웹 스크래핑은 웹사이트에서 데이터를 추출하는 강력한 도구일 수 있지만 복잡하고 시간이 많이 걸리는 프로세스일 수도 있습니다. 다행스럽게도 Google 스프레드시트는 복잡한 코드를 작성할 필요 없이 웹사이트에서 데이터를 스크랩할 수 있는 사용자 친화적인 솔루션을 제공합니다. Google Sheets의 강력한 기능을 활용하면 웹 페이지에서 쉽게 데이터를 추출하고 다양한 방식으로 분석할 수 있습니다. 이 블로그에서는 Google 스프레드시트를 사용하여 웹페이지를 스크랩하는 과정을 안내하고 자신의 프로젝트에 대한 웹 스크래핑의 잠재력을 여는 데 도움을 줄 것입니다. 자, 시작하겠습니다!
웹 스크래핑은 시간이 많이 걸리고 복잡하며 많은 코딩이 필요할 수 있습니다. 비코더용. Google 스프레드시트는 웹 스크래핑을 위한 탁월한 대안입니다. Google 시트 웹 스크래핑에는 코딩이 필요하지 않으며 웹 사이트 데이터를 분석하는 다양한 방법을 제공합니다.
이 블로그에서는 Google 스프레드시트를 사용하여 웹 페이지를 쉽게 스크랩하는 방법을 알아봅니다. 시작하겠습니다!
웹 스크래핑에 Google 스프레드시트를 사용하는 이유는 무엇인가요?
Google 스프레드시트가 웹 스크래핑을 위한 훌륭한 도구인 데에는 몇 가지 이유가 있습니다.
- Google 스프레드시트는 사용자 친화적이고 친숙한 인터페이스를 가지고 있습니다.
- 프로그래밍 언어 지식이 필요하지 않습니다.
- Google 스프레드시트는 어디에서나 액세스할 수 있습니다.
- Google 스프레드시트는 무료로 제공되므로 개인 및 중소기업에 적합합니다.
- Google은 다른 도구 모음 도구와 쉽게 통합됩니다.
- 매크로 또는 스크립트를 사용하여 웹 스크래핑 작업을 자동화할 수 있습니다.
- Google 시트 공식을 사용하여 스크랩한 데이터를 쉽게 분석할 수 있습니다.
단 한 번의 클릭으로 모든 웹페이지에서 텍스트를 추출합니다. 나노넷으로 이동 웹 사이트 스크레이퍼, URL을 추가하고 "스크랩"을 클릭하고 웹 페이지 텍스트를 파일로 즉시 다운로드하십시오. 지금 무료로 사용해 보세요.
Google Sheets Web Scraping에 사용할 기능은 무엇입니까?
다음은 Google 스프레드시트를 사용하여 웹페이지를 스크랩해야 할 때 사용할 수 있는 몇 가지 기능입니다.
가져오기HTML:
HTML 페이지에서 테이블과 목록을 추출합니다.
=IMPORTHTML(url, query, index)- url: 스크랩하려는 웹페이지의 링크입니다.
- 쿼리: 데이터 유형 – 테이블, 목록
- 인덱스: 특정 테이블을 추출하려는 경우 이것을 사용할 수 있습니다.
예:
=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)","table",1)가져오기XML:
XML 페이지에서 데이터를 추출합니다.
=IMPORTXML(url, xpath_query)- url: 스크랩하려는 웹페이지의 링크입니다.
- xpath_query: 추출하려는 데이터를 식별하는 XPath 표현식
예:
=IMPORTXML("https://www.w3schools.com/xml/note.xml", "//note/to")수입 데이터:
CSV 및 TSV 파일에서 데이터를 추출합니다.
=IMPORTDATA(url)- url: 데이터를 추출하려는 CSV 또는 TSV 파일의 URL
예:
=IMPORTDATA("https://www.stats.govt.nz/assets/Uploads/Annual-enterprise-survey/Annual-enterprise-survey-2021-financial-year-provisional/Download-data/annual-enterprise-survey-2021-financial-year-provisional-size-bands.csv")정규 추출:
이 함수는 정규식 패턴과 일치하는 데이터를 추출할 수 있습니다.
=REGEXEXTRACT(text, regular_expression)- 텍스트: 패턴을 검색하려는 텍스트
- regular_expression: 일치시키려는 패턴
예:
=REGEXEXTRACT("1 pound = $1.40", "$d+.d+")참고: 이러한 기능은 모든 웹사이트에서 작동하지 않을 수 있습니다. 웹 사이트의 레이아웃에 따라 다릅니다. 더 많은 데이터가 필요한 경우 Python 및 Java를 사용하는 웹 스크래핑 자습서에 의존하거나 Nanonets와 같은 웹 사이트-텍스트 도구를 사용할 수 있습니다.
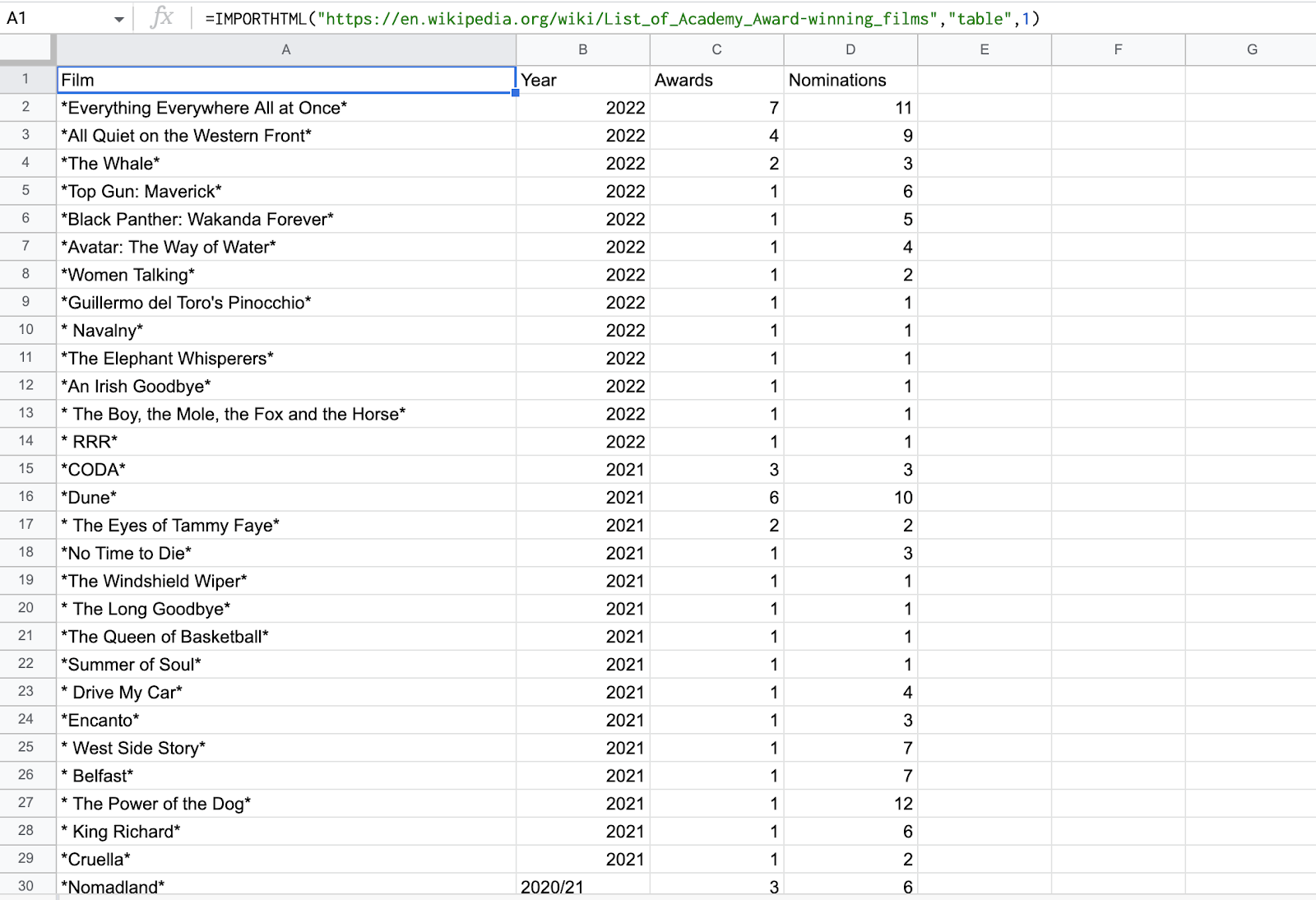
HTML 표를 Google Sheets로 추출해 봅시다. 우리는 테이블에서 긁어 내려고 노력할 것입니다 아카데미 수상 영화 목록 Wikipedia 페이지.
- Google 스프레드시트를 엽니다.
- 새 셀에 =IMPORTHTML(url, query, index)를 입력합니다.
1. 우리의 코드는,
=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_Academy_Award-winning_films","table",1) =IMPORTHTML("https://en.wikipedia.org/wiki/List_of_Academy_Award-winning_films","표",1)
Wikipedia 페이지의 첫 번째 테이블을 스크랩합니다.
3. 결과 확인
Google 스프레드시트 웹 스크래핑을 사용하여 데이터를 스크랩하는 방법은 무엇입니까?
Google 스프레드시트를 사용하여 제목, 설명, H1 등을 스크랩하는 방법을 살펴보겠습니다. Google 스프레드시트로 H1 스크래핑을 시작하기 위해 이 특정 작업에 IMPORTXML 기능을 사용합니다. 나노넷 페이지. 단계는 다음과 같습니다.
- 신규 또는 기존 Google 시트를 엽니다.
- 셀에 다음 수식을 입력합니다.
=IMPORTXML(“https://nanonets.com/image-to-text”, “//h1/text()”)- H1 태그를 추출하려면 다음 XPath 표현식을 사용하십시오. //h1/text()
- 제목 태그를 추출하려면 다음 XPath 표현식을 사용하십시오. //title/text()
- 메타 설명 태그를 추출하려면 다음 XPath 표현식을 사용하십시오. //meta[@name='description']/@content
- 모든 페이지 링크를 추출하려면 다음 XPath 표현식을 사용하십시오. //a/@href
Enter 키를 누르면 Google 스프레드시트가 자동으로 데이터를 스크랩하여 선택한 셀에 표시합니다.
그런 다음 수식을 다른 셀에 복사하여 동일하거나 다른 웹 페이지에서 추가 데이터를 스크랩할 수 있습니다.
단 한 번의 클릭으로 모든 웹페이지에서 텍스트를 추출합니다. 나노넷으로 이동 웹 사이트 스크레이퍼, URL을 추가하고 "스크랩"을 클릭하고 웹 페이지 텍스트를 파일로 즉시 다운로드하십시오. 지금 무료로 사용해 보세요.
Google Sheets Web Scraper를 사용하면 어떤 단점이 있나요?
- Google 스프레드시트에는 기능이 제한되어 있습니다. 복잡한 레이아웃의 경우 동적 콘텐츠를 처리할 수 없습니다.
- Google Sheets 웹 스크래핑 수식을 사용하여 데이터를 스크래핑할 때 데이터 불일치가 있을 수 있습니다.
- 웹 사이트에서 데이터를 스크랩할 때 실수로 민감하거나 기밀 정보를 스크랩할 수 있습니다. 특히 스크랩한 데이터가 보안되지 않은 위치에 공유되거나 저장되는 경우 개인 정보 및 보안 문제가 발생할 수 있습니다.
팁: Google Sheets Web Scraping은 메타 제목, 목록 또는 표 추출과 같은 복잡하지 않은 웹 스크래핑 작업을 위한 훌륭한 대안입니다. 복잡한 작업의 경우 웹 스크래핑 도구를 사용해야 합니다.
자주 묻는 질문
Google 스프레드시트로 웹 스크랩을 할 수 있나요?
예, Google 스프레드시트에는 IMPORTHTML, IMPORTXML, IMPORTDATA와 같은 기능이 내장되어 있습니다.
REGEXTRACT를 사용하면 웹사이트에서 Google 스프레드시트로 직접 데이터를 캡처할 수 있습니다. 그러나 기능이 제한될 수 있으며 더 복잡한 웹 스크래핑 작업에는 별도의 웹 스크래퍼를 사용하거나 사용자 지정 코드를 작성해야 할 수 있습니다.
데이터를 Google 시트에 스크랩하려면 어떻게 해야 하나요?
IMPORTHTML, IMPORTXML, IMPORTDATA 또는 REGEXTRACT와 같은 기본 제공 기능 중 하나를 사용하여 데이터를 Google 시트로 스크랩할 수 있습니다. 이러한 함수를 사용하면 웹 사이트, CSV 또는 TSV 파일에서 데이터를 추출하고 정규식 패턴을 일치시킬 수 있습니다. URL, 쿼리, 인덱스 또는 정규식 패턴을 지정하기만 하면 데이터가 스크랩되어 Google 시트에 채워집니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://nanonets.com/blog/scrape-websites-using-google-sheets-formulas/
- :이다
- 1
- 11
- 2023
- 7
- a
- Academy
- 얻기 쉬운
- 추가
- 저렴한
- All
- 대안
- 분석하다
- 및
- 어딘가에
- 있군요
- AS
- 자동화
- 자동적으로
- 수상 경력
- BE
- 된다
- 블로그
- 내장
- 사업
- by
- CAN
- 기능
- 포착
- 케이스
- 셀
- 검사
- 클릭
- 닫기
- 암호
- 코딩
- 복잡한
- 우려 사항
- 함유량
- 관습
- 데이터
- 따라
- 설명
- 다른
- 직접
- 디스플레이
- 다운로드
- 동적
- 마다
- 용이하게
- 엔터 버튼
- 특히
- 에테르 (ETH)
- 모든
- 우수한
- 현존하는
- 추출물
- 추출
- 익숙한
- 특징
- 입양 부모로서의 귀하의 적합성을 결정하기 위해 미국 이민국에
- 파일
- 영화
- 먼저,
- 수행원
- 럭셔리
- 공식
- 다행히도
- 무료
- 에
- 기능
- 기능
- 기능
- 얻을
- 구글
- 정부
- 큰
- 안내
- 핸들
- 머리
- 도움
- 여기에서 지금 확인해 보세요.
- 방법
- How To
- 그러나
- HTML
- HTTPS
- i
- 식별하다
- in
- 색인
- 개인
- 정보
- 통합
- 인터페이스
- 감다
- IT
- 자바
- 딱 하나만
- 지식
- 언어
- 레이아웃
- 레버리지
- 처럼
- 제한된
- LINK
- 모래밭
- 기울기
- 위치
- 롯
- 매크로
- 유튜브 영상을 만드는 것은
- .
- 경기
- 메타
- 수도
- 배우기
- 필요
- 필요
- 신제품
- of
- 제공
- on
- ONE
- 주문
- 기타
- 자신의
- 페이지
- 특별한
- 무늬
- 패턴
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 인구가 많은
- 가능성
- 파운드
- 힘
- 강한
- 개인 정보 보호
- 개인 정보 및 보안
- 방법
- 프로그램 작성
- 프로젝트
- 제공
- Python
- 모집
- 이유
- 정규병
- 필요
- 필요
- 리조트
- s
- 같은
- 스크 레이 핑
- 스크립트
- 검색
- 보안
- 선택된
- 민감한
- 별도의
- 몇몇의
- 공유
- 영상을
- 단순, 간단, 편리
- 간단히
- 작은
- 중소기업
- So
- 해결책
- 일부
- 구체적인
- 시작
- 통계
- 단계
- 저장
- 이러한
- 스위트
- 테이블
- 테이블 추출
- TAG
- 작업
- 그
- XNUMXD덴탈의
- Bowman의
- 을 통하여
- 시간이 많이 걸리는
- Title
- 제목들
- 에
- 수단
- 검색을
- 자습서
- 잠금을 해제
- 무담보의
- URL
- 사용
- 사용하기 쉬운
- 종류
- 방법
- 웹
- 웹 스크래핑
- 웹 사이트
- 웹 사이트
- 위키 백과
- 의지
- 과
- 없이
- 작업
- 쓰다
- 쓰기
- XML
- 너의
- 제퍼 넷