SmugMug exploiteert twee zeer grote online fotoplatforms, SmugMug en Flickr, waardoor meer dan 100 miljoen klanten tientallen miljarden foto's veilig kunnen opslaan, doorzoeken, delen en verkopen. Klanten die tientallen jaren aan foto's uploadden en doorzochten, hielpen zoekopdrachten om te zetten in een kritieke infrastructuur, die gestaag groeide sinds SmugMug voor het eerst werd gebruikt Amazon Cloud Search in 2012, gevolgd door Amazon OpenSearch-service sinds 2018, na het bereiken van miljarden documenten en terabytes aan zoekopslag.
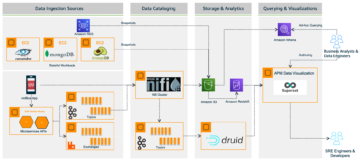
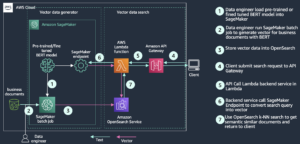
Hier deelt Lee Shepherd, SmugMug Staff Engineer, de zoekarchitectuur van SmugMug die wordt gebruikt om live verkeer naar meerdere clusters te publiceren, aan te vullen en te spiegelen. SmugMug gebruikt deze pijplijnen voor het benchmarken, valideren en migreren naar nieuwe configuraties, waaronder op Graviton gebaseerde r6gd.2xlarge-instanties van i3.2xlarge, samen met testen Amazon OpenSearch Serverloos. We behandelen drie pijplijnen die worden gebruikt voor publiceren, opvullen en bevragen zonder stekelige, onrealistische verkeerspatronen te introduceren, en zonder enige impact op productieservices.
Er zijn twee belangrijke architecturale stukken die cruciaal zijn voor het proces:
- Een duurzame bron van waarheid voor indexgegevens. Het is de beste praktijk en onderdeel van onze back-upstrategie om een duurzame opslag te hebben buiten de OpenSearch-index, en Amazon DynamoDB biedt schaalbaarheid en integratie met AWS Lambda dat vereenvoudigt een groot deel van het proces. We gebruiken DynamoDB voor andere niet-zoekservices, dus dit was een logische match.
- Een Lambda-functie voor het publiceren van gegevens uit de bron van de waarheid in OpenSearch. Gebruik makend van functie-aliassen helpt bij het tegelijkertijd uitvoeren van meerdere configuraties van dezelfde Lambda-functie en is essentieel voor het gesynchroniseerd houden van gegevens.
Reclame
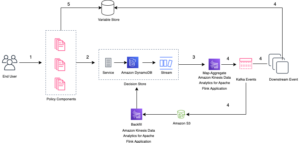
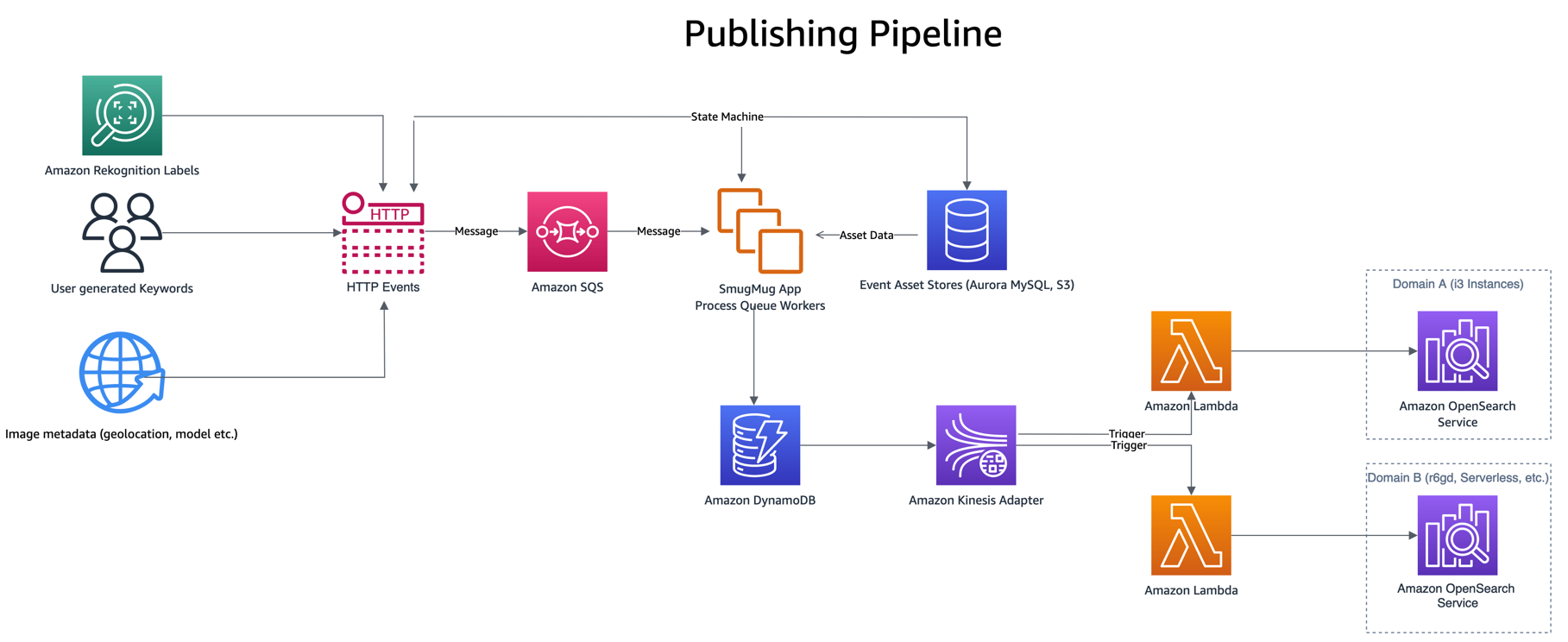
De publicatiepijplijn wordt aangestuurd door gebeurtenissen zoals een gebruiker die trefwoorden of bijschriften invoert, nieuwe uploads of labeldetectie Amazon Rekognition. Deze gebeurtenissen worden verwerkt, waarbij gegevens van een paar andere activawinkels worden gecombineerd, zoals Amazon Aurora MySQL-compatibele editie en Eenvoudige opslagservice van Amazon (Amazon S3), voordat u een enkel item naar DynamoDB schrijft.
Schrijven naar DynamoDB roept een Lambda-publicatiefunctie op via de DynamoDB Streams Kinesis-adapter, dat een reeks bijgewerkte items uit DynamoDB haalt en deze indexeert in OpenSearch. Er zijn nog andere voordelen aan het gebruik van de DynamoDB Streams Kinesis Adapter, zoals het verminderen van het aantal gelijktijdige Lambda's dat nodig is.
De publicerende Lambda-functie gebruikt omgevingsvariabelen om te bepalen naar welk OpenSearch-domein en welke index moet worden gepubliceerd. Er is een productiealias geconfigureerd om naar het productie-OpenSearch-domein te schrijven, buiten de DynamoDB-tabel of Kinesis Stream
Bij het testen van nieuwe configuraties of bij migratie wordt een migratiealias geconfigureerd om naar het nieuwe OpenSearch-domein te schrijven, maar dezelfde trigger te gebruiken als de productiealias. Dit maakt dubbele indexering van gegevens naar beide OpenSearch Service-domeinen tegelijkertijd mogelijk.
Hier is een voorbeeld van het DynamoDB-tabelschema:
De waarde 'LastUpdated' wordt gebruikt als de documentversie bij het indexeren, waardoor OpenSearch eventuele updates die niet in de juiste volgorde staan, kan weigeren.
Aanvulling
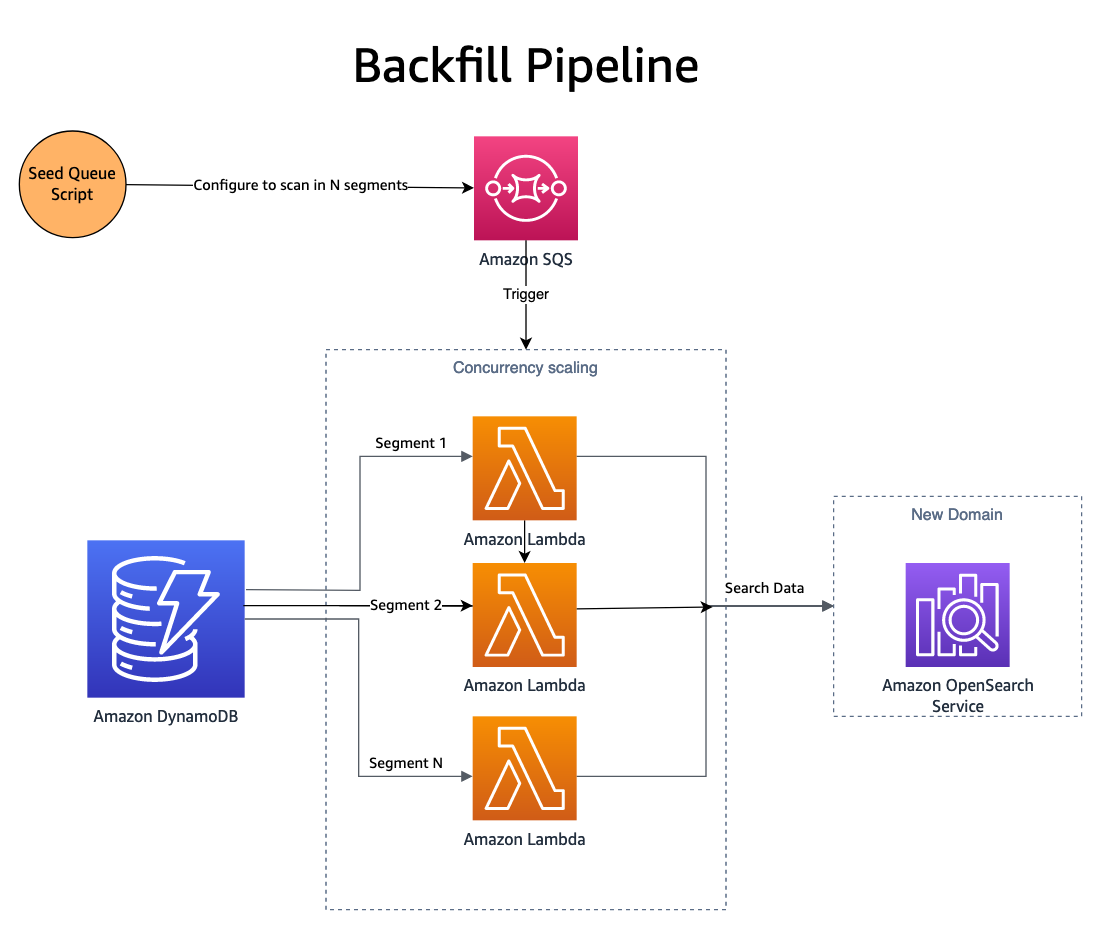
Nu er wijzigingen in beide domeinen worden gepubliceerd, moet het nieuwe domein (index) worden aangevuld met historische gegevens. Om een nieuw gemaakte index aan te vullen, wordt een combinatie van Amazon Simple Queue-service (Amazon SQS) en DynamoDB wordt gebruikt. Een script vult een SQS-wachtrij met berichten die instructies bevatten voor parallel scannen een segment van de DynamoDB-tabel.
De SQS-wachtrij lanceert een Lambda-functie die de berichtinstructies leest, een batch items ophaalt uit het overeenkomstige segment van de DynamoDB-tabel en deze naar een OpenSearch-index schrijft. Nieuwe berichten worden naar de SQS-wachtrij geschreven om de voortgang door het segment bij te houden. Nadat het segment is voltooid, worden er geen berichten meer naar de SQS-wachtrij geschreven en stopt het proces zichzelf.
Gelijktijdigheid wordt bepaald door het aantal segmenten, met extra controles die worden geboden door Lambda-gelijktijdigheidsschaling. SmugMug kan meer dan 1 miljard documenten per uur indexeren in hun OpenSearch-configuratie, zonder enige impact op het productiedomein.
Een op NodeJS AWS-SDK gebaseerd script wordt gebruikt om de SQS-wachtrij te seeden. Hier is een fragment van de opties van het SQS-configuratiescript:
Samen met het formaat van het resulterende SQS-bericht:
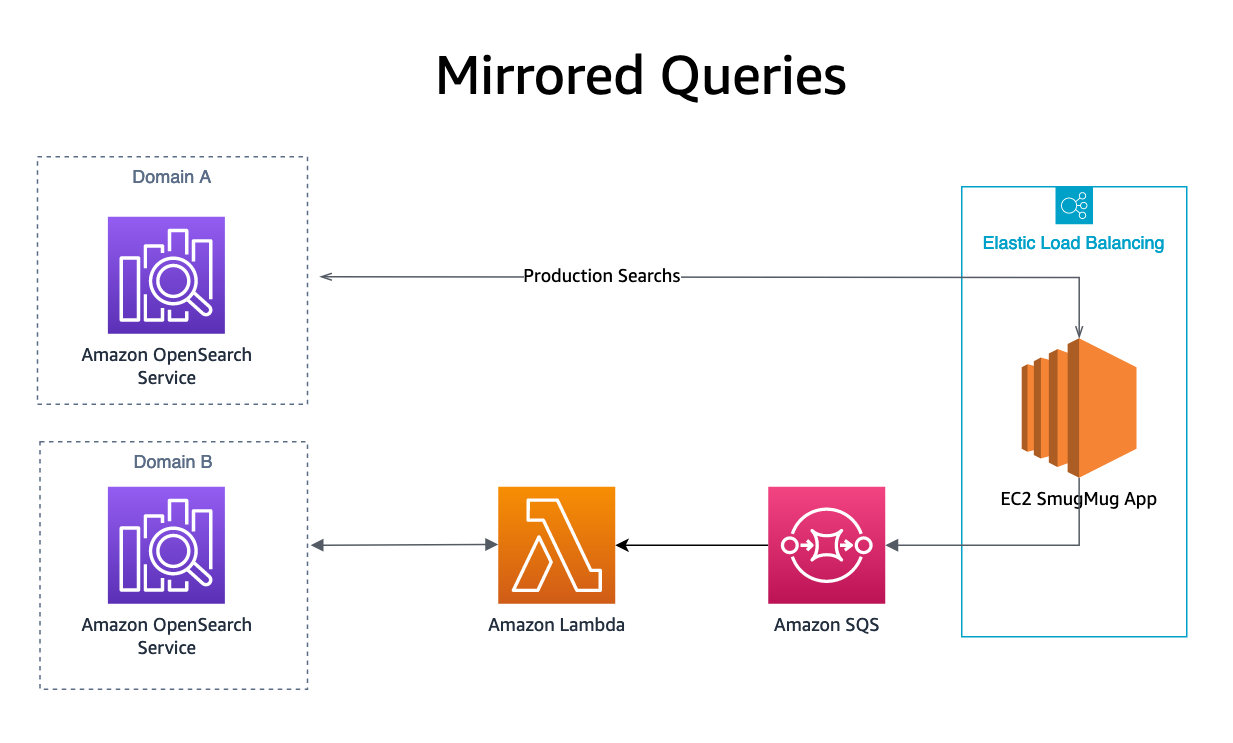
Mirroring
Als laatste, onze gespiegelde zoekopdracht resultaten worden uitgevoerd door een OpenSearch-query naar een SQS-wachtrij te sturen, naast ons productiedomein. De SQS-wachtrij start een Lambda-functie die de query opnieuw afspeelt naar het replicadomein. De zoekresultaten van deze verzoeken worden naar geen enkele gebruiker verzonden, maar maken het mogelijk de productiebelasting op de geteste OpenSearch-service te repliceren zonder gevolgen voor productiesystemen of klanten.
Conclusie
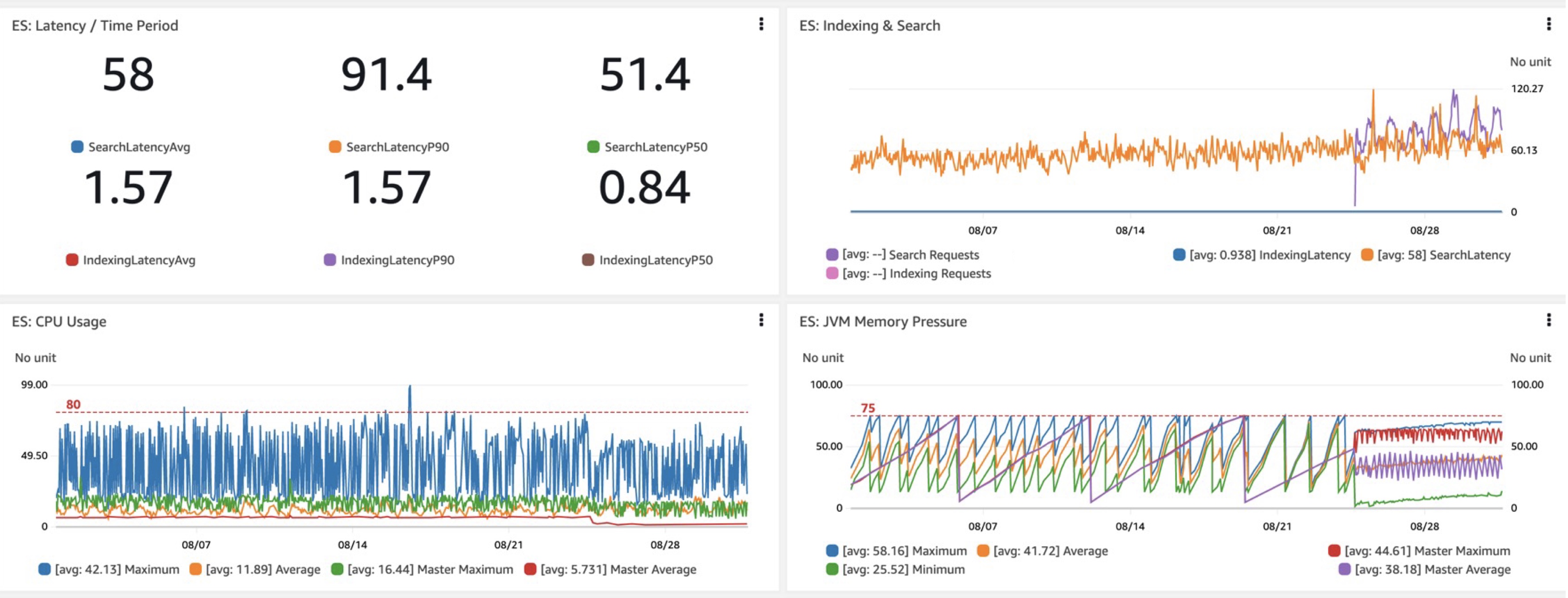
Bij het evalueren van een nieuw OpenSearch-domein of nieuwe configuratie zijn de belangrijkste statistieken waarin we geïnteresseerd zijn de prestaties van de querylatentie, namelijk de benodigde latenties (latenties per tijd), en vooral de latenties voor zoeken. Bij onze overstap naar Graviton R6gd zagen we ongeveer 40 procent lagere P50-P99-latenties, samen met vergelijkbare winsten in CPU-gebruik vergeleken met die van i3 (waarbij de lagere kosten van Graviton buiten beschouwing worden gelaten). Een ander welkom voordeel was de meer voorspelbare en controleerbare JVM-geheugendruk met de veranderingen in de garbagecollection als gevolg van de toevoeging van G1GC op R6gd en andere nieuwe instances.
Met behulp van deze pijplijn testen we ook OpenSearch Serverless en vinden we de beste gebruiksscenario's. We zijn enthousiast over die service en zijn van plan om op termijn een volledig serverloze architectuur te hebben. Blijf op de hoogte voor de resultaten.
Over de auteurs
Lee Herder is een SmugMug-stafsoftware-ingenieur
Aydn Bekirov is een Amazon Web Services Principal Technical Account Manager
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/smugmugs-durable-search-pipelines-for-amazon-opensearch-service/
- :is
- :niet
- 1
- 100
- 12
- 14
- 20
- 2012
- 2018
- 40
- 7
- 9
- a
- in staat
- Over
- Account
- toegevoegd
- toevoeging
- Extra
- Na
- toelaten
- Het toestaan
- langs
- ook
- Amazone
- Amazon Web Services
- an
- en
- Nog een
- elke
- bouwkundig
- architectuur
- ZIJN
- AS
- aanwinst
- At
- Aurora
- AWS
- backup
- gebaseerde
- BE
- vaardigheden
- wezen
- criterium
- voordeel
- betekent
- BEST
- Verder
- Miljard
- miljarden
- zowel
- maar
- by
- bijschriften
- Wijzigingen
- Collectie
- combinatie van
- combineren
- vergeleken
- verenigbaar
- voltooit
- gelijktijdig
- Configuratie
- geconfigureerd
- bevatten
- controles
- Overeenkomend
- Kosten
- deksel
- CPU
- aangemaakt
- kritisch
- Kritische infrastructuur
- Klanten
- gegevens
- decennia
- Opsporing
- Bepalen
- vastbesloten
- document
- documenten
- domein
- domeinen
- gedreven
- elk
- maakt
- waardoor
- Endpoint
- ingenieur
- het invoeren van
- geheel
- Milieu
- Ether (ETH)
- evalueren
- EVENTS
- voorbeeld
- opgewonden
- weinig
- Velden
- het vinden van
- Voornaam*
- geschikt
- gevolgd
- Voor
- formaat
- oppompen van
- geheel
- functie
- verdiensten
- Groeiend
- Hebben
- Hoogte
- geholpen
- helpt
- historisch
- uur
- HTML
- http
- HTTPS
- i
- i3
- ID
- Impact
- belangrijker
- in
- Inclusief
- index
- indexen
- Infrastructuur
- gevallen
- instructies
- integratie
- voornemens zijn
- geïnteresseerd
- in
- de invoering
- oproept
- artikelen
- herhaling
- HAAR
- zelf
- jpg
- Houden
- houden
- sleutel
- trefwoorden
- label
- Groot
- Wachttijd
- lanceert
- Luwte
- als
- leven
- laden
- lot
- te verlagen
- Hoofd
- Geheugen
- Bericht
- berichten
- Metriek
- trekken
- migreren
- migratie
- miljoen
- miljoen klanten
- spiegel
- meer
- meest
- beweging
- meervoudig
- MySQL
- naam
- namelijk
- Naturel
- behoeften
- New
- onlangs
- volgende
- geen
- aantal
- of
- korting
- on
- online.
- exploiteert
- Opties
- Opt
- or
- Overige
- onze
- Parallel
- deel
- patronen
- voor
- procent
- prestatie
- foto
- Foto's
- stukken
- pijpleiding
- platforms
- Plato
- Plato gegevensintelligentie
- PlatoData
- Voorspelbaar
- druk
- vorig
- Principal
- verwerkt
- productie
- Voortgang
- mits
- biedt
- publiceren
- gepubliceerde
- Reclame
- het bereiken van
- vermindering
- antwoord
- verzoeken
- nodig
- verkregen
- Resultaten
- lopen
- veilig
- dezelfde
- zagen
- Schaalbaarheid
- scaling
- script
- Ontdek
- zoeken
- zaad
- segment
- segmenten
- verkopen
- verzending
- verzonden
- Serverless
- service
- Diensten
- Delen
- Aandelen
- gelijk
- Eenvoudig
- gelijktijdig
- sinds
- single
- snipper
- So
- Software
- bron
- Medewerkers
- blijven
- gestaag
- Stopt
- mediaopslag
- shop
- winkels
- Strategie
- streams
- dergelijk
- Systems
- tafel
- neemt
- Technisch
- tienen
- proef
- Testen
- neem contact
- dat
- De
- De Bron
- hun
- Ze
- Er.
- Deze
- dit
- drie
- Door
- niet de tijd of
- naar
- nam
- spoor
- verkeer
- leiden
- waarheid
- BEURT
- twee
- voor
- bijgewerkt
- updates
- Uploaden
- URL
- Gebruik
- .
- gebruiksgevallen
- gebruikt
- Gebruiker
- toepassingen
- gebruik
- BEVESTIG
- waarde
- versie
- zeer
- was
- we
- web
- webservices
- welkom
- Wat
- wanneer
- en
- Met
- zonder
- schrijven
- het schrijven van
- geschreven
- zephyrnet
- nul