Met de lancering van de neurale zoekfunctie voor Amazon OpenSearch-service in OpenSearch 2.9 is het nu moeiteloos te integreren met AI/ML-modellen om semantisch zoeken en andere gebruiksscenario's mogelijk te maken. OpenSearch Service ondersteunt zowel lexicale als vectorzoekopdrachten sinds de introductie van de functie k-nearest neighbour (k-NN) in 2020; Voor het configureren van semantisch zoeken was echter het bouwen van een raamwerk nodig om machine learning-modellen (ML) te integreren voor opname en zoeken. De neurale zoekfunctie vergemakkelijkt de transformatie van tekst naar vector tijdens opname en zoeken. Wanneer u tijdens het zoeken een neurale zoekopdracht gebruikt, wordt de zoekopdracht vertaald in een vectorinbedding en wordt k-NN gebruikt om de dichtstbijzijnde vectorinbedding uit het corpus te retourneren.
Als u neuraal zoeken wilt gebruiken, moet u een ML-model instellen. We raden u aan AI/ML-connectoren te configureren voor AWS AI- en ML-services (zoals Amazon Sage Maker or Amazonebodem) of alternatieven van derden. Vanaf versie 2.9 op OpenSearch Service integreren AI/ML-connectoren met neuraal zoeken om de vertaling van uw gegevenscorpus en zoekopdrachten naar vectorinbedding te vereenvoudigen en te operationaliseren, waardoor een groot deel van de complexiteit van vectorhydratatie en zoeken wordt weggenomen.
In dit bericht laten we zien hoe u AI/ML-connectors kunt configureren voor externe modellen via de OpenSearch Service-console.
Overzicht oplossingen
Dit bericht begeleidt u specifiek bij het verbinden met een model in SageMaker. Vervolgens begeleiden we u bij het gebruik van de connector om semantisch zoeken op OpenSearch Service te configureren als voorbeeld van een gebruiksscenario dat wordt ondersteund via verbinding met een ML-model. Amazon Bedrock- en SageMaker-integraties worden momenteel ondersteund op de OpenSearch Service-console-UI, en de lijst met door de UI ondersteunde integraties van eerste en derde partijen zal blijven groeien.
Voor modellen die niet via de gebruikersinterface worden ondersteund, kunt u deze in plaats daarvan instellen met behulp van de beschikbare API's en de ML-blauwdrukken. Voor meer informatie, zie: Inleiding tot OpenSearch-modellen. U kunt blauwdrukken voor elke connector vinden in de ML Commons GitHub-repository.
Voorwaarden
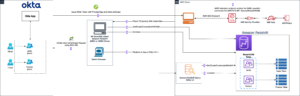
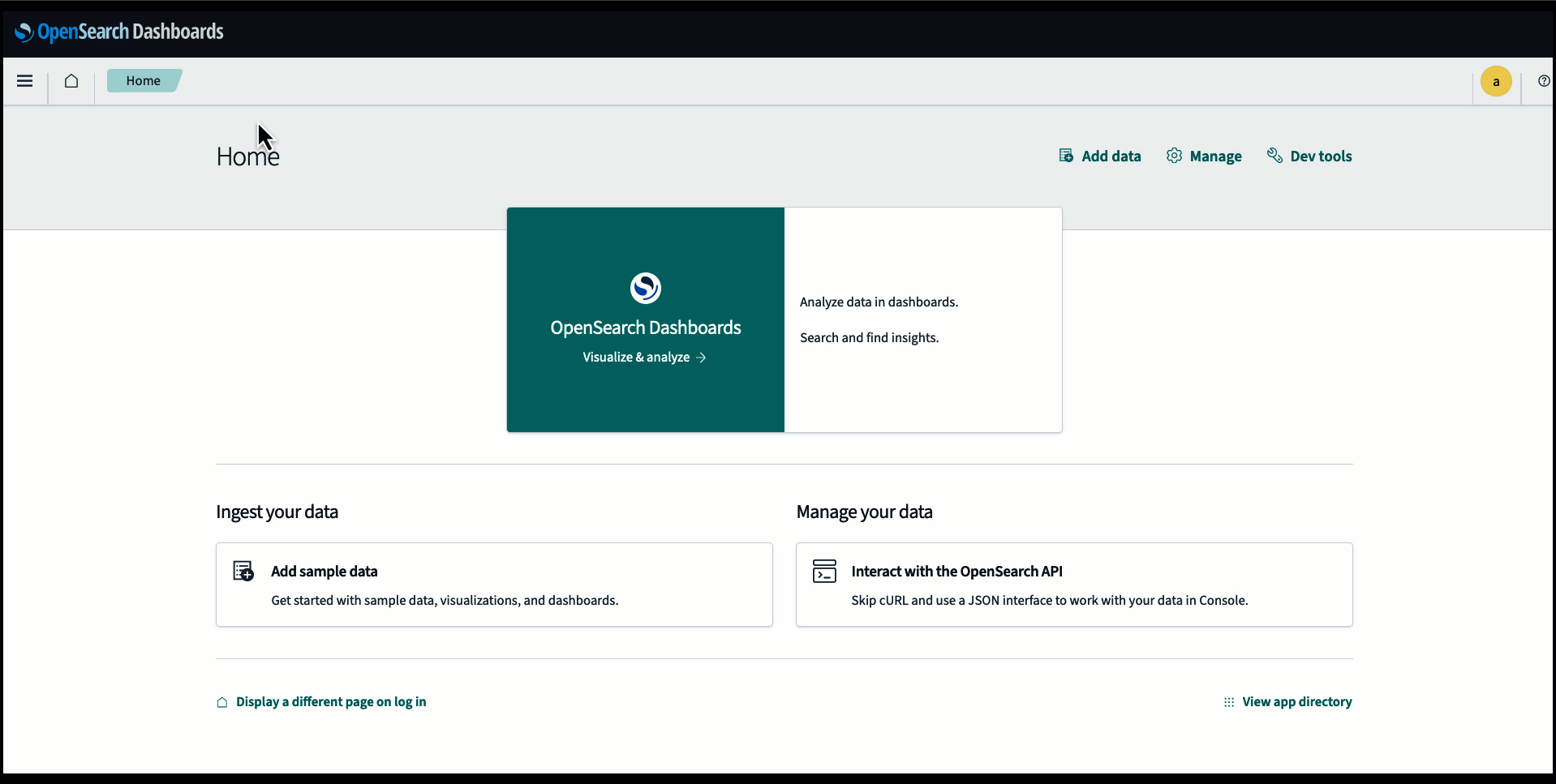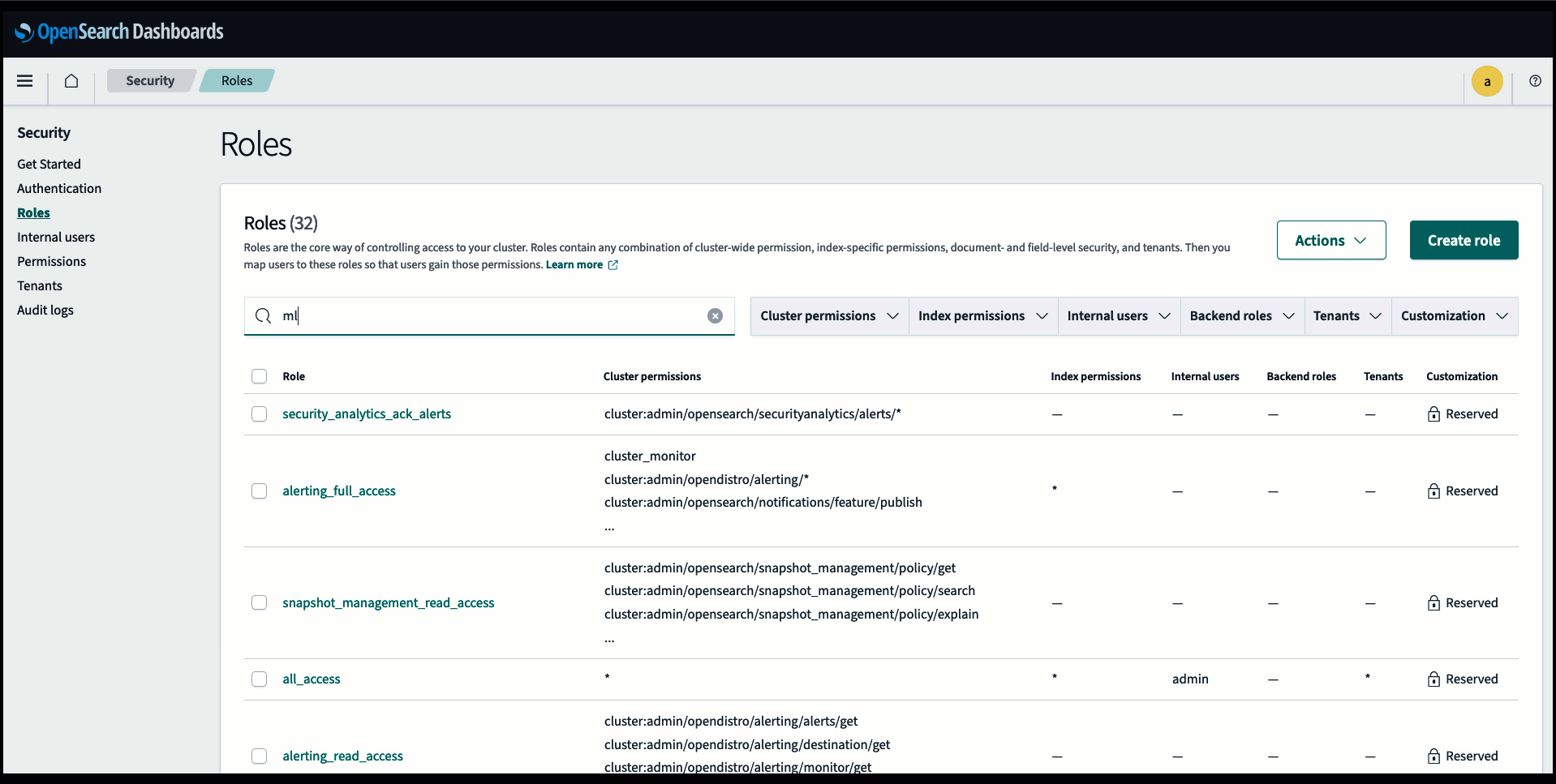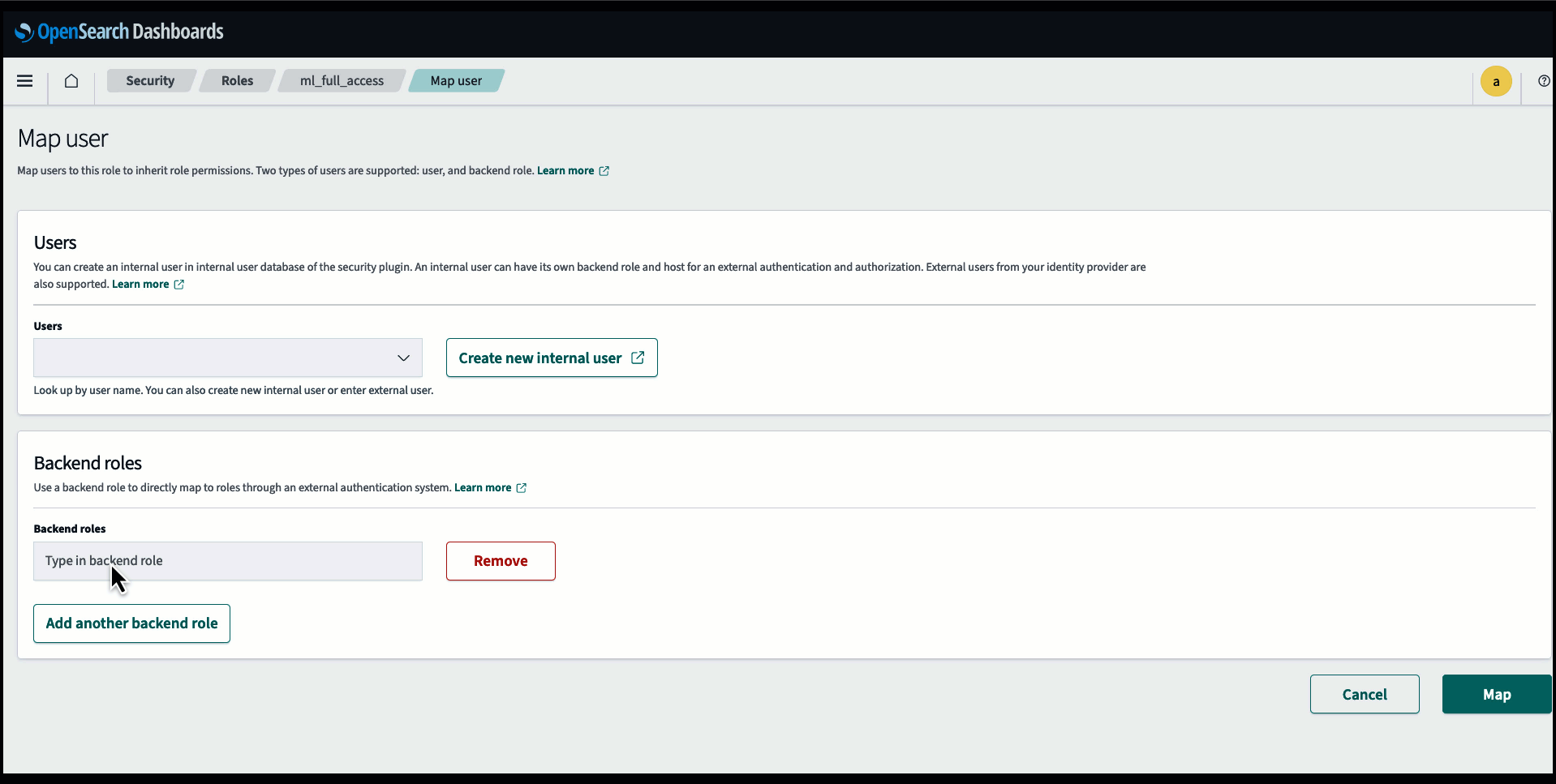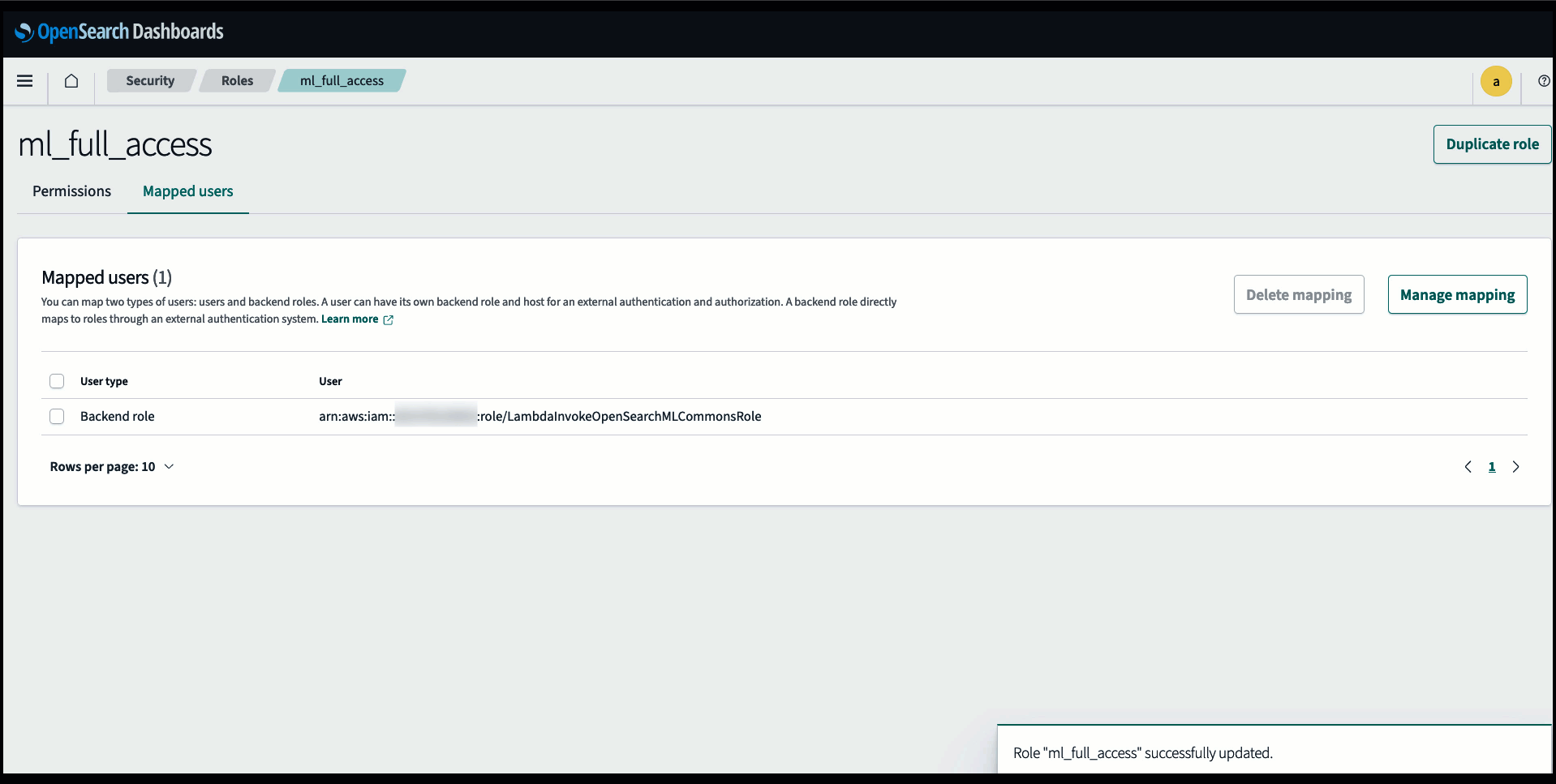
Voordat u het model aansluit via de OpenSearch Service-console, maakt u een OpenSearch Service-domein aan. Kaart een AWS Identiteits- en toegangsbeheer (IAM) rol met de naam LambdaInvokeOpenSearchMLCommonsRole als de backend-rol op de ml_full_access rol met behulp van de beveiligingsplug-in op OpenSearch Dashboards, zoals weergegeven in de volgende video. De workflow voor OpenSearch Service-integraties is vooraf ingevuld om de LambdaInvokeOpenSearchMLCommonsRole Standaard IAM-rol om de connector te maken tussen het OpenSearch Service-domein en het model dat op SageMaker is geïmplementeerd. Als u een aangepaste IAM-rol gebruikt in de OpenSearch Service-console-integraties, zorg er dan voor dat de aangepaste rol wordt toegewezen als de backend-rol met ml_full_access machtigingen voordat u de sjabloon implementeert.
Implementeer het model met AWS CloudFormation
De volgende video demonstreert de stappen om de OpenSearch Service-console te gebruiken om binnen enkele minuten een model op Amazon SageMaker te implementeren en de model-ID te genereren via de AI-connectoren. De eerste stap is kiezen Integraties in het navigatievenster op de OpenSearch Service AWS-console, dat naar een lijst met beschikbare integraties leidt. De integratie wordt opgezet via een gebruikersinterface, die u om de nodige invoer zal vragen.
Om de integratie in te stellen, hoeft u alleen het OpenSearch Service-domeineindpunt en een modelnaam op te geven om de modelverbinding uniek te identificeren. Standaard gebruikt de sjabloon het Hugging Face-zintransformatorenmodel, djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
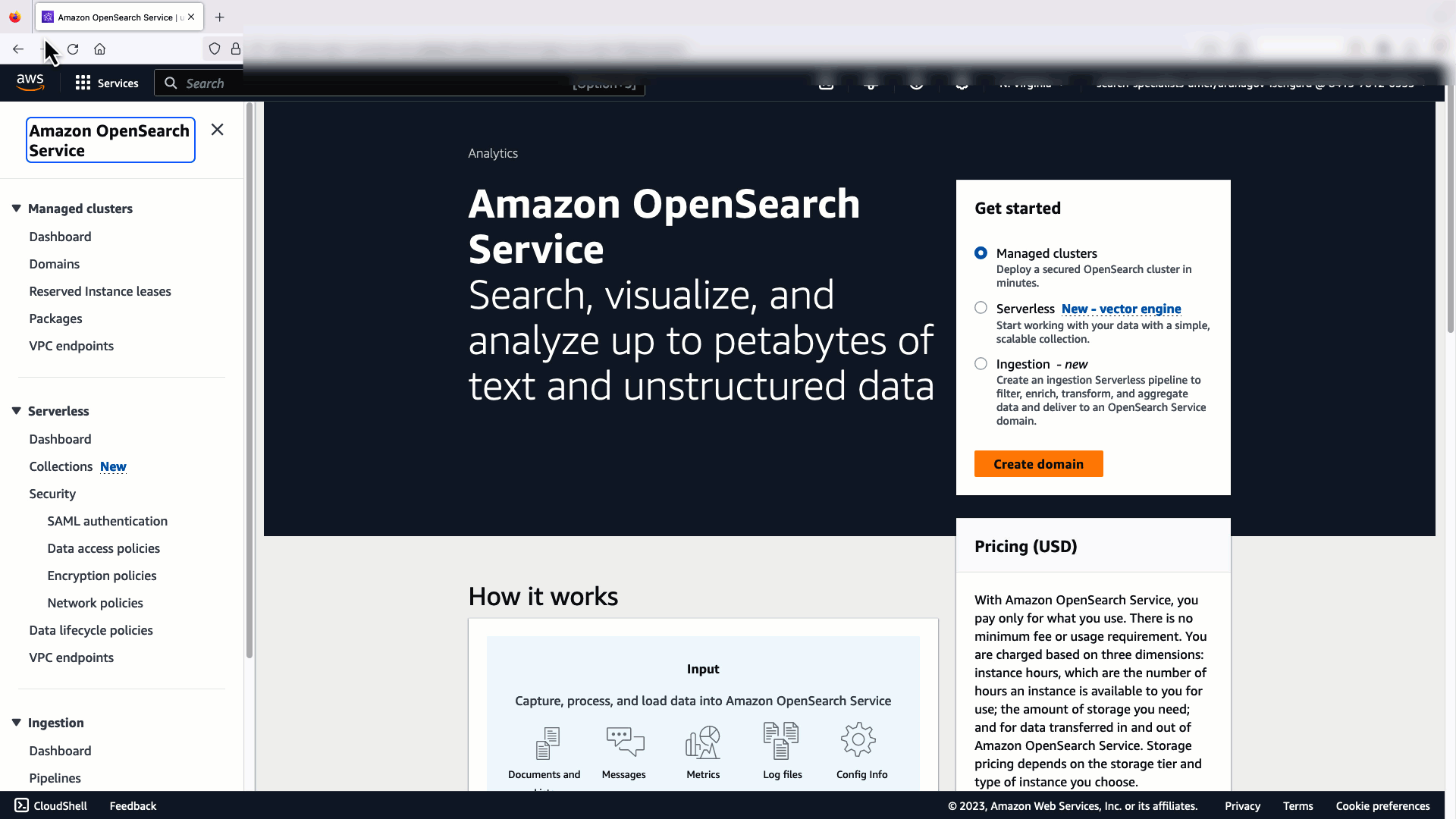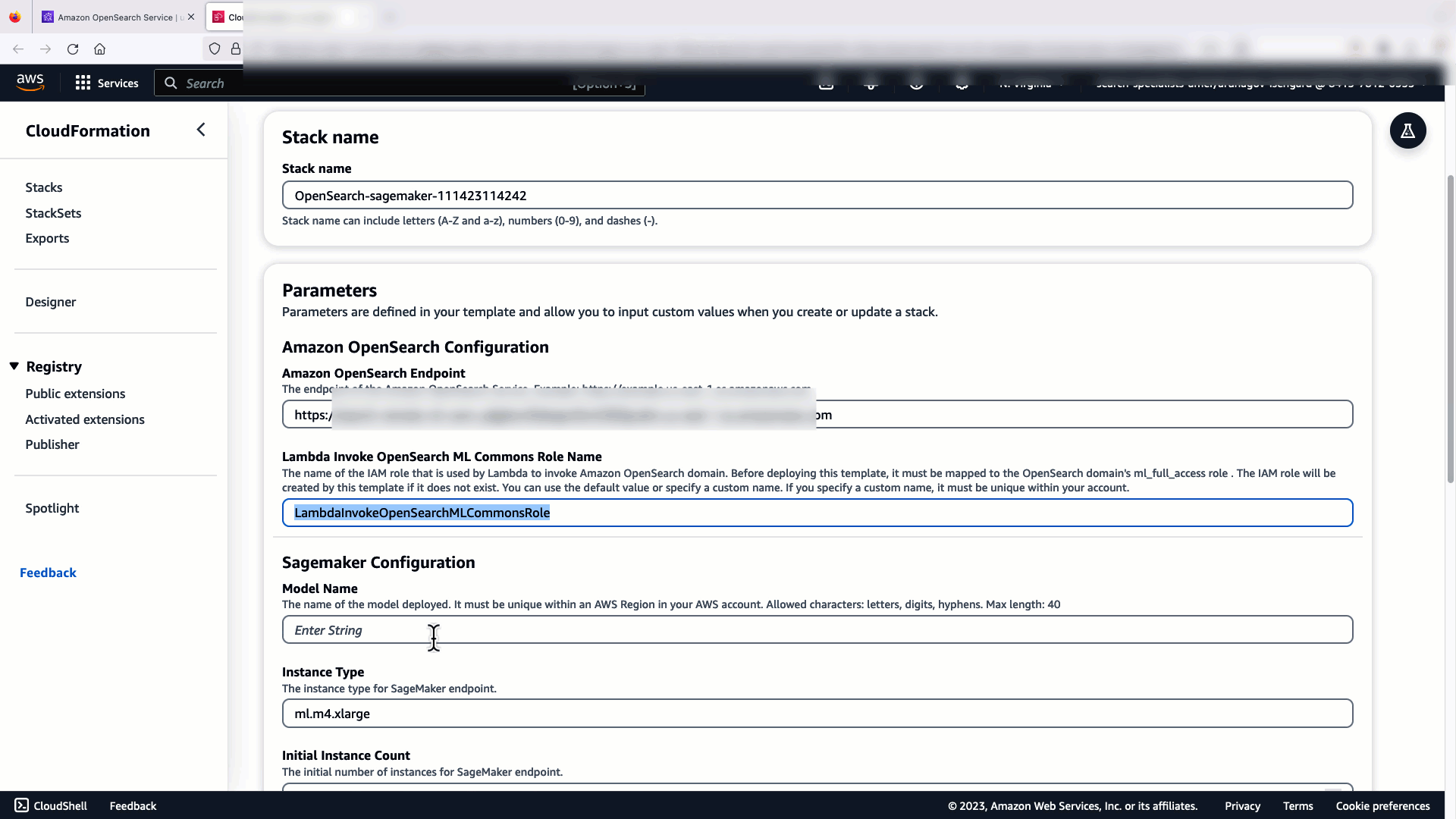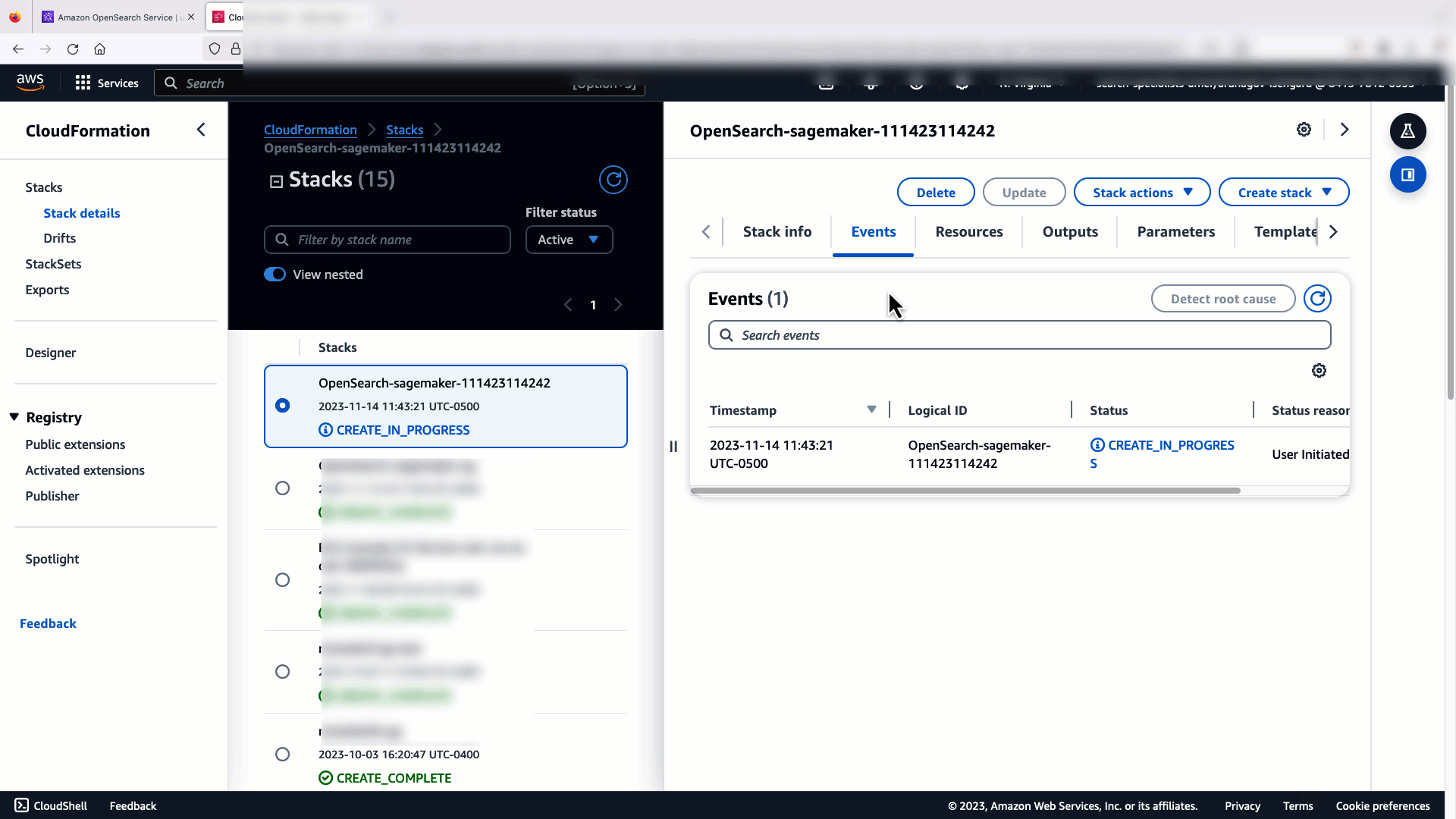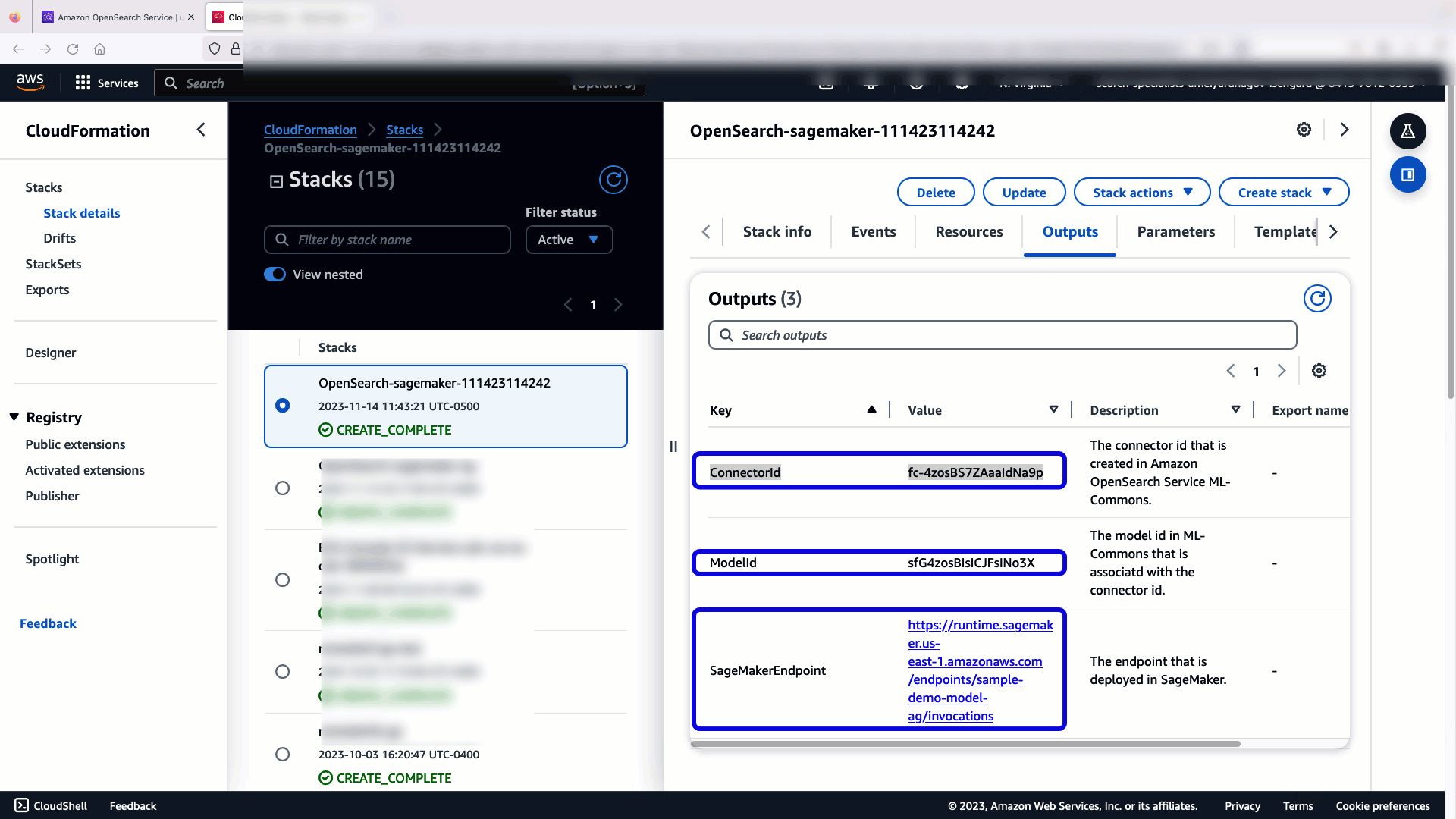
Wanneer je kiest Maak een stapel, u wordt doorgestuurd naar de AWS CloudFormatie troosten. De CloudFormation-sjabloon implementeert de architectuur die wordt beschreven in het volgende diagram.

De CloudFormation-stack creëert een AWS Lambda toepassing die een model implementeert Amazon eenvoudige opslagservice (Amazon S3), maakt de connector en genereert de model-ID in de uitvoer. U kunt deze model-ID vervolgens gebruiken om een semantische index te maken.
Als het standaard volledig MiniLM-L6-v2-model niet uw doel dient, kunt u elk tekstinsluitingsmodel van uw keuze implementeren op de gekozen modelhost (SageMaker of Amazon Bedrock) door uw modelartefacten aan te bieden als een toegankelijk S3-object. Als alternatief kunt u een van de volgende opties selecteren vooraf getrainde taalmodellen en implementeer het in SageMaker. Voor instructies voor het instellen van uw eindpunt en modellen raadpleegt u Beschikbare Amazon SageMaker-afbeeldingen.
SageMaker is een volledig beheerde service die een breed scala aan tools samenbrengt om hoogwaardige, goedkope ML voor elk gebruik mogelijk te maken, en belangrijke voordelen biedt zoals modelmonitoring, serverloze hosting en workflowautomatisering voor voortdurende training en implementatie. Met SageMaker kunt u de levenscyclus van modellen voor het insluiten van tekst hosten en beheren, en deze gebruiken om semantische zoekopdrachten in OpenSearch Service aan te sturen. Wanneer verbonden, host SageMaker uw modellen en wordt de OpenSearch Service gebruikt om zoekopdrachten uit te voeren op basis van de gevolgtrekkingsresultaten van SageMaker.
Bekijk het geïmplementeerde model via OpenSearch Dashboards
Om te verifiëren dat de CloudFormation-sjabloon het model met succes heeft geïmplementeerd op het OpenSearch Service-domein en de model-ID ophaalt, kunt u de ML Commons REST GET API gebruiken via OpenSearch Dashboards Dev Tools.
De GET _plugins REST API biedt nu extra API's om ook de modelstatus te bekijken. Met het volgende commando kunt u de status van een extern model bekijken:
Zoals weergegeven in de volgende schermafbeelding, a DEPLOYED De status in het antwoord geeft aan dat het model met succes is geïmplementeerd op het OpenSearch Service-cluster.

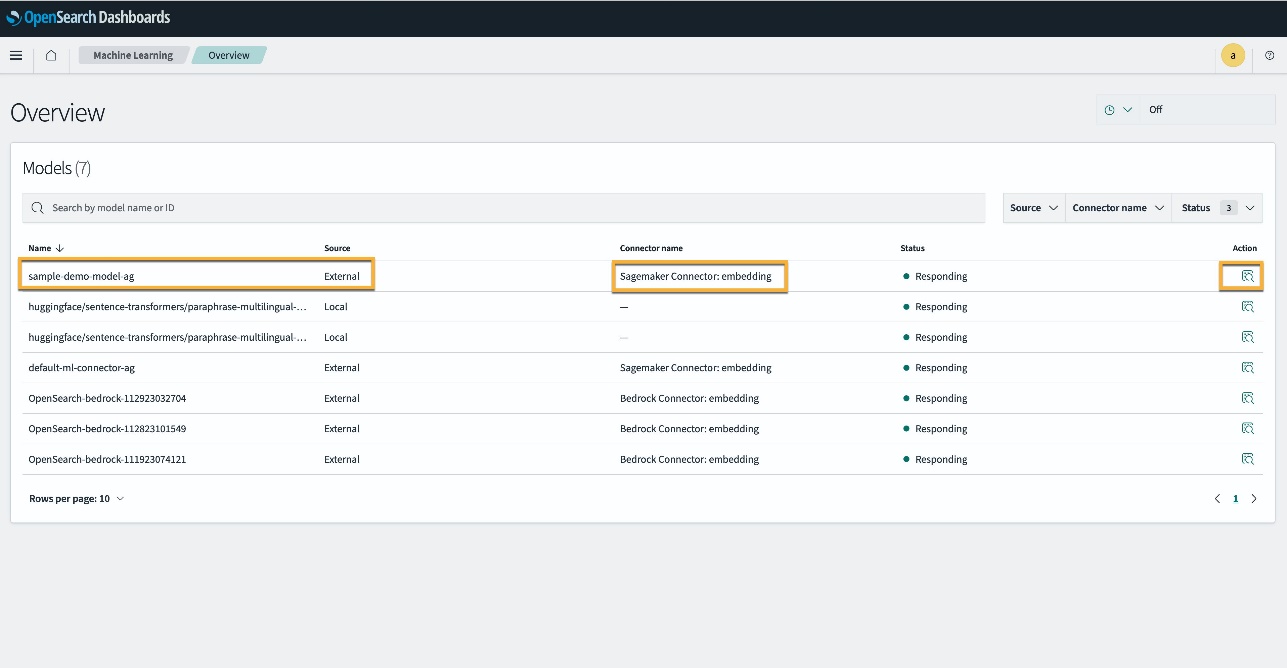
Als alternatief kunt u het model bekijken dat is geïmplementeerd op uw OpenSearch Service-domein met behulp van de Machine leren pagina van OpenSearch Dashboards.

Op deze pagina vindt u de modelinformatie en de statussen van alle geïmplementeerde modellen.

Maak de neurale pijplijn met behulp van de model-ID
Wanneer de status van het model als een van beide wordt weergegeven DEPLOYED in Dev Tools of groen en reageren in OpenSearch Dashboards kunt u de model-ID gebruiken om uw neurale opnamepijplijn op te bouwen. De volgende opnamepijplijn wordt uitgevoerd in de OpenSearch Dashboards Dev Tools van uw domein. Zorg ervoor dat u de model-ID vervangt door de unieke ID die is gegenereerd voor het model dat in uw domein is geïmplementeerd.

Maak de semantische zoekindex met behulp van de neurale pijplijn als de standaardpijplijn
U kunt nu uw indextoewijzing definiëren met de standaardpijplijn die is geconfigureerd om de nieuwe neurale pijplijn te gebruiken die u in de vorige stap hebt gemaakt. Zorg ervoor dat de vectorvelden zijn gedeclareerd als knn_vector en de afmetingen zijn geschikt voor het model dat op SageMaker wordt geïmplementeerd. Als u de standaardconfiguratie voor het implementeren van het volledig MiniLM-L6-v2-model op SageMaker hebt behouden, behoudt u de volgende instellingen zoals ze zijn en voert u de opdracht uit in Dev Tools.

Neem voorbeelddocumenten op om vectoren te genereren
Voor deze demo kunt u de voorbeeld van een demostore-productcatalogus voor de detailhandel naar het nieuwe semantic_demostore inhoudsopgave. Vervang de gebruikersnaam, het wachtwoord en het domeineindpunt door uw domeininformatie en neem onbewerkte gegevens op in de OpenSearch Service:

Valideer de nieuwe semantic_demostore-index
Nu u uw dataset hebt opgenomen in het OpenSearch Service-domein, valideert u of de vereiste vectoren zijn gegenereerd met behulp van een eenvoudige zoekopdracht om alle velden op te halen. Valideer of de velden zijn gedefinieerd als knn_vectors over de vereiste vectoren beschikken.

Vergelijk lexicale zoekopdrachten en semantische zoekopdrachten, mogelijk gemaakt door neuraal zoeken, met behulp van de tool Zoekresultaten vergelijken
De Hulpmiddel Zoekresultaten vergelijken op OpenSearch Dashboards is beschikbaar voor productieworkloads. U kunt navigeren naar de Vergelijk zoekresultaten pagina en vergelijk de zoekopdrachtresultaten tussen lexicale zoekopdrachten en neurale zoekopdrachten die zijn geconfigureerd om de eerder gegenereerde model-ID te gebruiken.

Opruimen
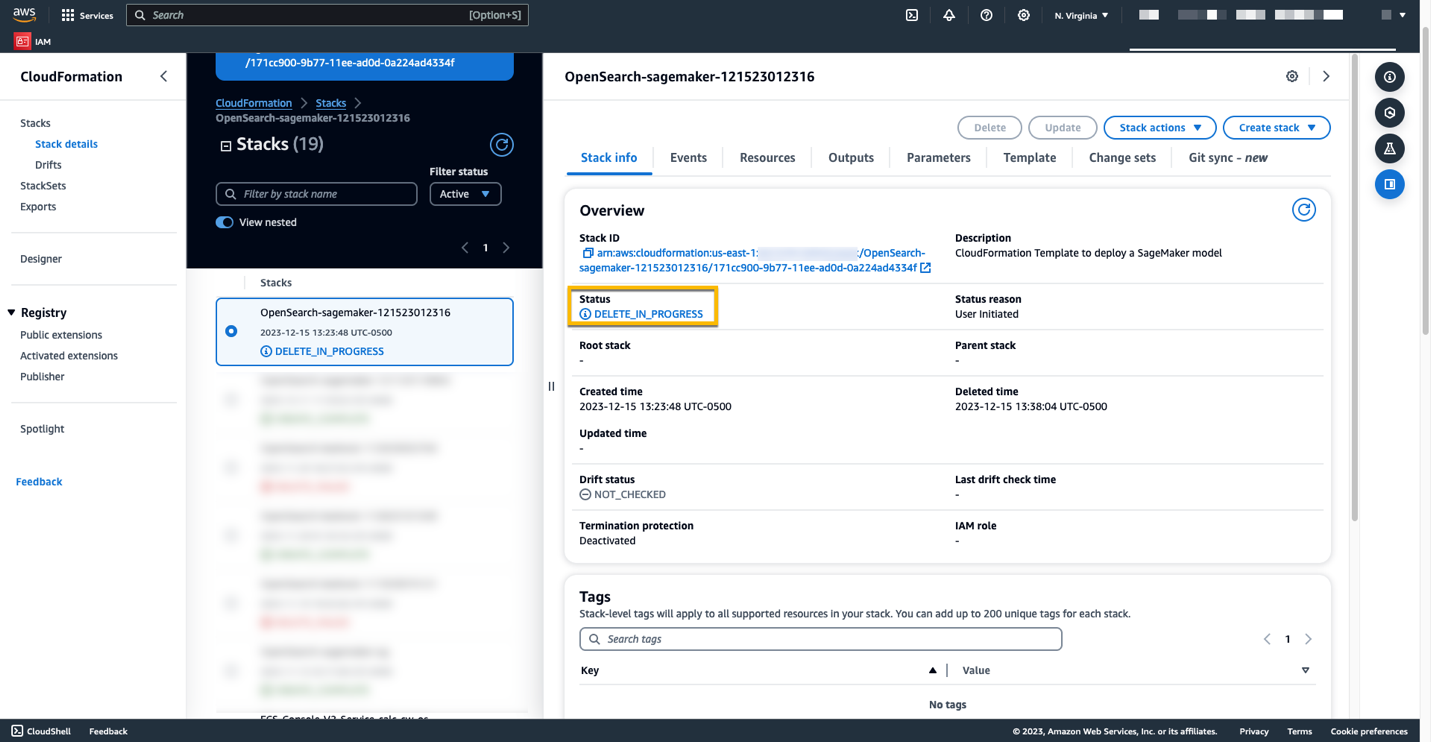
Je kunt de bronnen die je hebt gemaakt verwijderen door de instructies in dit bericht te volgen door de CloudFormation-stack te verwijderen. Hiermee worden de Lambda-bronnen en de S3-bucket verwijderd die het model bevatten dat in SageMaker is geïmplementeerd. Voer de volgende stappen uit:
- Navigeer op de AWS CloudFormation-console naar de pagina met uw stackdetails.
- Kies Verwijder.

- Kies Verwijder bevestigen.

U kunt de voortgang van het verwijderen van de stapel volgen op de AWS CloudFormation-console.
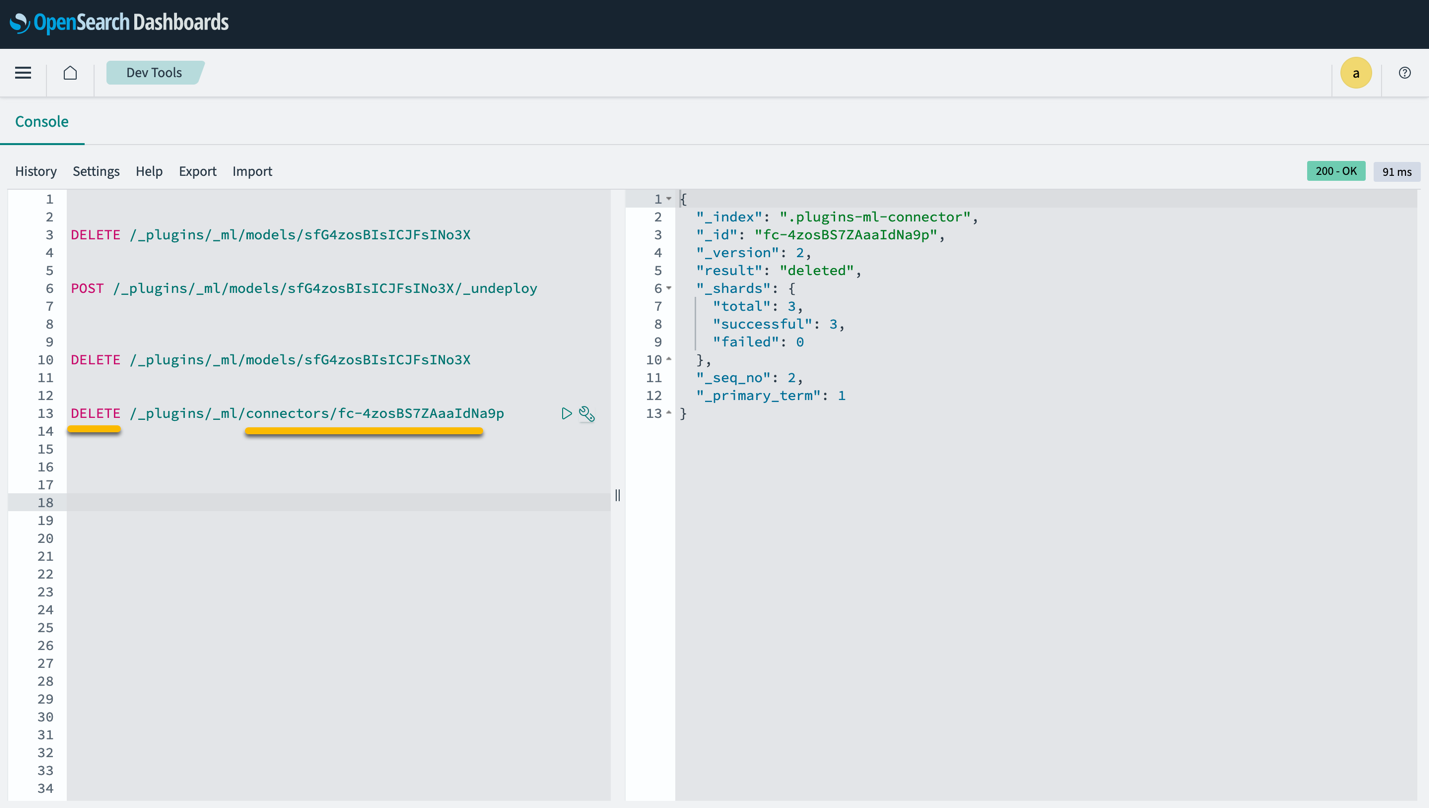
Houd er rekening mee dat het verwijderen van de CloudFormation-stack niet het model verwijdert dat is geïmplementeerd in het SageMaker-domein en de gemaakte AI/ML-connector. Dit komt omdat deze modellen en de connector aan meerdere indexen binnen het domein kunnen worden gekoppeld. Als u specifiek een model en de bijbehorende connector wilt verwijderen, gebruikt u de model-API's zoals weergegeven in de volgende schermafbeeldingen.
Eerste, undeploy het model uit het OpenSearch Service-domeingeheugen:

Vervolgens kunt u het model uit de modelindex verwijderen:

Verwijder ten slotte de connector uit de connectorindex:
Conclusie
In dit bericht heb je geleerd hoe je een model in SageMaker kunt implementeren, de AI/ML-connector kunt maken met behulp van de OpenSearch Service-console en de neurale zoekindex kunt bouwen. De mogelijkheid om AI/ML-connectoren in OpenSearch Service te configureren vereenvoudigt het vectorhydratatieproces door de integraties met externe modellen native te maken. U kunt binnen enkele minuten een neurale zoekindex maken met behulp van de neurale opnamepijplijn en de neurale zoekopdracht die de model-ID gebruiken om de vectorinsluiting direct te genereren tijdens opname en zoeken.
Voor meer informatie over deze AI/ML-connectoren raadpleegt u Amazon OpenSearch Service AI-connectoren voor AWS-services, AWS CloudFormation-sjabloonintegraties voor semantisch zoeken en Connectors maken voor ML-platforms van derden.
Over de auteurs
 Aruna Govindaraju is een Amazon OpenSearch Specialist Solutions Architect en heeft met veel commerciële en open source zoekmachines gewerkt. Ze heeft een passie voor zoeken, relevantie en gebruikerservaring. Haar expertise in het correleren van signalen van eindgebruikers met het gedrag van zoekmachines heeft veel klanten geholpen hun zoekervaring te verbeteren.
Aruna Govindaraju is een Amazon OpenSearch Specialist Solutions Architect en heeft met veel commerciële en open source zoekmachines gewerkt. Ze heeft een passie voor zoeken, relevantie en gebruikerservaring. Haar expertise in het correleren van signalen van eindgebruikers met het gedrag van zoekmachines heeft veel klanten geholpen hun zoekervaring te verbeteren.
 Dagney Braun is een Principal Product Manager bij AWS gericht op OpenSearch.
Dagney Braun is een Principal Product Manager bij AWS gericht op OpenSearch.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- : heeft
- :is
- :niet
- $UP
- 1
- 100
- 12
- 15%
- 2020
- 25
- 7
- 8
- 9
- a
- vermogen
- Over
- toegang
- beschikbaar
- Extra
- AI
- AI / ML
- Alles
- toestaat
- ook
- alternatieven
- Amazone
- Amazon Sage Maker
- Amazon Web Services
- an
- en
- elke
- api
- APIs
- Aanvraag
- passend
- architectuur
- ZIJN
- AS
- geassocieerd
- At
- Automatisering
- Beschikbaar
- AWS
- AWS CloudFormatie
- backend
- gebaseerde
- BE
- omdat
- gedrag
- betekent
- tussen
- zowel
- Brengt
- breed
- bouw
- Gebouw
- by
- CAN
- geval
- gevallen
- catalogus
- keuze
- Kies
- uitgekozen
- TROS
- commercieel
- Volk
- vergelijken
- compleet
- ingewikkeldheid
- Configuratie
- geconfigureerd
- configureren
- Bevestigen
- gekoppeld blijven
- Wij verbinden
- versterken
- troosten
- bevatten
- voortzetten
- doorlopend
- correleren
- en je merk te creëren
- aangemaakt
- creëert
- Op dit moment
- gewoonte
- Klanten
- dashboards
- gegevens
- Standaard
- bepalen
- gedefinieerd
- het leveren van
- Demo
- tonen
- demonstreert
- implementeren
- ingezet
- het inzetten
- inzet
- ontplooit
- beschrijving
- gedetailleerd
- gegevens
- Dev
- Afmeting
- Afmeting
- documenten
- Nee
- domein
- gedurende
- elk
- Vroeger
- zonder inspanning
- beide
- inbedding
- in staat stellen
- Endpoint
- Motor
- Motoren
- verzekeren
- Ether (ETH)
- voorbeeld
- ervaring
- expertise
- extern
- Gezicht
- vergemakkelijkt
- Kenmerk
- Velden
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Voornaam*
- gericht
- volgend
- Voor
- Achtergrond
- oppompen van
- geheel
- voortbrengen
- gegenereerde
- genereert
- krijgen
- gif
- GitHub
- Groen
- Groeien
- gids
- Hebben
- geholpen
- haar
- hoge performantie
- gastheer
- Hosting
- hosts
- Hoe
- How To
- Echter
- HTML
- http
- HTTPS
- KnuffelenGezicht
- hydratatie
- IAM
- ID
- identificeren
- Identiteit
- if
- verbeteren
- in
- index
- indexen
- geeft aan
- informatie
- ingangen
- verkrijgen in plaats daarvan
- instructies
- integreren
- integratie
- integraties
- in
- Introductie
- IT
- HAAR
- jpg
- json
- Houden
- sleutel
- taal
- lancering
- LEARN
- geleerd
- leren
- levenscyclus van uw product
- Lijst
- lijsten
- Low-cost
- machine
- machine learning
- maken
- maken
- beheer
- beheerd
- manager
- veel
- kaart
- in kaart brengen
- Geheugen
- methode
- minuten
- ML
- model
- modellen
- monitor
- Grensverkeer
- meer
- veel
- meervoudig
- Dan moet je
- naam
- inheemse
- OP DEZE WEBSITE VIND JE
- Navigatie
- noodzakelijk
- Noodzaak
- Neural
- New
- nu
- object
- of
- on
- EEN
- Slechts
- open
- open source
- or
- Overige
- uitgang
- pagina
- brood
- hartstochtelijk
- Wachtwoord
- permissies
- pijpleiding
- Plato
- Plato gegevensintelligentie
- PlatoData
- inpluggen
- Post
- energie
- aangedreven
- vorig
- Principal
- Voorafgaand
- processors
- Product
- product manager
- productie
- Voortgang
- vastgoed
- zorgen voor
- biedt
- het verstrekken van
- doel
- queries
- Rauw
- ruwe data
- adviseren
- verwijzen
- vanop
- het verwijderen van
- vervangen
- nodig
- Resources
- antwoord
- REST
- Resultaten
- <HR>Retail
- behouden
- terugkeer
- Rol
- wegen
- lopen
- sagemaker
- screenshots
- Ontdek
- zoekmachine
- Zoekmachines
- veiligheid
- zien
- kiezen
- dienen
- Serverless
- service
- Diensten
- reeks
- settings
- ze
- getoond
- Shows
- signalen
- Eenvoudig
- vereenvoudigt
- vereenvoudigen
- sinds
- Oplossingen
- bron
- specialist
- specifiek
- stack
- Start
- Status
- Stap voor
- Stappen
- mediaopslag
- Met goed gevolg
- dergelijk
- ondersteunde
- zeker
- sjabloon
- tekst
- dat
- De
- hun
- Ze
- harte
- daarbij
- Deze
- van derden
- dit
- Door
- naar
- samen
- tools
- Trainingen
- Transformatie
- Vertaling
- waar
- type dan:
- ui
- unieke
- uniek
- .
- use case
- gebruikt
- Gebruiker
- Gebruikerservaring
- gebruik
- BEVESTIG
- controleren
- versie
- via
- Video
- Bekijk
- loopt
- was
- we
- web
- webservices
- wanneer
- welke
- wil
- Met
- binnen
- werkte
- workflow
- workflow automatisering
- u
- Your
- zephyrnet