Bilde av Freepik
Conversational AI refererer til virtuelle agenter og chatbots som etterligner menneskelig interaksjon og kan engasjere mennesker i samtale. Å bruke konversasjons-AI begynner raskt å bli en livsstil – fra å spørre Alexa til "finn nærmeste restaurant” å be Siri om å "lag en påminnelse» virtuelle assistenter og chatbots brukes ofte til å svare på spørsmål fra forbrukere, løse klager, gjøre reservasjoner og mye mer.
Å utvikle disse virtuelle assistentene krever betydelig innsats. Men å forstå og håndtere de viktigste utfordringene kan effektivisere utviklingsprosessen. Jeg har brukt min førstehåndserfaring i å lage en moden chatbot for en rekrutteringsplattform som et referansepunkt for å forklare sentrale utfordringer og deres tilsvarende løsninger.
For å bygge en samtale-AI-chatbot kan utviklere bruke rammeverk som RASA, Amazons Lex eller Googles Dialogflow for å bygge chatboter. De fleste foretrekker RASA når de planlegger tilpassede endringer, eller roboten er i moden fase, da det er et rammeverk med åpen kildekode. Andre rammer egner seg også som utgangspunkt.
Utfordringene kan klassifiseres som tre hovedkomponenter i en chatbot.
Naturlig språkforståelse (NLU) er en bots evne til å forstå menneskelig dialog. Den utfører intensjonsklassifisering, enhetsutvinning og henting av svar.
Dialogansvarlig er ansvarlig for et sett med handlinger som skal utføres basert på gjeldende og tidligere sett med brukerinndata. Den tar intensjoner og enheter som input (som en del av forrige samtale) og identifiserer neste svar.
Generering av naturlig språk (NLG) er prosessen med å generere skrevne eller talte setninger fra gitte data. Den rammer inn svaret, som deretter presenteres for brukeren.
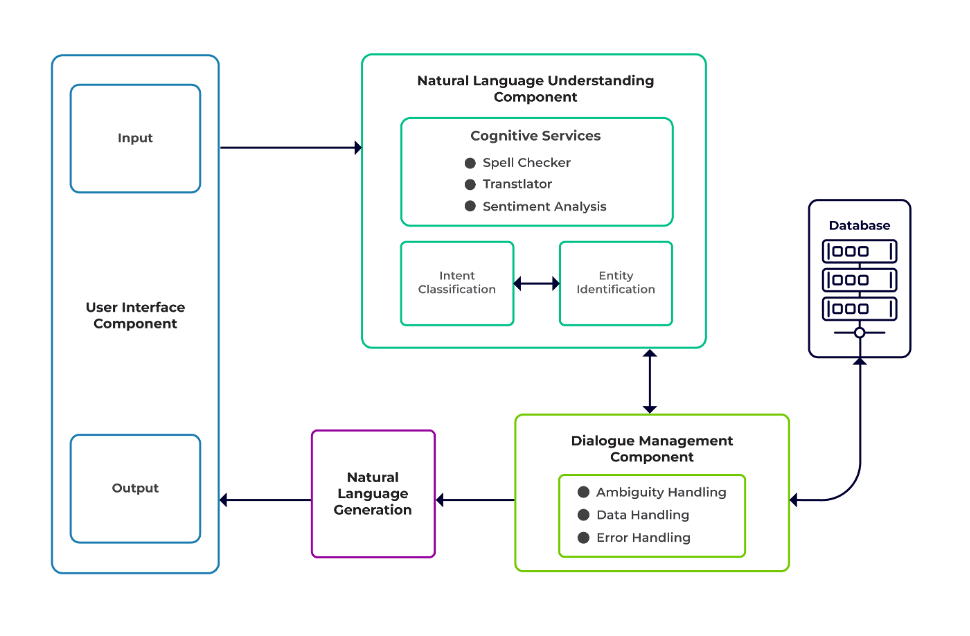
Bilde fra Talentica Software
Utilstrekkelig data
Når utviklere erstatter vanlige spørsmål eller andre støttesystemer med en chatbot, får de en anstendig mengde treningsdata. Men det samme skjer ikke når de lager boten fra bunnen av. I slike tilfeller genererer utviklere treningsdata syntetisk.
Hva gjør jeg?
En malbasert datagenerator kan generere en anstendig mengde brukerforespørsler for opplæring. Når chatboten er klar, kan prosjekteiere eksponere den for et begrenset antall brukere for å forbedre treningsdata og oppgradere den over en periode.
Upassende modellvalg
Passende modellvalg og treningsdata er avgjørende for å få de beste hensikts- og enhetsutvinningsresultatene. Utviklere trener vanligvis chatboter på et spesifikt språk og domene, og de fleste av de tilgjengelige forhåndstrente modellene er ofte domenespesifikke og trent på ett enkelt språk.
Det kan også være tilfeller av blandede språk der folk er polyglot. De kan skrive inn søk på et blandet språk. For eksempel, i en fransk-dominert region, kan folk bruke en type engelsk som er en blanding av både fransk og engelsk.
Hva gjør jeg?
Bruk av modeller som er trent på flere språk kan redusere problemet. En forhåndstrent modell som LaBSE (Språkagnostisk Bert-setningsinnbygging) kan være nyttig i slike tilfeller. LaBSE er trent i mer enn 109 språk på en setningslikhetsoppgave. Modellen kjenner allerede lignende ord på et annet språk. I vårt prosjekt fungerte det veldig bra.
Feil enhetsutvinning
Chatbots krever at enheter identifiserer hva slags data brukeren søker etter. Disse enhetene inkluderer tid, sted, person, element, dato osv. Bots kan imidlertid ikke identifisere en enhet fra naturlig språk:
Samme kontekst, men forskjellige enheter. For eksempel kan roboter forvirre et sted som en enhet når en bruker skriver "Navn på studenter fra IIT Delhi" og deretter "Navn på studenter fra Bengaluru."
Scenarier der enhetene blir feilspådd med lav selvtillit. For eksempel kan en bot identifisere IIT Delhi som en by med lav selvtillit.
Delvis enhetsutvinning etter maskinlæringsmodell. Hvis en bruker skriver «studenter fra IIT Delhi», kan modellen bare identifisere «IIT» bare som en enhet i stedet for «IIT Delhi».
Enkeltord-inndata uten kontekst kan forvirre maskinlæringsmodellene. For eksempel kan et ord som "Rishikesh" bety både navnet på en person så vel som en by.
Hva gjør jeg?
Å legge til flere treningseksempler kan være en løsning. Men det er en grense hvor det ikke hjelper å legge til flere. Dessuten er det en uendelig prosess. En annen løsning kan være å definere regex-mønstre ved å bruke forhåndsdefinerte ord for å hjelpe til med å trekke ut enheter med et kjent sett med mulige verdier, som by, land, etc.
Modeller deler lavere tillit når de ikke er sikre på enhetsprediksjon. Utviklere kan bruke dette som en utløser for å kalle en tilpasset komponent som kan rette opp den lite trygge enheten. La oss vurdere eksemplet ovenfor. Hvis IIT Delhi er spådd som en by med lav selvtillit, så kan brukeren alltid søke etter den i databasen. Etter å ha unnlatt å finne den anslåtte enheten i City tabell, ville modellen gå videre til andre tabeller og til slutt finne den i Institute tabell, noe som resulterer i enhetskorreksjon.
Feil hensiktsklassifisering
Hver brukermelding har en hensikt knyttet til seg. Siden intensjoner utleder neste handlingsforløp til en bot, er det avgjørende å korrekt klassifisere brukerforespørsler med hensikt. Utviklere må imidlertid identifisere intensjoner med minimal forvirring på tvers av intensjoner. Ellers kan det oppstå tilfeller av forvirring. For eksempel, "Vis meg ledige stillinger" vs. "Vis meg ledige stillingskandidater».
Hva gjør jeg?
Det er to måter å skille forvirrende søk på. For det første kan en utvikler introdusere underhensikt. For det andre kan modeller håndtere forespørsler basert på identifiserte enheter.
En domenespesifikk chatbot bør være et lukket system der den tydelig skal identifisere hva den er i stand til og hva den ikke er. Utviklere må gjøre utviklingen i faser mens de planlegger for domenespesifikke chatbots. I hver fase kan de identifisere chatbotens funksjoner som ikke støttes (via ikke-støttede hensikter).
De kan også identifisere hva chatboten ikke kan håndtere i hensikt "utenfor omfanget". Men det kan være tilfeller der boten er forvirret med tanke på at den ikke støttes og er utenfor omfanget. For slike scenarier bør en reservemekanisme være på plass der, hvis intensjonens konfidens er under en terskel, kan modellen fungere elegant med en reservehensikt for å håndtere forvirringssaker.
Når boten identifiserer hensikten med en brukers melding, må den sende et svar tilbake. Bot bestemmer svaret basert på et visst sett med definerte regler og historier. For eksempel kan en regel være så enkel som fullstendig "god morgen" når brukeren hilser "Hei". Men oftest omfatter samtaler med chatbots oppfølgingsinteraksjon, og svarene deres avhenger av den generelle konteksten til samtalen.
Hva gjør jeg?
For å håndtere dette mates chatbots med ekte samtaleeksempler kalt Stories. Brukere samhandler imidlertid ikke alltid etter hensikten. En moden chatbot bør håndtere alle slike avvik på en elegant måte. Designere og utviklere kan garantere dette hvis de ikke bare fokuserer på en lykkelig vei mens de skriver historier, men også jobber på ulykkelige veier.
Brukerengasjement med chatbots er sterkt avhengig av chatbot-svarene. Brukere kan miste interessen hvis svarene er for robotiske eller for kjente. For eksempel kan det hende at en bruker ikke liker et svar som "Du har skrevet feil søk" for feil inndata selv om svaret er riktig. Svaret her samsvarer ikke med personligheten til en assistent.
Hva gjør jeg?
Chatboten fungerer som en assistent og bør ha en spesifikk persona og tone i stemmen. De skal være imøtekommende og ydmyke, og utviklere bør utforme samtaler og ytringer deretter. Svarene skal ikke høres robotiske eller mekaniske ut. For eksempel kan roboten si, "Beklager, det virker som jeg ikke har noen detaljer. Kan du skrive inn spørsmålet ditt på nytt?» for å adressere feil input.
LLM (Large Language Model) baserte chatbots som ChatGPT og Bard er spillendrende innovasjoner og har forbedret mulighetene til samtale-AIer. De er ikke bare flinke til å lage åpne menneskelignende samtaler, men de kan utføre forskjellige oppgaver som tekstoppsummering, avsnittsskriving, etc., som kan oppnås tidligere bare med spesifikke modeller.
En av utfordringene med tradisjonelle chatbot-systemer er å kategorisere hver setning i hensikter og bestemme svaret deretter. Denne tilnærmingen er ikke praktisk. Svar som "Beklager, jeg kunne ikke få deg" er ofte irriterende. Hensiktsløse chatbot-systemer er veien videre, og LLM-er kan gjøre dette til en realitet.
LLM-er kan enkelt oppnå toppmoderne resultater i generell gjenkjenning av navngitte enheter, med unntak av viss domenespesifikk enhetsgjenkjenning. En blandet tilnærming til bruk av LLM med alle chatbot-rammeverk kan inspirere til et mer modent og robust chatbot-system.
Med de siste fremskrittene og kontinuerlig forskning innen konversasjons-AI, blir chatbots bedre for hver dag. Områder som å håndtere komplekse oppgaver med flere hensikter, for eksempel "Bestill et fly til Mumbai og ordne en drosje til Dadar," får mye oppmerksomhet.
Snart vil personlige samtaler finne sted basert på egenskapene til brukeren for å holde brukeren engasjert. For eksempel, hvis en bot finner ut at brukeren er misfornøyd, omdirigerer den samtalen til en ekte agent. I tillegg, med stadig økende chatbot-data, kan dyplæringsteknikker som ChatGPT automatisk generere svar for spørsmål ved hjelp av en kunnskapsbase.
Suman Saurav er en dataforsker ved Talentica Software, et programvareutviklingsselskap. Han er en alumnus ved NIT Agartala med over 8 års erfaring med å designe og implementere revolusjonerende AI-løsninger ved bruk av NLP, Conversational AI og Generative AI.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- : har
- :er
- :ikke
- :hvor
- 8
- a
- evne
- Om oss
- ovenfor
- tilsvar
- Oppnå
- oppnådd
- tvers
- handlinger
- legge
- I tillegg
- adresse
- adressering
- fremskritt
- Etter
- Agent
- agenter
- AI
- AI chatbot
- Alexa
- Alle
- allerede
- også
- alumnus
- alltid
- beløp
- an
- og
- En annen
- besvare
- noen
- tilnærming
- ER
- områder
- AS
- spør
- Assistent
- assistenter
- assosiert
- At
- oppmerksomhet
- automatisk
- tilgjengelig
- unngå
- tilbake
- basen
- basert
- BE
- bli
- vesener
- under
- BEST
- Bedre
- Bot
- både
- roboter
- bygge
- men
- by
- ring
- som heter
- CAN
- kan ikke
- evner
- stand
- saker
- kategorisering
- viss
- utfordringer
- Endringer
- egenskaper
- chatbot
- chatbots
- ChatGPT
- City
- klassifisering
- klassifisert
- klart
- stengt
- Selskapet
- klager
- komplekse
- komponent
- komponenter
- fatte
- selvtillit
- forvirret
- forvirrende
- forvirring
- Vurder
- kontekst
- kontinuerlig
- Samtale
- conversational
- samtale AI
- samtaler
- korrigere
- riktig
- Tilsvarende
- kunne
- land
- kurs
- skape
- Opprette
- avgjørende
- Gjeldende
- skikk
- dato
- dataforsker
- Database
- Dato
- dag
- anstendig
- Avgjør
- dyp
- dyp læring
- definere
- definert
- Delhi
- avhenge
- Derive
- utforming
- designere
- utforme
- detaljer
- Utvikler
- utviklere
- Utvikling
- dialogflyt
- Dialog
- forskjellig
- differensiere
- do
- ikke
- domene
- ikke
- hver enkelt
- Tidligere
- lett
- innsats
- embedding
- Endless
- engasjere
- engasjert
- engasjement
- Engelsk
- forbedre
- Enter
- enheter
- enhet
- etc
- Selv
- etter hvert
- stadig økende
- Hver
- hver dag
- eksempel
- eksempler
- erfaring
- Forklar
- trekke ut
- utdrag
- FAIL
- sviktende
- kjent
- FAST
- Egenskaper
- Fed
- Finn
- funn
- flytur
- Fokus
- Til
- Forward
- Rammeverk
- rammer
- Fransk
- fra
- general
- generere
- genererer
- generasjonen
- generative
- Generativ AI
- generator
- få
- få
- gitt
- god
- Googles
- garantere
- håndtere
- Håndtering
- skje
- lykkelig
- Ha
- å ha
- he
- tungt
- hjelpe
- nyttig
- her.
- Hvordan
- Hvordan
- Men
- HTTPS
- menneskelig
- ydmyk
- i
- identifisert
- identifiserer
- identifisere
- if
- implementere
- forbedret
- in
- inkludere
- innovasjoner
- inngang
- innganger
- inspirere
- f.eks
- i stedet
- tiltenkt
- hensikt
- samhandle
- interaksjon
- interaksjoner
- interesse
- inn
- introdusere
- IT
- jpg
- bare
- KDnuggets
- Hold
- nøkkel
- Type
- kunnskap
- kjent
- vet
- Språk
- språk
- stor
- siste
- læring
- Life
- i likhet med
- BEGRENSE
- Begrenset
- taper
- Lav
- lavere
- maskin
- maskinlæring
- større
- gjøre
- Making
- Match
- moden
- Kan..
- me
- bety
- mekanisk
- mekanisme
- melding
- kunne
- minimal
- bland
- blandet
- modell
- modeller
- mer
- Videre
- mest
- mye
- flere
- Mumbai
- må
- my
- navn
- oppkalt
- Naturlig
- Naturlig språk
- neste
- NLG
- nlp
- NLU
- Nei.
- Antall
- of
- ofte
- on
- gang
- bare
- åpen
- åpen kildekode
- or
- Annen
- ellers
- vår
- enn
- samlet
- eiere
- del
- banen
- baner
- mønstre
- Ansatte
- utføre
- utført
- utfører
- perioden
- person
- Personlig
- fase
- faser
- Sted
- fly
- planlegging
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- vær så snill
- Point
- posisjon
- besitter
- mulig
- Praktisk
- spådd
- prediksjon
- trekker
- presentert
- forrige
- Problem
- fortsette
- prosess
- Produkt
- produktutvikling
- prosjekt
- spørsmål
- spørsmål
- R
- rasa
- klar
- ekte
- Reality
- virkelig
- anerkjennelse
- rekruttering
- redusere
- referanse
- refererer
- region
- avhengige
- påminnelse
- erstatte
- krever
- Krever
- forskning
- løse
- svar
- svar
- ansvarlig
- resulterende
- Resultater
- revolusjonær
- robust
- Regel
- regler
- samme
- sier
- scenarier
- Forsker
- skraper
- Søk
- søker
- synes
- utvalg
- send
- dømme
- serverer
- sett
- Del
- bør
- lignende
- Enkelt
- siden
- enkelt
- siri
- Software
- løsning
- Solutions
- noen
- Lyd
- spesifikk
- talt
- Scene
- Start
- state-of-the-art
- Stories
- effektivisere
- Studenter
- betydelig
- slik
- egnet
- støtte
- Støttesystemer
- sikker
- syntetisk
- system
- Systemer
- T
- bord
- Ta
- tar
- Oppgave
- oppgaver
- teknikker
- tekst
- enn
- Det
- De
- deres
- Dem
- deretter
- Der.
- Disse
- de
- denne
- selv om?
- tre
- terskel
- tid
- til
- TONE
- Tonefall
- også
- tradisjonelle
- Tog
- trent
- Kurs
- utløse
- to
- typen
- typer
- forståelse
- oppgradering
- bruke
- brukt
- Bruker
- Brukere
- ved hjelp av
- vanligvis
- Verdier
- av
- virtuelle
- Voice
- vs
- W
- Vei..
- måter
- velkommen
- VI VIL
- Hva
- når
- når som helst
- hvilken
- mens
- vil
- med
- ord
- ord
- Arbeid
- arbeidet
- ville
- skriving
- skrevet
- Feil
- år
- du
- Din
- zephyrnet