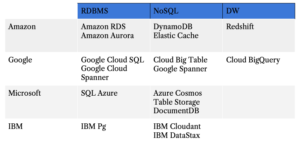
I dag er AI og ML overalt.
Enten det er alle som leker med ChatGPT (den raskeste vedtatt app i historien) eller et nylig forslag å legge til en fjerde farge til trafikklys for å gjøre overgangen til selvkjørende biler tryggere, har AI grundig mettet livene våre. Selv om AI kan virke mer tilgjengelig enn noen gang, har kompleksiteten til AI-modeller økt eksponentielt.
AI-modeller faller inn i hovedkategoriene svart boks og hvit boks-modeller. Black box-modeller tar en beslutning uten forklaring, mens white box-modeller gir et resultat basert på reglene som ga det resultatet.
Ettersom vi fortsetter å bevege oss mot en verden av dype læringsmetoder, er de fleste i stor grad graviterende mot svarte boks-modeller.
Problemet med den tilnærmingen? Black box-modeller (som de som er bygget i datasyn) kan ikke konsumeres direkte. Dette blir ofte referert til som black box-problemet. Selv om omskolering av svarte boks-modeller kan gi brukere en hoppstart, blir det vanskeligere å tolke modellen og forstå resultatene av svarte boks-modellen etter hvert som modellene øker i kompleksitet.
En taktikk for å løse problemet med black box er å lage en veldig skreddersydd og forklarlig modell.
Men dette er ikke retningen verden beveger seg.
Der modellforklaring slutter, begynner dataforklaring
Forklarbarhet er avgjørende fordi det forbedrer modellens gjennomsiktighet, nøyaktighet og rettferdighet og kan også forbedre tilliten til AI. Mens modellforklarbarhet er en konvensjonell tilnærming, oppstår det nå også behovet for en ny type: dataforklarbarhet.
Modellforklarbarhet betyr å forstå algoritmen, for å forstå sluttresultatet. For eksempel, hvis en modell brukt i en onkologisk enhet er designet for å teste om en vekst er kreft, bør en helsepersonell forstå variablene som skaper sluttresultatene. Selv om dette høres bra ut i teorien, løser ikke modellforklaringen helt problemet med black box.
Ettersom modellene blir stadig mer komplekse, vil de fleste utøvere ikke være i stand til å identifisere transformasjonene og tolke beregningene i de indre lagene av modellen. De stoler i stor grad på hva de kan kontrollere, det vil si treningsdatasettene og det de observerer, resultatene og prediksjonsmålene.
La oss bruke eksemplet med en dataforsker som bygger en modell for å oppdage bilder av kaffekrus fra tusenvis av fotografier – men modellen begynner også å oppdage bilder av drikkeglass og ølkrus, for eksempel. Mens glass- og ølkrusene kan ha en viss likhet med kaffekrus, er det tydelige forskjeller, som typiske materialer, farge, ugjennomsiktighet og strukturelle proporsjoner.
For at modellen skal oppdage kaffekrus med høyere pålitelighet, må dataforskeren ha svar på spørsmål som:
- Hvilke bilder tok modellen opp i stedet for kaffekrus?
- Mislyktes modellen fordi jeg ikke ga den nok eller de riktige eksemplene på kaffekrus?
- Er den modellen til og med god nok for det jeg prøvde å oppnå?
- Trenger jeg å utfordre mitt syn på modellen?
- Hva kan jeg endelig fastslå er årsaken til at modellen mislykkes?
- Bør jeg generere nye forutsetninger for modellen?
- Valgte jeg bare feil modell for jobben til å begynne med?
Som du kan se, er det svært usannsynlig å levere denne typen innsikt, forståelse og modellforklaring hver gang det er et problem.
Dataforklarlighet er å forstå dato brukes til opplæring og input til en modell, for å forstå hvordan en modells sluttresultat nås. Etter hvert som ML-algoritmer blir stadig mer komplekse, men mer utbredt på tvers av yrker og bransjer, vil dataforklarlighet tjene som nøkkelen til raskt å låse opp og løse vanlige problemer, som eksempelet vårt med kaffekrus.
Øke rettferdighet og åpenhet i ML med dataforklaring
Rettferdighet innenfor ML-modeller er et hett tema, som kan gjøres enda hetere ved å bruke dataforklarbarhet.
Hvorfor buzz? Bias i AI kan skape fordomsfulle resultater for én gruppe. En av de mest veldokumenterte tilfellene av dette er skjevheter i tilfeller av rasebruk. La oss se på et eksempel.
La oss si at en stor, kjent forbrukerplattform ansetter for en ny markedsdirektørstilling. For å håndtere massen av CV-er som mottas daglig, distribuerer HR-avdelingen en AI/ML-modell for å effektivisere søknads- og rekrutteringsprosessen ved å velge nøkkelegenskaper eller kvalifiserte søkere.
For å utføre denne oppgaven, og skjelne og sette sammen hver CV, vil modellen gjøre det ved å forstå viktige dominerende egenskaper. Dessverre, dette også betyr at modellen implisitt kan fange opp generelle rasemessige skjevheter hos kandidatene også. Hvordan skulle dette skje? Hvis en søkerpool inkluderer en mindre prosentandel av én rase, vil maskinen tro at organisasjonen foretrekker medlemmer av en annen rase, eller av det dominerende datasettet.
Hvis en modell mislykkes, selv om den er utilsiktet, må feilen løses av selskapet. I hovedsak må den som har distribuert modellen være i stand til å forsvare bruken av modellen.
I ansettelses- og rasebias-saken, må forsvareren være i stand til å forklare en sint offentlighet og/eller applikasjonspool bruken av datasett for å trene modellen, de første vellykkede resultatene av modellen basert på den opplæringen, feilen i modellen å plukke opp på en hjørnekasse, og hvordan dette førte til en utilsiktet dataubalanse som til slutt skapte en rasistisk partisk filtreringsprosess.
For de fleste vil ikke denne typen grove detaljer i AI, ubalansedatasett, modelltrening og eventuell feil via dataovervåking bli mottatt eller til og med forstått. Men hva vil bli forstått og bli ved med denne historien? Selskapet XYZ praktiserer rasemessig skjevhet ved ansettelse.
Moralen i dette altfor vanlige eksemplet er at utilsiktede feil fra en veldig smart modell skjer og kan påvirke mennesker negativt og få alvorlige konsekvenser.
Hvor dataforklaringen tar oss
I stedet for å oversette resultater via en forståelse av en kompleks maskinlæringsmodell, er dataforklarlighet å bruke dataene til å forklare spådommer og feil.
Dataforklarlighet er da en kombinasjon av å se testdataene og forstå hva en modell vil plukke opp fra disse dataene. Dette inkluderer forståelse av underrepresenterte dataprøver, overrepresenterte prøver (som i ansettelseseksemplet) og gjennomsiktigheten av en modells deteksjon for å nøyaktig forstå spådommer og feilprediksjoner.
Denne forståelsen av dataforklarbarhet vil ikke bare forbedre modellens nøyaktighet og rettferdighet, men det vil også være det som hjelper modellene med å akselerere raskere.
Ettersom vi fortsetter å stole på og integrere komplekse AI- og ML-programmer i hverdagen, blir det kritisk å løse black box-problemet, spesielt for feil og feilspådommer.
Selv om modellforklaring alltid vil ha sin plass, krever den et annet lag. Vi trenger dataforklarbarhet, da forståelse av hva en modell ser og leser aldri vil bli dekket av klassisk modellforklarbarhet.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoAiStream. Web3 Data Intelligence. Kunnskap forsterket. Tilgang her.
- Minting the Future med Adryenn Ashley. Tilgang her.
- Kjøp og selg aksjer i PRE-IPO-selskaper med PREIPO®. Tilgang her.
- kilde: https://www.dataversity.net/data-explainability-the-counterpart-to-model-explainability/
- : har
- :er
- :ikke
- $OPP
- a
- I stand
- akselerere
- tilgjengelig
- utrette
- nøyaktighet
- nøyaktig
- tvers
- adresse
- AI
- AI / ML
- algoritme
- algoritmer
- også
- alltid
- an
- og
- En annen
- svar
- app
- søkere
- Søknad
- påføring
- tilnærming
- ER
- rundt
- AS
- At
- basert
- BE
- fordi
- bli
- blir
- bli
- øl
- begynne
- Bias
- forutinntatt
- skjevheter
- Svart
- Eske
- Bygning
- bygget
- men
- by
- CAN
- kandidater
- kan ikke
- hvilken
- biler
- saken
- saker
- kategorier
- forårsaker
- utfordre
- egenskaper
- Velg
- Kaffe
- farge
- kombinasjon
- Felles
- Selskapet
- komplekse
- kompleksitet
- datamaskin
- Datamaskin syn
- selvtillit
- Konsekvenser
- forbrukes
- forbruker
- fortsette
- kontroll
- gåten
- konvensjonell
- Corner
- kunne
- motstykke
- dekket
- lage
- skape
- opprettet
- kritisk
- daglig
- dato
- dataforsker
- datasett
- DATAVERSITET
- avtale
- avgjørelse
- dyp
- dyp læring
- leverer
- levere
- Avdeling
- utplassert
- Distribueres
- designet
- detalj
- Gjenkjenning
- Bestem
- gJORDE
- forskjeller
- forskjellig
- dire
- retning
- direkte
- Regissør
- distinkt
- do
- ikke
- dominerende
- e
- hver enkelt
- slutt
- slutter
- nok
- hovedsak
- Selv
- eventuell
- etter hvert
- NOEN GANG
- Hver
- alle
- nøyaktig
- eksempel
- eksempler
- Forklar
- Forklarbarhet
- forklaring
- eksponentielt
- FAIL
- mislykkes
- Failure
- rettferdighet
- Fall
- raskere
- filtrering
- Til
- Fjerde
- fra
- general
- generere
- Gi
- glass
- briller
- skal
- god
- flott
- Gruppe
- Vekst
- skje
- Ha
- Helse
- Health Care
- hjelper
- høyere
- svært
- Ansetter
- HOT
- Hvordan
- hr
- HTML
- HTTPS
- Mennesker
- i
- if
- bilder
- ubalanse
- Påvirkning
- forbedre
- forbedrer
- in
- inkluderer
- innlemme
- Øke
- økt
- bransjer
- innledende
- inngang
- innsikt
- f.eks
- i stedet
- inn
- utstedelse
- IT
- DET ER
- Jobb
- bare
- nøkkel
- Type
- stor
- i stor grad
- lag
- lag
- læring
- Led
- i likhet med
- Bor
- Se
- maskin
- maskinlæring
- laget
- Hoved
- gjøre
- Making
- Marketing
- Marketing Director
- Mass
- materialer
- Kan..
- midler
- målinger
- medlemmer
- metoder
- kunne
- feil
- ML
- ML-algoritmer
- modell
- modeller
- moralsk
- mer
- mest
- flytte
- flytting
- må
- my
- Trenger
- negativt
- aldri
- Ny
- nå
- observere
- of
- ofte
- on
- onkologi
- ONE
- bare
- ugjennomsiktig
- or
- rekkefølge
- organisasjon
- vår
- oppsyn
- spesielt
- prosent
- utføre
- fotografier
- Bilder
- plukke
- Sted
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- basseng
- posisjon
- praksis
- prediksjon
- Spådommer
- fordomsfull
- Problem
- problemer
- prosess
- produsert
- programmer
- forslag
- gi
- leverandør
- offentlig
- kvalifisert
- spørsmål
- raskt
- Race
- Raseforspenning
- å nå
- nådd
- Lesning
- mottatt
- nylig
- rekruttering
- referert
- pålitelighet
- avhengige
- Krever
- resultere
- Resultater
- gjenoppta
- omskolering
- ikke sant
- regler
- sikrere
- Forsker
- se
- se
- synes
- velge
- self-kjøring
- forstand
- betjene
- bør
- enkelt
- mindre
- Smart
- So
- løse
- noen
- Stick
- Story
- effektivisere
- strukturell
- vellykket
- slik
- tar
- Oppgave
- test
- enn
- Det
- De
- Oppstyret
- verden
- deretter
- teori
- Der.
- de
- tror
- denne
- grundig
- De
- tusener
- tid
- til
- Tema
- mot
- trafikk
- Tog
- Kurs
- transformasjoner
- overgang
- Åpenhet
- typen
- typisk
- ute av stand
- underrepresenterte
- forstå
- forståelse
- forstås
- dessverre
- enhet
- opplåsing
- bruke
- brukt
- Brukere
- ved hjelp av
- veldig
- av
- Se
- syn
- var
- we
- VI VIL
- velkjent
- Hva
- hvilken
- mens
- hvit
- hvit boks
- hvem som helst
- hele
- allment
- vil
- med
- innenfor
- uten
- verden
- ville
- Feil
- Yahoo
- du
- zephyrnet