Verdien av data er tidssensitiv. Sanntidsbehandling gjør datadrevne beslutninger nøyaktige og handlingsbare på sekunder eller minutter i stedet for timer eller dager. Change data capture (CDC) refererer til prosessen med å identifisere og fange opp endringer gjort i data i en database og deretter levere disse endringene i sanntid til et nedstrømssystem. Å fange opp hver endring fra transaksjoner i en kildedatabase og flytte dem til målet i sanntid, holder systemene synkroniserte, og hjelper med brukstilfeller for sanntidsanalyse og databasemigreringer med null nedetid. Følgende er noen fordeler med CDC:
- Det eliminerer behovet for massebelastningsoppdatering og upraktiske batchvinduer ved å aktivere inkrementell lasting eller sanntidsstrømming av dataendringer til mållageret ditt.
- Det sikrer at data i flere systemer forblir synkronisert. Dette er spesielt viktig hvis du tar tidssensitive beslutninger i et datamiljø med høy hastighet.
Kafka Connect er en åpen kildekode-komponent av Apache Kafka som fungerer som en sentralisert datahub for enkel dataintegrasjon mellom databaser, nøkkelverdilagre, søkeindekser og filsystemer. De AWS limskjemaregister lar deg sentralt oppdage, kontrollere og utvikle datastrømskjemaer. Kafka Connect og Schema Registry integreres for å fange opp skjemainformasjon fra koblinger. Kafka Connect gir en mekanisme for å konvertere data fra de interne datatypene som brukes av Kafka Connect til datatyper representert som Avro, Protobuf eller JSON Schema. AvroConverter, ProtobufConverter og JsonSchemaConverter registrerer automatisk skjemaer generert av Kafka-koblinger (kilde) som produserer data til Kafka. Koblinger (sink) som forbruker data fra Kafka mottar skjemainformasjon i tillegg til dataene for hver melding. Dette lar synkekoblinger kjenne strukturen til dataene for å gi muligheter som å vedlikeholde et databasetabellskjema i en datakatalog.
Innlegget demonstrerer hvordan du bygger en ende-til-ende CDC ved hjelp av Amazon MSK Connect, en AWS-administrert tjeneste for å distribuere og kjøre Kafka Connect-applikasjoner og AWS Glue Schema Registry, som lar deg sentralt oppdage, kontrollere og utvikle datastrømskjemaer.
Løsningsoversikt
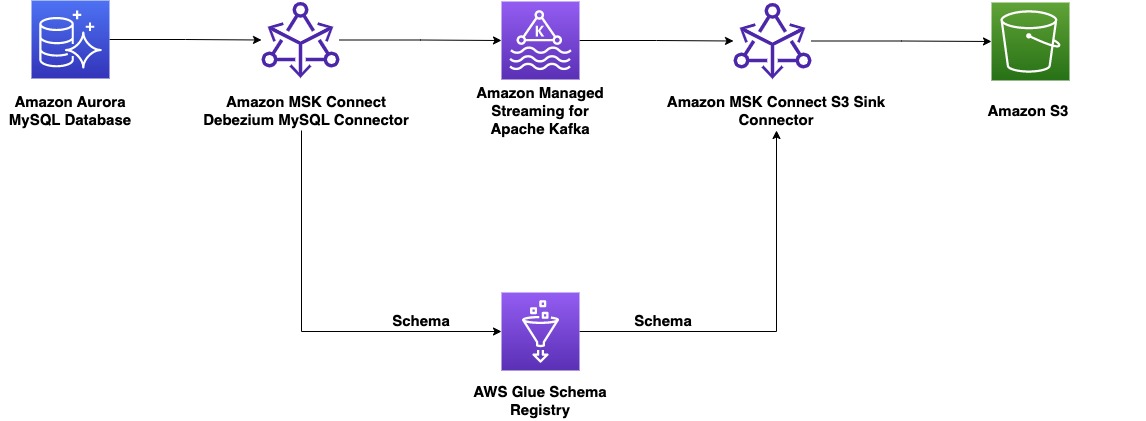
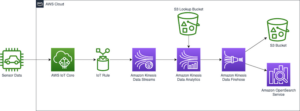
På produsentsiden velger vi for dette eksempelet en MySQL-kompatibel Amazonas Aurora database som datakilde, og vi har en Debezium MySQL-kontakt for å utføre CDC. Debezium-koblingen overvåker kontinuerlig databasene og skyver endringer på radnivå til et Kafka-emne. Koblingen henter skjemaet fra databasen for å serialisere postene til en binær form. Hvis skjemaet ikke allerede eksisterer i registeret, vil skjemaet bli registrert. Hvis skjemaet eksisterer, men serializeren bruker en ny versjon, sjekker skjemaregisteret kompatibilitetsmodus av skjemaet før du oppdaterer skjemaet. I denne løsningen bruker vi bakoverkompatibilitetsmodus. Skjemaregisteret returnerer en feil hvis en ny versjon av skjemaet ikke er bakoverkompatibel, og vi kan konfigurere Kafka Connect til å sende inkompatible meldinger til dødbokstavskøen.
På forbrukersiden bruker vi en Amazon enkel lagringstjeneste (Amazon S3) synkekontakt for å deserialisere platen og lagre endringer til Amazon S3. Vi bygger og distribuerer Debezium-kontakten og Amazon S3-vasken ved hjelp av MSK Connect.
Eksempelskjema
For dette innlegget bruker vi følgende skjema som den første versjonen av tabellen:
Forutsetninger
Før vi konfigurerer MSK-produsent- og forbrukerkoblingene, må vi først sette opp en datakilde, MSK-klynge og nytt skjemaregister. Vi gir en AWS skyformasjon mal for å generere støtteressursene som trengs for løsningen:
- En MySQL-kompatibel Aurora-database som datakilde. For å utføre CDC, slår vi på binær logging i DB-klyngeparametergruppe.
- En MSK-klynge. For å forenkle nettverkstilkoblingen bruker vi samme VPC for Aurora-databasen og MSK-klyngen.
- To skjemaregistre for å håndtere skjemaer for meldingsnøkkel og meldingsverdi.
- Én S3-bøtte som datasynk.
- MSK Connect-plugins og arbeiderkonfigurasjon er nødvendig for denne demoen.
- En Amazon Elastic Compute Cloud (Amazon EC2) forekomst for å kjøre databasekommandoer.
For å sette opp ressurser i AWS-kontoen din, fullfør følgende trinn i en AWS-region som støtter Amazon MSK, MSK Connect og AWS Glue Schema Registry:
- Velg Start Stack:
- Velg neste.
- Til Stabelnavn, skriv inn passende navn.
- Til Database passord, skriv inn passordet du ønsker for databasebrukeren.
- Behold andre verdier som standard.
- Velg neste.
- På neste side velger du neste.
- Gå gjennom detaljene på den siste siden og velg Jeg erkjenner at AWS CloudFormation kan skape IAM-ressurser.
- Velg Lag stabel.
Egendefinert plugin for kilde- og destinasjonskontakten
En tilpasset plugin er et sett med JAR-filer som inneholder implementeringen av én eller flere koblinger, transformasjoner eller omformere. Amazon MSK vil installere plugin-en på arbeiderne til MSK Connect-klyngen der kontakten kjører. Som en del av denne demoen bruker vi åpen kildekode for kildekoblingen Debezium MySQL-kontakt JAR-er, og for destinasjonskoblingen bruker vi Confluent-fellesskapet lisensiert Amazon S3 vaskkontakt JARs. Begge pluginene er også lagt til med biblioteker for Avro Serializers og Deserializers av AWS Glue Schema Registry. Disse tilpassede pluginene er allerede opprettet som en del av CloudFormation-malen som ble distribuert i forrige trinn.
Bruk AWS Glue Schema Registry med Debezium-kontakten på MSK Connect som MSK-produsent
Vi distribuerer først kildekontakten ved å bruke Debezium MySQL-plugin for å streame data fra en Amazon Aurora MySQL-kompatibel utgave database til Amazon MSK. Fullfør følgende trinn:
- På Amazon MSK-konsollen, i navigasjonsruten, under MSK Connect, velg Kontakter.
- Velg Opprett kobling.
- Velg Bruk eksisterende tilpasset plugin og velg deretter den tilpassede plugin-en med navnet som starter
msk-blog-debezium-source-plugin. - Velg neste.
- Skriv inn et passende navn som
debezium-mysql-connectorog en valgfri beskrivelse. - Til Apache Kafka-klynge, velg MSK-klynge og velg klyngen opprettet av CloudFormation-malen.
- In Koblingskonfigurasjon, slett standardverdiene og bruk følgende konfigurasjonsnøkkel-verdi-par og med de riktige verdiene:
- navn – Navnet som brukes for kontakten.
- database.vertsnavn – CloudFormation-utgangen for Database endepunkt.
- database.bruker og database.passord – Parametrene som sendes i CloudFormation-malen.
- database.history.kafka.bootstrap.servere – CloudFormation-utgangen for Kafka Bootstrap.
- key.converter.region og value.converter.region – Din region.
Noen av disse innstillingene er generiske og bør spesifiseres for enhver kobling. For eksempel:
- connector.class er Java-klassen til kontakten
- tasks.max er det maksimale antallet oppgaver som skal opprettes for denne koblingen
Noen innstillinger (database.*, transforms.*) er spesifikke for Debezium MySQL-kontakten. Referere til Debezium MySQL Source Connector Configuration Properties for mer informasjon.
Noen innstillinger (key.converter.* og value.converter.*) er spesifikke for Schema Registry. Vi bruker AWSKafkaAvroConverter fra AWS Glue Schema Registry Library som formatkonverterer. For å konfigurere AWSKafkaAvroConverter, bruker vi verdien til strengkonstanten-egenskapene i AWSSchemaRegistryConstants klasse:
key.converterogvalue.converterkontrollere formatet til dataene som skal skrives til Kafka for kildekoblinger eller leses fra Kafka for vaskkoblinger. Vi brukerAWSKafkaAvroConverterfor Avro-format.key.converter.registry.nameogvalue.converter.registry.namedefinere hvilket skjemaregister som skal brukes.key.converter.compatibilityogvalue.converter.compatibilitydefinere kompatibilitetsmodellen.
Referere til Bruke Kafka Connect med AWS Glue Schema Registry for mer informasjon.
- Deretter konfigurerer vi Koblingskapasitet. Vi kan velge Forsynt og la andre egenskaper være standard
- Til Arbeiderkonfigurasjon, velg den tilpassede arbeiderkonfigurasjonen med navnet som starter
msk-gsr-blogopprettet som en del av CloudFormation-malen. - Til Adgangstillatelser, bruke AWS identitets- og tilgangsadministrasjon (IAM)-rolle generert av CloudFormation-malen
MSKConnectRole. - Velg neste.
- Til Sikkerhet, velg standardinnstillingene.
- Velg neste.
- Til Logglevering, plukke ut Lever til Amazon CloudWatch-logger og bla etter logggruppen opprettet av CloudFormation-malen (
msk-connector-logs). - Velg neste.
- Gjennomgå innstillingene og velg Opprett kobling.
Etter noen minutter endres kontakten til kjørestatus.
Bruk AWS Glue Schema Registry med Confluent S3 vaskekontakten som kjører på MSK Connect som MSK-forbruker
Vi distribuerer sink-kontakten ved å bruke Confluent S3 sink-plugin for å streame data fra Amazon MSK til Amazon S3. Fullfør følgende trinn:
-
- På Amazon MSK-konsollen, i navigasjonsruten, under MSK Connect, velg Kontakter.
- Velg Opprett kobling.
- Velg Bruk eksisterende tilpasset plugin og velg den tilpassede plugin-en med navnet som starter
msk-blog-S3sink-plugin. - Velg neste.
- Skriv inn et passende navn som
s3-sink-connectorog en valgfri beskrivelse. - Til Apache Kafka-klynge, velg MSK-klynge og velg klyngen opprettet av CloudFormation-malen.
- In Koblingskonfigurasjon, slett standardverdiene som er oppgitt og bruk følgende konfigurasjonsnøkkel-verdi-par med passende verdier:
-
- navn – Samme navn som brukes for kontakten.
- s3.bucket.name – CloudFormation-utgangen for Bøtte navn.
- s3.region, key.converter.region og value.converter.region – Din region.
-
- Deretter konfigurerer vi Koblingskapasitet. Vi kan velge Forsynt og la andre egenskaper være standard
- Til Arbeiderkonfigurasjon, velg den tilpassede arbeiderkonfigurasjonen med navnet som starter
msk-gsr-blogopprettet som en del av CloudFormation-malen. - Til Adgangstillatelser, bruk IAM-rollen generert av CloudFormation-malen
MSKConnectRole. - Velg neste.
- Til Sikkerhet, velg standardinnstillingene.
- Velg neste.
- Til Logglevering, plukke ut Lever til Amazon CloudWatch-logger og bla etter logggruppen opprettet av CloudFormation-malen
msk-connector-logs. - Velg neste.
- Gjennomgå innstillingene og velg Opprett kobling.
Etter noen minutter kjører kontakten.
Test ende-til-ende CDC-loggstrømmen
Nå som både Debezium- og S3-vaskekontaktene er oppe og går, fullfør følgende trinn for å teste ende-til-ende CDC:
- På Amazon EC2-konsollen, naviger til Sikkerhetsgrupper side.
- Velg sikkerhetsgruppen
ClientInstanceSecurityGroupOg velg Rediger innkommende regler. - Legg til en innkommende regel som tillater SSH-tilkobling fra ditt lokale nettverk.
- På Forekomster siden, velg forekomsten
ClientInstanceOg velg Koble. - På EC2 Instance Connect kategorien, velg Koble.
- Sørg for at din nåværende arbeidskatalog er
/home/ec2-userog den har filenecreate_table.sql,alter_table.sql,initial_insert.sqloginsert_data_with_new_column.sql. - Opprett en tabell i MySQL-databasen din ved å kjøre følgende kommando (oppgi databasevertsnavnet fra CloudFormation-malutgangene):
- Når du blir bedt om et passord, skriv inn passordet fra CloudFormation-malparameterne.
- Sett inn noen eksempeldata i tabellen med følgende kommando:
- Når du blir bedt om et passord, skriv inn passordet fra CloudFormation-malparameterne.
- Velg på AWS Lim-konsollen Skjemaregistre i navigasjonsruten, og velg deretter Skjemaer.
- naviger til
db1.sampledatabase.moviesversjon 1 for å sjekke det nye skjemaet som er opprettet for filmtabellen:
En egen S3-mappe opprettes for hver partisjon av Kafka-emnet, og data for emnet skrives i den mappen.
- På Amazon S3-konsollen, se etter data skrevet i parkettformat i mappen for Kafka-emnet ditt.
Skjema evolusjon
Etter at det første skjemaet er definert, kan det hende at applikasjoner må utvikle det over tid. Når dette skjer, er det avgjørende for nedstrømsforbrukerne å kunne håndtere data som er kodet med både det gamle og det nye skjemaet sømløst. Kompatibilitetsmodus lar deg kontrollere hvordan skjemaer kan eller ikke kan utvikle seg over tid. Disse modusene danner kontrakten mellom applikasjoner som produserer og forbruker data. For detaljert informasjon om forskjellige kompatibilitetsmoduser tilgjengelig i AWS Glue Schema Registry, se AWS limskjemaregister. I vårt eksempel bruker vi bakoverkombabilitet for å sikre at forbrukere kan lese både gjeldende og tidligere skjemaversjoner. Fullfør følgende trinn:
- Legg til en ny kolonne i tabellen ved å kjøre følgende kommando:
- Sett inn nye data i tabellen ved å kjøre følgende kommando:
- Velg på AWS Lim-konsollen Skjemaregistre i navigasjonsruten, og velg deretter Skjemaer.
- Naviger til skjemaet
db1.sampledatabase.moviesversjon 2 for å sjekke den nye versjonen av skjemaet som er opprettet for filmtabellfilmene, inkludert landkolonnen du la til:
- På Amazon S3-konsollen, se etter data skrevet i parkettformat i mappen for Kafka-emnet.
Rydd opp
For å forhindre uønskede belastninger på AWS-kontoen din, slett AWS-ressursene du brukte i dette innlegget:
- På Amazon S3-konsollen, naviger til S3-bøtten opprettet av CloudFormation-malen.
- Velg alle filer og mapper og velg Delete.
- Skriv inn slett permanent som anvist og velg Slett objekter.
- På AWS CloudFormation-konsollen sletter du stabelen du opprettet.
- Vent til stabelstatusen endres til DELETE_COMPLETE.
konklusjonen
Dette innlegget demonstrerte hvordan du bruker Amazon MSK, MSK Connect og AWS Glue Schema Registry for å bygge en CDC-loggstrøm og utvikle skjemaer for datastrømmer etter hvert som forretningsbehov endres. Du kan bruke dette arkitekturmønsteret på andre datakilder med forskjellige Kafka-koblinger. For mer informasjon, se MSK Connect eksempler.
om forfatteren
 Kalyan Janaki er Senior Big Data & Analytics Specialist med Amazon Web Services. Han hjelper kundene med å bygge og bygge svært skalerbare, ytende og sikre skybaserte løsninger på AWS.
Kalyan Janaki er Senior Big Data & Analytics Specialist med Amazon Web Services. Han hjelper kundene med å bygge og bygge svært skalerbare, ytende og sikre skybaserte løsninger på AWS.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-change-data-capture-with-amazon-msk-connect-and-aws-glue-schema-registry/
- :er
- $OPP
- 1
- 10
- 11
- 7
- 8
- a
- I stand
- Om oss
- adgang
- Logg inn
- nøyaktig
- anerkjenne
- la til
- tillegg
- Alle
- tillate
- tillater
- allerede
- Amazon
- Amazon EC2
- Amazon Web Services
- analytics
- og
- Apache
- Apache Kafka
- søknader
- Påfør
- hensiktsmessig
- arkitektur
- ER
- AS
- Aurora
- automatisk
- tilgjengelig
- AWS
- AWS skyformasjon
- AWS Lim
- BE
- før du
- Fordeler
- mellom
- Stor
- Store data
- Bootstrap
- bygge
- virksomhet
- by
- CAN
- evner
- fangst
- fange
- saker
- katalog
- CDC
- sentralisert
- endring
- Endringer
- avgifter
- sjekk
- Sjekker
- Velg
- klasse
- Cluster
- Kolonne
- samfunnet
- kompatibilitet
- kompatibel
- fullføre
- komponent
- Beregn
- Konfigurasjon
- kryss
- Koble
- tilkobling
- Konsoll
- konstant
- forbruke
- forbruker
- Forbrukere
- kontinuerlig
- kontrakt
- kontroll
- land
- skape
- opprettet
- kritisk
- Gjeldende
- skikk
- Kunder
- dato
- dataintegrasjon
- data-drevet
- Database
- databaser
- Dager
- avgjørelser
- Misligholde
- mislighold
- definert
- levere
- Demo
- demonstrert
- demonstrerer
- utplassere
- utplassert
- beskrivelse
- destinasjonen
- detaljert
- detaljer
- forskjellig
- oppdage
- ikke
- Drop
- hver enkelt
- eliminerer
- muliggjør
- ende til ende
- sikre
- sikrer
- Enter
- Miljø
- feil
- spesielt
- Eter (ETH)
- Hver
- utvikle seg
- eksempel
- eksisterende
- finnes
- Noen få
- Felt
- filet
- Filer
- slutt~~POS=TRUNC
- Først
- etter
- Til
- skjema
- format
- fra
- generere
- generert
- Gruppe
- Gruppens
- håndtere
- Håndtering
- skjer
- Ha
- hjelpe
- hjelper
- svært
- historie
- vert
- TIMER
- Hvordan
- Hvordan
- HTML
- http
- HTTPS
- Hub
- IAM
- identifisering
- Identitet
- gjennomføring
- viktig
- in
- Inkludert
- indekser
- informasjon
- innledende
- installere
- f.eks
- i stedet
- integrere
- integrering
- intern
- IT
- Java
- jpg
- JSON
- Kafka
- nøkkel
- Vet
- Permisjon
- bibliotekene
- Licensed
- i likhet med
- laste
- lasting
- lokal
- Lang
- laget
- GJØR AT
- Making
- fikk til
- Master
- max
- maksimal
- mekanisme
- melding
- meldinger
- kunne
- minutter
- modell
- moduser
- skjermer
- mer
- Filmer
- flytting
- flere
- MySQL
- navn
- Naviger
- Navigasjon
- Trenger
- nødvendig
- behov
- nettverk
- Ny
- neste
- Antall
- of
- Gammel
- on
- ONE
- åpen kildekode
- Annen
- produksjon
- side
- par
- brød
- parameter
- parametere
- del
- bestått
- Passord
- Mønster
- utføre
- permanent
- plukke
- plato
- Platon Data Intelligence
- PlatonData
- plugg inn
- plugins
- Post
- forebygge
- forrige
- prosess
- prosessering
- produsere
- produsent
- egenskaper
- gi
- forutsatt
- gir
- Lese
- ekte
- sanntids
- motta
- rekord
- poster
- refererer
- region
- registrere
- registrert
- registret
- Repository
- representert
- Ressurser
- avkastning
- Rolle
- Regel
- Kjør
- rennende
- samme
- skalerbar
- sømløst
- Søk
- sekunder
- sikre
- sikkerhet
- senior
- sensitive
- separat
- tjeneste
- Tjenester
- sett
- innstillinger
- bør
- Enkelt
- forenkle
- løsning
- Solutions
- noen
- kilde
- Kilder
- spesialist
- spesifikk
- spesifisert
- stable
- Start
- status
- Trinn
- Steps
- lagring
- oppbevare
- butikker
- stream
- streaming
- bekker
- struktur
- egnet
- Støtte
- Støtter
- synk.
- system
- Systemer
- bord
- Target
- oppgaver
- mal
- test
- Det
- De
- Kilden
- Dem
- Disse
- tid
- tidssensitiv
- Tittel
- til
- Tema
- Transaksjoner
- SVING
- typer
- etter
- uønsket
- oppdatering
- bruke
- Bruker
- verdi
- Verdier
- versjon
- web
- webtjenester
- hvilken
- vil
- vinduer
- med
- arbeidstaker
- arbeidere
- arbeid
- virker
- skrevet
- Din
- zephyrnet