OpenAI ChatGPT가 24시간 뉴스 주기에서 모든 산소를 빨아들이는 동안 Google은 비디오, 이미지 및 텍스트 입력이 제공될 때 비디오를 생성할 수 있는 새로운 AI 모델을 조용히 공개했습니다. 새로운 Google Dreamix AI 비디오 편집기는 이제 생성된 비디오를 현실에 더 가깝게 만듭니다.
GitHub에 게시된 연구에 따르면 Dreamix는 비디오 및 텍스트 프롬프트를 기반으로 비디오를 편집합니다. 결과 비디오는 색상, 자세, 개체 크기 및 카메라 포즈에 대한 충실도를 유지하여 시간적으로 일관된 비디오를 생성합니다. 현재 Dreamix는 프롬프트만으로 비디오를 생성할 수 없지만 기존 자료를 가져와 텍스트 프롬프트를 사용하여 비디오를 수정할 수 있습니다.
Google은 DALL-E2 또는 오픈 소스 Stable Diffusion과 같은 이미지 AI에서 볼 수 있는 대부분의 비디오 이미지 편집에 성공적으로 적용된 접근 방식인 Dreamix용 비디오 확산 모델을 사용합니다.
이 접근 방식은 입력 비디오를 크게 줄이고 인공 노이즈를 추가한 다음 비디오 확산 모델에서 처리한 다음 텍스트 프롬프트를 사용하여 원본 비디오의 일부 속성을 유지하고 다른 속성을 다시 렌더링하는 새 비디오를 생성하는 방법을 포함합니다. 텍스트 입력에.
비디오 확산 모델은 비디오 작업의 새로운 시대를 열 수 있는 유망한 미래를 제공합니다.

예를 들어, 아래 비디오에서 Dreamix는 "곰이 춤을 추고 경쾌한 음악에 맞춰 점프하며 몸 전체를 움직입니다."라는 프롬프트에 따라 먹는 원숭이(왼쪽)를 춤추는 곰(오른쪽)으로 바꿉니다.
아래의 또 다른 예에서 Dreamix는 단일 사진을 템플릿으로 사용하고(이미지에서 비디오로) 개체는 프롬프트를 통해 비디오에서 애니메이션으로 표시됩니다. 새로운 장면이나 후속 타임랩스 녹화에서도 카메라 움직임이 가능합니다.
또 다른 예에서 Dreamix는 물웅덩이(왼쪽)에 있는 오랑우탄을 아름다운 욕실에서 목욕하는 주황색 머리카락을 가진 오랑우탄으로 바꿉니다.
“확산 모델은 이미지 편집에 성공적으로 적용되었지만 비디오 편집에는 거의 적용되지 않았습니다. 일반 동영상의 모션 및 외형 편집을 텍스트 기반으로 수행할 수 있는 최초의 확산 기반 방식을 제시합니다.”
Google 연구 논문에 따르면 Dreamix는 비디오 확산 모델을 사용하여 추론 시간에 원본 비디오의 저해상도 시공간 정보를 안내 텍스트 프롬프트에 맞춰 합성한 새로운 고해상도 정보와 결합합니다.”
구글은 "원본 비디오에 대한 높은 충실도를 얻으려면 고해상도 정보의 일부를 유지해야 하기 때문에 원본 비디오에 모델을 미세 조정하는 예비 단계를 추가하여 충실도를 크게 높인다"고 말했습니다.
아래는 Dreamix 작동 방식에 대한 비디오 개요입니다.
[포함 된 콘텐츠]
Dreamix 비디오 확산 모델의 작동 방식
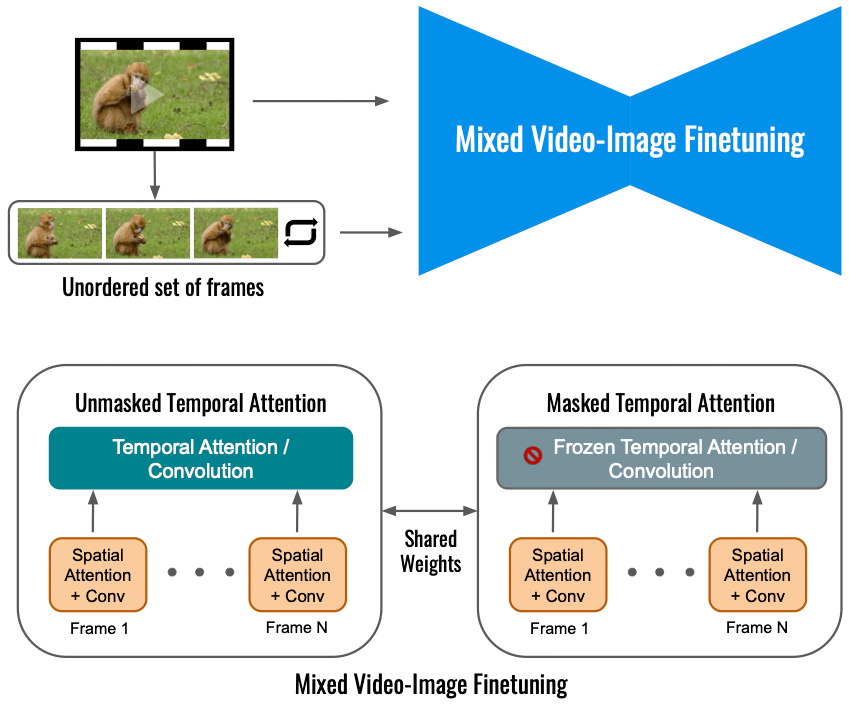
Google에 따르면 입력 비디오에서만 Dreamix의 비디오 확산 모델을 미세 조정하면 모션 변경 범위가 제한됩니다. 대신, 원래 대물렌즈(왼쪽 아래) 외에 정렬되지 않은 프레임 세트에서도 미세 조정되는 혼합 대물렌즈를 사용합니다. 이것은 "마스킹된 임시 주의"를 사용하여 수행되어 임시 주의 및 컨볼루션이 미세 조정되는 것을 방지합니다(오른쪽 아래). 이를 통해 정적 비디오에 모션을 추가할 수 있습니다.
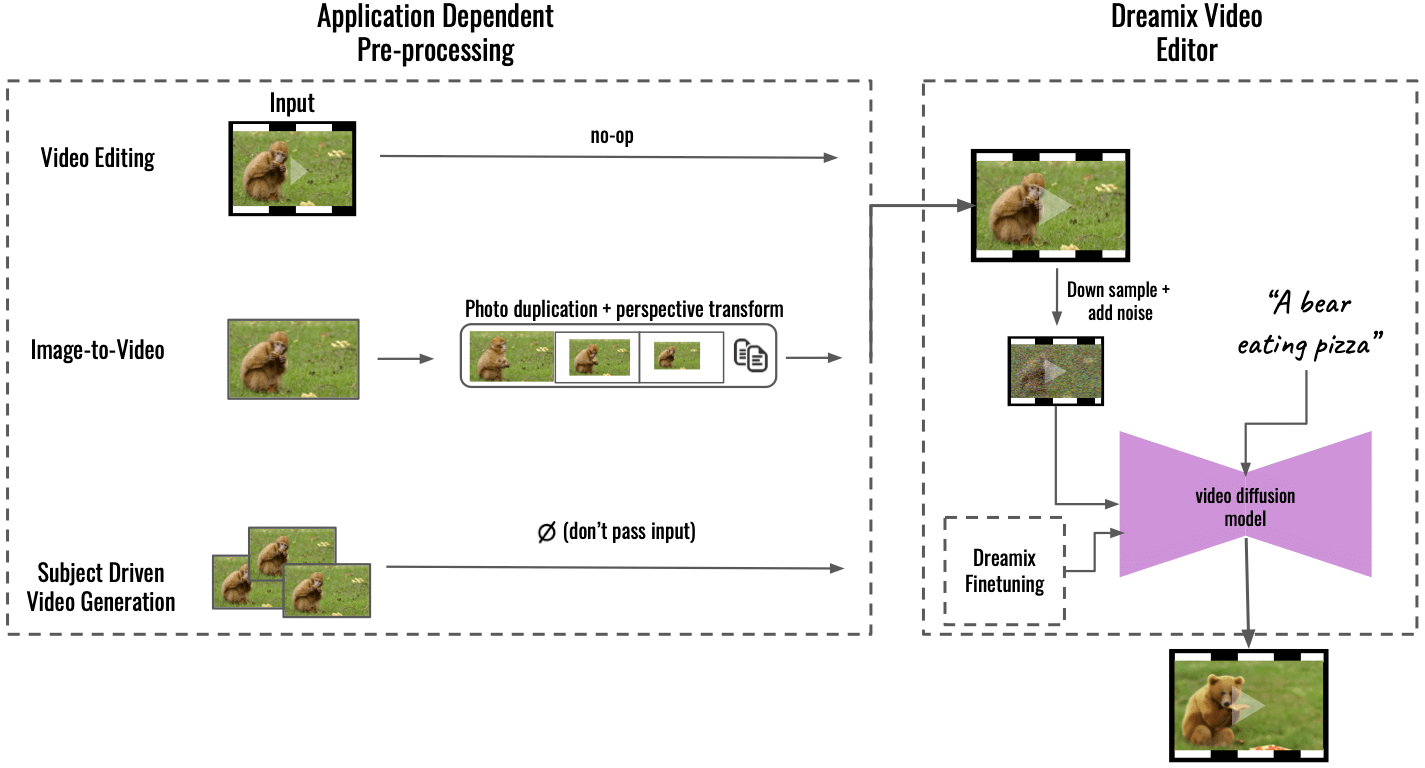
“우리의 방법은 입력 콘텐츠를 균일한 비디오 형식으로 변환하는 애플리케이션 종속 사전 처리(왼쪽)를 통해 여러 애플리케이션을 지원합니다. 이미지 대 비디오의 경우 입력 이미지가 복제되고 원근 변환을 사용하여 변환되어 약간의 카메라 움직임이 있는 대략적인 비디오를 합성합니다. 피사체 중심의 비디오 생성의 경우 입력이 생략됩니다. 미세 조정만으로 충실도를 관리할 수 있습니다. 그런 다음 일반 "Dreamix Video Editor"(오른쪽)를 사용하여 이 거친 비디오를 편집합니다. 먼저 다운샘플링한 다음 노이즈를 추가하여 비디오를 손상시킵니다. 그런 다음 비디오를 최종 시공간 해상도로 업스케일링하는 미세 조정된 텍스트 안내 비디오 확산 모델을 적용합니다.”라고 Dream은 에 썼습니다. GitHub의.
아래 연구 논문을 읽을 수 있습니다.
구글 드리믹스- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://techstartups.com/2023/02/10/google-launches-ai-powered-video-editor-dreamix-to-create-edit-videos-and-animate-images/
- a
- 할 수 있는
- 에 따르면
- AI
- 인공 지능 비디오
- AI 기반
- All
- 수
- 혼자
- 과
- 다른
- 어플리케이션
- 적용된
- 신청
- 접근
- 인조의
- 주의
- 기반으로
- 곰
- 아름다운
- 때문에
- 존재
- 이하
- 몸
- 증폭
- 바닥
- 돋보이게
- 카메라
- 한
- 이전 단계로 돌아가기
- ChatGPT
- 자세히
- 색
- 결합
- 일관된
- 함유량
- 만들기
- 주기
- 댄스
- 방송
- 꿈
- 편집자
- 임베디드
- 대
- 예
- 현존하는
- 를
- 충실도
- 최후의
- 먼저,
- 다음에
- 체재
- 에
- 미래
- 일반
- 생성
- 생성
- 세대
- 지프
- GitHub의
- 주어진
- 구글
- 헤어
- 무겁게
- 높은 해상도
- 방법
- 그러나
- HTTPS
- 영상
- 형상
- in
- 정보
- 입력
- 를 받아야 하는 미국 여행자
- IT
- 시작
- 제한
- 유지
- 자료
- 최대
- 방법
- 혼합 된
- 모델
- 모델
- 수정
- 순간
- 가장
- 운동
- 이동
- 움직이는
- 여러
- 음악
- 신제품
- news
- 노이즈
- 대상
- 목표
- 제공
- 오픈 소스
- OpenAI
- 주황색
- 실물
- 기타
- 개요
- 산소
- 서
- 수행
- 관점
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 풀
- 가능한
- 제시
- 방지
- 처리
- 장래가 촉망되는
- 속성
- 출판
- 조용히
- 읽기
- 현실
- 방송
- 감소
- 필요
- 연구
- 분해능
- 결과
- 유지
- 말했다
- 장면
- 세트
- 크게
- 단일
- 크기
- So
- 일부
- 안정된
- 단계
- 후속의
- 성공적으로
- 이러한
- 지원
- 받아
- 이 템플릿
- XNUMXD덴탈의
- 시간
- 에
- 변환
- 변환
- 공개
- 사용
- 를 통해
- Video
- 동영상
- 물
- 어느
- 일하는
- 일
- 유튜브
- 제퍼 넷











