Amazon EMR runtime for Apache Spark er en ytelsesoptimalisert kjøretid for Apache Spark som er 100 % API-kompatibel med åpen kildekode Apache Spark. Med Amazon EMR utgivelse 6.9.0, EMR-kjøretiden for Apache Spark støtter tilsvarende Spark versjon 3.3.0.
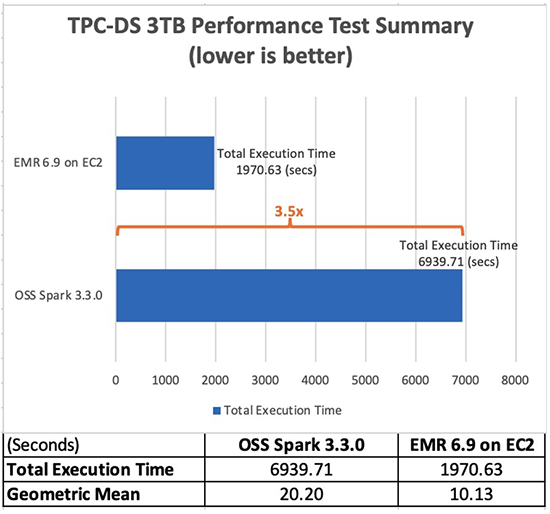
Med Amazon EMR 6.9.0 kan du nå kjøre dine Apache Spark 3.x-applikasjoner raskere og til lavere kostnad uten å kreve noen endringer i applikasjonene dine. I våre ytelsestester, avledet fra TPC-DS ytelsestester på 3 TB skala, fant vi at EMR-kjøringen for Apache Spark 3.3.0 gir en ytelsesforbedring på 3.5 ganger (ved bruk av total kjøretid) i gjennomsnitt sammenlignet med åpen kildekode Apache Spark 3.3.0. XNUMX.
I dette innlegget analyserer vi resultatene fra våre benchmark-tester som kjører en TPC-DS-applikasjon på åpen kildekode Apache Spark og deretter på Amazon EMR 6.9, som kommer med en optimalisert Spark-kjøringstid som er kompatibel med åpen kildekode Spark. Vi går gjennom en detaljert kostnadsanalyse og gir til slutt trinnvise instruksjoner for å kjøre benchmark.
Resultater observert
For å evaluere ytelsesforbedringene brukte vi et Spark-ytelsestestverktøy med åpen kildekode som er avledet fra TPC-DS-ytelsestestverktøysettet. Vi kjørte testene på en syv-node (seks kjernenoder og en primær node) c5d.9xlarge EMR-klynge med EMR-kjøretiden for Apache Spark, og en andre selvadministrert klynge med syv noder på Amazon Elastic Compute Cloud (Amazon EC2) med tilsvarende åpen kildekode-versjon av Spark. Vi kjørte begge testene med data inn Amazon enkel lagringstjeneste (Amazon S3).
Dynamic Resource Allocation (DRA) er en flott funksjon å bruke for varierende arbeidsbelastninger. Men for en benchmarking-øvelse der vi sammenligner to plattformer utelukkende på ytelse, og testdatavolumer ikke endres (3 TB i vårt tilfelle), mener vi det er best å unngå variasjon for å kjøre en epler-til-epler-sammenligning. I testene våre i både åpen kildekode Spark og Amazon EMR, deaktiverte vi DRA mens vi kjørte benchmarking-applikasjonen.
Tabellen nedenfor viser total jobbkjøringstid for alle spørringer (i sekunder) i 3 TB spørringsdatasettet mellom Amazon EMR versjon 6.9.0 og åpen kildekode Spark versjon 3.3.0. Vi observerte at TPC-DS-testene våre hadde en total jobbkjøringstid på Amazon EMR på Amazon EC2 som var 3.5 ganger raskere enn ved bruk av en Spark-klynge med åpen kildekode med samme konfigurasjon.
Hastigheten per spørring på Amazon EMR 6.9 med og uten EMR-kjøretiden for Apache Spark er illustrert i følgende diagram. Den horisontale aksen viser hvert søk i 3 TB benchmark. Den vertikale aksen viser hastigheten for hver spørring på grunn av EMR-kjøretiden. Bemerkelsesverdige ytelsesgevinster er over 10 ganger raskere for TPC-DS-spørringer 24b, 72, 95 og 96.

Kostnadsanalyse
Ytelsesforbedringene til EMR-kjøretiden for Apache Spark fører direkte til lavere kostnader. Vi var i stand til å realisere en kostnadsbesparelse på 67 % ved å kjøre benchmark-applikasjonen på Amazon EMR sammenlignet med kostnadene for å kjøre den samme applikasjonen på åpen kildekode Spark på Amazon EC2 med samme klyngestørrelse på grunn av reduserte timer med Amazon EMR og Amazon EC2 bruk. Amazon EMR-priser er for EMR-applikasjoner som kjører på EMR-klynger med EC2-forekomster. Amazon EMR-prisen legges til de underliggende beregnings- og lagringsprisene som EC2-forekomstpris og Amazon Elastic Block Store (Amazon EBS) kostnad (hvis du vedlegger EBS-volumer). Totalt sett er den estimerte referansekostnaden i USAs østlige (N. Virginia)-regionen $27.01 per kjøring for åpen kildekode Spark på Amazon EC2 og $8.82 per kjøring for Amazon EMR.
| Benchmark jobb | Kjøretid (time) | Estimert kostnad | Total EC2-forekomst | Total vCPU | Totalt minne (GiB) | Rotenhet (Amazon EBS) |
|
Åpen kildekode Spark på Amazon EC2 (1 primær og 6 kjernenoder) |
2.23 | $27.01 | 7 | 252 | 504 | 20 GiB gp2 |
|
Amazon EMR på Amazon EC2 (1 primær og 6 kjernenoder) |
0.63 | $8.82 | 7 | 252 | 504 | 20 GiB gp2 |
Kostnadsoversikt
Følgende er kostnadsoversikten for Spark on Amazon EC2-jobben med åpen kildekode ($27.01):
- Total Amazon EC2-kostnad – (7 * $1.728 * 2.23) = (antall forekomster * c5d.9xlarge timepris * jobbkjøring i time) = $26.97
- Amazon EBS-kostnad – ($0.1/730 * 20 * 7 * 2.23) = (Amazon EBS per GB-timepris * root EBS-størrelse * antall forekomster * jobbkjøring i time) = $0.042
Følgende er kostnadsoversikten for Amazon EMR på Amazon EC2-jobben ($8.82):
- Total Amazon EMR-kostnad – (7 * $0.27 * 0.63) = ((antall kjernenoder + antall primærnoder)* c5d.9xlarge Amazon EMR-pris * jobbkjøring i time) = $1.19
- Total Amazon EC2-kostnad – (7 * $1.728 * 0.63) = ((antall kjernenoder + antall primærnoder)* c5d.9xlarge forekomstpris * jobbkjøring i time) = $7.62
- Amazon EBS-kostnad – ($0.1/730 * 20 GiB * 7 * 0.63) = (Amazon EBS per GB-timepris * EBS-størrelse * antall forekomster * jobbkjøring i time) = $0.012
Sett opp OSS Spark-benchmarking
I de følgende avsnittene gir vi en kort oversikt over trinnene som er involvert i å sette opp benchmarkingen. For detaljerte instruksjoner med eksempler, se GitHub repo.
For vår OSS Spark-benchmarking bruker vi åpen kildekode-verktøyet Flintrock å lansere vår Amazon EC2-baserte Apache Spark klynge. Flintrock gir en rask måte å starte en Apache Spark-klynge på Amazon EC2 ved å bruke kommandolinjen.
Forutsetninger
Fullfør følgende forutsetningstrinn:
- Har Python 3.7.x eller nyere.
- Har Pip3 22.2.2 eller nyere.
- Legg til Python bin-katalogen til miljøbanen din. Flintrock-binærfilen vil bli installert i denne banen.
- Kjør
aws configurefor å konfigurere din AWS kommandolinjegrensesnitt (AWS CLI)-skallet for å peke på benchmarking-kontoen. Referere til Rask konfigurasjon med aws configure for instruksjoner. - Ha en nøkkelpar med restriktive filtillatelser for å få tilgang til OSS Spark-primærnoden.
- Opprett en ny S3-bøtte i testkontoen din om nødvendig.
- Kopier TPC-DS-kildedataene som input til S3-bøtten din.
- Bygg referanseapplikasjonen ved å følge trinnene gitt i Trinn for å bygge gnist-benchmark-assembly-applikasjon. Alternativt kan du laste ned en forhåndsbygd spark-benchmark-assembly-3.3.0.jar hvis du vil ha en Spark 3.3.0-basert applikasjon.
Distribuer Spark-klyngen og kjør benchmark-jobben
Fullfør følgende trinn:
- Installer Flintrock-verktøyet via pip som vist i Trinn for å konfigurere OSS Spark Benchmarking.
- Kjør kommandoen flintrock configure, som dukker opp en standard konfigurasjonsfil.
- Endre standard
config.yamlfil basert på dine behov. Alternativt kan du kopiere og lime inn config.yaml-filen innholdet til standard konfigurasjonsfil. Lagre deretter filen der den var. - Til slutt, lanser 7-node Spark-klyngen på Amazon EC2 via Flintrock.
Dette bør opprette en Spark-klynge med én primær node og seks arbeidernoder. Hvis du ser noen feilmeldinger, dobbeltsjekk konfigurasjonsfilverdiene, spesielt Spark- og Hadoop-versjonene og attributtene til nedlastingskilden og AMI.
OSS Spark-klyngen kommer ikke med YARN-ressursadministrator. For å aktivere det, må vi konfigurere klyngen.
- Last ned yarn-site.xml og enable-yarn.sh filer fra GitHub-repoen.
- Erstatte med IP-adressen til primærnoden i Flintrock-klyngen.
Du kan hente IP-adressen fra Amazon EC2-konsollen.
- Last opp filene til alle nodene i Spark-klyngen.
- Kjør enable-yarn-skriptet.
- Aktiver Snappy-støtte i Hadoop (referansejobben leser Snappy-komprimerte data).
- Last ned JAR-filen for benchmark-verktøyet spark-benchmark-assembly-3.3.0.jar til din lokale maskin.
- Kopier denne filen til klyngen.
- Logg på primærnoden og start YARN.
- Send inn referansejobben på Spark-klyngen med åpen kildekode som vist i Send inn benchmarkjobben.
Oppsummer resultatene
Last ned testresultatfilen fra S3-utgangen s3://$YOUR_S3_BUCKET/EC2_TPCDS-TEST-3T-RESULT/timestamp=xxxx/summary.csv/xxx.csv. (Erstatte $YOUR_S3_BUCKET med S3-bøttenavnet ditt.) Du kan bruke Amazon S3-konsollen og navigere til S3-utgangen eller bruke AWS CLI.
Spark benchmark-applikasjonen oppretter en tidsstempelmappe og skriver en sammendragsfil i et summary.csv-prefiks. Tidsstempelet og filnavnet ditt vil være forskjellig fra det som er vist i det foregående eksempelet.
Utdata-CSV-filene har fire kolonner uten overskriftsnavn. De er:
- Spørringsnavn
- Median tid
- Minimum tid
- Maksimal tid
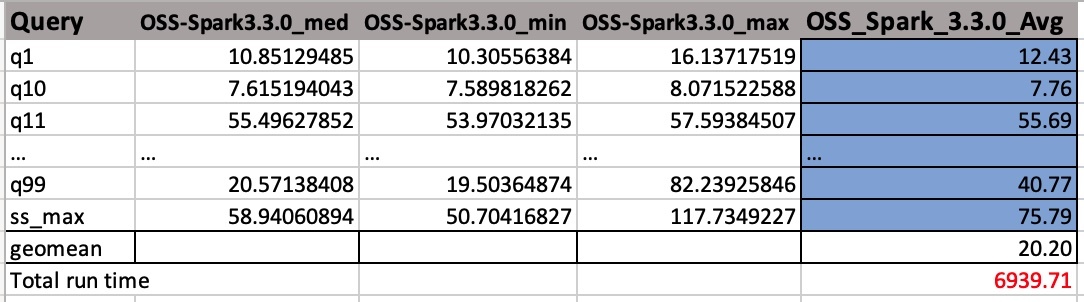
Følgende skjermbilde viser et eksempelutgang. Vi har lagt til kolonnenavn manuelt. Måten vi beregner geometrien og den totale jobbkjøringen er basert på aritmetiske gjennomsnitt. Vi tar først gjennomsnittet av med-, min- og maksverdiene ved å bruke formelen AVERAGE(B2:D2). Deretter tar vi et geometrisk gjennomsnitt av Avg-kolonnen ved å bruke formelen GEOMEAN(E2:E105).
Sett opp Amazon EMR-benchmarking
For detaljerte instruksjoner, se Trinn for å konfigurere EMR-benchmarking.
Forutsetninger
Fullfør følgende forutsetningstrinn:
- Kjør
aws configurefor å konfigurere AWS CLI-skallet til å peke på benchmarking-kontoen. Referere til Rask konfigurasjon med aws configure for instruksjoner. - Last opp benchmark-applikasjonen til Amazon S3.
Distribuer EMR-klyngen og kjør benchmark-jobben
Fullfør følgende trinn:
- Spinn opp Amazon EMR i AWS CLI-skallet ved å bruke kommandolinjen som vist i Distribuer EMR Cluster og kjør benchmarkjobb.
- Konfigurer Amazon EMR med én primær (c5d.9xlarge) og seks kjernenoder (c5d.9xlarge). Referere til opprette-klynge for en detaljert beskrivelse av AWS CLI-alternativer.
- Lagre klynge-ID-en fra svaret. Du trenger dette i neste trinn.
- Send inn referansejobben i Amazon EMR ved å bruke tilleggstrinn i AWS CLI.
Oppsummer resultatene
Oppsummer resultatene fra utdatabøtten s3://$YOUR_S3_BUCKET/blog/EMRONEC2_TPCDS-TEST-3T-RESULT på samme måte som vi gjorde for OSS-resultatene og sammenligne.
Rydd opp
For å unngå fremtidige kostnader, slett ressursene du opprettet ved å bruke instruksjonene i Oppryddingsdelen av GitHub-repoen.
- Stopp EMR- og OSS Spark-klyngene. Du kan også slette dem hvis du ikke vil beholde innholdet. Du kan slette disse ressursene ved å kjøre skriptet cleanup-benchmark-env.sh fra en terminal i ditt benchmark-miljø.
- Hvis du brukte AWS Cloud9 som din IDE for å bygge benchmark-applikasjonen JAR-fil ved hjelp av Trinn for å bygge gnist-benchmark-assembly-applikasjon, kan det være lurt å slette miljøet også.
konklusjonen
Du kan kjøre Apache Spark-arbeidsbelastningene 3.5 ganger (basert på total kjøretid) raskere og til lavere kostnad uten å gjøre noen endringer i applikasjonene dine ved å bruke Amazon EMR 6.9.0.
For å holde deg oppdatert, abonner på Big Data-bloggen RSS-feed for å lære mer om EMR-kjøretiden for Apache Spark, beste praksis for konfigurasjon og råd om justering.
For tidligere benchmark-tester, se Kjør Apache Spark 3.0 arbeidsbelastninger 1.7 ganger raskere med Amazon EMR runtime for Apache Spark. Merk at det tidligere referanseresultatet på 1.7 ganger ytelsen var basert på geometrisk gjennomsnitt. Basert på geometrisk gjennomsnitt var ytelsen i Amazon EMR 6.9 to ganger raskere.
Om forfatterne
 Sekar Srinivasan er en senior spesialistløsningsarkitekt hos AWS med fokus på Big Data og Analytics. Sekar har over 20 års erfaring med å jobbe med data. Han brenner for å hjelpe kunder med å bygge skalerbare løsninger som moderniserer arkitekturen deres og genererer innsikt fra dataene deres. På fritiden liker han å jobbe med ideelle prosjekter, spesielt de som fokuserer på underprivilegerte barns utdanning.
Sekar Srinivasan er en senior spesialistløsningsarkitekt hos AWS med fokus på Big Data og Analytics. Sekar har over 20 års erfaring med å jobbe med data. Han brenner for å hjelpe kunder med å bygge skalerbare løsninger som moderniserer arkitekturen deres og genererer innsikt fra dataene deres. På fritiden liker han å jobbe med ideelle prosjekter, spesielt de som fokuserer på underprivilegerte barns utdanning.
 Prabu Ravichandran er en senior dataarkitekt med Amazon Web Services, fokusert på Analytics, data Lake-arkitektur og implementering. Han hjelper kundene med å bygge og bygge skalerbare og robuste løsninger ved hjelp av AWS-tjenester. På fritiden liker Prabu å reise og tilbringe tid med familien.
Prabu Ravichandran er en senior dataarkitekt med Amazon Web Services, fokusert på Analytics, data Lake-arkitektur og implementering. Han hjelper kundene med å bygge og bygge skalerbare og robuste løsninger ved hjelp av AWS-tjenester. På fritiden liker Prabu å reise og tilbringe tid med familien.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/run-apache-spark-workloads-3-5-times-faster-with-amazon-emr-6-9/
- 1
- 10
- 100
- 1040
- 20 år
- 7
- 9
- a
- I stand
- Om oss
- ovenfor
- adgang
- Logg inn
- la til
- adresse
- råd
- Alle
- allokering
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- analyse
- analytics
- analysere
- og
- Apache
- Apache Spark
- api
- Søknad
- søknader
- arkitektur
- attributter
- gjennomsnittlig
- AVG
- AWS
- Axis
- basert
- tro
- benchmark
- BEST
- beste praksis
- mellom
- Stor
- Store data
- Blokker
- Breakdown
- bygge
- Bygning
- saken
- endring
- Endringer
- avgifter
- Figur
- Cluster
- Kolonne
- kolonner
- Kom
- sammenligne
- sammenligning
- kompatibel
- Beregn
- Konfigurasjon
- Konsoll
- innhold
- Kjerne
- Kostnad
- kostnadsbesparelser
- Kostnader
- skape
- opprettet
- skaper
- Kunder
- dato
- Data Lake
- Dato
- Misligholde
- Avledet
- beskrivelse
- detaljert
- enhet
- gJORDE
- forskjellig
- direkte
- deaktivert
- ikke
- ikke
- nedlasting
- hver enkelt
- øst
- ebs
- Kunnskap
- muliggjøre
- Miljø
- Tilsvarende
- feil
- spesielt
- anslått
- Eter (ETH)
- evaluere
- eksempel
- eksempler
- Øvelse
- erfaring
- familie
- raskere
- Trekk
- filet
- Filer
- Endelig
- Først
- fokuserte
- fokusert
- etter
- formel
- funnet
- Gratis
- fra
- framtid
- inntjening
- genererer
- GitHub
- flott
- Hadoop
- hjelpe
- hjelper
- Horisontal
- TIMER
- Men
- HTML
- HTTPS
- gjennomføring
- forbedring
- forbedringer
- in
- inngang
- innsikt
- f.eks
- instruksjoner
- involvert
- IP
- IP-adresse
- IT
- Jobb
- Hold
- innsjø
- lansere
- LÆRE
- linje
- lokal
- plassering
- maskin
- Making
- leder
- måte
- manuelt
- max
- midler
- Minne
- meldinger
- mer
- navn
- navn
- Naviger
- Trenger
- nødvendig
- behov
- Ny
- neste
- node
- noder
- non-profit
- bemerkelsesverdig
- Antall
- ONE
- åpen kildekode
- optimalisert
- alternativer
- rekkefølge
- Oss
- omriss
- samlet
- lidenskapelig
- Past
- banen
- ytelse
- tillatelser
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- Point
- Pops
- Post
- praksis
- pris
- Prisene
- prising
- primære
- privat
- prosjekter
- gi
- forutsatt
- gir
- rent
- Python
- Rask
- Sats
- realisere
- Redusert
- region
- slipp
- erstatte
- ressurs
- Ressurser
- svar
- restriktiv
- resultere
- Resultater
- robust
- root
- Kjør
- rennende
- samme
- Spar
- Besparelser
- skalerbar
- Skala
- Sekund
- sekunder
- Seksjon
- seksjoner
- senior
- Tjenester
- innstilling
- oppsett
- Shell
- bør
- vist
- Viser
- Enkelt
- SIX
- Størrelse
- Solutions
- kilde
- Spark
- spesialist
- utgifter
- Begynn
- Trinn
- Steps
- lagring
- abonnere
- slik
- SAMMENDRAG
- støtte
- Støtter
- bord
- Ta
- terminal
- test
- tester
- De
- deres
- Gjennom
- tid
- ganger
- tidsstempel
- til
- verktøy
- verktøykasse
- Totalt
- oversette
- Traveling
- underliggende
- underprivilegerte
- us
- bruk
- bruke
- verktøyet
- Verdier
- versjon
- av
- Virginia
- volumer
- web
- webtjenester
- hvilken
- mens
- vil
- uten
- Arbeid
- arbeidstaker
- arbeid
- X
- XML
- yaml
- år
- Din
- zephyrnet