We realiseerden ons onlangs dat we u al een tijdje geen data science-spiekbriefjes hadden gegeven. En het is niet vanwege hun gebrek aan beschikbaarheid; cheatsheets voor datawetenschap zijn overal, variërend van de inleidende tot de geavanceerde, en behandelen onderwerpen van algoritmen tot statistieken, tot interviewtips en meer.
Maar wat is een goede cheatsheet? Wat maakt een cheatsheet het waard om als bijzonder goed te worden aangemerkt? Het is moeilijk om de vinger er op te leggen Precies wat een goede cheatsheet is, maar uiteraard een die essentiële informatie beknopt weergeeft – of die informatie nu van specifieke of algemene aard is – is zeker een goed begin. En dat is wat onze kandidaten vandaag de dag opmerkelijk maakt. Lees dus verder voor vier samengestelde aanvullende cheatsheets om u te helpen bij het leren of beoordelen van datawetenschap.
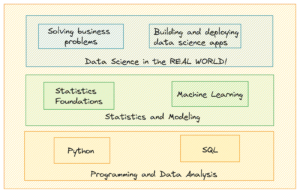
Maar eerst is er Data Science Cheatsheet 2.0 van Aaron Wang, een compilatie van vier pagina's met statistische abstracties, fundamentele machine learning-algoritmen en diepgaande leeronderwerpen en -concepten. Het is niet bedoeld om uitputtend te zijn, maar is in plaats daarvan bedoeld als een snelle referentie voor situaties zoals de voorbereiding van sollicitatiegesprekken en examenbeoordelingen, en al het andere dat een vergelijkbaar niveau van beoordelingsdiepte vereist. De auteur merkt op dat hoewel degenen met een basiskennis van statistiek en lineaire algebra deze hulpbron het meeste voordeel zullen ondervinden, beginners ook nuttige informatie uit de inhoud ervan zouden moeten kunnen halen.

Screenshot van Aaron Wang Cheatsheet voor gegevenswetenschap 2.0
Ons volgende spiekbriefje van vandaag is datgene waarop de bron van Aaron Wang is gebaseerd: Maverick Lin's Cheatsheet voor datawetenschap (Wangs verwijzing naar de zijne als 2.0 is een directe knipoog naar Lin's 'origineel'). We kunnen de cheatsheet van Lin beschouwen als diepgaander dan die van Wang (hoewel Wang's beslissing om zijn minder diepgaand te maken opzettelijk en een nuttig alternatief lijkt), die meer fundamentele datawetenschapsconcepten omvat, zoals het opschonen van gegevens, het idee van modellering, het doen van " big data” met Hadoop, SQL en zelfs de basisprincipes van Python.
Dit zal duidelijk degenen aanspreken die zich meer in het ‘beginnerskamp’ bevinden, en het doet goed werk om de eetlust op te wekken en lezers bewust te maken van het brede veld van datawetenschap, en veel van de verschillende concepten die het omvat. Dit is absoluut weer een solide bron, vooral als de lezer nieuwkomer is in datawetenschap.

Screenshot van Maverick Lin's Cheatsheet voor gegevenswetenschap
Terwijl we verder teruggaan in de tijd – op zoek naar de inspiratie voor Lin’s cheatsheet – komen we dit tegen William Chen's kanscheatsheet 2.0. Chen's cheatsheet heeft door de jaren heen veel aandacht en lof gekregen, en dus ben je het misschien wel eens tegengekomen. Het is duidelijk dat met een andere focus (gezien de naam), Chen's cheatsheet een spoedcursus is over, of diepgaande evaluatie van, waarschijnlijkheidsconcepten, waaronder een verscheidenheid aan verdelingen, covariantie en transformaties, voorwaardelijke verwachting, Markov-ketens, verschillende belangrijke formules, en veel meer.
Op 10 pagina's zou u zich de breedte van de waarschijnlijkheidsonderwerpen moeten kunnen voorstellen die hierin worden behandeld. Maar laat dat je niet afschrikken; Chens vermogen om concepten terug te brengen tot de essentiële punten en deze in gewoon Engels uit te leggen, zonder concessies te doen aan de essentie, is opmerkelijk. Het is ook rijk aan verklarende visualisaties, iets wat heel handig is als de ruimte beperkt is en de wens om beknopt te zijn sterk is.
Niet alleen is Chen's compilatie van hoge kwaliteit en je tijd waard, als beginner of iemand die geïnteresseerd is in een volledige recensie, zou ik in omgekeerde volgorde werken als hoe deze bronnen werden gepresenteerd - van Chen's cheatsheet, tot die van Lin, en uiteindelijk tot die van Wang. gaandeweg voortbouwend op concepten.
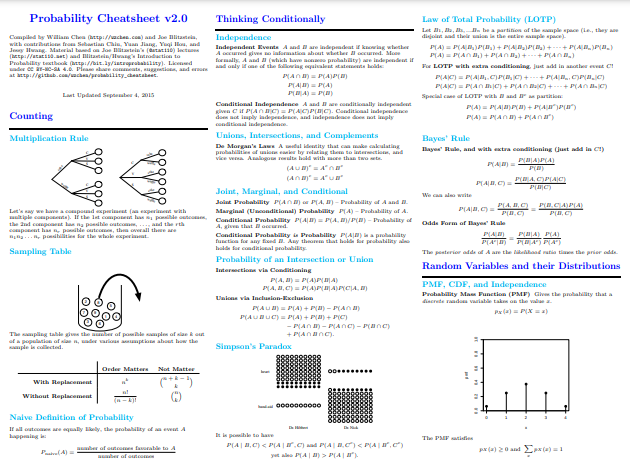
Screenshot van William Chen Cheatsheet voor waarschijnlijkheid 2.0
Een laatste bron die ik hier opneem, hoewel technisch gezien geen spiekbriefje, is Machine learning-bites van Rishabh Anand. Anand heeft zichzelf bestempeld als ‘een interviewgids over algemene Machine Learning-concepten, best practices, definities en theorie’ en heeft een brede verzameling kennisbites samengesteld, waarvan de bruikbaarheid beslist de oorspronkelijk beoogde interviewvoorbereiding overstijgt. Onderwerpen die daarin aan bod komen zijn onder meer:
- Modelscorestatistieken
- Parameter delen
- k-voudige kruisvalidatie
- Python-gegevenstypen
- Modelprestaties verbeteren
- Computer Vision-modellen
- Aandacht en zijn varianten
- Omgaan met klassenonevenwicht
- Woordenlijst voor computervisie
- Vanille-backpropagatie
- Regularisatie
- Referenties

Schermafbeelding van Machine Learning-bites
Hoewel de “concepten, best practices, definities en theorie” van machine learning worden aangestipt, zoals beloofd in de beschrijving van de bron zelf, zijn deze “bites” zeker gericht op de praktijk, waardoor de site complementair is aan veel van het materiaal dat wordt behandeld in de drie eerder genoemde cheatsheets. Als ik al het materiaal in alle vier de bronnen in dit bericht zou willen behandelen, zou ik hier zeker naar kijken na de andere drie.
Dus daar heb je vier spiekbriefjes (of drie spiekbriefjes en één aan de spiekbriefjes grenzende bron) die je kunt gebruiken voor je leer- of beoordelingswerk. Hopelijk is hier iets nuttigs voor je, en ik nodig iedereen uit om de cheatsheets die zij nuttig hebben gevonden te delen in de reacties hieronder.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2021/03/more-data-science-cheatsheets.html?utm_source=rss&utm_medium=rss&utm_campaign=more-data-science-cheatsheets
- 10
- a
- Aaron
- vermogen
- in staat
- over
- vergevorderd
- Na
- algoritmen
- Alles
- alternatief
- en
- Nog een
- iedereen
- hoger beroep
- aandacht
- auteur
- beschikbaarheid
- terug
- gebaseerde
- basis-
- De Basis
- beginners
- wezen
- onder
- voordeel
- BEST
- 'best practices'
- Verder
- Groot
- Big data
- factuuradres
- breedte
- breed
- bracht
- Gebouw
- Kamp
- kandidaten
- zeker
- ketens
- chen
- klasse
- Schoonmaak
- duidelijk
- Collectie
- hoe
- opmerkingen
- Gemeen
- complementair
- concepten
- content
- cursus
- deksel
- bedekt
- aan het bedekken
- Neerstorten
- Cross
- curated
- gegevens
- data science
- beslissing
- deep
- diepe duik
- diepgaand leren
- definitief
- diepte
- beschrijving
- anders
- moeilijk
- directe
- Uitkeringen
- doen
- beneden
- omvat
- Engels
- vooral
- essentieel
- essentials
- Ether (ETH)
- Zelfs
- tentamen
- verwachting
- Verklaren
- veld-
- Figuur
- finale
- Tot slot
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- stevig
- Focus
- gevonden
- oppompen van
- vol
- fundamenteel
- verder
- afgestemd
- Algemeen
- gegeven
- Go
- goed
- goede baan
- gids
- hier
- Hopelijk
- Hoe
- HTTPS
- idee
- onbalans
- belang
- in
- diepgaande
- omvatten
- Inclusief
- informatie
- Inspiratie
- verkrijgen in plaats daarvan
- Opzettelijk
- geïnteresseerd
- Interview
- inleidende
- uitnodigt
- IT
- zelf
- Jobomschrijving:
- kennis
- Gebrek
- leren
- Niveau
- Beperkt
- Kijk
- op zoek
- machine
- machine learning
- maken
- MERKEN
- maken
- veel
- materiaal
- non-conformist
- vermeld
- Metriek
- model
- modellen
- meer
- meest
- beweging
- naam
- NATUUR
- volgende
- Opmerkingen
- opmerkelijk
- notie
- het aanbieden van
- EEN
- bestellen
- origineel
- oorspronkelijk
- Overige
- het te bezitten.
- vooral
- prestatie
- Eenvoudig
- Plato
- Plato gegevensintelligentie
- PlatoData
- punt
- punten
- Post
- PRAKTISCH
- praktijken
- gepresenteerd
- die eerder
- beloofde
- zetten
- Python
- kwaliteit
- Quick
- variërend
- Lees
- Lezer
- lezers
- realiseerde
- onlangs
- hulpbron
- Resources
- omkeren
- beoordelen
- Recensies
- Rijk
- concessies te doen
- Wetenschap
- scoren
- op zoek naar
- lijkt
- Delen
- delen
- moet
- gelijk
- website
- situaties
- So
- solide
- sommige
- Iemand
- iets
- Tussenruimte
- specifiek
- begin
- statistisch
- statistiek
- sterke
- dergelijk
- De
- The Basics
- hun
- drie
- niet de tijd of
- tips
- naar
- vandaag
- top
- onderwerpen
- in de richting van
- transformaties
- types
- begrip
- .
- bevestiging
- variëteit
- divers
- visie
- Wat
- of
- welke
- en
- WIE
- breed
- wil
- binnen
- Mijn werk
- zou
- jaar
- Your
- zephyrnet