Med Amazon EMR 6.15, lanserte vi AWS Lake formasjon baserte finkornede tilgangskontroller (FGAC) på åpne tabellformater (OTF), inkludert Apache Hudi, Apache Iceberg og Delta lake. Dette lar deg forenkle sikkerhet og styring over transaksjonelle datainnsjøer ved å gi tilgangskontroller på tabell-, kolonne- og radnivå-tillatelser med Apache Spark-jobbene dine. Mange store bedrifter søker å bruke transaksjonsdatainnsjøen sin for å få innsikt og forbedre beslutningstaking. Du kan bygge en innsjøhusarkitektur ved å bruke Amazon EMR integrert med Lake Formation for FGAC. Denne kombinasjonen av tjenester lar deg utføre dataanalyse på transaksjonsdatasjøen din samtidig som du sikrer sikker og kontrollert tilgang.
Amazon EMR-postserverkomponenten støtter tabell-, kolonne-, rad-, celle- og nestet attributt-nivå datafiltreringsfunksjonalitet. Den utvider støtte til formatene Hive, Apache Hudi, Apache Iceberg og Delta lake for både lesing (inkludert tidsreiser og inkrementelle spørringer) og skriveoperasjoner (på DML-setninger som INSERT). I tillegg, med versjon 6.15, introduserer Amazon EMR tilgangskontrollbeskyttelse for sitt applikasjonsnettgrensesnitt, slik som Spark History Server på klyngen, Yarn Timeline Server og Yarn Resource Manager UI.
I dette innlegget viser vi hvordan du implementerer FGAC på Apache Hudi tabeller som bruker Amazon EMR integrert med Lake Formation.
Brukscase for transaksjonsdata
Amazon EMR-kunder bruker ofte åpne tabellformater for å støtte deres behov for ACID-transaksjoner og tidsreiser i en datainnsjø. Ved å ta vare på historiske versjoner, gir datainnsjø-tidsreiser fordeler som revisjon og samsvar, datagjenoppretting og tilbakeføring, reproduserbar analyse og datautforskning på forskjellige tidspunkter.
En annen populær transaksjonsdatainnsjø er inkrementell spørring. Inkrementell spørring refererer til en spørringsstrategi som fokuserer på å behandle og analysere bare de nye eller oppdaterte dataene i en datainnsjø siden siste spørring. Nøkkelideen bak inkrementelle spørringer er å bruke metadata eller endre sporingsmekanismer for å identifisere nye eller modifiserte data siden siste spørring. Ved å identifisere disse endringene kan spørringsmotoren optimalisere spørringen til kun å behandle de relevante dataene, noe som reduserer behandlingstiden og ressurskravene betydelig.
Løsningsoversikt
I dette innlegget viser vi hvordan du implementerer FGAC på Apache Hudi-tabeller ved å bruke Amazon EMR på Amazon Elastic Compute Cloud (Amazon EC2) integrert med Lake Formation. Apache Hudi er en åpen kildekode for transaksjonelle datainnsjøer som i stor grad forenkler inkrementell databehandling og utvikling av datapipelines. Denne nye FGAC-funksjonen støtter alle OTF. Foruten å demonstrere med Hudi her, vil vi følge opp med andre OTF-tabeller med andre blogger. Vi bruker notatbøker in Amazon SageMaker Studio å lese og skrive Hudi-data via forskjellige brukertilgangstillatelser gjennom en EMR-klynge. Dette gjenspeiler virkelige datatilgangsscenarier – for eksempel hvis en ingeniørbruker trenger full datatilgang for å feilsøke på en dataplattform, mens dataanalytikere kanskje bare trenger å få tilgang til et undersett av disse dataene som ikke inneholder personlig identifiserbar informasjon (PII ). Integrering med Lake Formation via Amazon EMR runtime rolle gir deg ytterligere mulighet til å forbedre din datasikkerhetsstilling og forenkler datakontrolladministrasjonen for Amazon EMR-arbeidsbelastninger. Denne løsningen sikrer et sikkert og kontrollert miljø for datatilgang, som møter de ulike behovene og sikkerhetskravene til ulike brukere og roller i en organisasjon.
Følgende diagram illustrerer løsningsarkitekturen.
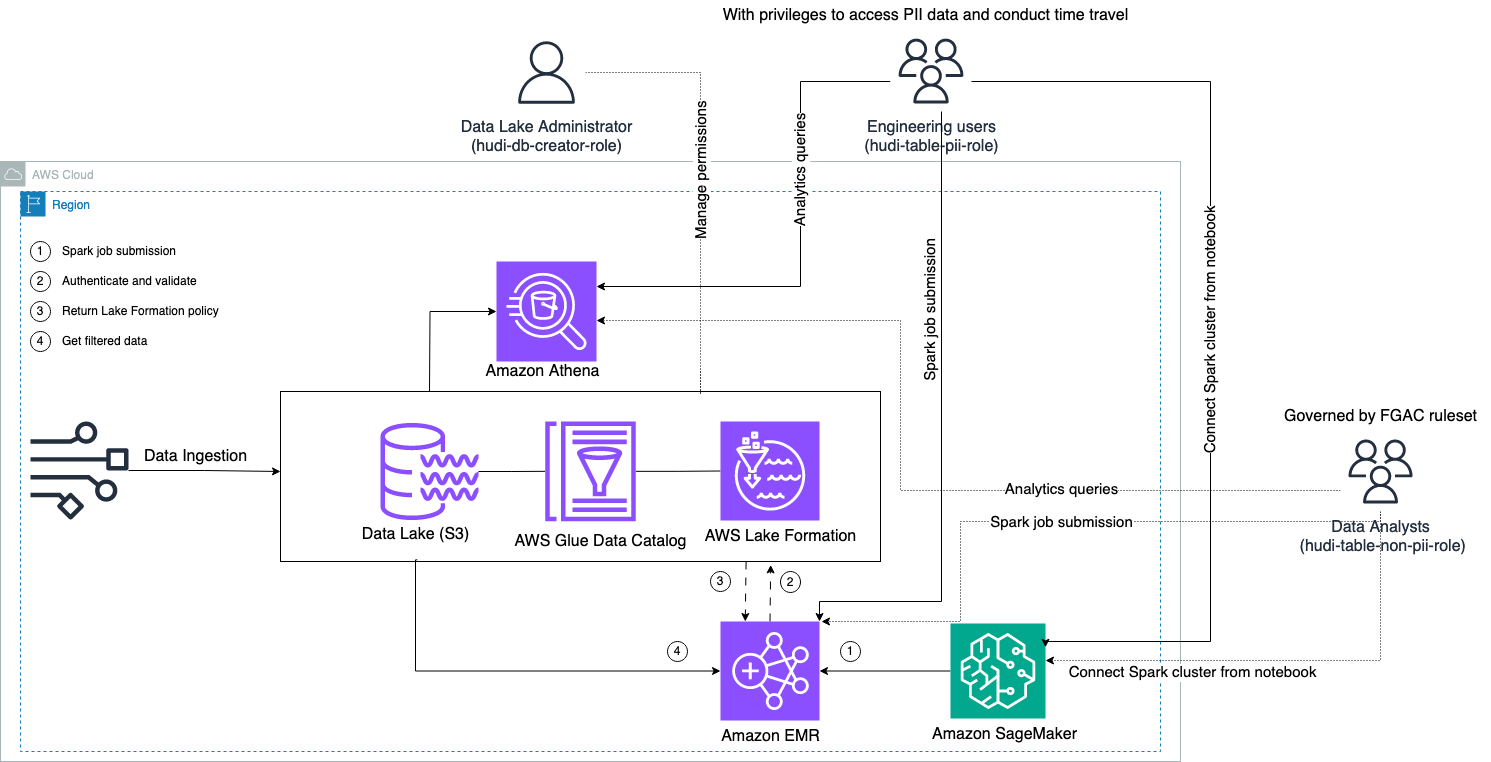
Vi gjennomfører en datainntaksprosess for å oppdatere (oppdatere og sette inn) et Hudi-datasett til en Amazon enkel lagringstjeneste (Amazon S3) bøtte, og vedvarer eller oppdater tabellskjemaet i AWS Lim Datakatalog. Med null databevegelse kan vi spørre Hudi-tabellen styrt av Lake Formation via ulike AWS-tjenester, som f.eks. Amazonas Athena, Amazon EMR og Amazon SageMaker.
Når brukere sender inn en Spark-jobb gjennom EMR-klynge-endepunkter (EMR Steps, Livy, EMR Studio og SageMaker), validerer Lake Formation privilegiene deres og instruerer EMR-klyngen om å filtrere ut sensitive data som PII-data.
Denne løsningen har tre forskjellige typer brukere med ulike nivåer av tillatelser for å få tilgang til Hudi-dataene:
- hudi-db-skaper-rolle – Dette brukes av datainnsjø-administratoren som har rettigheter til å utføre DDL-operasjoner som å lage, endre og slette databaseobjekter. De kan definere datafiltreringsregler på Lake Formation for datatilgangskontroll på radnivå og kolonnenivå. Disse FGAC-reglene sikrer at datainnsjø er sikret og oppfyller personvernforskriftene som kreves.
- hudi-table-pii-rolle – Dette brukes av ingeniørbrukere. Tekniske brukere er i stand til å utføre tidsreiser og inkrementelle spørringer på både Copy-on-Write (CoW) og Merge-on-Read (MoR). De har også privilegium til å få tilgang til PII-data basert på eventuelle tidsstempler.
- hudi-bord-ikke-pii-rolle – Dette brukes av dataanalytikere. Dataanalytikeres datatilgangsrettigheter styres av FGAC-autoriserte regler kontrollert av datainnsjøadministratorer. De har ikke synlighet på kolonner som inneholder PII-data som navn og adresser. I tillegg kan de ikke få tilgang til rader med data som ikke oppfyller visse betingelser. For eksempel kan brukerne bare få tilgang til datarader som tilhører deres land.
Forutsetninger
Du kan laste ned de tre notatbøkene som brukes i dette innlegget fra GitHub repo.
Før du distribuerer løsningen, sørg for at du har følgende:
Fullfør følgende trinn for å konfigurere tillatelsene dine:
- Logg på AWS-kontoen din med din admin IAM-bruker.
Sørg for at du er ius-east-1Region.
- Lag en S3-bøtte i
us-east-1Region (f.eks.emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
Deretter aktiverer vi Lake Formation ved endre standard tillatelsesmodell.
- Logg på Lake Formation-konsollen som administratorbruker.
- Velg Datakataloginnstillinger etter Administrasjon i navigasjonsruten.
- Under Standardtillatelser for nyopprettede databaser og tabeller, fjern merket Bruk kun IAM-tilgangskontroll for nye databaser og Bruk bare IAM-tilgangskontroll for nye tabeller i nye databaser.
- Velg Spar.
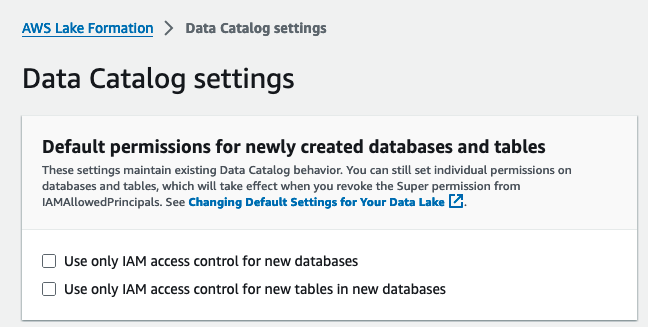
Alternativt må du tilbakekalle IAMAllowedPrincipals på ressurser (databaser og tabeller) opprettet hvis du startet Lake Formation med standardalternativet.
Til slutt lager vi et nøkkelpar for Amazon EMR.
- På Amazon EC2-konsollen velger du Nøkkelpar i navigasjonsruten.
- Velg Lag nøkkelpar.
- Til Navn, skriv inn et navn (for eksempel
emr-fgac-hudi-keypair). - Velg Lag nøkkelpar.
Det genererte nøkkelparet (for dette innlegget, emr-fgac-hudi-keypair.pem) vil lagre på din lokale datamaskin.
Deretter lager vi en AWS Cloud9 interaktivt utviklingsmiljø (IDE).
- På AWS Cloud9-konsollen velger du Miljøer i navigasjonsruten.
- Velg Skap miljø.
- Til Navn¸ skriv inn et navn (f.eks.
emr-fgac-hudi-env). - Behold de andre innstillingene som standard.
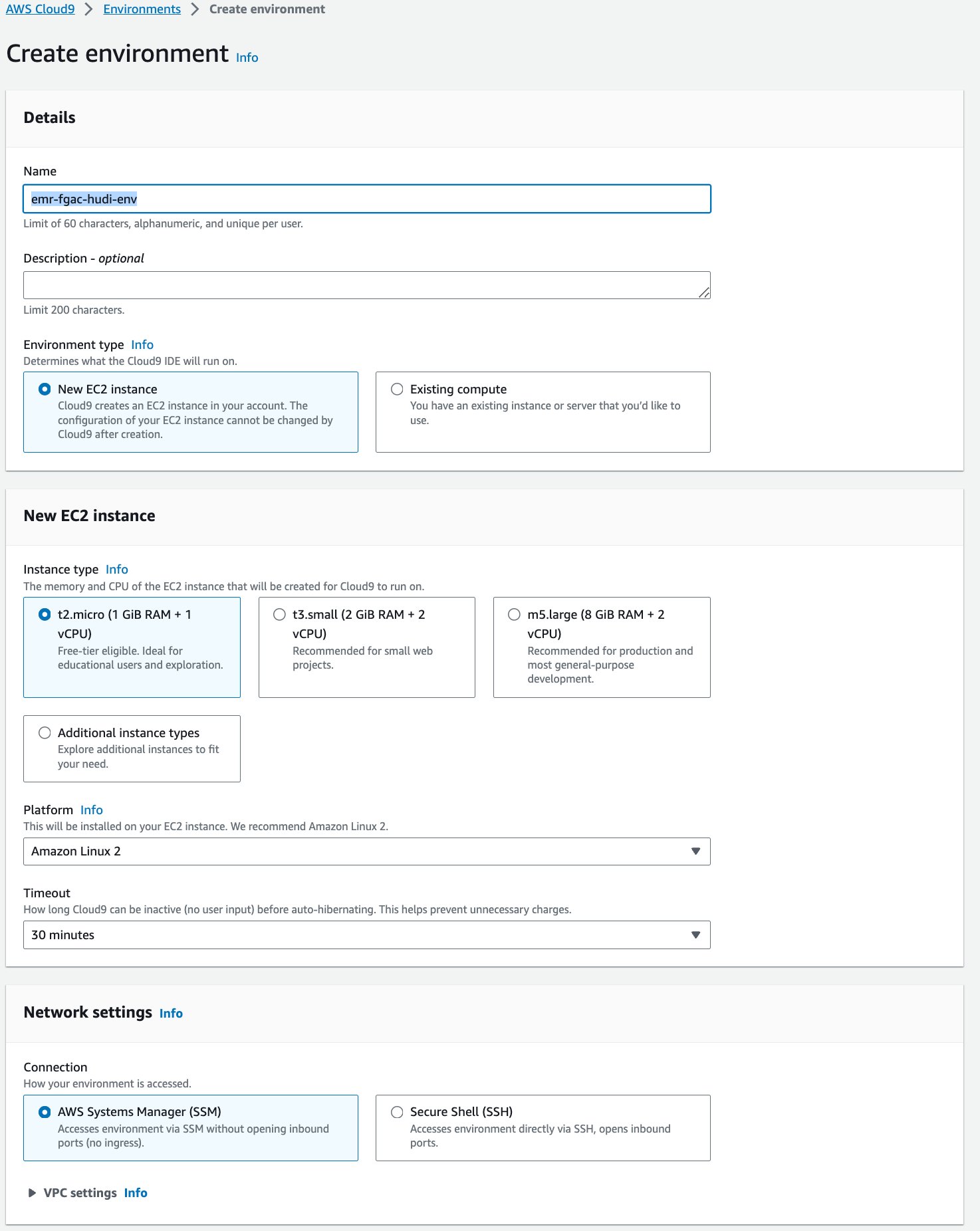
- Velg Opprett.
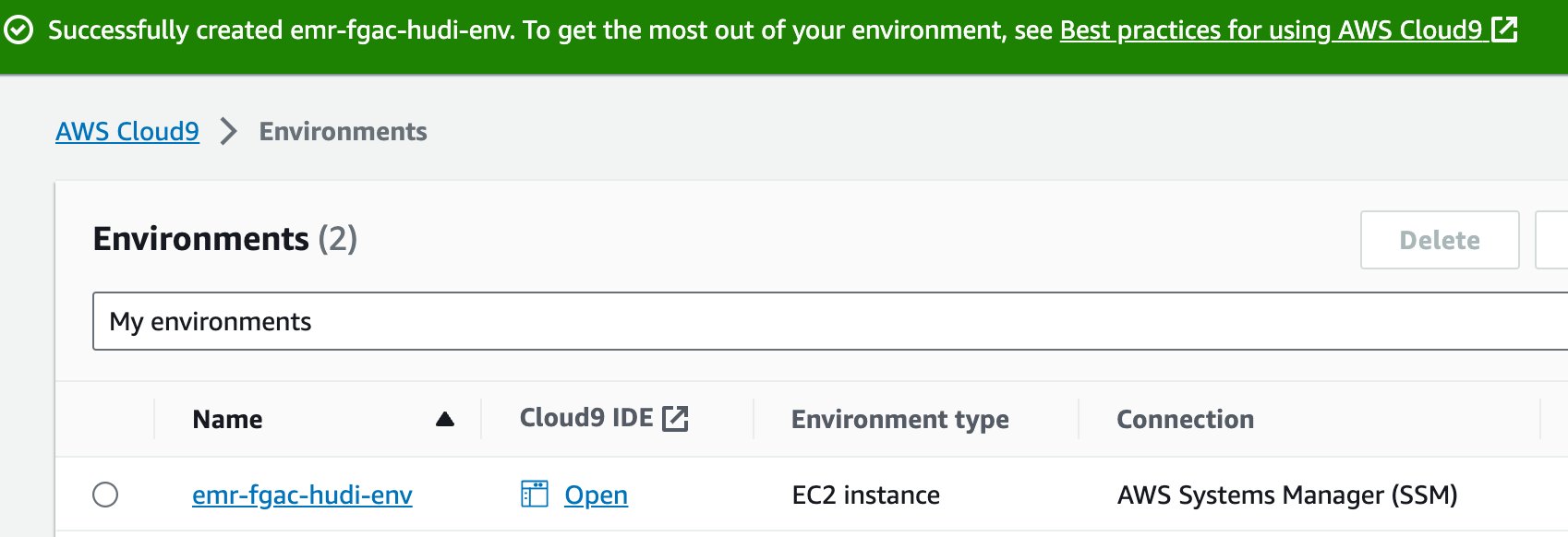
- Når IDE er klar, velg Åpen å åpne den.
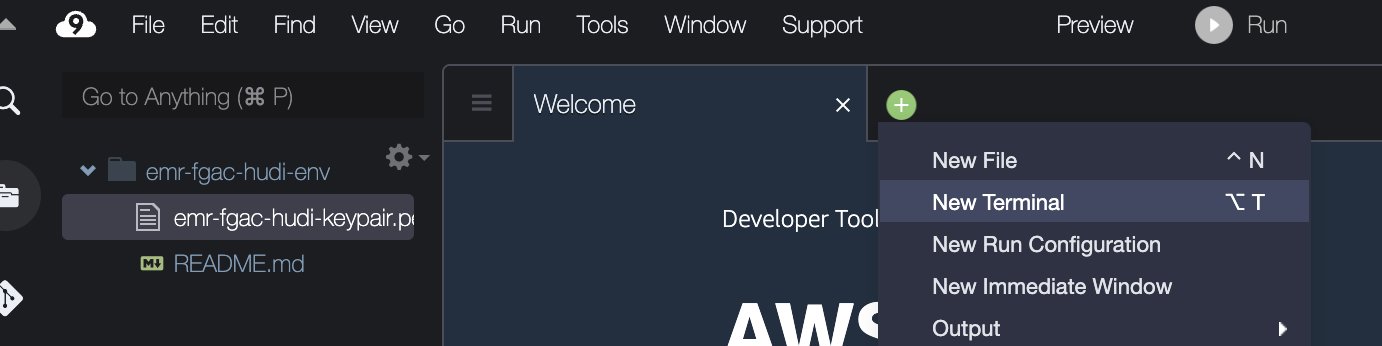
- I AWS Cloud9 IDE, på filet meny, velg Last opp lokale filer.

- Last opp nøkkelpar-filen (
emr-fgac-hudi-keypair.pem). - Velg plusstegnet og velg Ny terminal.
- Skriv inn følgende kommandolinjer i terminalen:
Merk at eksempelkoden kun er et proof of concept for demonstrasjonsformål. For produksjonssystemer, bruk en betrodd sertifiseringsinstans (CA) for å utstede sertifikater. Referere til Tilbyr sertifikater for kryptering av data under overføring med Amazon EMR-kryptering for mer informasjon.
Distribuer løsningen via AWS CloudFormation
Vi tilbyr en AWS skyformasjon mal som automatisk setter opp følgende tjenester og komponenter:
- En S3 bøtte for datasjøen. Den inneholder eksempelet TPC-DS-datasettet.
- En EMR-klynge med sikkerhetskonfigurasjon og offentlig DNS aktivert.
- EMR runtime IAM-roller med Lake Formation finmaskede tillatelser:
- -hudi-db-skaperrolle – Denne rollen brukes til å lage Apache Hudi-database og tabeller.
- -hudi-table-pii-rolle – Denne rollen gir tillatelse til å spørre alle kolonner i Hudi-tabeller, inkludert kolonner med PII.
- -hudi-tabell-ikke-pii-rolle – Denne rollen gir tillatelse til å spørre etter Hudi-tabeller som har filtrert ut PII-kolonner etter Lake Formation.
- SageMaker Studio-utførelsesroller som lar brukerne påta seg sine tilsvarende EMR-kjøretidsroller.
- Nettverksressurser som VPC, undernett og sikkerhetsgrupper.
Fullfør følgende trinn for å distribuere ressursene:
- Velg Rask opprett bunke for å starte CloudFormation-stakken.
- Til Stabelnavn, skriv inn et stabelnavn (f.eks.
rsv2-emr-hudi-blog). - Til Ec2KeyPair, skriv inn navnet på nøkkelparet ditt.
- Til IdleTimeout, angi en inaktiv tidsavbrudd for EMR-klyngen for å unngå å betale for klyngen når den ikke brukes.
- Til InitS3Bucket, skriv inn S3-bøttenavnet du opprettet for å lagre .zip-filen for Amazon EMR-krypteringssertifikatet.
- Til S3CertsZip, skriv inn S3-URI-en til Amazon EMR-krypteringssertifikatet .zip-fil.
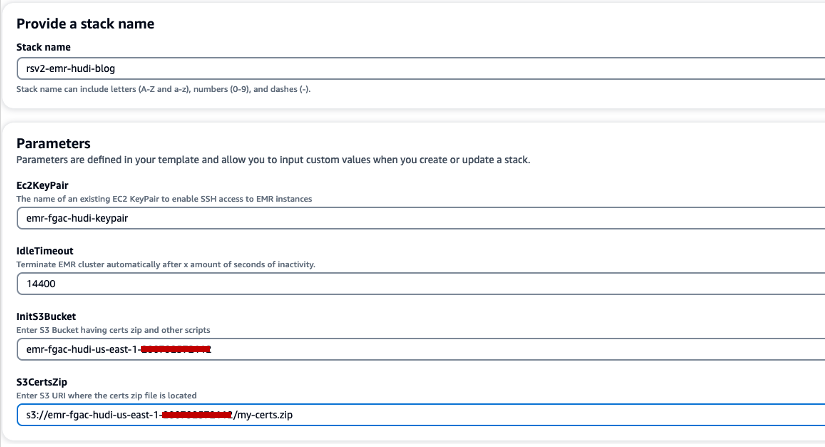
- Plukke ut Jeg erkjenner at AWS CloudFormation kan lage IAM-ressurser med tilpassede navn.
- Velg Lag stabel.
CloudFormation-stabeldistribusjonen tar rundt 10 minutter.
Sett opp Lake Formation for Amazon EMR-integrasjon
Fullfør følgende trinn for å sette opp Lake Formation:
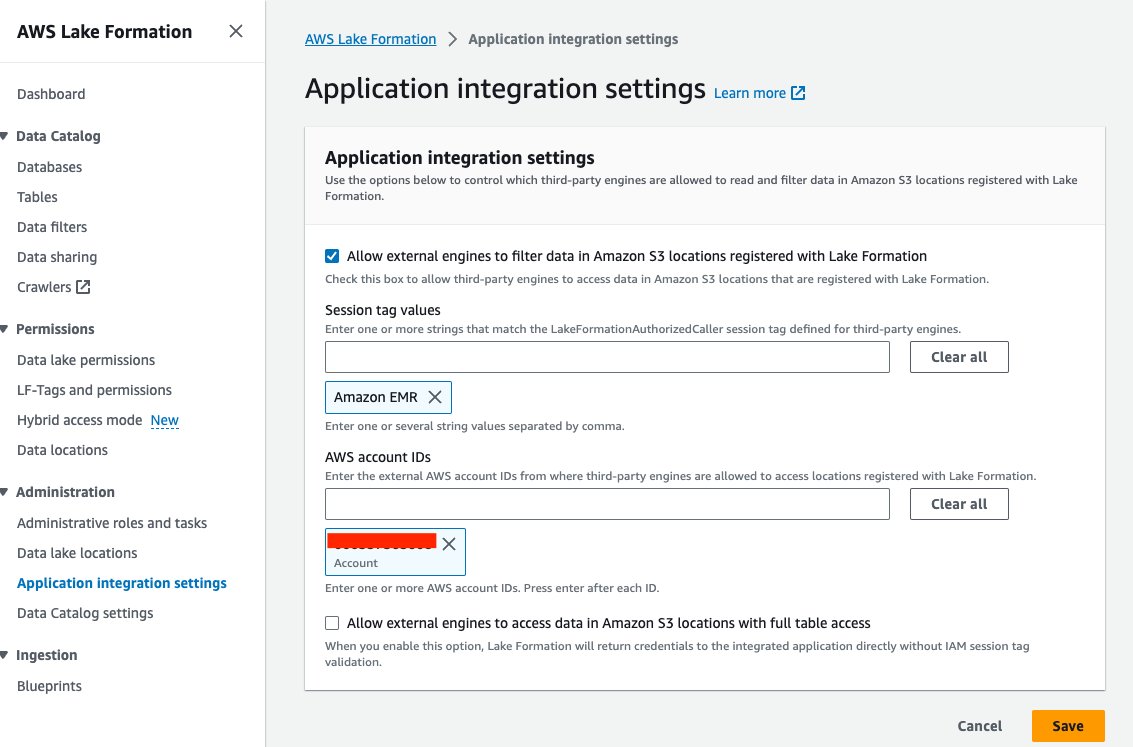
- Velg på Lake Formation-konsollen Innstillinger for applikasjonsintegrasjon etter Administrasjon i navigasjonsruten.
- Plukke ut Tillat eksterne motorer å filtrere data i Amazon S3-lokasjoner registrert hos Lake Formation.
- Velg Amazon EMR forum Verdier for økttagger.
- Skriv inn din AWS-konto-ID for AWS-konto-IDer.
- Velg Spar.
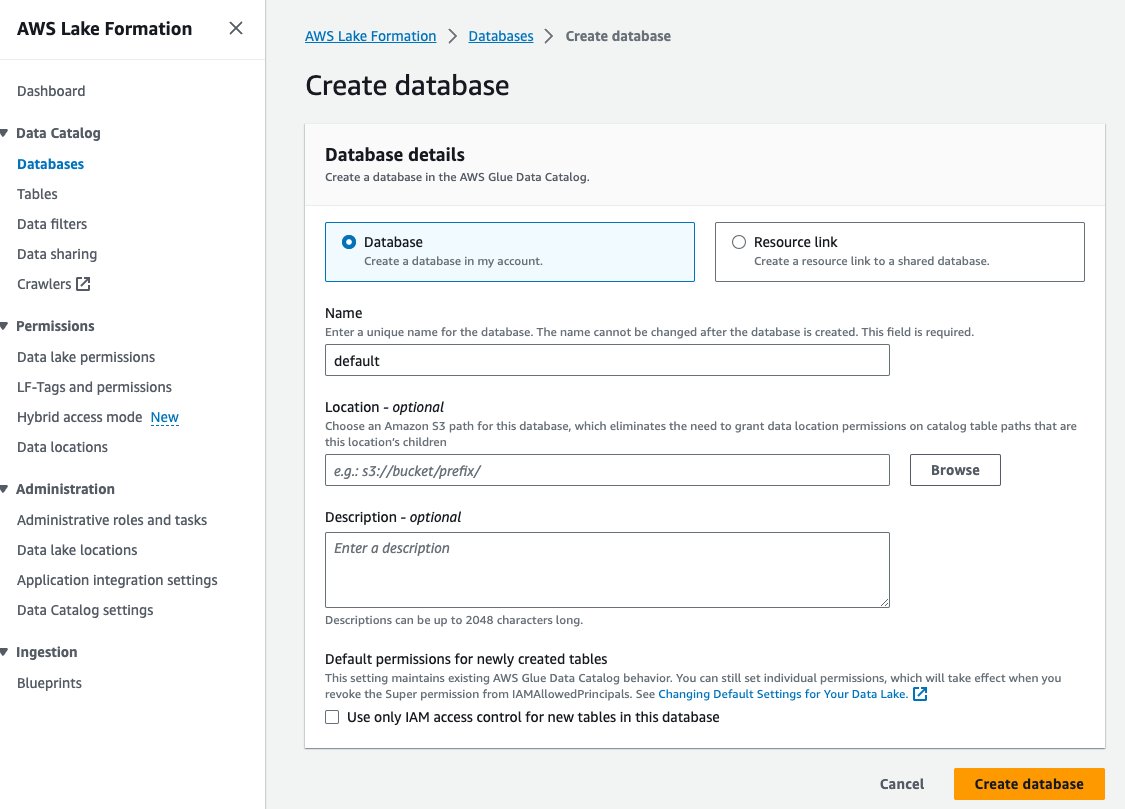
- Velg databaser etter Datakatalog i navigasjonsruten.
- Velg Lag database.
- Til Navn, skriv inn standard.
- Velg Lag database.
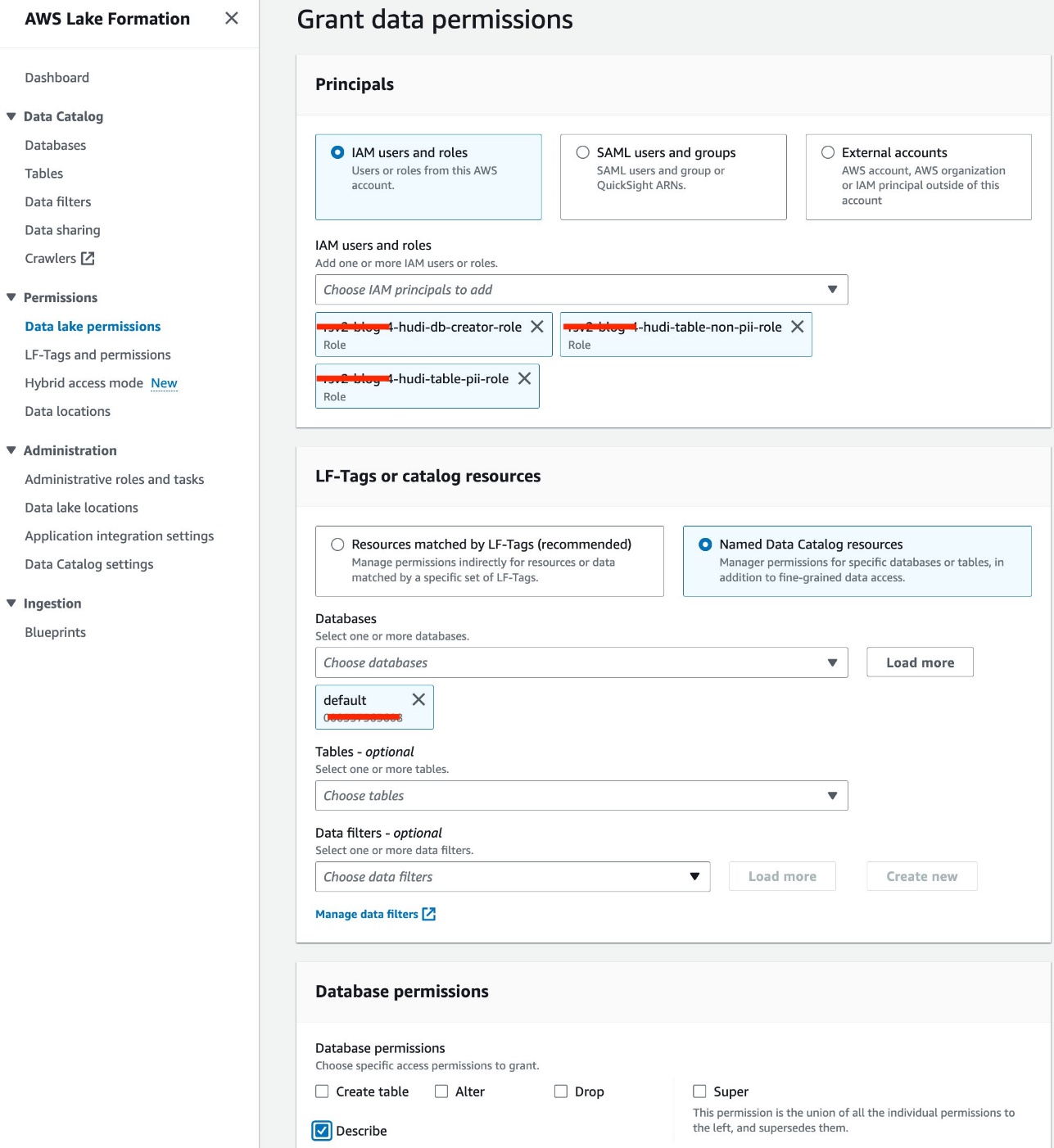
- Velg Datainnsjø-tillatelser etter Tillatelser i navigasjonsruten.
- Velg Grant.
- Plukke ut IAM-brukere og roller.
- Velg dine IAM-roller.
- Til databaser, velg standard.
- Til Database tillatelser, plukke ut Beskriv.
- Velg Grant.
Kopier Hudi JAR-filen til Amazon EMR HDFS
Til bruk Hudi med Jupyter-notatbøker, må du fullføre følgende trinn for EMR-klyngen, som inkluderer kopiering av en Hudi JAR-fil fra Amazon EMR-lokalkatalogen til HDFS-lagringen, slik at du kan konfigurere en Spark-økt til å bruke Hudi:
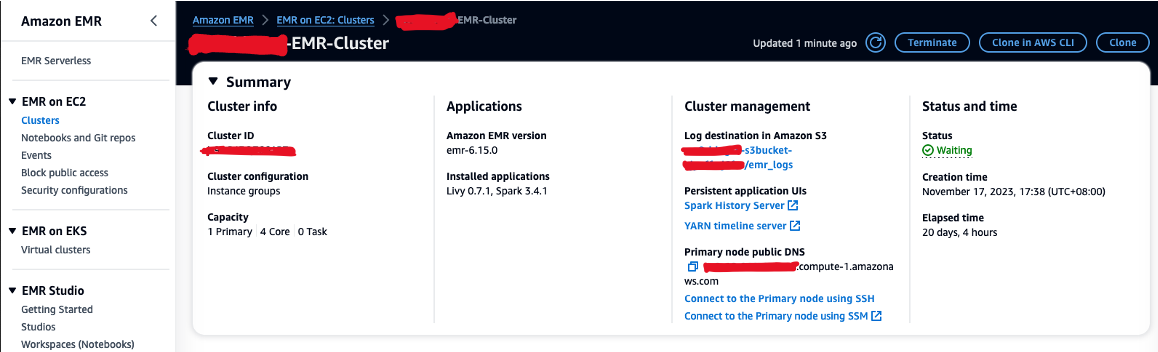
- Autoriser innkommende SSH-trafikk (port 22).
- Kopier verdien for Primær node offentlig DNS (for eksempel ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) fra EMR-klyngen Oppsummering seksjon.
- Gå tilbake til forrige AWS Cloud9-terminal du brukte til å opprette EC2-nøkkelparet.
- Kjør følgende kommando til SSH inn i EMR-primærnoden. Bytt ut plassholderen med ditt EMR DNS-vertsnavn:
- Kjør følgende kommando for å kopiere Hudi JAR-filen til HDFS:
Lag Hudi-databasen og tabellene i Lake Formation
Nå er vi klare til å lage Hudi-databasen og tabellene med FGAC aktivert av EMR-runtime-rollen. De EMR kjøretidsrolle er en IAM-rolle som du kan spesifisere når du sender en jobb eller spørring til en EMR-klynge.
Gi tillatelse til å opprette database
Først, la oss gi Lake Formation-databasen tillatelse til<STACK-NAME>-hudi-db-creator-role:
- Logg på AWS-kontoen din som administrator.
- Velg på Lake Formation-konsollen Administrative roller og oppgaver etter Administrasjon i navigasjonsruten.
- Bekreft at AWS-påloggingsbrukeren din er lagt til som datainnsjø-administrator.
- på Database skaper delen velger Grant.
- Til IAM-brukere og roller, velg
<STACK-NAME>-hudi-db-creator-role. - Til Katalogtillatelser, plukke ut Lag database.
- Velg Grant.
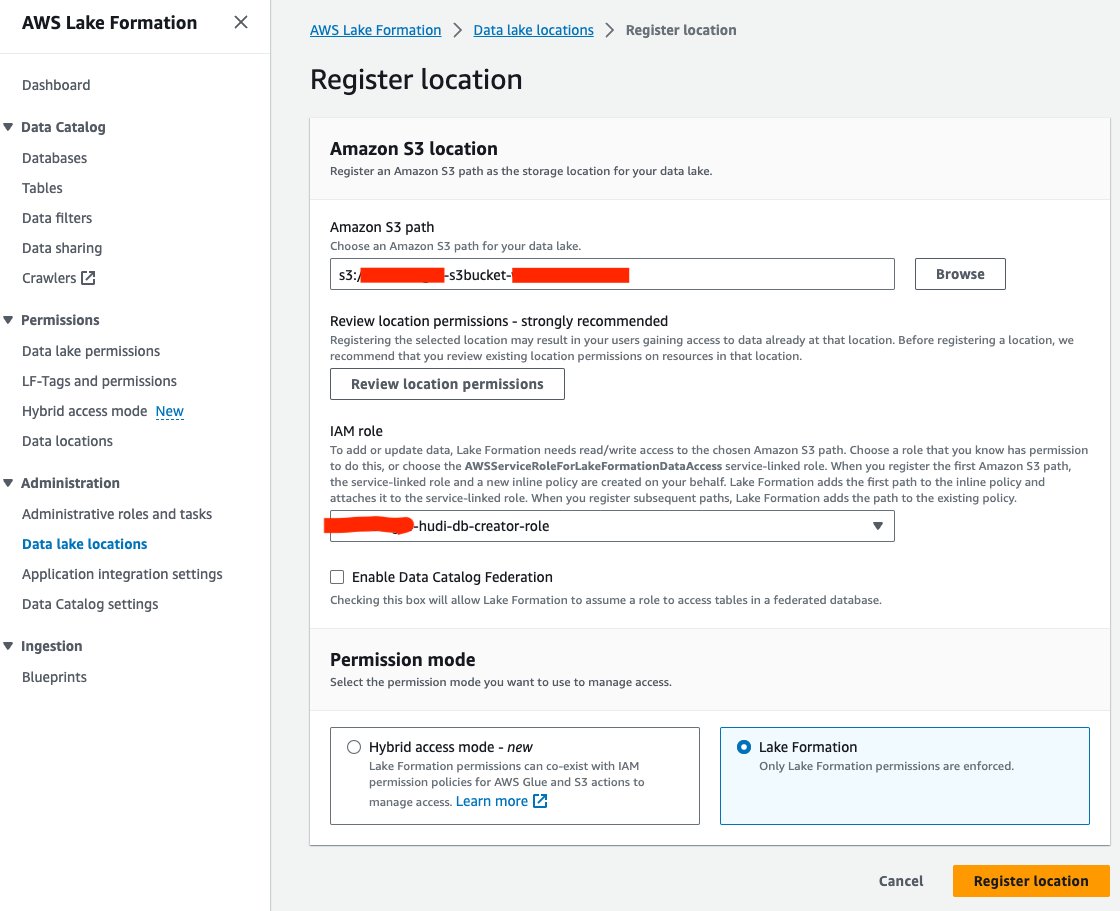
Registrer datainnsjøens plassering
La oss deretter registrere S3-datainnsjøplasseringen i Lake Formation:
- Velg på Lake Formation-konsollen Data lake steder etter Administrasjon i navigasjonsruten.
- Velg Registrer sted.
- Til Amazon S3-bane, Velg Søk og velg data lake S3-bøtten. (
<STACK_NAME>s3bucket-XXXXXXX) opprettet fra CloudFormation-stabelen. - Til IAM-rolle, velg
<STACK-NAME>-hudi-db-creator-role. - Til Tillatelsesmodus, plukke ut Innsjøformasjon.
- Velg Registrer sted.
Gi tillatelse til dataplassering
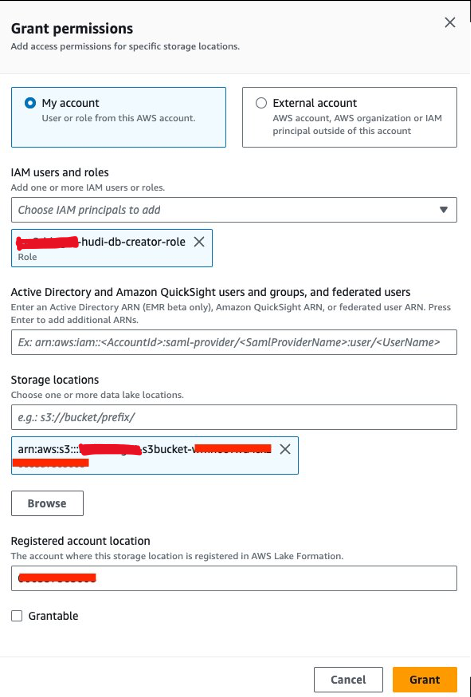
Deretter må vi gi<STACK-NAME>-hudi-db-creator-roledataplasseringstillatelsen:
- Velg på Lake Formation-konsollen Datasteder etter Tillatelser i navigasjonsruten.
- Velg Grant.
- Til IAM-brukere og roller, velg
<STACK-NAME>-hudi-db-creator-role. - Til Oppbevaringssteder, skriv inn S3-bøtten (
<STACK_NAME>-s3bucket-XXXXXXX). - Velg Grant.
Koble til EMR-klyngen
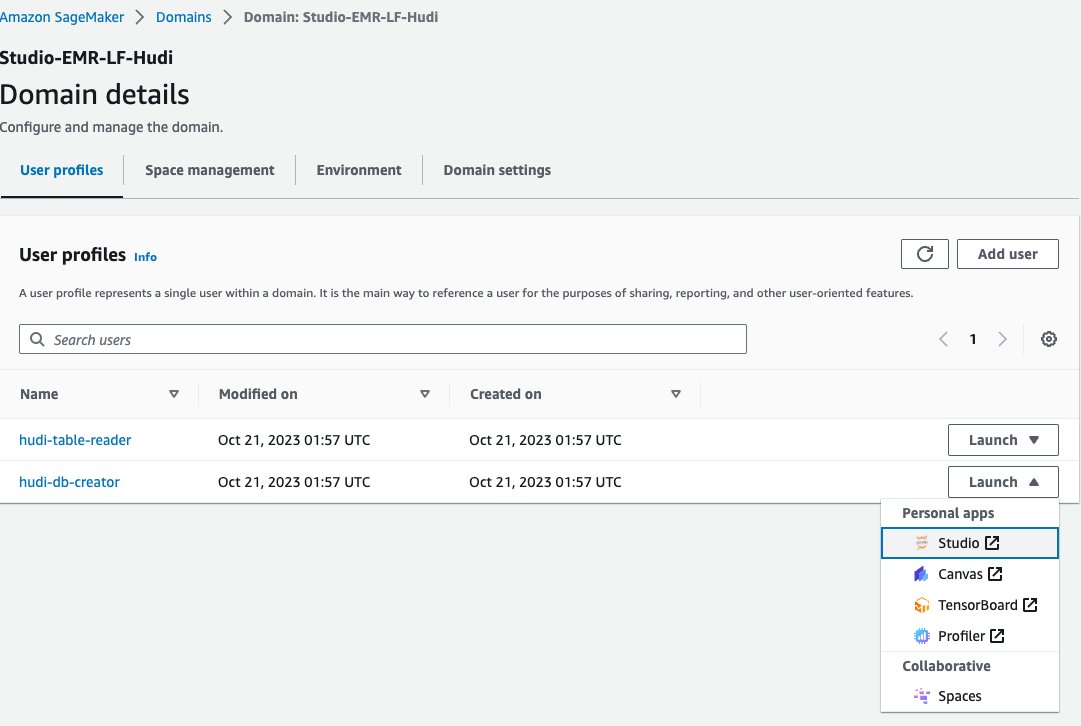
La oss nå bruke en Jupyter-notisbok i SageMaker Studio for å koble til EMR-klyngen med databaseskaperen EMR-runtime-rollen:
- Velg på SageMaker-konsollen Domener i navigasjonsruten.
- Velg domenet
<STACK-NAME>-Studio-EMR-LF-Hudi. - På Start menyen ved siden av brukerprofilen
<STACK-NAME>-hudi-db-creator, velg studie.
- Last ned notatboken rsv2-hudi-db-creator-notebook.
- Velg opplastingsikonet.
- Velg den nedlastede Jupyter-notisboken og velg Åpen.
- Åpne den opplastede notatboken.
- Til Bilde, velg SparkMagic.
- Til Kernel, velg PySpark.
- La de andre konfigurasjonene være standard og velg Plukke ut.
- Velg Cluster for å koble til EMR-klyngen.

- Velg EMR på EC2-klyngen (
<STACK-NAME>-EMR-Cluster) opprettet med CloudFormation-stakken. - Velg Koble.
- Til EMR-utførelsesrolle, velg
<STACK-NAME>-hudi-db-creator-role. - Velg Koble.
Lag database og tabeller
Nå kan du følge trinnene i notatboken for å lage Hudi-databasen og tabellene. De viktigste trinnene er som følger:
- Når du starter den bærbare datamaskinen, konfigurer
“spark.sql.catalog.spark_catalog.lf.managed":"true"å informere Spark om at spark_catalog er beskyttet av Lake Formation. - Lag Hudi-tabeller ved å bruke følgende Spark SQL.
- Sett inn data fra kildetabellen til Hudi-tabellene.
- Sett inn data igjen i Hudi-tabellene.
Spør Hudi-tabellene via Lake Formation med FGAC
Etter at du har opprettet Hudi-databasen og tabellene, er du klar til å spørre tabellene ved hjelp av finmasket tilgangskontroll med Lake Formation. Vi har laget to typer Hudi-tabeller: Copy-On-Write (COW) og Merge-On-Read (MOR). COW-tabellen lagrer data i et kolonneformat (Parquet), og hver oppdatering lager en ny versjon av filer under en skriving. Dette betyr at for hver oppdatering omskriver Hudi hele filen, som kan være mer ressurskrevende, men gir raskere leseytelse. MOR, på den annen side, introduseres for tilfeller der COW kanskje ikke er optimal, spesielt for skrive- eller endringstunge arbeidsbelastninger. I en MOR-tabell, hver gang det er en oppdatering, skriver Hudi bare raden for den endrede posten, noe som reduserer kostnadene og muliggjør skriving med lav latens. Imidlertid kan leseytelsen være tregere sammenlignet med COW-tabeller.
Gi tabelltilgangstillatelse
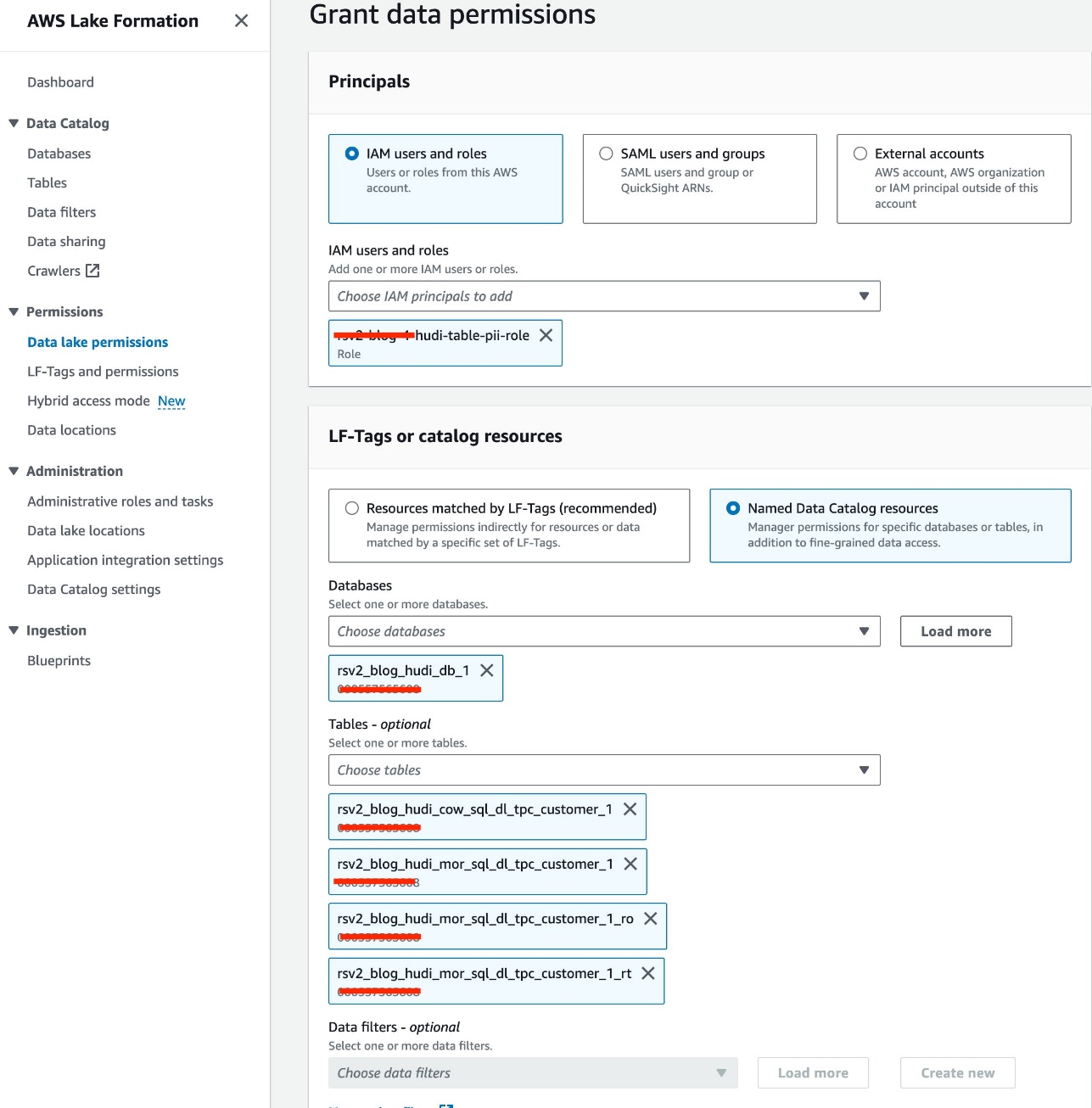
Vi bruker IAM-rollen<STACK-NAME>-hudi-table-pii-rolefor å spørre Hudi COW og MOR som inneholder PII-kolonner. Vi gir først bordets tilgangstillatelse via Lake Formation:
- Velg på Lake Formation-konsollen Datainnsjø-tillatelser etter Tillatelser i navigasjonsruten.
- Velg Grant.
- Velg
<STACK-NAME>-hudi-table-pii-roleforum IAM-brukere og roller. - Velg
rsv2_blog_hudi_db_1database for databaser. - Til tabeller, velg de fire Hudi-tabellene du opprettet i Jupyter-notisboken.
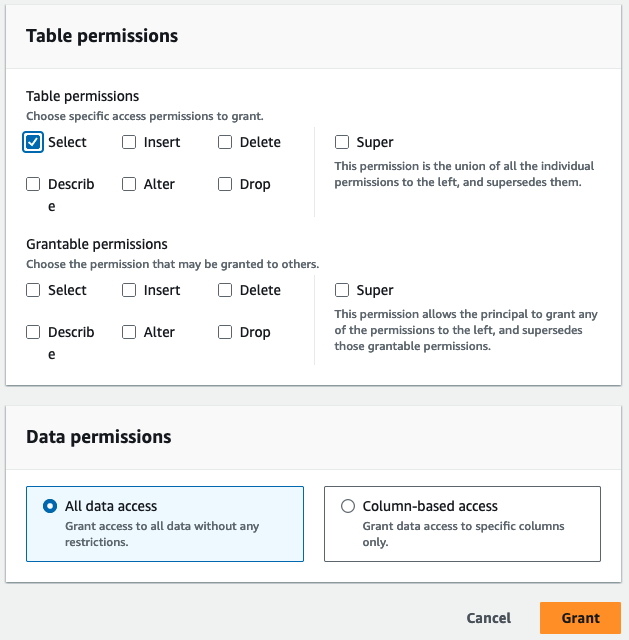
- Til Tabelltillatelser, plukke ut Plukke ut.
- Velg Grant.
Spør PII-kolonner
Nå er du klar til å kjøre notatboken for å spørre Hudi-tabellene. La oss følge lignende trinn som i forrige seksjon for å kjøre notatboken i SageMaker Studio:
- På SageMaker-konsollen, naviger til
<STACK-NAME>-Studio-EMR-LF-Hudidomene. - På Start menyen ved siden av
<STACK-NAME>-hudi-table-readerbrukerprofil, velg studie. - Last opp den nedlastede notatboken rsv2-hudi-table-pii-leser-notatbok.
- Åpne den opplastede notatboken.
- Gjenta trinnene for oppsett av bærbar PC og koble til samme EMR-klynge, men bruk rollen
<STACK-NAME>-hudi-table-pii-role.
I det nåværende stadiet må FGAC-aktivert EMR-klynge spørre Hudis forpliktelsestidskolonne for å utføre inkrementelle spørringer og tidsreiser. Den støtter ikke Sparks "tidsstempel fra" syntaks og Spark.read(). Vi jobber aktivt med å innlemme støtte for begge handlingene i fremtidige Amazon EMR-utgivelser med FGAC aktivert.
Du kan nå følge trinnene i notatboken. Følgende er noen fremhevede trinn:
- Kjør et øyeblikksbildespørring.
- Kjør en inkrementell spørring.
- Kjør en tidsreisespørring.
- Kjør MOR leseoptimaliserte og sanntidstabellspørringer.
Spør Hudi-tabellene med datafiltre på kolonnenivå og radnivå
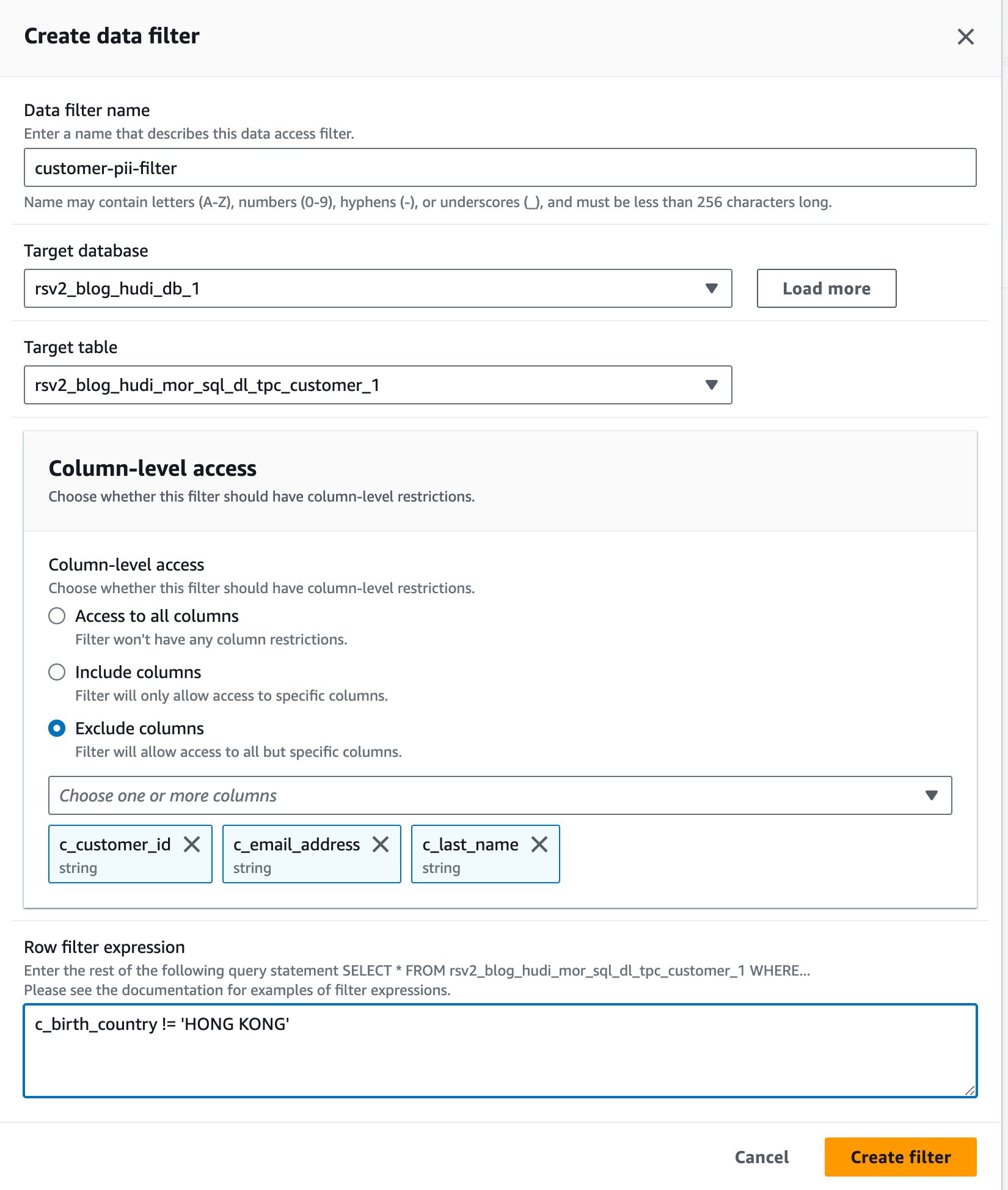
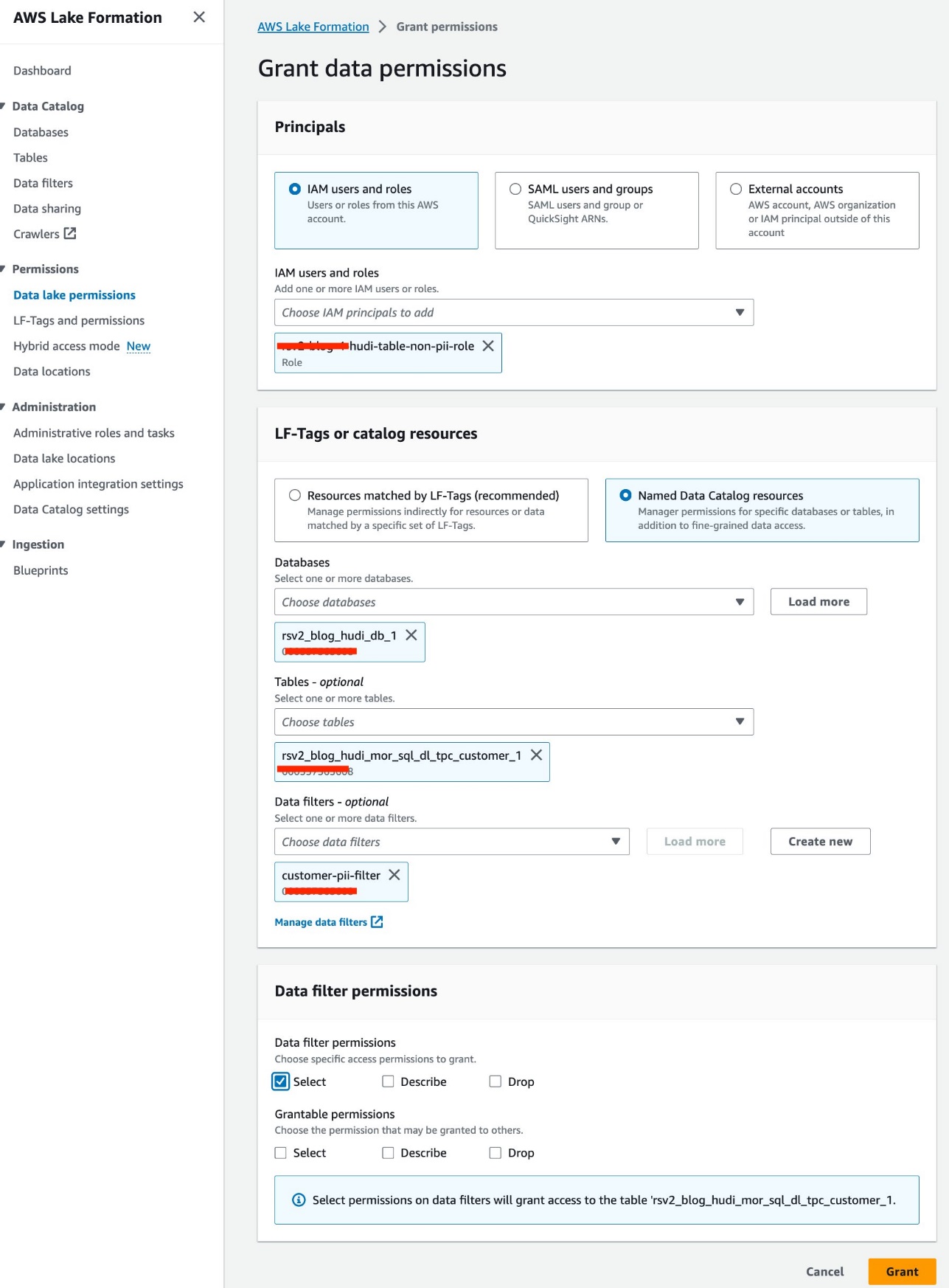
Vi bruker IAM-rollen<STACK-NAME>-hudi-table-non-pii-rolefor å spørre etter Hudi-tabeller. Denne rollen har ikke lov til å spørre etter kolonner som inneholder PII. Vi bruker Lake Formation-datafiltrene på kolonne- og radnivå for å implementere finmasket tilgangskontroll:
- Velg på Lake Formation-konsollen Datafiltre etter Datakatalog i navigasjonsruten.
- Velg Lag et nytt filter.
- Til Datafilternavn, Tast inn
customer-pii-filter. - Velg
rsv2_blog_hudi_db_1forum Måldatabase. - Velg
rsv2_blog_hudi_mor_sql_dl_customer_1forum Måltabell. - Plukke ut Ekskluder kolonner og velg
c_customer_id,c_email_addressogc_last_namekolonner. - Enter
c_birth_country != 'HONG KONG'forum Radfilteruttrykk. - Velg Opprett filter.
- Velg Datainnsjø-tillatelser etter Tillatelser i navigasjonsruten.
- Velg Grant.
- Velg
<STACK-NAME>-hudi-table-non-pii-roleforum IAM-brukere og roller. - Velg
rsv2_blog_hudi_db_1forum databaser. - Velg
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1forum tabeller. - Velg
customer-pii-filterforum Datafiltre. - Til Tillatelser for datafilter, plukke ut Plukke ut.
- Velg Grant.
La oss følge lignende trinn for å kjøre notatboken i SageMaker Studio:
- Naviger til domenet på SageMaker-konsollen
Studio-EMR-LF-Hudi. - På Start meny for
hudi-table-readerbrukerprofil, velg studie. - Last opp den nedlastede notatboken rsv2-hudi-tabell-ikke-pii-leser-notatbok Og velg Åpen.
- Gjenta oppsettstrinnene for den bærbare datamaskinen og koble til samme EMR-klynge, men velg rollen
<STACK-NAME>-hudi-table-non-pii-role.
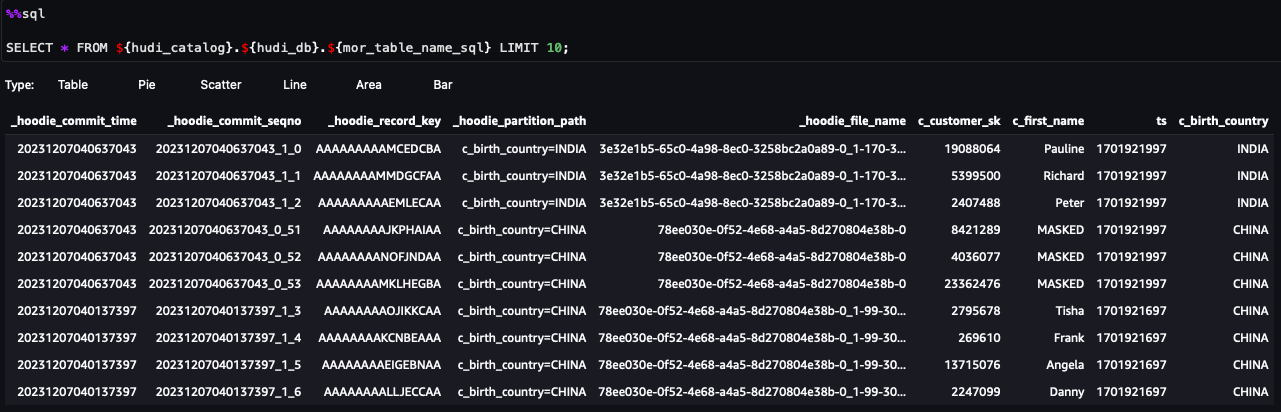
Du kan nå følge trinnene i notatboken. Fra søkeresultatene kan du se at FGAC via Lake Formation-datafilteret er brukt. Rollen kan ikke se PII-kolonnenec_customer_id,c_last_nameogc_email_address. Også radene fraHONG KONGhar blitt filtrert.
Rydd opp
Etter at du er ferdig med å eksperimentere med løsningen, anbefaler vi å rydde opp i ressurser med følgende trinn for å unngå uventede kostnader:
- Slå av SageMaker Studio-appene for brukerprofilene.
EMR-klyngen vil automatisk bli slettet etter verdien for inaktiv timeout.
- Slett Amazon elastisk filsystem (Amazon EFS) volum opprettet for domenet.
- Tøm S3-bøttene opprettet av CloudFormation-stakken.
- Slett stabelen på AWS CloudFormation-konsollen.
konklusjonen
I dette innlegget brukte vi Apachi Hudi, en type OTF-tabeller, for å demonstrere denne nye funksjonen for å håndheve finmasket tilgangskontroll på Amazon EMR. Du kan definere granulære tillatelser i Lake Formation for OTF-tabeller og bruke dem via Spark SQL-spørringer på EMR-klynger. Du kan også bruke transaksjonelle datainnsjøfunksjoner som å kjøre øyeblikksbildespørringer, inkrementelle spørringer, tidsreiser og DML-spørringer. Vær oppmerksom på at denne nye funksjonen dekker alle OTF-bord.
Denne funksjonen lanseres fra og med Amazon EMR utgivelse 6.15 i alt regioner hvor Amazon EMR er tilgjengelig. Med Amazon EMR-integrasjonen med Lake Formation kan du trygt administrere og behandle big data, låse opp innsikt og legge til rette for informert beslutningstaking samtidig som du opprettholder datasikkerhet og styring.
For å lære mer, se Aktiver Lake Formation med Amazon EMR og ta gjerne kontakt med AWS Solutions Architects, som kan være behjelpelige med datareisen din.
om forfatteren
 Raymond Lai er en senior løsningsarkitekt som spesialiserer seg på å imøtekomme behovene til store bedriftskunder. Hans ekspertise ligger i å hjelpe kunder med å migrere intrikate bedriftssystemer og databaser til AWS, konstruere bedriftsdatavarehus og datainnsjøplattformer. Raymond utmerker seg i å identifisere og designe løsninger for AI/ML-brukstilfeller, og han har et spesielt fokus på AWS Serverless-løsninger og Event Driven Architecture-design.
Raymond Lai er en senior løsningsarkitekt som spesialiserer seg på å imøtekomme behovene til store bedriftskunder. Hans ekspertise ligger i å hjelpe kunder med å migrere intrikate bedriftssystemer og databaser til AWS, konstruere bedriftsdatavarehus og datainnsjøplattformer. Raymond utmerker seg i å identifisere og designe løsninger for AI/ML-brukstilfeller, og han har et spesielt fokus på AWS Serverless-løsninger og Event Driven Architecture-design.
 Bin Wang, PhD, er en senior analytisk spesialistløsningsarkitekt ved AWS, med over 12 års erfaring i ML-bransjen, med spesielt fokus på reklame. Han har ekspertise innen naturlig språkbehandling (NLP), anbefalingssystemer, forskjellige ML-algoritmer og ML-operasjoner. Han er dypt lidenskapelig opptatt av å bruke ML/DL og big data-teknikker for å løse problemer i den virkelige verden.
Bin Wang, PhD, er en senior analytisk spesialistløsningsarkitekt ved AWS, med over 12 års erfaring i ML-bransjen, med spesielt fokus på reklame. Han har ekspertise innen naturlig språkbehandling (NLP), anbefalingssystemer, forskjellige ML-algoritmer og ML-operasjoner. Han er dypt lidenskapelig opptatt av å bruke ML/DL og big data-teknikker for å løse problemer i den virkelige verden.
 Aditya Shah er programvareutviklingsingeniør hos AWS. Han er interessert i databaser og datavarehusmotorer og har jobbet med ytelsesoptimaliseringer, sikkerhetsoverholdelse og ACID-samsvar for motorer som Apache Hive og Apache Spark.
Aditya Shah er programvareutviklingsingeniør hos AWS. Han er interessert i databaser og datavarehusmotorer og har jobbet med ytelsesoptimaliseringer, sikkerhetsoverholdelse og ACID-samsvar for motorer som Apache Hive og Apache Spark.
 Melodi Yang er senior Big Data Solution Architect for Amazon EMR hos AWS. Hun er en erfaren analyseleder som jobber med AWS-kunder for å gi veiledning og tekniske råd for beste praksis for å hjelpe deres suksess med datatransformasjon. Hennes interesseområder er rammeverk med åpen kildekode og automatisering, datateknikk og DataOps.
Melodi Yang er senior Big Data Solution Architect for Amazon EMR hos AWS. Hun er en erfaren analyseleder som jobber med AWS-kunder for å gi veiledning og tekniske råd for beste praksis for å hjelpe deres suksess med datatransformasjon. Hennes interesseområder er rammeverk med åpen kildekode og automatisering, datateknikk og DataOps.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 10
- 100
- 11
- 12
- 130
- 15%
- 16
- 17
- 20
- 22
- 400
- 7
- 8
- 9
- a
- Om oss
- adgang
- Logg inn
- anerkjenne
- handlinger
- aktivt
- la til
- I tillegg
- adresser
- admin
- administratorer
- Annonsering
- råd
- Etter
- en gang til
- AI / ML
- algoritmer
- Alle
- tillate
- tillatt
- tillater
- sammen
- også
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- an
- analyse
- analytikere
- analytisk
- analytics
- analyserer
- og
- noen
- Apache
- Apache Spark
- Søknad
- anvendt
- Påfør
- påføring
- arkitekter
- arkitektur
- ER
- områder
- rundt
- AS
- bistå
- Assistanse
- bistå
- anta
- At
- revisjon
- myndighet
- autorisert
- automatisk
- Automatisering
- tilgjengelig
- unngå
- AWS
- AWS Cloud9
- AWS skyformasjon
- AWS Lake formasjon
- tilbake
- basert
- BE
- vært
- bak
- være
- Fordeler
- foruten
- BEST
- Stor
- Store data
- blogger
- skryt
- både
- bygge
- men
- by
- CA
- CAN
- stand
- bære
- bærer
- saken
- saker
- katalog
- catering
- viss
- sertifikat
- sertifikater
- sertifisering
- endring
- endret
- Endringer
- Kina
- Velg
- Rengjøring
- Cloud9
- Cluster
- kode
- Kolonne
- kolonner
- COM
- kombinasjon
- forplikte
- Selskaper
- sammenlignet
- fullføre
- samsvar
- komponent
- komponenter
- Beregn
- datamaskin
- konsept
- forhold
- Gjennomføre
- selvsikkert
- Konfigurasjon
- Koble
- Konsoll
- konstruere
- kontakt
- inneholde
- inneholder
- kontroll
- kontrolleres
- kontroller
- kopiering
- Tilsvarende
- Kostnad
- Kostnader
- land
- dekker
- skape
- opprettet
- skaper
- Opprette
- skaperen
- Gjeldende
- skikk
- Kunder
- dato
- data tilgang
- dataanalyse
- Data Lake
- Dataplattform
- personvern
- databehandling
- datasikkerhet
- datalager
- Database
- databaser
- Beslutningstaking
- dypt
- Misligholde
- definere
- Delta
- demonstrere
- demonstrere
- utplassere
- distribusjon
- utforming
- utforme
- detaljer
- Utvikling
- forskjellig
- distinkt
- diverse
- dns
- do
- gjør
- ikke
- domene
- gjort
- ikke
- ned
- nedlasting
- drevet
- under
- hver enkelt
- ellers
- muliggjøre
- aktivert
- muliggjør
- kryptering
- slutt
- endepunkter
- håndheve
- Motor
- ingeniør
- Ingeniørarbeid
- Motorer
- sikre
- sikrer
- sikrer
- Enter
- Enterprise
- bedriftskunder
- Hele
- Miljø
- Eter (ETH)
- Event
- Hver
- eksempel
- gjennomføring
- finnes
- erfaring
- erfaren
- ekspertise
- leting
- strekker
- utvendig
- tilrettelegging
- raskere
- Trekk
- Egenskaper
- føler
- filet
- Filer
- filtrere
- filtrering
- filtre
- Først
- Fokus
- fokuserer
- følge
- etter
- følger
- Til
- format
- formasjon
- fire
- Rammeverk
- rammer
- Gratis
- fra
- Innfri
- fullt
- funksjonalitet
- videre
- framtid
- Gevinst
- generert
- styresett
- styrt
- innvilge
- sterkt
- Gruppe
- Gruppens
- veiledning
- hånd
- Ha
- he
- her
- her.
- Fremhevet
- hans
- historisk
- historie
- Hive
- Hong
- Hong Kong
- hus
- Hvordan
- Hvordan
- Men
- HTML
- http
- HTTPS
- IAM
- ICON
- ID
- Tanken
- identifisere
- identifisering
- Idle
- if
- illustrerer
- iverksette
- forbedre
- in
- inkluderer
- Inkludert
- innlemme
- inkrementell
- india
- industri
- informere
- informasjon
- informert
- inngang
- innsikt
- integrert
- Integrering
- integrering
- interaktiv
- interessert
- interesser
- Interface
- intern
- inn
- innviklet
- introdusert
- Introduserer
- utstedelse
- IT
- DET ER
- Jobb
- Jobb
- reise
- jpg
- Jupyter Notebook
- nøkkel
- Kong
- innsjø
- Språk
- stor
- Siste
- lansere
- lansert
- leder
- LÆRE
- nivåer
- ligger
- i likhet med
- BEGRENSE
- linjer
- lokal
- plassering
- steder
- Logg inn
- større
- gjøre
- administrer
- fikk til
- ledelse
- leder
- mange
- Kan..
- midler
- mekanismer
- møte
- Meny
- metadata
- kunne
- Migrere
- minutter
- ML
- ML-algoritmer
- modifisert
- mer
- bevegelse
- navn
- navn
- Naturlig
- Naturlig språk
- Natural Language Processing
- Naviger
- Navigasjon
- Trenger
- behov
- Ny
- ny funksjon
- nylig
- neste
- nlp
- node
- note
- bærbare
- notatbøker
- nå
- gjenstander
- of
- ofte
- on
- ONE
- bare
- åpen
- åpen kildekode
- openssl
- Drift
- optimal
- Optimalisere
- Alternativ
- alternativer
- or
- rekkefølge
- organisasjon
- Annen
- ut
- enn
- par
- brød
- Spesielt
- spesielt
- lidenskapelig
- betalende
- ytelse
- utfører
- tillatelse
- tillatelser
- personlig
- phd
- PII
- placeholder
- plattform
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- vær så snill
- i tillegg til
- poeng
- Populær
- besitter
- Post
- praksis
- bevarer
- forrige
- primære
- privatliv
- privilegium
- privilegier
- problemer
- prosess
- prosessering
- Produksjon
- Profil
- Profiler
- bevis
- proof of concept
- beskyttet
- beskyttelse
- gi
- gir
- gi
- offentlig
- formål
- spørsmål
- Lese
- Lesning
- klar
- virkelige verden
- sanntids
- anbefaler
- rekord
- utvinning
- reduserer
- redusere
- referere
- refererer
- Gjenspeiler
- region
- registrere
- registrert
- forskrifter
- slipp
- Utgivelser
- relevant
- erstatte
- påkrevd
- Krav
- ressurs
- ressurskrevende
- Ressurser
- resultere
- Resultater
- rettigheter
- Rolle
- roller
- RAD
- rsa
- regler
- Kjør
- rennende
- sagemaker
- samme
- Spar
- Seksjon
- sikre
- sikret
- sikkerhet
- se
- Søke
- velg
- senior
- sensitive
- server
- server~~POS=TRUNC
- Tjenester
- Session
- sett
- sett
- innstillinger
- oppsett
- hun
- undertegne
- betydelig
- lignende
- Enkelt
- forenkler
- forenkle
- siden
- Snapshot
- So
- Software
- programvareutvikling
- løsning
- Solutions
- LØSE
- noen
- kilde
- Spark
- spesialist
- spesialisert
- SQL
- stable
- Scene
- Begynn
- startet
- Start
- uttalelser
- Steps
- lagring
- butikker
- Strategi
- String
- studio
- send
- subnett
- suksess
- slik
- SAMMENDRAG
- støtte
- Støtter
- sikker
- syntaks
- Systemer
- bord
- TAG
- tar
- Teknisk
- teknikker
- mal
- terminal
- Det
- De
- Kilden
- deres
- Dem
- deretter
- Der.
- Disse
- de
- denne
- tre
- Gjennom
- tid
- tidsreiser
- tidslinje
- til
- Sporing
- Transaksjonen
- transaksjonell
- Transformation
- transitt
- reiser
- sant
- klarert
- Ts
- to
- typen
- typer
- ui
- etter
- Uventet
- ukjent
- opplåsing
- Oppdater
- oppdatert
- opprettholdelse
- lastet opp
- URI
- bruke
- bruk sak
- brukt
- Bruker
- Brukere
- ved hjelp av
- validerer
- verdi
- ulike
- versjon
- av
- synlighet
- volum
- Warehouse
- lager
- we
- web
- webtjenester
- når
- mens
- hvilken
- mens
- HVEM
- vil
- med
- innenfor
- arbeidet
- arbeid
- skrive
- år
- du
- Din
- zephyrnet
- null
- Zip