Forskere fortsetter å utvikle nye modellarkitekturer for vanlige maskinlæringsoppgaver (ML). En slik oppgave er bildeklassifisering, der bilder aksepteres som input og modellen forsøker å klassifisere bildet som en helhet med objektetikettutganger. Med mange tilgjengelige modeller i dag som utfører denne bildeklassifiseringsoppgaven, kan en ML-utøver stille spørsmål som: "Hvilken modell bør jeg finjustere og deretter distribuere for å oppnå best ytelse på datasettet mitt?" Og en ML-forsker kan stille spørsmål som: "Hvordan kan jeg generere min egen rettferdige sammenligning av flere modellarkitekturer mot et spesifisert datasett mens jeg kontrollerer treningshyperparametre og datamaskinspesifikasjoner, som GPUer, CPUer og RAM?" Det førstnevnte spørsmålet tar for seg modellvalg på tvers av modellarkitekturer, mens det siste spørsmålet gjelder benchmarking av trente modeller mot et testdatasett.
I dette innlegget vil du se hvordan TensorFlow bildeklassifisering algoritme av Amazon SageMaker JumpStart kan forenkle implementeringene som kreves for å løse disse spørsmålene. Sammen med gjennomføringen detaljer i en tilsvarende eksempel Jupyter notatbok, vil du ha verktøy tilgjengelig for å utføre modellvalg ved å utforske pareto-grenser, der det ikke er mulig å forbedre én ytelsesverdi, for eksempel nøyaktighet, uten å forverre en annen beregning, for eksempel gjennomstrømning.
Løsningsoversikt
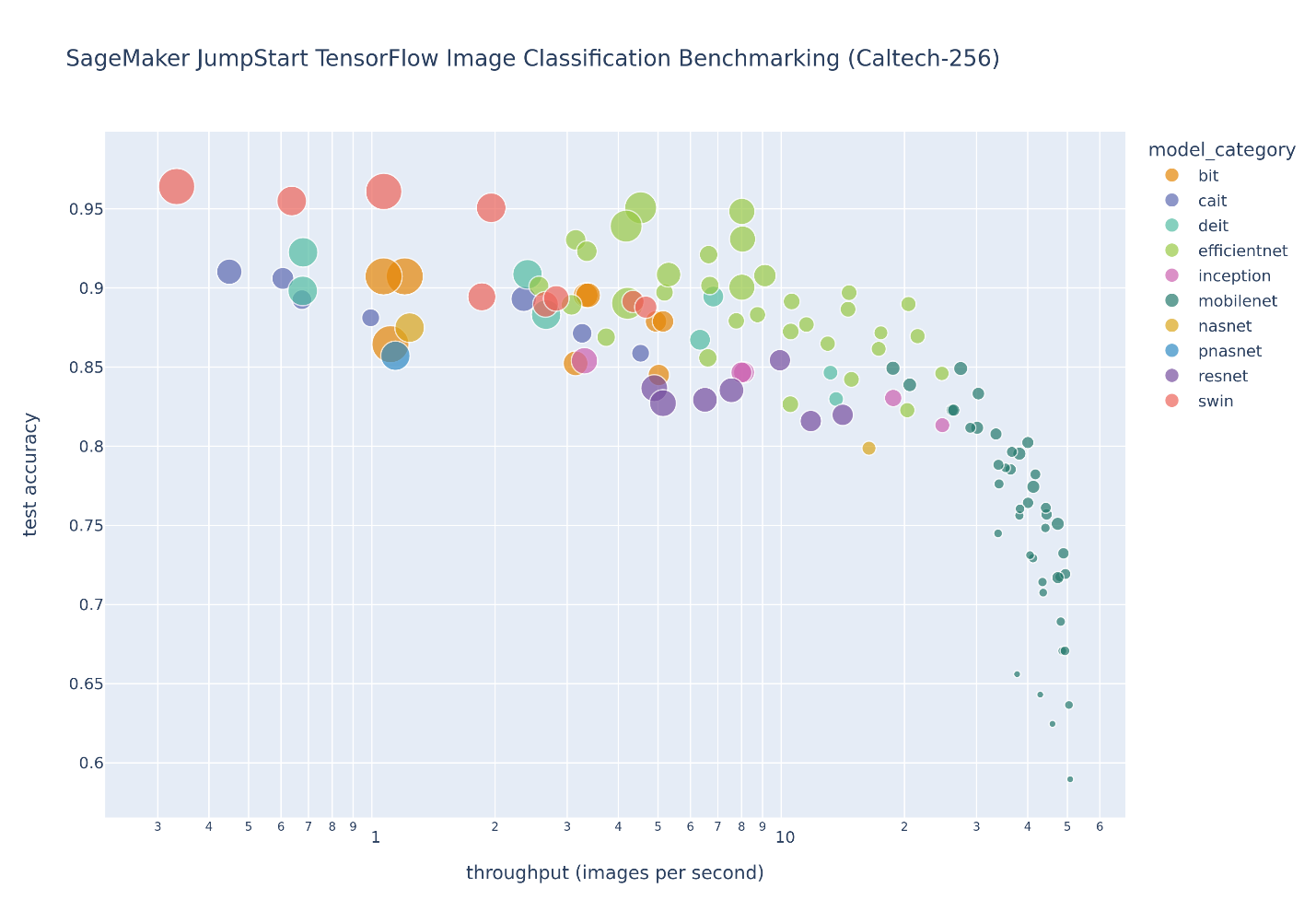
Følgende figur illustrerer avveiningen av modellvalg for et stort antall bildeklassifiseringsmodeller finjustert på Caltech-256 datasett, som er et utfordrende sett med 30,607 256 bilder fra den virkelige verden som spenner over XNUMX objektkategorier. Hvert punkt representerer en enkelt modell, punktstørrelser skaleres med hensyn til antall parametere som utgjør modellen, og punktene er fargekodet basert på deres modellarkitektur. For eksempel representerer de lysegrønne punktene EfficientNet-arkitekturen; hvert lysegrønne punkt er en annen konfigurasjon av denne arkitekturen med unike finjusterte modellytelsesmålinger. Figuren viser eksistensen av en pareto-grense for modellvalg, hvor høyere nøyaktighet byttes ut med lavere gjennomstrømning. Til syvende og sist avhenger valget av en modell langs pareto-grensen, eller settet med pareto-effektive løsninger, av ytelseskravene for modelldistribusjon.
Hvis du observerer testnøyaktighet og tester gjennomstrømningsgrenser av interesse, trekkes settet med pareto-effektive løsninger på den foregående figuren ut i følgende tabell. Rader er sortert slik at testgjennomstrømningen øker og testnøyaktigheten avtar.
| Modellnavn | Antall parametere | Test nøyaktighet | Test Topp 5-nøyaktighet | Gjennomstrømning (bilder/er) | Varighet per epoke(r) |
| swin-large-patch4-window12-384 | 195.6M | 96.4% | 99.5% | 0.3 | 2278.6 |
| swin-large-patch4-window7-224 | 195.4M | 96.1% | 99.5% | 1.1 | 698.0 |
| efficientnet-v2-imagenet21k-ft1k-l | 118.1M | 95.1% | 99.2% | 4.5 | 1434.7 |
| efficientnet-v2-imagenet21k-ft1k-m | 53.5M | 94.8% | 99.1% | 8.0 | 769.1 |
| efficientnet-v2-imagenet21k-m | 53.5M | 93.1% | 98.5% | 8.0 | 765.1 |
| efficientnet-b5 | 29.0M | 90.8% | 98.1% | 9.1 | 668.6 |
| efficientnet-v2-imagenet21k-ft1k-b1 | 7.3M | 89.7% | 97.3% | 14.6 | 54.3 |
| efficientnet-v2-imagenet21k-ft1k-b0 | 6.2M | 89.0% | 97.0% | 20.5 | 38.3 |
| efficientnet-v2-imagenet21k-b0 | 6.2M | 87.0% | 95.6% | 21.5 | 38.2 |
| mobilenet-v3-large-100-224 | 4.6M | 84.9% | 95.4% | 27.4 | 28.8 |
| mobilenet-v3-large-075-224 | 3.1M | 83.3% | 95.2% | 30.3 | 26.6 |
| mobilenet-v2-100-192 | 2.6M | 80.8% | 93.5% | 33.5 | 23.9 |
| mobilenet-v2-100-160 | 2.6M | 80.2% | 93.2% | 40.0 | 19.6 |
| mobilenet-v2-075-160 | 1.7M | 78.2% | 92.8% | 41.8 | 19.3 |
| mobilenet-v2-075-128 | 1.7M | 76.1% | 91.1% | 44.3 | 18.3 |
| mobilenet-v1-075-160 | 2.0M | 75.7% | 91.0% | 44.5 | 18.2 |
| mobilenet-v1-100-128 | 3.5M | 75.1% | 90.7% | 47.4 | 17.4 |
| mobilenet-v1-075-128 | 2.0M | 73.2% | 90.0% | 48.9 | 16.8 |
| mobilenet-v2-075-96 | 1.7M | 71.9% | 88.5% | 49.4 | 16.6 |
| mobilenet-v2-035-96 | 0.7M | 63.7% | 83.1% | 50.4 | 16.3 |
| mobilenet-v1-025-128 | 0.3M | 59.0% | 80.7% | 50.8 | 16.2 |
Dette innlegget gir detaljer om hvordan du implementerer storskala Amazon SageMaker benchmarking og modellvalgoppgaver. Først introduserer vi JumpStart og de innebygde TensorFlow-bildeklassifiseringsalgoritmene. Vi diskuterer deretter implementeringshensyn på høyt nivå, for eksempel JumpStart hyperparameterkonfigurasjoner, metrisk utvinning fra Amazon CloudWatch-logger, og lanserer asynkrone hyperparameterjusteringsjobber. Til slutt dekker vi implementeringsmiljøet og parameteriseringen som fører til de pareto-effektive løsningene i den foregående tabellen og figuren.
Introduksjon til JumpStart TensorFlow bildeklassifisering
JumpStart gir ett-klikks finjustering og distribusjon av et bredt utvalg av forhåndstrente modeller på tvers av populære ML-oppgaver, samt et utvalg ende-til-ende-løsninger som løser vanlige forretningsproblemer. Disse funksjonene fjerner de tunge løftene fra hvert trinn i ML-prosessen, noe som gjør det enklere å utvikle høykvalitetsmodeller og reduserer tiden til utrulling. De JumpStart APIer lar deg programmere distribuere og finjustere et stort utvalg av forhåndstrente modeller på dine egne datasett.
JumpStart-modellhuben gir tilgang til et stort antall TensorFlow bildeklassifiseringsmodeller som muliggjør overføringslæring og finjustering på tilpassede datasett. Når dette skrives, inneholder JumpStart modellhub 135 TensorFlow bildeklassifiseringsmodeller på tvers av en rekke populære modellarkitekturer fra TensorFlow Hub, for å inkludere gjenværende nettverk (ResNet), MobileNet, Effektivt nett, Inception, Neural Architecture Search Networks (NASNet), Stor overføring (Bit), forskjøvet vindu (Svin) transformatorer, klasseoppmerksomhet i bildetransformatorer (CaiT), og dataeffektive bildetransformatorer (DeiT).
Meget forskjellige interne strukturer omfatter hver modellarkitektur. For eksempel bruker ResNet-modeller hoppkoblinger for å tillate vesentlig dypere nettverk, mens transformatorbaserte modeller bruker selvoppmerksomhetsmekanismer som eliminerer den iboende lokaliteten til konvolusjonsoperasjoner til fordel for mer globale mottakelige felt. I tillegg til de forskjellige funksjonssettene disse forskjellige strukturene gir, har hver modellarkitektur flere konfigurasjoner som justerer modellstørrelsen, formen og kompleksiteten i den arkitekturen. Dette resulterer i hundrevis av unike bildeklassifiseringsmodeller tilgjengelig på JumpStart-modellhuben. Kombinert med innebygd overføringslæring og inferensskript som omfatter mange SageMaker-funksjoner, er JumpStart API et flott startpunkt for ML-utøvere for å komme raskt i gang med opplæring og distribusjon av modeller.
Referere til Overfør læring for TensorFlow bildeklassifiseringsmodeller i Amazon SageMaker og følgende eksempel notisbok for å lære om SageMaker TensorFlow bildeklassifisering i mer dybde, inkludert hvordan du kjører slutninger på en forhåndstrent modell samt finjusterer den forhåndstrente modellen på et tilpasset datasett.
Storskala modellvalg
Modellvalg er prosessen med å velge den beste modellen fra et sett med kandidatmodeller. Denne prosessen kan brukes på tvers av modeller av samme type med forskjellige parametervekter og på tvers av modeller av forskjellige typer. Eksempler på modellvalg på tvers av modeller av samme type inkluderer å tilpasse samme modell med forskjellige hyperparametre (for eksempel læringshastighet) og tidlig stopp for å forhindre overtilpasning av modellvekter til togdatasettet. Modellvalg på tvers av modeller av forskjellige typer inkluderer å velge den beste modellarkitekturen (for eksempel Swin vs. MobileNet) og velge de beste modellkonfigurasjonene innenfor en enkelt modellarkitektur (f.eks. mobilenet-v1-025-128 vs mobilenet-v3-large-100-224).
Betraktningene skissert i denne delen muliggjør alle disse modellvalgprosessene på et valideringsdatasett.
Velg hyperparameterkonfigurasjoner
TensorFlow bildeklassifisering i JumpStart har et stort antall tilgjengelige hyperparametere som kan justere overføringslæringsskriptatferden ensartet for alle modellarkitekturer. Disse hyperparametrene er relatert til dataforsterkning og -forbehandling, optimeringsspesifikasjon, overtilpasningskontroller og trenbare lagindikatorer. Du oppfordres til å justere standardverdiene for disse hyperparametrene etter behov for applikasjonen din:
For denne analysen og den tilhørende notatboken er alle hyperparametre satt til standardverdier bortsett fra læringshastighet, antall epoker og spesifikasjoner for tidlig stopp. Læringshastighet justeres som en kategorisk parameter ved SageMaker automatisk modellinnstilling jobb. Fordi hver modell har unike standard hyperparameterverdier, inkluderer den diskrete listen over mulige læringsrater standard læringshastighet samt en femtedel av standard læringshastighet. Dette starter to treningsjobber for én enkelt hyperparameterjusteringsjobb, og treningsjobben med best rapportert ytelse på valideringsdatasettet velges. Fordi antall epoker er satt til 10, som er større enn standard hyperparameterinnstilling, samsvarer ikke alltid den valgte beste treningsjobben med standard læringshastighet. Til slutt brukes et tidlig stoppkriterium med en tålmodighet, eller antall epoker for å fortsette treningen uten forbedring, på tre epoker.
En standard hyperparameterinnstilling av spesiell betydning er train_only_on_top_layer, hvor, hvis satt til True, er modellens funksjonsekstraksjonslag ikke finjustert på det medfølgende opplæringsdatasettet. Optimalisatoren vil kun trene parametere i det øverste fullt tilkoblede klassifiseringslaget med utdatadimensjonalitet lik antall klasseetiketter i datasettet. Som standard er denne hyperparameteren satt til True, som er en innstilling rettet mot overføringslæring på små datasett. Du kan ha et tilpasset datasett der funksjonsuttaket fra forhåndsopplæringen på ImageNet-datasettet ikke er tilstrekkelig. I disse tilfellene bør du angi train_only_on_top_layer til False. Selv om denne innstillingen vil øke treningstiden, vil du trekke ut mer meningsfulle funksjoner for problemet du er interessert i, og dermed øke nøyaktigheten.
Trekk ut beregninger fra CloudWatch-logger
JumpStart TensorFlow bildeklassifiseringsalgoritmen logger pålitelig en rekke beregninger under trening som er tilgjengelige for SageMaker Estimator og HyperparameterTuner-objekter. Konstruktøren av en SageMaker Estimator har en metric_definitions nøkkelordargument, som kan brukes til å evaluere treningsjobben ved å gi en liste over ordbøker med to nøkler: Navn for navnet på metrikken, og Regex for det regulære uttrykket som brukes til å trekke ut beregningen fra loggene. Den medfølgende bærbare viser implementeringsdetaljene. Tabellen nedenfor viser tilgjengelige beregninger og tilhørende regulære uttrykk for alle JumpStart TensorFlow-bildeklassifiseringsmodeller.
| Metrisk navn | Regular Expression |
| antall parametere | "- Antall parametere: ([0-9\.]+)" |
| antall trenbare parametere | "- Antall trenbare parametere: ([0-9\.]+)" |
| antall ikke trenbare parametere | "- Antall parametere som ikke kan trenes: ([0-9\.]+)" |
| metrikk for togdatasett | f"- {metrisk}: ([0-9\.]+)" |
| valideringsdatasettmetrikk | f"- val_{metrisk}: ([0-9\.]+)" |
| test datasett metrikk | f"- Test {metrisk}: ([0-9\.]+)" |
| togets varighet | "- Total treningsvarighet: ([0-9\.]+)" |
| togvarighet per epoke | "- Gjennomsnittlig treningsvarighet per epoke: ([0-9\.]+)" |
| latens for testevaluering | "- Testevalueringsforsinkelse: ([0-9\.]+)" |
| testlatens per prøve | "- Gjennomsnittlig testforsinkelse per prøve: ([0-9\.]+)" |
| testgjennomstrømning | "- Gjennomsnittlig testgjennomstrømning: ([0-9\.]+)" |
Det innebygde overføringslæringsskriptet gir en rekke trenings-, validerings- og testdatasettberegninger innenfor disse definisjonene, som representert av f-strengerstatningsverdiene. De eksakte beregningene som er tilgjengelige varierer basert på typen klassifisering som utføres. Alle kompilerte modeller har en loss metrisk, som er representert ved et kryssentropitap for enten et binært eller kategorisk klassifiseringsproblem. Førstnevnte brukes når det er én klasseetikett; sistnevnte brukes hvis det er to eller flere klasseetiketter. Hvis det bare er en enkelt klasseetikett, beregnes, logges og trekkes følgende beregninger ut via f-strengen regulære uttrykk i den foregående tabellen: antall sanne positive (true_pos), antall falske positive (false_pos), antall sanne negative (true_neg), antall falske negativer (false_neg), precision, recall, område under mottakerens driftskarakteristikk (ROC) kurve (auc), og området under presisjonsgjenkallingskurven (PR) (prc). Tilsvarende, hvis det er seks eller flere klasseetiketter, en topp-5 nøyaktighetsberegning (top_5_accuracy) kan også beregnes, logges og pakkes ut via de foregående regulære uttrykkene.
Under trening spesifiserte beregninger til en SageMaker Estimator sendes ut til CloudWatch-logger. Når opplæringen er fullført, kan du påkalle SageMaker DescribeTrainingJob API og inspiser FinalMetricDataList tast inn JSON-svaret:
Denne APIen krever at bare jobbnavnet oppgis til spørringen, så når den er fullført, kan beregninger innhentes i fremtidige analyser så lenge opplæringsjobbnavnet er riktig logget og kan gjenopprettes. For denne modellvalgoppgaven lagres jobbnavn for hyperparameterinnstilling og påfølgende analyser kobler til en HyperparameterTuner objekt gitt tuning jobbnavnet, trekk ut det beste treningsjobbnavnet fra den vedlagte hyperparametertuneren, og start deretter DescribeTrainingJob API som beskrevet tidligere for å få målinger knyttet til den beste treningsjobben.
Start asynkrone hyperparameterjusteringsjobber
Se tilsvarende bærbare for implementeringsdetaljer om asynkron lansering av hyperparameterjusteringsjobber, som bruker Python-standardbibliotekets samtidige futures modul, et høynivågrensesnitt for asynkront kjøring av callables. Flere SageMaker-relaterte hensyn er implementert i denne løsningen:
- Hver AWS-konto er tilknyttet SageMaker tjenestekvoter. Du bør se dine nåværende grenser for å utnytte ressursene dine fullt ut og potensielt be om økning av ressursgrensene etter behov.
- Hyppige API-kall for å lage mange samtidige hyperparameterjusteringsjobber kan overskride Python SDK-hastigheten og gi struping-unntak. En løsning på dette er å lage en SageMaker Boto3-klient med en tilpasset konfigurasjon for forsøk på nytt.
- Hva skjer hvis skriptet ditt støter på en feil eller skriptet stoppes før det er fullført? For et så stort modellutvalg eller benchmarking-studie kan du logge tuning jobbnavn og tilby bekvemmelighetsfunksjoner til koble til hyperparameterinnstillingsjobber på nytt som allerede eksisterer:
Analysedetaljer og diskusjon
Analysen i dette innlegget utfører overføringslæring for modell IDer i JumpStart TensorFlow bildeklassifiseringsalgoritmen på Caltech-256-datasettet. Alle treningsjobber ble utført på SageMaker-treningsinstansen ml.g4dn.xlarge, som inneholder en enkelt NVIDIA T4 GPU.
Testdatasettet blir evaluert på treningsforekomsten ved slutten av opplæringen. Modellvalg utføres før testdatasettet-evalueringen for å sette modellvekter til epoken med best valideringssettytelse. Testgjennomstrømningen er ikke optimalisert: datasettet batchstørrelsen er satt til standard treningshyperparameter batchstørrelse, som ikke er justert for å maksimere GPU-minnebruken; rapportert testgjennomstrømning inkluderer datainnlastingstid fordi datasettet ikke er forhåndsbufret; og distribuert slutning på tvers av flere GPUer brukes ikke. Av disse grunnene er denne gjennomstrømningen en god relativ måling, men faktisk gjennomstrømning vil i stor grad avhenge av konfigurasjonene for endepunktdistribusjon for den trente modellen.
Selv om JumpStart-modellhuben inneholder mange bildeklassifiseringsarkitekturtyper, domineres denne pareto-grensen av utvalgte Swin-, EfficientNet- og MobileNet-modeller. Swin-modeller er større og relativt mer nøyaktige, mens MobileNet-modeller er mindre, relativt mindre nøyaktige og egnet for ressursbegrensninger for mobile enheter. Det er viktig å merke seg at denne grensen er betinget av en rekke faktorer, inkludert det eksakte datasettet som brukes og de valgte finjusteringshyperparametrene. Du kan oppleve at det tilpassede datasettet ditt produserer et annet sett med pareto-effektive løsninger, og du kan ønske deg lengre treningstider med forskjellige hyperparametre, for eksempel mer dataforsterkning eller finjustering av mer enn bare det øverste klassifiseringslaget i modellen.
konklusjonen
I dette innlegget viste vi hvordan du kjører storskala modellvalg eller benchmarking-oppgaver ved å bruke JumpStart-modellhuben. Denne løsningen kan hjelpe deg å velge den beste modellen for dine behov. Vi oppfordrer deg til å prøve ut og utforske dette løsning på ditt eget datasett.
Referanser
Mer informasjon er tilgjengelig på følgende ressurser:
Om forfatterne
 Dr. Kyle Ulrich er en anvendt vitenskapsmann med Amazon SageMaker innebygde algoritmer team. Hans forskningsinteresser inkluderer skalerbare maskinlæringsalgoritmer, datasyn, tidsserier, Bayesianske ikke-parametriske og Gaussiske prosesser. Hans doktorgrad er fra Duke University og han har publisert artikler i NeurIPS, Cell og Neuron.
Dr. Kyle Ulrich er en anvendt vitenskapsmann med Amazon SageMaker innebygde algoritmer team. Hans forskningsinteresser inkluderer skalerbare maskinlæringsalgoritmer, datasyn, tidsserier, Bayesianske ikke-parametriske og Gaussiske prosesser. Hans doktorgrad er fra Duke University og han har publisert artikler i NeurIPS, Cell og Neuron.
 Dr. Ashish Khetan er Senior Applied Scientist med Amazon SageMaker innebygde algoritmer og hjelper til med å utvikle maskinlæringsalgoritmer. Han fikk sin doktorgrad fra University of Illinois Urbana Champaign. Han er en aktiv forsker innen maskinlæring og statistisk inferens og har publisert mange artikler i NeurIPS, ICML, ICLR, JMLR, ACL og EMNLP-konferanser.
Dr. Ashish Khetan er Senior Applied Scientist med Amazon SageMaker innebygde algoritmer og hjelper til med å utvikle maskinlæringsalgoritmer. Han fikk sin doktorgrad fra University of Illinois Urbana Champaign. Han er en aktiv forsker innen maskinlæring og statistisk inferens og har publisert mange artikler i NeurIPS, ICML, ICLR, JMLR, ACL og EMNLP-konferanser.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/image-classification-model-selection-using-amazon-sagemaker-jumpstart/
- 10
- 100
- 9
- a
- Om oss
- adgang
- tilgjengelig
- Logg inn
- nøyaktighet
- nøyaktig
- Oppnå
- tvers
- aktiv
- tillegg
- adresse
- adresser
- justert
- Tilknyttet
- mot
- algoritme
- algoritmer
- Alle
- allerede
- Selv
- alltid
- Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- analyse
- og
- En annen
- api
- Søknad
- anvendt
- hensiktsmessig
- arkitektur
- AREA
- argument
- assosiert
- feste
- forsøk
- Automatisk
- tilgjengelig
- gjennomsnittlig
- AWS
- basert
- Bayesiansk
- fordi
- før du
- være
- BEST
- Stor
- innebygd
- virksomhet
- Samtaler
- kandidat
- saker
- kategorier
- utfordrende
- karakteristisk
- Velg
- klasse
- klassifisering
- Klassifisere
- kunde
- kombinert
- Felles
- sammenligning
- fullføre
- Terminado
- ferdigstillelse
- kompleksitet
- datamaskin
- Datamaskin syn
- bekymringer
- konferanser
- Konfigurasjon
- tilkoblet
- Tilkoblinger
- betraktninger
- begrensninger
- inneholder
- fortsette
- kontrollerende
- kontroller
- bekvemmelighet
- Tilsvarende
- dekke
- skape
- Gjeldende
- skjøger
- skikk
- dato
- datasett
- dypere
- Misligholde
- avhenger
- utplassere
- utplasserings
- distribusjon
- dybde
- beskrevet
- beskrivelse
- detaljer
- utvikle
- Enheter
- forskjellig
- diskutere
- distribueres
- diverse
- ikke
- Duke
- duke universitetet
- under
- hver enkelt
- Tidligere
- Tidlig
- enklere
- effektiv
- enten
- eliminere
- muliggjøre
- oppmuntre
- oppfordret
- ende til ende
- Endpoint
- Miljø
- epoke
- epoker
- feil
- Eter (ETH)
- evaluere
- evaluert
- evaluering
- eksempel
- eksempler
- Unntatt
- utforske
- Utforske
- uttrykkene
- trekke ut
- utdrag
- faktorer
- rettferdig
- favorisere
- Trekk
- Egenskaper
- Felt
- Figur
- Endelig
- Finn
- Først
- fitting
- etter
- Tidligere
- fra
- Frontier
- Frontiers
- fullt
- funksjoner
- framtid
- Futures
- generere
- få
- gitt
- Global
- god
- GPU
- GPU
- flott
- større
- Grønn
- skjer
- tungt
- hjelpe
- hjelper
- høyt nivå
- høykvalitets
- høyere
- Hvordan
- Hvordan
- HTML
- HTTPS
- Hub
- Hundrevis
- Innstilling av hyperparameter
- ICLR
- Illinois
- bilde
- Bildeklassifisering
- IMAGEnet
- bilder
- iverksette
- gjennomføring
- implementert
- betydning
- viktig
- forbedring
- bedre
- in
- inkludere
- inkluderer
- Inkludert
- Øke
- øker
- økende
- indikatorer
- informasjon
- inngang
- f.eks
- interesse
- interesser
- Interface
- intern
- egenverdi
- introdusere
- IT
- Jobb
- Jobb
- JSON
- nøkkel
- nøkler
- Etiketten
- etiketter
- stor
- storskala
- større
- Ventetid
- lanseringer
- lansere
- lag
- lag
- ledende
- LÆRE
- læring
- løfte
- lett
- BEGRENSE
- grenser
- Liste
- lister
- lasting
- Lang
- lenger
- tap
- maskin
- maskinlæring
- Making
- mange
- Maksimer
- meningsfylt
- målinger
- Minne
- metrisk
- Metrics
- ML
- Mobil
- håndholdte enheter
- modell
- modeller
- moduler
- mer
- flere
- navn
- navn
- nødvendig
- nødvendig
- behov
- nettverk
- neural
- NeurIPS
- Ny
- bærbare
- Antall
- Nvidia
- objekt
- gjenstander
- observere
- få
- innhentet
- ONE
- drift
- Drift
- optimalisert
- skissert
- egen
- papirer
- parameter
- parametere
- Spesielt
- Tålmodighet
- utføre
- ytelse
- utfører
- plato
- Platon Data Intelligence
- PlatonData
- Point
- poeng
- Populær
- mulig
- Post
- potensielt
- pr
- forebygge
- Før
- Problem
- problemer
- prosess
- Prosesser
- gi
- forutsatt
- gir
- gi
- publisert
- Python
- spørsmål
- spørsmål
- raskt
- RAM
- Sats
- priser
- virkelige verden
- grunner
- redusere
- regelmessig
- relativt
- fjerne
- rapportert
- representere
- representert
- representerer
- anmode
- påkrevd
- Krav
- Krever
- forskning
- forsker
- oppløsning
- ressurs
- Ressurser
- svar
- Resultater
- Kjør
- rennende
- sagemaker
- samme
- skalerbar
- Forsker
- skript
- SDK
- Søk
- Seksjon
- valgt
- velge
- utvalg
- senior
- Serien
- tjeneste
- Session
- sett
- sett
- innstilling
- flere
- Form
- bør
- Viser
- på samme måte
- forenkle
- samtidig
- enkelt
- SIX
- Størrelse
- størrelser
- liten
- mindre
- So
- løsning
- Solutions
- LØSE
- spesifikasjon
- spesifikasjoner
- spesifisert
- Standard
- startet
- statistisk
- Trinn
- stoppet
- stoppe
- lagret
- Studer
- senere
- i det vesentlige
- slik
- tilstrekkelig
- egnet
- bord
- målrettet
- Oppgave
- oppgaver
- lag
- tensorflow
- test
- De
- deres
- derved
- tre
- gjennomstrømning
- tid
- Tidsserier
- ganger
- til
- i dag
- sammen
- verktøy
- topp
- top 5
- Totalt
- Tog
- trent
- Kurs
- overføre
- transformers
- sant
- typer
- Til syvende og sist
- etter
- unik
- universitet
- bruk
- bruke
- bruke
- benyttes
- validering
- Verdier
- variasjon
- enorme
- av
- Se
- syn
- hvilken
- mens
- bred
- vil
- innenfor
- uten
- ville
- skriving
- Din
- zephyrnet