- Bank
- basert
- bli
- før du
- bak
- være
- under
- nytte
- Fordeler
- BEST
- Bedre
- mellom
- Beyond
- Sedler
- Blogg
- skryte
- branded
- bringe
- budsjett
- bygge
- innebygd
- virksomhet
- forretningsprosesser
- bedrifter
- C + +
- kan ikke
- evner
- fangst
- Kort
- saker
- Celler
- Endringer
- endring
- karakter
- karaktergjenkjenning
- tegn
- sjekk
- valg
- valg
- Velg
- krav
- klasser
- klassifisering
- nærmere
- Cloud
- sky lagring
- kode
- Koding
- kognitiv
- samling
- Felles
- vanligvis
- Selskaper
- Selskapet
- sammenligne
- sammenlignet
- kompatibel
- fullføre
- helt
- komplekse
- komponenter
- omfattende
- datamaskin
- konsepter
- forhold
- tilkobling
- Ulemper
- Vurder
- ansett
- konsistent
- Konsoll
- konsolidere
- begrensninger
- inneholder
- innhold
- content management
- innhold
- kontroll
- Konvertering
- konverteringer
- konvertere
- konvertert
- Kjerne
- Tilsvarende
- Kostnad
- kostnadseffektiv
- Kostnader
- land
- skape
- Opprette
- kritisk
- CRM
- I dag
- skikk
- kunde
- Kunder
- tilpasning
- tilpasse
- daglig
- dato
- Data Analytics
- dataregistrering
- Database
- databaser
- datoer
- dag
- dyp
- dyp læring
- Avdeling
- avhengig
- betegnelse
- designet
- desktop
- Gjenkjenning
- bestemme
- Utvikler
- utviklere
- Enheter
- forskjell
- forskjeller
- forskjellig
- vanskelig
- digitalt
- digitalisering
- Digitize
- rabatter
- diverse
- dokument
- dokumenthåndtering
- dokumentasjon
- dokumenter
- ikke
- Dollar
- ikke
- nedlasting
- dusin
- under
- hver enkelt
- brukervennlighet
- enklere
- lett
- redigering programvare
- effektivt
- effektivitet
- effektivt
- enten
- elektronisk
- emalje
- e-post
- innebygd
- muliggjør
- kryptering
- Motor
- Ingeniører
- Motorer
- Engelsk
- forbedret
- nok
- berikende
- Enterprise
- Enterprise Solutions
- bedriftsnivå
- entry
- ERP
- feil
- spesielt
- etablere
- etc
- Eter (ETH)
- Selv
- Event
- hendelser
- hver dag
- hverdagen
- alle
- utvikle seg
- eksempel
- Excel
- eksisterende
- utvidet
- dyrt
- erfaring
- utforske
- eksportere
- trekke ut
- trekke ut dataene
- utdrag
- ekstrakter
- øye
- ansikter
- faktorer
- FAST
- raskere
- Trekk
- Egenskaper
- Noen få
- felt
- Felt
- filet
- Filer
- finansiere
- finansiell
- Finn
- finne
- Først
- passer
- følger
- fonter
- Fotspor
- format
- tidligere
- skjemaer
- funnet
- Stiftet
- RAMME
- svindel
- Gratis
- Fransk
- fra
- funksjonalitet
- funksjoner
- Gevinst
- generelt
- få
- Global
- Går
- god
- Google Cloud
- Regjeringen
- Gruppe
- Gruppens
- Økende
- Halvparten
- håndtere
- Håndtering
- å ha
- hode
- overskrifter
- helsetjenester
- tungt
- hjelpe
- hjelper
- Høy
- høyt nivå
- høyest
- historisk
- Hvordan
- Hvordan
- Men
- HTML
- HTTPS
- stort
- menneskelig
- ideell
- identifisere
- bilde
- bildeanalyse
- bilder
- viktig
- forbedre
- bedre
- in
- I andre
- inkludere
- inkluderer
- Inkludert
- Innkommende
- øker
- indeks
- individer
- bransjer
- industri
- informasjon
- innledende
- inngang
- innsikt
- installere
- i stedet
- forsikring
- integrere
- integrering
- integrasjoner
- integritet
- Intelligens
- Intelligent
- interesse
- Interface
- intern
- Internet
- Internett-tilkobling
- intuitiv
- investering
- Fakturabehandling
- fakturabehandling
- iOS
- IT
- varer
- selv
- Java
- Hold
- nøkkel
- kunnskap
- Språk
- språk
- stor
- storskala
- lag
- Layout
- LÆRE
- læring
- Lovlig
- Nivå
- nivåer
- bibliotekene
- Tillatelse
- Lisensiering
- linje
- linjer
- Liste
- lån
- plassering
- Se
- å miste
- Lot
- Lav
- mac
- maskin
- maskinlæring
- maskinoversettelse
- laget
- Hoved
- vedlikeholde
- gjøre
- Making
- administrer
- ledelse
- Management Solution
- administrerende
- manipulert
- Manipulasjon
- håndbok
- manuelt
- produksjon
- mange
- merke
- marked
- Markets
- matchende
- betyr
- midler
- medisinsk
- Minne
- metadata
- metode
- metoder
- Microsoft
- Microsoft Excel
- Microsoft Office
- millioner
- minimal
- ML
- Mobil
- Mobilapp
- håndholdte enheter
- Mote
- modeller
- penger
- mer
- Moskva
- mest
- Mest populær
- flere
- navn
- innfødt
- Naturlig
- Naturlig språk
- Natural Language Processing
- Ryddig
- Trenger
- nødvendig
- trenger
- behov
- nettverk
- Ny
- nyheter
- Antall
- gjenstander
- OCR
- OCR-programvare
- OCR-løsning
- ocr verktøy
- tilby
- tilbudt
- tilby
- Tilbud
- Office
- offline
- ONE
- åpen
- åpen kildekode
- opererer
- operatør
- Optisk karaktergjenkjennelse
- Alternativ
- alternativer
- ordrer
- organisasjoner
- original
- Annen
- andre
- oversikt
- egen
- pakker
- betalt
- Papir
- spesielt
- mønstre
- betalinger
- Ansatte
- perfekt
- ytelse
- utfører
- fase
- rørledning
- Plain
- plattform
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- plugins
- dårlig
- Populær
- popularitet
- mulig
- Post
- kraftig
- presentere
- forebygge
- pris
- primært
- primære
- Før
- pro
- prosess
- Prosesser
- prosessering
- produsere
- Produkt
- Produksjon
- Produkter
- program
- Programmering
- programmerings språk
- prosjekt
- ordentlig
- proprietær
- PROS
- gi
- tilbydere
- gir
- gi
- Kjøp
- formål
- sette
- pytesseract
- Python
- kvalitet
- Quickbooks
- raskt
- område
- priser
- Lese
- sanntids
- kvitteringer
- mottatt
- anerkjennelse
- gjenkjenne
- Redusert
- redusere
- referanser
- Uansett
- regioner
- forholdet
- relevant
- pålitelig
- Rapportering
- Rapporter
- krever
- påkrevd
- Krav
- Krever
- Ressurser
- resulterende
- Resultater
- anmeldelse
- Anmeldelser
- Sør-Afrika
- Regel
- regler
- Kjør
- samme
- Spar
- skalerbar
- Skala
- skanne
- skanning
- Scener
- SDK
- sømløst
- søker
- Seksjon
- segmentering
- tjeneste
- Tjenester
- sett
- innstilling
- delt
- undertegne
- signifikant
- betydelig
- lignende
- Enkelt
- ganske enkelt
- langsom
- liten
- Smart
- smarttelefon
- problemfritt
- So
- Software
- løsning
- Solutions
- noen
- noe
- et sted
- kilde
- kildekoden
- Kilder
- Rom
- Spansk
- spesiell
- spesifikk
- spesielt
- fart
- stående
- standardisere
- Tilstand
- uttalelser
- status
- Still
- lagring
- lagret
- effektivisere
- tilstreber
- struktur
- strukturert
- slik
- Dress
- egnet
- suite
- overlegen
- støtte
- Støtter
- system
- Systemer
- bord
- utvinning av bordet
- Ta
- tar
- oppgaver
- lag
- rive ned
- teknikker
- Technologies
- Teknologi
- maler
- vilkår
- Tesseract
- Tekstgjenkjenning
- thai
- De
- deres
- derfor
- tredjeparts
- Gjennom
- tid
- tidslinje
- Tittel
- til
- sammen
- også
- verktøy
- verktøy
- berøringsfri
- spor
- Sporing
- Tog
- Kurs
- Transaksjoner
- oversette
- Oversettelse
- Oversettelser
- Trender
- typisk
- ui
- Til syvende og sist
- etter
- forståelse
- unik
- universitet
- enestående
- lastet opp
- bruke
- Bruker
- brukervennlig
- Brukere
- vanligvis
- verdi
- Verdier
- variasjon
- ulike
- Verifisering
- allsidig
- versjon
- av
- videoer
- syn
- volum
- volumer
- Avfall
- om
- hvilken
- mens
- HVEM
- helt
- bred
- Bred rekkevidde
- vil
- vinduer
- innenfor
- uten
- ord
- Arbeid
- arbeidsflyt
- arbeidsflyt
- arbeid
- virker
- ville
- skrevet
- Xero
- XML
- Din
- deg selv
- zephyrnet