Hoe vaak worden machine learning-projecten succesvol geïmplementeerd? Niet vaak genoeg. Er is overvloed of -industrie onderzoek tonen dat ML-projecten doorgaans geen rendement opleveren, maar slechts weinigen hebben de verhouding tussen mislukking en succes gemeten vanuit het perspectief van datawetenschappers – de mensen die precies de modellen ontwikkelen die deze projecten moeten inzetten.
In aansluiting op een onderzoek door datawetenschappers die ik vorig jaar met KDnuggets dirigeerde, de toonaangevende Data Science Survey van dit jaar gerund door ML-adviesbureau Rexer Analytics heeft de vraag beantwoord – deels omdat Karl Rexer, de oprichter en president van het bedrijf, ondergetekende toestond om deel te nemen, waardoor de opname van vragen over het succes van de implementatie werd gestimuleerd (een deel van mijn werk tijdens een eenjarig hoogleraarschap in analytics dat ik bekleedde bij UVA Darden).
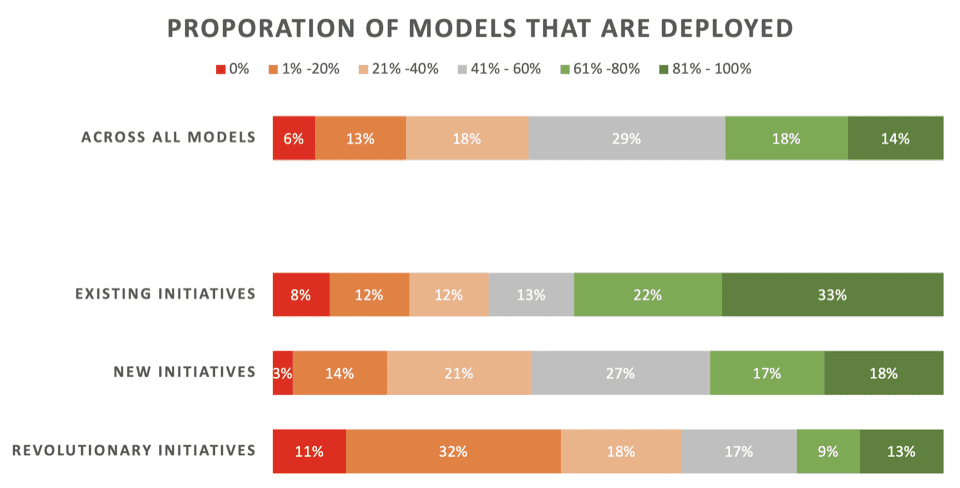
Het nieuws is niet geweldig. Slechts 22% van de datawetenschappers zegt dat hun ‘revolutionaire’ initiatieven – modellen die zijn ontwikkeld om een nieuw proces of nieuwe mogelijkheid mogelijk te maken – doorgaans worden ingezet. 43% zegt dat 80% of meer er niet in slaagt te implementeren.
Aan de overkant allen Bij dit soort ML-projecten – inclusief het vernieuwen van modellen voor bestaande implementaties – zegt slechts 32% dat hun modellen doorgaans worden ingezet.
Hier volgen de gedetailleerde resultaten van dat deel van het onderzoek, zoals gepresenteerd door Rexer Analytics, waarbij de inzetpercentages over drie soorten ML-initiatieven worden uitgesplitst:
Sleutel:
- Bestaande initiatieven: Modellen die zijn ontwikkeld om een bestaand model dat al met succes is geïmplementeerd, bij te werken/vernieuwen
- Nieuwe initiatieven: Modellen ontwikkeld om een bestaand proces te verbeteren waarvoor nog geen model werd ingezet
- Revolutionaire initiatieven: Modellen ontwikkeld om een nieuw proces of nieuwe mogelijkheid mogelijk te maken
Naar mijn mening komt deze strijd om deze in te zetten voort uit twee belangrijke factoren die hieraan bijdragen: een wijdverbreide onderplanning en zakelijke belanghebbenden die geen concrete zichtbaarheid hebben. Veel dataprofessionals en bedrijfsleiders zijn zich niet bewust geworden van het feit dat de beoogde operationalisering van ML vanaf het begin van elk ML-project tot in de kleinste details moet worden gepland en agressief moet worden nagestreefd.
Ik heb daar zelfs een nieuw boek over geschreven: Het AI-playbook: de zeldzame kunst van de implementatie van machinaal leren beheersen. In dit boek introduceer ik een op implementatie gerichte praktijk in zes stappen om machine learning-projecten van concept tot implementatie in te luiden. bizML (pre-order de hardcover of het e-book en ontvang een gratis geavanceerd exemplaar van de audioboekversie meteen).
De belangrijkste stakeholder van een ML-project – de persoon die verantwoordelijk is voor de operationele effectiviteit die moet worden verbeterd, zoals een line-of-business manager – heeft inzicht nodig in hoe ML precies hun activiteiten zal verbeteren en hoeveel waarde de verbetering naar verwachting zal opleveren. Ze hebben dit nodig om uiteindelijk groen licht te werpen op de implementatie van een model en om, daarvoor, invloed uit te oefenen op de uitvoering van het project gedurende de pre-implementatiefasen.
Maar de prestaties van ML worden vaak niet gemeten! Toen in het Rexer-onderzoek werd gevraagd: “Hoe vaak meet uw bedrijf/organisatie de prestaties van analytische projecten?” slechts 48% van de datawetenschappers zei ‘altijd’ of ‘meestal’. Dat is behoorlijk wild. Het zou eerder 99% of 100% moeten zijn.
En wanneer prestaties worden gemeten, gebeurt dat in termen van technische statistieken die geheimzinnig zijn en grotendeels irrelevant voor zakelijke belanghebbenden. Datawetenschappers weten wel beter, maar houden zich daar doorgaans niet aan – deels omdat ML-tools over het algemeen alleen maar technische statistieken opleveren. Volgens het onderzoek rangschikken datawetenschappers zakelijke KPI's zoals ROI en omzet als de belangrijkste statistieken, maar noemen ze technische statistieken zoals lift en AUC als de meest gemeten.
Technische prestatiestatistieken zijn “fundamenteel nutteloos voor en losgekoppeld van zakelijke belanghebbenden”, aldus Harvard Data Science-recensie. Dit is waarom: ze vertellen je alleen de relatief prestaties van een model, zoals hoe het zich verhoudt tot raden of een andere basislijn. Bedrijfsstatistieken vertellen u de absoluut bedrijfswaarde die het model naar verwachting zal opleveren – of, bij evaluatie na de implementatie, dat het heeft bewezen te leveren. Dergelijke statistieken zijn essentieel voor implementatiegerichte ML-projecten.
Naast de toegang tot bedrijfsstatistieken moeten zakelijke belanghebbenden ook hun inspanningen vergroten. Toen het Rexer-onderzoek vroeg: “Zijn de managers en besluitvormers in uw organisatie die de implementatie van modellen moeten goedkeuren, over het algemeen voldoende geïnformeerd om dergelijke beslissingen op een goed geïnformeerde manier te nemen?” slechts 49% van de respondenten antwoordde ‘Meestal’ of ‘Altijd’.
Dit is wat er volgens mij gebeurt. De ‘klant’ van de datawetenschapper, de zakelijke stakeholder, krijgt vaak koude voeten als het gaat om het autoriseren van de implementatie, omdat dit zou betekenen dat er een aanzienlijke operationele verandering moet worden doorgevoerd in de basis van het bedrijf, de grootste processen van het bedrijf. Ze beschikken niet over het contextuele raamwerk. Ze vragen zich bijvoorbeeld af: “Hoe moet ik begrijpen in hoeverre dit model, dat verre van kristalheldere perfectie presteert, daadwerkelijk zal helpen?” Zo sterft het project. Vervolgens kun je op een creatieve manier een positieve draai geven aan de ‘opgedane inzichten’ om de mislukking netjes onder het tapijt te vegen. De AI-hype blijft intact, ook al gaat de potentiële waarde, het doel van het project, verloren.
Over dit onderwerp – het betrekken van belanghebbenden – zal ik mijn nieuwe boek pluggen, Het AI-speelboek, nog een keer. Het boek behandelt niet alleen de bizML-praktijk, maar verbetert ook de vaardigheden van zakelijke professionals door een essentiële maar vriendelijke dosis semi-technische achtergrondkennis te bieden die alle belanghebbenden nodig hebben om machine learning-projecten van begin tot eind te leiden of eraan deel te nemen. Hierdoor komen business- en dataprofessionals op één lijn, zodat ze diepgaand kunnen samenwerken en gezamenlijk nauwkeurig tot stand kunnen komen wat machine learning moet voorspellen, hoe goed het voorspelt en hoe er op zijn voorspellingen wordt gereageerd om de bedrijfsvoering te verbeteren. Deze essentiële zaken maken of breken elk initiatief. Als u ze op de juiste manier aanpakt, wordt de weg vrijgemaakt voor de waardegedreven implementatie van machine learning.
Het is veilig om te zeggen dat het daar moeilijk is, vooral voor nieuwe ML-initiatieven die voor het eerst worden geprobeerd. Terwijl de pure kracht van de AI-hype zijn vermogen verliest om voortdurend goed te maken
minder gerealiseerde waarde dan beloofd, zal er steeds meer druk komen om de operationele waarde van ML te bewijzen. Dus ik zeg: loop hier nu voorop en begin met het creëren van een effectievere cultuur van samenwerking tussen ondernemingen en implementatiegericht projectleiderschap!
Voor meer gedetailleerde resultaten van de Rexer Analytics Data Science-enquête uit 2023, Klik hier. Dit is het grootste onderzoek onder professionals op het gebied van datawetenschap en analyse in de sector. Het bestaat uit ongeveer 35 meerkeuzevragen en open vragen die veel meer bestrijken dan alleen de succespercentages van implementaties – zeven algemene gebieden van de wetenschap en praktijk van datamining: (1) Veld en doelen, (2) Algoritmen, (3) Modellen, ( 4) Tools (gebruikte softwarepakketten), (5) Technologie, (6) Uitdagingen en (7) Toekomst. Het wordt uitgevoerd als een service (zonder bedrijfssponsoring) voor de datawetenschapsgemeenschap, en de resultaten worden meestal bekendgemaakt op de Machine Learning Week-conferentie en gedeeld via gratis beschikbare samenvattende rapporten.
Dit artikel is het resultaat van het werk van de auteur terwijl hij een jaar lang de functie bekleedde van Bodily Bicentennial Professor in Analytics aan de UVA Darden School of Business, wat uiteindelijk culmineerde in de publicatie van Het AI-playbook: de zeldzame kunst van de implementatie van machinaal leren beheersen (gratis luisterboekaanbieding).
Erik Siegel, Ph.D., is een vooraanstaand consultant en voormalig professor aan de Columbia University die machine learning begrijpelijk en boeiend maakt. Hij is de oprichter van de Predictive Analytics Wereld en Diepe leerwereld conferentieserie, die sinds 17,000 meer dan 2009 deelnemers heeft bediend, de instructeur van de veelgeprezen cursus Leiderschap en praktijk op het gebied van machine learning - end-to-end beheersing, een populaire spreker waarvoor een opdracht is gegeven 100+ keynote-adressen, en hoofdredacteur van De Machine Learning Times. Hij schreef de bestseller Voorspellende analyses: de kracht om te voorspellen wie zal klikken, kopen, liegen of sterven, dat is gebruikt in cursussen aan meer dan 35 universiteiten, en hij won onderwijsprijzen toen hij professor was aan Columbia University, waar hij zong leerzame liedjes aan zijn studenten. Eric publiceert ook opiniestukken over analyse en sociale rechtvaardigheid. Volg hem op @predictanalytisch.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/survey-machine-learning-projects-still-routinely-fail-to-deploy?utm_source=rss&utm_medium=rss&utm_campaign=survey-machine-learning-projects-still-routinely-fail-to-deploy
- : heeft
- :is
- :niet
- :waar
- $UP
- 000
- 1
- 17
- 35%
- 7
- a
- vermogen
- Over
- toegang
- geprezen
- Volgens
- over
- werkelijk
- aangesproken
- vergevorderd
- Na
- agressief
- vooruit
- AI
- algoritmen
- Alles
- toegestaan
- al
- ook
- altijd
- am
- an
- analytisch
- analytics
- en
- aangekondigd
- Nog een
- goedkeuren
- ongeveer
- geheim
- ZIJN
- gebieden
- Kunst
- dit artikel
- AS
- At
- attendees
- geen
- Geschreven
- Beschikbaar
- awards
- weg
- achtergrond
- Baseline
- BE
- omdat
- geweest
- vaardigheden
- geloofd wie en wat je bent
- best verkopende
- Betere
- boek
- Brood
- Breken
- Breaking
- bedrijfsdeskundigen
- Zakelijke leiders
- maar
- kopen
- by
- Bellen
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- CAN
- bekwaamheid
- boeiende
- uitdagingen
- verandering
- lading
- keuze
- Klik
- klant
- koud
- samenwerken
- samenwerking
- Columbia
- COM
- hoe
- komt
- algemeen
- gemeenschap
- afstand
- Bedrijf
- opvatting
- beton
- uitgevoerd
- Conferentie
- bestaat uit
- consultancy
- consultant
- contextual
- permanent
- bij te dragen
- Bedrijfs-
- cursus
- cursussen
- deksel
- aan het bedekken
- creatief
- cs
- Culture
- gegevens
- datamining
- data science
- data scientist
- besluitvormers
- beslissingen
- diep
- leveren
- het leveren van
- implementeren
- ingezet
- inzet
- implementaties
- detail
- gedetailleerd
- ontwikkelen
- ontwikkelde
- losgekoppeld
- do
- doet
- don
- Dont
- dosis
- beneden
- aandrijving
- gedurende
- elk
- editor
- effectief
- effectiviteit
- in staat stellen
- einde
- eind tot eind
- endemisch
- verhogen
- genoeg
- eric
- vooral
- essentieel
- essentials
- oprichting
- Ether (ETH)
- evalueren
- Zelfs
- Alle
- voorbeeld
- uitvoering
- uitvoerend
- bestaand
- verwacht
- feit
- factoren
- FAIL
- Storing
- ver
- Voeten
- weinig
- veld-
- volgen
- Voor
- Dwingen
- Voormalig
- oprichter
- Achtergrond
- Gratis
- vrij
- vriendelijk
- oppompen van
- toekomst
- opgedaan
- Algemeen
- algemeen
- krijgen
- het krijgen van
- Doelen
- Kopen Google Reviews
- groot
- Happening
- Hebben
- he
- Held
- hulp
- hem
- zijn
- Hoe
- HTML
- http
- HTTPS
- Hype
- i
- IBM
- belangrijk
- verbeteren
- verbetering
- in
- begin
- Inclusief
- inclusie
- -industrie
- toonaangevende
- initiatief
- initiatieven
- inzichten
- bestemde
- in
- voorstellen
- isn
- IT
- HAAR
- voor slechts
- eentje maar
- karl
- KDnuggets
- sleutel
- Grondtoon
- Soort
- blijven
- kennis
- ontbreekt
- grootste
- Achternaam*
- Afgelopen jaar
- leiden
- leiders
- Leadership
- leidend
- leren
- Leugen
- als
- Lijst
- ll
- Verliest
- verloren
- machine
- machine learning
- Hoofd
- maken
- MERKEN
- maken
- manager
- Managers
- manier
- veel
- het beheersen van
- gemiddelde
- betekende
- maatregel
- afgemeten
- Metriek
- Mijnbouw
- MIT
- ML
- model
- modellen
- meer
- meest
- meestal
- veel
- meervoudig
- Dan moet je
- my
- Noodzaak
- behoeften
- New
- nieuws
- geen
- nu
- of
- vaak
- on
- EEN
- degenen
- Slechts
- operationele
- Operations
- or
- bestellen
- organisatie
- uit
- Paketten
- pagina
- deel
- deelnemen
- wrakken
- perfectie
- prestatie
- presteert
- persoon
- perspectief
- gepland
- Plato
- Plato gegevensintelligentie
- PlatoData
- stekker
- Populair
- positie
- positief
- potentieel
- energie
- praktijk
- pre-order
- Kostbaar
- Precies
- voorspellen
- Voorspellingen
- voorspelt
- gepresenteerd
- president
- druk
- mooi
- processen
- Product
- professionals
- Hoogleraar
- project
- projecten
- beloofde
- Bewijzen
- bewezen
- Publicatie
- publiceert
- doel
- puts
- Putting
- vraag
- Contact
- Ramp
- rampen
- rangschikken
- BIJZONDER
- Tarieven
- verhouding
- bereiken
- realiseerde
- herkennen
- stoffelijk overschot
- Rapporten
- respondenten
- Resultaten
- Retourneren
- inkomsten
- revolutionair
- rechts
- rotsachtig
- ROI
- routinematig
- lopen
- s
- veilig
- Zei
- dezelfde
- ervaren
- Scale
- School
- Wetenschap
- Wetenschapper
- wetenschappers
- -Series
- dienen
- geserveerd
- bedient
- service
- zeven
- gedeeld
- aanzienlijke
- sinds
- So
- Social
- Software
- sommige
- Spreker
- spinnen
- sponsoring
- stadia
- stakeholders
- stakeholders
- begin
- stengels
- Still
- Leerlingen
- succes
- geslaagd
- Met goed gevolg
- dergelijk
- OVERZICHT
- Enquête
- Vegen
- T
- doelgerichte
- Onderwijs
- Technisch
- Technologie
- vertellen
- termen
- neem contact
- dat
- De
- hun
- Ze
- harte
- Er.
- Deze
- ze
- dit
- drie
- overal
- Dus
- niet de tijd of
- naar
- tools
- onderwerp
- echt
- twee
- Tenslotte
- voor
- begrijpen
- begrijpelijk
- Universiteiten
- universiteit-
- op
- gebruikt
- inluiden
- doorgaans
- waarde
- Ve
- zeer
- via
- Bekijk
- zichtbaarheid
- vitaal
- was
- Manier..
- week
- wegen
- GOED
- Wat
- wanneer
- welke
- en
- WIE
- Waarom
- Wild
- wil
- Met
- zonder
- Won
- wonder
- Mijn werk
- zou
- geschreven
- jaar
- nog
- u
- Your
- zephyrnet