In 2021 og 2020, fortalte vi deg om de nye funksjonene i Amazon RedShift som gjør det enklere, raskere og mer kostnadseffektivt å analysere alle dataene dine og finne rik og kraftig innsikt. I 2022 er vi glade for å kunne rapportere at Amazon Redshift-teamet jobbet hardt. Vi jobbet baklengs fra kundenes krav og annonserte flere nye funksjoner for å gjøre det enklere, raskere og mer kostnadseffektivt å analysere alle dataene dine. Dette innlegget dekker noen av disse nye funksjonene.
Hos AWS, for data og analyser, er strategien vår å gi deg en moderne dataarkitektur som hjelper deg å slippe fri fra datasiloer; ha spesialbygde data, analyser, maskinlæring (ML) og kunstig intelligens-tjenester for å bruke riktig verktøy for riktig jobb; og har åpne, styrte, sikre og fullstendig administrerte tjenester for å gjøre analyser tilgjengelig for alle. Innenfor AWS sin moderne dataarkitektur forblir Amazon Redshift som skydatavarehuset en nøkkelkomponent, som lar deg kjøre kompleks SQL-analyse i skala og ytelse på terabyte til petabyte med strukturerte og ustrukturerte data, og gjøre innsikten allment tilgjengelig gjennom populær forretningsintelligens ( BI) og analyseverktøy. Vi fortsetter å jobbe bakover fra kundenes krav, og lanserte i 2022 over 40 funksjoner i Amazon Redshift for å hjelpe kunder med deres beste datavarehusbruk, inkludert:
- Selvbetjeningsanalyse
- Enkel datainntak
- Datadeling og samarbeid
- Datavitenskap og maskinlæring
- Sikker og pålitelig analyse
- Beste prisytelsesanalyse
La oss dykke dypere og diskutere de nye Amazon Redshift-funksjonene i disse områdene.
Selvbetjeningsanalyse
Kunder fortsetter å fortelle oss at data og analyser blir allestedsnærværende, og alle i deres organisasjon trenger analyser. Vi annonserte Amazon Redshift Serverløs (i forhåndsvisning) i 2021 for å gjøre det enkelt å kjøre og skalere analyser på sekunder uten å måtte klargjøre og administrere datavarehusinfrastruktur. I juli 2022 kunngjorde vi generell tilgjengelighet av Redshift Serverless, og siden den gang har tusenvis av kunder, inkludert Peloton, Broadridge Financials og NextGen Healthcare, brukt det til raskt og enkelt å analysere dataene sine. Amazon Redshift Serverless sørger automatisk for og skalerer datavarehuskapasiteten på en intelligent måte for å levere høy ytelse for all analyse, og du betaler kun for beregningen som brukes for varigheten av arbeidsbelastningene per sekund. Siden GA har vi lagt til funksjoner som ressurstagging, forenklet overvåking og tilgjengelighet i flere AWS-regioner for å forenkle faktureringen ytterligere og utvide rekkevidden til flere regioner over hele verden.
I 2021 lanserte vi Amazon Redshift Query Editor V2, som er et gratis nettbasert verktøy for dataanalytikere, dataforskere og utviklere til å utforske, analysere og samarbeide om data i Amazon Redshift-datavarehus og datainnsjøer. I 2022 fikk Query Editor V2 ytterligere forbedringer som f.eks støtte for bærbare datamaskiner for forbedret samarbeid for å skrive, organisere og kommentere spørsmål; brukertilgang gjennom identitetsleverandør (IdP) legitimasjon for enkel pålogging; og muligheten til å kjøre flere spørringer samtidig for å forbedre utviklerproduktiviteten.
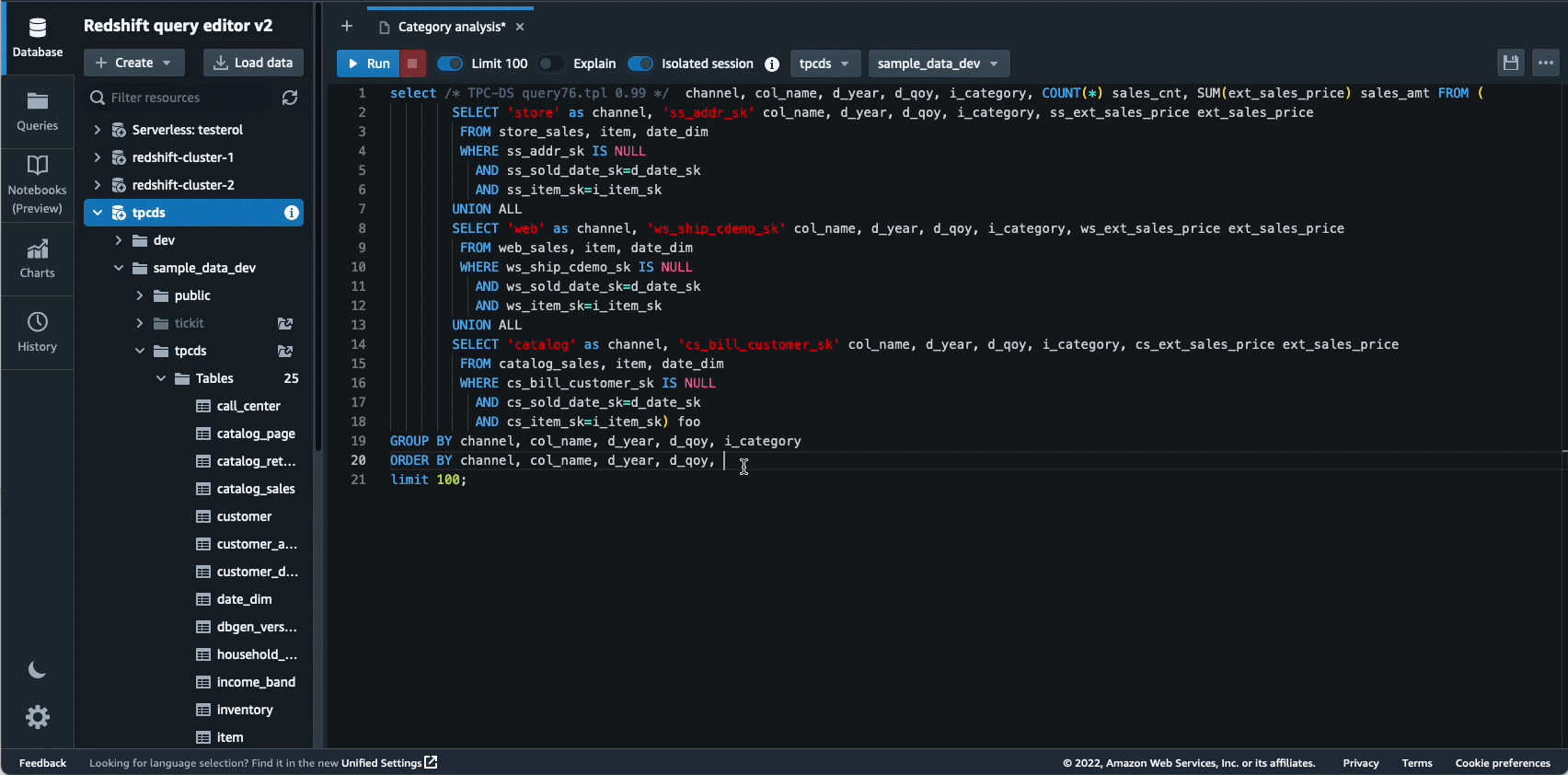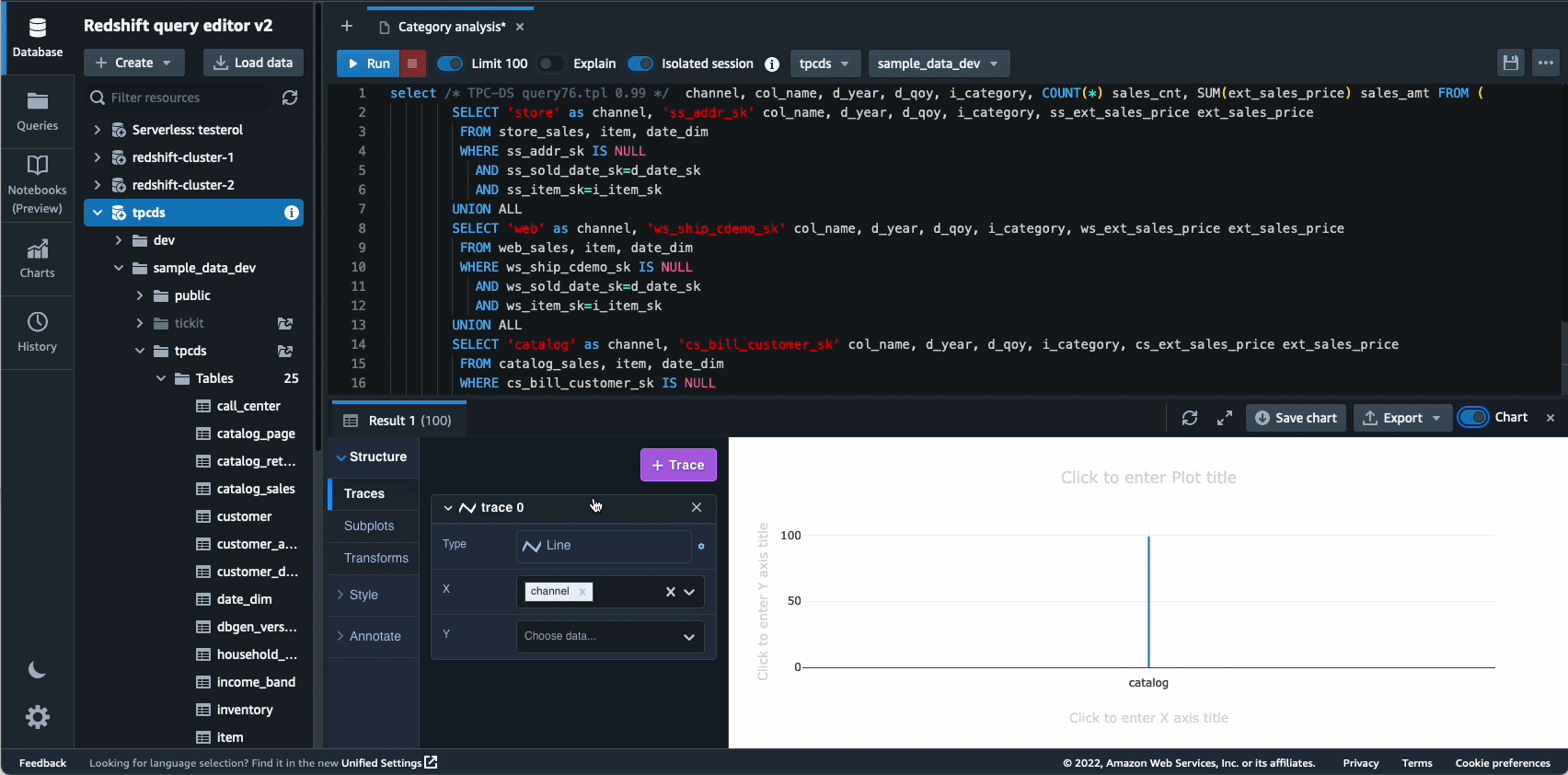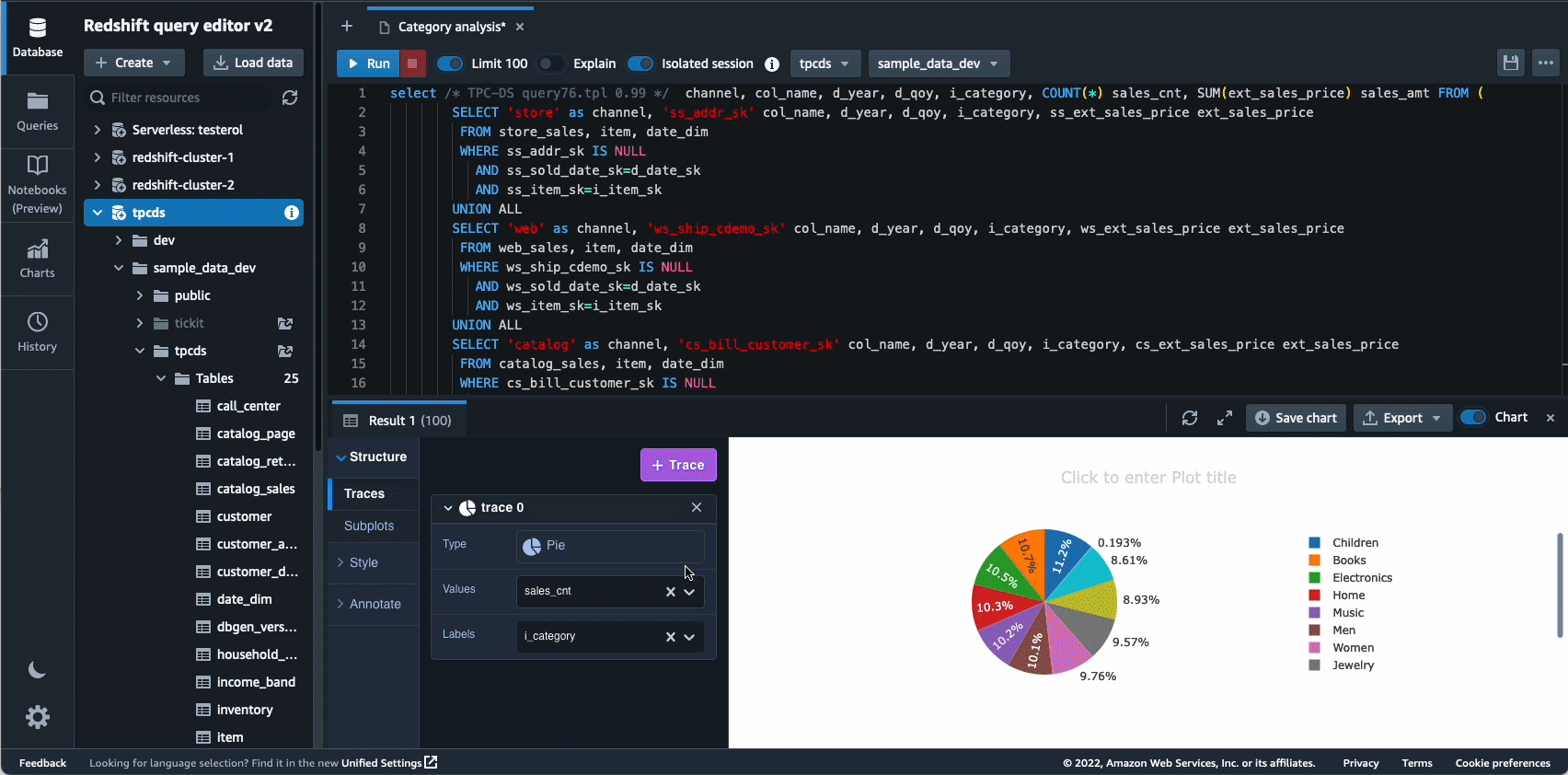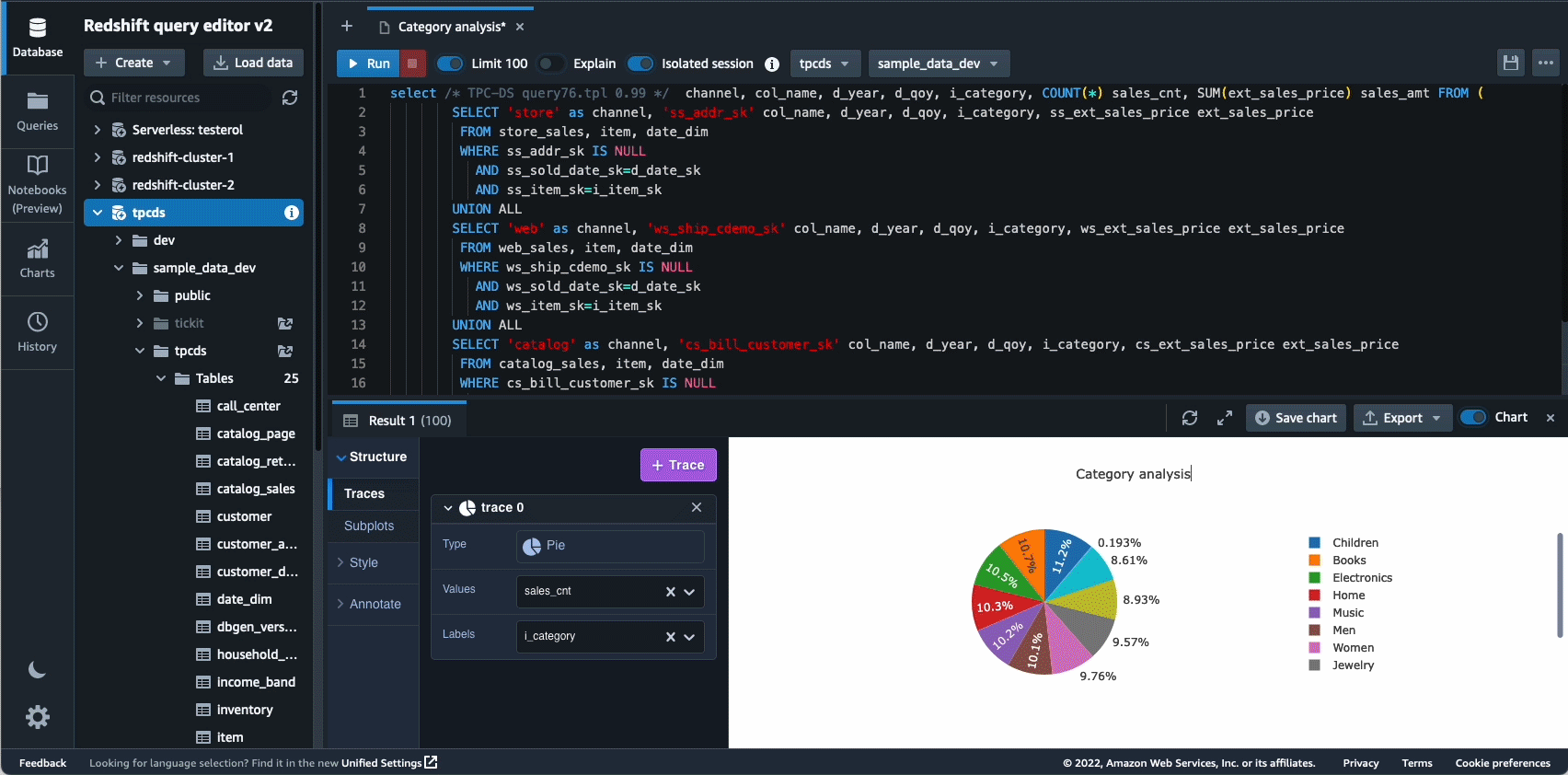
Autonomics er et annet område hvor vi jobber aktivt med å bruke ML-baserte optimaliseringer og gi kundene et selvlærende og selvoptimaliserende datavarehus. I 2022 annonserte vi generell tilgjengelighet av Automatiserte materialiserte visninger (AutoMVs) for å forbedre ytelsen til spørringer (redusere den totale kjøretiden) uten brukerinnsats ved automatisk å opprette og vedlikeholde materialiserte visninger. AutoMV-er, kombinert med automatisk oppdatering, inkrementell oppdatering og automatisk omskriving av spørringer for materialiserte visninger, gjorde materialiserte visninger vedlikeholdsfrie, og ga deg raskere ytelse automatisk. i tillegg automatisk tabelloptimalisering (ATO) mulighet for skjemaoptimalisering og automatisk arbeidsbelastningsstyring (auto WLM) kapasitet for arbeidsbelastningsoptimalisering fikk ytterligere forbedringer for bedre søkeytelse.
Enkel datainntak
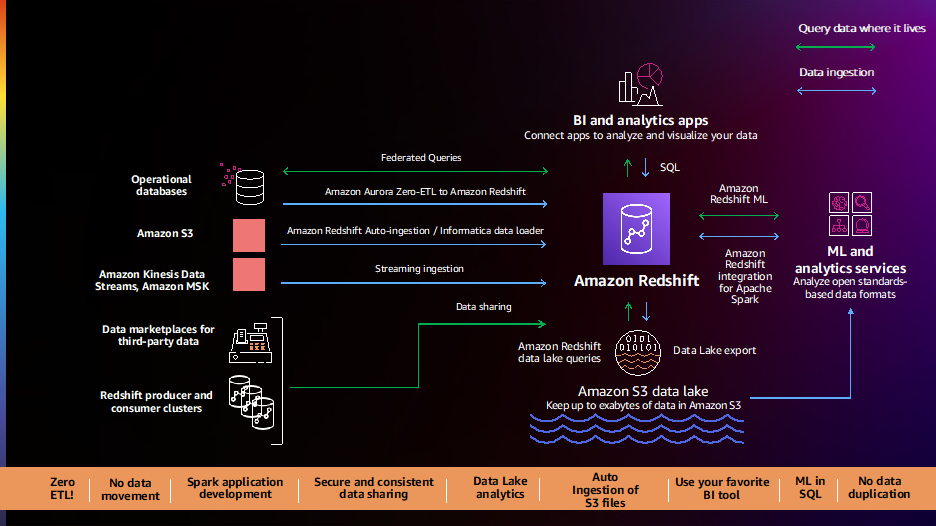
Kunder forteller oss at de har dataene sine distribuert over flere datakilder som transaksjonsdatabaser, datavarehus, datainnsjøer og store datasystemer. De vil ha fleksibiliteten til å integrere disse dataene med no-code/low-code, null-ETL datapipelines eller analysere disse dataene på plass uten å flytte dem. Kunder forteller oss at deres nåværende datapipelines er komplekse, manuelle, rigide og trege, noe som resulterer i ufullstendige, inkonsekvente og foreldede datavisninger, noe som begrenser innsikten. Kunder har bedt oss om en bedre vei videre, og vi er glade for å kunngjøre en rekke nye muligheter for å forenkle og automatisere datapipelines.
Amazon Aurora null-ETL-integrasjon med Amazon Redshift (forhåndsvisning) lar deg kjøre nesten sanntidsanalyse og ML på petabyte med transaksjonsdata. Den tilbyr en kodefri løsning for å lage transaksjonsdata fra flere Amazonas Aurora databaser tilgjengelig i Amazon Redshift-datavarehus innen sekunder etter at de er skrevet til Aurora, noe som eliminerer behovet for å bygge og vedlikeholde komplekse datapipelines. Med denne funksjonen kan Aurora-kunder også få tilgang til Amazon Redshift-funksjoner som kompleks SQL-analyse, innebygd ML, datadeling og forent tilgang til flere datalagre og datainnsjøer. Denne funksjonen er nå tilgjengelig i forhåndsvisning for Amazon Aurora MySQL-kompatibel utgave versjon 3 (med MySQL 8.0-kompatibilitet), og du kan be om tilgang til forhåndsvisningen.
Amazon Redshift støtter nå autokopier fra Amazon S3 (forhåndsvisning) for å forenkle datainnlasting fra Amazon enkel lagringstjeneste (Amazon S3) til Amazon Redshift. Du kan nå sette opp regler for kontinuerlig filinntak (kopijobber) for å spore Amazon S3-banene dine og automatisk laste inn nye filer uten behov for ekstra verktøy eller tilpassede løsninger. Kopieringsjobber kan overvåkes gjennom systemtabeller, og de holder automatisk oversikt over tidligere lastede filer og ekskluderer dem fra inntaksprosessen for å forhindre duplisering av data. Denne funksjonen er nå tilgjengelig i forhåndsvisning; du kan prøve denne funksjonen ved å opprette en ny klynge ved å bruke forhåndsvisningssporet.
Kunder fortsetter å fortelle oss at de trenger øyeblikkelig analyse i sanntid, og vi er glade for å kunngjøre generell tilgjengelighet av støtte for strømming i Amazon Redshift for Amazon Kinesis datastrømmer og Amazon administrerte strømming for Apache Kafka (Amazon MSK). Denne funksjonen eliminerer behovet for å iscenesette strømmedata i Amazon S3 før de tas inn i Amazon Redshift, noe som gjør at du kan oppnå lav ventetid, målt i sekunder, mens du inntar hundrevis av megabyte med strømmedata per sekund i datavarehusene dine. Du kan bruke SQL i Amazon Redshift for å koble til og direkte innta data fra flere Kinesis-datastrømmer eller MSK-emner, lage automatisk oppfriskende streamingmaterialiserte visninger med transformasjoner på toppen av strømmer direkte for å få tilgang til strømmedata, og kombinere sanntidsdata med historiske data for bedre innsikt. For eksempel har Adobe integrert Amazon Redshift-streaming-inntak som en del av deres Adobe Experience-plattform for å innta og analysere, i sanntid, web- og applikasjonsklikkstrøm og øktdata for ulike applikasjoner som CRM og kundestøtteapplikasjoner.
Kunder har fortalt oss at de ønsker enkel, ut-av-boksen integrasjon mellom Amazon Redshift, BI og ETL (ekstrahere, transformere og laste)-verktøy, og forretningsapplikasjoner som Salesforce og Marketo. Vi er glade for å kunngjøre den generelle tilgjengeligheten av Informatica Data Loader for Amazon Redshift, som lar deg bruke Informatica Data Loader for høyhastighets- og høyvolumsdatalasting til Amazon Redshift gratis. Du kan ganske enkelt velge alternativet Informatica Data Loader på Amazon Redshift-konsollen. Når du først er i Informatica Data Loader, kan du koble til kilder som Salesforce eller Marketo, velge Amazon Redshift som mål og begynne å laste inn dataene dine.
Datadeling og samarbeid
Kunder fortsetter å fortelle oss at de ønsker å analysere alle sine førsteparts- og tredjepartsdata og gjøre den rike datadrevne innsikten tilgjengelig for sine kunder, partnere og leverandører. Vi lanserte nye funksjoner i 2021, som f.eks Datadeling og AWS Data Exchange-integrasjon, for å gjøre det enklere for deg å analysere alle dataene dine og dele dem innenfor og utenfor organisasjonene dine.
Et godt eksempel på en kunde som bruker datadeling er Orion. Orion leverer sanntidsdata som en tjeneste (DaaS)-løsninger for kunder i finansnæringen, som for eksempel formuesforvaltning, kapitalforvaltning og leverandører av investeringsforvaltning. De har over 2,500 datakilder som primært er SQL Server-databaser som sitter både i lokalene og i AWS. Data strømmes ved hjelp av Kafka-koblinger til Amazon Redshift. De har en produsentklynge som mottar alle disse dataene og deretter bruker Datadeling til å dele data i sanntid for samarbeid. Dette er en multi-tenant-arkitektur som betjener flere klienter. Gitt sensitiviteten til dataene deres, er datadeling en måte å gi arbeidsbelastningsisolasjon mellom klynger og også trygt dele disse dataene til sluttbrukere.
I 2022 fortsatte vi å investere i dette området for å forbedre ytelsen, styringen og utviklerproduktiviteten med nye funksjoner for å gjøre det enklere, enklere og raskere å dele og samarbeide om data.
Ettersom kunder bygger store datadelingskonfigurasjoner, har de bedt om forenklet styring og sikkerhet for delte data, og vi legger til sentralisert tilgangskontroll med AWS Lake Formation for Amazon Redshift-datadeling for å muliggjøre deling av live-data på tvers av flere Amazon Redshift-datavarehus. Med denne funksjonen støtter Amazon Redshift nå forenklet styring av Amazon Redshift-datadelinger ved å bruke AWS Lake formasjon som en enkelt glassrute for sentral administrasjon av data eller tillatelser på datadeling. Du kan se, endre og revidere tillatelser, inkludert sikkerhet på rad- og kolonnenivå på tabellene og visningene i Amazon Redshift-datadelingene, ved å bruke Lake Formation APIer og AWS-administrasjonskonsoll, og la Amazon Redshift-datadelingene oppdages og konsumeres av andre Amazon Redshift-datavarehus.
Datavitenskap og maskinlæring
Kunder fortsetter å fortelle oss at de vil at data- og analysesystemene deres skal hjelpe dem med å svare på et bredt spekter av spørsmål, fra hva som skjer i virksomheten deres (deskriptiv analyse) til hvorfor det skjer (diagnostisk analyse) og hva som vil skje i fremtiden (prediktiv analyse). Amazon Redshift tilbyr funksjoner som kompleks SQL-analyse, datainnsjøanalyse og Amazon Redshift ML for kunder å analysere dataene sine og oppdage kraftig innsikt. Rødforskyvning ML integrerer Amazon Redshift med Amazon SageMaker, en fullstendig administrert ML-tjeneste, som lar deg opprette, trene og distribuere ML-modeller ved hjelp av kjente SQL-kommandoer.
Kunder har også bedt oss om bedre integrasjon mellom Amazon Redshift og Apache Spark, så vi er glade for å kunngjøre Amazon Redshift-integrasjon for Apache Spark å gjøre datavarehus lett tilgjengelig for Spark-baserte applikasjoner. Nå bruker utviklere AWS-analyse og ML-tjenester som f.eks Amazon EMR, AWS Lim, og SageMaker kan enkelt bygge Apache Spark-applikasjoner som leser fra og skriver til deres Amazon Redshift-datavarehus. Amazon EMR og AWS Glue pakker Redshift-Spark-kontakten slik at du enkelt kan koble til datavarehuset ditt fra dine Spark-baserte applikasjoner. Du kan bruke flere pushdown-funksjoner for operasjoner som sorterings-, aggregerings-, limit-, join- og skalarfunksjoner, slik at bare de relevante dataene flyttes fra Amazon Redshift-datavarehuset til den forbrukende Spark-applikasjonen. Du kan også gjøre applikasjonene dine sikrere ved å bruke AWS identitets- og tilgangsadministrasjon (IAM)-legitimasjon for å koble til Amazon Redshift.
Sikker og pålitelig analyse
Kunder fortsetter å fortelle oss at datavarehusene deres er virksomhetskritiske systemer som trenger høy tilgjengelighet, pålitelighet og sikkerhet. Vi lanserte en rekke nye funksjoner i 2022 på dette området.
Amazon Redshift støtter nå Multi-AZ-utplasseringer (i forhåndsvisning) for RA3-instansbaserte klynger, som gjør det mulig å kjøre datavarehuset ditt i flere AWS-tilgjengelighetssoner samtidig og kontinuerlig drift i uforutsette feilscenarier for tilgjengelighetssone. Multi-AZ-støtte er allerede tilgjengelig for Redshift Serverless. En Amazon Redshift Multi-AZ-distribusjon lar deg gjenopprette i tilfelle Availability Zone-feil uten brukerintervensjon. Et Amazon Redshift Multi-AZ-datavarehus er tilgjengelig som et enkelt datavarehus med ett endepunkt, og hjelper deg med å maksimere ytelsen ved å distribuere arbeidsbelastningsbehandling over flere tilgjengelighetssoner automatisk. Ingen applikasjonsendringer er nødvendig for å opprettholde forretningskontinuitet under uforutsette avbrudd.
I 2022 lanserte vi funksjoner som rollebasert tilgangskontroll, sikkerhet på radnivå og datamaskering (i forhåndsvisning) for å gjøre det enklere for deg å administrere tilgang og bestemme hvem som har tilgang til hvilke data, inkludert tilsløring av personlig identifiserbar informasjon (PII) ) som kredittkortnumre.
Du kan bruke rollebasert tilgangskontroll (RBAC) å kontrollere sluttbrukers tilgang til data på et bredt eller granulært nivå basert på sluttbrukerens jobbrolle og tillatelser. Med RBAC kan du opprette en rolle ved hjelp av SQL, gi en samling granulære tillatelser til rollen og deretter tilordne den rollen til sluttbrukere. Roller kan gis tillatelser på objektnivå, kolonnenivå og systemnivå. I tillegg introduserer RBAC ut-av-boksen systemroller for DBAer, operatører, sikkerhetsadministratorer eller tilpassede roller.
Sikkerhet på radnivå (RLS) forenkler design og implementering av finmasket tilgang til radene i tabeller. Med RLS kan du begrense tilgangen til et undersett av rader i en tabell basert på brukernes jobbrolle eller tillatelser med SQL.
Amazon Redshift-støtte for dynamisk datamaskering (DDM), som nå er tilgjengelig i forhåndsvisning, lar deg forenkle beskyttelsen av PII som personnummer, kredittkortnumre og telefonnumre i ditt Amazon Redshift-datavarehus. Med dynamisk datamaskering kontrollerer du tilgangen til dataene dine gjennom enkle SQL-baserte maskeringspolicyer som bestemmer hvordan Amazon Redshift returnerer sensitive data til brukeren på spørringstidspunktet. Du kan opprette maskeringspolicyer for å definere konsistente, formatbevarende og irreversible maskerte dataverdier. Du kan bruke en maskeringspolicy på en bestemt kolonne eller liste over kolonner i en tabell. Du har også fleksibiliteten til å velge hvordan du vil vise de maskerte dataene. For eksempel kan du skjule dataene fullstendig, erstatte delvise reelle verdier med jokertegn, eller definere din egen måte å maskere dataene ved å bruke SQL-uttrykk, Python eller AWS Lambda brukerdefinerte funksjoner. I tillegg kan du bruke en betinget maskeringspolicy basert på andre kolonner, som selektivt beskytter kolonnedataene i en tabell basert på verdiene i én eller flere forskjellige kolonner.
Vi annonserte også forbedringer til revisjonslogging, innfødt integrasjon med Microsoft Azure Active Directory, og støtte for standard IAM-roller i flere regioner for å forenkle sikkerhetsadministrasjonen ytterligere.
Beste prisytelsesanalyse
Kunder fortsetter å fortelle oss at de trenger raske og kostnadseffektive datavarehus som leverer høy ytelse uansett skala samtidig som kostnadene holdes lave. Fra dag 1 siden Amazon Redshifts lansering i 2012, har vi tatt en datadrevet tilnærming og brukt flåtetelemetri for å bygge en skydatavarehustjeneste som gir deg den beste prisytelsen uansett skala. Gjennom årene har vi utviklet oss Amazon Redshifts arkitektur og lanserte funksjoner som f.eks Redshift Managed Storage (RMS) for separasjon av lagring og databehandling, Amazon Redshift Spectrum for datainnsjøforespørsler, automatisk tabelloptimalisering for fysisk skjemaoptimalisering, automatisk arbeidsbelastningsstyring å prioritere arbeidsbelastninger og allokere riktig datamaskin og minne, endre størrelsen på klyngen å skalere beregning og lagring vertikalt, og samtidighetsskalering å dynamisk skalere beregne ut eller inn. Vår ytelses benchmarks fortsett å demonstrere Amazon Redshifts lederskap i prisytelse.
I 2022 la vi til nye funksjoner som den generelle tilgjengeligheten av samtidighetsskalering for skriveoperasjoner som COPY, INSERT, UPDATE og DELETE for å støtte tilnærmet ubegrenset antall samtidige brukere og spørringer. Vi introduserte også ytelsesforbedringer for strengbasert databehandling gjennom vektoriserte skanninger over lette, CPU-effektive, ordbokkodede strengkolonner, som lar databasemotoren operere direkte over komprimerte data.
Vi har også lagt til støtte for SQL-operatører som f.eks SLÅ SAMMEN (enkeltoperatør for innlegg eller oppdateringer); CONNECY_BY (for hierarkiske spørsmål); GRUPPERINGSSETT, ROLLUP og CUBE (for flerdimensjonal rapportering); og økte størrelsen på SUPER-datatypen til 16 MB for å gjøre det enklere for deg å migrere fra eldre datavarehus til Amazon Redshift.
konklusjonen
Kundene våre fortsetter å fortelle oss at data og analyser fortsatt er en toppprioritet for dem, og behovet for å kostnadseffektivt trekke ut mer forretningsverdi fra dataene deres i disse tider er mer uttalt enn noen annen gang tidligere. Amazon Redshift som skydatavarehuset ditt lar deg kjøre kompleks SQL-analyse med skala og ytelse på terabyte til petabyte med strukturerte og ustrukturerte data og gjøre innsikten allment tilgjengelig gjennom populære BI- og analyseverktøy.
Selv om vi lanserte over 40 funksjoner i 2022 og innovasjonstakten fortsetter å akselerere, er det fortsatt dag 1, og vi ser frem til å høre fra deg om hvordan disse funksjonene hjelper deg å frigjøre mer verdi for organisasjonene dine. Vi inviterer deg til å prøve disse nye funksjonene og ta kontakt med oss gjennom ditt AWS-kontoteam hvis du har flere kommentarer.
Om forfatteren
 Manan Goel er Product Go-To-Market Leader for AWS Analytics Services inkludert Amazon Redshift hos AWS. Han har mer enn 25 års erfaring og er godt kjent med databaser, datavarehus, business intelligence og analyser. Manan har en MBA fra Duke University og en BS i elektronikk- og kommunikasjonsteknikk.
Manan Goel er Product Go-To-Market Leader for AWS Analytics Services inkludert Amazon Redshift hos AWS. Han har mer enn 25 års erfaring og er godt kjent med databaser, datavarehus, business intelligence og analyser. Manan har en MBA fra Duke University og en BS i elektronikk- og kommunikasjonsteknikk.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/whats-new-in-amazon-redshift-2022-a-year-in-review/
- 1
- 100
- 2021
- 2022
- a
- evne
- Om oss
- akselerere
- adgang
- Tilgang til data
- aksesseres
- tilgjengelig
- Logg inn
- Oppnå
- tvers
- aktiv
- aktivt
- la til
- tillegg
- Ytterligere
- I tillegg
- Adobe
- Alle
- tillater
- allerede
- Amazon
- Amazon EMR
- analytikere
- analytics
- analysere
- analyserer
- og
- Kunngjøre
- annonsert
- En annen
- besvare
- Apache
- Apache Spark
- APIer
- Søknad
- søknader
- Påfør
- tilnærming
- arkitektur
- AREA
- områder
- kunstig
- kunstig intelligens
- eiendel
- Kapitalforvaltning
- revisjon
- Aurora
- forfatter
- auto
- automatisere
- Automatisk
- automatisk
- tilgjengelighet
- tilgjengelig
- AWS
- AWS Lim
- Azure
- basert
- basis
- bli
- før du
- være
- BEST
- Bedre
- mellom
- Stor
- Store data
- fakturering
- Break
- bred
- Broadridge
- bygge
- Bygning
- innebygd
- virksomhet
- Business Applications
- Forretnings kontinuitet
- business intelligence
- evner
- Kapasitet
- kort
- saken
- saker
- Endringer
- tegn
- Velg
- velge
- klienter
- Cloud
- Cluster
- samarbeide
- samarbeid
- samling
- Kolonne
- kolonner
- kombinere
- kombinert
- kommentarer
- kommunikasjon
- kompatibilitet
- helt
- komplekse
- komponent
- Beregn
- samtidig
- Koble
- konsistent
- Konsoll
- forbrukes
- fortsette
- fortsatte
- fortsetter
- kontinuerlig
- kontroll
- kostnadseffektiv
- Kostnader
- dekker
- skape
- Opprette
- Credentials
- kreditt
- kredittkort
- studiepoeng
- CRM
- Gjeldende
- skikk
- kunde
- Kundeservice
- Kunder
- tilpasset
- dato
- Datautveksling
- Data Lake
- databehandling
- datadeling
- datalager
- datavarehus
- data-drevet
- Database
- databaser
- dag
- dypere
- leverer
- demonstrere
- utplassere
- distribusjon
- utforming
- Bestem
- Utvikler
- utviklere
- forskjellig
- direkte
- oppdage
- oppdaget
- diskutere
- distribueres
- distribusjon
- Duke
- duke universitetet
- under
- dynamisk
- enklere
- lett
- redaktør
- innsats
- Elektronikk
- eliminerer
- eliminere
- muliggjøre
- muliggjør
- muliggjør
- Endpoint
- Motor
- Ingeniørarbeid
- Eter (ETH)
- alle
- utviklet seg
- eksempel
- utveksling
- opphisset
- Expand
- erfaring
- utforske
- uttrykkene
- trekke ut
- Failure
- kjent
- FAST
- raskere
- Trekk
- Egenskaper
- filet
- Filer
- finansiell
- finansielle tjenester
- økonomi
- Finn
- FLÅTE
- fleksibilitet
- formasjon
- Forward
- Gratis
- fra
- fullt
- funksjoner
- videre
- framtid
- general
- få
- gif
- Gi
- gitt
- gir
- Giving
- glass
- Gå til markedet
- styresett
- innvilge
- innvilget
- flott
- skje
- lykkelig
- Hard
- å ha
- helsetjenester
- hørsel
- hjelpe
- hjelper
- Gjemme seg
- Høy
- historisk
- holder
- Hvordan
- Hvordan
- HTML
- HTTPS
- Hundrevis
- IAM
- Identitet
- gjennomføring
- forbedre
- forbedret
- forbedringer
- in
- Inkludert
- økt
- industri
- informasjon
- Infrastruktur
- Innovasjon
- Setter inn
- innsikt
- integrere
- integrert
- Integrerer
- integrering
- Intelligens
- intervensjon
- introdusert
- Introduserer
- Investere
- investering
- invitere
- isolasjon
- IT
- Jobb
- Jobb
- bli medlem
- Juli
- Kafka
- Hold
- holde
- nøkkel
- Kinesis datastrømmer
- innsjø
- storskala
- Ventetid
- lansere
- lansert
- leder
- Ledelse
- læring
- Legacy
- Nivå
- lettvekt
- BEGRENSE
- Liste
- leve
- live data
- laste
- loader
- lasting
- Se
- Lav
- maskin
- maskinlæring
- laget
- vedlikeholde
- vedlikehold
- gjøre
- Making
- administrer
- fikk til
- ledelse
- håndbok
- Marketo
- maske
- Maksimer
- Minne
- migrere
- ML
- modeller
- Moderne
- modifisere
- overvåket
- overvåking
- mer
- flytting
- flere
- MySQL
- innfødt
- Trenger
- nødvendig
- behov
- Ny
- Nye funksjoner
- Antall
- tall
- Tilbud
- ONE
- åpen
- betjene
- drift
- Drift
- operatør
- operatører
- optimalisering
- Alternativ
- organisasjon
- organisasjoner
- Annen
- brudd
- utenfor
- egen
- Fred
- pakke
- brød
- del
- partnere
- Past
- Betale
- peloton
- ytelse
- tillatelser
- personlig
- telefon
- fysisk
- PII
- Sted
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- fornøyd
- Politikk
- politikk
- Populær
- Post
- kraftig
- Prediktiv Analytics
- forebygge
- Forhåndsvisning
- tidligere
- pris
- primært
- Prioriter
- prioritet
- prosess
- prosessering
- produsent
- Produkt
- produktivitet
- beskytte
- gi
- leverandør
- tilbydere
- gir
- forsyning
- Python
- spørsmål
- raskt
- område
- å nå
- Lese
- ekte
- sanntids
- sanntidsdata
- mottar
- Gjenopprette
- redusere
- regioner
- relevant
- pålitelighet
- pålitelig
- forblir
- erstatte
- rapporterer
- Rapportering
- Krav
- begrense
- resulterende
- avkastning
- anmeldelse
- omskriving
- Rich
- rigid
- Rolle
- roller
- rull opp
- regler
- Kjør
- rennende
- sagemaker
- Salesforce
- Skala
- vekter
- skalering
- scenarier
- Vitenskap
- forskere
- Sekund
- sekunder
- sikre
- sikkert
- sikkerhet
- sensitive
- Følsomhet
- server~~POS=TRUNC
- serverer
- tjeneste
- Tjenester
- Session
- sett
- sett
- flere
- Del
- delt
- deling
- Vis
- Enkelt
- forenklet
- forenkle
- ganske enkelt
- samtidig
- siden
- enkelt
- Sittende
- Størrelse
- langsom
- So
- selskap
- løsning
- Solutions
- noen
- Kilder
- Spark
- spesifikk
- SQL
- Scene
- lagring
- butikker
- Strategi
- streames
- streaming
- bekker
- strukturert
- strukturerte og ustrukturerte data
- slik
- Super
- leverandører
- støtte
- Støtter
- system
- Systemer
- bord
- Target
- lag
- De
- Fremtiden
- deres
- tredjeparts
- tusener
- Gjennom
- tid
- ganger
- til
- verktøy
- verktøy
- topp
- temaer
- Totalt
- berøre
- spor
- Tog
- transaksjonell
- Transform
- transformasjoner
- allestedsnærværende
- uforutsett
- universitet
- ubegrenset
- låse opp
- Oppdater
- oppdateringer
- us
- bruke
- Bruker
- Brukere
- utnytte
- verdi
- Verdier
- ulike
- versjon
- Se
- visninger
- nesten
- Warehouse
- lager
- Rikdom
- formuesforvaltning
- web
- Web-basert
- Hva
- Hva er
- hvilken
- mens
- HVEM
- bred
- Bred rekkevidde
- allment
- vil
- innenfor
- uten
- Arbeid
- arbeidet
- arbeid
- verdensomspennende
- skrive
- skrevet
- år
- år
- Din
- zephyrnet
- soner