
AI가 클라우드에서 엣지로 이동함에 따라 이상 탐지부터 스마트 쇼핑, 감시, 로봇 공학, 공장 자동화를 포함한 애플리케이션에 이르기까지 점점 더 다양한 사용 사례에서 기술이 사용되는 것을 볼 수 있습니다. 따라서 모든 경우에 적용할 수 있는 일률적인 솔루션은 없습니다. 그러나 카메라 지원 장치가 급속히 성장함에 따라 AI는 실시간 비디오 데이터를 분석하여 비디오 모니터링을 자동화하여 안전성을 높이고, 운영 효율성을 향상시키며, 더 나은 고객 경험을 제공함으로써 궁극적으로 업계에서 경쟁 우위를 확보하는 데 가장 널리 채택되었습니다. . 비디오 분석을 더 잘 지원하려면 엣지 AI 배포에서 시스템 성능을 최적화하기 위한 전략을 이해해야 합니다.
- 필요한 성능 수준을 충족하거나 초과하기 위해 적절한 규모의 컴퓨팅 엔진을 선택합니다. AI 애플리케이션의 경우 이러한 컴퓨팅 엔진은 전체 비전 파이프라인의 기능(예: 비디오 사전 및 사후 처리, 신경망 추론)을 수행해야 합니다.
CPU나 GPU에서 AI 추론을 실행하는 것과 달리, 개별형이든 SoC에 통합되어 있든 전용 AI 가속기가 필요할 수 있습니다.
- 처리량과 대기 시간의 차이 이해 처리량은 시스템에서 데이터가 처리될 수 있는 속도이고 대기 시간은 시스템을 통한 데이터 처리 지연을 측정하며 종종 실시간 응답성과 관련됩니다. 예를 들어, 시스템은 초당 100프레임(처리량)으로 이미지 데이터를 생성할 수 있지만 이미지가 시스템을 통과하는 데 100ms(대기 시간)가 걸립니다.
- 증가하는 요구 사항, 변화하는 요구 사항 및 진화하는 기술(예: 향상된 기능과 정확성을 위한 고급 AI 모델)을 수용하기 위해 향후 AI 성능을 쉽게 확장할 수 있는 능력을 고려합니다. 모듈 형식의 AI 가속기 또는 추가 AI 가속기 칩을 사용하여 성능 확장을 달성할 수 있습니다.
실제 성능 요구 사항은 애플리케이션에 따라 다릅니다. 일반적으로 비디오 분석을 위해 시스템은 카메라에서 초당 30~60프레임, 해상도 1080p 또는 4k로 들어오는 데이터 스트림을 처리해야 한다고 예상할 수 있습니다. AI 지원 카메라는 단일 스트림을 처리합니다. Edge Appliance는 여러 스트림을 병렬로 처리합니다. 두 경우 모두 엣지 AI 시스템은 카메라의 센서 데이터를 AI 추론 섹션의 입력 요구 사항과 일치하는 형식으로 변환하는 전처리 기능을 지원해야 합니다(그림 1).
전처리 기능은 원시 데이터를 가져와 크기 조정, 정규화, 색상 공간 변환 등의 작업을 수행한 후 AI 가속기에서 실행되는 모델에 입력을 공급합니다. 전처리는 OpenCV와 같은 효율적인 이미지 처리 라이브러리를 사용하여 전처리 시간을 줄일 수 있습니다. 후처리에는 추론 결과 분석이 포함됩니다. 이는 비최대 억제(NMS는 대부분의 객체 감지 모델의 출력을 해석함) 및 이미지 표시와 같은 작업을 사용하여 경계 상자, 클래스 레이블 또는 신뢰 점수와 같은 실행 가능한 통찰력을 생성합니다.

그림 1. AI 모델 추론의 경우 사전 처리 및 사후 처리 기능은 일반적으로 애플리케이션 프로세서에서 수행됩니다.
AI 모델 추론은 애플리케이션의 기능에 따라 프레임당 여러 신경망 모델을 처리해야 하는 추가적인 과제를 안고 있을 수 있습니다. 컴퓨터 비전 애플리케이션에는 일반적으로 여러 모델의 파이프라인이 필요한 여러 AI 작업이 포함됩니다. 게다가 한 모델의 출력이 다음 모델의 입력이 되는 경우가 많습니다. 즉, 애플리케이션의 모델은 서로 의존하는 경우가 많으며 순차적으로 실행되어야 합니다. 실행할 정확한 모델 세트는 정적이지 않을 수 있으며 프레임 단위에서도 동적으로 달라질 수 있습니다.
여러 모델을 동적으로 실행하려면 모델을 저장할 만큼 충분히 큰 전용 메모리를 갖춘 외부 AI 가속기가 필요합니다. SoC 내부의 통합 AI 가속기는 공유 메모리 하위 시스템과 SoC의 기타 리소스로 인한 제약으로 인해 다중 모델 워크로드를 관리할 수 없는 경우가 많습니다.
예를 들어, 모션 예측 기반 객체 추적은 연속 감지에 의존하여 미래 위치에서 추적된 객체를 식별하는 데 사용되는 벡터를 결정합니다. 이 접근 방식은 실제 재식별 기능이 부족하기 때문에 효율성이 제한됩니다. 모션 예측을 사용하면 탐지 누락, 폐색 또는 객체가 시야를 벗어나는 경우 객체의 트랙이 순간적으로 손실될 수 있습니다. 일단 손실되면 개체의 트랙을 다시 연결할 방법이 없습니다. 재식별을 추가하면 이러한 제한이 해결되지만 시각적 모양 삽입(예: 이미지 지문)이 필요합니다. 모양 임베딩에는 첫 번째 네트워크에서 감지된 객체의 경계 상자 내부에 포함된 이미지를 처리하여 특징 벡터를 생성하는 두 번째 네트워크가 필요합니다. 이러한 임베딩은 시간이나 공간에 관계없이 객체를 다시 식별하는 데 사용될 수 있습니다. 시야에서 감지된 각 객체에 대해 임베딩을 생성해야 하므로 장면이 복잡해지면 처리 요구 사항도 늘어납니다. 재식별을 통한 객체 추적에는 고정밀/고해상도/고프레임 속도 감지 수행과 임베딩 확장성을 위한 충분한 오버헤드 확보 사이에서 신중한 고려가 필요합니다. 처리 요구 사항을 해결하는 한 가지 방법은 전용 AI 가속기를 사용하는 것입니다. 앞서 언급했듯이 SoC의 AI 엔진은 공유 메모리 리소스 부족으로 어려움을 겪을 수 있습니다. 모델 최적화를 사용하여 처리 요구 사항을 낮출 수도 있지만 성능 및/또는 정확성에 영향을 미칠 수 있습니다.
스마트 카메라 또는 엣지 기기에서 통합 SoC(즉, 호스트 프로세서)는 비디오 프레임을 획득하고 앞서 설명한 전처리 단계를 수행합니다. 이러한 기능은 SoC의 CPU 코어 또는 GPU(사용 가능한 경우)를 통해 수행될 수 있지만 SoC의 전용 하드웨어 가속기(예: 이미지 신호 프로세서)를 통해 수행될 수도 있습니다. 이러한 사전 처리 단계가 완료된 후 SoC에 통합된 AI 가속기는 시스템 메모리에서 이 양자화된 입력에 직접 액세스할 수 있습니다. 또는 개별 AI 가속기의 경우 일반적으로 추론을 위해 입력이 전달됩니다. USB 또는 PCIe 인터페이스.
통합 SoC에는 CPU, GPU, AI 가속기, 비전 프로세서, 비디오 인코더/디코더, 이미지 신호 프로세서(ISP) 등을 포함한 다양한 계산 장치가 포함될 수 있습니다. 이러한 계산 단위는 모두 동일한 메모리 버스를 공유하므로 결과적으로 동일한 메모리에 액세스합니다. 또한 CPU와 GPU도 추론에서 역할을 수행해야 할 수 있으며 이러한 장치는 배포된 시스템에서 다른 작업을 실행하는 데 바쁠 것입니다. 이것이 시스템 수준 오버헤드의 의미입니다(그림 2).
많은 개발자가 시스템 수준 오버헤드가 전체 성능에 미치는 영향을 고려하지 않고 SoC에 내장된 AI 가속기의 성능을 실수로 평가합니다. 예를 들어, SoC에 통합된 50 TOPS AI 가속기에서 YOLO 벤치마크를 실행하면 100개의 추론/초(IPS)라는 벤치마크 결과를 얻을 수 있습니다. 그러나 다른 모든 계산 장치가 활성화된 배포 시스템에서는 50 TOPS가 12 TOPS로 줄어들 수 있으며 전체 성능은 넉넉한 25% 활용률을 가정할 때 25 IPS에 불과합니다. 플랫폼이 지속적으로 비디오 스트림을 처리하는 경우 시스템 오버헤드는 항상 중요한 요소입니다. 또는 개별 AI 가속기(예: Kinara Ara-1, Hailo-8, Intel Myriad X)를 사용하면 호스트 SoC가 추론 기능을 시작하고 AI 모델의 입력을 전송하면 시스템 수준 활용도가 90%보다 높아질 수 있습니다. 데이터가 수집되면 가속기는 모델 가중치 및 매개변수에 액세스하기 위해 전용 메모리를 활용하여 자동으로 실행됩니다.
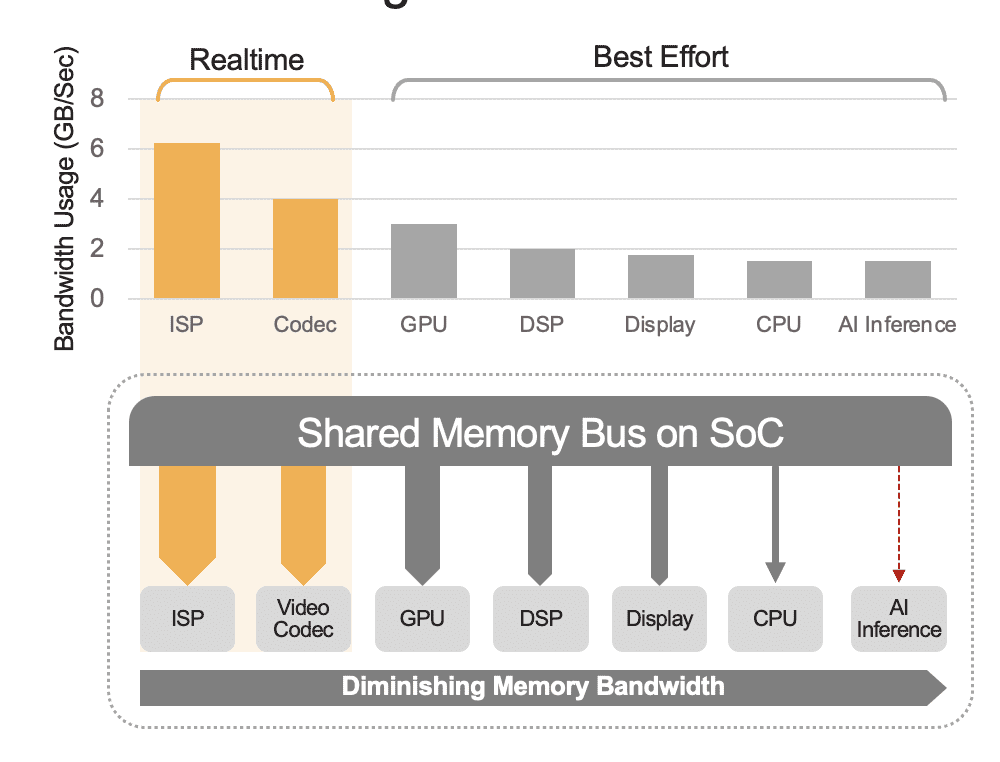
그림 2. 여기에 예상 값과 함께 표시된 공유 메모리 버스는 시스템 수준 성능을 제어합니다. 실제 값은 애플리케이션 사용 모델과 SoC의 컴퓨팅 장치 구성에 따라 달라집니다.
지금까지 초당 프레임 수와 TOPS 측면에서 AI 성능에 대해 논의했습니다. 그러나 낮은 대기 시간은 시스템의 실시간 응답성을 제공하기 위한 또 다른 중요한 요구 사항입니다. 예를 들어, 게임에서 특히 모션 제어 게임과 가상 현실(VR) 시스템에서 원활하고 반응성이 뛰어난 게임 경험을 위해서는 낮은 대기 시간이 매우 중요합니다. 자율 주행 시스템에서는 실시간 객체 감지, 보행자 인식, 차선 감지, 교통 표지판 인식을 통해 안전 저하를 방지하기 위해 짧은 대기 시간이 필수적입니다. 자율주행 시스템은 일반적으로 감지부터 실제 조치까지 150ms 미만의 엔드투엔드 지연 시간이 필요합니다. 마찬가지로, 제조 분야에서는 실시간 결함 감지, 이상 인식 및 로봇 안내를 위해 짧은 대기 시간이 필수적이며, 효율적인 운영을 보장하고 생산 중단 시간을 최소화하기 위해 짧은 대기 시간 비디오 분석이 필요합니다.
일반적으로 비디오 분석 애플리케이션에는 지연 시간의 세 가지 구성 요소가 있습니다(그림 3).
- 데이터 캡처 대기 시간은 카메라 센서가 비디오 프레임을 캡처한 후 처리를 위해 분석 시스템에서 프레임을 사용할 수 있을 때까지의 시간입니다. 빠른 센서와 낮은 대기 시간 프로세서를 갖춘 카메라를 선택하고, 최적의 프레임 속도를 선택하고, 효율적인 비디오 압축 형식을 사용하여 이 대기 시간을 최적화할 수 있습니다.
- 데이터 전송 대기 시간은 캡처 및 압축된 비디오 데이터가 카메라에서 에지 장치 또는 로컬 서버로 이동하는 시간입니다. 여기에는 각 끝점에서 발생하는 네트워크 처리 지연이 포함됩니다.
- 데이터 처리 지연 시간은 엣지 디바이스가 프레임 압축 해제 및 분석 알고리즘(예: 동작 예측 기반 객체 추적, 얼굴 인식)과 같은 비디오 처리 작업을 수행하는 데 걸리는 시간을 의미합니다. 앞서 지적했듯이 처리 지연 시간은 각 비디오 프레임에 대해 여러 AI 모델을 실행해야 하는 애플리케이션의 경우 훨씬 더 중요합니다.
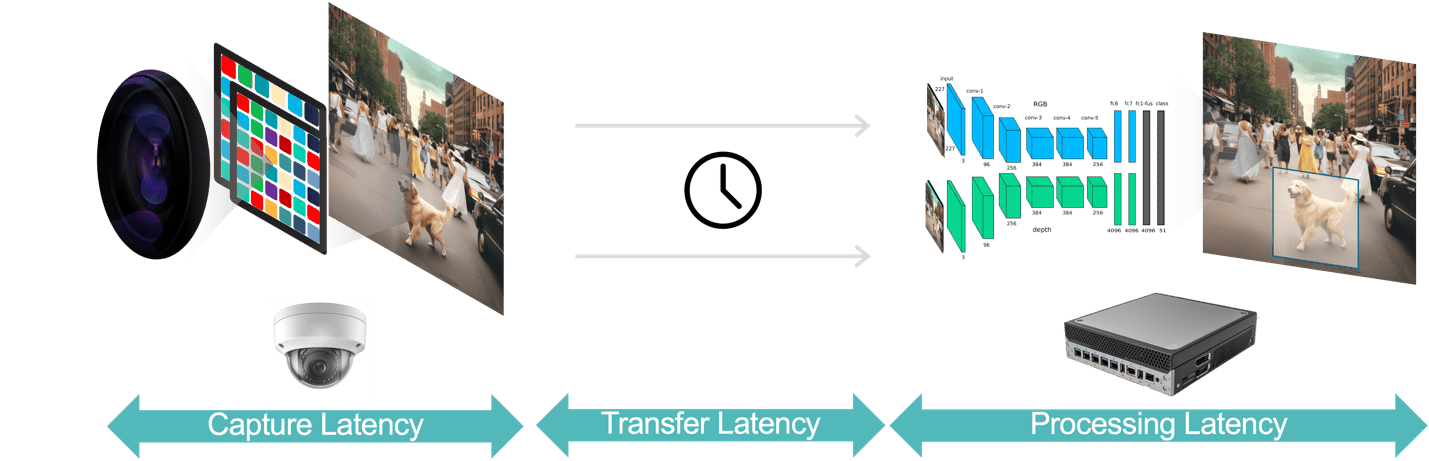
그림 3. 비디오 분석 파이프라인은 데이터 캡처, 데이터 전송 및 데이터 처리로 구성됩니다.
데이터 처리 대기 시간은 칩 전체와 컴퓨팅 및 메모리 계층의 다양한 수준 사이의 데이터 이동을 최소화하도록 설계된 아키텍처를 갖춘 AI 가속기를 사용하여 최적화할 수 있습니다. 또한 대기 시간과 시스템 수준 효율성을 개선하려면 아키텍처가 모델 간 전환 시간을 XNUMX(또는 거의 XNUMX)으로 지원하여 앞서 논의한 다중 모델 애플리케이션을 더 효과적으로 지원해야 합니다. 향상된 성능과 대기 시간을 위한 또 다른 요소는 알고리즘 유연성과 관련이 있습니다. 즉, 일부 아키텍처는 특정 AI 모델에서만 최적의 동작을 하도록 설계되었지만, 급변하는 AI 환경에 따라 더 높은 성능과 더 나은 정확도를 위한 새로운 모델이 이틀에 한 번씩 등장하고 있습니다. 따라서 모델 토폴로지, 연산자, 크기에 대한 실질적인 제한이 없는 엣지 AI 프로세서를 선택하세요.
성능 및 대기 시간 요구 사항, 시스템 오버헤드를 포함하여 엣지 AI 어플라이언스의 성능을 극대화하려면 고려해야 할 많은 요소가 있습니다. 성공적인 전략을 위해서는 SoC AI 엔진의 메모리 및 성능 한계를 극복하기 위해 외부 AI 가속기를 고려해야 합니다.
CH 치 뛰어난 제품 마케팅 및 관리 임원인 Chee는 기업과 소비자를 포함한 다양한 시장을 위한 비전 기반 AI, 연결성 및 비디오 인터페이스에 중점을 두고 반도체 산업의 제품 및 솔루션을 홍보하는 데 광범위한 경험을 보유하고 있습니다. 기업가로서 Chee는 공공 반도체 회사에 인수된 두 개의 비디오 반도체 스타트업을 공동 창립했습니다. Chee는 제품 마케팅 팀을 이끌었고 훌륭한 결과를 달성하는 데 중점을 두는 소규모 팀과 함께 일하는 것을 즐깁니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- :있다
- :이다
- :아니
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- 능력
- 가속 자
- 가속기
- ACCESS
- 액세스
- 수용하다
- 달성
- 달성
- 획득한
- 인수
- 가로질러
- 동작
- 활동적인
- 실제
- 첨가
- 추가
- 채택
- 많은
- 후
- 다시
- AI
- AI 엔진
- AI 모델
- 알고리즘
- 알고리즘
- All
- 또한
- 항상
- an
- 분석
- 분석
- 분석하는
- 및
- 이상 감지
- 다른
- 어플리케이션
- 어플리케이션
- 접근
- 아키텍처
- 있군요
- AS
- 관련
- At
- 자동화
- 자동화
- 자발적인
- 자율적으로
- 유효성
- 가능
- 피하기
- 기반으로
- 기초
- BE
- 때문에
- 된다
- 된
- 전에
- 존재
- 기준
- 더 나은
- 사이에
- 두
- 보물상자
- 박스
- 내장
- 버스
- 바쁜
- 비자 면제 프로그램에 해당하는 국가의 시민권을 가지고 있지만
- by
- 카메라
- 카메라
- CAN
- 기능
- 능력
- 포착
- 캡처
- 캡처
- 주의
- 케이스
- 가지 경우
- 도전
- 변화
- 칩
- 칩
- 선택
- 수업
- 클라우드
- 색
- 오는
- 회사
- 경쟁력
- 진행완료
- 구성 요소들
- 손상
- 계산
- 계산
- 계산
- 컴퓨터
- 컴퓨터 비전
- 컴퓨터 비전 애플리케이션
- 자신
- 구성
- 입/출력 라인
- 따라서
- 고려
- 고려
- 고려
- 치고는
- 구성
- 제약
- 소비자
- 포함하는
- 포함
- 끊임없는
- 지속적으로
- 매출 상승
- 수
- CPU
- 임계
- 고객
- 데이터
- 데이터 처리
- 일
- 전용
- 지연
- 지연
- 배달하다
- 전달
- 의존하는
- 의존
- 배포
- 배포
- 기술 된
- 설계
- 탐지 된
- Detection System
- 결정
- 개발자
- 디바이스
- 차이
- 직접
- 논의 된
- 디스플레이
- 중단 시간
- 운전
- 두
- 역동적 인
- e
- 마다
- 이전
- 용이하게
- Edge
- 효과
- 유효성
- 효율성
- 효율성
- 효율적인
- 중
- 임베딩
- end
- 끝으로 종료
- 엔진
- 엔진
- 강화
- 확인
- Enterprise
- 전체의
- 기업가
- 환경
- 필수
- 예상
- 평가
- 조차
- 모든
- 진화하는
- 예
- 넘다
- 실행
- 처형 된
- 행정부
- 기대
- 경험
- 체험
- 광대 한
- 광범위한 경험
- 외부
- 페이스메이크업
- 얼굴 인식
- 인자
- 요인
- 공장
- FAST
- 특색
- 먹이
- 들
- 그림
- 지문
- 먼저,
- 유연성
- 집중
- 초점
- 럭셔리
- 체재
- FRAME
- 에
- 기능
- 기능
- 기능
- 게다가
- 미래
- 획득
- Games
- 노름
- 게임 경험
- 일반
- 생성
- 생성
- 관대한
- Go
- GPU
- GPU
- 큰
- 큰
- 성장하는
- 성장
- 지도
- 하드웨어
- 있다
- 금후
- 여기에서 지금 확인해 보세요.
- 계층
- 높은
- 더 높은
- 주인
- HTTPS
- i
- 확인
- if
- 영상
- 영향
- 중대한
- 부과
- 개선
- 개선하는
- in
- 기타의
- 포함
- 포함
- 증가
- 증가
- 산업
- 산업
- 시작
- 입력
- 내부
- 통찰력
- 통합 된
- 인텔
- 인터페이스
- 인터페이스
- 으로
- 감다
- 포함
- 무의미한
- ISP
- IT
- 그
- 너 겟츠
- 레이블
- 결핍
- 레인
- 넓은
- 숨어 있음
- 출발
- 지도
- 적게
- 레벨
- 도서관
- 처럼
- 한정
- 한계
- 제한된
- 링크드인
- 지방의
- 잃어버린
- 낮은
- 절감
- 관리
- 구축
- 제조
- .
- 마케팅
- 시장
- 극대화하다
- 최대화
- XNUMX월..
- 평균
- 조치들
- 소개
- 메모리
- 말하는
- 수도
- 놓친
- 모델
- 모델
- 모듈
- 모니터링
- 배우기
- 가장
- 운동
- 운동
- 여러
- 절대로 필요한 것
- 무수한, 매우 많은
- 가까운
- 요구
- 네트워크
- 신경
- 신경망
- 신제품
- 다음 것
- 아니
- 대상
- 객체 감지
- 발생
- of
- 자주
- on
- 일단
- ONE
- 만
- OpenCV
- 조작
- 운영
- 운영자
- 반대하는
- 최적의
- 최적화
- 최적화
- 최적화
- 최적화
- or
- 기타
- 아웃
- 출력
- 위에
- 전체
- 극복하다
- 평행
- 매개 변수
- 특별히
- 용
- 수행
- 성능
- 수행
- 실행할 수 있는
- 수행하다
- 관로
- 플랫폼
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 연극
- 포인트 적립
- 위치
- 사후 처리
- 실용적인
- 예측
- 방법
- 처리
- 처리
- 프로세서
- 가공업자
- 프로덕트
- 생산
- 제품
- 홍보
- 제공
- 공개
- 범위
- 이르기까지
- 빠른
- 빠르게
- 율
- 거주비용
- 살갗이 벗어 진
- 원시 데이터
- 현실
- 실시간
- 현실
- 인식
- 감소
- 의미
- 필요
- 필수
- 요구 사항
- 요구조건 니즈
- 필요
- 분해능
- 제품 자료
- 반응
- 제한
- 결과
- 결과
- 로봇
- 직위별
- 달리기
- 달리는
- 실행
- 안전
- 같은
- 확장성
- 규모
- 규모 인공 지능
- 스케일링
- 장면
- 점수
- 원활한
- 둘째
- 섹션
- 참조
- 것
- 선택
- 반도체
- 세트
- 공유
- 공유
- 쇼핑
- 영상을
- 표시
- 기호
- 신호
- 비슷하게
- 이후
- 단일
- 크기
- 작은
- 스마트 한
- 해결책
- 솔루션
- 풀다
- 해결
- 일부
- 무언가
- 스페이스 버튼
- 구체적인
- 신생 기업
- 단계
- 저장
- 전략들
- 전략
- 흐름
- 스트림
- 성공한
- 이러한
- 충분한
- SUPPORT
- 억압
- 감시
- 체계
- 시스템은
- 받아
- 소요
- 작업
- 팀
- 팀
- 기술
- Technology
- 조건
- 보다
- 그
- XNUMXD덴탈의
- 미래
- 그들의
- 그때
- 그곳에.
- 따라서
- Bowman의
- 그들
- 이
- 그
- 세
- 을 통하여
- 처리량
- 시간
- 시대
- 에
- 상의
- 금액
- 선로
- 추적
- 교통
- 이전
- 전송
- 변환
- 여행
- 참된
- 두
- 일반적으로
- 궁극적으로
- 할 수 없는
- 이해
- 단위
- 단위
- 용법
- USB
- 사용
- 익숙한
- 사용
- 사용
- 보통
- 활용
- 마케팅은:
- 종류
- 여러
- Video
- 관측
- 온라인
- 가상 현실
- 시력
- 필수
- vr
- 방법..
- we
- 했다
- 뭐
- 여부
- 어느
- 크게
- 의지
- 과
- 없이
- 말
- 일하는
- 겠지
- X
- 수율
- 욜로
- 당신
- 너의
- 제퍼 넷
- 제로







