이미지 출처 : Pexels
지난 겨울, 나는 'BQML을 사용하여 더욱 예측 가능한 시계열 모델'에서 GDG 데브페스트 타슈켄트 2022 우즈베키스탄의 수도 타슈켄트에서.
프레젠테이션에 사용한 DevFest 이후 일부 자료와 코드를 공유하려고 했는데 시간이 지나고 일부 내용과 겹치는 새로운 기능이 BQML에 출시되었습니다.
따라서 대신 새로운 기능과 여전히 유효한 일부 기능에 대해 간략하게 언급하겠습니다.
시계열 데이터 많은 조직에서 다양한 목적으로 사용되며, 다음 사항에 유의하는 것이 중요합니다.예측 분석s'는 시간 속의 '미래'에 관한 것입니다. 시계열 예측 분석은 단기, 중기, 장기로 활용되어 왔으며, 부정확성과 위험성이 많지만 꾸준히 개선되어 왔습니다.
"예측"은 매우 유용해 보이기 때문에 시계열 데이터가 있는 경우 시계열 예측 모델을 적용하고 싶은 유혹을 느낄 수도 있습니다. 그러나 시계열 예측 모델은 일반적으로 계산 집약적이며 데이터가 많으면 계산 집약적입니다. 그래서 처리가 번거롭고 힘들고, 분석환경에 올려서 분석하는 것이
당신이 사용하는 경우 구글 빅쿼리 데이터 관리를 위해 다음을 사용할 수 있습니다. 바베큐L(BigQuery ML)을 사용하면 간단하고 쉽고 빠르게 데이터에 머신러닝 알고리즘을 적용할 수 있습니다. 많은 사람들이 BigQuery를 사용하여 많은 데이터를 처리하며, 해당 데이터 중 상당수는 시계열 데이터인 경우가 많습니다. 그리고 BQML은 시계열 모델도 지원합니다.
현재 BQML이 지원하는 시계열 모델의 기본은 자동 회귀 통합 이동 평균(ARIMA) 모델. ARIMA 모델은 기존 시계열 데이터만을 이용하여 예측하며 단기 예측 성능이 좋은 것으로 알려져 있으며, AR과 MA를 결합한 모델이므로 폭넓은 시계열 모델을 포괄할 수 있는 인기 모델입니다.
그러나 이 모델은 전체적으로 계산 집약적이며, 정규성이 있는 시계열 데이터만을 활용하기 때문에 추세나 계절성이 있는 경우에는 사용하기 어렵습니다. 그러므로, ARIMA_PLUS BQML에는 몇 가지 추가 기능이 옵션으로 포함되어 있습니다. 시계열 분해, 계절성 요인, 급등 및 급락, 계수 변경 등을 모델에 추가하거나 별도로 살펴보고 모델을 수동으로 조정할 수 있습니다. 또한 개인적으로 휴일 옵션을 자동으로 통합하여 주기를 조정할 수 있다는 사실이 마음에 듭니다. 이는 날짜 관련 정보를 수동으로 추가할 필요가 없는 플랫폼 사용의 이점 중 하나입니다.
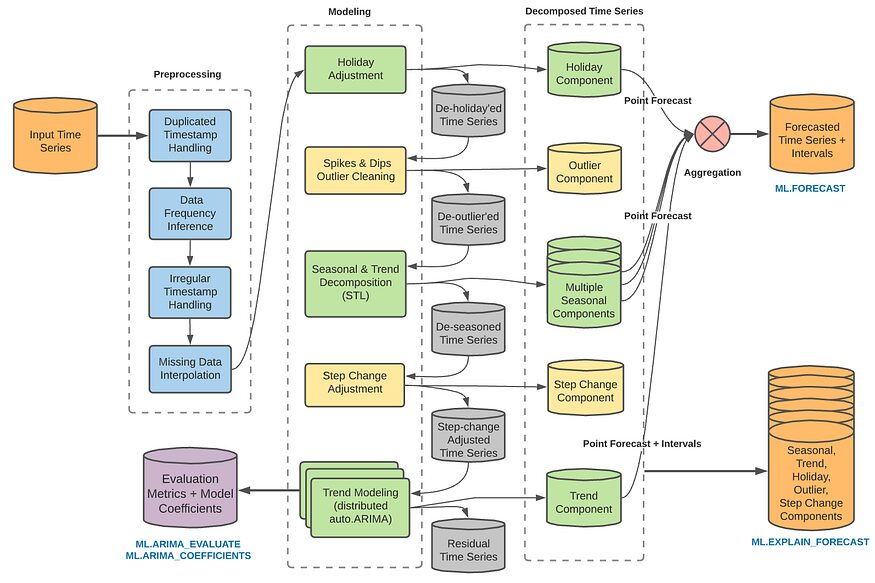
ARIMA_PLUS의 구조(에서 BQML 매뉴얼)
이것을 참조 할 수 있습니다 페이지
그러나 실제 응용 분야에서는 시계열 예측이 이만큼 간단하지 않습니다. 물론 ARIMA_PLUS를 사용하여 여러 주기를 식별하고 여러 시계열에 개입을 추가할 수 있었지만 시계열 데이터와 관련된 외부 요인이 많고 단독으로 발생하는 이벤트는 거의 없습니다. 시계열 데이터에서는 정상성을 찾기 어려울 수 있습니다.
원본 프레젠테이션에서는 예측 모델을 만들기 위해 이러한 실제 시계열 데이터를 처리하는 방법을 살펴보았습니다. 이 시계열을 분해하다, 분해된 데이터를 정리하고 Python으로 가져온 다음 이를 다른 변수와 결합하여 다변량 시계열 함수를 만들고, 인과관계를 추정하고 이를 예측 모델에 통합하고, 사건의 변화에 따라 효과가 달라지는 정도를 추정합니다.
그리고 최근 몇 달 동안, 외부 변수를 사용하여 다변량 시계열 함수를 생성하는 새로운 기능(ARIMA_PLUS_XREG, XREG 아래)는 BQML의 완전한 기능이 되었습니다..
당신은 그것에 대해 모두 읽을 수 있습니다 여기에서 지금 확인해 보세요.(2023년 XNUMX월 현재 미리보기 단계이지만 올해 말에 출시될 것으로 예상됩니다).
나는 신청한다 공식 튜토리얼 이를 기존의 일변량 시계열 모델과 비교하여 어떻게 작동하는지 확인할 수 있습니다.
단계는 튜토리얼과 동일하므로 복제하지는 않지만 여기에 제가 만든 두 가지 모델이 있습니다. 먼저 전통주를 만들었습니다. ARIMA_PLUS 모델 그리고 그 다음 XREG 동일한 데이터를 사용하지만 당시의 온도와 풍속을 추가하여 모델을 만듭니다.
# ARIMA_PLUS
# ARIMA_PLUS
CREATE OR REPLACE MODEL test_dt_us.seattle_pm25_plus_model
OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'pm25') AS
SELECT date, pm25
FROM test_dt_us.seattle_air_quality_daily
WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31')
#ARIMA_PLUS_XREG
CREATE OR REPLACE MODEL test_dt_us.seattle_pm25_xreg_model OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS_XREG', time_series_timestamp_col = 'date', time_series_data_col = 'pm25') AS
SELECT date, pm25, temperature, wind_speed
FROM test_dt_us.seattle_air_quality_daily
WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31')
이러한 여러 데이터를 사용하는 모델은 다음과 같습니다.
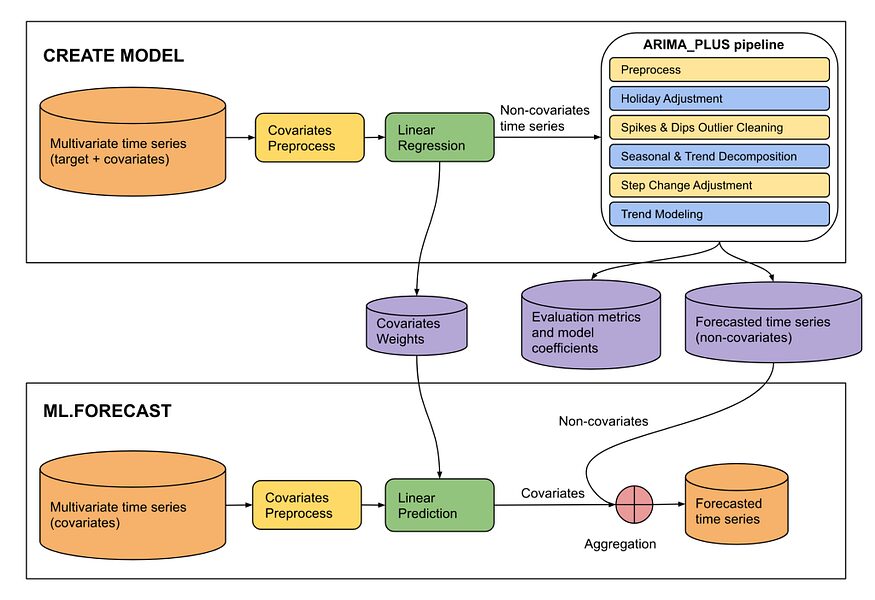
구조 ARIMA_PLUS_XREG(에서 BQML 매뉴얼)
ML.Evaluate를 사용하여 두 모델을 비교합니다.
SELECT * FROM ML.EVALUATE ( MODEL test_dt_us.seattle_pm25_plus_model, ( SELECT date, pm25 FROM test_dt_us.seattle_air_quality_daily WHERE date > DATE('2020-12-31') ))
SELECT * FROM ML.EVALUATE ( MODEL test_dt_us.seattle_pm25_xreg_model, ( SELECT date, pm25, temperature, wind_speed FROM test_dt_us.seattle_air_quality_daily WHERE date > DATE('2020-12-31') ), STRUCT( TRUE AS perform_aggregation, 30 AS horizon))
결과는 아래와 같습니다.
ARIMA_PLUS

ARIMA_PLUS_XREG

당신은 볼 수 있습니다 XREG 모델은 MAE, MSE 및 MAPE와 같은 기본 성능 지표에서 앞서 있습니다. (물론 이것이 완벽한 해결책은 아니지만, 데이터 의존적, 또 다른 유용한 도구가 있다고 말할 수 있습니다.)
다변량 시계열 분석은 많은 경우에 꼭 필요한 옵션이지만 여러 가지 이유로 적용하기 어려운 경우가 많습니다. 이제 그 이유가 데이터와 분석 단계에 있다면 이를 사용할 수 있습니다. 이에 대한 좋은 옵션이 있는 것 같으므로 이에 대해 알아두는 것이 좋으며 많은 경우에 유용할 수 있기를 바랍니다.
권정민 기계 학습 모델과 데이터 마이닝을 활용한 실무 경험이 10년 이상인 프리랜서 선임 데이터 과학자입니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 자동차 / EV, 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- BlockOffsets. 환경 오프셋 소유권 현대화. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/2023/07/multivariate-timeseries-prediction-bqml.html?utm_source=rss&utm_medium=rss&utm_campaign=multivariate-time-series-prediction-with-bqml
- :있다
- :이다
- :아니
- :어디
- $UP
- 2023
- 30
- a
- 할 수 있는
- 소개
- IT에 대해
- 더하다
- 첨가
- 추가
- 후
- 앞으로
- 알고리즘
- All
- 또한
- an
- 분석
- 분석
- 분석하다
- 및
- 다른
- 어플리케이션
- 신청
- AR
- 있군요
- AS
- At
- 자동적으로
- 가능
- 평균
- 기본
- 기초
- BE
- 가
- 된
- 이하
- 혜택
- 사이에
- 큰 쿼리
- 간단히
- 비자 면제 프로그램에 해당하는 국가의 시민권을 가지고 있지만
- by
- CAN
- 자본
- 가지 경우
- 변경
- 암호
- 결합
- 제공
- 커뮤니티
- 비교
- 함유량
- 코스
- 엄호
- 만들
- 만든
- 만들기
- 현재
- 주기
- 데이터
- 데이터 관리
- 데이터 마이닝
- 데이터 과학자
- 날짜
- 날짜
- 거래
- 도
- 어려운
- 하지 않습니다
- 두
- 쉽게
- 효과
- 환경
- 견적
- 평가
- 이벤트
- 현존하는
- 경험
- 외부
- 사실
- 요인
- FAST
- 특색
- 특징
- 를
- Find
- 먼저,
- 럭셔리
- 자유 계약의
- 에
- 기능
- 기능
- Go
- 가는
- 좋은
- 구글
- 손 -에
- 발생
- 하드
- 있다
- 여기에서 지금 확인해 보세요.
- 휴일
- 희망
- 수평선
- 방법
- How To
- HTTPS
- i
- 악
- 확인
- if
- import
- 중대한
- 개선
- in
- 포함
- 통합
- 통합
- 정보
- 를 받아야 하는 미국 여행자
- 통합 된
- 으로
- 격리
- IT
- JPG
- 7월
- 다만
- 너 겟츠
- 알아
- 알려진
- 성
- 후에
- 배우기
- 레버리지
- 처럼
- 링크드인
- 하중
- 긴
- 보기
- 보고
- 봐라.
- 롯
- 기계
- 기계 학습
- 유튜브 영상을 만드는 것은
- 구축
- 수동으로
- .
- 자료
- 매질
- 통계
- 수도
- 채굴
- ML
- 모델
- 모델
- 개월
- 배우기
- 움직이는
- media móvil
- 많이 필요한
- 여러
- 신제품
- 새로운 기능
- 새로운 기능
- 지금
- of
- 공무원
- 자주
- on
- ONE
- 만
- 선택권
- 옵션
- or
- 조직
- 실물
- 기타
- 전체
- 합격
- 사람들
- 완전한
- 성능
- 몸소
- 플랫폼
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 인기 문서
- 예측 가능
- 예측
- 예측 분석
- 예측
- 프레젠테이션
- 시사
- 방법
- 목적
- Python
- 범위
- 읽기
- 현실 세계
- 이유
- 관련
- 출시
- 교체
- 필요
- 위험
- 같은
- 라고
- 과학자
- 참조
- 것
- 연장자
- 연속
- 몇몇의
- 공유
- 짧은
- 단기간의
- 단순, 간단, 편리
- 이후
- So
- 해결책
- 일부
- 무언가
- 속도
- 스파이크
- 단계
- 아직도
- 이러한
- 지원
- 지원
- 기간
- 그
- XNUMXD덴탈의
- 수도
- 그들
- 그때
- 그곳에.
- 따라서
- Bowman의
- 일
- 이
- 올해
- 을 통하여
- 시간
- 시계열
- 에
- 수단
- 전통적인
- 트렌드
- 참된
- 지도 시간
- 두
- 사용
- 익숙한
- 사용
- 사용
- 보통
- 이용하다
- 우즈베키스탄
- 종류
- 여러
- 대단히
- 였다
- 방법..
- we
- 언제
- 어느
- 동안
- 넓은
- 넓은 범위
- 위키 백과
- 의지
- 바람
- 겨울
- 과
- 일
- 겠지
- year
- 년
- 당신
- 너의
- 제퍼 넷








