와 아마존 EMR 6.15, 우리는 출시했습니다 AWS Lake 형성 Apache Hudi, Apache Iceberg 및 Delta Lake를 포함한 OTF(Open Table Formats)에 대한 FGAC(세분화된 액세스 제어) 기반입니다. 이를 통해 보안 및 거버넌스를 단순화할 수 있습니다. 트랜잭션 데이터 레이크 Apache Spark 작업에 테이블, 열, 행 수준 권한에 대한 액세스 제어를 제공합니다. 많은 대기업은 통찰력을 얻고 의사 결정을 개선하기 위해 트랜잭션 데이터 레이크를 사용하려고 합니다. FGAC용 Lake Formation과 통합된 Amazon EMR을 사용하여 레이크 하우스 아키텍처를 구축할 수 있습니다. 이러한 서비스 조합을 사용하면 안전하고 통제된 액세스를 보장하면서 트랜잭션 데이터 레이크에 대한 데이터 분석을 수행할 수 있습니다.
Amazon EMR 레코드 서버 구성 요소는 테이블, 열, 행, 셀 및 중첩 속성 수준 데이터 필터링 기능을 지원합니다. 읽기(시간 이동 및 증분 쿼리 포함) 및 쓰기 작업(INSERT와 같은 DML 문에서) 모두에 대해 Hive, Apache Hudi, Apache Iceberg 및 Delta Lake 형식으로 지원을 확장합니다. 또한 Amazon EMR 버전 6.15에서는 클러스터 내 Spark 기록 서버, Yarn 타임라인 서버 및 Yarn Resource Manager UI와 같은 애플리케이션 웹 인터페이스에 대한 액세스 제어 보호 기능을 도입했습니다.
이 게시물에서는 FGAC를 구현하는 방법을 보여줍니다. 아파치 후디 Lake Formation과 통합된 Amazon EMR을 사용하는 테이블.
거래 데이터 레이크 사용 사례
Amazon EMR 고객은 데이터 레이크에서 ACID 트랜잭션 및 시간 이동 요구 사항을 지원하기 위해 Open Table Format을 사용하는 경우가 많습니다. 기록 버전을 보존함으로써 데이터 레이크 시간 이동은 감사 및 규정 준수, 데이터 복구 및 롤백, 재현 가능한 분석, 다양한 시점의 데이터 탐색과 같은 이점을 제공합니다.
또 다른 인기 있는 트랜잭션 데이터 레이크 사용 사례는 증분 쿼리입니다. 증분 쿼리는 마지막 쿼리 이후 데이터 레이크 내에서 새로운 데이터나 업데이트된 데이터만 처리하고 분석하는 데 초점을 맞춘 쿼리 전략을 의미합니다. 증분 쿼리의 핵심 아이디어는 메타데이터 또는 변경 내용 추적 메커니즘을 사용하여 마지막 쿼리 이후 새 데이터 또는 수정된 데이터를 식별하는 것입니다. 이러한 변경 사항을 식별함으로써 쿼리 엔진은 관련 데이터만 처리하도록 쿼리를 최적화하여 처리 시간과 리소스 요구 사항을 크게 줄일 수 있습니다.
솔루션 개요
이 게시물에서는 Amazon EMR을 사용하여 Apache Hudi 테이블에 FGAC를 구현하는 방법을 보여줍니다. 아마존 엘라스틱 컴퓨트 클라우드 (Amazon EC2)가 Lake Formation과 통합되었습니다. Apache Hudi는 증분 데이터 처리와 데이터 파이프라인 개발을 크게 단순화하는 오픈 소스 트랜잭션 데이터 레이크 프레임워크입니다. 이 새로운 FGAC 기능은 모든 OTF를 지원합니다. 여기에서 Hudi를 시연하는 것 외에도 다른 블로그를 통해 다른 OTF 테이블에 대한 후속 조치를 취할 것입니다. 우리는 사용 노트북 in 아마존 세이지 메이커 스튜디오 EMR 클러스터를 통해 다양한 사용자 액세스 권한을 통해 Hudi 데이터를 읽고 쓸 수 있습니다. 이는 실제 데이터 액세스 시나리오를 반영합니다. 예를 들어 엔지니어링 사용자가 데이터 플랫폼의 문제를 해결하기 위해 전체 데이터 액세스가 필요한 반면, 데이터 분석가는 개인 식별 정보(PII)가 포함되지 않은 해당 데이터의 하위 집합에만 액세스하면 될 수 있습니다. ). 다음을 통해 Lake Formation과 통합 Amazon EMR 런타임 역할 더욱이 데이터 보안 상태를 개선하고 Amazon EMR 워크로드에 대한 데이터 제어 관리를 단순화할 수 있습니다. 이 솔루션은 데이터 액세스를 위한 안전하고 통제된 환경을 보장하여 조직 내 다양한 사용자와 역할의 다양한 요구 사항과 보안 요구 사항을 충족합니다.
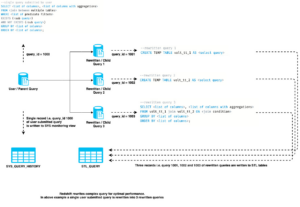
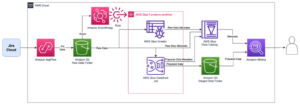
다음 다이어그램은 솔루션 아키텍처를 보여줍니다.
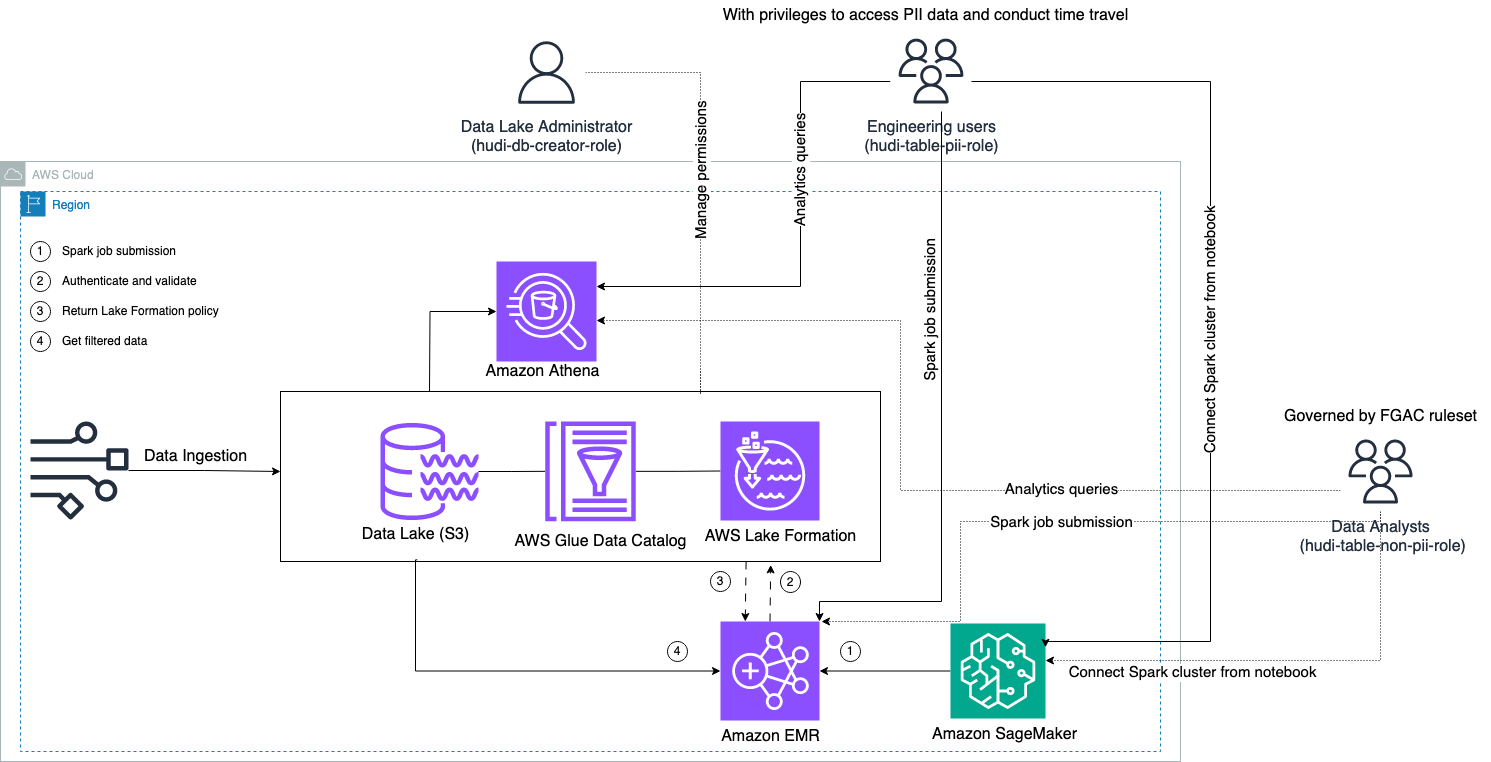
우리는 Hudi 데이터 세트를 업데이트(업데이트 및 삽입)하기 위해 데이터 수집 프로세스를 수행합니다. 아마존 단순 스토리지 서비스 (Amazon S3) 버킷에서 테이블 스키마를 유지하거나 업데이트합니다. AWS 접착제 데이터 카탈로그. 데이터 이동 없이 다음과 같은 다양한 AWS 서비스를 통해 Lake Formation이 관리하는 Hudi 테이블을 쿼리할 수 있습니다. 아마존 아테나, Amazon EMR 및 아마존 세이지 메이커.
사용자가 EMR 클러스터 엔드포인트(EMR Steps, Livy, EMR Studio 및 SageMaker)를 통해 Spark 작업을 제출하면 Lake Formation은 해당 권한을 검증하고 EMR 클러스터에 PII 데이터와 같은 민감한 데이터를 필터링하도록 지시합니다.
이 솔루션에는 Hudi 데이터에 액세스할 수 있는 다양한 수준의 권한을 가진 세 가지 유형의 사용자가 있습니다.
- hudi-db-창조자-역할 – 데이터베이스 객체 생성, 수정, 삭제 등 DDL 작업을 수행할 수 있는 권한을 가진 데이터 레이크 관리자가 사용합니다. 행 수준 및 열 수준 데이터 액세스 제어를 위해 Lake Formation에서 데이터 필터링 규칙을 정의할 수 있습니다. 이러한 FGAC 규칙은 데이터 레이크의 보안을 보장하고 필요한 데이터 개인 정보 보호 규정을 충족합니다.
- hudi-테이블-pii-역할 – 엔지니어링 사용자가 사용합니다. 엔지니어링 사용자는 CoW(기록 시 복사) 및 MoR(읽기 시 병합) 모두에서 시간 이동 및 증분 쿼리를 수행할 수 있습니다. 또한 타임스탬프를 기반으로 PII 데이터에 액세스할 수 있는 권한도 있습니다.
- hudi-테이블-비-pii-역할 – 이는 데이터 분석가가 사용합니다. 데이터 분석가의 데이터 액세스 권한은 데이터 레이크 관리자가 제어하는 FGAC 승인 규칙에 따라 관리됩니다. 이름 및 주소와 같은 PII 데이터가 포함된 열은 표시되지 않습니다. 또한 특정 조건을 충족하지 않는 데이터 행에는 액세스할 수 없습니다. 예를 들어, 사용자는 자신의 국가에 속한 데이터 행에만 액세스할 수 있습니다.
사전 조건
이 게시물에 사용된 3개의 노트북은 다음에서 다운로드할 수 있습니다. GitHub 레포.
솔루션을 배포하기 전에 다음 사항이 있는지 확인하세요.
권한을 설정하려면 다음 단계를 완료하세요.
- 관리자 IAM 사용자로 AWS 계정에 로그인합니다.
당신이에 있는지 확인하십시오us-east-1부위.
- S3 버킷을 생성합니다.
us-east-1지역(예:emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
다음으로 Lake Formation을 활성화합니다. 기본 권한 모델 변경.
- Lake Formation 콘솔에 관리자로 로그인합니다.
- 왼쪽 메뉴에서 데이터 카탈로그 설정 아래에 행정실 탐색 창에서
- $XNUMX Million 미만 새로 생성된 데이터베이스 및 테이블에 대한 기본 권한, 선택 취소 새 데이터베이스에 대해 IAM 액세스 제어만 사용 및 새 데이터베이스의 새 테이블에 대한 IAM 액세스 제어 만 사용.
- 왼쪽 메뉴에서 찜하기.
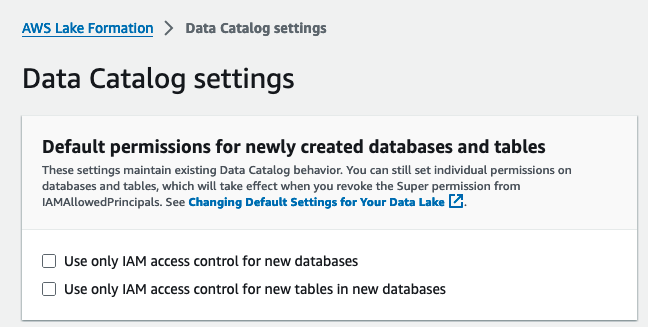
또는 기본 옵션으로 Lake Formation을 시작한 경우 생성된 리소스(데이터베이스 및 테이블)에서 IAMAllowedPrincipals를 취소해야 합니다.
마지막으로 Amazon EMR용 키 페어를 생성합니다.
- Amazon EC2 콘솔에서 다음을 선택합니다. 키 쌍 탐색 창에서
- 왼쪽 메뉴에서 키 쌍 생성.
- 럭셔리 성함, 이름을 입력합니다(예:
emr-fgac-hudi-keypair). - 왼쪽 메뉴에서 키 쌍 생성.
생성된 키 쌍(이 게시물에서는 emr-fgac-hudi-keypair.pem)은 로컬 컴퓨터에 저장됩니다.
다음으로 우리는 AWS 클라우드9 대화형 개발 환경(IDE).
- AWS Cloud9 콘솔에서 환경 탐색 창에서
- 왼쪽 메뉴에서 환경 조성.
- 럭셔리 성함¸ 이름을 입력하십시오 (예 :
emr-fgac-hudi-env). - 다른 설정은 기본값으로 유지하세요.
- 왼쪽 메뉴에서 만들기.
- IDE가 준비되면 다음을 선택합니다. 엽니다 그것을여십시오.
- AWS Cloud9 IDE에서는 입양 부모로서의 귀하의 적합성을 결정하기 위해 미국 이민국에 메뉴, 선택 로컬 파일 업로드.

- 키 쌍 파일을 업로드합니다(
emr-fgac-hudi-keypair.pem). - 더하기 기호를 선택하고 새 터미널.
- 터미널에서 다음 명령줄을 입력합니다.
예제 코드는 데모 목적으로만 개념을 증명한 것입니다. 프로덕션 시스템의 경우 신뢰할 수 있는 인증 기관(CA)을 사용하여 인증서를 발급합니다. 인용하다 Amazon EMR 암호화를 사용하여 전송 중인 데이터를 암호화하기 위한 인증서 제공 자세한 내용은.
AWS CloudFormation을 통해 솔루션 배포
우리는 AWS 클라우드 포메이션 다음 서비스 및 구성 요소를 자동으로 설정하는 템플릿:
- 데이터 레이크용 S3 버킷. 여기에는 샘플 TPC-DS 데이터세트가 포함되어 있습니다.
- 보안 구성 및 퍼블릭 DNS가 활성화된 EMR 클러스터.
- Lake Formation 세분화된 권한이 있는 EMR 런타임 IAM 역할:
- -hudi-db-creator-role – 이 역할은 Apache Hudi 데이터베이스 및 테이블을 생성하는 데 사용됩니다.
- -hudi-table-pii-role – 이 역할은 PII가 있는 열을 포함하여 Hudi 테이블의 모든 열을 쿼리할 수 있는 권한을 제공합니다.
- -hudi-table-non-pii-role – 이 역할은 Lake Formation을 기준으로 PII 열을 필터링한 Hudi 테이블을 쿼리할 수 있는 권한을 제공합니다.
- 사용자가 해당 EMR 런타임 역할을 맡을 수 있도록 하는 SageMaker Studio 실행 역할.
- VPC, 서브넷, 보안 그룹과 같은 네트워킹 리소스.
리소스를 배포하려면 다음 단계를 완료하세요.
- 왼쪽 메뉴에서 빠른 스택 생성 CloudFormation 스택을 시작합니다.
- 럭셔리 스택 이름, 스택 이름을 입력합니다(예:
rsv2-emr-hudi-blog). - 럭셔리 Ec2키페어에서 키 쌍의 이름을 입력하세요.
- 럭셔리 유휴 시간 초과, 사용하지 않을 때 클러스터 비용을 지불하지 않도록 EMR 클러스터에 대한 유휴 시간 제한을 입력합니다.
- 럭셔리 InitS3Bucket, Amazon EMR 암호화 인증서 .zip 파일을 저장하기 위해 생성한 S3 버킷 이름을 입력합니다.
- 럭셔리 S3인증서우편번호, Amazon EMR 암호화 인증서 .zip 파일의 S3 URI를 입력합니다.
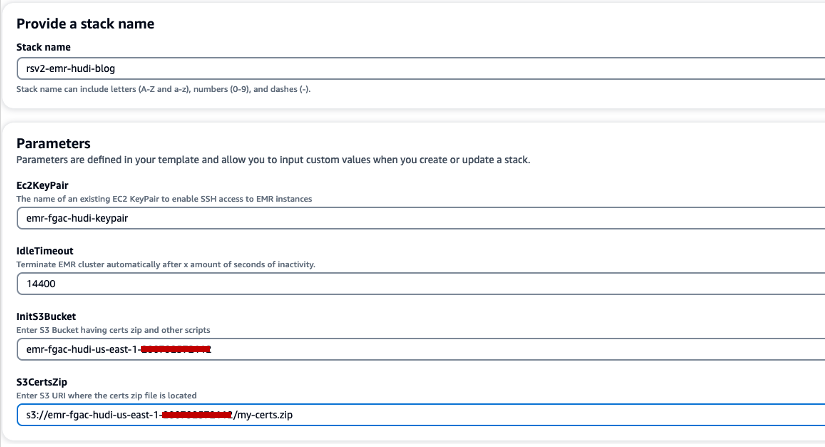
- 선택 AWS CloudFormation이 사용자 지정 이름으로 IAM 리소스를 생성 할 수 있음을 인정합니다.
- 왼쪽 메뉴에서 스택 생성.
CloudFormation 스택 배포에는 약 10분이 소요됩니다.
Amazon EMR 통합을 위한 Lake Formation 설정
Lake Formation을 설정하려면 다음 단계를 완료하세요.
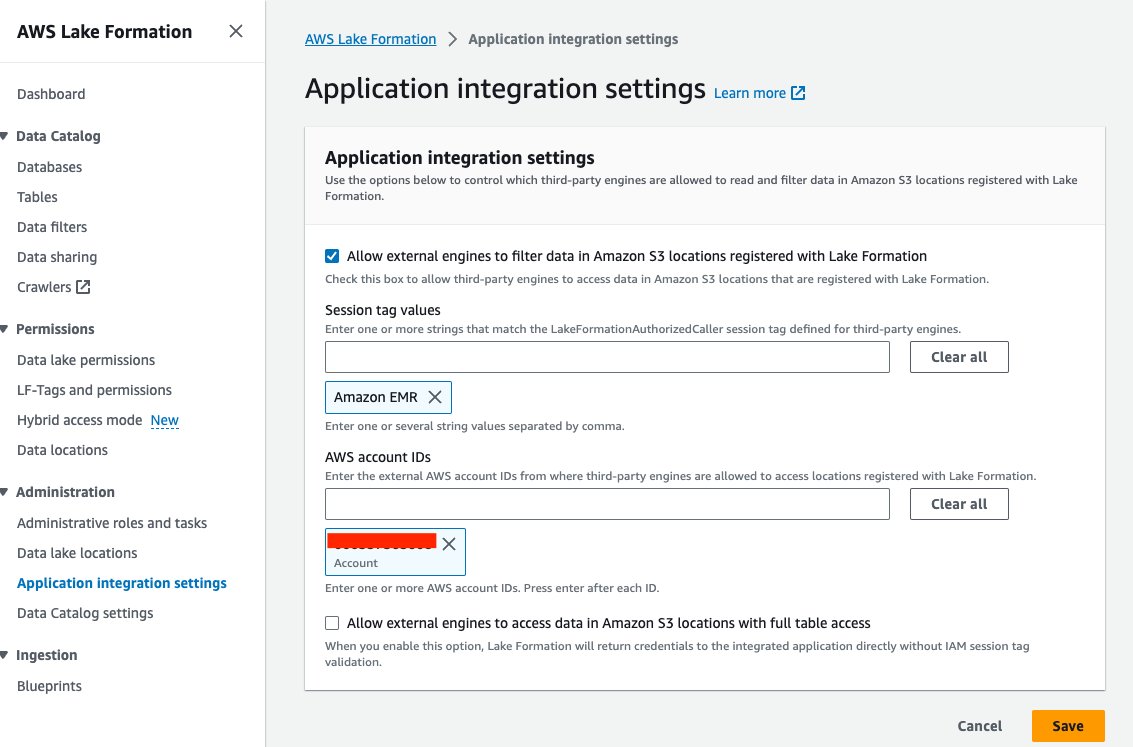
- Lake Formation 콘솔에서 애플리케이션 통합 설정 아래에 행정실 탐색 창에서
- 선택 외부 엔진이 Lake Formation에 등록된 Amazon S3 위치의 데이터를 필터링하도록 허용.
- 왼쪽 메뉴에서 아마존 EMR for 세션 태그 값.
- 다음에 대한 AWS 계정 ID를 입력하세요. AWS 계정 ID.
- 왼쪽 메뉴에서 찜하기.
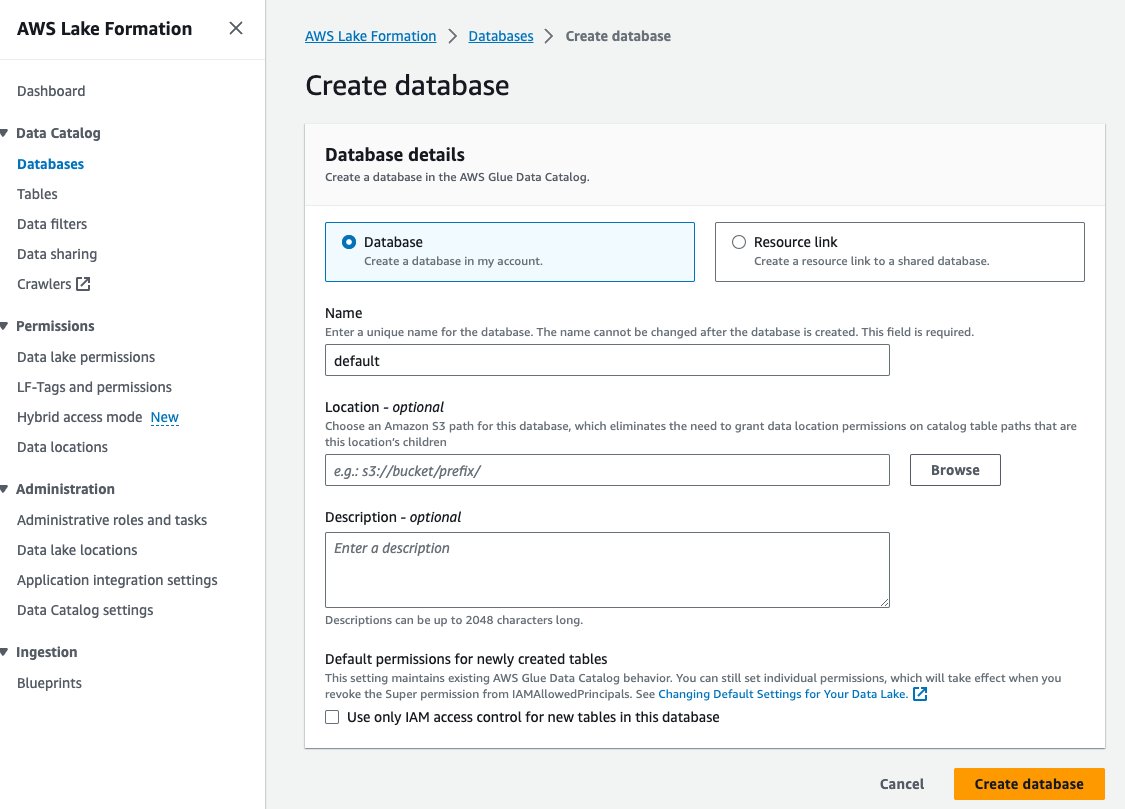
- 왼쪽 메뉴에서 데이터베이스 아래에 데이터 카탈로그 탐색 창에서
- 왼쪽 메뉴에서 데이터베이스 생성.
- 럭셔리 성함, 기본값을 입력합니다.
- 왼쪽 메뉴에서 데이터베이스 생성.
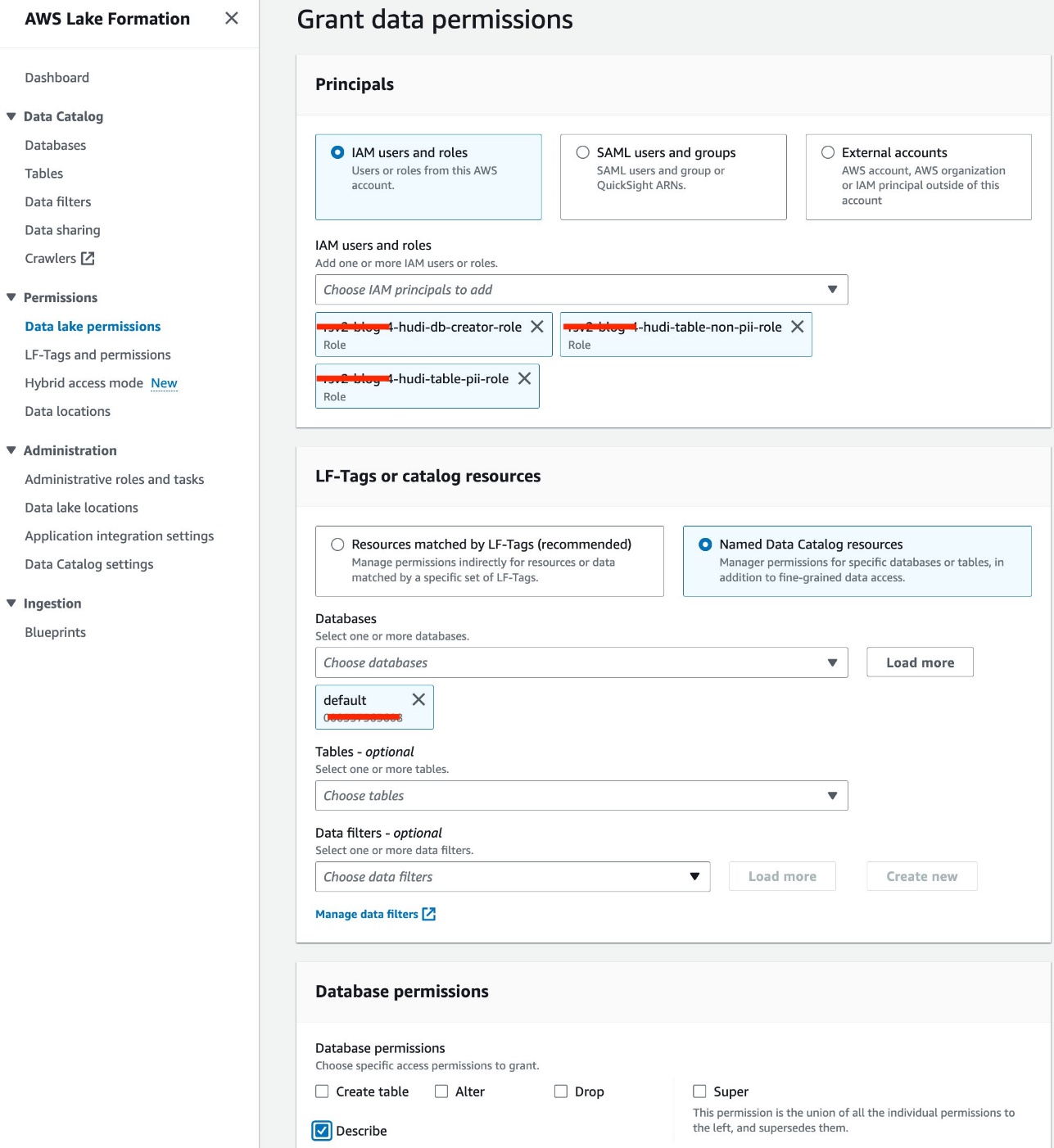
- 왼쪽 메뉴에서 데이터 레이크 권한 아래에 권한 탐색 창에서
- 왼쪽 메뉴에서 부여.
- 선택 IAM 사용자 및 역할.
- IAM 역할을 선택하세요.
- 럭셔리 데이터베이스, 기본값을 선택하세요.
- 럭셔리 데이터베이스 권한, 고르다 설명.
- 왼쪽 메뉴에서 부여.
Hudi JAR 파일을 Amazon EMR HDFS에 복사
에 Jupyter 노트북과 함께 Hudi 사용, Hudi를 사용하도록 Spark 세션을 구성할 수 있도록 Amazon EMR 로컬 디렉터리에서 HDFS 스토리지로 Hudi JAR 파일을 복사하는 작업이 포함된 EMR 클러스터에 대해 다음 단계를 완료해야 합니다.
- 인바운드 SSH 트래픽 승인 (포트 22).
- 값 복사 기본 노드 퍼블릭 DNS (예: ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) EMR 클러스터 요약 안내
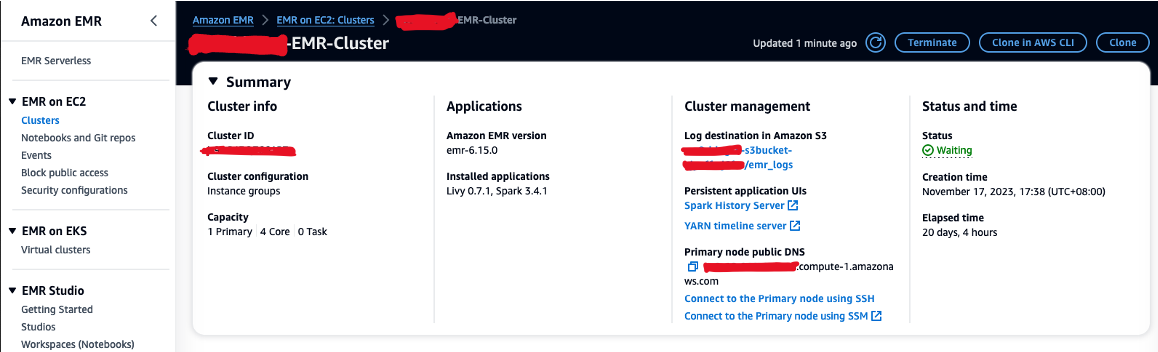
- EC9 키 페어를 생성하는 데 사용한 이전 AWS Cloud2 터미널로 돌아갑니다.
- 다음 명령을 실행하여 EMR 기본 노드에 SSH로 연결합니다. 자리 표시자를 EMR DNS 호스트 이름으로 바꿉니다.
- 다음 명령을 실행하여 Hudi JAR 파일을 HDFS에 복사합니다.
Lake Formation에서 Hudi 데이터베이스 및 테이블 생성
이제 EMR 런타임 역할로 활성화된 FGAC를 사용하여 Hudi 데이터베이스와 테이블을 생성할 준비가 되었습니다. 그만큼 EMR 런타임 역할 EMR 클러스터에 작업이나 쿼리를 제출할 때 지정할 수 있는 IAM 역할입니다.
데이터베이스 생성자 권한 부여
먼저 Lake Formation 데이터베이스 생성자 권한을 부여해 보겠습니다.<STACK-NAME>-hudi-db-creator-role:
- AWS 계정에 관리자로 로그인합니다.
- Lake Formation 콘솔에서 관리 역할 및 작업 아래에 행정실 탐색 창에서
- AWS 로그인 사용자가 데이터 레이크 관리자로 추가되었는지 확인하세요.
- . 데이터베이스 생성자 섹션 선택 부여.
- 럭셔리 IAM 사용자 및 역할선택한다.
<STACK-NAME>-hudi-db-creator-role. - 럭셔리 카탈로그 권한, 고르다 데이터베이스 생성.
- 왼쪽 메뉴에서 부여.
데이터 레이크 위치 등록
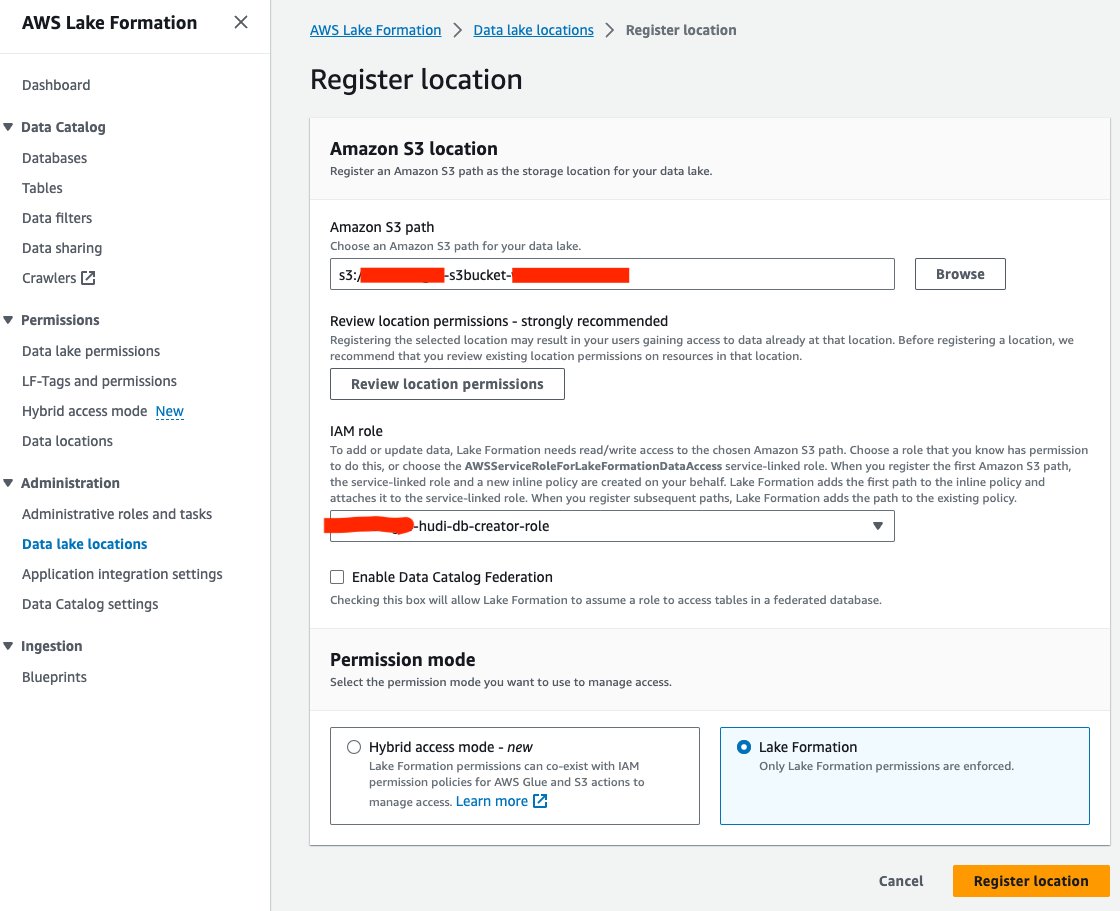
다음으로 Lake Formation에 S3 데이터 레이크 위치를 등록해 보겠습니다.
- Lake Formation 콘솔에서 데이터 레이크 위치 아래에 행정실 탐색 창에서
- 왼쪽 메뉴에서 위치 등록.
- 럭셔리 Amazon S3 경로, 선택 검색 데이터 레이크 S3 버킷을 선택합니다. (
<STACK_NAME>s3bucket-XXXXXXX)는 CloudFormation 스택에서 생성됩니다. - 럭셔리 IAM 역할선택한다.
<STACK-NAME>-hudi-db-creator-role. - 럭셔리 권한 모드, 고르다 호수 형성.
- 왼쪽 메뉴에서 위치 등록.
데이터 위치 권한 부여
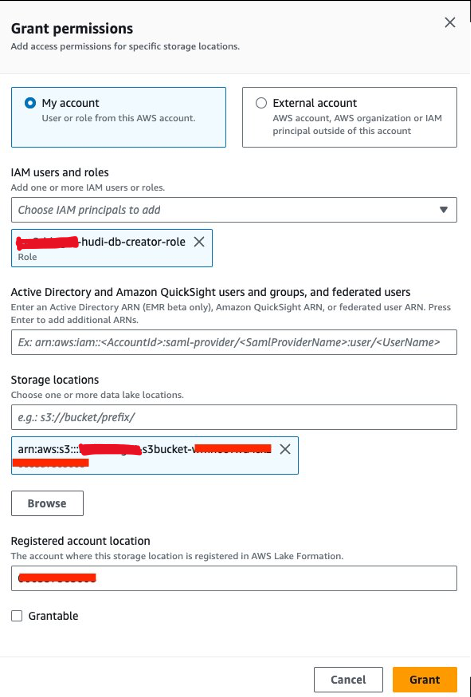
다음으로 권한을 부여해야 합니다.<STACK-NAME>-hudi-db-creator-role데이터 위치 권한:
- Lake Formation 콘솔에서 데이터 위치 아래에 권한 탐색 창에서
- 왼쪽 메뉴에서 부여.
- 럭셔리 IAM 사용자 및 역할선택한다.
<STACK-NAME>-hudi-db-creator-role. - 럭셔리 보관 장소, S3 버킷(
<STACK_NAME>-s3bucket-XXXXXXX). - 왼쪽 메뉴에서 부여.
EMR 클러스터에 연결
이제 SageMaker Studio에서 Jupyter 노트북을 사용하여 데이터베이스 생성자 EMR 런타임 역할로 EMR 클러스터에 연결해 보겠습니다.
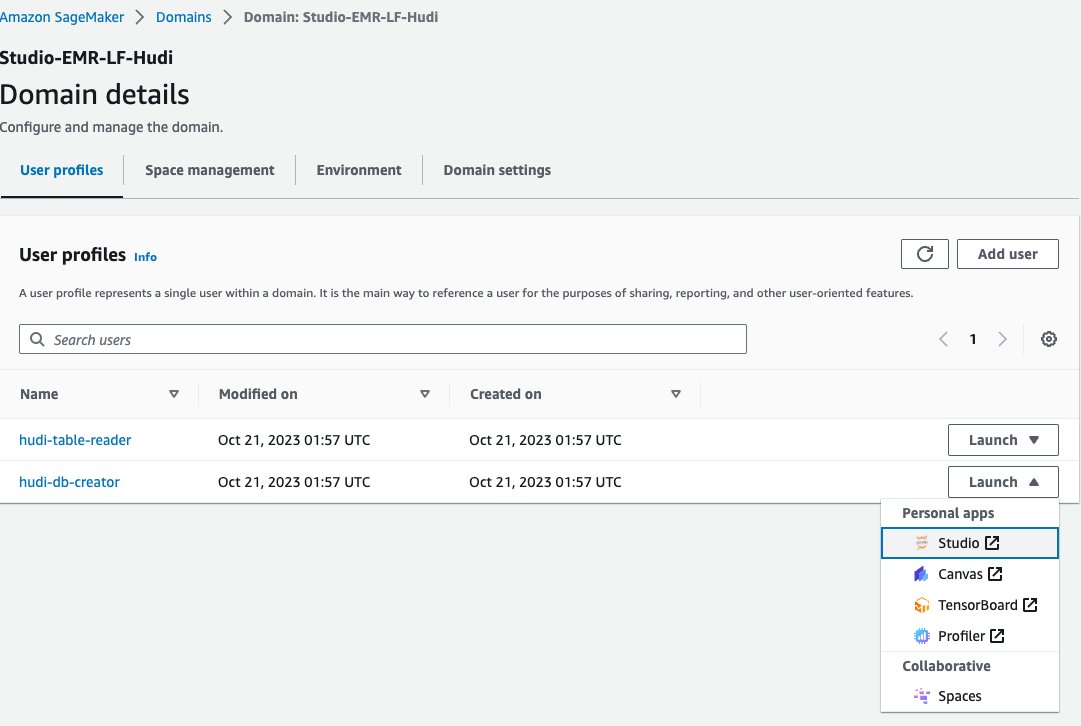
- SageMaker 콘솔에서 도메인 탐색 창에서
- 도메인을 선택하세요
<STACK-NAME>-Studio-EMR-LF-Hudi. - 에 실행 사용자 프로필 옆 메뉴
<STACK-NAME>-hudi-db-creator선택한다. Studio.
- 노트북 다운로드 rsv2-hudi-db-creator-노트북.
- 업로드 아이콘을 선택하세요.
- 다운로드한 Jupyter 노트북을 선택하고 엽니다.
- 업로드된 노트북을 엽니다.
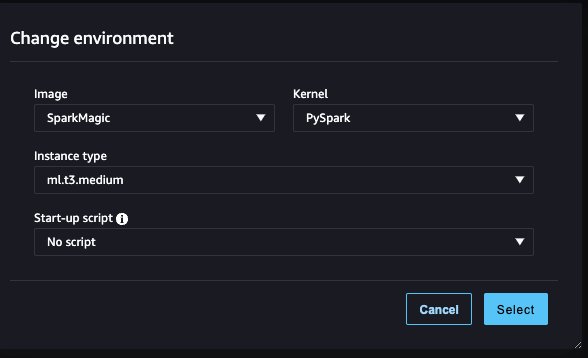
- 럭셔리 영상선택한다. 스파크매직.
- 럭셔리 핵심선택한다. 파이 스파크.
- 다른 구성은 기본값으로 두고 다음을 선택합니다. 선택.
- 왼쪽 메뉴에서 클러스터 EMR 클러스터에 연결합니다.

- EC2 클러스터에서 EMR을 선택합니다(
<STACK-NAME>-EMR-Cluster)은 CloudFormation 스택으로 생성되었습니다. - 왼쪽 메뉴에서 연결하기.
- 럭셔리 EMR 실행 역할선택한다.
<STACK-NAME>-hudi-db-creator-role. - 왼쪽 메뉴에서 연결하기.
데이터베이스 및 테이블 생성
이제 노트북의 단계에 따라 Hudi 데이터베이스와 테이블을 생성할 수 있습니다. 주요 단계는 다음과 같습니다.
- 노트북을 시작할 때 구성합니다.
“spark.sql.catalog.spark_catalog.lf.managed":"true"Spark_catalog가 Lake Formation에 의해 보호된다는 것을 Spark에 알립니다. - 다음 Spark SQL을 사용하여 Hudi 테이블을 만듭니다.
- 소스 테이블의 데이터를 Hudi 테이블에 삽입합니다.
- Hudi 테이블에 데이터를 다시 삽입합니다.
FGAC를 사용하여 Lake Formation을 통해 Hudi 테이블 쿼리
Hudi 데이터베이스와 테이블을 생성한 후에는 Lake Formation을 통해 세분화된 액세스 제어를 사용하여 테이블을 쿼리할 수 있습니다. 우리는 COW(Copy-On-Write)와 MOR(Merge-On-Read)이라는 두 가지 유형의 Hudi 테이블을 만들었습니다. COW 테이블은 데이터를 열 형식(Parquet)으로 저장하며 각 업데이트는 쓰기 중에 새 버전의 파일을 생성합니다. 즉, 업데이트할 때마다 Hudi가 전체 파일을 다시 작성하므로 리소스 집약적일 수 있지만 더 빠른 읽기 성능을 제공합니다. 반면 MOR은 특히 쓰기 또는 변경이 많은 워크로드의 경우 COW가 최적이 아닐 수 있는 경우에 도입됩니다. MOR 테이블에서는 업데이트가 있을 때마다 Hudi가 변경된 레코드에 대한 행만 기록하므로 비용이 절감되고 지연 시간이 짧은 쓰기가 가능합니다. 그러나 COW 테이블에 비해 읽기 성능이 느릴 수 있습니다.
테이블 액세스 권한 부여
우리는 IAM 역할을 사용합니다<STACK-NAME>-hudi-table-pii-rolePII 열이 포함된 Hudi COW 및 MOR을 쿼리합니다. 먼저 Lake Formation을 통해 테이블 액세스 권한을 부여합니다.
- Lake Formation 콘솔에서 데이터 레이크 권한 아래에 권한 탐색 창에서
- 왼쪽 메뉴에서 부여.
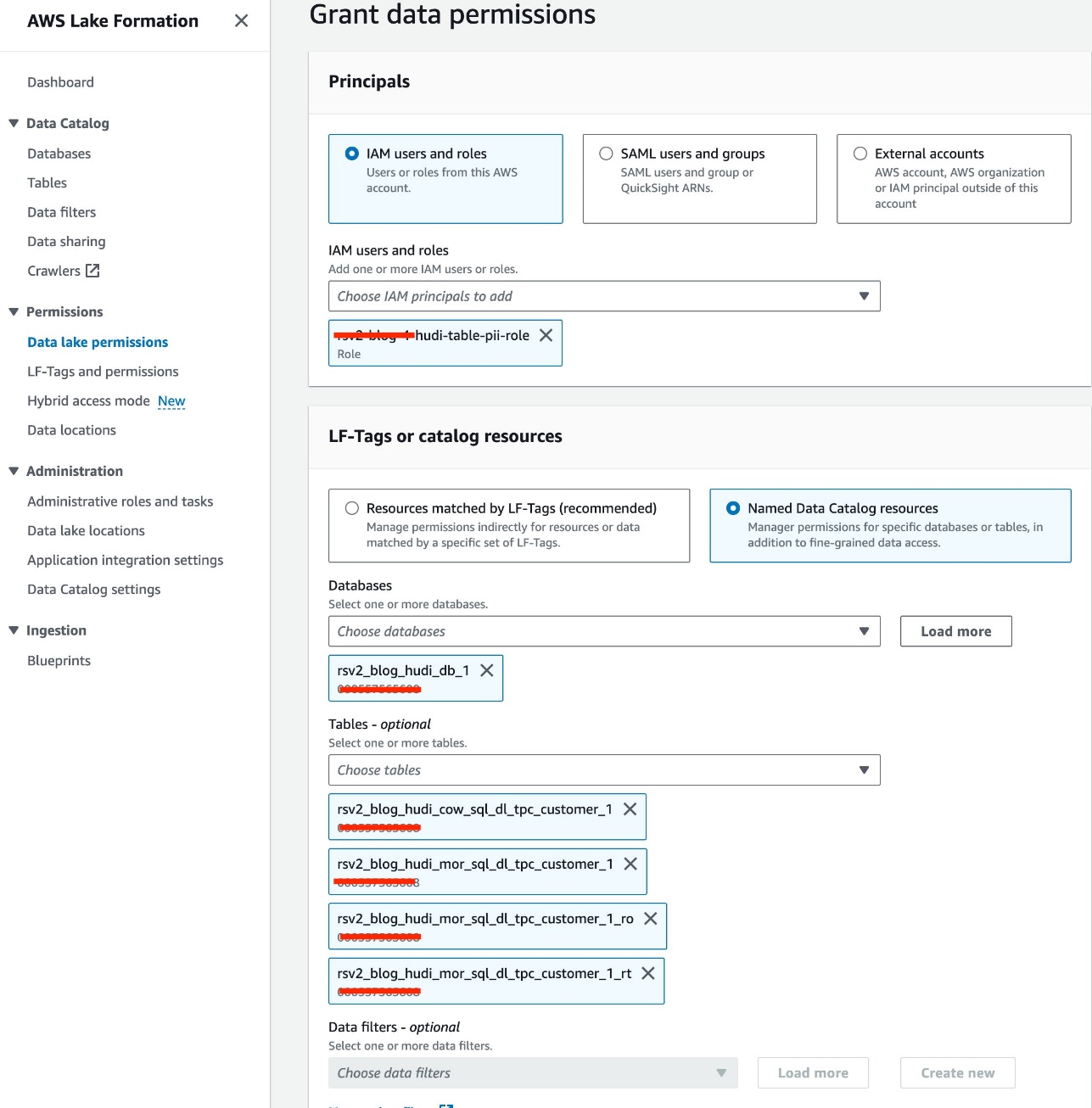
- 왼쪽 메뉴에서
<STACK-NAME>-hudi-table-pii-rolefor IAM 사용자 및 역할. - 선택
rsv2_blog_hudi_db_1데이터베이스 데이터베이스. - 럭셔리 테이블에서 Jupyter Notebook에서 생성한 Hudi 테이블 4개를 선택합니다.
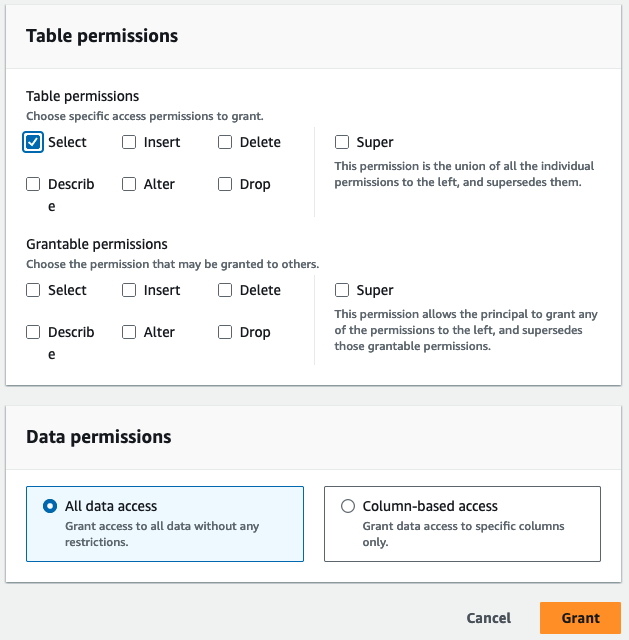
- 럭셔리 테이블 권한, 고르다 선택.
- 왼쪽 메뉴에서 부여.
PII 열 쿼리
이제 노트북을 실행하여 Hudi 테이블을 쿼리할 준비가 되었습니다. SageMaker Studio에서 노트북을 실행하려면 이전 섹션과 비슷한 단계를 따르세요.
- SageMaker 콘솔에서
<STACK-NAME>-Studio-EMR-LF-Hudi도메인입니다. - 에 실행 옆에 메뉴
<STACK-NAME>-hudi-table-reader사용자 프로필, 선택 Studio. - 다운로드한 노트 업로드 rsv2-hudi-테이블-pii-리더-노트북.
- 업로드된 노트북을 엽니다.
- 노트북 설정 단계를 반복하고 동일한 EMR 클러스터에 연결하되 역할을 사용하십시오.
<STACK-NAME>-hudi-table-pii-role.
현재 단계에서 FGAC 지원 EMR 클러스터는 증분 쿼리 및 시간 이동을 수행하기 위해 Hudi의 커밋 시간 열을 쿼리해야 합니다. Spark의 "현재 타임스탬프" 구문을 지원하지 않으며 Spark.read(). 우리는 FGAC가 활성화된 향후 Amazon EMR 릴리스에서 두 작업에 대한 지원을 통합하기 위해 적극적으로 노력하고 있습니다.
이제 노트북의 단계를 따를 수 있습니다. 다음은 몇 가지 주요 단계입니다.
- 스냅샷 쿼리를 실행합니다.
- 증분 쿼리를 실행합니다.
- 시간 여행 쿼리를 실행합니다.
- MOR 읽기 최적화 및 실시간 테이블 쿼리를 실행합니다.
열 수준 및 행 수준 데이터 필터를 사용하여 Hudi 테이블 쿼리
우리는 IAM 역할을 사용합니다<STACK-NAME>-hudi-table-non-pii-roleHudi 테이블을 쿼리합니다. 이 역할은 PII가 포함된 열을 쿼리할 수 없습니다. Lake Formation 열 수준 및 행 수준 데이터 필터를 사용하여 세분화된 액세스 제어를 구현합니다.
- Lake Formation 콘솔에서 데이터 필터 아래에 데이터 카탈로그 탐색 창에서
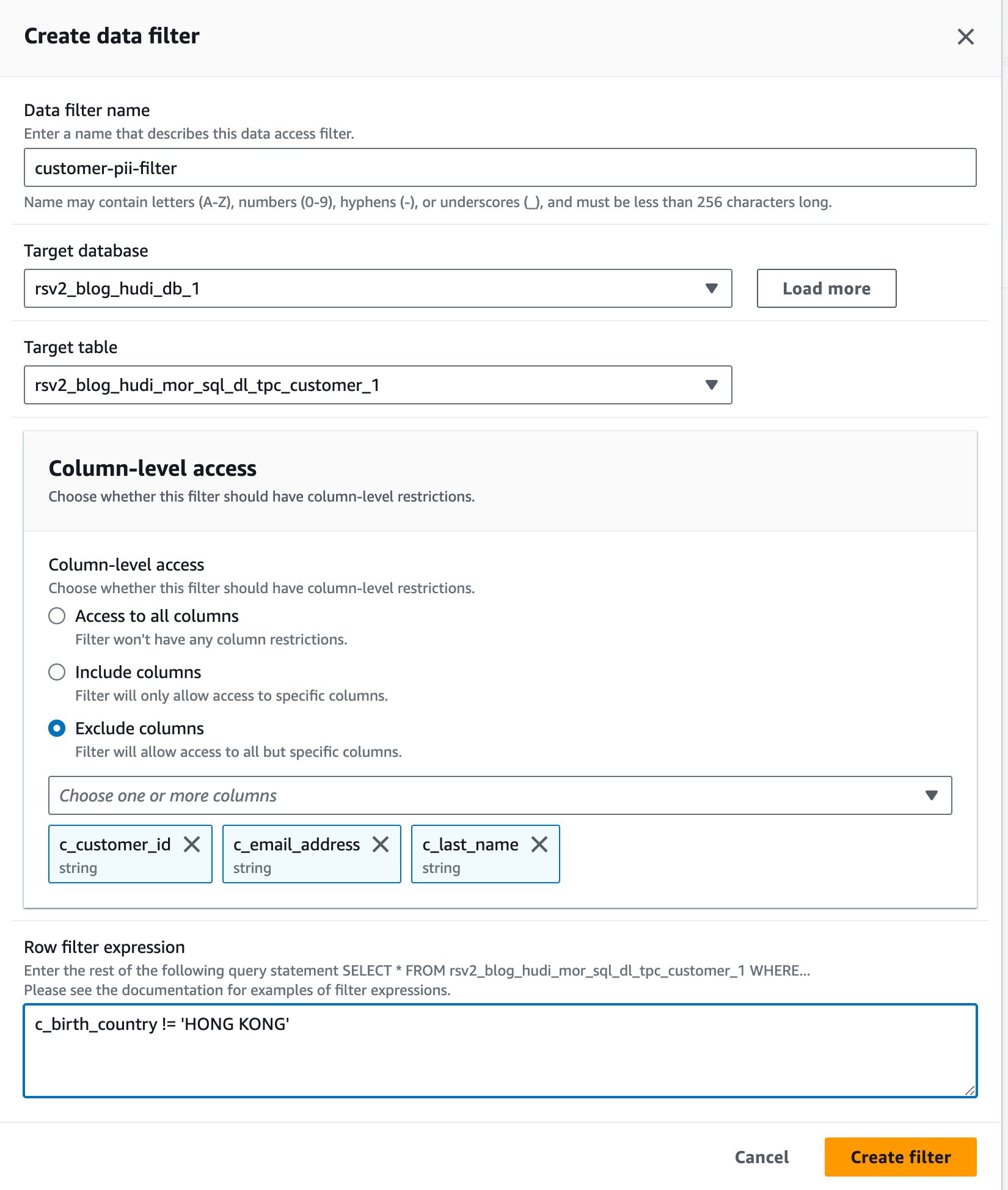
- 왼쪽 메뉴에서 새 필터 만들기.
- 럭셔리 데이터 필터 이름, 입력
customer-pii-filter. - 왼쪽 메뉴에서
rsv2_blog_hudi_db_1for 대상 데이터베이스. - 왼쪽 메뉴에서
rsv2_blog_hudi_mor_sql_dl_customer_1for 대상 테이블. - 선택 열 제외 선택하고
c_customer_id,c_email_address및c_last_name열. - 엔터 버튼
c_birth_country != 'HONG KONG'for 행 필터 표현식. - 왼쪽 메뉴에서 필터 만들기.
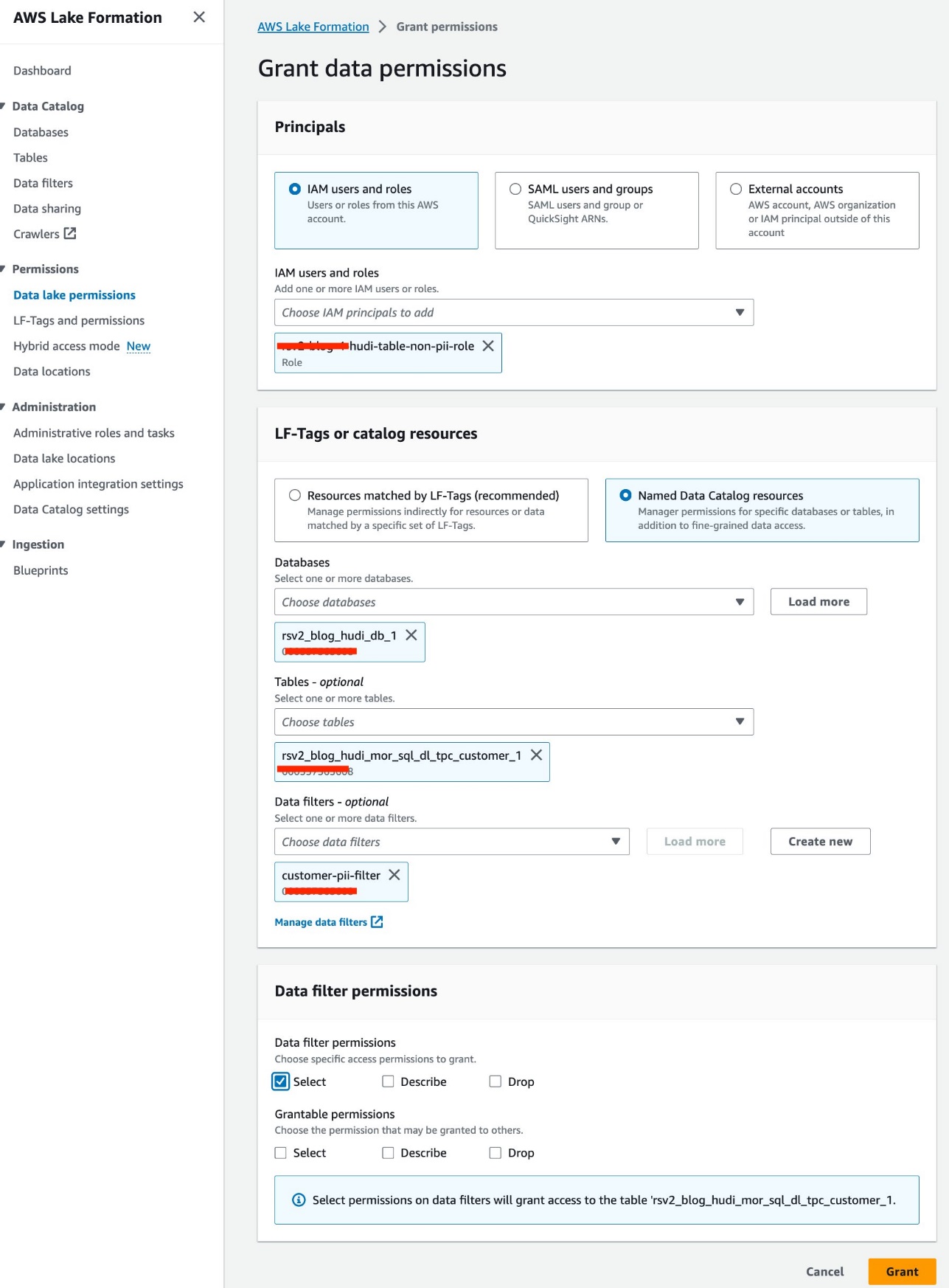
- 왼쪽 메뉴에서 데이터 레이크 권한 아래에 권한 탐색 창에서
- 왼쪽 메뉴에서 부여.
- 왼쪽 메뉴에서
<STACK-NAME>-hudi-table-non-pii-rolefor IAM 사용자 및 역할. - 왼쪽 메뉴에서
rsv2_blog_hudi_db_1for 데이터베이스. - 왼쪽 메뉴에서
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1for 테이블. - 왼쪽 메뉴에서
customer-pii-filterfor 데이터 필터. - 럭셔리 데이터 필터 권한, 고르다 선택.
- 왼쪽 메뉴에서 부여.
SageMaker Studio에서 노트북을 실행하기 위해 유사한 단계를 따르겠습니다.
- SageMaker 콘솔에서 도메인으로 이동합니다.
Studio-EMR-LF-Hudi. - 에 실행 메뉴
hudi-table-reader사용자 프로필, 선택 Studio. - 다운로드한 노트 업로드 rsv2-hudi-테이블-비-pii-리더-노트북 선택하고 엽니다.
- 노트북 설정 단계를 반복하고 동일한 EMR 클러스터에 연결하되 역할을 선택하세요.
<STACK-NAME>-hudi-table-non-pii-role.
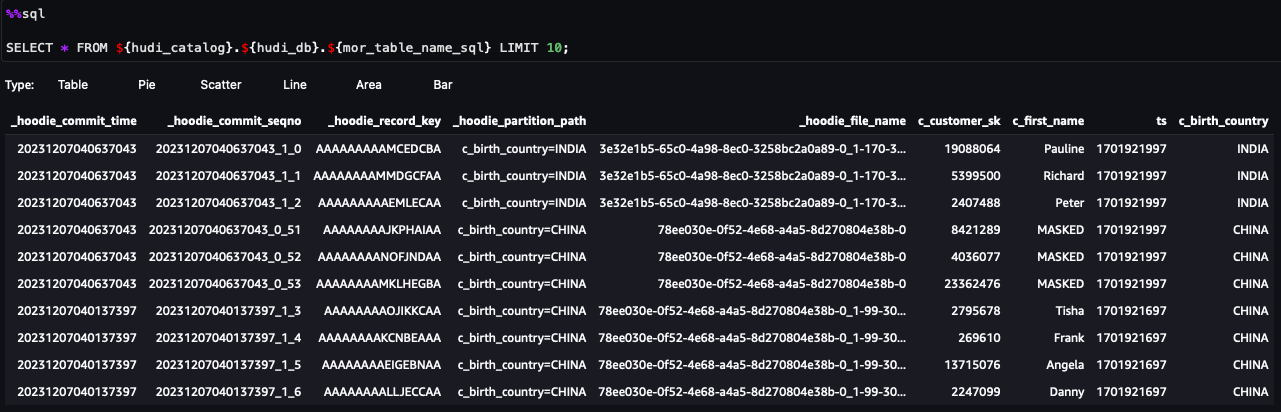
이제 노트북의 단계를 따를 수 있습니다. 쿼리 결과를 보면 Lake Formation 데이터 필터를 통한 FGAC가 적용된 것을 확인할 수 있습니다. 해당 역할은 PII 열을 볼 수 없습니다.c_customer_id,c_last_name및c_email_address. 또한HONG KONG필터링되었습니다.
정리
솔루션 실험을 마친 후에는 예상치 못한 비용이 발생하지 않도록 다음 단계에 따라 리소스를 정리하는 것이 좋습니다.
- SageMaker Studio 앱 종료 사용자 프로필의 경우.
유휴 제한 시간 값이 지나면 EMR 클러스터가 자동으로 삭제됩니다.
- 삭제 아마존 탄성 파일 시스템 (Amazon EFS) 도메인용으로 생성된 볼륨입니다.
- S3 버킷 비우기 CloudFormation 스택에 의해 생성됩니다.
- AWS CloudFormation 콘솔에서 스택을 삭제합니다.
결론
이 게시물에서는 OTF 테이블 유형 중 하나인 Apachi Hudi를 사용하여 Amazon EMR에서 세분화된 액세스 제어를 적용하는 이 새로운 기능을 시연했습니다. OTF 테이블에 대한 Lake Formation에서 세부적인 권한을 정의하고 EMR 클러스터의 Spark SQL 쿼리를 통해 적용할 수 있습니다. 또한 스냅샷 쿼리 실행, 증분 쿼리, 시간 이동 및 DML 쿼리와 같은 트랜잭션 데이터 레이크 기능을 사용할 수도 있습니다. 이 새로운 기능은 모든 OTF 테이블에 적용됩니다.
이 기능은 Amazon EMR 릴리스 6.15부터 모두 출시되었습니다. 지역 Amazon EMR을 사용할 수 있는 곳. Amazon EMR과 Lake Formation의 통합을 통해 빅 데이터를 자신있게 관리 및 처리하여 통찰력을 얻고 정보에 입각한 의사 결정을 촉진하는 동시에 데이터 보안 및 거버넌스를 유지할 수 있습니다.
자세한 내용은 다음을 참조하십시오. Amazon EMR을 통해 Lake Formation 활성화 데이터 여정에 도움을 줄 수 있는 AWS 솔루션스 아키텍트에게 언제든지 문의하세요.
저자에 관하여
 레이몬드 라이 대기업 고객의 요구 사항을 전문적으로 충족하는 수석 솔루션 설계자입니다. 그의 전문 지식은 고객이 복잡한 엔터프라이즈 시스템과 데이터베이스를 AWS로 마이그레이션하고 엔터프라이즈 데이터 웨어하우징 및 데이터 레이크 플랫폼을 구축하도록 지원하는 데 있습니다. Raymond는 AI/ML 사용 사례를 위한 솔루션을 식별하고 설계하는 데 탁월하며 특히 AWS 서버리스 솔루션 및 이벤트 기반 아키텍처 설계에 중점을 두고 있습니다.
레이몬드 라이 대기업 고객의 요구 사항을 전문적으로 충족하는 수석 솔루션 설계자입니다. 그의 전문 지식은 고객이 복잡한 엔터프라이즈 시스템과 데이터베이스를 AWS로 마이그레이션하고 엔터프라이즈 데이터 웨어하우징 및 데이터 레이크 플랫폼을 구축하도록 지원하는 데 있습니다. Raymond는 AI/ML 사용 사례를 위한 솔루션을 식별하고 설계하는 데 탁월하며 특히 AWS 서버리스 솔루션 및 이벤트 기반 아키텍처 설계에 중점을 두고 있습니다.
 왕빈, PhD는 AWS의 수석 분석 전문가 솔루션 아키텍트이며 특히 광고에 중점을 두고 ML 업계에서 12년 이상의 경험을 자랑합니다. 그는 자연어 처리(NLP), 추천 시스템, 다양한 ML 알고리즘 및 ML 운영에 대한 전문 지식을 보유하고 있습니다. 그는 ML/DL 및 빅데이터 기술을 적용하여 실제 문제를 해결하는 데 깊은 열정을 갖고 있습니다.
왕빈, PhD는 AWS의 수석 분석 전문가 솔루션 아키텍트이며 특히 광고에 중점을 두고 ML 업계에서 12년 이상의 경험을 자랑합니다. 그는 자연어 처리(NLP), 추천 시스템, 다양한 ML 알고리즘 및 ML 운영에 대한 전문 지식을 보유하고 있습니다. 그는 ML/DL 및 빅데이터 기술을 적용하여 실제 문제를 해결하는 데 깊은 열정을 갖고 있습니다.
 아디트야 샤 AWS의 소프트웨어 개발 엔지니어입니다. 그는 데이터베이스 및 데이터 웨어하우스 엔진에 관심이 있으며 Apache Hive 및 Apache Spark와 같은 엔진에 대한 성능 최적화, 보안 규정 준수 및 ACID 규정 준수 작업을 해왔습니다.
아디트야 샤 AWS의 소프트웨어 개발 엔지니어입니다. 그는 데이터베이스 및 데이터 웨어하우스 엔진에 관심이 있으며 Apache Hive 및 Apache Spark와 같은 엔진에 대한 성능 최적화, 보안 규정 준수 및 ACID 규정 준수 작업을 해왔습니다.
 멜로디 양 AWS에서 Amazon EMR의 수석 빅 데이터 솔루션 아키텍트입니다. 그녀는 데이터 변환의 성공을 지원하기 위해 AWS 고객과 협력하여 모범 사례 지침 및 기술 조언을 제공하는 숙련된 분석 리더입니다. 그녀의 관심 분야는 오픈 소스 프레임워크 및 자동화, 데이터 엔지니어링 및 DataOps입니다.
멜로디 양 AWS에서 Amazon EMR의 수석 빅 데이터 솔루션 아키텍트입니다. 그녀는 데이터 변환의 성공을 지원하기 위해 AWS 고객과 협력하여 모범 사례 지침 및 기술 조언을 제공하는 숙련된 분석 리더입니다. 그녀의 관심 분야는 오픈 소스 프레임워크 및 자동화, 데이터 엔지니어링 및 DataOps입니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/
- :있다
- :이다
- :아니
- :어디
- $UP
- 1
- 10
- 100
- 11
- 12
- 130
- 15%
- 16
- 17
- 20
- 22
- 400
- 7
- 8
- 9
- a
- 소개
- ACCESS
- 계정
- 인정
- 행위
- 활발히
- 추가
- 또한
- 구애
- 관리자
- 관리자
- 광고
- 조언
- 후
- 다시
- AI / ML
- 알고리즘
- All
- 수
- 수
- 수
- 함께
- 또한
- 아마존
- Amazon EC2
- 아마존 EMR
- Amazon Web Services
- an
- 분석
- 애널리스트
- 분석
- 분석
- 분석하는
- 및
- 어떤
- 아파치
- 아파치 스파크
- 어플리케이션
- 적용된
- 신청
- 적용
- 건축가
- 아키텍처
- 있군요
- 지역
- 약
- AS
- 지원
- 원조
- 돕는
- 취하다
- At
- 감사
- 권위
- 허가
- 자동적으로
- 자동화
- 가능
- 피하기
- AWS
- AWS 클라우드9
- AWS 클라우드 포메이션
- AWS Lake 형성
- 뒤로
- 기반으로
- BE
- 된
- 뒤에
- 존재
- 혜택
- 게다가
- BEST
- 큰
- 빅 데이터
- 블로그
- 자랑하는
- 두
- 빌드
- 비자 면제 프로그램에 해당하는 국가의 시민권을 가지고 있지만
- by
- CA
- CAN
- 수
- 나르다
- 적재
- 케이스
- 가지 경우
- 목록
- 음식
- 어떤
- 증명서
- 인증
- 인증
- 이전 단계로 돌아가기
- 변경
- 변경
- 중국
- 왼쪽 메뉴에서
- 청소관련
- Cloud9
- 클러스터
- 암호
- 단
- 열
- COM
- 결합
- 범하다
- 기업
- 비교
- 완전한
- compliance
- 구성 요소
- 구성 요소들
- 계산
- 컴퓨터
- 개념
- 조건
- 행위
- 자신있게
- 구성
- 연결하기
- 콘솔에서
- 건설 중의
- CONTACT
- 포함하는
- 이 포함되어 있습니다
- 제어
- 통제
- 컨트롤
- 사자
- 동
- 비용
- 비용
- 국가
- 커버
- 만들
- 만든
- 생성
- 만들기
- 창조자
- Current
- 관습
- 고객
- 데이터
- 데이터 액세스
- 데이터 분석
- 데이터 레이크
- 데이터 플랫폼
- 데이터 프라이버시
- 데이터 처리
- 데이터 보안
- 데이터웨어 하우스
- 데이터베이스
- 데이터베이스
- 의사 결정
- 깊이
- 태만
- 밝히다
- 델타
- 보여
- 시연하는
- 배포
- 전개
- 디자인
- 설계
- 세부설명
- 개발
- 다른
- 뚜렷한
- 몇몇의
- DNS
- do
- 하지
- 하지 않습니다
- 도메인
- 한
- 말라
- 아래 (down)
- 다운로드
- 구동
- ...동안
- 마다
- 그렇지 않으면
- 가능
- 사용 가능
- 수
- 암호화
- end
- 엔드 포인트
- 억지로 시키다
- 엔진
- 기사
- 엔지니어링
- 엔진
- 확인
- 보장
- 보장
- 엔터 버튼
- Enterprise
- 기업 고객
- 전체의
- 환경
- 에테르 (ETH)
- 이벤트
- 모든
- 예
- 실행
- 존재
- 경험
- 경험
- 전문적 지식
- 탐구
- 확장하다
- 외부
- 촉진
- 빠른
- 특색
- 특징
- 세 연령의 아시안이
- 입양 부모로서의 귀하의 적합성을 결정하기 위해 미국 이민국에
- 파일
- 필터링
- 필터링
- 필터
- 먼저,
- 초점
- 집중
- 따라
- 수행원
- 다음
- 럭셔리
- 체재
- 형성
- 사
- 뼈대
- 프레임 워크
- 무료
- 에
- 다하다
- 가득 찬
- 기능
- 추가
- 미래
- 이득
- 생성
- 통치
- 통치되는
- 부여
- 매우
- 그룹
- 여러 떼
- 지도
- 손
- 있다
- he
- 그녀의
- 여기에서 지금 확인해 보세요.
- 강조
- 그의
- 역사적인
- history
- 하이브
- 홍콩
- 香港
- 집
- 방법
- How To
- 그러나
- HTML
- HTTP
- HTTPS
- IAM
- ICON
- ID
- 생각
- 확인
- 식별
- 유휴
- if
- 설명하다
- 구현
- 개선
- in
- 포함
- 포함
- 통합
- 증분
- 인도
- 산업
- 통보
- 정보
- 정보
- 입력
- 통찰력
- 통합 된
- 통합
- 완성
- 대화형
- 관심있는
- 이해
- 인터페이스
- 내부의
- 으로
- 뒤얽힌
- 소개
- 소개합니다
- 발행물
- IT
- 그
- 일
- 작업
- 여행
- JPG
- 주피터 수첩
- 키
- 홍콩
- 소금물
- 언어
- 넓은
- 성
- 시작
- 시작
- 리더
- 배우다
- 레벨
- 거짓
- 처럼
- 제한
- 라인
- 지방의
- 위치
- 위치
- 로그인
- 주요한
- 확인
- 관리
- 관리
- 구축
- 매니저
- .
- XNUMX월..
- 방법
- 메커니즘
- 회의
- 메뉴
- 메타 데이터
- 수도
- 이주하는
- 분
- ML
- ML 알고리즘
- 수정
- 배우기
- 운동
- name
- 이름
- 자연의
- 자연어
- 자연 언어 처리
- 이동
- 카테고리
- 필요
- 요구
- 신제품
- 새로운 기능
- 새로운
- 다음 것
- nlp
- 노드
- 주의
- 수첩
- 노트북
- 지금
- 사물
- of
- 자주
- on
- ONE
- 만
- 열 수
- 오픈 소스
- 하려면 openssl
- 행정부
- 최적의
- 최적화
- 선택권
- 옵션
- or
- 주문
- 조직
- 기타
- 아웃
- 위에
- 쌍
- 빵
- 특별한
- 특별히
- 열렬한
- 지불하는
- 성능
- 실행할 수 있는
- 허가
- 권한
- 몸소
- 박사 학위
- pii
- 자리
- 플랫폼
- 플랫폼
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 부디
- ...을 더한
- 전철기
- 인기 문서
- 소유하다
- 게시하다
- 연습
- 보존
- 너무 이른
- 일차
- 개인 정보 보호
- 특권
- 권한
- 문제
- 방법
- 처리
- 생산
- 프로필
- 프로필
- 증명
- 개념 증명
- 보호
- 보호
- 제공
- 제공
- 제공
- 공개
- 목적
- 쿼리
- 읽기
- 읽기
- 준비
- 현실 세계
- 실시간
- 권하다
- 기록
- 회복
- 감소
- 감소
- 참조
- 의미
- 반영하다
- 지방
- 회원가입
- 등록된
- 규정
- 공개
- 보도 자료
- 관련된
- 교체
- 필수
- 요구조건 니즈
- 의지
- 자원 집약적
- 제품 자료
- 결과
- 결과
- 권리
- 직위별
- 역할
- 열
- RSA
- 규칙
- 달리기
- 달리는
- 현자
- 같은
- 찜하기
- 섹션
- 안전해야합니다.
- 보안
- 보안
- 참조
- 찾으라
- 고르다
- 연장자
- 민감한
- 섬기는 사람
- 서버리스
- 서비스
- 세션
- 세트
- 설정
- 설정
- 설치
- 그녀
- 기호
- 크게
- 비슷한
- 단순, 간단, 편리
- 단순화하다
- 단순화
- 이후
- 스냅 사진
- So
- 소프트웨어
- 소프트웨어 개발
- 해결책
- 솔루션
- 풀다
- 일부
- 출처
- 불꽃
- 전문가
- 전문적으로
- SQL
- 스택
- 단계
- 스타트
- 시작
- 시작 중
- 문
- 단계
- 저장
- 상점
- 전략
- 끈
- 스튜디오
- 제출
- 서브넷
- 성공
- 이러한
- 개요
- SUPPORT
- 지원
- 확인
- 구문
- 시스템은
- 테이블
- TAG
- 소요
- 테크니컬
- 기법
- 이 템플릿
- 단말기
- 그
- XNUMXD덴탈의
- 소스
- 그들의
- 그들
- 그때
- 그곳에.
- Bowman의
- 그들
- 이
- 세
- 을 통하여
- 시간
- 시간 여행
- 타임 라인
- 에
- 추적
- 거래
- 거래상의
- 변환
- 운송
- 여행
- 참된
- 신뢰할 수있는
- Ts
- 두
- 유형
- 유형
- ui
- 아래에
- 예기치 않은
- 알 수없는
- 잠금 해제
- 업데이트
- 업데이트
- 지지
- 업로드
- URI
- 사용
- 유스 케이스
- 익숙한
- 사용자
- 사용자
- 사용
- 검증
- 가치
- 여러
- 버전
- 를 통해
- 가시성
- 음량
- 창고
- 창고
- we
- 웹
- 웹 서비스
- 언제
- 이므로
- 어느
- 동안
- 누구
- 의지
- 과
- 이내
- 일
- 일하는
- 쓰다
- 년
- 당신
- 너의
- 제퍼 넷
- 제로
- 지퍼