Dette er et gjesteinnlegg skrevet av Alex Naumov, hoveddataarkitekt ved smava.
smava GmbH er et av de ledende finansielle tjenesteselskapene i Tyskland, som gjør personlige lån transparente, rettferdige og rimelige for forbrukere. Basert på digitale prosesser sammenligner smava lånetilbud fra mer enn 20 banker. På denne måten kan låntakere velge de avtalene som er mest fordelaktige for dem på en rask, digitalisert og effektiv måte.
smava tror på og utnytter datadrevne beslutninger for å bli markedsleder. Dataplattform-teamet er ansvarlig for å støtte datadrevne beslutninger hos smava ved å tilby dataprodukter på tvers av alle avdelinger og grener av selskapet. Avdelingene inkluderer team fra engineering til salg og markedsføring. Filialer varierer etter produkter, nemlig B2C-lån, B2B-lån og tidligere også B2C-lån. Dataproduktene som brukes i selskapet inkluderer blant annet innsikt fra brukerreiser, driftsrapporter og resultater fra markedsføringskampanjer. Dataplattformen betjener i gjennomsnitt 60 tusen søk per dag. Datavolumet er i tosifrede TB-er med jevn vekst etter hvert som virksomheten og datakilder utvikler seg.
smavas dataplattformteam sto overfor utfordringen med å levere data til interessenter med forskjellige SLAer, samtidig som de beholdt fleksibiliteten til å skalere opp og ned samtidig som de forblir kostnadseffektive. Det tok opptil 3 timer å generere daglig rapportering, noe som påvirket forretningsbeslutninger når omberegninger måtte skje i løpet av dagen. For å øke hastigheten på selvbetjeningsanalysen og fremme innovasjon basert på data, var det nødvendig med en løsning for å gi måter å tillate ethvert team å lage dataprodukter på egenhånd på en desentralisert måte. For å opprette og administrere dataproduktene, bruker smava Amazon RedShift, et skydatavarehus.
I dette innlegget viser vi hvordan smava optimaliserte dataplattformen deres ved å bruke Amazon Redshift Serverløs og Amazon Redshift datadeling å overvinne utfordringer med riktig størrelse for uforutsigbare arbeidsmengder og ytterligere forbedre prisytelse. Gjennom optimaliseringene oppnådde smava opptil 50 % kostnadsbesparelser og opptil tre ganger raskere rapportgenerering sammenlignet med den forrige analyseinfrastrukturen.
Oversikt over løsning
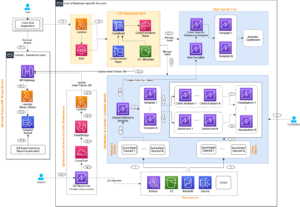
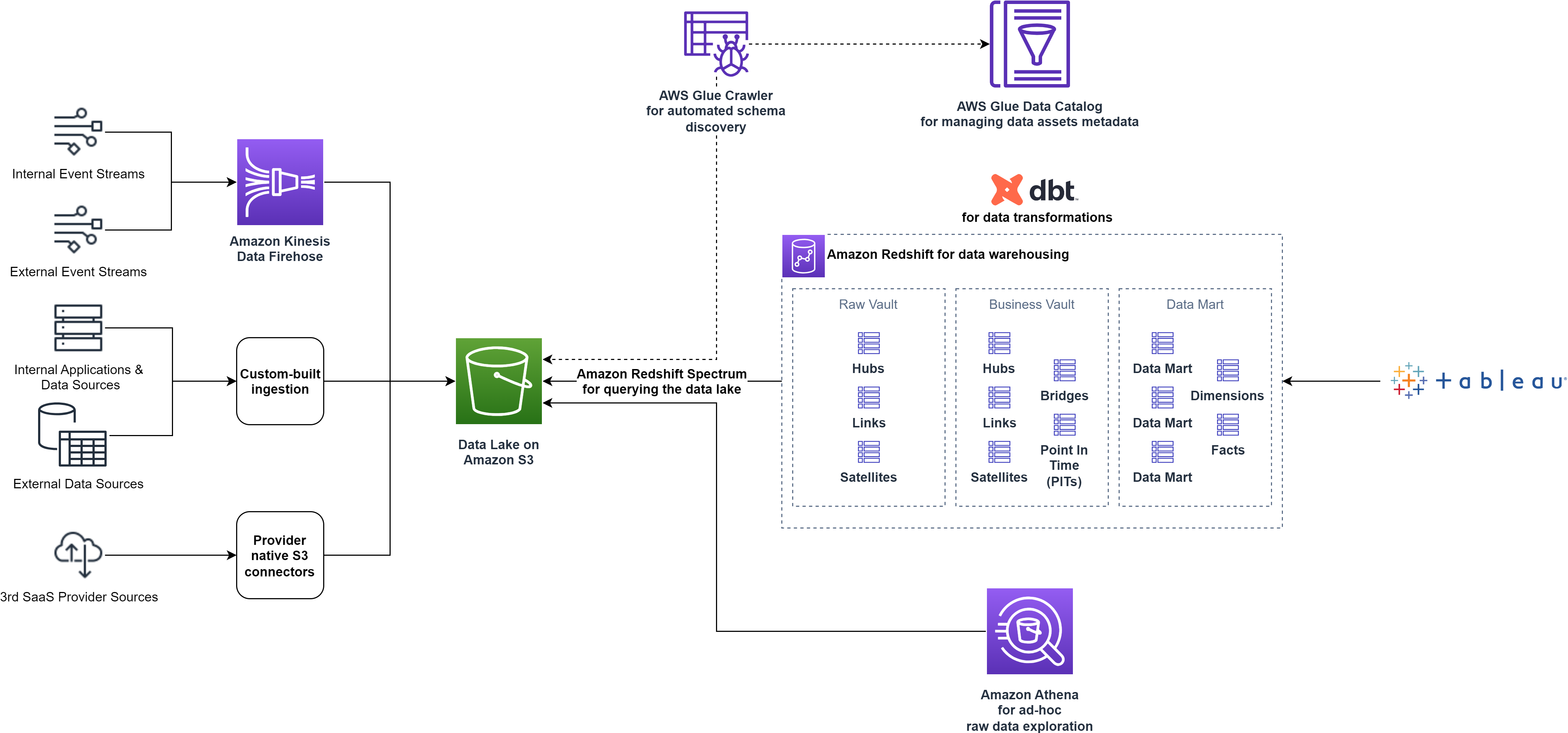
Som et datadrevet selskap er smava avhengig av AWS Cloud for å drive analysebrukssakene deres. For å gi kundene sine de beste tilbudene og brukeropplevelsen, følger smava moderne dataarkitektur prinsipper med en datainnsjø som et skalerbart, holdbart datalager og spesialbygde datalagre for analytisk behandling og dataforbruk.
smava inntar data fra ulike eksterne og interne datakilder til et landingssted på datasjøen basert på Amazon enkel lagringstjeneste (Amazon S3). For å innta dataene bruker smava et sett med populære tredjeparts kundedataplattformer supplert med tilpassede skript.
Etter at dataene lander i Amazon S3, bruker smava AWS Lim Datakatalog og crawlere å automatisk katalogisere de tilgjengelige dataene, fange opp metadataene og tilby et grensesnitt som gjør det mulig å søke etter alle dataressurser.
Dataanalytikere som trenger tilgang til de rå eiendelene på datainnsjøen bruker Amazonas Athena, en serverløs, interaktiv analysetjeneste for utforskning med ad hoc-søk. For nedstrømsforbruk av alle avdelinger på tvers av organisasjonen, utarbeider smavas dataplattformteam kuraterte dataprodukter etter trekke ut, laste inn og transformere (ELT) mønster. smava bruker Amazon Redshift som deres skydatavarehus for å transformere, lagre og analysere data og bruk Amazon Redshift Spectrum å effektivt spørre og hente strukturerte og semi-strukturerte data fra datasjøen ved hjelp av SQL.
smava følger datahvelvmodellering metodikk med Raw Vault-, Business Vault- og Data Mart-stadiene for å forberede dataproduktene for sluttforbrukere. Raw Vault beskriver objekter lastet direkte fra datakildene og representerer en kopi av landingsstadiet i datasjøen. Business Vault er fylt med data hentet fra Raw Vault og transformert i henhold til forretningsreglene. Til slutt blir dataene aggregert til spesifikke dataprodukter orientert mot en spesifikk forretningslinje. Dette er Databutikk scene. Dataproduktene fra Business Vault- og Data Mart-stadiene er nå tilgjengelige for forbrukere. smava bestemte seg for å bruke Tableau for forretningsintelligens, datavisualisering og videre analyser. Datatransformasjonene administreres med DBT for å forenkle arbeidsflytstyring og teamsamarbeid.
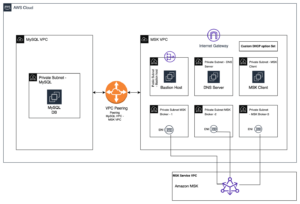
Følgende diagram viser dataplattformarkitekturen på høyt nivå før optimaliseringene.
Utvikling av kravene til dataplattformen
smava startet med en enkelt Redshift-klynge for å være vert for alle tre datatrinn. De valgte klargjorte klyngenoder for RA3 type med Reserverte forekomster (RIer) for kostnadsoptimalisering. Ettersom datavolumene vokste med 53 % fra år til år, økte kompleksiteten og kravene fra ulike analytiske arbeidsmengder.
smava tok raskt tak i de økende datavolumene ved å tilpasse klyngen riktig og bruke Amazon Redshift samtidighetsskalering for maksimal arbeidsbelastning. Videre ønsket smava å gi alle team muligheten til å lage sine egne dataprodukter på en selvbetjent måte for å øke innovasjonstakten. For å unngå forstyrrelser med de sentralstyrte dataproduktene, måtte de desentraliserte produktutviklingsmiljøene være strengt isolert. Det samme kravet ble også brukt for isolering av ulike produktstadier kurert av dataplattformteamet.
Optimalisering av arkitekturen med datadeling og Redshift Serverless
For å møte de utviklede kravene, bestemte smava seg for å skille arbeidsmengden ved å dele opp den enkelt klargjorte Redshift-klyngen i flere datavarehus, der hvert varehus betjener et annet trinn. I tillegg la smava til nye oppsamlingsmiljøer i Business Vault for å utvikle nye dataprodukter uten risiko for å forstyrre eksisterende produktpipelines. For å unngå forstyrrelser med de sentralstyrte dataproduktene til Data Platform-teamet, introduserte smava en ekstra Redshift-klynge, som isolerte de desentraliserte arbeidsbelastningene.
smava var på utkikk etter en klar løsning for å oppnå arbeidsbelastningsisolasjon uten å administrere en kompleks datareplikeringspipeline.
Rett etter lanseringen av Redshift datadeling kapasiteter i 2021, anerkjente Data Platform-teamet at dette var løsningen de hadde lett etter. smava tok i bruk datadelingsfunksjonen for å ha dataene fra produsentklynger tilgjengelige for lesetilgang på forskjellige forbrukerklynger, med hver av disse forbrukerklyngene på forskjellige trinn.
Redshift-datadeling muliggjør umiddelbar, detaljert og rask datatilgang på tvers av Redshift-klynger uten behov for å kopiere data. Den gir direkte tilgang til data slik at brukerne alltid ser den mest oppdaterte og konsistente informasjonen når den oppdateres i datavarehuset. Med datadeling kan du trygt dele live data med Redshift-klynger i samme eller forskjellige AWS-kontoer og på tvers av regioner.
Med Redshift-datadeling var smava i stand til å optimalisere dataarkitekturen ved å separere dataarbeidsbelastningene til individuelle forbrukerklynger uten å måtte replikere dataene. Følgende diagram illustrerer dataplattformarkitekturen på høyt nivå etter å ha splittet den enkle Redshift-klyngen i flere klynger.
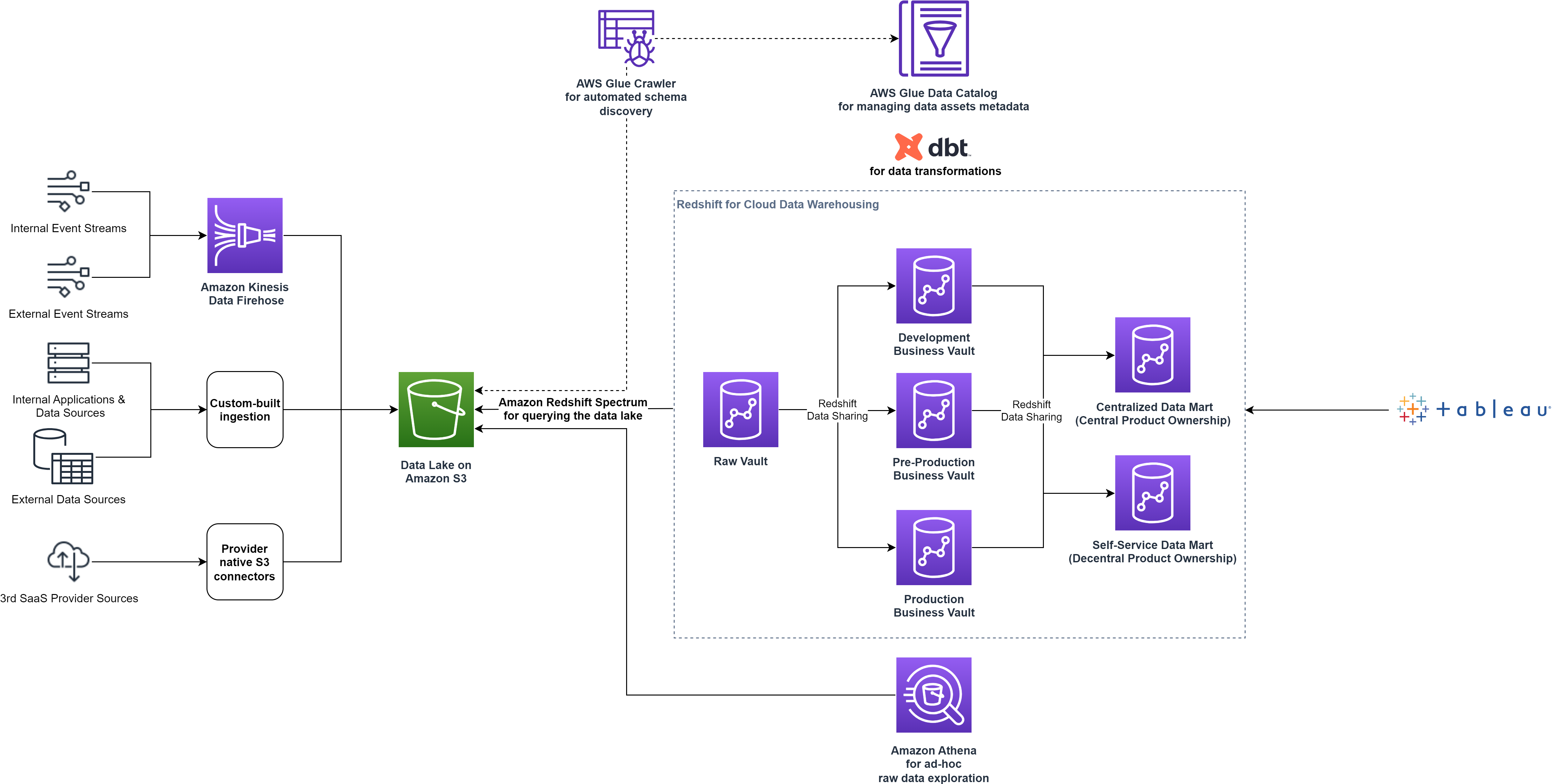
Ved å tilby en selvbetjent datamart, økte smava datademokratiseringen ved å gi brukerne tilgang til alle aspekter av dataene. De ga også teamene et sett med tilpassede verktøy for dataoppdagelse, ad hoc-analyse, prototyping og drift av hele livssyklusen til modne dataprodukter.
Etter å ha samlet inn driftsdata fra de individuelle klyngene, identifiserte dataplattformteamet ytterligere potensielle optimaliseringer: Raw Vault-klyngen var under jevn belastning 24/7, men Business Vault-klyngene ble bare oppdatert hver natt. For å optimalisere for kostnader, brukte smava pause og gjenoppta funksjoner av Redshift-klargjorte klynger. Disse egenskapene er nyttige for klynger som må være tilgjengelige til bestemte tider. Mens klyngen er satt på pause, blir fakturering på forespørsel suspendert. Bare klyngens lagring påløper kostnader.
Pause og gjenoppta-funksjonen hjalp smava med å optimalisere for kostnader, men det krevde ekstra driftskostnader for å utløse klyngeoperasjonene. I tillegg forble utviklingsklyngene underlagt ledige tider i arbeidstiden. Disse utfordringene ble til slutt løst ved å ta i bruk Redshift Serverless i 2022. Dataplattformteamet bestemte seg for å flytte Business Data Vault-faseklyngene til Redshift Serverless, som lar dem betale for datavarehuset kun når det er i bruk, pålitelig og effektivt.
Redshift Serverless er ideell for tilfeller der det er vanskelig å forutsi databehov som variable arbeidsbelastninger, periodiske arbeidsbelastninger med inaktiv tid og steady-state arbeidsbelastninger med topper. I tillegg, ettersom bruksetterspørselen utvikler seg med nye arbeidsbelastninger og flere samtidige brukere, tildeler Redshift Serverless automatisk de riktige dataressursene, og datavarehuset skaleres sømløst og automatisk, uten behov for manuell intervensjon. Datadeling støttes i begge retninger mellom Redshift Serverless og klargjorte Redshift-klynger med RA3-noder, så ingen endringer i smava-arkitekturen var nødvendig. Følgende diagram viser høynivåarkitekturoppsettet etter overgangen til Redshift Serverless.
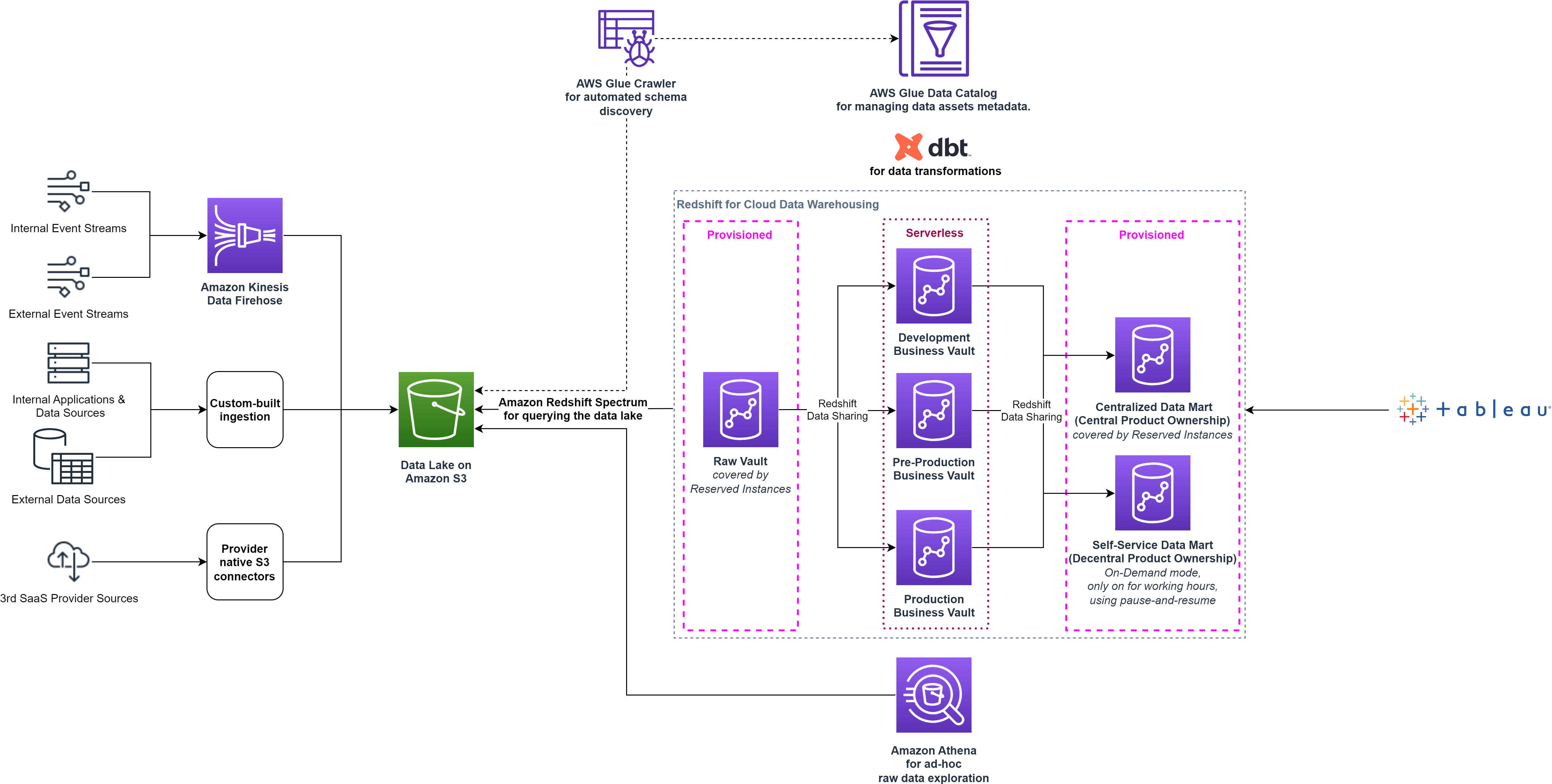
smava kombinerte fordelene med Redshift Serverless og dbt gjennom en sømløs CI/CD-pipeline, og tok i bruk en trunk-basert utviklingsmetodikk. Endringer på Git-depotet distribueres automatisk til et teststadium og valideres ved hjelp av automatiserte integrasjonstester. Denne tilnærmingen økte effektiviteten til utviklerne og reduserte den gjennomsnittlige tiden til produksjon fra dager til minutter.
smava tok i bruk en arkitektur som bruker både klargjorte og serverløse Redshift-datavarehus, sammen med datadelingsevnen for å isolere arbeidsbelastningene. Ved å velge de riktige arkitektoniske mønstrene for deres behov, var smava i stand til å oppnå følgende:
- Forenkle datarørledningene og reduser driftskostnader
- Reduser utgivelsestiden for funksjoner fra dager til minutter
- Øk prisytelse ved å redusere inaktive tider og tilpasse arbeidsmengden i riktig størrelse
- Oppnå opptil tre ganger raskere rapportgenerering (raskere beregninger og høyere parallellisering) til 50 % av de opprinnelige oppsettkostnadene
- Øk smidigheten til alle avdelinger og støtte datadrevet beslutningstaking ved å demokratisere tilgangen til data
- Øk innovasjonshastigheten ved å eksponere selvbetjente datafunksjoner for team på tvers av alle avdelinger og styrke A/B-testfunksjonene for å dekke hele kundereisen
Nå bruker alle avdelinger hos smava de tilgjengelige dataproduktene for å ta datadrevne, nøyaktige og smidige beslutninger.
Fremtidsvisjon
For fremtiden planlegger smava å fortsette å optimalisere dataplattformen basert på operasjonelle beregninger. De vurderer å bytte flere klargjorte klynger som Self-Service Data Mart-klyngen til serverløse. I tillegg optimaliserer smava ELT-orkestreringsverktøykjeden for å øke antallet parallelle datapipelines som skal kjøres. Dette vil øke utnyttelsen av klargjorte Redshift-ressurser og gi mulighet for kostnadsreduksjoner.
Med introduksjonen av den desentraliserte selvbetjeningen for dataproduktskaping, tok smava et skritt fremover mot en datanettingsarkitektur. I fremtiden planlegger dataplattformteamet å evaluere behovene til tjenestebrukerne sine ytterligere og etablere ytterligere datanettprinsipper som forent datastyring.
konklusjonen
I dette innlegget viste vi hvordan smava optimaliserte dataplattformen deres ved å isolere miljøer og arbeidsbelastninger ved å bruke Redshift Serverless og datadelingsfunksjoner. Disse Redshift-miljøene er godt integrert med deres infrastruktur, fleksible i skalering på forespørsel, og svært tilgjengelige, og de krever minimalt med administrasjonsinnsats. Samlet sett har smava økt ytelsen med tre ganger samtidig som den har redusert de totale plattformkostnadene med 50 %. I tillegg reduserte de driftskostnader til et minimum samtidig som de opprettholder de eksisterende SLAene for rapportgenereringstider. Dessuten har smava styrket innovasjonskulturen ved å tilby selvbetjente dataproduktfunksjoner for å fremskynde tiden til markedet.
Hvis du er interessert i å lære mer om Amazon Redshift-funksjoner, anbefaler vi å se den nyeste Hva er nytt med Amazon Redshift-økten i AWS Events-kanalen for å få en oversikt over funksjonene som nylig er lagt til i tjenesten. Du kan også utforske selvbetjente, praktiske Amazon Redshift-laboratorier å eksperimentere med viktige Amazon Redshift-funksjoner på en veiledet måte.
Du kan også dykke dypere inn Redshift Serverless use cases og brukstilfeller for datadeling. I tillegg, sjekk ut beste praksis for datadeling og finn ut hvordan andre kunder optimalisert for kostnader og ytelse med Redshift-datadeling å bli inspirert til dine egne arbeidsmengder.
Hvis du foretrekker bøker, sjekk ut Amazon Redshift: The Definitive Guide av O'Reilly, der forfatterne beskriver egenskapene til Amazon Redshift og gir deg innsikt i tilsvarende mønstre og teknikker.
Om forfatterne
 Alex Naumov er Principal Data Architect hos smava GmbH, og leder transformasjonsprosjektene ved Dataavdelingen. Alex har tidligere jobbet 10 år som konsulent og data-/løsningsarkitekt i en lang rekke domener, som telekommunikasjon, bank, energi og finans, ved bruk av ulike teknologistabler og i mange forskjellige land. Han har en stor lidenskap for data og å transformere organisasjoner til å bli datadrevne og best i det de gjør.
Alex Naumov er Principal Data Architect hos smava GmbH, og leder transformasjonsprosjektene ved Dataavdelingen. Alex har tidligere jobbet 10 år som konsulent og data-/løsningsarkitekt i en lang rekke domener, som telekommunikasjon, bank, energi og finans, ved bruk av ulike teknologistabler og i mange forskjellige land. Han har en stor lidenskap for data og å transformere organisasjoner til å bli datadrevne og best i det de gjør.
 Lingli Zheng jobber som Business Development Manager i AWS verdensomspennende spesialistorganisasjon, og støtter kunder i DACH-regionen for å få mest mulig ut av Amazons analysetjenester. Med over 12 års erfaring innen energi, automasjon og programvareindustrien med fokus på dataanalyse, AI og ML, er hun dedikert til å hjelpe kunder med å oppnå håndgripelige forretningsresultater gjennom digital transformasjon.
Lingli Zheng jobber som Business Development Manager i AWS verdensomspennende spesialistorganisasjon, og støtter kunder i DACH-regionen for å få mest mulig ut av Amazons analysetjenester. Med over 12 års erfaring innen energi, automasjon og programvareindustrien med fokus på dataanalyse, AI og ML, er hun dedikert til å hjelpe kunder med å oppnå håndgripelige forretningsresultater gjennom digital transformasjon.
 Alexander Spivak er Senior Startup Solutions Architect hos AWS, med fokus på B2B ISV-kunder over hele EMEA Nord. Før AWS jobbet Alexander som konsulent innen finansielle tjenester, inkludert ulike roller innen programvareutvikling og arkitektur. Han er lidenskapelig opptatt av dataanalyse, serverløse arkitekturer og å skape effektive organisasjoner.
Alexander Spivak er Senior Startup Solutions Architect hos AWS, med fokus på B2B ISV-kunder over hele EMEA Nord. Før AWS jobbet Alexander som konsulent innen finansielle tjenester, inkludert ulike roller innen programvareutvikling og arkitektur. Han er lidenskapelig opptatt av dataanalyse, serverløse arkitekturer og å skape effektive organisasjoner.
Dette innlegget ble vurdert for teknisk nøyaktighet av David Greenshtein, Senior Analytics Solutions Architect.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/how-smava-makes-loans-transparent-and-affordable-using-amazon-redshift-serverless/
- : har
- :er
- :hvor
- $OPP
- 10
- 100
- 12
- 125
- 20
- 2021
- 2022
- 60
- a
- I stand
- Om oss
- adgang
- Tilgang til data
- utrette
- Ifølge
- kontoer
- nøyaktighet
- nøyaktig
- Oppnå
- oppnådd
- tvers
- Ad
- la til
- tillegg
- Ytterligere
- I tillegg
- adressert
- administrasjon
- vedtatt
- vedta
- Fordel
- rimelig
- Etter
- smidig
- AI
- alex
- Alexander
- Alle
- tillate
- tillater
- også
- alltid
- Amazon
- Amazon Web Services
- blant
- an
- analyse
- analytikere
- analytisk
- Analytisk
- analytics
- analysere
- og
- noen
- anvendt
- tilnærming
- arkitektonisk
- arkitektur
- ER
- AS
- aspekter
- Eiendeler
- At
- forfatter
- forfattere
- Automatisert
- automatisk
- Automatisering
- tilgjengelig
- gjennomsnittlig
- unngå
- AWS
- B2B
- B2C
- Banking
- Banker
- basert
- BE
- bli
- vært
- før du
- mener
- Fordeler
- BEST
- mellom
- fakturering
- Blogg
- bøker
- låntakere
- både
- grener
- bringe
- virksomhet
- forretningsutvikling
- business intelligence
- men
- by
- Kampanje
- CAN
- evner
- evne
- fangst
- saker
- katalog
- utfordre
- utfordringer
- Endringer
- avgifter
- sjekk
- Velg
- velge
- valgte
- Cloud
- Cluster
- samarbeid
- Samle
- kombinert
- Selskaper
- Selskapet
- sammenlignet
- fullføre
- komplekse
- kompleksitet
- Beregn
- samtidig
- vurderer
- konsistent
- konsulent
- forbruker
- Forbrukere
- forbruk
- fortsette
- Tilsvarende
- Kostnad
- kostnadsbesparelser
- Kostnader
- land
- dekke
- skape
- Opprette
- skaperverket
- Kultur
- kuratert
- skikk
- kunde
- kunde Data
- Kunder
- daglig
- dato
- data tilgang
- Data Analytics
- Data Lake
- Dataplattform
- datadeling
- datavisualisering
- datalager
- datavarehus
- data-drevet
- David
- dag
- Dager
- Tilbud
- desentralisert
- besluttet
- Beslutningstaking
- avgjørelser
- redusert
- dedikert
- dypere
- definitive
- leverer
- Etterspørsel
- demokratisering
- Demokratisering
- Avdeling
- avdelinger
- utplassert
- detalj
- utvikle
- utviklere
- Utvikling
- gJORDE
- forskjellig
- vanskelig
- digitalt
- Digital Transformation
- retninger
- direkte
- oppdage
- Funnet
- dykk
- do
- domener
- ned
- under
- hver enkelt
- effektivitet
- effektiv
- effektivt
- innsats
- EMEA
- muliggjør
- slutt
- energi
- engasjementer
- Ingeniørarbeid
- miljøer
- etablere
- Eter (ETH)
- evaluere
- hendelser
- utvikle seg
- utviklet seg
- utvikler seg
- eksisterende
- erfaring
- eksperiment
- leting
- utforske
- utvendig
- møtt
- rettferdig
- FAST
- raskere
- gunstig
- Trekk
- Egenskaper
- Endelig
- finansiere
- finansiell
- finansielle tjenester
- fleksibilitet
- fleksibel
- Fokus
- fokusering
- etter
- følger
- Til
- For forbrukere
- tidligere
- Forward
- Foster
- fra
- fullt
- funksjonalitet
- videre
- Dess
- framtid
- generere
- generasjonen
- Tyskland
- få
- gå
- Gi
- GmBH
- styresett
- flott
- vokste
- Økende
- Vekst
- Gjest
- gjest innlegg
- veilede
- guidet
- HAD
- hands-on
- skje
- Ha
- å ha
- he
- hjulpet
- hjelpe
- høyt nivå
- høyere
- svært
- vert
- TIMER
- Hvordan
- HTML
- HTTPS
- ideell
- identifisert
- Idle
- illustrerer
- påvirket
- forbedre
- in
- inkludere
- Inkludert
- Øke
- økt
- individuelt
- industri
- informasjon
- Infrastruktur
- Innovasjon
- innsiden
- innsikt
- inspirert
- forekomster
- instant
- integrert
- integrering
- Intelligens
- interaktiv
- interessert
- Interface
- forstyrrelser
- forstyrrende
- intern
- intervensjon
- inn
- introdusert
- innføre
- Introduksjon
- isolert
- isolasjon
- isv
- IT
- Journeys
- nøkkel
- innsjø
- landing
- lander
- lansere
- leder
- ledende
- Fører
- læring
- Livssyklus
- i likhet med
- linje
- leve
- live data
- laste
- lån
- Lån
- ser
- laget
- opprettholde
- gjøre
- GJØR AT
- Making
- administrer
- fikk til
- leder
- administrerende
- måte
- håndbok
- mange
- marked
- Markedsleder
- Marketing
- moden
- Møt
- mesh
- metadata
- metodikk
- Metrics
- minimum
- minutter
- ML
- mer
- Videre
- boliglån
- mest
- flytte
- flere
- nemlig
- Trenger
- nødvendig
- behov
- Ny
- Nei.
- noder
- nord
- nå
- Antall
- gjenstander
- of
- Tilbud
- on
- På etterspørsel
- ONE
- bare
- drift
- operasjonell
- Drift
- optimalisering
- Optimalisere
- optimalisert
- optimalisere
- Alternativ
- or
- orkestre
- rekkefølge
- organisasjon
- organisasjoner
- original
- Annen
- andre
- ut
- enn
- samlet
- Overcome
- oversikt
- egen
- Fred
- Parallel
- lidenskap
- lidenskapelig
- Mønster
- mønstre
- pause
- pauset
- Betale
- Topp
- for
- ytelse
- periodisk
- personlig
- Personlige lån
- rørledning
- planer
- plattform
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- Populær
- befolket
- Post
- potensiell
- makt
- forutsi
- trekker
- Forbered
- forbereder
- forrige
- tidligere
- Principal
- prinsipper
- Før
- Prosesser
- prosessering
- produsent
- Produkt
- produktutvikling
- Produksjon
- Produkter
- prosjekter
- prototyping
- gi
- forutsatt
- gir
- gi
- spørsmål
- raskt
- område
- Raw
- Lese
- nylig
- nylig
- gjenkjent
- anbefaler
- redusere
- Redusert
- redusere
- reduksjoner
- region
- regioner
- slipp
- forble
- replikering
- rapporterer
- Rapportering
- Rapporter
- Repository
- representerer
- krever
- påkrevd
- behov
- Krav
- Ressurser
- ansvarlig
- Resultater
- gjenoppta
- anmeldt
- ikke sant
- Risiko
- roller
- regler
- Kjør
- salg
- Salg og markedsføring
- samme
- Besparelser
- skalerbar
- Skala
- vekter
- skalering
- skript
- sømløs
- sømløst
- sikkert
- se
- Selvbetjening
- senior
- separat
- separering
- server~~POS=TRUNC
- serverer
- tjeneste
- Tjenester
- servering
- Session
- sett
- oppsett
- Del
- deling
- hun
- Vis
- viste
- Viser
- Enkelt
- forenkle
- enkelt
- So
- Software
- programvareutvikling
- løsning
- Solutions
- løst
- hentet
- Kilder
- spesialist
- spesifikk
- fart
- pigger
- SQL
- Stabler
- Scene
- stadier
- iscenesettelse
- interessenter
- startet
- oppstart
- blir
- jevn
- Trinn
- lagring
- oppbevare
- butikker
- styrket
- styrke
- strukturert
- emne
- slik
- støtte
- Støttes
- Støtte
- suspendert
- Tableau
- tar
- håndgripelig
- lag
- lag
- tech
- Teknisk
- teknikker
- telekommunikasjon
- test
- tester
- enn
- Det
- De
- Fremtiden
- deres
- Dem
- Disse
- de
- tredjeparts
- denne
- De
- tusen
- tre
- Gjennom
- tid
- ganger
- til
- sammen
- tok
- verktøy
- Totalt
- mot
- Transform
- Transformation
- transformasjoner
- forvandlet
- transformere
- gjennomsiktig
- utløse
- etter
- uforutsigbare
- up-to-date
- oppdatert
- bruk
- bruke
- brukt
- Bruker
- Brukererfaring
- Brukere
- bruker
- ved hjelp av
- bruker
- validert
- verdi
- variabel
- variasjon
- ulike
- Vault
- visualisering
- volum
- volumer
- ønsket
- Warehouse
- var
- se
- Vei..
- måter
- we
- web
- webtjenester
- VI VIL
- var
- Hva
- når
- hvilken
- mens
- HVEM
- bred
- Wikipedia
- vil
- med
- uten
- arbeidet
- arbeidsflyt
- arbeid
- Arbeidstid
- virker
- Verksteder
- verdensomspennende
- år
- år
- du
- Din
- youtube
- zephyrnet