Bilde av redaktør
Det er 2023, noe som betyr at de fleste virksomheter i de fleste bransjer samler inn innsikt og tar smartere beslutninger ved hjelp av big data. Dette kommer ikke som noen overraskelse i disse dager – muligheten til å samle, kategorisere og analysere store sett med data er utrolig nyttig når det gjelder ta datadrevne forretningsbeslutninger.
Og ettersom et økende antall organisasjoner omfavner digitalisering, vil evnen til å forstå og stole på dataanalyses nytte bare fortsette å vokse.
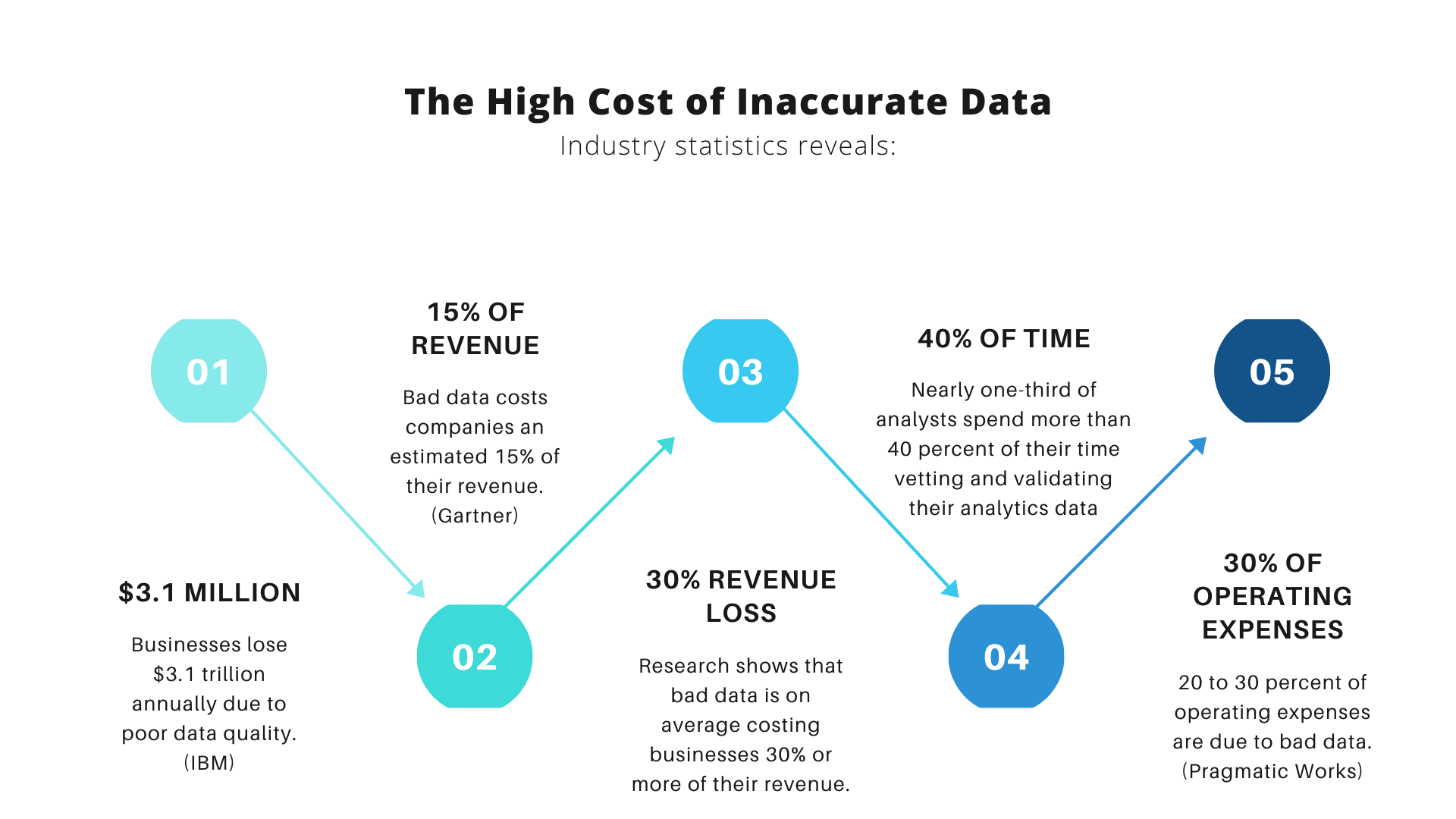
Men her er tingen med big data: ettersom flere organisasjoner kommer til å stole på det, jo større er sjansen for at flere av dem vil bruke big data feil. Hvorfor? Fordi big data og innsikten den gir er bare nyttig hvis organisasjoner analyserer dataene sine nøyaktig.
Bilde fra datastige
For det formål, la oss sørge for at du unngår noen vanlige feil som ofte påvirker nøyaktigheten til dataanalyse. Les videre for å lære om disse problemene og hvordan du kan unngå dem.
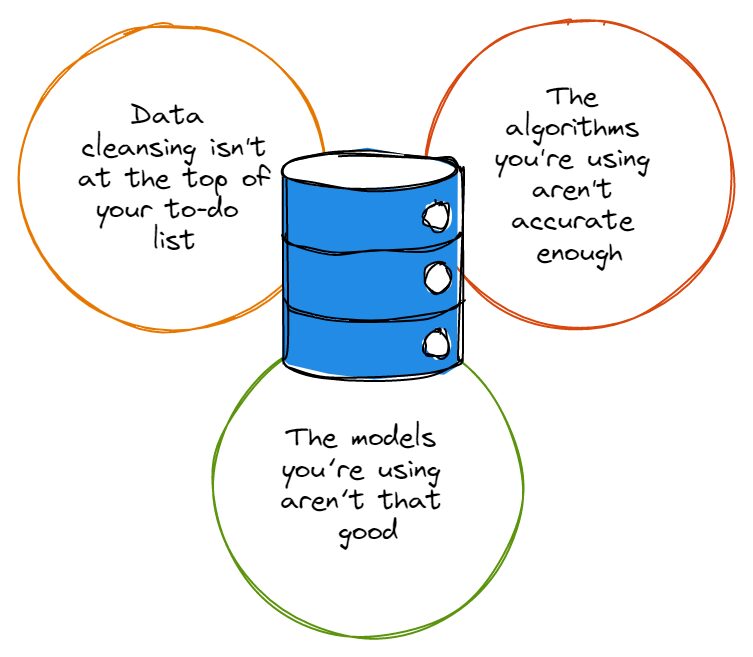
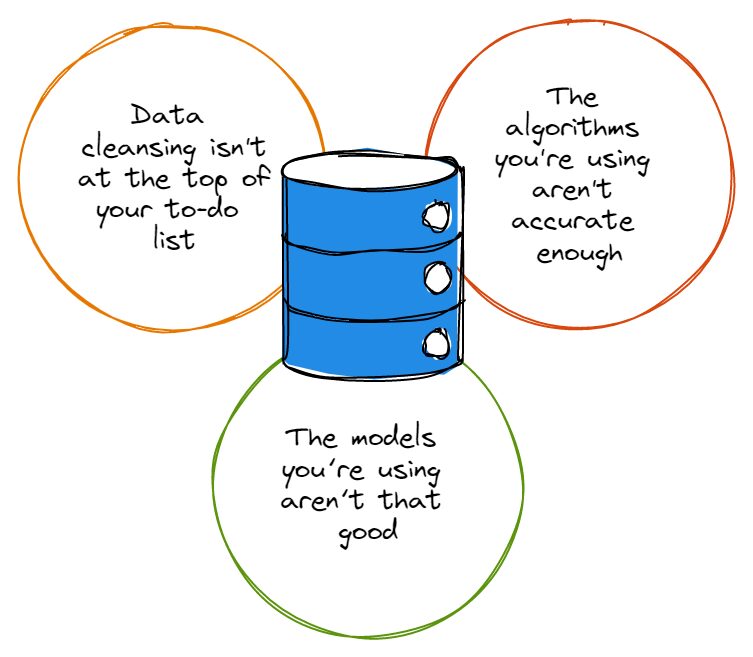
Før vi peker fingre, må vi innrømme at de fleste sett med data har sin rimelige andel feil, og disse feilene gjør ingen tjenester når det er på tide å analysere data. Enten det er skrivefeil, rare navnekonvensjoner eller redundanser, forvirrer feil i datasett nøyaktigheten til dataanalysen.
Så før du blir for begeistret for å dykke dypt inn i kaninhullet for dataanalyse, må du først sørge for at datarensing er øverst på oppgavelisten din, og at du alltid renser datasettene på riktig måte. Du sier kanskje «hei, datarensing er for tidkrevende for meg å bry meg med», som vi nikker sympatisk til.
Heldigvis for deg kan du investere i løsninger som utvidet analyse. Dette utnytter maskinlæringsalgoritmer for å akselerere hastigheten du utfører dataanalysen med (og det forbedrer også nøyaktigheten til analysen).
Konklusjonen: uansett hvilken løsning du bruker for å automatisere og forbedre datarensingen din, må du fortsatt gjøre selve rensingen – hvis du ikke gjør det, vil du aldri ha det riktige grunnlaget å basere nøyaktig dataanalyse på.
Som tilfellet er med datasett, er de fleste algoritmer ikke hundre prosent perfekte; de fleste av dem har sin del av feilene og fungerer rett og slett ikke slik du vil at de skal hver gang du bruker dem. Algoritmer med en rekke ufullkommenheter kan til og med ignorere data som er avgjørende for analysen din, eller de kan fokusere på feil type data som faktisk ikke er så viktig.
Det er ingen hemmelighet at de største navnene innen teknologi er undersøker stadig algoritmene deres og justere dem så nær perfeksjon som mulig, og det er fordi så få algoritmer faktisk er feilfrie. Jo mer nøyaktig algoritmen din er, desto større er garantien for at programmene dine når målene sine og gjør det du trenger at de skal gjøre.
I tillegg, hvis organisasjonen din bemanner til og med bare et par dataforskere, bør den sørge for at disse dataforskerne jevnlig gjør oppdateringer til algoritmene som deres dataanalyseprogrammer - det kan til og med være verdt å etablere en tidsplan som holder team ansvarlige for å opprettholde og oppdatere sine dataanalysealgoritmer etter en avtalt tidsplan.
Enda bedre enn det kan være å etablere en strategi som utnytter AI/ML-baserte algoritmer, som skal kunne oppdatere seg selv automatisk.
For det meste forståelig nok er det mange bedriftsledere som ikke er direkte engasjert i dataanalyseteamene deres, ikke innser at algoritmer og modeller er ikke de samme tingene. I tilfelle DU ikke var klar over det, husk at algoritmer er metodene vi bruker for å analysere data; modeller er beregningene som blir opprettet ved å utnytte en algoritmes utgang.
Algoritmer kan knuse data hele dagen lang, men hvis utdataene deres ikke går gjennom modeller som er designet for å sjekke den påfølgende analysen, vil du ikke ha noen brukbar eller nyttig innsikt.
Tenk på det slik: hvis du har fancy algoritmer som knuser data, men ikke har noen innsikt å vise til det, kommer du ikke til å ta datadrevne beslutninger bedre enn du var før du hadde disse algoritmene; det ville være som å ville bygge brukerundersøkelser inn i produktets veikart, men ignorere det faktum at for eksempel markedsundersøkelsesindustrien genererte 76.4 milliarder dollar i omsetning i 2021, noe som representerer en 100 % økning siden 2008.
Intensjonene dine kan være beundringsverdige, men du må bruke de moderne verktøyene og kunnskapen som er tilgjengelig for deg for å skaffe deg denne innsikten eller bygge brukerforskningen inn i veikartet ditt etter beste evne.
Det er uheldig at suboptimale modeller er en sikker måte å lage et rot i algoritmenes produksjon på, uansett hvor sofistikerte disse algoritmene er. Det er derfor viktig at bedriftsledere og tekniske ledere engasjerer sine dataanalyseeksperter tettere for å lage modeller som verken er for kompliserte eller for enkle.
Og avhengig av hvor mye data de jobber med, kan bedriftsledere velge å gå gjennom noen forskjellige modeller før de bestemmer seg for en som passer best for volumet og typen data de trenger å håndtere.
På slutten av dagen, hvis du vil forsikre deg om at dataanalysen din ikke er konsekvent feil, må du også huske å aldri bli offer for partiskhet. Bias er dessverre en av de største hindringene som må overvinnes når det gjelder å opprettholde nøyaktigheten til dataanalyse.
Enten de påvirker typen data som samles inn eller påvirker måten bedriftsledere tolker data på, er skjevheter varierte og ofte vanskelige å finne ut – ledere må gjøre sitt beste for å identifisere sine skjevheter og gi avkall på dem for å dra nytte av konsekvent nøyaktig dataanalyse.
Data er kraftige: Når de brukes riktig, kan de gi bedriftsledere og deres organisasjoner enormt nyttig innsikt som kan transformere hvordan de utvikler og leverer produktene sine til kundene sine. Bare sørg for at du gjør alt i din makt for å sikre at dataanalysene dine er nøyaktige og ikke lider av de lett unngåelige feilene vi har skissert i denne artikkelen.
Nahla Davies er en programvareutvikler og teknologiskribent. Før hun viet arbeidet sitt på heltid til teknisk skriving, klarte hun – blant annet spennende – å fungere som hovedprogrammerer ved en Inc. 5,000 erfaringsbasert merkevareorganisasjon med kunder som Samsung, Time Warner, Netflix og Sony.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://www.kdnuggets.com/2023/03/3-mistakes-could-affecting-accuracy-data-analytics.html?utm_source=rss&utm_medium=rss&utm_campaign=3-mistakes-that-could-be-affecting-the-accuracy-of-your-data-analytics
- :er
- 000
- 2021
- 2023
- a
- evner
- evne
- I stand
- Om oss
- akselerere
- gjennomføre
- nøyaktighet
- nøyaktig
- nøyaktig
- faktisk
- beundringsverdig
- innrømme
- påvirke
- påvirker
- algoritme
- algoritmer
- Alle
- alltid
- blant
- analyse
- analytics
- analysere
- analyserer
- og
- noen
- ER
- Artikkel
- AS
- At
- augmented
- automatisere
- automatisk
- tilgjengelig
- unngå
- basen
- BE
- fordi
- blir
- før du
- være
- nytte
- BEST
- Bedre
- Bias
- Stor
- Store data
- større
- Biggest
- Bunn
- branding
- bygge
- Bunch
- virksomhet
- bedrifter
- by
- CAN
- saken
- sjanse
- sjekk
- Velg
- klienter
- Lukke
- tett
- Codecademy
- Samle
- Kom
- Felles
- komplisert
- beregninger
- fortsette
- konvensjoner
- kunne
- Par
- skape
- opprettet
- knase
- Kunder
- dato
- dataanalyse
- Data Analytics
- datasett
- data-drevet
- dag
- Dager
- avgjørelser
- dyp
- leverer
- avhengig
- designet
- utvikle
- Utvikler
- forskjellig
- vanskelig
- digitalisering
- direkte
- gjør
- ned
- kjøring
- lett
- enten
- omfavne
- engasjere
- engasjert
- sikre
- feil
- avgjørende
- etablere
- etablere
- Selv
- Hver
- alt
- eksempel
- opphisset
- ledere
- eksperimentelle
- eksperter
- rettferdig
- Fall
- favoriserer
- Noen få
- Først
- feil
- Fokus
- etter
- Til
- Fundament
- fra
- fullt
- få
- Go
- Mål
- skal
- innvilge
- gripe
- større
- størst
- Grow
- Økende
- garantere
- håndtere
- Ha
- .
- hjelpe
- holder
- Hvordan
- HTML
- http
- HTTPS
- hekk
- identifisere
- umåtelig
- viktig
- forbedre
- forbedrer
- in
- Inc.
- inkludere
- feil
- Øke
- bransjer
- industri
- å påvirke
- innsikt
- intensjoner
- Investere
- saker
- IT
- jpg
- KDnuggets
- Type
- kunnskap
- føre
- ledere
- LÆRE
- læring
- utnytter
- utnytte
- i likhet med
- linje
- Liste
- Lang
- Lot
- maskin
- maskinlæring
- gjøre
- Making
- fikk til
- marked
- markedsundersøkelser
- Saken
- midler
- metoder
- feil
- modeller
- Moderne
- mer
- mest
- navn
- navngiving
- Trenger
- Ingen
- Netflix
- Antall
- of
- Tilbud
- on
- ONE
- rekkefølge
- organisasjon
- organisasjoner
- Annen
- skissert
- produksjon
- Overcome
- prosent
- perfekt
- utføre
- PEWRESEARCH
- plato
- Platon Data Intelligence
- PlatonData
- mulig
- makt
- kraftig
- Produkt
- Produkter
- Programmerer
- programmer
- ordentlig
- riktig
- Kanin
- Sats
- RE
- Lese
- realisere
- regelmessig
- husker
- representerer
- forskning
- inntekter
- veikart
- s
- samme
- Samsung
- planlegge
- forskere
- Secret
- betjene
- sett
- bosette
- Del
- bør
- Vis
- Enkelt
- ganske enkelt
- siden
- smartere
- So
- Software
- løsning
- Solutions
- noen
- Sony
- sofistikert
- Still
- Strategi
- senere
- slik
- lidelse
- overraskelse
- lag
- tech
- Teknisk
- Det
- De
- deres
- Dem
- seg
- derfor
- Disse
- ting
- ting
- Gjennom
- tid
- tidkrevende
- til
- også
- verktøy
- topp
- Transform
- tweaking
- Forståelig
- uheldig
- Oppdater
- oppdateringer
- oppdatering
- bruk
- bruke
- Bruker
- Ve
- Offer
- volum
- ønsker
- Warner
- Vei..
- Hva
- om
- hvilken
- HVEM
- vil
- med
- Arbeid
- arbeid
- verdt
- forfatter
- skriving
- Feil
- Din
- zephyrnet