Vi lever i en tidsalder med sanntidsdata og innsikt, drevet av datastrømmeapplikasjoner med lav latens. I dag forventer alle en personlig opplevelse i enhver applikasjon, og organisasjoner innoverer hele tiden for å øke hastigheten på forretningsdrift og beslutningstaking. Volumet av tidssensitive data som produseres øker raskt, med forskjellige dataformater som introduseres på tvers av nye virksomheter og kundebruk. Derfor er det avgjørende for organisasjoner å omfavne en lav latens, skalerbar og pålitelig datastrømningsinfrastruktur for å levere sanntids forretningsapplikasjoner og bedre kundeopplevelser.
Dette er det første innlegget til en bloggserie som tilbyr vanlige arkitektoniske mønstre for å bygge sanntidsdatastrømningsinfrastrukturer ved å bruke Kinesis Data Streams for et bredt spekter av bruksområder. Den har som mål å gi et rammeverk for å lage strømmeapplikasjoner med lav latens på AWS Cloud ved hjelp av Amazon Kinesis datastrømmer og AWS spesialbygde dataanalysetjenester.
I dette innlegget vil vi gjennomgå de vanlige arkitektoniske mønstrene for to brukstilfeller: tidsseriedataanalyse og hendelsesdrevne mikrotjenester. I det påfølgende innlegget i serien vår vil vi utforske de arkitektoniske mønstrene i å bygge strømmingspipelines for sanntids BI-dashboard, kontaktsenteragent, reskontrodata, personlig tilpasset sanntidsanbefaling, logganalyse, IoT-data, Change Data Capture og ekte -tidsmarkedsføringsdata. Alle disse arkitekturmønstrene er integrert med Amazon Kinesis Data Streams.
Sanntidsstrømming med Kinesis Data Streams
Amazon Kinesis Data Streams er en skybasert, serverløs strømmedatatjeneste som gjør det enkelt å fange opp, behandle og lagre sanntidsdata i alle skalaer. Med Kinesis Data Streams kan du samle inn og behandle hundrevis av gigabyte med data per sekund fra hundretusenvis av kilder, slik at du enkelt kan skrive applikasjoner som behandler informasjon i sanntid. De innsamlede dataene er tilgjengelige i millisekunder for å tillate brukstilfeller for sanntidsanalyse, for eksempel sanntidsdashboard, sanntidsavviksdeteksjon og dynamisk prissetting. Som standard lagres dataene i Kinesis Data Stream i 24 timer med mulighet for å øke dataoppbevaringen til 365 dager. Hvis kunder ønsker å behandle de samme dataene i sanntid med flere applikasjoner, kan de bruke funksjonen Enhanced Fan-Out (EFO). Før denne funksjonen delte hver applikasjon som forbrukte data fra strømmen 2 MB/sekund/shard-utgang. Ved å konfigurere strømforbrukere til å bruke forbedret fan-out, mottar hver dataforbruker dedikert 2 MB/sekund lesegjennomstrømning per shard for å redusere ventetiden i datahenting ytterligere.
For høy tilgjengelighet og holdbarhet oppnår Kinesis Data Streams høy holdbarhet ved å synkront replikere de streamede dataene på tvers av tre tilgjengelighetssoner i en AWS-region og gir deg muligheten til å beholde data i opptil 365 dager. For sikkerhet gir Kinesis Data Streams server-side kryptering slik at du kan møte strenge databehandlingskrav ved å kryptere dataene dine i hvile og Amazon Virtual Private Cloud (VPC) grensesnittendepunkter for å holde trafikken mellom Amazon VPC og Kinesis Data Streams privat.
Kinesis Data Streams har native integrasjoner med andre AWS-tjenester som f.eks AWS Lim og Amazon EventBridge å bygge sanntidsstrømmeapplikasjoner på AWS. Se Amazon Kinesis Data Streams-integrasjoner for ytterligere detaljer.
Moderne datastrømningsarkitektur med Kinesis Data Streams
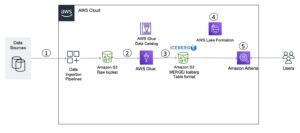
En moderne strømmedataarkitektur med Kinesis Data Streams kan utformes som en stabel med fem logiske lag; hvert lag er sammensatt av flere spesialbygde komponenter som oppfyller spesifikke krav, som illustrert i følgende diagram:
Arkitekturen består av følgende nøkkelkomponenter:
- Strømmekilder – Kilden til strømmedata inkluderer datakilder som klikkstrømdata, sensorer, sosiale medier, Internet of Things (IoT)-enheter, loggfiler generert ved å bruke nett- og mobilapplikasjonene dine, og mobile enheter som genererer semistrukturerte og ustrukturerte data som kontinuerlige strømmer ved høy hastighet.
- Strøminntak – Strøminntakslaget er ansvarlig for å ta inn data inn i strømlagringslaget. Det gir muligheten til å samle inn data fra titusenvis av datakilder og innta i sanntid. Du kan bruke Kinesis SDK for inntak av strømmedata gjennom APIer, Kinesis produsentbibliotek for å bygge høyytelses og langvarige strømmeprodusenter, eller en Kinesis agent for å samle et sett med filer og ta dem inn i Kinesis Data Streams. I tillegg kan du bruke mange pre-build integrasjoner som f.eks AWS Database Migration Service (AWS DMS), Amazon DynamoDBog AWS IoT-kjerne å innta data uten kode. Du kan også innta data fra tredjepartsplattformer som Apache Spark og Apache Kafka Connect
- Strømlagring – Kinesis Data Streams tilbyr to moduser for å støtte datagjennomstrømningen: On-Demand og Provisioned. On-Demand-modus, nå standardvalget, kan skaleres elastisk for å absorbere variable gjennomstrømninger, slik at kundene ikke trenger å bekymre seg for kapasitetsstyring og betale etter datagjennomstrømning. On-Demand-modus skalerer automatisk opp 2 ganger strømkapasiteten over dens historiske maksimale datainntak for å gi tilstrekkelig kapasitet for uventede topper i datainntak. Alternativt kan kunder som ønsker detaljert kontroll over strømressursene bruke den klargjorte modusen og proaktivt skalere opp og ned antallet Shards for å møte gjennomstrømningskravene deres. I tillegg kan Kinesis Data Streams lagre strømmedata i opptil 24 timer som standard, men kan utvides til 7 dager eller 365 dager avhengig av brukstilfeller. Flere applikasjoner kan konsumere den samme strømmen.
- Strømbehandling – Strømbehandlingslaget er ansvarlig for å transformere data til en forbrukstilstand gjennom datavalidering, opprydding, normalisering, transformasjon og berikelse. Strømmepostene leses i den rekkefølgen de produseres, noe som gir mulighet for sanntidsanalyse, bygging av hendelsesdrevne applikasjoner eller streaming av ETL (ekstrahere, transformere og laste). Du kan bruke Amazon Managed Service for Apache Flink for kompleks strømdatabehandling, AWS Lambda for statsløs strømdatabehandling, og AWS Lim & Amazon EMR for nesten sanntidsberegning. Du kan også bygge tilpassede forbrukerapplikasjoner med Kinesis Consumer Library, som vil ta seg av mange komplekse oppgaver knyttet til distribuert databehandling.
- Mål - Destinasjonslaget er som en spesialbygd destinasjon avhengig av din brukssituasjon. Du kan streame data direkte til Amazon RedShift for datavarehus og Amazon EventBridge for å bygge hendelsesdrevne applikasjoner. Du kan også bruke Amazon Kinesis Data Firehose for streaming-integrasjon der du kan lett streame prosessering med AWS Lambda, og deretter levere behandlet streaming til destinasjoner som Amazon S3 datainnsjø, OpenSearch Service for operasjonell analyse, et Redshift-datavarehus, No-SQL-databaser som Amazon DynamoDB og relasjonsdatabaser som Amazon RDS å konsumere sanntidsstrømmer til forretningsapplikasjoner. Destinasjonen kan være en hendelsesdrevet applikasjon for dashbord i sanntid, automatiske beslutninger basert på behandlede strømmedata, sanntidsendring og mer.
Sanntidsanalysearkitektur for tidsserier
Tidsseriedata er en sekvens av datapunkter registrert over et tidsintervall for å måle hendelser som endres over tid. Eksempler er aksjekurser over tid, klikkstrømmer på nettsider og enhetslogger over tid. Kunder kan bruke tidsseriedata til å overvåke endringer over tid, slik at de kan oppdage anomalier, identifisere mønstre og analysere hvordan visse variabler påvirkes over tid. Tidsseriedata genereres vanligvis fra flere kilder i store volumer, og de må samles inn på en kostnadseffektiv måte i nesten sanntid.
Vanligvis er det tre primære mål som kunder ønsker å oppnå ved behandling av tidsseriedata:
- Få innsikt i sanntid i systemytelse og oppdage uregelmessigheter
- Forstå sluttbrukeratferd for å spore trender og spørre/bygge visualiseringer fra denne innsikten
- Ha en holdbar lagringsløsning for å innta og lagre både arkivdata og data som ofte brukes.
Med Kinesis Data Streams kan kunder kontinuerlig fange opp terabyte med tidsseriedata fra tusenvis av kilder for rengjøring, berikelse, lagring, analyse og visualisering.
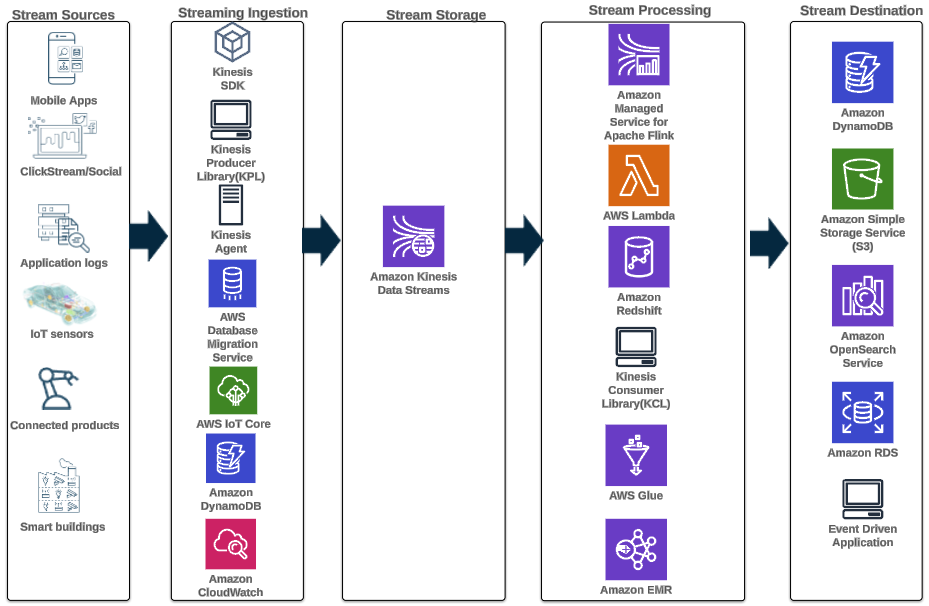
Følgende arkitekturmønster illustrerer hvordan sanntidsanalyse kan oppnås for tidsseriedata med Kinesis-datastrømmer:
Arbeidsflyttrinnene er som følger:
- Datainntak og lagring – Kinesis Data Streams kan kontinuerlig fange og lagre terabyte med data fra tusenvis av kilder.
- Strømbehandling – En applikasjon laget med Amazon Managed Service for Apache Flink kan lese postene fra datastrømmen for å oppdage og rense eventuelle feil i tidsseriedataene og berike dataene med spesifikke metadata for å optimalisere operasjonelle analyser. Å bruke en datastrøm i midten gir fordelen av å bruke tidsseriedataene i andre prosesser og løsninger samtidig. En Lambda-funksjon blir deretter påkalt med disse hendelsene, og kan utføre tidsserieberegninger i minnet.
- Destinasjoner – Etter rengjøring og berikelse kan de behandlede tidsseriedataene streames til Amazon Timestream database for sanntids dashboarding og analyse, eller lagret i databaser som DynamoDB for sluttbrukerspørring. Rådataene kan streames til Amazon S3 for arkivering.
- Visualisering og få innsikt – Kunder kan spørre, visualisere og opprette varsler ved hjelp av Amazon Managed Service for Grafana. Grafana støtter datakilder som er lagringsbackends for tidsseriedata. For å få tilgang til dataene dine fra Timestream, må du installere Timestream-plugin for Grafana. Sluttbrukere kan søke etter data fra DynamoDB-tabellen med Amazon API-gateway opptrer som fullmektig.
Referere til Nær sanntidsbehandling med Amazon Kinesis, Amazon Timestream og Grafana viser frem en serverløs strømmingspipeline for å behandle og lagre enhetstelemetri IoT-data i et tidsserieoptimalisert datalager som Amazon Timestream.
Berikende og avspilling av data i sanntid for hendelsessourcing-mikrotjenester
Mikrotjenester er en arkitektonisk og organisatorisk tilnærming til programvareutvikling der programvare er sammensatt av små uavhengige tjenester som kommuniserer over veldefinerte APIer. Ved bygging av hendelsesdrevne mikrotjenester ønsker kunder å oppnå 1. høy skalerbarhet for å håndtere volumet av innkommende hendelser og 2. pålitelighet av hendelsesbehandling og opprettholde systemfunksjonalitet i møte med feil.
Kunder bruker mikrotjenestearkitekturmønstre for å akselerere innovasjon og time-to-market for nye funksjoner, fordi det gjør applikasjoner enklere å skalere og raskere å utvikle. Det er imidlertid utfordrende å berike og spille av dataene i en nettverksanrop til en annen mikrotjeneste fordi det kan påvirke påliteligheten til applikasjonen og gjøre det vanskelig å feilsøke og spore feil. For å løse dette problemet er event-sourcing et effektivt designmønster som sentraliserer historiske registreringer av alle tilstandsendringer for berikelse og replay, og kobler lesing fra skrivearbeidsbelastninger. Kunder kan bruke Kinesis Data Streams som den sentraliserte hendelsesbutikken for hendelsessourcing-mikrotjenester, fordi KDS kan 1/ håndtere gigabyte datagjennomstrømning per sekund per strøm og streame dataene i millisekunder, for å møte kravet om høy skalerbarhet og nesten sanntid ventetid, 2/ integreres med Flink og S3 for dataanriking og oppnåelse mens de er fullstendig frakoblet fra mikrotjenestene, og 3/ tillat forsøk på nytt og asynkron lesing på et senere tidspunkt, fordi KDS beholder dataposten i en standard på 24 timer, og eventuelt opptil 365 dager.
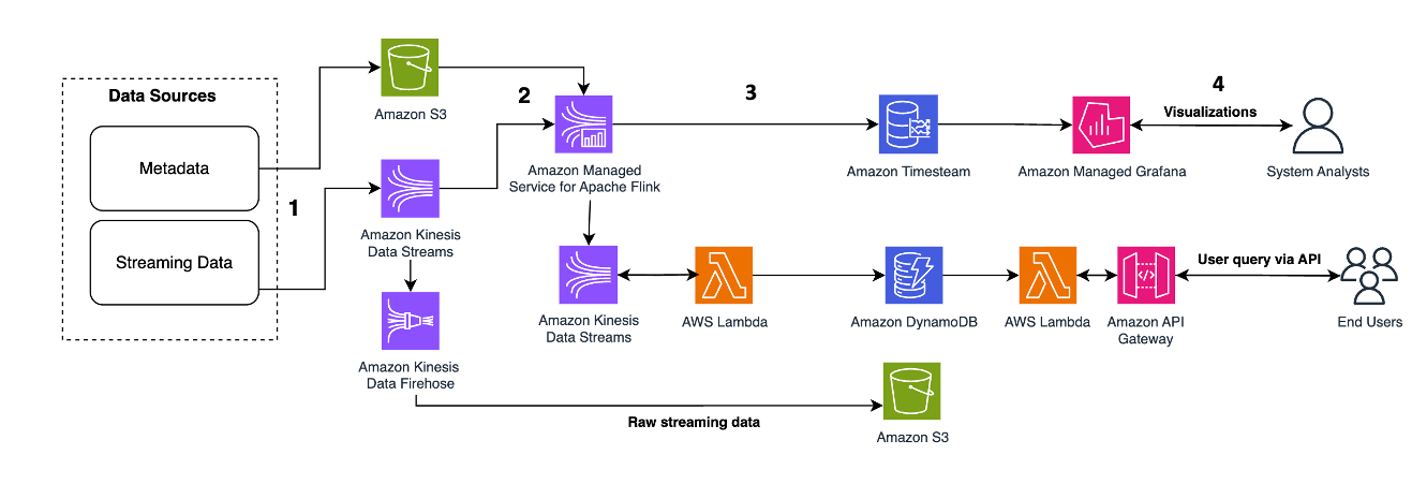
Følgende arkitektoniske mønster er en generisk illustrasjon av hvordan Kinesis Data Streams kan brukes for Event-Sourcing Microservices:
Trinnene i arbeidsflyten er som følger:
- Datainntak og lagring – Du kan samle inndataene fra mikrotjenestene dine til Kinesis Data Streams for lagring.
- Stream behandling - Apache Flink Stateful Functions forenkler bygging av distribuerte stateful hendelsesdrevne applikasjoner. Den kan motta hendelsene fra en Kinesis-datastrøm og rute den resulterende strømmen til en utdatastrøm. Du kan opprette en stateful funksjonsklynge med Apache Flink basert på applikasjonens forretningslogikk.
- Statens øyeblikksbilde i Amazon S3 – Du kan lagre tilstandsbildet i Amazon S3 for sporing.
- Utgangsstrømmer – Utgangsstrømmene kan konsumeres gjennom Lambda-fjernfunksjoner gjennom HTTP/gRPC-protokollen gjennom API-gateway.
- Lambda fjernkontroll funksjoner – Lambda-funksjoner kan fungere som mikrotjenester for ulike applikasjoner og forretningslogikk for å betjene forretningsapplikasjoner og mobilapper.
For å lære hvordan andre kunder bygde sine hendelsesbaserte mikrotjenester med Kinesis Data Streams, se følgende:
Viktige hensyn og beste praksis
Følgende er hensyn og beste fremgangsmåter du bør huske på:
- Dataoppdaging bør være ditt første skritt i å bygge moderne datastrømmeapplikasjoner. Du må definere forretningsverdien og deretter identifisere strømmingsdatakilder og brukerpersonas for å oppnå de ønskede forretningsresultatene.
- Velg verktøyet for inntak av strømmedata basert på din dampende datakilde. Du kan for eksempel bruke Kinesis SDK for inntak av strømmedata gjennom APIer, Kinesis produsentbibliotek for å bygge høyytelses og langvarige strømmeprodusenter, a Kinesis agent for å samle et sett med filer og ta dem inn i Kinesis Data Streams, AWS DMS for CDC-strømmebruk, og AWS IoT-kjerne for inntak av IoT-enhetsdata i Kinesis Data Streams. Du kan ta inn strømmedata direkte inn i Amazon Redshift for å bygge strømmeapplikasjoner med lav latens. Du kan også bruke tredjepartsbiblioteker som Apache Spark og Apache Kafka for å innta strømmedata i Kinesis Data Streams.
- Du må velge strømmedatabehandlingstjenester basert på din spesifikke brukssituasjon og forretningskrav. Du kan for eksempel bruke Amazon Kinesis Managed Service for Apache Flink for avanserte brukstilfeller for streaming med flere streamingdestinasjoner og kompleks stateful stream-behandling eller hvis du vil overvåke forretningsberegninger i sanntid (som hver time). Lambda er bra for hendelsesbasert og statsløs behandling. Du kan bruke Amazon EMR for strømming av databehandling for å bruke dine favorittrammeverk for stordata med åpen kildekode. AWS Glue er bra for strømmedatabehandling i nær sanntid for brukstilfeller som streaming av ETL.
- Kinesis Data Streams on-demand-modus lader etter bruk og skalerer opp ressurskapasiteten automatisk, så det er bra for piggete strømmearbeidsbelastninger og håndfritt vedlikehold. Tilordnet modus belastes etter kapasitet og krever proaktiv kapasitetsadministrasjon, så det er bra for forutsigbare strømmearbeidsbelastninger.
- Du kan også bruke det Kinesis delt kalkulator for å beregne antall shards som trengs for klargjort modus. Du trenger ikke være bekymret for shards med on-demand-modus.
- Når du gir tillatelser, bestemmer du hvem som får hvilke tillatelser til hvilke Kinesis Data Streams-ressurser. Du aktiverer spesifikke handlinger som du vil tillate på disse ressursene. Derfor bør du bare gi tillatelsene som kreves for å utføre en oppgave. Du kan også kryptere dataene i hvile ved å bruke en KMS kundeadministrert nøkkel (CMK).
- Du kan oppdatere oppbevaringsperioden via Kinesis Data Streams-konsollen eller ved å bruke Øk strømoppbevaringsperioden og Reduser strømoppbevaringsperioden operasjoner basert på dine spesifikke brukstilfeller.
- Kinesis Data Streams støtter resharding. Anbefalt API for denne funksjonen er OppdaterShardCount, som lar deg endre antall shards i strømmen din for å tilpasse seg endringer i dataflythastigheten gjennom strømmen. Resharding-API-ene (Split og Merge) brukes vanligvis til å håndtere varme shards.
konklusjonen
Dette innlegget demonstrerte forskjellige arkitektoniske mønstre for å bygge strømmeapplikasjoner med lav latens med Kinesis Data Streams. Du kan bygge dine egne dampapplikasjoner med lav latens med Kinesis Data Streams ved å bruke informasjonen i dette innlegget.
For detaljerte arkitektoniske mønstre, se følgende ressurser:
Hvis du vil bygge en datavisjon og -strategi, sjekk ut AWS datadrevet alt (D2E) program.
Om forfatterne
 Raghavarao Sodabatathina er en hovedløsningsarkitekt hos AWS, med fokus på dataanalyse, AI/ML og skysikkerhet. Han engasjerer seg med kunder for å skape innovative løsninger som adresserer kundenes forretningsproblemer og for å akselerere innføringen av AWS-tjenester. På fritiden liker Raghavarao å tilbringe tid med familien, lese bøker og se filmer.
Raghavarao Sodabatathina er en hovedløsningsarkitekt hos AWS, med fokus på dataanalyse, AI/ML og skysikkerhet. Han engasjerer seg med kunder for å skape innovative løsninger som adresserer kundenes forretningsproblemer og for å akselerere innføringen av AWS-tjenester. På fritiden liker Raghavarao å tilbringe tid med familien, lese bøker og se filmer.
 Heng Zuo er senior produktsjef i Amazon Kinesis Data Streams-teamet hos Amazon Web Services. Han brenner for å utvikle intuitive produktopplevelser som løser komplekse kundeproblemer og gjør det mulig for kundene å nå sine forretningsmål.
Heng Zuo er senior produktsjef i Amazon Kinesis Data Streams-teamet hos Amazon Web Services. Han brenner for å utvikle intuitive produktopplevelser som løser komplekse kundeproblemer og gjør det mulig for kundene å nå sine forretningsmål.
 Shwetha Radhakrishnan er en Solutions Architect for AWS med fokus på Data Analytics. Hun har bygget løsninger som driver skyadopsjon og hjelper organisasjoner med å ta datadrevne beslutninger innen offentlig sektor. Utenom jobben elsker hun å danse, tilbringe tid med venner og familie og reise.
Shwetha Radhakrishnan er en Solutions Architect for AWS med fokus på Data Analytics. Hun har bygget løsninger som driver skyadopsjon og hjelper organisasjoner med å ta datadrevne beslutninger innen offentlig sektor. Utenom jobben elsker hun å danse, tilbringe tid med venner og familie og reise.
 Brittany Ly er løsningsarkitekt hos AWS. Hun er fokusert på å hjelpe bedriftskunder med deres skyadopsjon og moderniseringsreise og har en interesse for sikkerhet og analysefeltet. Utenom jobben elsker hun å tilbringe tid med hunden sin og spille pickleball.
Brittany Ly er løsningsarkitekt hos AWS. Hun er fokusert på å hjelpe bedriftskunder med deres skyadopsjon og moderniseringsreise og har en interesse for sikkerhet og analysefeltet. Utenom jobben elsker hun å tilbringe tid med hunden sin og spille pickleball.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/architectural-patterns-for-real-time-analytics-using-amazon-kinesis-data-streams-part-1/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 100
- 24
- 7
- a
- evne
- Om oss
- akselerere
- adgang
- aksesseres
- Oppnå
- oppnådd
- oppnår
- oppnå
- tvers
- Handling
- skuespill
- handlinger
- tilpasse
- tillegg
- Ytterligere
- I tillegg
- adresse
- Adopsjon
- avansert
- Fordel
- Etter
- alder
- Agent
- aggregat
- AI / ML
- mål
- varsler
- Alle
- tillate
- tillate
- tillater
- også
- Amazon
- Amazon Kinesis
- Amazon Timestream
- Amazon Web Services
- an
- analyse
- analytics
- analysere
- og
- anomali påvisning
- En annen
- noen
- Apache
- Apache Kafka
- Apache Spark
- api
- APIer
- Søknad
- søknader
- tilnærming
- apps
- arkitektonisk
- arkitektur
- ER
- AS
- assosiert
- At
- Automatisk
- automatisk
- tilgjengelighet
- tilgjengelig
- AWS
- AWS Lim
- AWS Lambda
- basert
- BE
- fordi
- vært
- atferd
- være
- BEST
- beste praksis
- Bedre
- mellom
- Stor
- Store data
- Blogg
- bøker
- både
- bygge
- Bygning
- bygget
- virksomhet
- Business Applications
- bedrifter
- men
- by
- beregne
- ring
- CAN
- Kapasitet
- fangst
- hvilken
- saken
- saker
- CDC
- sentrum
- sentralisert
- viss
- utfordrende
- endring
- Endringer
- avgifter
- sjekk
- valg
- Velg
- ren
- Rengjøring
- Cloud
- skyadopsjon
- Cloud Security
- Cluster
- samle
- Samle
- Felles
- kommunisere
- helt
- komplekse
- komponenter
- komponert
- Beregn
- databehandling
- bekymret
- konfigurering
- betraktninger
- består
- Konsoll
- stadig
- forbruke
- forbrukes
- forbruker
- Forbrukere
- kontakt
- kontakt senter
- kontinuerlig
- kontinuerlig
- kontroll
- skape
- opprettet
- kritisk
- kunde
- Kunder
- tilpasset
- Dans
- oversikter
- dato
- dataanalyse
- Data Analytics
- datarikning
- Data Lake
- Dataledelse
- datapunkter
- databehandling
- datalager
- data-drevet
- Database
- databaser
- Dager
- bestemme
- avgjørelse
- Beslutningstaking
- avgjørelser
- dekoblet
- dedikert
- Misligholde
- definere
- leverer
- demonstrert
- avhengig
- utforming
- designet
- ønsket
- destinasjonen
- destinasjoner
- detaljert
- detaljer
- oppdage
- Gjenkjenning
- utvikle
- utvikle
- Utvikling
- enhet
- Enheter
- forskjellig
- vanskelig
- direkte
- Funnet
- distribueres
- distribuert databehandling
- do
- Hund
- ikke
- ned
- stasjonen
- drevet
- slitestyrke
- dynamisk
- hver enkelt
- enklere
- lett
- lett
- Effektiv
- omfavne
- muliggjøre
- kryptering
- endepunkter
- engasjerer
- forbedret
- berike
- Enterprise
- bedriftskunder
- feil
- Eter (ETH)
- Event
- hendelser
- Hver
- alle
- eksempel
- eksempler
- forventer
- erfaring
- Erfaringer
- utforske
- utvide
- trekke ut
- Face
- feil
- familie
- Mote
- raskere
- Favoritt
- Trekk
- Egenskaper
- felt
- Filer
- Først
- fem
- flyten
- Fokus
- fokuserte
- fokusering
- etter
- følger
- Til
- Rammeverk
- rammer
- ofte
- venner
- fra
- funksjon
- funksjonalitet
- funksjoner
- videre
- Gevinst
- gateway
- generere
- generert
- få
- GitHub
- gir
- Mål
- god
- innvilge
- innvilgelse
- håndtere
- Henge
- he
- hjelpe
- hjelpe
- her
- Høy
- høy ytelse
- hans
- historisk
- HOT
- time
- TIMER
- Hvordan
- Men
- HTML
- http
- HTTPS
- Hundrevis
- identifisere
- if
- illustrerer
- Påvirkning
- in
- I andre
- inkluderer
- Innkommende
- Øke
- økende
- uavhengig
- påvirket
- informasjon
- Infrastruktur
- infrastruktur
- nyskapende
- Innovasjon
- innovative
- inngang
- innsikt
- installere
- integrere
- integrert
- integrering
- integrasjoner
- interesse
- Interface
- Internet
- Internett av ting
- inn
- introdusert
- intuitiv
- påkalt
- IOT
- IoT-enhet
- IT
- DET ER
- reise
- jpg
- Kafka
- Hold
- nøkkel
- Kinesis datastrømmer
- innsjø
- Ventetid
- seinere
- lag
- lag
- LÆRE
- Ledger
- bibliotekene
- Bibliotek
- lett
- i likhet med
- levende
- laste
- logg
- logikk
- logisk
- elsker
- vedlikeholde
- vedlikehold
- gjøre
- GJØR AT
- Making
- fikk til
- ledelse
- leder
- mange
- Marketing
- maksimal
- måling
- Media
- Møt
- Minne
- Flett
- metadata
- Metrics
- microservices
- Middle
- migrasjon
- millisekunder
- tankene
- Mobil
- Mobilapplikasjoner
- håndholdte enheter
- mobil-apps
- Mote
- Moderne
- modernisering
- moduser
- modifisere
- Overvåke
- mer
- Filmer
- flere
- må
- innfødt
- Nær
- Trenger
- nødvendig
- behov
- nettverk
- Ny
- Nye funksjoner
- nå
- Antall
- of
- tilby
- Tilbud
- on
- På etterspørsel
- bare
- åpen
- åpen kildekode
- drift
- operasjonell
- Drift
- Optimalisere
- optimalisert
- Alternativ
- or
- rekkefølge
- organisasjons
- organisasjoner
- Annen
- vår
- ut
- utfall
- produksjon
- utenfor
- enn
- egen
- del
- lidenskapelig
- Mønster
- mønstre
- Betale
- for
- utføre
- ytelse
- tillatelser
- Personlig
- rør
- rørledning
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- Spille
- plugg inn
- poeng
- Post
- praksis
- Forutsigbar
- Prisene
- prising
- primære
- Principal
- Før
- privat
- Proaktiv
- Problem
- problemer
- prosess
- behandlet
- Prosesser
- prosessering
- produsert
- produsent
- Produsentene
- Produkt
- Produktsjef
- program
- protokollen
- gi
- gir
- proxy
- offentlig
- område
- raskt
- Sats
- Raw
- rådata
- Lese
- Lesning
- ekte
- sanntids
- sanntidsdata
- motta
- mottar
- Anbefaling
- anbefales
- rekord
- registrert
- poster
- redusere
- referere
- region
- pålitelighet
- pålitelig
- fjernkontroll
- påkrevd
- behov
- Krav
- Krever
- ressurs
- Ressurser
- ansvarlig
- REST
- resulterende
- beholde
- beholder
- oppbevaring
- anmeldelse
- Rute
- samme
- skalerbarhet
- skalerbar
- Skala
- vekter
- Sekund
- sektor
- sikkerhet
- senior
- sensorer
- Sequence
- Serien
- betjene
- server~~POS=TRUNC
- tjeneste
- Tjenester
- sett
- delt
- hun
- bør
- utstillingsvindu
- forenkler
- liten
- Snapshot
- So
- selskap
- sosiale medier
- Software
- programvareutvikling
- løsning
- Solutions
- LØSE
- kilde
- Kilder
- Spark
- spesifikk
- fart
- bruke
- utgifter
- pigger
- splittet
- stable
- Tilstand
- Trinn
- Steps
- lager
- lagring
- oppbevare
- lagret
- Strategi
- stream
- streames
- streaming
- bekker
- streng
- senere
- slik
- tilstrekkelig
- støtte
- Støtter
- system
- bord
- Ta
- Oppgave
- oppgaver
- lag
- titus
- Det
- De
- informasjonen
- Staten
- deres
- Dem
- deretter
- Der.
- derfor
- Disse
- de
- ting
- tredjeparts
- denne
- De
- tusener
- tre
- Gjennom
- gjennomstrømning
- tid
- Tidsserier
- tidssensitiv
- til
- i dag
- verktøy
- spore
- spor
- Sporing
- trafikk
- Transform
- Transformation
- transformere
- Traveling
- Trender
- to
- typisk
- Uventet
- upon
- bruk
- bruke
- bruk sak
- brukt
- Bruker
- ved hjelp av
- bruke
- validering
- verdi
- variabel
- ulike
- Hastighet
- av
- virtuelle
- syn
- visualisering
- visualisere
- volum
- volumer
- ønsker
- Warehouse
- lager
- se
- we
- web
- webtjenester
- veldefinerte
- Hva
- når
- hvilken
- mens
- HVEM
- bred
- Bred rekkevidde
- vil
- med
- innenfor
- Arbeid
- arbeidsflyt
- bekymring
- skrive
- du
- Din
- zephyrnet
- soner