
Bilde fra Adobe Firefly
«Det var for mange av oss. Vi hadde tilgang til for mye penger, for mye utstyr, og litt etter litt ble vi gale.»
Francis Ford Coppola laget ikke en metafor for AI-selskaper som bruker for mye og går seg vill, men han kunne ha vært det. Apokalypse Nå var episk, men også et langt, vanskelig og kostbart prosjekt å lage, omtrent som GPT-4. Jeg vil antyde at utviklingen av LLM-er har tiltrukket seg for mye penger og for mye utstyr. Og noe av "vi har nettopp oppfunnet generell intelligens"-hypen er litt vanvittig. Men nå er det åpen kildekode-fellesskaps tur til å gjøre det de kan best: å levere gratis konkurrerende programvare med langt mindre penger og utstyr.
OpenAI har overtatt 11 milliarder dollar i finansiering og det anslås at GPT-3.5 koster 5-6 millioner dollar per treningsløp. Vi vet veldig lite om GPT-4 fordi OpenAI ikke sier noe, men jeg tror det er trygt å anta at det ikke er mindre enn GPT-3.5. Det er for tiden en verdensomspennende GPU-mangel, og – for en forandring – er det ikke på grunn av den nyeste kryptomynten. Generative AI-start-ups lander $100m+ Series A-runder til enorme verdier når de ikke eier noen av IP-en for LLM de bruker til å drive produktet sitt. LLM-vognen er på høygir og pengene strømmer på.
Det hadde sett ut som terningen var støpt: bare selskaper med dype lommer som Microsoft/OpenAI, Amazon og Google hadde råd til å trene hundre milliarder parametermodeller. Større modeller ble antatt å være bedre modeller. GPT-3 har noe galt? Bare vent til det er en større versjon, så går det bra! Mindre selskaper som ønsket å konkurrere, måtte skaffe langt mer kapital eller bli stående å bygge vareintegrasjoner i ChatGPT-markedet. Akademia, med enda mer begrensede forskningsbudsjetter, ble henvist til sidelinjen.
Heldigvis tok en haug med smarte mennesker og åpen kildekode-prosjekter dette som en utfordring snarere enn en begrensning. Forskere ved Stanford ga ut Alpaca, en 7-milliarder parametermodell hvis ytelse kommer nær GPT-3.5s 175-milliarder parametermodell. I mangel av ressurser til å bygge et treningssett av størrelsen som brukes av OpenAI, valgte de smart å ta en trent åpen kildekode LLM, LLaMA, og finjustere den på en serie GPT-3.5-instruksjoner og utganger i stedet. I hovedsak lærte modellen hva GPT-3.5 gjør, noe som viser seg å være en veldig effektiv strategi for å gjenskape oppførselen.
Alpaca er lisensiert for ikke-kommersiell bruk kun i både kode og data, da den bruker den ikke-kommersielle LLaMA-modellen med åpen kildekode, og OpenAI tillater eksplisitt all bruk av API-ene for å lage konkurrerende produkter. Det skaper de fristende mulighetene for å finjustere en annen åpen kildekode LLM på ledetekster og utdata fra Alpaca ... å skape en tredje GPT-3.5-lignende modell med forskjellige lisensieringsmuligheter.
Det er et annet lag med ironi her, ved at alle de store LLM-ene ble opplært på opphavsrettsbeskyttet tekst og bilder tilgjengelig på Internett, og de betalte ikke en krone til rettighetshaverne. Selskapene hevder "fair use"-unntaket under amerikansk opphavsrettslovgivning med argumentet om at bruken er "transformativ". Men når det kommer til produksjonen av modellene de bygger med gratis data, vil de virkelig ikke at noen skal gjøre det samme med dem. Jeg regner med at dette vil endre seg etter hvert som rettighetshaverne lurer på det, og kan havne i retten på et tidspunkt.
Dette er et eget og distinkt poeng fra det som ble reist av forfattere av restriktiv lisensiert åpen kildekode som, for generativ AI for kodeprodukter som CoPilot, motsetter seg at koden deres brukes til opplæring med den begrunnelse at lisensen ikke blir fulgt. Problemet for individuelle forfattere med åpen kildekode er at de må vise standpunkt – reell kopiering – og at de har pådratt seg skader. Og siden modellene gjør det vanskelig å koble utgangskode til input (linjene med kildekode av forfatteren) og det ikke er noe økonomisk tap (det er ment å være gratis), er det langt vanskeligere å lage en sak. Dette er i motsetning til for-profit-skapere (f.eks. fotografer) hvis hele forretningsmodellen er å lisensiere/selge arbeidet deres, og som er representert av aggregatorer som Getty Images som kan vise reell kopiering.
En annen interessant ting med LLaMA er at den kom ut av Meta. Det ble opprinnelig gitt ut bare til forskere og deretter lekket ut via BitTorrent til verden. Meta er i en fundamentalt annerledes virksomhet enn OpenAI, Microsoft, Google og Amazon ved at den ikke prøver å selge deg skytjenester eller programvare, og har derfor svært forskjellige insentiver. Den har åpnet databehandlingsdesignene sine tidligere (OpenCompute) og sett fellesskapet forbedre seg på dem – den forstår verdien av åpen kildekode.
Meta kan vise seg å være en av de viktigste åpen kildekode AI-bidragsyterne. Ikke bare har det enorme ressurser, men det er fordelaktig hvis det er en spredning av stor generativ AI-teknologi: det vil være mer innhold for å tjene penger på sosiale medier. Meta har gitt ut tre andre åpen kildekode AI-modeller: ImageBind (flerdimensjonal dataindeksering), DINOv2 (datasyn) og Segment Anything. Sistnevnte identifiserer unike objekter i bilder og utgis under den svært tillatelige Apache-lisensen.
Til slutt hadde vi også den påståtte lekkasje av et internt Google-dokument «We Have No Moat, and Heller Does OpenAI» som tar et svakt syn på lukkede modeller kontra innovasjonen av samfunn som produserer langt mindre, billigere modeller som yter nær eller bedre enn deres motparter med lukket kilde. Jeg sier angivelig fordi det ikke er noen måte å bekrefte kilden til artikkelen som intern Google. Imidlertid inneholder den denne overbevisende grafen:
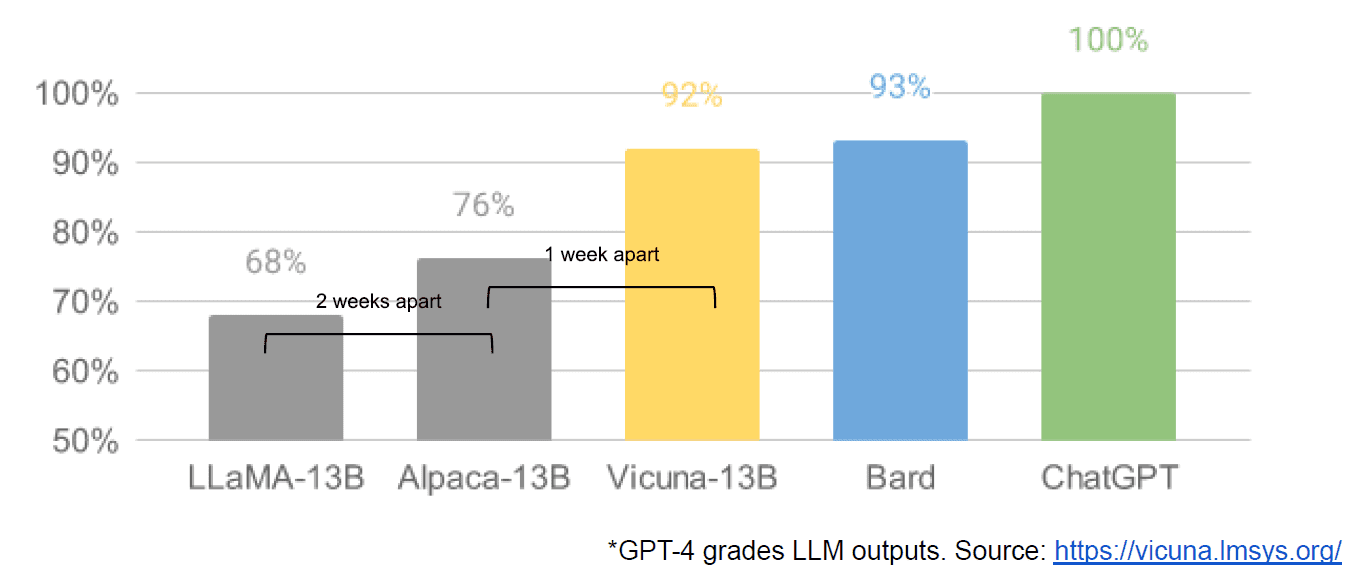
Den vertikale aksen er graderingen av LLM-utgangene av GPT-4, for å være tydelig.
Stable Diffusion, som syntetiserer bilder fra tekst, er et annet eksempel på hvor åpen kildekode generativ AI har vært i stand til å avansere raskere enn proprietære modeller. En nylig gjentakelse av det prosjektet (ControlNet) har forbedret det slik at det har overgått Dall-E2s evner. Dette kom fra en hel masse fiksing over hele verden, noe som resulterte i et fremskritt som er vanskelig for en enkelt institusjon å matche. Noen av disse tinkererne fant ut hvordan de kunne gjøre Stable Diffusion raskere å trene og kjøre på billigere maskinvare, noe som muliggjorde kortere iterasjonssykluser av flere mennesker.
Og dermed har vi kommet hele sirkelen. Å ikke ha for mye penger og for mye utstyr har inspirert et utspekulert nivå av innovasjon hos et helt fellesskap av vanlige mennesker. For en tid å være en AI-utvikler.
Mathew Lodge er administrerende direktør i Diffblue, en AI For Code-oppstart. Han har 25+ års mangfoldig erfaring innen produktledelse i selskaper som Anaconda og VMware. Lodge sitter for tiden i styret for Good Law Project og er nestleder i Board of Trustees i Royal Photographic Society.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoAiStream. Web3 Data Intelligence. Kunnskap forsterket. Tilgang her.
- Minting the Future med Adryenn Ashley. Tilgang her.
- Kjøp og selg aksjer i PRE-IPO-selskaper med PREIPO®. Tilgang her.
- kilde: https://www.kdnuggets.com/2023/05/llm-apocalypse-revenge-open-source-clones.html?utm_source=rss&utm_medium=rss&utm_campaign=llm-apocalypse-now-revenge-of-the-open-source-clones
- : har
- :er
- :ikke
- :hvor
- $OPP
- 9
- a
- I stand
- Om oss
- Academia
- adgang
- Adobe
- avansere
- aggregat
- AI
- Alle
- påstått
- angivelig
- også
- Amazon
- an
- og
- En annen
- noen
- noen
- hva som helst
- Apache
- APIer
- ER
- argument
- Artikkel
- AS
- antatt
- At
- forfatter
- forfattere
- tilgjengelig
- Axis
- BE
- fordi
- vært
- være
- Fordeler
- BEST
- Bedre
- større
- BitTorrent
- borde
- både
- Budsjetter
- bygge
- Bygning
- Bunch
- virksomhet
- forretningsmodell
- men
- by
- kom
- CAN
- evner
- hovedstad
- saken
- konsernsjef
- Chair
- utfordre
- endring
- ChatGPT
- billigere
- valgte
- Circle
- hevder
- fjerne
- Lukke
- stengt
- Cloud
- skytjenester
- kode
- Kom
- kommer
- handelsvare
- Communities
- samfunnet
- Selskaper
- overbevisende
- konkurrere
- konkurrerende
- Beregn
- datamaskin
- Datamaskin syn
- innhold
- bidragsytere
- kopiering
- copyright
- Kostnader
- kunne
- Court
- skape
- Opprette
- skaperne
- kryptokoin
- I dag
- sykluser
- dato
- levere
- nestleder
- design
- Utvikler
- Utvikling
- Die
- forskjellig
- vanskelig
- kringkasting
- distinkt
- diverse
- do
- dokument
- gjør
- ikke
- e
- økonomisk
- Effektiv
- muliggjør
- slutt
- Hele
- EPIC
- utstyr
- hovedsak
- anslått
- Selv
- eksempel
- forvente
- dyrt
- erfaring
- langt
- raskere
- tenkte
- Rennende
- fulgt
- Til
- Ford
- Gratis
- fra
- fullt
- fundamentalt
- finansiering
- Gear
- general
- generative
- Generativ AI
- god
- GPU
- graf
- flott
- HAD
- Hard
- maskinvare
- Ha
- å ha
- he
- her.
- Høy
- svært
- holdere
- Hvordan
- Hvordan
- Men
- HTTPS
- stort
- Hype
- i
- identifiserer
- if
- bilder
- viktig
- forbedre
- forbedret
- in
- Incentiver
- individuelt
- Innovasjon
- inngang
- SINNSYK
- inspirert
- i stedet
- Institusjon
- integrasjoner
- interessant
- intern
- Internet
- Oppfunnet
- IP
- ironi
- IT
- køyring
- DET ER
- bare
- KDnuggets
- Vet
- landing
- siste
- Law
- lag
- Ledelse
- lært
- venstre
- mindre
- Nivå
- Tillatelse
- Licensed
- Lisensiering
- i likhet med
- linjer
- LINK
- lite
- Llama
- Lang
- så
- ser
- taper
- tap
- Lot
- større
- gjøre
- Making
- mange
- markedsplass
- massive
- Match
- Kan..
- Media
- Meta
- Microsoft
- modell
- modeller
- tjene penger
- penger
- mer
- mest
- mye
- Trenger
- Ingen
- Nei.
- ikke-kommersielt
- nå
- objekt
- gjenstander
- of
- on
- ONE
- bare
- åpen
- åpen kildekode
- open source prosjekter
- OpenAI
- or
- vanlig
- opprinnelig
- Annen
- ut
- produksjon
- enn
- egen
- Fred
- parameter
- Past
- Betale
- Ansatte
- utføre
- ytelse
- plato
- Platon Data Intelligence
- PlatonData
- Point
- muligheter
- makt
- Problem
- Produkt
- Produkter
- prosjekt
- prosjekter
- proprietær
- prospektet
- heve
- hevet
- heller
- virkelig
- nylig
- utgitt
- representert
- forskning
- forskere
- Ressurser
- begrensning
- resulterende
- rettigheter
- runder
- kongelig
- Kjør
- s
- trygge
- samme
- sier
- sett
- segmentet
- selger
- separat
- Serien
- Serie A
- serverer
- Tjenester
- sett
- mangel
- Vis
- siden
- enkelt
- Størrelse
- mindre
- Smart
- So
- selskap
- sosiale medier
- Samfunnet
- Software
- noen
- noe
- kilde
- kildekoden
- bruke
- stabil
- stanford
- start-ups
- oppstart
- Strategi
- slik
- foreslår
- ment
- gått
- Ta
- tatt
- tar
- Teknologi
- enn
- Det
- De
- Kilden
- verden
- deres
- Dem
- deretter
- Der.
- de
- ting
- tror
- Tredje
- denne
- De
- tre
- tid
- til
- også
- tok
- Tog
- trent
- Kurs
- SVING
- snur
- etter
- forstår
- unik
- I motsetning til
- til
- us
- bruke
- brukt
- bruker
- ved hjelp av
- verdivurdering
- verdi
- verifisere
- versjon
- vertikal
- veldig
- av
- Se
- syn
- VMware
- vs
- vente
- ønsker
- var
- Vei..
- we
- gikk
- var
- Hva
- når
- hvilken
- HVEM
- hele
- hvem sin
- vil
- KLOK
- med
- Arbeid
- verden
- Feil
- du
- zephyrnet









