- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.nanowerk.com/news2/robotics/newsid=63842.php
- :er
- 10
- 100
- 15%
- 2023
- 7
- a
- I stand
- tvers
- vedta
- AI
- alike
- Alle
- Selv
- blant
- an
- og
- svar
- anvendt
- ER
- AS
- spør
- aspekter
- assistenter
- assosiert
- At
- angripe
- Angrep
- tilgjengelig
- borte
- BE
- være
- mellom
- milliarder
- bygge
- bedrifter
- men
- by
- CAN
- nøye
- konsernsjef
- chatbots
- ChatGPT
- fjerne
- stengt
- Felles
- Selskaper
- datamaskin
- Bekymring
- angå
- Konferanse
- kunne
- skape
- Opprette
- kritisk
- I dag
- cyber
- Dato
- demonstrere
- demonstrert
- utplasserings
- detaljert
- Gjenkjenning
- utvikle
- forskjellig
- digitalt
- oppdaget
- dr
- bedrifter
- Hele
- Selv
- bevis
- eksisterer
- eksisterende
- Exploit
- utdrag
- ekstremt
- fascinerende
- finansiell
- finansielle tjenester
- Først
- fokuserte
- Til
- fra
- videre
- fikk
- gitt
- Giving
- Ground
- Ha
- skjult
- striper
- vert
- Hvordan
- Hvordan
- Men
- HTTPS
- Klem ansikt
- viktig
- in
- økt
- stadig
- industri
- informere
- informasjon
- informasjonssikkerhet
- innsiktsfull
- Internet
- Investere
- investere
- IT
- jpg
- nøkkel
- kunnskap
- kjent
- Språk
- stor
- Store bedrifter
- lansere
- ledende
- LÆRE
- læring
- mindre
- lite
- maskin
- maskinlæring
- større
- Kan..
- måling
- millioner
- modell
- modeller
- mye
- Ny
- of
- on
- åpen
- åpen kildekode
- or
- ut
- egen
- Papir
- parti
- Peter
- steder
- planlegging
- plato
- Platon Data Intelligence
- PlatonData
- mulig
- potensielt
- kraftig
- forbereder
- presentert
- Principal
- privat
- gi
- offentlig
- område
- Sats
- replikert
- forespørsler
- forskning
- forskere
- avsløre
- risikoer
- Sa
- sier
- forskere
- sikkerhet
- Tjenester
- sett
- bør
- Vis
- mindre
- Smart
- So
- noen
- kilde
- Scene
- Oppstart
- Storm
- Studer
- suksess
- vellykket
- slik
- tatt
- snakker
- målrettet
- rettet mot
- oppgaver
- lag
- Technologies
- Teknologi
- Testing
- enn
- Det
- De
- informasjonen
- Storbritannia
- verden
- deres
- deretter
- Der.
- Disse
- de
- tror
- Tredje
- denne
- dette året
- ganger
- til
- verktøy
- overføres
- transformative
- Uk
- forståelse
- påta
- universitet
- bruke
- brukt
- bruker
- verdsatt
- veldig
- Sikkerhetsproblemer
- var
- Vei..
- we
- uke
- var
- hvilken
- bred
- Bred rekkevidde
- vil
- med
- innenfor
- uten
- Arbeid
- trene
- virker
- verden
- bekymringsfull
- år
- zephyrnet
Mer fra Nanowerk
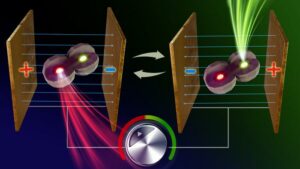
Slipper løs en ny æra av fargejusterbare nanoenheter – den minste lyskilden noensinne med omskiftbare farger dannet
Kilde node: 2801585
Tidstempel: August 3, 2023

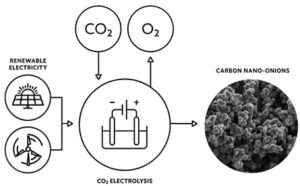
Karbon nanorør kan spille en betydelig rolle i å binde atmosfærisk karbondioksid
Kilde node: 2836729
Tidstempel: August 21, 2023

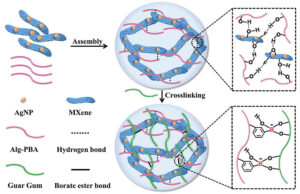
MXene hydrogelbaserte antibakterielle epidermiske sensorer
Kilde node: 2661017
Tidstempel: Kan 18, 2023
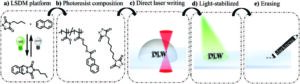
3D-utskrifter slutter seg til den mørke siden og forsvinner
Kilde node: 2903619
Tidstempel: September 27, 2023
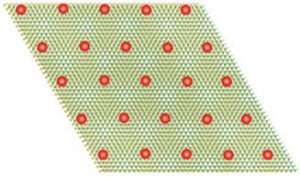
Når materialet blir kvante, bremser elektronene ned og danner en krystall
Kilde node: 1975767
Tidstempel: Februar 23, 2023

Ingeniører utvikler en effektiv prosess for å lage drivstoff fra karbondioksid
Kilde node: 2963812
Tidstempel: Oktober 30, 2023