I dagens verden administrerer kunder enorme mengder data i deres Amazon enkel lagringstjeneste (Amazon S3) datainnsjøer, som krever kronglete datarørledninger for kontinuerlig å forstå endringene i dataoppsettet og gjøre dem tilgjengelige for forbrukende systemer. AWS Lim crawlere gir en enkel måte å katalogisere data i AWS Glue Data Catalog som fjerner de tunge løftene når det kommer til skjemaadministrasjon og dataklassifisering. AWS Glue-crawlere trekker ut dataskjemaet og partisjonene fra Amazon S3 for automatisk å fylle ut datakatalogen, og holde metadataene oppdatert.
Men med data som vokser eksponentielt over tid, kan antallet partisjoner i en gitt tabell vokse betydelig. Fordi analysetjenester som Amazonas Athena spørre en tabell som inneholder millioner av partisjoner, øker tiden som trengs for å hente partisjonen og kan føre til at spørringens kjøretid øker.
I dag har AWS Glue-crawler-støtten blitt utvidet for automatisk å legge til partisjonsindekser for nylig oppdagede tabeller for å optimalisere spørringsbehandlingen på det partisjonerte datasettet. Nå, når robotsøkeprogrammet oppretter en ny datakatalogtabell under en robotsøking, oppretter den også en partisjonsindeks som standard, med den største permutasjonen av alle numeriske og strengtype-partisjonskolonner som nøkler. Datakatalogen oppretter deretter en søkbar indeks basert på disse nøklene, noe som reduserer tiden som kreves for å hente og filtrere partisjonsmetadata på tabeller med millioner av partisjoner. Opprettelsen av partisjonsindekser fordeler analysearbeidsbelastningene som kjører på Athena, Amazon EMR, Amazon Redshift Spectrum, og AWS Lim.
I dette innlegget beskriver vi hvordan du oppretter partisjonsindekser med en AWS Glue-crawler og sammenligner forbedringen av søkeytelsen når du får tilgang til de gjennomsøkte dataene med og uten en partisjonsindeks fra Athena.
Løsningsoversikt
Vi bruker en AWS skyformasjon mal for å lage våre løsningsressurser. I de følgende trinnene viser vi hvordan du konfigurerer AWS Glue-søkeroboten til å lage en partisjonsindeks ved å bruke enten AWS Glue-konsollen eller AWS kommandolinjegrensesnitt (AWS CLI). Deretter sammenligner vi forbedringene av spørringsytelsen ved å bruke Athena.
Forutsetninger
For å følge med på dette innlegget må du ha tilgang til en AWS identitets- og tilgangsadministrasjon (IAM) administratorrolle for å opprette ressurser ved hjelp av AWS CloudFormation.
Sett opp løsningsressursene dine
CloudFormation-malen genererer følgende ressurser:
- IAM roller og policyer
- En AWS Glue-database for å holde skjemaet
- En AWS Glue-crawler som peker til et svært partisjonert datasett
- En Athena-arbeidsgruppe og bøtte for å lagre søkeresultater
Fullfør følgende trinn for å konfigurere løsningsressursene:
- Logg deg inn på AWS-administrasjonskonsoll som IAM-administrator.
- Velg Start Stack for å distribuere CloudFormation-malen:

- Til Databasenavn, beholder standard
blog_partition_index_crawlerdb.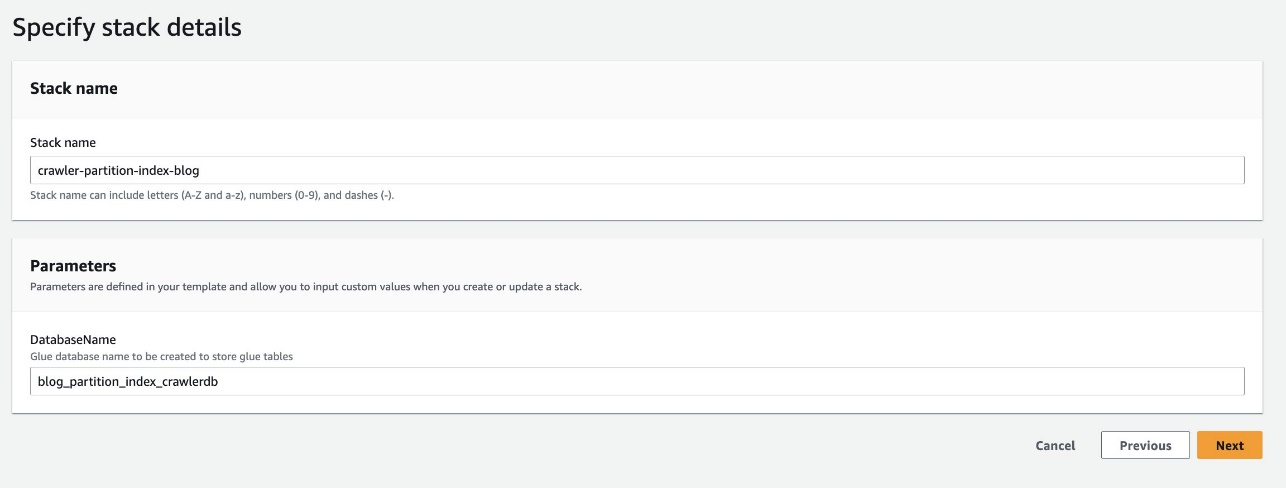
- Velg neste.
- Gå gjennom detaljene på den siste siden og velg Jeg erkjenner at AWS CloudFormation kan skape IAM-ressurser.
- Velg Lag stabel.
- Når stabelen er fullført, på AWS CloudFormation-konsollen, naviger til Utganger fanen på stabelen.
- Noter ned verdier på
DatabaseNameogGlueCrawlerName.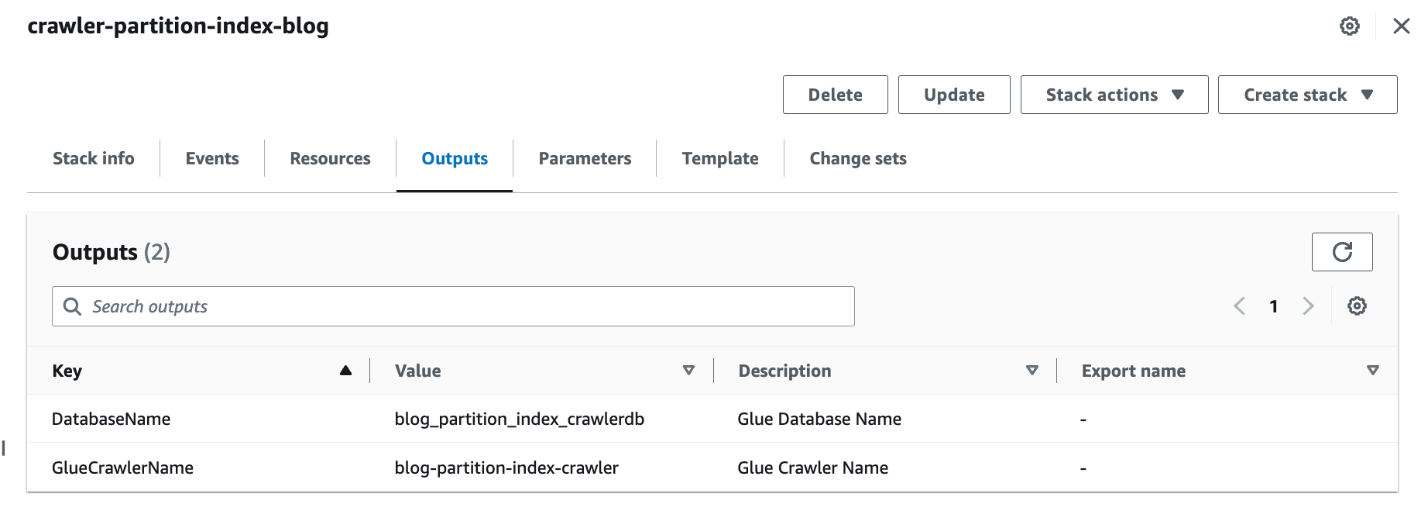
Noen av ressursene som denne stabelen distribuerer pådrar seg kostnader når de er i bruk.
Rediger og kjør AWS Glue-crawler
For å konfigurere og kjøre AWS Glue-crawler, fullfør følgende trinn:
- Velg på AWS Lim-konsollen crawlers i navigasjonsruten.
- Finn
crawler blog-partition-index-crawlerOg velg Rediger.
- på Angi utgang og planlegging delen, under Avanserte alternativer, plukke ut Lag partisjonsindekser automatisk.
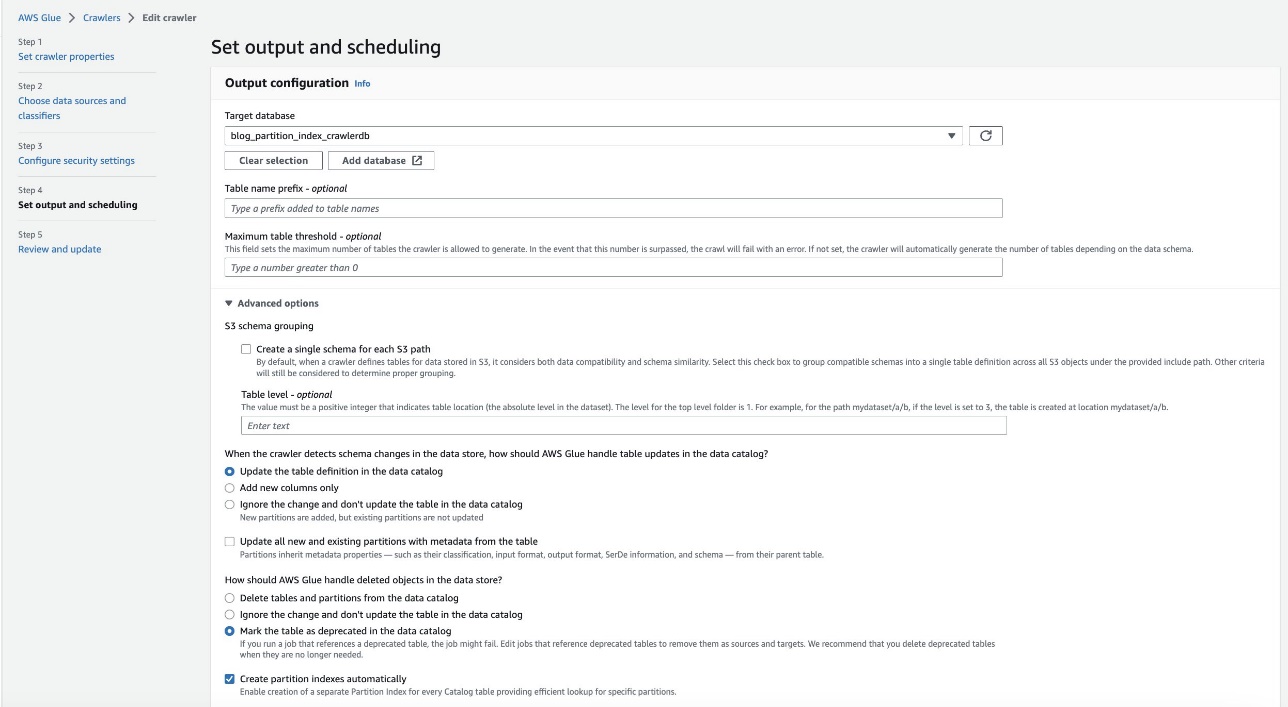
- Se gjennom og oppdater søkerobotinnstillingene.
Alternativt kan du konfigurere robotsøkeprogrammet ved å bruke AWS CLI (oppgi din IAM-rolle og region):
- Kjør nå søkeroboten og kontroller at robotsøkingen er fullført.
Dette er svært partisjonert datasett og vil ta omtrent 90 minutter å fullføre.
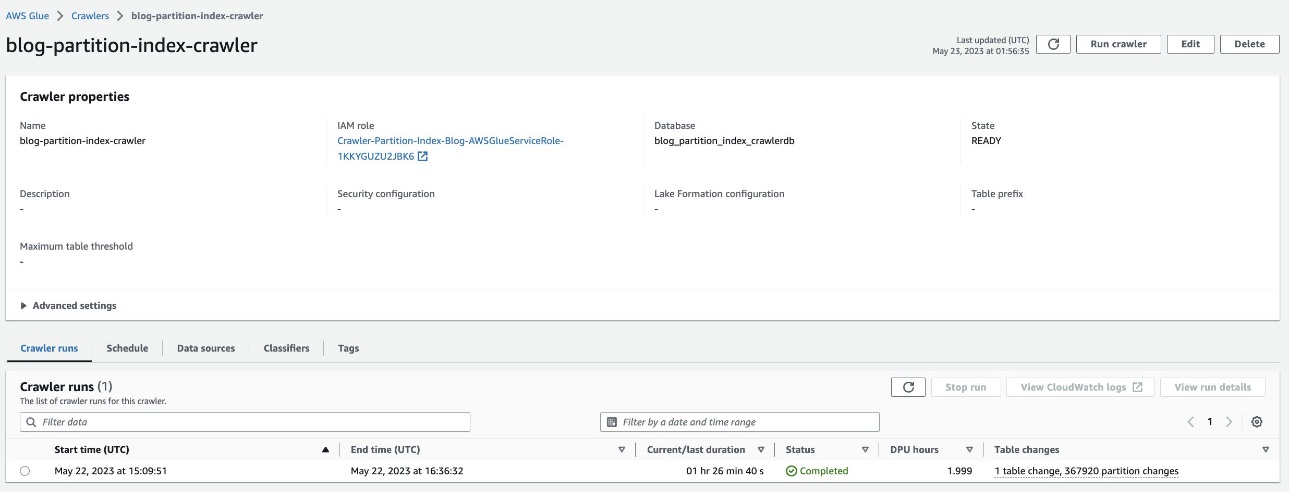
Bekreft den partisjonerte tabellen
I AWS Glue-databasen blog_partition_index_crawlerdb, bekreft at tabellen highly_partitioned_table er opprettet.
Som standard bestemmer søkeroboten en indeks basert på den største permutasjonen av partisjonskolonner med gyldige kolonnetyper i samme rekkefølge av partisjonskolonner, som enten er numeriske eller strenger. For tabellen opprettet av søkeroboten (highly_partitioned_table), har vi partisjonskolonner year (Streng), month (Streng), day (streng), og hour (streng).
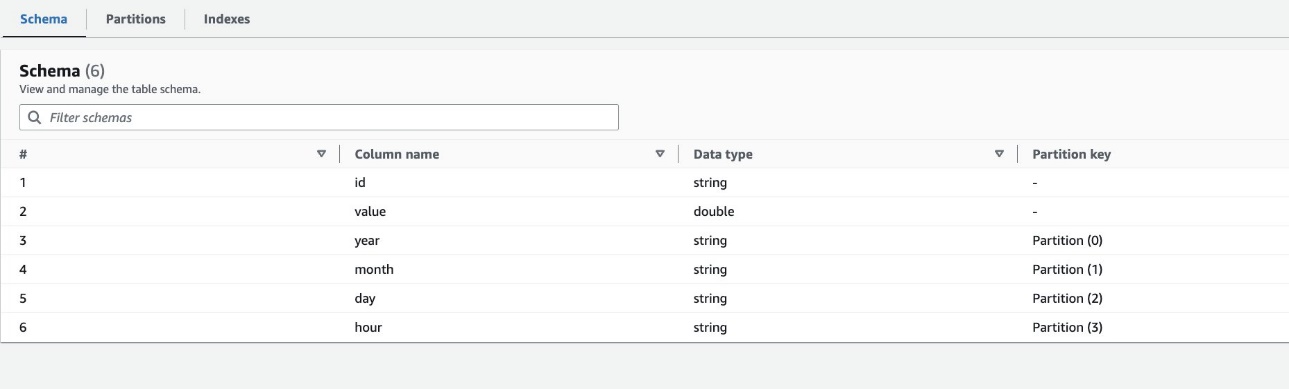
Basert på denne definisjonen opprettet robotsøkeprogrammet en indeks på permutasjonen av år, måned, dag og time. Søkeroboten opprettet indeksene med prefiks crawler_ på enhver partisjonsindeks som er opprettet som standard.
Bekreft det samme ved å navigere til tabellen highly_partitioned_table på AWS Glue-konsollen og velge Indekser fanen.
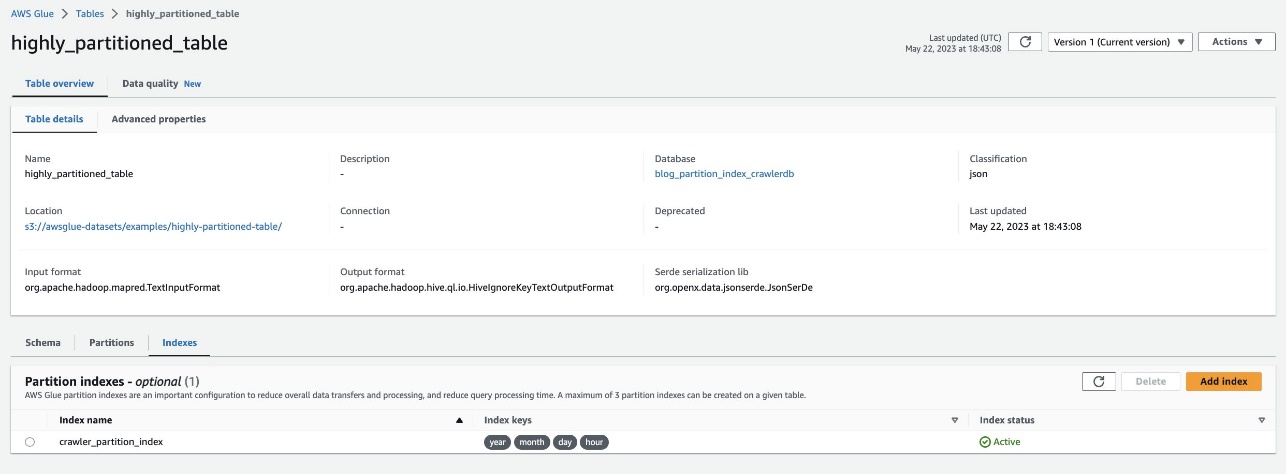
Søkeroboten var i stand til å gjennomsøke S3-datakilden og fylle ut partisjonsindeksene for tabellen.
Sammenlign søkeytelsesforbedringene ved å bruke Athena
Først spør vi tabellen i Athena uten å bruke partisjonsindeksen. For å verifisere tabellene med Athena, fullfør følgende trinn:
- Velg på Athena-konsollen
crawler-primary-workgroupsom Athena-arbeidsgruppen og velg Anerkjenne.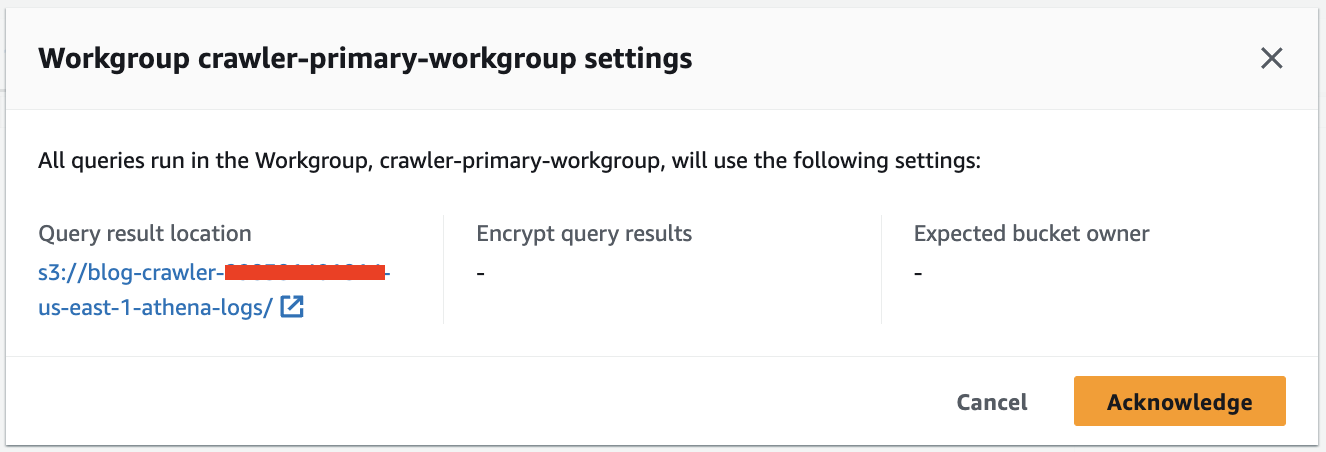
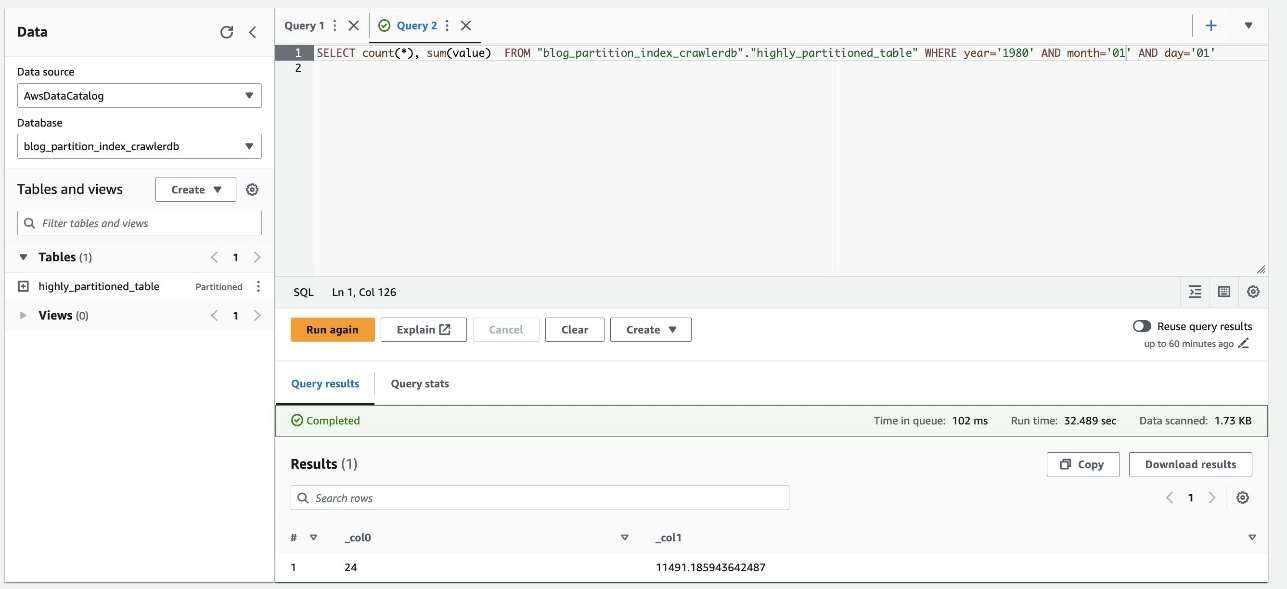
- Kjør følgende spørring:
Følgende skjermbilde viser spørringen tok omtrent 32 sekunder uten filtrering aktivert ved hjelp av partisjonsindeksen.
- Nå aktiverer vi partisjonsindeksen på Athena-spørringen:
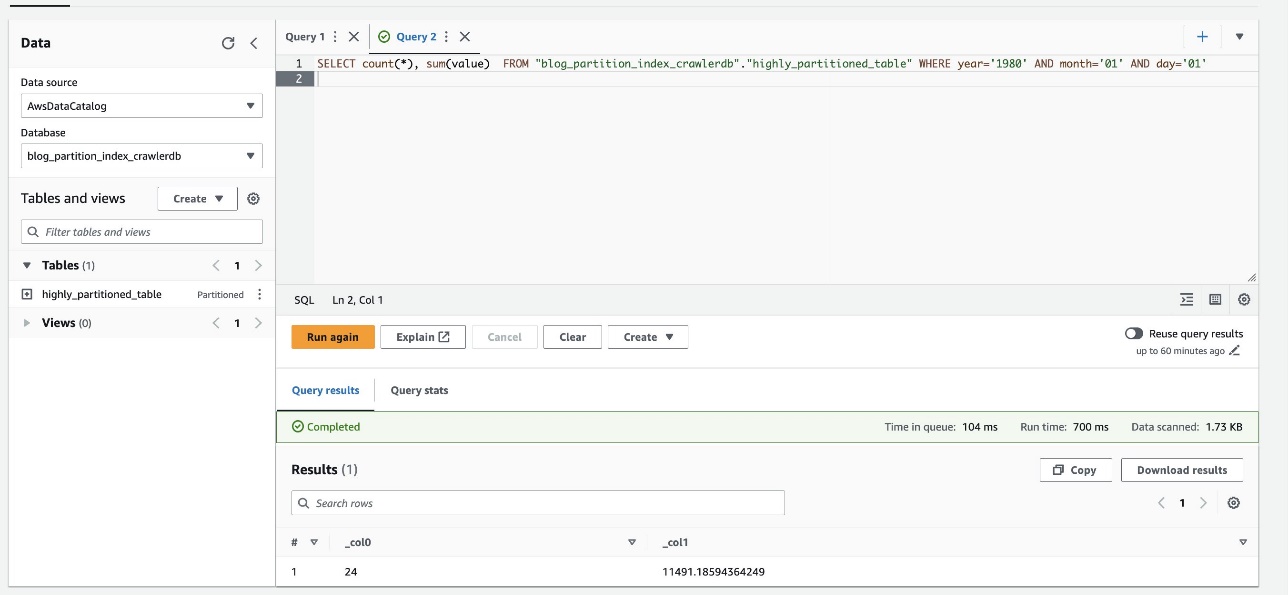
- Kjør følgende spørring igjen og noter kjøretiden:
Følgende skjermbilde viser at spørringen tok bare 700 millisekunder, noe som er mye raskere med filtrering aktivert ved hjelp av partisjonsindeksen.
Rydd opp
For å unngå uønskede belastninger på AWS-kontoen din, kan du slette AWS-ressursene:
- Logg på CloudFormation-konsollen som IAM-administratoren som ble brukt til å lage CloudFormation-stakken.
- Slett CloudFormation-stakken du opprettet.
konklusjonen
I dette innlegget forklarte vi hvordan du konfigurerer en AWS-crawler for å lage partisjonsindekser og sammenlignet spørringsytelsen når du får tilgang til dataene med indekser fra Athena.
Hvis ingen partisjonsindekser er til stede på tabellen, laster AWS Glue alle partisjonene i tabellen, og filtrerer deretter de innlastede partisjonene, noe som resulterer i ineffektiv henting av metadata. Analysetjenester som Redshift Spectrum, Amazon EMR og AWS Glue ETL Spark DataFrames kan nå bruke indekser for å hente partisjoner, noe som resulterer i betydelig søkeytelse.
For mer informasjon om partisjonsindekser og søkeytelse på tvers av ulike analytiske motorer, se Forbedre Amazon Athena-spørringsytelsen ved å bruke AWS Glue Data Catalog-partisjonsindekser og Forbedre ytelsen til spørring ved å bruke AWS Lim-partisjonsindekser.
Spesiell takk til alle som har bidratt til lanseringen av denne robotfunksjonen: Yuhang Chen, Kyle Duong og Mita Gavade.
Om forfatterne
 Srividya Parthasarathy er senior Big Data Architect på AWS Lake Formation-teamet. Hun liker å bygge datanettløsninger og dele dem med samfunnet.
Srividya Parthasarathy er senior Big Data Architect på AWS Lake Formation-teamet. Hun liker å bygge datanettløsninger og dele dem med samfunnet.
 Sandeep Adwankar er senior teknisk produktsjef i AWS. Basert i California Bay Area jobber han med kunder over hele verden for å oversette forretningsmessige og tekniske krav til produkter som gjør det mulig for kundene å forbedre hvordan de administrerer, sikrer og får tilgang til data.
Sandeep Adwankar er senior teknisk produktsjef i AWS. Basert i California Bay Area jobber han med kunder over hele verden for å oversette forretningsmessige og tekniske krav til produkter som gjør det mulig for kundene å forbedre hvordan de administrerer, sikrer og får tilgang til data.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- EVM Finans. Unified Interface for desentralisert økonomi. Tilgang her.
- Quantum Media Group. IR/PR forsterket. Tilgang her.
- PlatoAiStream. Web3 Data Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- : har
- :er
- :hvor
- $OPP
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- I stand
- adgang
- Tilgang
- Logg inn
- anerkjenne
- tvers
- legge til
- admin
- en gang til
- Alle
- langs
- også
- Amazon
- Amazonas Athena
- Amazon EMR
- Amazon Web Services
- beløp
- an
- Analytisk
- analytics
- og
- noen
- ca
- ER
- AREA
- rundt
- AS
- At
- automatisk
- tilgjengelig
- unngå
- AWS
- AWS skyformasjon
- AWS Lim
- AWS Lake formasjon
- basert
- bukt
- fordi
- vært
- Fordeler
- Stor
- Store data
- Bygning
- virksomhet
- by
- california
- CAN
- katalog
- Årsak
- Endringer
- avgifter
- chen
- Velg
- velge
- klassifisering
- Kolonne
- kolonner
- kommer
- samfunnet
- sammenligne
- sammenlignet
- fullføre
- Konsoll
- kontinuerlig
- bidratt
- Kostnader
- crawler
- skape
- opprettet
- skaper
- Opprette
- skaperverket
- Gjeldende
- Kunder
- dato
- data tilgang
- Data Lake
- Database
- dag
- Misligholde
- demonstrere
- utplassere
- Distribueres
- beskrive
- detaljer
- bestemmes
- oppdaget
- ned
- under
- effektivt
- enten
- muliggjøre
- aktivert
- Motorer
- Eter (ETH)
- alle
- utvidet
- forklarte
- eksponentielt
- trekke ut
- trekke ut dataene
- raskere
- Trekk
- filtrere
- filtrering
- filtre
- slutt~~POS=TRUNC
- følge
- etter
- Til
- formasjon
- fra
- genererer
- gitt
- globus
- Grow
- Økende
- Ha
- he
- tung
- tung løfting
- svært
- hold
- time
- Hvordan
- Hvordan
- HTML
- http
- HTTPS
- IAM
- Identitet
- forbedre
- forbedring
- forbedringer
- in
- Øke
- øker
- indeks
- indekser
- ineffektiv
- informasjon
- inn
- IT
- jpg
- Hold
- holde
- nøkler
- innsjø
- største
- lansere
- Layout
- løfte
- i likhet med
- linje
- laster
- gjøre
- administrer
- ledelse
- leder
- mesh
- metadata
- kunne
- millioner
- minutter
- Måned
- mer
- mye
- må
- Naviger
- navigere
- Navigasjon
- nødvendig
- Ny
- nylig
- Nei.
- nå
- Antall
- of
- on
- bare
- Optimalisere
- or
- rekkefølge
- vår
- produksjon
- enn
- side
- brød
- banen
- ytelse
- plato
- Platon Data Intelligence
- PlatonData
- Post
- presentere
- prosessering
- Produkt
- Produktsjef
- Produkter
- gi
- redusere
- region
- påkrevd
- Krav
- Krever
- Ressurser
- resulterende
- Resultater
- Rolle
- roller
- Kjør
- rennende
- samme
- sekunder
- Seksjon
- sikre
- senior
- Tjenester
- sett
- innstillinger
- deling
- hun
- Viser
- signifikant
- betydelig
- Enkelt
- løsning
- Solutions
- kilde
- Spark
- Spectrum
- stable
- Steps
- lagring
- oppbevare
- rett fram
- String
- vellykket
- støtte
- Systemer
- bord
- Ta
- lag
- Teknisk
- mal
- Takk
- Det
- De
- deres
- Dem
- deretter
- Disse
- de
- denne
- tid
- til
- dagens
- tok
- oversette
- sant
- typen
- typer
- etter
- forstå
- uønsket
- Oppdater
- bruke
- brukt
- ved hjelp av
- bruke
- verdi
- Verdier
- ulike
- enorme
- verifisere
- versjon
- var
- Vei..
- we
- web
- webtjenester
- når
- hvilken
- HVEM
- vil
- med
- uten
- arbeidsgruppe
- virker
- verden
- yaml
- år
- du
- Din
- zephyrnet