문자열 데이터의 효율적인 처리는 많은 데이터 과학 응용 프로그램에 필수적입니다. 문자열 데이터에서 중요한 정보를 추출하려면 래피즈 libcudf 문자열 데이터 변환을 가속화하기 위한 강력한 도구를 제공합니다. libcudf는 데이터를 로드, 결합, 집계 및 필터링하는 데 사용되는 C++ GPU DataFrame 라이브러리입니다.
데이터 과학에서 문자열 데이터는 음성, 텍스트, 유전자 시퀀스, 로깅 및 기타 여러 유형의 정보를 나타냅니다. 기계 학습 및 기능 엔지니어링을 위해 문자열 데이터로 작업할 때 특정 사용 사례에 적용하기 전에 데이터를 자주 정규화하고 변환해야 합니다. libcudf는 범용 API와 장치 측 유틸리티를 모두 제공하여 광범위한 사용자 정의 문자열 작업을 가능하게 합니다.
이 게시물은 libcudf 범용 API를 사용하여 문자열 열을 능숙하게 변환하는 방법을 보여줍니다. 사용자 정의 커널 및 libcudf 장치 측 유틸리티를 사용하여 최고 성능을 잠금 해제하는 방법에 대한 새로운 지식을 얻을 수 있습니다. 또한 이 게시물은 GPU 메모리를 가장 잘 관리하고 문자열 변환 속도를 높이기 위해 libcudf 열을 효율적으로 구성하는 방법에 대한 예제를 안내합니다.
libcudf는 다음을 사용하여 장치 메모리에 문자열 데이터를 저장합니다. 화살표 형식, 문자열 열을 두 개의 하위 열로 나타냅니다. chars and offsets (그림 1).
XNUMXD덴탈의 chars 열은 문자열 데이터를 메모리에 연속적으로 저장되는 UTF-8 인코딩 문자 바이트로 보유합니다.
XNUMXD덴탈의 offsets 열에는 chars 데이터 배열 내에서 각 개별 문자열의 시작을 식별하는 바이트 위치인 증가하는 정수 시퀀스가 포함됩니다. 마지막 오프셋 요소는 chars 열의 총 바이트 수입니다. 이것은 행에서 개별 문자열의 크기를 의미합니다. i (offsets[i+1]-offsets[i]).
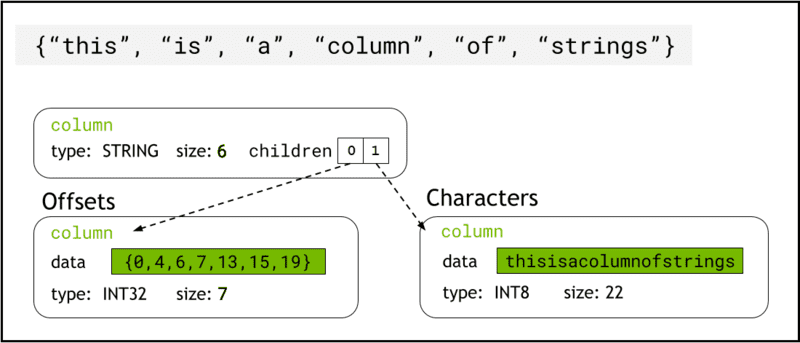 그림 1. 화살표 형식이 문자열 열을 나타내는 방법을 보여주는 개략도
그림 1. 화살표 형식이 문자열 열을 나타내는 방법을 보여주는 개략도 chars 및 offsets 하위 열
예제 문자열 변환을 설명하기 위해 두 개의 입력 문자열 열을 수신하고 하나의 수정된 출력 문자열 열을 생성하는 함수를 고려하십시오.
입력 데이터의 형식은 공백으로 구분된 이름과 성을 포함하는 "names" 열과 "public" 또는 "private" 상태를 포함하는 "visibilities" 열입니다.
입력 데이터에 대해 작동하는 "redact" 기능을 제안하여 성의 첫 번째 이니셜과 공백 및 전체 이름으로 구성된 출력 데이터를 생성합니다. 그러나 해당 가시성 열이 "private"인 경우 출력 문자열은 "X X"로 완전히 수정되어야 합니다.
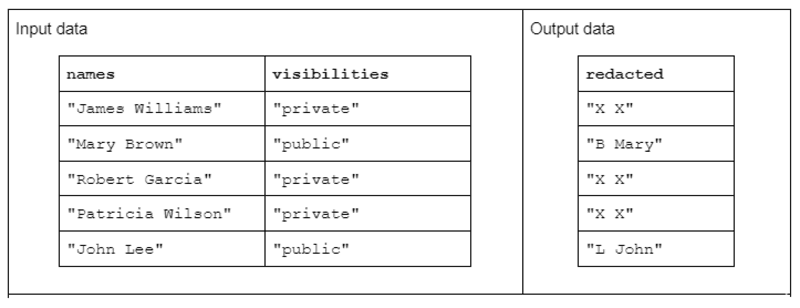 표 1. 이름 및 가시성 문자열 열을 입력으로 받고 부분적으로 또는 완전히 개정된 데이터를 출력으로 수신하는 "교정" 문자열 변환의 예
표 1. 이름 및 가시성 문자열 열을 입력으로 받고 부분적으로 또는 완전히 개정된 데이터를 출력으로 수신하는 "교정" 문자열 변환의 예
첫째, 문자열 변환은 다음을 사용하여 수행할 수 있습니다. libcudf 문자열 API. 범용 API는 우수한 출발점이자 성능 비교를 위한 좋은 기준입니다.
API 함수는 전체 문자열 열에서 작동하여 함수당 최소 하나의 커널을 시작하고 문자열당 하나의 스레드를 할당합니다. 각 스레드는 GPU에서 병렬로 데이터의 단일 행을 처리하고 단일 행을 새 출력 열의 일부로 출력합니다.
범용 API를 사용하여 교정 예제 기능을 완료하려면 다음 단계를 따르십시오.
- 다음을 사용하여 "가시성" 문자열 열을 부울 열로 변환합니다.
contains - 부울 열의 해당 행 항목이 "false"일 때마다 "XX"를 복사하여 이름 열에서 새 문자열 열을 만듭니다.
- "수정됨" 열을 이름 및 성 열로 분할
- 성의 첫 글자를 성 이니셜로 슬라이스
- 마지막 이니셜 열과 이름 열을 공백(" ") 구분 기호로 연결하여 출력 열을 작성합니다.
// convert the visibility label into a boolean
auto const visible = cudf::string_scalar(std::string("public"));
auto const allowed = cudf::strings::contains(visibilities, visible); // redact names auto const redaction = cudf::string_scalar(std::string("X X"));
auto const redacted = cudf::copy_if_else(names, redaction, allowed->view()); // split the first name and last initial into two columns
auto const sv = cudf::strings_column_view(redacted->view())
auto const first_last = cudf::strings::split(sv);
auto const first = first_last->view().column(0);
auto const last = first_last->view().column(1);
auto const last_initial = cudf::strings::slice_strings(last, 0, 1); // assemble a result column
auto const tv = cudf::table_view({last_initial->view(), first});
auto result = cudf::strings::concatenate(tv, std::string(" "));
이 접근 방식은 3.5K 데이터 행이 있는 A6000에서 약 600ms가 걸립니다. 이 예제는 contains, copy_if_else, split, slice_strings 및 concatenate 사용자 지정 문자열 변환을 수행합니다. 프로파일링 분석 엔사이트 시스템즈 보여줍니다 split 함수가 가장 오래 걸리고 그 다음이 slice_strings 및 concatenate.
그림 2는 redact 예제의 Nsight Systems의 프로파일링 데이터를 보여주며, 초당 최대 ~600억 요소에서 종단 간 문자열 처리를 보여줍니다. 영역은 각 기능과 관련된 NVTX 범위에 해당합니다. 하늘색 범위는 CUDA 커널이 실행되는 기간에 해당합니다.
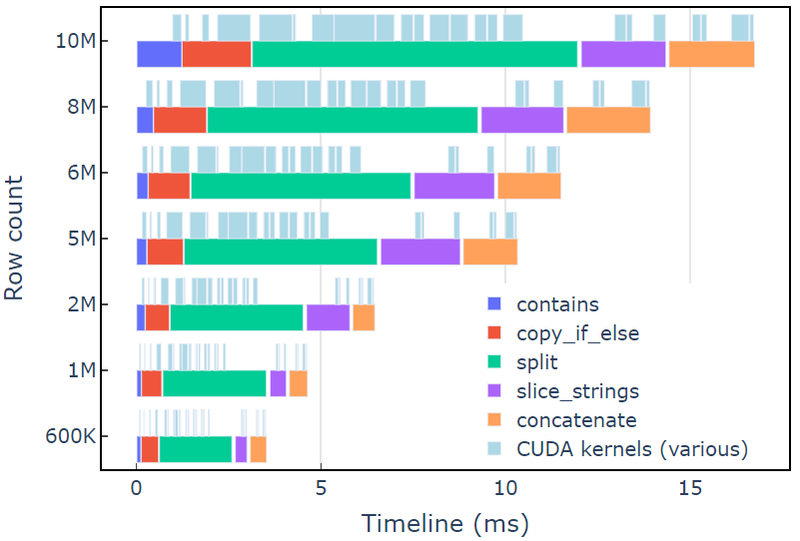 그림 2. redact 예제의 Nsight Systems에서 데이터 프로파일링
그림 2. redact 예제의 Nsight Systems에서 데이터 프로파일링
libcudf strings API는 문자열 변환을 위한 빠르고 효율적인 툴킷이지만 때로는 성능에 중요한 기능이 더 빠르게 실행되어야 합니다. libcudf strings API에서 추가 작업의 주요 소스는 각 API 호출에 대해 전역 장치 메모리에 하나 이상의 새 strings 열을 생성하여 여러 API 호출을 사용자 지정 커널로 결합할 수 있는 기회를 여는 것입니다.
커널 malloc 호출의 성능 제한
먼저 redact 예제 변환을 구현하기 위해 사용자 지정 커널을 빌드합니다. 이 커널을 설계할 때 libcudf 문자열 열은 변경할 수 없다는 점을 염두에 두어야 합니다.
문자열 열은 문자 바이트가 연속적으로 저장되기 때문에 제자리에서 변경할 수 없으며 문자열 길이를 변경하면 오프셋 데이터가 무효화됩니다. 따라서 redact_kernel 사용자 지정 커널은 libcudf 열 팩터리를 사용하여 새 문자열 열을 생성하여 둘 다 빌드합니다. offsets 및 chars 자식 열.
이 첫 번째 접근 방식에서 각 행의 출력 문자열은 동적 장치 메모리 커널 내부에서 malloc 호출을 사용합니다. 사용자 지정 커널 출력은 각 행 출력에 대한 장치 포인터의 벡터이며 이 벡터는 문자열 열 팩터리에 대한 입력으로 사용됩니다.
커스텀 커널은 cudf::column_device_view 문자열 열 데이터에 액세스하고 element 반환하는 메소드 cudf::string_view 지정된 행 인덱스에서 문자열 데이터를 나타냅니다. 커널 출력은 다음 유형의 벡터입니다. cudf::string_view 출력 문자열과 해당 문자열의 크기(바이트)를 포함하는 장치 메모리에 대한 포인터를 보유합니다.
XNUMXD덴탈의 cudf::string_view 클래스는 std::string_view 클래스와 유사하지만 libcudf용으로 특별히 구현되었으며 UTF-8로 인코딩된 장치 메모리에서 고정 길이의 문자 데이터를 래핑합니다. 동일한 기능이 많이 있습니다(find 및 substr 예를 들어 함수) 및 제한 사항(null 종결자 없음)을 std 짝. ㅏ cudf::string_view 장치 메모리에 저장된 문자 시퀀스를 나타내므로 여기에서 이를 사용하여 출력 벡터에 대한 malloc'd 메모리를 기록할 수 있습니다.
Malloc 커널
// note the column_device_view inputs to the kernel __global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, cudf::string_view* d_output)
{ // get index for this thread auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; char* output_ptr = static_cast(malloc(output_size)); // build output string d_output[index] = cudf::string_view{output_ptr, output_size}; memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
} __global__ void free_kernel(cudf::string_view redaction, cudf::string_view* d_output, int count)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= count) return; auto ptr = const_cast(d_output[index].data()); if (ptr != redaction.data()) free(ptr); // free everything that does match the redaction string
}
이것은 커널 성능이 측정되기 전까지는 합리적인 접근 방식처럼 보일 수 있습니다. 이 접근 방식은 108K 데이터 행이 있는 A6000에서 약 600ms가 걸리며 libcudf strings API를 사용하여 위에서 제공한 솔루션보다 30배 이상 느립니다.
redact_kernel 60.3ms
free_kernel 45.5ms
make_strings_column 0.5ms
주요 병목 현상은 malloc/free 여기에서 두 커널 내부를 호출합니다. CUDA 동적 장치 메모리에는 다음이 필요합니다. malloc/free 동기화할 커널의 호출로 인해 병렬 실행이 순차적 실행으로 변질됩니다.
병목 현상을 제거하기 위한 작업 메모리 사전 할당
제거 malloc/free 를 교체하여 병목 현상 malloc/free 커널을 시작하기 전에 미리 할당된 작업 메모리로 커널을 호출합니다.
교정 예제의 경우 로직이 문자만 제거하므로 이 예제의 각 문자열의 출력 크기는 입력 문자열 자체보다 크지 않아야 합니다. 따라서 단일 디바이스 메모리 버퍼는 입력 버퍼와 동일한 크기로 사용할 수 있습니다. 입력 오프셋을 사용하여 각 행 위치를 찾습니다.
문자열 열의 오프셋에 액세스하려면 cudf::column_view 와 cudf::strings_column_view 그리고 그것의 offsets_begin 방법. 의 크기 chars 하위 열은 다음을 사용하여 액세스할 수도 있습니다. chars_size 방법. 그 다음에 rmm::device_uvector 문자 출력 데이터를 저장하기 위해 커널을 호출하기 전에 미리 할당됩니다.
auto const scv = cudf::strings_column_view(names);
auto const offsets = scv.offsets_begin();
auto working_memory = rmm::device_uvector(scv.chars_size(), stream);미리 할당된 커널
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, char* working_memory, cudf::offset_type const* d_offsets, cudf::string_view* d_output)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // resolve output string location char* output_ptr = working_memory + d_offsets[index]; d_output[index] = cudf::string_view{output_ptr, output_size}; // build output string into output_ptr memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
}
커널은 다음의 벡터를 출력합니다. cudf::string_view 에게 전달되는 객체 cudf::make_strings_column 공장 기능. 이 함수의 두 번째 매개변수는 출력 열에서 null 항목을 식별하는 데 사용됩니다. 이 게시물의 예제에는 null 항목이 없으므로 nullptr 자리 표시자 cudf::string_view{nullptr,0} 사용.
auto str_ptrs = rmm::device_uvector(names.size(), stream); redact_kernel>>(*d_names, *d_visibilities, d_redaction.value(), working_memory.data(), offsets, str_ptrs.data()); auto result = cudf::make_strings_column(str_ptrs, cudf::string_view{nullptr,0}, stream);
이 접근 방식은 1.1K 데이터 행이 있는 A6000에서 약 600ms가 걸리므로 기준선을 2배 이상 능가합니다. 대략적인 분석은 다음과 같습니다.
redact_kernel 66us make_strings_column 400us
남은 시간은 cudaMalloc, cudaFree, cudaMemcpy, 이는 임시 인스턴스를 관리하기 위한 일반적인 오버헤드입니다. rmm::device_uvector. 이 방법은 모든 출력 문자열이 입력 문자열과 크기가 같거나 작을 경우 잘 작동합니다.
전반적으로 RAPIDS RMM을 사용하여 대량 작업 메모리 할당으로 전환하는 것은 사용자 정의 문자열 기능을 위한 상당한 개선 및 좋은 솔루션입니다.
더 빠른 컴퓨팅 시간을 위한 열 생성 최적화
이것을 더 개선할 수 있는 방법이 있습니까? 병목 현상은 이제 cudf::make_strings_column 두 개의 문자열 열 구성요소를 빌드하는 팩토리 함수, offsets 및 chars, 벡터에서 cudf::string_view 사물.
libcudf에는 문자열 열을 작성하기 위한 많은 팩토리 함수가 포함되어 있습니다. 이전 예제에서 사용된 팩토리 함수는 cudf::device_span of cudf::string_view 다음을 수행하여 기둥을 구성합니다. gather 기본 문자 데이터에서 오프셋 및 문자 하위 열을 빌드합니다. ㅏ rmm::device_uvector 로 자동 변환됩니다. cudf::device_span 데이터를 복사하지 않고.
그러나 문자의 벡터와 오프셋의 벡터가 직접 빌드되는 경우 다른 팩터리 함수를 사용할 수 있습니다. 이 함수는 데이터를 복사하기 위해 수집할 필요 없이 간단히 문자열 열을 생성합니다.
XNUMXD덴탈의 sizes_kernel 각 출력 행의 정확한 출력 크기를 계산하기 위해 입력 데이터에 대한 첫 번째 패스를 만듭니다.
최적화된 커널: 파트 1
__global__ void sizes_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type* d_sizes)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); cudf::size_type result = redaction.size_bytes(); // init to redaction size if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); result = first.size_bytes() + last_initial.size_bytes() + 1; } d_sizes[index] = result;
}
출력 크기는 인플레이스를 수행하여 오프셋으로 변환됩니다. exclusive_scan. 참고로 offsets 벡터는 names.size()+1 집단. 마지막 항목은 총 바이트 수(모든 크기를 더한 값)이고 첫 번째 항목은 0입니다. 둘 다 exclusive_scan 전화. 의 크기 chars 열은 의 마지막 항목에서 검색됩니다. offsets chars 벡터를 빌드하는 열입니다.
// create offsets vector
auto offsets = rmm::device_uvector(names.size() + 1, stream); // compute output sizes
sizes_kernel>>( *d_names, *d_visibilities, offsets.data()); thrust::exclusive_scan(rmm::exec_policy(stream), offsets.begin(), offsets.end(), offsets.begin());
XNUMXD덴탈의 redact_kernel 논리는 출력을 허용한다는 점을 제외하면 여전히 매우 동일합니다. d_offsets 각 행의 출력 위치를 확인하기 위한 벡터:
최적화된 커널: 파트 2
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type const* d_offsets, char* d_chars)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); // resolve output_ptr using the offsets vector char* output_ptr = d_chars + d_offsets[index]; auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // build output string memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { memcpy(output_ptr, redaction.data(), redaction.size_bytes()); }
}
출력의 크기 d_chars 열은 의 마지막 항목에서 검색됩니다. d_offsets 열을 사용하여 chars 벡터를 할당합니다. 커널은 미리 계산된 오프셋 벡터로 시작하고 채워진 문자 벡터를 반환합니다. 마지막으로 libcudf 문자열 열 팩터리는 출력 문자열 열을 생성합니다.
이 cudf::make_strings_column 팩토리 함수는 데이터를 복사하지 않고 strings 열을 만듭니다. 그만큼 offsets 데이터 및 chars 데이터는 이미 올바른 예상 형식이며 이 팩터리는 단순히 각 벡터에서 데이터를 이동하고 주변에 열 구조를 만듭니다. 완료되면 rmm::device_uvectors for
offsets 및 chars 비어 있고 데이터가 출력 열로 이동되었습니다.
cudf::size_type output_size = offsets.back_element(stream);
auto chars = rmm::device_uvector(output_size, stream); redact_kernel>>( *d_names, *d_visibilities, offsets.data(), chars.data()); // from pre-assembled offsets and character buffers
auto result = cudf::make_strings_column(names.size(), std::move(offsets), std::move(chars));
이 접근 방식은 300K 데이터 행이 있는 A0.3에서 약 6000us(600ms)가 걸리며 이전 접근 방식보다 2배 이상 향상됩니다. 당신은 그것을 알 수 있습니다 sizes_kernel 및 redact_kernel 동일한 논리를 많이 공유합니다. 한 번은 출력의 크기를 측정한 다음 다시 출력을 채우는 것입니다.
코드 품질 관점에서 변환을 크기 및 교정 커널 모두에서 호출하는 장치 함수로 리팩터링하는 것이 좋습니다. 성능 관점에서 변환의 계산 비용이 두 번 지불되는 것을 보고 놀랄 수 있습니다.
메모리 관리 및 보다 효율적인 열 생성의 이점은 종종 변환을 두 번 수행하는 계산 비용보다 큽니다.
표 2는 이 게시물에서 논의된 네 가지 솔루션에 대해 처리된 컴퓨팅 시간, 커널 수 및 바이트를 보여줍니다. "총 커널 실행"은 컴퓨팅 및 도우미 커널을 모두 포함하여 실행된 총 커널 수를 반영합니다. "처리된 총 바이트"는 누적 DRAM 읽기 + 쓰기 처리량이며 "처리된 최소 바이트"는 테스트 입력 및 출력에 대한 행당 평균 37.9바이트입니다. 이상적인 "메모리 대역폭 제한" 사례는 A768의 이론적 최대 처리량인 6000GB/s 대역폭을 가정합니다.
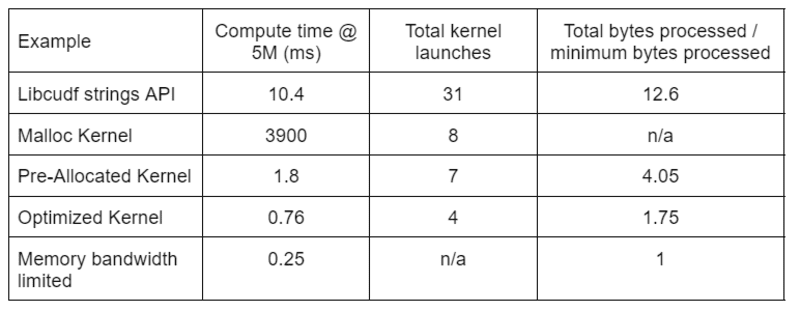 표 2. 이 게시물에서 논의된 네 가지 솔루션에 대해 처리된 컴퓨팅 시간, 커널 수 및 바이트
표 2. 이 게시물에서 논의된 네 가지 솔루션에 대해 처리된 컴퓨팅 시간, 커널 수 및 바이트
"최적화된 커널"은 감소된 커널 실행 횟수와 처리되는 총 바이트 수 감소로 인해 최고의 처리량을 제공합니다. 효율적인 사용자 정의 커널을 사용하면 총 커널 시작이 31에서 4로 감소하고 처리된 총 바이트는 입력 및 출력 크기의 12.6x에서 1.75x로 감소합니다.
결과적으로 사용자 지정 커널은 교정 변환을 위한 범용 문자열 API보다 10배 이상 높은 처리량을 달성합니다.
풀 메모리 리소스 RAPIDS 메모리 관리자(RMM) 성능을 향상시키는 데 사용할 수 있는 또 다른 도구입니다. 위의 예에서는 전역 장치 메모리를 할당하고 해제하기 위해 기본 "CUDA 메모리 리소스"를 사용합니다. 그러나 작업 메모리를 할당하는 데 필요한 시간으로 인해 문자열 변환 단계 사이에 상당한 대기 시간이 추가됩니다. RMM의 "풀 메모리 리소스"는 대규모 메모리 풀을 미리 할당하고 처리 중에 필요에 따라 하위 할당을 할당하여 대기 시간을 줄입니다.
CUDA 메모리 리소스를 사용하는 "최적화된 커널"은 증가하는 할당 크기로 인해 더 높은 행 수에서 떨어지기 시작하는 10x-15x 속도 향상을 보여줍니다(그림 3). 풀 메모리 리소스를 사용하면 이 효과가 완화되고 libcudf strings API 접근 방식에 비해 15x-25x 속도 향상이 유지됩니다.
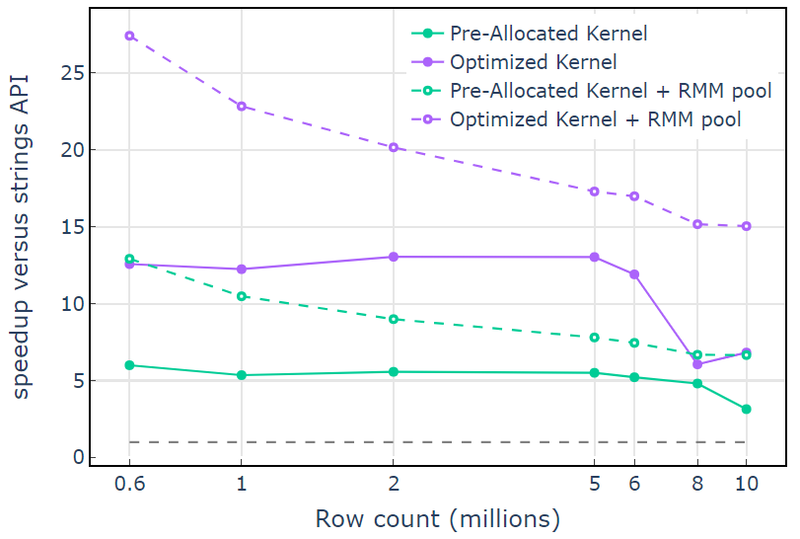 그림 3. 기본 CUDA 메모리 리소스(실선) 및 풀 메모리 리소스(점선)를 사용하는 사용자 지정 커널 "사전 할당된 커널" 및 "최적화된 커널"과 기본 CUDA 메모리 리소스를 사용하는 libcudf 문자열 API의 속도 향상
그림 3. 기본 CUDA 메모리 리소스(실선) 및 풀 메모리 리소스(점선)를 사용하는 사용자 지정 커널 "사전 할당된 커널" 및 "최적화된 커널"과 기본 CUDA 메모리 리소스를 사용하는 libcudf 문자열 API의 속도 향상
풀 메모리 리소스를 사용하여 320패스 알고리즘의 이론적 한계에 근접한 종단 간 메모리 처리량을 보여줍니다. "최적화된 커널"은 340-4GB/s 처리량에 도달하며 입력 크기와 출력 크기 및 컴퓨팅 시간을 사용하여 측정됩니다(그림 XNUMX).
6000단계 접근 방식은 먼저 출력 요소의 크기를 측정하고 메모리를 할당한 다음 출력으로 메모리를 설정합니다. 768패스 처리 알고리즘이 주어지면 "최적화된 커널"의 구현은 메모리 대역폭 제한에 가깝게 수행됩니다. "엔드 투 엔드 메모리 처리량"은 입력과 출력 크기(GB)를 컴퓨팅 시간으로 나눈 값으로 정의됩니다. *RTX AXNUMX 메모리 대역폭(XNUMXGB/s).
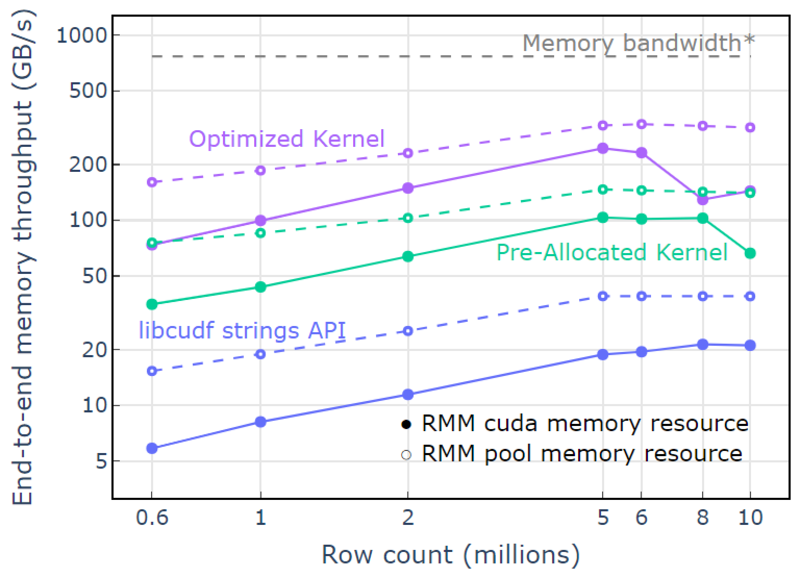 그림 4. 입력/출력 행 수의 함수로서 "최적화된 커널", "사전 할당된 커널" 및 "libcudf strings API"의 메모리 처리량
그림 4. 입력/출력 행 수의 함수로서 "최적화된 커널", "사전 할당된 커널" 및 "libcudf strings API"의 메모리 처리량
이 게시물은 libcudf에서 효율적인 문자열 데이터 변환을 작성하기 위한 두 가지 접근 방식을 보여줍니다. libcudf 범용 API는 개발자에게 빠르고 간단하며 우수한 성능을 제공합니다. libcudf는 사용자 지정 커널과 함께 사용하도록 설계된 장치 측 유틸리티도 제공하며, 이 예에서는 10배 이상 빠른 성능을 제공합니다.
지식 적용
RAPIDS cuDF를 시작하려면 래피드사이/커드프 GitHub 저장소. 문자열 처리 워크로드에 대해 cuDF 및 libcudf를 아직 시도하지 않은 경우 최신 릴리스를 테스트하는 것이 좋습니다. 고정 컨테이너 릴리스 및 야간 빌드용으로 제공됩니다. 콘다 패키지 더 쉽게 테스트하고 배포할 수 있도록 사용할 수도 있습니다. 이미 cuDF를 사용하고 있다면 다음을 방문하여 새 문자열 변환 예제를 실행하는 것이 좋습니다. rapidsai/cudf/tree/HEAD/cpp/예제/문자열 GitHub에.
데이비드 웬트 RAPIDS용 C++/CUDA 코드를 개발하는 NVIDIA의 선임 시스템 소프트웨어 엔지니어입니다. David는 Johns Hopkins University에서 전기 공학 석사 학위를 받았습니다.
그레고리 킴볼 RAPIDS 팀에서 일하는 NVIDIA의 소프트웨어 엔지니어링 관리자입니다. Gregory는 RAPIDS cuDF를 지원하는 컬럼 데이터 처리용 CUDA/C++ 라이브러리인 libcudf의 개발을 이끌고 있습니다. Gregory는 California Institute of Technology에서 응용 물리학 박사 학위를 받았습니다.
실물. 허가를 받아 다시 게시했습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/2023/01/mastering-string-transformations-rapids-libcudf.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-string-transformations-in-rapids-libcudf
- 1
- 7
- 9
- a
- 소개
- 위의
- 가속하는
- 수락
- ACCESS
- 액세스
- 달성
- 가로질러
- 추가
- 추가
- 연산
- All
- 할당하다
- 배당
- 이미
- 양
- 분석
- 및
- 다른
- 아파치
- API를
- API
- 어플리케이션
- 적용된
- 접근
- 구혼
- 접근하는
- 약
- 배열
- 관련
- 자동
- 자동적으로
- 가능
- 평균
- 대역폭
- 기준
- 때문에
- 전에
- 존재
- 이하
- 유익한
- 혜택
- BEST
- 사이에
- 파란색
- 분석
- 버퍼
- 빌드
- 건물
- 빌드
- 내장
- C + +
- 캘리포니아
- 전화
- 라는
- 부름
- 통화
- 케이스
- 가지 경우
- 일으키는
- 변경
- 문자
- 문자
- 아이
- 수업
- 닫기
- 암호
- 단
- 열
- 결합
- 비교
- 완전한
- 진행완료
- 구성 요소들
- 계산
- 계산
- 고려
- 구성
- 구축
- 이 포함되어 있습니다
- 변하게 하다
- 변환
- 사자
- 동
- 비용
- 만들
- 만든
- 생성
- 창조
- 관습
- 데이터
- 데이터 처리
- 데이터 과학
- 데이비드
- 태만
- 도
- 제공
- 시연
- 전개
- 설계
- 설계
- 개발자
- 개발
- 개발
- 장치
- 다른
- 직접
- 논의 된
- 분할 된
- 도커
- 드롭
- ...동안
- 동적
- 마다
- 쉽게
- 효과
- 효율적인
- 효율적으로
- 전기 공학
- 요소
- 제거
- 가능
- 격려
- 끝으로 종료
- 기사
- 엔지니어링
- 전체의
- 항목
- 에테르 (ETH)
- 조차
- 모두
- 예
- 예
- 우수한
- 외
- 실행
- 기대하는
- 외부
- 여분의
- 추출물
- 공장
- FAST
- 빠른
- 특색
- 특징
- 그림
- 필터링
- 최후의
- 최종적으로
- 먼저,
- 고정
- 따라
- 다음에
- 수행원
- 형태
- 체재
- 무료
- 자주
- 에
- 앞
- 충분히
- 기능
- 기능
- 추가
- 이득
- 일반
- 생성
- 얻을
- GitHub의
- 주어진
- 글로벌
- 좋은
- GPU
- 보장
- 처리
- 데
- 여기에서 지금 확인해 보세요.
- 더 높은
- 최고
- 보유
- 방법
- How To
- 그러나
- HTML
- HTTPS
- 이상
- 식별
- 불변의
- 구현
- 이행
- 구현
- 개선
- 개량
- 향상
- in
- 포함
- 포함
- 증가
- 증가
- 색인
- 개인
- 정보
- 처음에는
- 입력
- 학회
- 내부의
- IT
- 그 자체
- 존스 홉킨스
- 존스 홉킨스 대학
- 가입
- 너 겟츠
- 유지
- 키
- 지식
- 라벨
- 넓은
- 큰
- 성
- 숨어 있음
- 최근
- 최신 릴리스
- 시작
- 시작
- 진수
- 오퍼
- 배우기
- 길이
- 도서관
- 빛
- 제한
- 한계
- 로드
- 위치
- 기계
- 기계 학습
- 본관
- 유지
- 확인
- 제작
- 유튜브 영상을 만드는 것은
- 관리
- 구축
- 매니저
- 관리
- .
- 석사
- 마스터
- 경기
- 방법
- 측정
- 조치들
- 메모리
- 방법
- 수도
- 백만
- 신경
- 배우기
- 보다 효율적으로
- 이동
- MS
- 여러
- name
- 이름
- 필요
- 필요
- 신제품
- 번호
- 엔비디아
- 사물
- 오프셋
- ONE
- 열기
- 운영
- 운영
- 행정부
- 기회
- 기타
- 지급
- 평행
- 매개 변수
- 부품
- 합격
- 피크 (캐노피 지붕쪽)
- 성능
- 실행할 수 있는
- 수행하다
- 미문
- 허가
- 관점
- 물리학
- 장소
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- ...을 더한
- 포인트 적립
- 풀
- 인구가 많은
- 위치
- 위치
- 게시하다
- 강한
- 권력
- 너무 이른
- 처리
- 생산
- 프로파일 링
- 제안
- 제공
- 제공
- 공개
- 목적
- 품질
- 범위
- 도달하다
- 읽기
- 합리적인
- 수신
- 기록
- 감소
- 감소
- 리팩터링
- 반영하다
- 지역
- 공개
- 보도 자료
- 나머지
- 대표
- 대표
- 의지
- 결과
- return
- 반품
- 열
- 달리기
- 달리는
- 같은
- 과학
- 둘째
- 연장자
- 순서
- 봉사하다
- 설정
- 공유
- 영상을
- 표시
- 쇼
- 상당한
- 비슷한
- 간단히
- 이후
- 단일
- 크기
- 크기
- 작은
- So
- 소프트웨어
- 소프트웨어 엔지니어
- 소프트웨어 공학
- 고체
- 해결책
- 솔루션
- 출처
- 스페이스 버튼
- 구체적인
- 구체적으로
- 지정
- 연설
- 속도
- 지출
- 분열
- 스타트
- 시작
- 시작 중
- Status
- 단계
- 아직도
- 저장
- 저장
- 상점
- 똑 바른
- 흐름
- 구조
- 깜짝
- 시스템은
- 소요
- 팀
- Technology
- 일시적인
- test
- 지원
- XNUMXD덴탈의
- 그들의
- 이론적 인
- 따라서
- 을 통하여
- 처리량
- 시간
- 에
- 함께
- 수단
- 툴킷
- 검색을
- 금액
- 변환
- 변환
- 변환
- 변환
- 변화
- tv
- 유형
- 전형적인
- 밑에 있는
- 대학
- 잠금을 해제
- 잠금 해제
- us
- 사용
- 유용
- 가치 있는
- 귀중한 정보
- 대
- 가시성
- 눈에 보이는
- 필수
- 어느
- 동안
- 넓은
- 넓은 범위
- 의지
- 이내
- 없이
- 작업
- 일하는
- 일
- 겠지
- 쓰다
- 쓰기
- X
- 너의
- 제퍼 넷










