Organisaties in alle sectoren hebben complexe gegevensverwerkingsvereisten voor hun analytische use-cases in verschillende analysesystemen, zoals datameren op AWS, datawarehouses (Amazon roodverschuiving), zoekopdracht (Amazon OpenSearch-service), GeenSQL (Amazon DynamoDB), machinaal leren (Amazon Sage Maker), en meer. Analytics-professionals hebben de taak waarde te ontlenen aan gegevens die zijn opgeslagen in deze gedistribueerde systemen om betere, veilige en kostengeoptimaliseerde ervaringen voor hun klanten te creëren. Digitale mediabedrijven proberen bijvoorbeeld datasets in interne en externe databases te combineren en te verwerken om uniforme weergaven van hun klantprofielen op te bouwen, ideeën voor innovatieve functies aan te wakkeren en platformbetrokkenheid te vergroten.
In deze scenario's gebruiken klanten die op zoek zijn naar een serverloos data-integratieaanbod AWS lijm als een kerncomponent voor het verwerken en catalogiseren van gegevens. AWS Glue is goed geïntegreerd met AWS-services en partnerproducten en biedt low-code/no-code extractie-, transformatie- en laadopties (ETL) om analyses, machine learning (ML) of workflows voor applicatieontwikkeling mogelijk te maken. AWS Glue ETL-taken kunnen een onderdeel zijn van een complexere pijplijn. Het orkestreren van de werking van en het beheren van afhankelijkheden tussen deze componenten is een belangrijke mogelijkheid in een gegevensstrategie. Door Amazon beheerde workflows voor Apache Airflows (Amazon MWAA) orkestreert datapijplijnen met behulp van gedistribueerde technologieën, waaronder lokale bronnen, AWS-services en componenten van derden.
In dit bericht laten we zien hoe u het monitoren van een AWS Glue-taak, georkestreerd door Airflow, kunt vereenvoudigen met behulp van de nieuwste functies van Amazon MWAA.
Overzicht van de oplossing
Dit bericht bespreekt het volgende:
- Een Amazon MWAA-omgeving upgraden naar versie 2.4.3.
- Een AWS Glue-taak orkestreren vanuit een Airflow Gerichte Acyclische grafiek (DAG).
- De waarneembaarheidsverbeteringen van het Airflow Amazon-providerpakket in Amazon MWAA. U kunt nu uitvoeringslogboeken van AWS Glue-taken consolideren op de Airflow-console om het oplossen van problemen met gegevenspijplijnen te vereenvoudigen. De Amazon MWAA-console wordt een enkele referentie voor het bewaken en analyseren van AWS Glue-taakuitvoeringen. Voorheen moesten ondersteuningsteams toegang krijgen tot de AWS-beheerconsole en onderneem handmatige stappen voor deze zichtbaarheid. Deze functie is standaard beschikbaar vanaf Amazon MWAA versie 2.4.3.
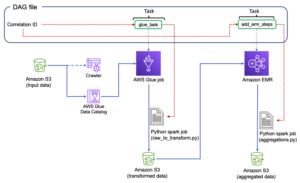
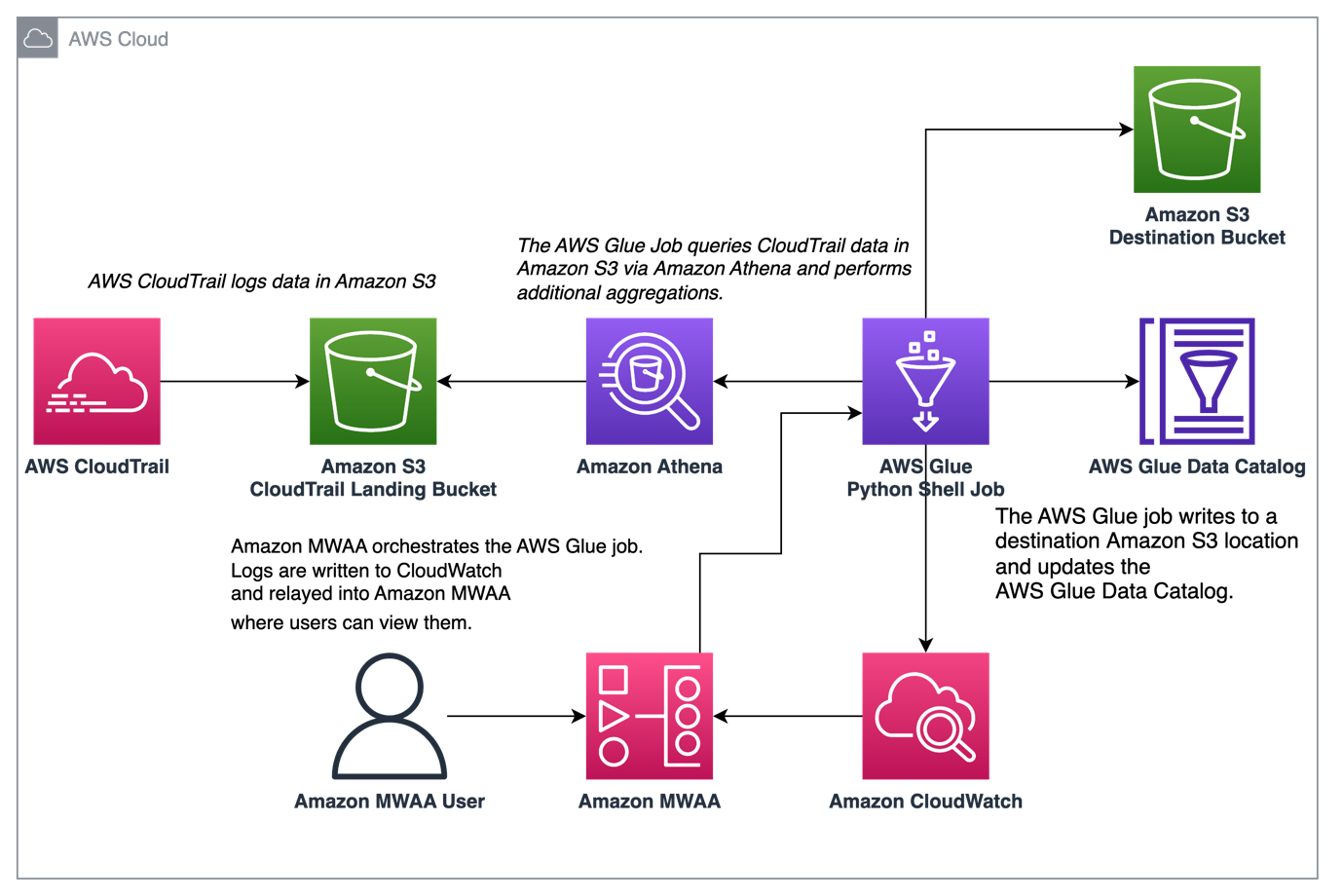
Het volgende diagram illustreert onze oplossingsarchitectuur.
Voorwaarden
Je hebt de volgende voorwaarden nodig:
Stel de Amazon MWAA-omgeving in
Raadpleeg voor instructies over het maken van uw omgeving Creëer een Amazon MWAA-omgeving. Voor bestaande gebruikers raden we aan om te upgraden naar versie 2.4.3 om te profiteren van de waarneembaarheidsverbeteringen in dit bericht.
De stappen om Amazon MWAA te upgraden naar versie 2.4.3 verschillen, afhankelijk van of de huidige versie 1.10.12 of 2.2.2 is. We bespreken beide opties in dit bericht.
Vereisten voor het opzetten van een Amazon MWAA-omgeving
U moet aan de volgende voorwaarden voldoen:
Upgrade van versie 1.10.12 naar 2.4.3
Als u de Amazon MWAA-versie gebruikt 1.10.12, verwijzen naar Migreren naar een nieuwe Amazon MWAA-omgeving om te upgraden naar 2.4.3.
Upgrade van versie 2.0.2 of 2.2.2 naar 2.4.3
Als u Amazon MWAA-omgeving versie 2.2.2 of lager gebruikt, voert u de volgende stappen uit:
- Maak een requirements.txt voor eventuele aangepaste afhankelijkheden met specifieke versies die nodig zijn voor uw DAG's.
- Upload het bestand naar Amazon S3 op de juiste locatie waar de Amazon MWAA-omgeving verwijst naar het bestand requirements.txt voor het installeren van afhankelijkheden.
- Volg de stappen in Migreren naar een nieuwe Amazon MWAA-omgeving en selecteer versie 2.4.3.
Update uw DAG's
Klanten die een upgrade hebben uitgevoerd vanuit een oudere Amazon MWAA-omgeving, moeten mogelijk updates maken voor bestaande DAG's. In Airflow versie 2.4.3 gebruikt de Airflow-omgeving standaard het Amazon providerpakket versie 6.0.0. Dit pakket bevat mogelijk enkele mogelijk ingrijpende wijzigingen, zoals wijzigingen in de namen van operators. Bijvoorbeeld de AWSGlueJobOperator is verouderd en vervangen door de GlueJobOperator. Werk uw Airflow DAG's bij door verouderde of niet-ondersteunde operators uit eerdere versies te vervangen door de nieuwe om de compatibiliteit te behouden. Voer de volgende stappen uit:
- Navigeer naar Amazon AWS-operators.
- Selecteer de juiste versie die is geïnstalleerd in uw Amazon MWAA-instantie (standaard 6.0.0) om een lijst met ondersteunde Airflow-operators te vinden.
- Breng de nodige wijzigingen aan in de bestaande DAG-code en upload de gewijzigde bestanden naar de DAG-locatie in Amazon S3.
Orkestreer de AWS Glue-taak vanuit Airflow
Dit gedeelte behandelt de details van het orkestreren van een AWS Glue-taak binnen Airflow DAG's. Airflow vereenvoudigt de ontwikkeling van datapijplijnen met afhankelijkheden tussen heterogene systemen zoals lokale processen, externe afhankelijkheden, andere AWS-services en meer.
Organiseer CloudTrail-logaggregatie met AWS Glue en Amazon MWAA
In dit voorbeeld bekijken we een use-case van het gebruik van Amazon MWAA om een AWS Glue Python Shell-taak te orkestreren die geaggregeerde statistieken op basis van CloudTrail-logboeken behoudt.
CloudTrail maakt zichtbaarheid mogelijk van AWS API-aanroepen die worden gedaan in uw AWS-account. Een veelvoorkomende use-case met deze gegevens zou zijn om gebruiksstatistieken te verzamelen over opdrachtgevers die handelen op de bronnen van uw account voor audits en wettelijke vereisten.
Terwijl CloudTrail-gebeurtenissen worden gelogd, worden ze geleverd als JSON-bestanden in Amazon S3, wat niet ideaal is voor analytische vragen. We willen deze gegevens samenvoegen en bewaren als Parquet-bestanden om optimale queryprestaties mogelijk te maken. Als eerste stap kunnen we Athena gebruiken om de eerste gegevens op te vragen voordat we aanvullende aggregaties uitvoeren in onze AWS Glue-taak. Raadpleeg voor meer informatie over het maken van een AWS Glue Data Catalog-tabel De tabel maken voor CloudTrail-logboeken in Athena met behulp van partitieprojectie gegevens. Nadat we de gegevens via Athena hebben verkend en hebben besloten welke statistieken we in geaggregeerde tabellen willen behouden, kunnen we een AWS Glue-taak maken.
Maak een CloudTrail-tabel in Athena
Eerst moeten we een tabel maken in onze gegevenscatalogus waarmee CloudTrail-gegevens kunnen worden opgevraagd via Athena. Met de volgende voorbeeldquery wordt een tabel gemaakt met twee partities op de regio en de datum (snapshot_date genoemd). Vervang de tijdelijke aanduidingen voor uw CloudTrail-bucket, AWS-account-ID en CloudTrail-tabelnaam:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')Voer de voorgaande query uit op de Athena-console en noteer de tabelnaam en de AWS Glue Data Catalog-database waar deze is gemaakt. We gebruiken deze waarden later in de Airflow DAG-code.
Voorbeeld AWS Glue-taakcode
De volgende code is een voorbeeld AWS Glue Python Shell-taak dat doet het volgende:
- Neemt argumenten (die we doorgeven van onze Amazon MWAA DAG) over de gegevens van de dag die moeten worden verwerkt
- Gebruikt de AWS SDK voor Panda's om een Athena-query uit te voeren om de eerste filtering van de CloudTrail JSON-gegevens buiten AWS Glue uit te voeren
- Gebruikt Panda's om eenvoudige aggregaties uit te voeren op de gefilterde gegevens
- Voert de geaggregeerde gegevens uit naar de AWS Glue Data Catalog in een tabel
- Gebruikt logboekregistratie tijdens de verwerking, die zichtbaar zal zijn in Amazon MWAA
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
De volgende zijn enkele belangrijke voordelen in deze AWS Glue-taak:
- We gebruiken een Athena-query om ervoor te zorgen dat de eerste filtering buiten onze AWS Glue-taak om plaatsvindt. Als zodanig is een Python Shell-taak met minimale rekenkracht nog steeds voldoende voor het aggregeren van een grote CloudTrail-dataset.
- Wij zorgen voor de analytics bibliotheek-set optie is ingeschakeld bij het maken van onze AWS Glue-taak om de AWS SDK voor Panda's-bibliotheek te gebruiken.
Maak een AWS Glue-taak aan
Voer de volgende stappen uit om uw AWS Glue-taak te maken:
- Kopieer het script in de voorgaande sectie en sla het op in een lokaal bestand. Voor dit bericht heet het bestand
script.py. - Kies op de AWS Glue-console: ETL-banen in het navigatievenster.
- Maak een nieuwe taak aan en selecteer Python Shell-scripteditor.
- kies Een bestaand script uploaden en bewerken en upload het bestand dat u lokaal hebt opgeslagen.
- Kies creëren.

- Op de Details van de baan tabblad, voer een naam in voor uw AWS Glue-taak.
- Voor IAM-rol, kies een bestaande rol of maak een nieuwe rol met de vereiste machtigingen voor Amazon S3, AWS Glue en Athena. De rol moet de CloudTrail-tabel opvragen die u eerder hebt gemaakt en naar een uitvoerlocatie schrijven.
U kunt de volgende voorbeeldbeleidscode gebruiken. Vervang de tijdelijke aanduidingen door uw CloudTrail-logboekenbucket, uitvoertabelnaam, uitvoer AWS Glue-database, uitvoer S3-bucket, CloudTrail-tabelnaam, AWS Glue-database met de CloudTrail-tabel en uw AWS-account-ID.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
Voor Python-versie, kiezen Python 3.9.
- kies Laad algemene analysebibliotheken.
- Voor Gegevensverwerkingseenheden, kiezen 1 DPU.
- Laat de andere opties standaard staan of pas ze naar wens aan.

- Kies Bespaar om uw taakconfiguratie op te slaan.
Configureer een Amazon MWAA DAG om de AWS Glue-taak te orkestreren
De volgende code is voor een DAG die de AWS Glue-taak die we hebben gemaakt, kan orkestreren. We maken gebruik van de volgende belangrijke functies in deze DAG:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
Vergroot de waarneembaarheid van AWS Glue-taken in Amazon MWAA
De AWS Glue-taken schrijven logs naar Amazon Cloud Watch. Met de recente verbeteringen van de waarneembaarheid van Airflow's Amazon-providerpakket, zijn deze logboeken nu geïntegreerd met Airflow-taaklogboeken. Deze consolidatie biedt Airflow-gebruikers end-to-end zichtbaarheid rechtstreeks in de Airflow UI, waardoor het niet meer nodig is om te zoeken in CloudWatch of de AWS Glue-console.
Om deze functie te gebruiken, moet u ervoor zorgen dat de IAM-rol die is gekoppeld aan de Amazon MWAA-omgeving de volgende machtigingen heeft om de benodigde logboeken op te halen en te schrijven:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}Als breedsprakig = waar, worden de AWS Glue-taakrunlogboeken weergegeven in de Airflow-taaklogboeken. De standaardwaarde is onwaar. Voor meer informatie, zie parameters.
Indien ingeschakeld, lezen de DAG's uit de CloudWatch-logstroom van de AWS Glue-taak en sturen deze door naar de Airflow DAG AWS Glue-taakstaplogboeken. Dit biedt gedetailleerde inzichten in de uitvoering van een AWS Glue-taak in realtime via de DAG-logboeken. Houd er rekening mee dat AWS Glue-taken een CloudWatch-logboekgroep voor uitvoer en fouten genereren op basis van respectievelijk de STDOUT en STDERR van de taak. Alle logboeken in de uitvoerlogboekgroep en uitzonderings- of foutlogboeken van de foutenlogboekgroep worden doorgegeven aan Amazon MWAA.
AWS-beheerders kunnen nu de toegang van een ondersteuningsteam beperken tot alleen Airflow, waardoor Amazon MWAA het enige venster is op het gebied van taakorkestratie en taakgezondheidsbeheer. Voorheen moesten gebruikers de status van de AWS Glue-taakrun controleren in de Airflow DAG-stappen en de taakrun-ID ophalen. Vervolgens moesten ze toegang krijgen tot de AWS Glue-console om de taakuitvoeringsgeschiedenis te vinden, naar de taak van belang te zoeken met behulp van de identifier en ten slotte naar de CloudWatch-logboeken van de taak te navigeren om problemen op te lossen.
Maak de DAG
Voer de volgende stappen uit om de DAG te maken:
- Sla de voorgaande DAG-code op in een lokaal .py-bestand en vervang de aangegeven tijdelijke aanduidingen.
De waarden voor uw AWS-account-ID, AWS Glue-taaknaam, AWS Glue-database met CloudTrail-tabel en CloudTrail-tabelnaam zouden al bekend moeten zijn. U kunt de output S3-bucket, output AWS Glue-database en uitvoertabelnaam naar behoefte aanpassen, maar zorg ervoor dat de IAM-rol van de AWS Glue-taak die u eerder gebruikte, dienovereenkomstig is geconfigureerd.
- Navigeer op de Amazon MWAA-console naar uw omgeving om te zien waar de DAG-code is opgeslagen.
De map DAGs is het voorvoegsel binnen de S3-bucket waar uw DAG-bestand moet worden geplaatst.
- Upload daar je bewerkte bestand.

- Open de Amazon MWAA-console om te bevestigen dat de DAG in de tabel verschijnt.

Voer de DAG uit
Voer de volgende stappen uit om de DAG uit te voeren:
- Kies uit de volgende opties:
- Activeer DAG – Hierdoor worden de gegevens van gisteren gebruikt als de te verwerken gegevens
- Activeer DAG met configuratie – Met deze optie kunt u een andere datum doorgeven, eventueel voor aanvullingen, die wordt opgehaald met behulp van
dag_run.confin de DAG-code en vervolgens als parameter doorgegeven aan de AWS Glue-taak

De volgende schermafbeelding toont de aanvullende configuratie-opties als u daarvoor kiest Activeer DAG met configuratie.

- Bewaak de DAG terwijl deze wordt uitgevoerd.
- Wanneer de DAG is voltooid, opent u de details van de run.
In het rechterdeelvenster kunt u de logboeken bekijken of kiezen Details taakinstantie voor een volledig zicht.

- Bekijk de AWS Glue-taakuitvoerlogboeken in Amazon MWAA zonder de AWS Glue-console te gebruiken dankzij de
GlueJobOperatoruitgebreide vlag.

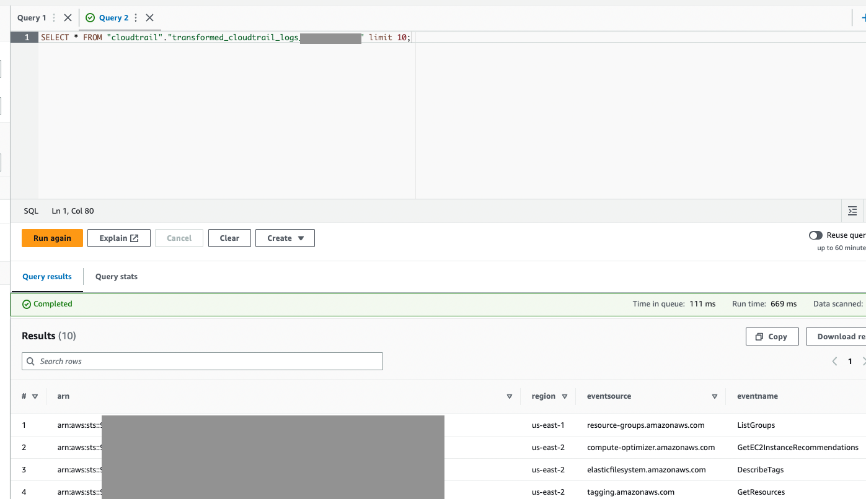
De AWS Glue-taak heeft resultaten geschreven naar de uitvoertabel die u hebt opgegeven.
- Vraag deze tabel via Athena om te bevestigen dat deze succesvol was.
Samengevat
Amazon MWAA biedt nu één plek om de status van AWS Glue-taken bij te houden en stelt u in staat om de Airflow-console te gebruiken als het enige venster voor taakorkestratie en gezondheidsbeheer. In dit bericht hebben we de stappen doorlopen om AWS Glue-taken via Airflow te orkestreren GlueJobOperator. Met de nieuwe observatieverbeteringen kunt u probleemloos problemen met AWS Glue-taken oplossen in een uniforme ervaring. We hebben ook gedemonstreerd hoe u uw Amazon MWAA-omgeving kunt upgraden naar een compatibele versie, afhankelijkheden kunt bijwerken en het IAM-rolbeleid dienovereenkomstig kunt wijzigen.
Raadpleeg voor meer informatie over algemene stappen voor probleemoplossing Problemen oplossen: een Amazon MWAA-omgeving maken en bijwerken. Raadpleeg voor meer informatie over migreren naar een Amazon MWAA-omgeving Upgraden van 1.10 naar 2. Raadpleeg de logs van AWS Glue-taken doorsturen.
Tot slot raden we aan om een bezoek te brengen aan de AWS Big Data-blog voor ander materiaal over analyse, ML en gegevensbeheer op AWS.
Over de auteurs
 Rushab Lokhande is een Data & ML Engineer met de AWS Professional Services Analytics Practice. Hij helpt klanten bij het implementeren van oplossingen voor big data, machine learning en analyse. Buiten zijn werk brengt hij graag tijd door met zijn gezin, lezen, hardlopen en golfen.
Rushab Lokhande is een Data & ML Engineer met de AWS Professional Services Analytics Practice. Hij helpt klanten bij het implementeren van oplossingen voor big data, machine learning en analyse. Buiten zijn werk brengt hij graag tijd door met zijn gezin, lezen, hardlopen en golfen.
 Ryan Gomes is een Data & ML Engineer met de AWS Professional Services Analytics Practice. Hij is gepassioneerd om klanten te helpen betere resultaten te behalen door middel van analyses en machine learning-oplossingen in de cloud. Buiten zijn werk houdt hij van fitness, koken en quality time doorbrengen met vrienden en familie.
Ryan Gomes is een Data & ML Engineer met de AWS Professional Services Analytics Practice. Hij is gepassioneerd om klanten te helpen betere resultaten te behalen door middel van analyses en machine learning-oplossingen in de cloud. Buiten zijn werk houdt hij van fitness, koken en quality time doorbrengen met vrienden en familie.
 Vishwa Gupta is een Senior Data Architect bij de AWS Professional Services Analytics Practice. Hij helpt klanten bij het implementeren van big data- en analyseoplossingen. Buiten zijn werk brengt hij graag tijd door met zijn gezin, reizen en nieuwe gerechten proberen.
Vishwa Gupta is een Senior Data Architect bij de AWS Professional Services Analytics Practice. Hij helpt klanten bij het implementeren van big data- en analyseoplossingen. Buiten zijn werk brengt hij graag tijd door met zijn gezin, reizen en nieuwe gerechten proberen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- : heeft
- :is
- :niet
- :waar
- $UP
- 1
- 10
- 100
- 12
- 8
- a
- Over
- toegang
- dienovereenkomstig
- Account
- Bereiken
- over
- Actie
- acyclische
- Extra
- Voordeel
- voordelen
- Na
- aggregatie
- Alles
- toelaten
- toestaat
- al
- ook
- Amazone
- Amazon Web Services
- an
- Analytisch
- analytics
- analyseren
- en
- elke
- apache
- api
- Aanvraag
- Application Development
- passend
- architectuur
- ZIJN
- argument
- argumenten
- AS
- At
- attributen
- auditing
- Beschikbaar
- AWS
- AWS lijm
- AWS professionele services
- gebaseerde
- BE
- wordt
- geweest
- vaardigheden
- wezen
- Betere
- tussen
- Groot
- Big data
- zowel
- Breaking
- bouw
- maar
- by
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- oproepen
- CAN
- geval
- gevallen
- catalogus
- oorzaken
- verandering
- Wijzigingen
- controle
- Kies
- Cloud
- code
- COM
- combineren
- commentaar
- Gemeen
- Bedrijven
- verenigbaarheid
- verenigbaar
- compleet
- complex
- bestanddeel
- componenten
- Berekenen
- Configuratie
- Bevestigen
- troosten
- consolideren
- consolidering
- koken
- Kern
- heeft betrekking op
- en je merk te creëren
- aangemaakt
- creëert
- Wij creëren
- Actueel
- gewoonte
- klant
- Klanten
- DAG
- gegevens
- gegevens integratie
- gegevensverwerking
- gegevensstrategie
- data warehouses
- Database
- databanken
- datasets
- Datum
- Data
- datetime
- dagen
- beslist
- Standaard
- geleverd
- gedemonstreerd
- Afhankelijk
- deprecated
- gedetailleerd
- gegevens
- Ontwikkeling
- verschillen
- anders
- digitaal
- Digitale media
- direct
- bespreken
- verdeeld
- gedistribueerde systemen
- do
- doet
- doen
- gedaan
- gedurende
- e
- Vroeger
- Gemak
- effect
- elimineren
- anders
- in staat stellen
- ingeschakeld
- maakt
- eind tot eind
- engagement
- ingenieur
- uitbreidingen
- verzekeren
- Enter
- Milieu
- fout
- Ether (ETH)
- EVENTS
- voorbeeld
- Behalve
- uitzondering
- bestaan
- bestaand
- bestaat
- ervaring
- Ervaringen
- Nagegaan
- uitdrukking
- extern
- extract
- Mislukt
- vals
- familie
- Kenmerk
- uitgelicht
- Voordelen
- Dien in
- Bestanden
- filtering
- Tot slot
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- geschiktheid
- volgend
- eten
- Voor
- formaat
- vrienden
- oppompen van
- vol
- verzamelen
- voortbrengen
- glas
- Go
- golfen
- bestuur
- Groep
- Hadoop
- Hebben
- he
- Gezondheid
- het helpen van
- helpt
- geschiedenis
- Bijenkorf
- Hoe
- How To
- HTML
- http
- HTTPS
- IAM
- ID
- ideaal
- ideeën
- identificatie
- if
- illustreert
- uitvoeren
- importeren
- in
- diepgaande
- omvatten
- Inclusief
- Laat uw omzet
- meer
- aangegeven
- industrieën
- info
- informatie
- eerste
- innovatieve
- inzichten
- installeren
- instantie
- instructies
- geïntegreerde
- integratie
- belang
- intern
- in
- IT
- Jobomschrijving:
- Vacatures
- jpg
- json
- sleutel
- bekend
- Groot
- later
- laatste
- LEARN
- leren
- Bibliotheek
- LIMIT
- Lijst
- laden
- lokaal
- plaatselijk
- plaats
- inloggen
- ingelogd
- logging
- op zoek
- machine
- machine learning
- gemaakt
- onderhouden
- maken
- maken
- beheerd
- management
- beheren
- handboek
- materiaal
- Mei..
- Media
- Maak kennis met
- Bericht
- Metriek
- migreren
- minimaal
- ML
- gewijzigd
- module
- monitor
- Grensverkeer
- meer
- Dan moet je
- naam
- namen
- OP DEZE WEBSITE VIND JE
- Navigatie
- noodzakelijk
- Noodzaak
- nodig
- behoeften
- New
- niets
- nu
- of
- het aanbieden van
- on
- EEN
- degenen
- Slechts
- open
- open source
- open-sourcecode
- operator
- exploitanten
- optimale
- Keuze
- Opties
- or
- georkestreerd
- orkestratie
- Overige
- onze
- resultaten
- uitgang
- buiten
- pakket
- panda's
- brood
- parameters
- partner
- passeren
- voorbij
- hartstochtelijk
- prestatie
- permissies
- aanhoudt
- pijpleiding
- plaats
- platform
- Plato
- Plato gegevensintelligentie
- PlatoData
- punten
- beleidsmaatregelen
- Post
- mogelijk
- praktijk
- vereisten
- vorig
- die eerder
- processen
- verwerking
- Producten
- professioneel
- professionals
- Profielen
- Projectie
- leverancier
- providers
- biedt
- Python
- kwaliteit
- queries
- verhogen
- reeks
- Lees
- lezing
- vast
- real-time
- recent
- adviseren
- regio
- regelgevers
- Relais
- vervangen
- vervangen
- nodig
- Voorwaarden
- hulpbron
- Resources
- respectievelijk
- antwoord
- Resultaten
- behouden
- rechts
- Rol
- RIJ
- lopen
- lopend
- s
- Bespaar
- scenario's
- sdk
- naadloos
- Ontdek
- sectie
- beveiligen
- zien
- Zoeken
- senior
- Serverless
- Diensten
- het instellen van
- setup
- Shell
- moet
- tonen
- Shows
- Eenvoudig
- vereenvoudigen
- sinds
- single
- Momentopname
- oplossing
- Oplossingen
- sommige
- specifiek
- gespecificeerd
- Uitgaven
- Statement
- Status
- Stap voor
- Stappen
- Still
- mediaopslag
- opgeslagen
- Strategie
- stream
- Draad
- geslaagd
- dergelijk
- voldoende
- ondersteuning
- ondersteunde
- Systems
- tafel
- Nemen
- het nemen
- Taak
- teams
- Technologies
- sjabloon
- bedankt
- dat
- De
- hun
- Ze
- harte
- Er.
- Deze
- ze
- van derden
- dit
- Door
- niet de tijd of
- naar
- spoor
- Transformeren
- Reizend
- waar
- proberen
- dinsdag
- Gedraaid
- twee
- type dan:
- ui
- unified
- eenheid
- bijwerken
- updates
- bijwerken
- upgrade
- opgewaardeerd
- Uploaden
- Gebruik
- .
- use case
- gebruikt
- gebruikers
- gebruik
- waarde
- Values
- versie
- via
- Bekijk
- .
- zichtbaarheid
- zichtbaar
- wandelde
- willen
- was
- we
- web
- webservices
- GOED
- Wat
- wanneer
- of
- welke
- WIE
- wil
- Met
- binnen
- zonder
- Mijn werk
- workflows
- zou
- schrijven
- geschreven
- u
- Your
- zephyrnet