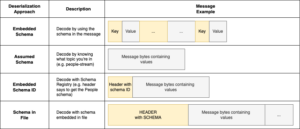
Amazon roodverschuiving is een cloud-datawarehousing-service die hoogwaardige analytische verwerking biedt op basis van een massaal parallelle verwerkingsarchitectuur (MPP). Het bouwen en onderhouden van datapipelines is een gemeenschappelijke uitdaging voor alle ondernemingen. Het beheren van de SQL-bestanden, het integreren van teamoverschrijdend werk, het integreren van alle software-engineeringprincipes en het importeren van externe hulpprogramma's kan een tijdrovende taak zijn die een complex ontwerp en veel voorbereiding vereist.
dbt (DataBuildTool) biedt dit mechanisme door een goed gestructureerd raamwerk te introduceren voor data-analyse, transformatie en orkestratie. Het past ook algemene software-engineeringprincipes toe, zoals integreren met git-repository's, opzetten Droger code, het toevoegen van functionele testgevallen en het opnemen van externe bibliotheken. Met dit mechanisme kunnen ontwikkelaars zich concentreren op het voorbereiden van de SQL-bestanden volgens de bedrijfslogica, en de rest wordt verzorgd door dbt.
In dit bericht onderzoeken we een optimale en kosteneffectieve manier om dbt binnen Amazon Redshift te integreren. We gebruiken Amazon-elastiek Containerregister (Amazon ECR) om onze dbt Docker-images op te slaan en AWS Fargate als Amazon Elastic Container-service (Amazon ECS)-taak om de taak uit te voeren.
Hoe werkt het dbt-framework met Amazon Redshift?
dbt heeft een Amazon Redshift-adaptermodule genaamd dbt-roodverschuiving waarmee het verbinding kan maken en kan werken met Amazon Redshift. Alle verbindingsprofielen worden geconfigureerd binnen de dbt profiles.yml bestand. In een optimale omgeving slaan wij de inloggegevens op AWS-geheimenmanager en haal ze op.
De volgende code toont de inhoud van profile.yml:
Het volgende diagram illustreert de belangrijkste componenten van het dbt-framework:
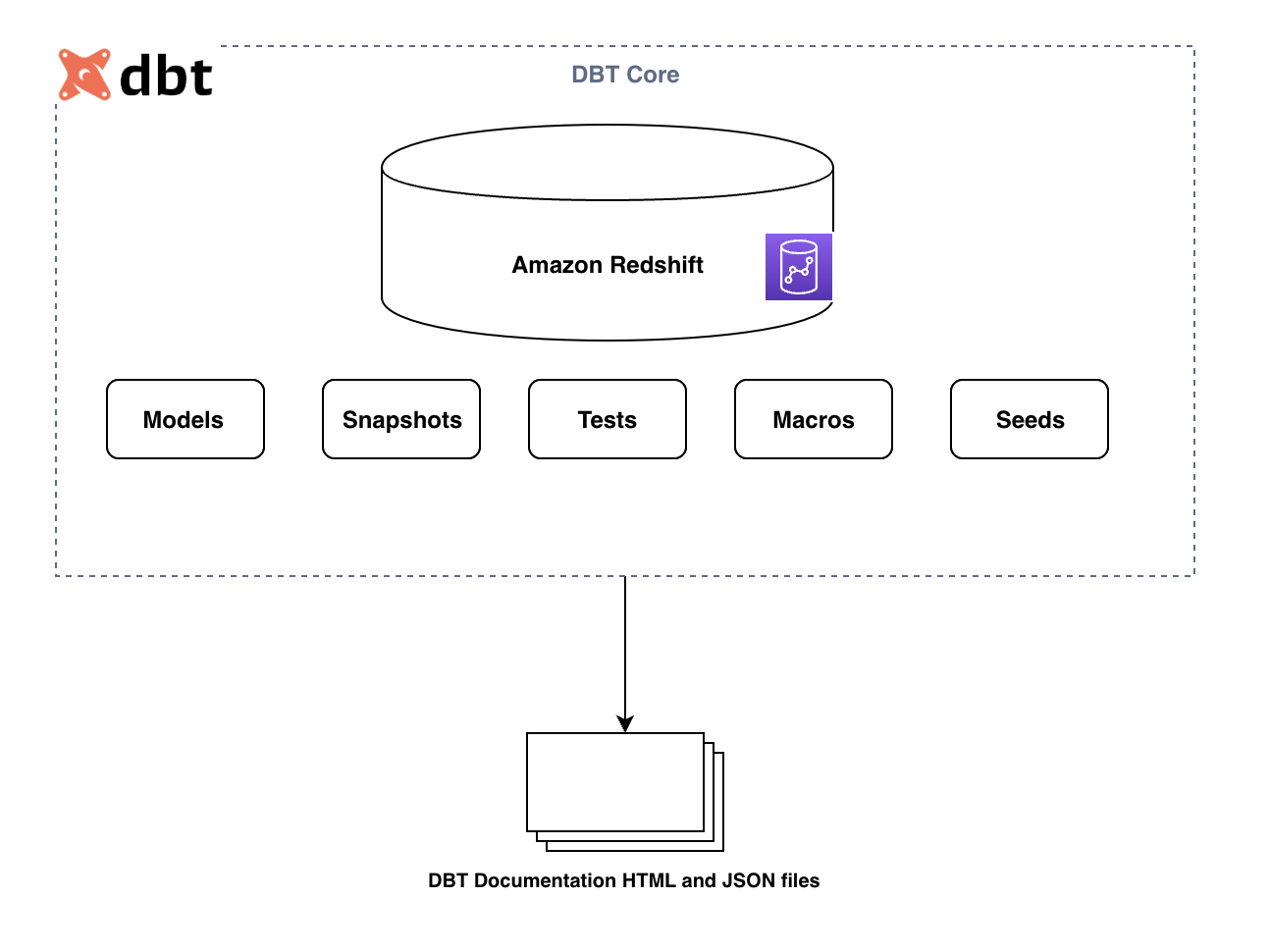
De belangrijkste componenten zijn als volgt:
- Modellen – Deze worden geschreven als een SELECT-instructie en opgeslagen als een .sql-bestand. Alle transformatiequery's kunnen hier worden geschreven en kunnen worden gematerialiseerd als een tabel of weergave. Het vernieuwen van de tabel kan volledig of incrementeel zijn, afhankelijk van de configuratie. Raadpleeg SQL-modellen voor meer informatie.
- Snapshots – Deze werktuigen type-2 langzaam veranderende afmetingen (SCD's) via veranderlijke brontabellen. Deze SCD's identificeren hoe een rij in een tabel in de loop van de tijd verandert.
- Zaden – Dit zijn CSV-bestanden in uw dbt-project (meestal in uw seeds-map), die dbt in uw datawarehouse met de
dbt seedopdracht. - Tests – Dit zijn beweringen die u doet over uw modellen en andere bronnen in uw dbt-project (zoals bronnen, zaden en snapshots). Wanneer je rent
dbt test, zal dbt u vertellen of elke test in uw project slaagt of faalt. - Macro's – Dit zijn stukjes code die meerdere keren hergebruikt kunnen worden. Ze zijn analoog aan “functies” in andere programmeertalen en zijn uiterst handig als u merkt dat u code in meerdere modellen herhaalt.
Deze componenten worden opgeslagen als .sql-bestanden en worden uitgevoerd door dbt CLI-opdrachten. Tijdens de run creëert dbt een Gerichte acyclische grafiek (DAG) gebaseerd op de interne referentie tussen de dbt-componenten. Het gebruikt de DAG om de uitvoeringsvolgorde dienovereenkomstig te orkestreren.
Er kunnen meerdere profielen worden aangemaakt binnen het bestand profielen.yml, dat dbt kan gebruiken om zich tijdens het uitvoeren op verschillende Redshift-omgevingen te richten. Voor meer informatie, zie Roodverschuiving instellen.
Overzicht oplossingen
Het volgende diagram illustreert onze oplossingsarchitectuur.
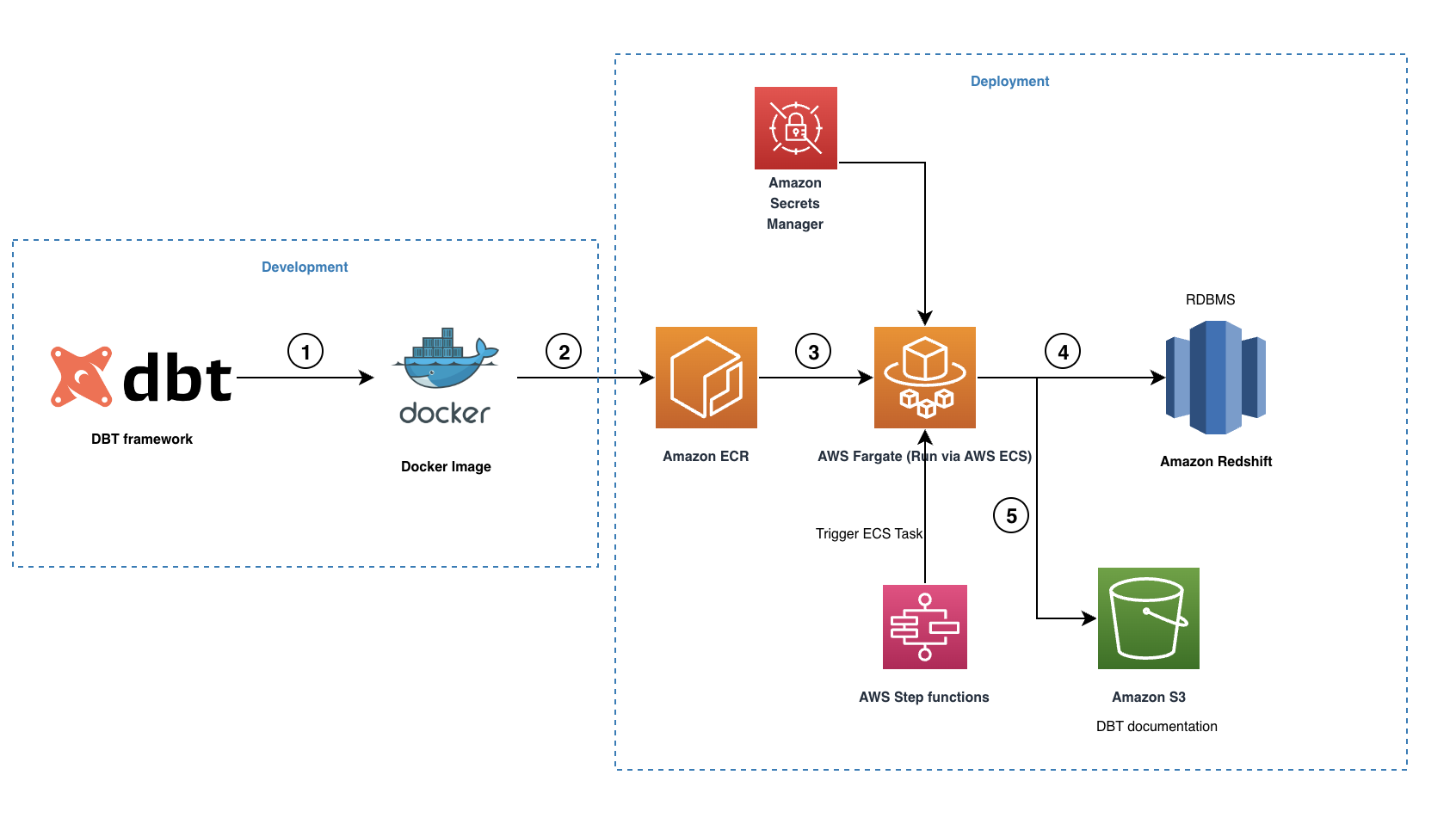
De workflow bevat de volgende stappen:
- De open source dbt-redshift connector wordt gebruikt om ons dbt-project te creëren, inclusief alle benodigde modellen, snapshots, tests, macro's en profielen.
- Er wordt een Docker-image gemaakt en naar de ECR-repository gepusht.
- De Docker-image wordt door Fargate uitgevoerd als een ECS-taak die wordt geactiveerd via AWS Stap Functies. Alle Amazon Redshift-inloggegevens worden opgeslagen in Secrets Manager, die vervolgens door de ECS-taak wordt gebruikt om verbinding te maken met Amazon Redshift.
- Tijdens de run converteert dbt alle modellen, snapshots, tests en macro's naar Amazon Redshift-compatibele SQL-instructies en orkestreert de run op basis van de interne gegevenslijngrafiek onderhouden. Deze SQL-opdrachten worden rechtstreeks op het Redshift-cluster uitgevoerd en daarom wordt de werklast rechtstreeks naar Amazon Redshift gepusht.
- Wanneer de run voltooid is, zal dbt een set HTML- en JSON-bestanden maken om de dbt documentatie, waarin de datacatalogus, gecompileerde SQL-instructies, data lineage-grafiek en meer worden beschreven.
Voorwaarden
U moet de volgende vereisten hebben:
- Een goed begrip van de dbt-principes en implementatiestappen.
- Een AWS-account met gebruikersroltoestemming voor toegang tot de AWS-services die in deze oplossing worden gebruikt.
- Beveiligingsgroepen voor Fargate om toegang te krijgen tot het Redshift-cluster en Secrets Manager van Amazon ECS.
- Een Redshift-cluster. Voor aanmaakinstructies, zie Een cluster maken.
- Een ECR-repository: Voor instructies, zie Een privé-opslagplaats maken
- Een geheimenmanager geheim met alle inloggegevens voor verbinding met Amazon Redshift. Dit omvat de host, poort, databasenaam, gebruikersnaam en wachtwoord. Voor meer informatie, zie Maak een AWS Secrets Manager-databasegeheim.
- An Amazon eenvoudige opslag (Amazon S3) bucket om documentatiebestanden te hosten.
Maak een dbt-project
We gebruiken dbt CLI, dus alle opdrachten worden op de opdrachtregel uitgevoerd. Installeer daarom pip als dit nog niet is gebeurd. Verwijzen naar installatie voor meer informatie.
Om een dbt-project aan te maken, voert u de volgende stappen uit:
- Installeer afhankelijke dbt-pakketten:
pip install dbt-redshift - Initialiseer een dbt-project met behulp van de
dbt init <project_name>opdracht, waarmee alle sjabloonmappen automatisch worden gemaakt. - Voeg alle vereiste DBT-artefacten toe.
Verwijs naar de dbt-roodverschuiving-etlpatroon repo die een referentie-dbt-project bevat. Voor meer informatie over bouwprojecten, zie Over dbt-projecten.
In het referentieproject hebben we de volgende functionaliteiten geïmplementeerd:
- SCD type 1 met behulp van incrementele modellen
- SCD type 2 met behulp van snapshots
- Seed-opzoekbestanden
- Macro's voor het toevoegen van herbruikbare code in het project
- Tests voor het analyseren van inkomende gegevens
Het Python-script is voorbereid om de inloggegevens op te halen die vereist zijn van Secrets Manager voor toegang tot Amazon Redshift. Verwijs naar de export_redshift_connection.py bestand.
- Bereid de
run_dbt.shscript om de dbt-pijplijn opeenvolgend uit te voeren. Dit script wordt in de hoofdmap van het dbt-project geplaatst, zoals weergegeven in de voorbeeldopslagplaats.
- Maak een Docker-bestand in de bovenliggende map van de dbt-projectmap. Met deze stap wordt de afbeelding opgebouwd van het dbt-project dat naar de ECR-repository moet worden gepusht.
Upload de afbeelding naar Amazon ECR en voer deze uit als een ECS-taak
Voer de volgende stappen uit om de afbeelding naar de ECR-repository te pushen:
- Haal een authenticatietoken op en authenticeer uw Docker-client in uw register:
- Bouw uw Docker-image met behulp van de volgende opdracht:
- Nadat de build is voltooid, tagt u uw afbeelding zodat u deze naar de repository kunt pushen:
- Voer de volgende opdracht uit om de afbeelding naar uw nieuw gemaakte AWS-repository te pushen:
- Maak op de Amazon ECS-console een cluster met Fargate als infrastructuuroptie.
- Geef indien nodig uw VPC en subnetten op.
- Nadat u het cluster hebt gemaakt, maakt u een ECS-taak en wijst u de gemaakte dbt-image toe als de taakdefinitiefamilie.
- Kies in het netwerkgedeelte uw VPC, subnetten en beveiligingsgroep om verbinding te maken met Amazon Redshift, Amazon S3 en Secrets Manager.
Deze taak activeert de run_dbt.sh pipeline-script en voer alle dbt-opdrachten opeenvolgend uit. Wanneer het script voltooid is, kunnen we de resultaten zien in Amazon Redshift en de documentatiebestanden die naar Amazon S3 zijn gepusht.
- U kunt de documentatie hosten via de statische websitehosting van Amazon S3. Voor meer informatie, zie Een statische website hosten met Amazon S3.
- Ten slotte kunt u deze taak in Step Functions uitvoeren als een ECS-taak om de taken naar wens te plannen. Voor meer informatie, zie Beheer Amazon ECS- of Fargate-taken met stapfuncties.
De dbt-roodverschuiving-etlpatroon repo heeft nu alle vereiste codevoorbeelden.
De kosten voor het uitvoeren van dbt-taken in AWS Fargate als een Amazon ECS-taak met minimale operationele vereisten zouden ongeveer $ 1.5 kosten (kosten_link) per maand.
Opruimen
Voer de volgende stappen uit om uw bronnen op te schonen:
- Verwijder het ECS-cluster jij hebt gemaakt.
- Verwijder de ECR-repository die u hebt gemaakt voor het opslaan van de afbeeldingsbestanden.
- Verwijder de roodverschuivingscluster jij hebt gemaakt.
- Verwijder de roodverschuivingsgeheimen opgeslagen in Geheimenbeheer.
Conclusie
Dit bericht behandelde de basisimplementatie van het op een kostenefficiënte manier gebruiken van dbt met Amazon Redshift door Fargate in Amazon ECS te gebruiken. We hebben de belangrijkste infrastructuur en configuratie-opzet beschreven met een voorbeeldproject. Deze architectuur kan u helpen profiteren van de voordelen van een dbt-framework om uw datawarehouse-platform in Amazon Redshift te beheren.
Raadpleeg het volgende voor meer informatie over dbt-macro's en modellen voor de interne werking en het onderhoud van Amazon Redshift GitHub repo. In een volgend bericht onderzoeken we de traditionele ETL-patronen (extract, transform en load) die u kunt implementeren met behulp van het dbt-framework in Amazon Redshift. Test deze oplossing in uw account en geef feedback of suggesties in de opmerkingen.
Over de auteurs
 Seshadri Senthamaraikannan is een data-architect met een AWS Professional Services-team gevestigd in Londen, VK. Hij heeft veel ervaring en is gespecialiseerd in Data Analytics en werkt met klanten die zich richten op het bouwen van innovatieve en schaalbare oplossingen in AWS Cloud om hun zakelijke doelstellingen te bereiken. In zijn vrije tijd brengt hij graag tijd door met zijn gezin en sport hij graag.
Seshadri Senthamaraikannan is een data-architect met een AWS Professional Services-team gevestigd in Londen, VK. Hij heeft veel ervaring en is gespecialiseerd in Data Analytics en werkt met klanten die zich richten op het bouwen van innovatieve en schaalbare oplossingen in AWS Cloud om hun zakelijke doelstellingen te bereiken. In zijn vrije tijd brengt hij graag tijd door met zijn gezin en sport hij graag.
 Mohammed Hamdi is een Senior Big Data Architect bij AWS Professional Services, gevestigd in Londen, VK. Hij heeft meer dan 15 jaar ervaring met het ontwerpen, leiden en bouwen van datawarehouses en big data-platforms. Hij helpt klanten bij het ontwikkelen van big data- en analyseoplossingen om hun bedrijfsresultaten te versnellen tijdens hun cloud-adoptietraject. Buiten zijn werk houdt Mohamed van reizen, hardlopen, zwemmen en squashen.
Mohammed Hamdi is een Senior Big Data Architect bij AWS Professional Services, gevestigd in Londen, VK. Hij heeft meer dan 15 jaar ervaring met het ontwerpen, leiden en bouwen van datawarehouses en big data-platforms. Hij helpt klanten bij het ontwikkelen van big data- en analyseoplossingen om hun bedrijfsresultaten te versnellen tijdens hun cloud-adoptietraject. Buiten zijn werk houdt Mohamed van reizen, hardlopen, zwemmen en squashen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/implement-data-warehousing-solution-using-dbt-on-amazon-redshift/
- : heeft
- :is
- :niet
- $UP
- 1
- 10
- 11
- 15 jaar
- 15%
- 7
- 8
- 90
- 970
- a
- Over
- versnellen
- toegang
- toegang
- Account
- over
- toevoegen
- toe te voegen
- Adoptie
- Voordeel
- Alles
- toestaat
- al
- ook
- Amazone
- Amazon Web Services
- an
- analyse
- Analytisch
- analytics
- het analyseren van
- en
- geldt
- architectuur
- ZIJN
- rond
- AS
- waarmerken
- authenticatie
- webmaster.
- AWS
- AWS professionele services
- gebaseerde
- basis-
- BE
- betekent
- tussen
- Groot
- Big data
- bouw
- Gebouw
- bouwt
- bedrijfsdeskundigen
- by
- CAN
- verzorging
- gevallen
- catalogus
- uitdagen
- Wijzigingen
- veranderende
- Kies
- schoon
- klant
- Cloud
- cloud adoptie
- TROS
- code
- opmerkingen
- Gemeen
- gecompileerd
- compleet
- complex
- compliant
- componenten
- Configuratie
- geconfigureerd
- Verbinden
- Wij verbinden
- versterken
- troosten
- Containers
- bevat
- inhoud
- kostenefficient
- bedekt
- en je merk te creëren
- aangemaakt
- creëert
- het aanmaken
- Geloofsbrieven
- gewoonte
- Klanten
- DAG
- gegevens
- gegevensanalyse
- gegevens Analytics
- datawarehouse
- data warehouses
- Database
- Standaard
- definitie
- afhankelijk
- beschreven
- Design
- Dev
- ontwikkelen
- ontwikkelaars
- anders
- direct
- havenarbeider
- documentatie
- doet
- gedurende
- elk
- maakt
- Engineering
- bedrijven
- Milieu
- omgevingen
- Ether (ETH)
- uitvoeren
- ervaring
- ervaren
- Verken
- extern
- extract
- uiterst
- mislukt
- familie
- Voordelen
- feedback
- Dien in
- Bestanden
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Focus
- gericht
- volgend
- volgt
- Voor
- Achtergrond
- oppompen van
- vol
- functioneel
- functies
- Algemeen
- voortbrengen
- Git
- Doelen
- goed
- diagram
- Groep
- Groep
- Hebben
- met
- he
- hulp
- helpt
- hier
- hoge performantie
- zijn
- gastheer
- Hosting
- Hoe
- HTML
- HTTPS
- identificeren
- if
- illustreert
- beeld
- afbeeldingen
- uitvoeren
- uitvoering
- geïmplementeerd
- importeren
- importeren
- in
- Anders
- omvat
- Inclusief
- opnemen
- incrementele
- informatie
- Infrastructuur
- innovatieve
- installeren
- instructies
- Integreren
- intern
- in
- de invoering
- IT
- Jobomschrijving:
- Vacatures
- json
- sleutel
- Talen
- laatste
- leidend
- bibliotheken
- als
- sympathieën
- Lijn
- laden
- logica
- Log in
- London
- Kijk
- veel
- macro's
- behoud van
- onderhoud
- maken
- beheer
- manager
- beheren
- massief
- mechanisme
- Maak kennis met
- minimaal
- model
- modellen
- module
- Mohamed
- Maand
- meer
- meervoudig
- naam
- Genoemd
- noodzakelijk
- netwerken
- onlangs
- nu
- of
- Aanbod
- on
- open
- open source
- operatie
- operationele
- optimale
- Keuze
- or
- orkestratie
- Overige
- onze
- resultaten
- uitgangen
- buiten
- over
- overzicht
- Paketten
- Parallel
- passes
- Wachtwoord
- patronen
- voor
- toestemming
- stukken
- pijpleiding
- geplaatst
- platform
- platforms
- Plato
- Plato gegevensintelligentie
- PlatoData
- Spelen
- spelen
- Post
- voorbereiding
- bereid
- voorbereiding
- vereisten
- primair
- principes
- privaat
- verwerking
- professioneel
- Profiel
- Profielen
- Programming
- programmeertalen
- project
- projecten
- zorgen voor
- biedt
- Duwen
- geduwd
- Python
- queries
- verwijzen
- referentie
- register
- bewaarplaats
- vereisen
- nodig
- Voorwaarden
- vereist
- Resources
- REST
- Resultaten
- herbruikbare
- Rol
- wortel
- RIJ
- lopen
- lopend
- gered
- schaalbare
- rooster
- script
- seconden
- geheimen
- sectie
- veiligheid
- zien
- zaad
- zaden
- senior
- Volgorde
- service
- Diensten
- reeks
- het instellen van
- moet
- getoond
- Shows
- Eenvoudig
- Langzaam
- Momentopname
- So
- Software
- software engineering
- oplossing
- Oplossingen
- bron
- bronnen
- gespecialiseerde
- Uitgaven
- Sport
- SQL
- Statement
- verklaringen
- Stap voor
- Stappen
- shop
- opgeslagen
- subnetten
- volgend
- dergelijk
- zwemmen
- tafel
- TAG
- Nemen
- ingenomen
- doelwit
- Taak
- taken
- team
- vertellen
- sjabloon
- proef
- testen
- dat
- De
- hun
- Ze
- harte
- daarom
- Deze
- ze
- dit
- Door
- niet de tijd of
- tijdrovend
- keer
- naar
- teken
- traditioneel
- Transformeren
- Transformatie
- leiden
- veroorzaakt
- type dan:
- typisch
- Uk
- begrip
- .
- gebruikt
- Gebruiker
- toepassingen
- gebruik
- utilities
- via
- Bekijk
- Magazijn
- Warehousing
- Manier..
- we
- web
- webservices
- Website
- GOED
- wanneer
- welke
- en
- Wikipedia
- wil
- Met
- binnen
- Mijn werk
- workflow
- Bedrijven
- zou
- geschreven
- jaar
- u
- Your
- jezelf
- zephyrnet