모든 산업 분야의 조직에는 다음과 같은 다양한 분석 시스템에서 분석 사용 사례에 대한 복잡한 데이터 처리 요구 사항이 있습니다. AWS의 데이터 레이크, 데이터 웨어하우스(아마존 레드 시프트), 찾다 (아마존 오픈서치 서비스), NoSQL(아마존 DynamoDB), 기계 학습(아마존 세이지 메이커), 그리고 더. 분석 전문가는 이러한 분산 시스템에 저장된 데이터에서 가치를 도출하여 고객을 위한 보다 우수하고 안전하며 비용 최적화된 경험을 창출해야 합니다. 예를 들어, 디지털 미디어 회사는 내부 및 외부 데이터베이스의 데이터 세트를 결합 및 처리하여 고객 프로필에 대한 통합 보기를 구축하고 혁신적인 기능에 대한 아이디어를 촉진하며 플랫폼 참여를 증가시키려고 합니다.
이러한 시나리오에서 서버리스 데이터 통합 오퍼링을 찾는 고객은 다음을 사용합니다. AWS 접착제 데이터 처리 및 분류를 위한 핵심 구성 요소로 사용됩니다. AWS Glue는 AWS 서비스 및 파트너 제품과 원활하게 통합되며 분석, 기계 학습(ML) 또는 애플리케이션 개발 워크플로를 지원하는 코드가 적거나 코드가 없는 ETL(추출, 변환 및 로드) 옵션을 제공합니다. AWS Glue ETL 작업은 보다 복잡한 파이프라인의 한 구성 요소일 수 있습니다. 이러한 구성 요소 간의 실행을 오케스트레이션하고 종속성을 관리하는 것은 데이터 전략의 핵심 기능입니다. Apache Airflows용 Amazon 관리형 워크플로 (Amazon MWAA)는 온프레미스 리소스, AWS 서비스 및 타사 구성 요소를 포함한 분산 기술을 사용하여 데이터 파이프라인을 오케스트레이션합니다.
이 게시물에서는 Amazon MWAA의 최신 기능을 사용하여 Airflow에서 오케스트레이션된 AWS Glue 작업 모니터링을 간소화하는 방법을 보여줍니다.
솔루션 개요
이 게시물에서는 다음에 대해 설명합니다.
- Amazon MWAA 환경을 버전 2.4.3으로 업그레이드하는 방법.
- Airflow에서 AWS Glue 작업을 오케스트레이션하는 방법 방향성 비순환 그래프 (가리비).
- Amazon MWAA에서 Airflow Amazon 공급자 패키지의 관찰 가능성이 향상되었습니다. 이제 Airflow 콘솔에서 AWS Glue 작업의 실행 로그를 통합하여 데이터 파이프라인 문제 해결을 간소화할 수 있습니다. Amazon MWAA 콘솔은 AWS Glue 작업 실행을 모니터링하고 분석하기 위한 단일 참조가 됩니다. 이전에는 지원 팀이 AWS 관리 콘솔 이 가시성을 위해 수동 조치를 취하십시오. 이 기능은 기본적으로 Amazon MWAA 버전 2.4.3에서 사용할 수 있습니다.
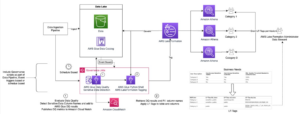
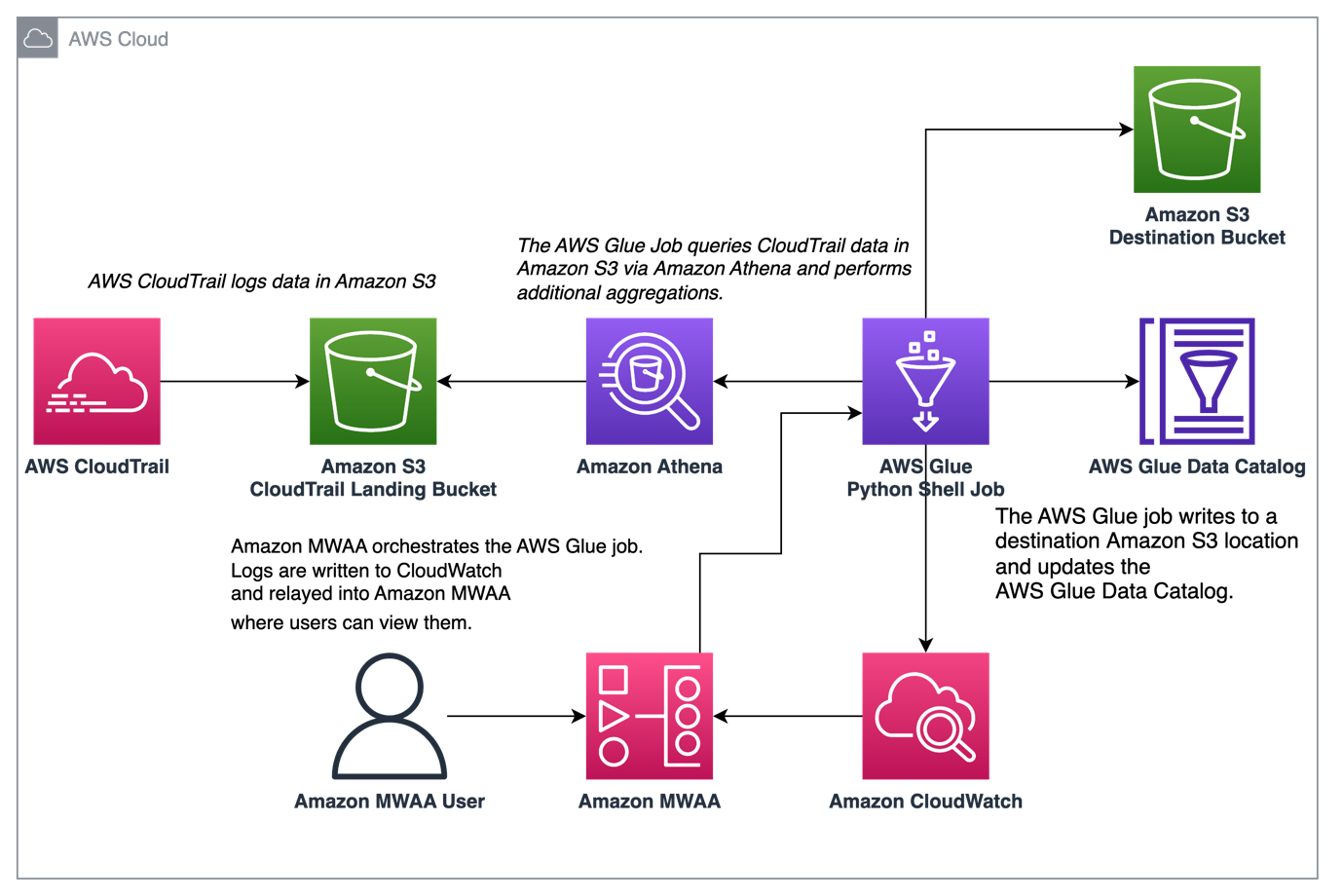
다음 다이어그램은 솔루션 아키텍처를 보여줍니다.
사전 조건
다음 전제 조건이 필요합니다.
Amazon MWAA 환경 설정
환경 생성에 대한 지침은 다음을 참조하십시오. Amazon MWAA 환경 생성. 기존 사용자의 경우 버전 2.4.3으로 업그레이드하여 이 게시물에 포함된 관측 가능성 향상을 활용하는 것이 좋습니다.
Amazon MWAA를 버전 2.4.3으로 업그레이드하는 단계는 현재 버전이 1.10.12인지 2.2.2인지에 따라 다릅니다. 이 게시물에서는 두 가지 옵션에 대해 논의합니다.
Amazon MWAA 환경 설정을 위한 전제 조건
다음 전제 조건을 충족해야 합니다.
버전 1.10.12에서 2.4.3으로 업그레이드
Amazon MWAA 버전을 사용하는 경우 1.10.12, 인용하다 새로운 Amazon MWAA 환경으로 마이그레이션 2.4.3으로 업그레이드합니다.
버전 2.0.2 또는 2.2.2에서 2.4.3으로 업그레이드
Amazon MWAA 환경 버전 2.2.2 이하를 사용하는 경우 다음 단계를 완료하십시오.
- 만들기 사용자 지정 종속성에 대한 requirements.txt DAG에 필요한 특정 버전이 있습니다.
- Amazon S3에 파일 업로드 Amazon MWAA 환경이 종속성 설치를 위해 requirements.txt를 가리키는 적절한 위치에 있습니다.
- 의 단계를 따르십시오 새로운 Amazon MWAA 환경으로 마이그레이션 버전 2.4.3을 선택합니다.
DAG 업데이트
이전 Amazon MWAA 환경에서 업그레이드한 고객은 기존 DAG를 업데이트해야 할 수 있습니다. Airflow 버전 2.4.3에서 Airflow 환경은 기본적으로 Amazon 공급자 패키지 버전 6.0.0을 사용합니다. 이 패키지에는 운영자 이름 변경과 같은 몇 가지 주요 변경 사항이 포함될 수 있습니다. 예를 들어, AWSGlueJobOperator 더 이상 사용되지 않으며 다음으로 대체되었습니다. GlueJobOperator. 호환성을 유지하려면 이전 버전에서 더 이상 사용되지 않거나 지원되지 않는 연산자를 새 연산자로 교체하여 Airflow DAG를 업데이트하세요. 다음 단계를 완료하십시오.
- 로 이동 아마존 AWS 운영자.
- 지원되는 Airflow 연산자 목록을 찾으려면 Amazon MWAA 인스턴스(기본적으로 6.0.0.)에 설치된 적절한 버전을 선택하십시오.
- 기존 DAG 코드에서 필요에 따라 변경하고 수정된 파일을 Amazon S3의 DAG 위치에 업로드합니다.
Airflow에서 AWS Glue 작업 오케스트레이션
이 섹션에서는 Airflow DAG 내에서 AWS Glue 작업을 오케스트레이션하는 세부 정보를 다룹니다. Airflow는 온프레미스 프로세스, 외부 종속성, 기타 AWS 서비스 등과 같은 이기종 시스템 간의 종속성이 있는 데이터 파이프라인의 개발을 용이하게 합니다.
AWS Glue 및 Amazon MWAA로 CloudTrail 로그 집계 오케스트레이션
이 예에서는 Amazon MWAA를 사용하여 CloudTrail 로그를 기반으로 집계된 지표를 유지하는 AWS Glue Python Shell 작업을 오케스트레이션하는 사용 사례를 살펴봅니다.
CloudTrail은 AWS 계정에서 수행되는 AWS API 호출에 대한 가시성을 제공합니다. 이 데이터의 일반적인 사용 사례는 감사 및 규제 요구를 위해 계정의 리소스에 작용하는 보안 주체에 대한 사용 지표를 수집하는 것입니다.
CloudTrail 이벤트가 기록되면 분석 쿼리에 적합하지 않은 Amazon S3에 JSON 파일로 전달됩니다. 최적의 쿼리 성능을 위해 이 데이터를 집계하고 Parquet 파일로 유지하려고 합니다. 초기 단계로 AWS Glue 작업에서 추가 집계를 수행하기 전에 Athena를 사용하여 데이터의 초기 쿼리를 수행할 수 있습니다. AWS Glue 데이터 카탈로그 테이블 생성에 대한 자세한 내용은 다음을 참조하십시오. 파티션 프로젝션을 사용하여 Athena에서 CloudTrail 로그용 테이블 생성 데이터. Athena를 통해 데이터를 탐색하고 집계 테이블에 유지할 지표를 결정한 후 AWS Glue 작업을 생성할 수 있습니다.
Athena에서 CloudTrail 테이블 생성
먼저 Athena를 통해 CloudTrail 데이터를 쿼리할 수 있도록 데이터 카탈로그에 테이블을 생성해야 합니다. 다음 샘플 쿼리는 지역 및 날짜(snapshot_date라고 함)에 두 개의 파티션이 있는 테이블을 생성합니다. CloudTrail 버킷, AWS 계정 ID 및 CloudTrail 테이블 이름에 대한 자리 표시자를 교체해야 합니다.
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')Athena 콘솔에서 이전 쿼리를 실행하고 생성된 테이블 이름과 AWS Glue 데이터 카탈로그 데이터베이스를 기록해 둡니다. 나중에 Airflow DAG 코드에서 이 값을 사용합니다.
샘플 AWS Glue 작업 코드
다음 코드는 샘플입니다. AWS Glue Python 셸 작업 다음을 수행합니다.
- 처리할 날짜의 데이터에 대한 인수(Amazon MWAA DAG에서 전달)를 취합니다.
- 사용 Pandas용 AWS SDK Athena 쿼리를 실행하여 AWS Glue 외부에서 CloudTrail JSON 데이터의 초기 필터링을 수행합니다.
- Pandas를 사용하여 필터링된 데이터에 대한 간단한 집계 수행
- 집계된 데이터를 테이블의 AWS Glue 데이터 카탈로그에 출력합니다.
- Amazon MWAA에 표시되는 처리 중 로깅 사용
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
다음은 이 AWS Glue 작업의 몇 가지 주요 이점입니다.
- Athena 쿼리를 사용하여 초기 필터링이 AWS Glue 작업 외부에서 수행되도록 합니다. 따라서 최소한의 컴퓨팅을 사용하는 Python Shell 작업은 대규모 CloudTrail 데이터 세트를 집계하는 데 여전히 충분합니다.
- 우리는 분석 라이브러리 세트 옵션 AWS SDK for Pandas 라이브러리를 사용하기 위해 AWS Glue 작업을 생성할 때 켜집니다.
AWS Glue 작업 생성
AWS Glue 작업을 생성하려면 다음 단계를 완료하십시오.
- 이전 섹션의 스크립트를 복사하여 로컬 파일에 저장합니다. 이 게시물의 경우 파일 이름은
script.py. - AWS Glue 콘솔에서 ETL 작업 탐색 창에서
- 새 작업을 만들고 선택 Python 셸 스크립트 편집기.
- 선택 기존 스크립트 업로드 및 편집 로컬에 저장한 파일을 업로드합니다.
- 왼쪽 메뉴에서 만들기.

- 에 직업 세부 정보 탭에서 AWS Glue 작업의 이름을 입력합니다.
- 럭셔리 IAM 역할, 기존 역할을 선택하거나 Amazon S3, AWS Glue 및 Athena에 필요한 권한이 있는 새 역할을 생성합니다. 역할은 이전에 생성한 CloudTrail 테이블을 쿼리하고 출력 위치에 써야 합니다.
다음 샘플 정책 코드를 사용할 수 있습니다. 자리 표시자를 CloudTrail 로그 버킷, 출력 테이블 이름, 출력 AWS Glue 데이터베이스, 출력 S3 버킷, CloudTrail 테이블 이름, CloudTrail 테이블이 포함된 AWS Glue 데이터베이스 및 AWS 계정 ID로 바꿉니다.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
럭셔리 파이썬 버전선택한다. 파이썬 3.9.
- 선택 일반 분석 라이브러리 로드.
- 럭셔리 데이터 처리 장치선택한다. DPU 1개.
- 다른 옵션은 기본값으로 두거나 필요에 따라 조정합니다.

- 왼쪽 메뉴에서 찜하기 작업 구성을 저장합니다.
AWS Glue 작업을 오케스트레이션하도록 Amazon MWAA DAG 구성
다음 코드는 생성한 AWS Glue 작업을 오케스트레이션할 수 있는 DAG용입니다. 이 DAG에서 다음과 같은 주요 기능을 활용합니다.
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
Amazon MWAA에서 AWS Glue 작업의 관찰 가능성 향상
AWS Glue 작업은 다음에 로그를 씁니다. 아마존 클라우드 워치. 최근 Airflow의 Amazon 제공자 패키지에 대한 관찰 가능성이 향상되어 이제 이러한 로그가 Airflow 작업 로그와 통합되었습니다. 이러한 통합은 Airflow 사용자에게 Airflow UI에서 직접 엔드 투 엔드 가시성을 제공하므로 CloudWatch 또는 AWS Glue 콘솔에서 검색할 필요가 없습니다.
이 기능을 사용하려면 Amazon MWAA 환경에 연결된 IAM 역할에 필요한 로그를 검색하고 쓸 수 있는 다음 권한이 있는지 확인하십시오.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}verbose=true인 경우 AWS Glue 작업 실행 로그가 Airflow 작업 로그에 표시됩니다. 기본값은 거짓입니다. 자세한 내용은 다음을 참조하십시오. 파라미터.
활성화되면 DAG는 AWS Glue 작업의 CloudWatch 로그 스트림에서 읽고 이를 Airflow DAG AWS Glue 작업 단계 로그로 전달합니다. 이는 DAG 로그를 통해 실시간으로 AWS Glue 작업 실행에 대한 자세한 통찰력을 제공합니다. AWS Glue 작업은 각각 작업의 STDOUT 및 STDERR을 기반으로 출력 및 오류 CloudWatch 로그 그룹을 생성합니다. 출력 로그 그룹의 모든 로그와 오류 로그 그룹의 예외 또는 오류 로그는 Amazon MWAA로 전달됩니다.
AWS 관리자는 이제 지원 팀의 액세스 권한을 Airflow로만 제한할 수 있으므로 Amazon MWAA를 작업 오케스트레이션 및 작업 상태 관리에 대한 단일 창으로 만들 수 있습니다. 이전에는 사용자가 Airflow DAG 단계에서 AWS Glue 작업 실행 상태를 확인하고 작업 실행 식별자를 검색해야 했습니다. 그런 다음 AWS Glue 콘솔에 액세스하여 작업 실행 기록을 찾고, 식별자를 사용하여 관심 있는 작업을 검색하고, 마지막으로 작업의 CloudWatch 로그로 이동하여 문제를 해결해야 했습니다.
DAG 만들기
DAG를 만들려면 다음 단계를 완료하세요.
- 앞의 DAG 코드를 로컬 .py 파일에 저장하여 표시된 자리 표시자를 바꿉니다.
AWS 계정 ID, AWS Glue 작업 이름, CloudTrail 테이블이 있는 AWS Glue 데이터베이스 및 CloudTrail 테이블 이름에 대한 값을 이미 알고 있어야 합니다. 필요에 따라 출력 S3 버킷, 출력 AWS Glue 데이터베이스 및 출력 테이블 이름을 조정할 수 있지만 이전에 사용한 AWS Glue 작업의 IAM 역할이 그에 따라 구성되었는지 확인하십시오.
- Amazon MWAA 콘솔에서 환경으로 이동하여 DAG 코드가 저장된 위치를 확인합니다.
DAGs 폴더는 DAG 파일을 배치해야 하는 S3 버킷 내의 접두사입니다.
- 거기에 편집한 파일을 업로드합니다.

- Amazon MWAA 콘솔을 열어 DAG가 테이블에 나타나는지 확인합니다.

DAG 실행
DAG를 실행하려면 다음 단계를 완료하세요.
- 다음 옵션 중에서 선택하십시오.
- 트리거 DAG – 이로 인해 어제의 데이터가 처리할 데이터로 사용됩니다.
- 구성으로 DAG 트리거 – 이 옵션을 사용하면 잠재적으로 백필을 위해 다른 날짜를 전달할 수 있습니다.
dag_run.confDAG 코드에서 매개변수로 AWS Glue 작업에 전달

다음 스크린샷은 선택한 경우 추가 구성 옵션을 보여줍니다. 구성으로 DAG 트리거.

- 실행되는 DAG를 모니터링합니다.
- DAG가 완료되면 실행 세부 정보를 엽니다.
오른쪽 창에서 로그를 보거나 작업 인스턴스 세부 정보 전체보기를 위해.

- 덕분에 AWS Glue 콘솔을 사용하지 않고도 Amazon MWAA에서 AWS Glue 작업 출력 로그를 볼 수 있습니다.
GlueJobOperator자세한 플래그.

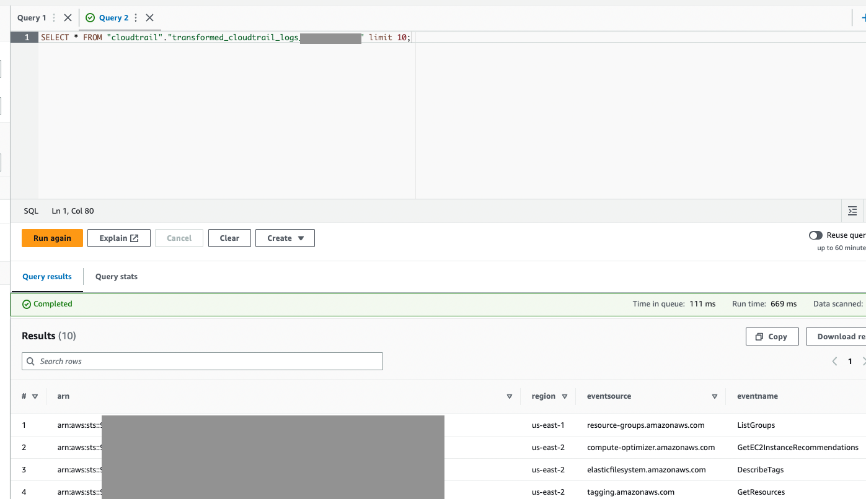
AWS Glue 작업은 지정한 출력 테이블에 결과를 기록합니다.
- Athena를 통해 이 테이블을 쿼리하여 성공했는지 확인합니다.
요약
Amazon MWAA는 이제 AWS Glue 작업 상태를 추적할 수 있는 단일 위치를 제공하고 Airflow 콘솔을 작업 오케스트레이션 및 상태 관리를 위한 단일 창으로 사용할 수 있습니다. 이 게시물에서는 다음을 사용하여 Airflow를 통해 AWS Glue 작업을 오케스트레이션하는 단계를 살펴보았습니다. GlueJobOperator. 새로운 관찰 기능 향상을 통해 통합 환경에서 AWS Glue 작업 문제를 원활하게 해결할 수 있습니다. 또한 Amazon MWAA 환경을 호환 가능한 버전으로 업그레이드하고, 종속성을 업데이트하고, 그에 따라 IAM 역할 정책을 변경하는 방법도 시연했습니다.
일반적인 문제 해결 단계에 대한 자세한 내용은 다음을 참조하십시오. 문제 해결: Amazon MWAA 환경 생성 및 업데이트. Amazon MWAA 환경으로의 마이그레이션에 대한 자세한 내용은 다음을 참조하십시오. 1.10에서 2로 업그레이드. Airflow Amazon 공급자 패키지에서 AWS Glue 작업의 관찰 가능성을 높이기 위한 오픈 소스 코드 변경 사항에 대해 알아보려면 다음을 참조하십시오. AWS Glue 작업의 릴레이 로그.
마지막으로, 우리는 방문하는 것이 좋습니다 AWS 빅 데이터 블로그 AWS의 분석, ML 및 데이터 거버넌스에 대한 기타 자료.
저자에 관하여
 루샤브 로칸데 AWS Professional Services Analytics Practice의 데이터 및 ML 엔지니어입니다. 그는 고객이 빅 데이터, 기계 학습 및 분석 솔루션을 구현하도록 돕습니다. 일 외에는 가족과 함께 시간을 보내고, 독서, 달리기, 골프를 즐깁니다.
루샤브 로칸데 AWS Professional Services Analytics Practice의 데이터 및 ML 엔지니어입니다. 그는 고객이 빅 데이터, 기계 학습 및 분석 솔루션을 구현하도록 돕습니다. 일 외에는 가족과 함께 시간을 보내고, 독서, 달리기, 골프를 즐깁니다.
 라이언 고메스 AWS Professional Services Analytics Practice의 데이터 및 ML 엔지니어입니다. 그는 고객이 클라우드에서 분석 및 기계 학습 솔루션을 통해 더 나은 결과를 얻을 수 있도록 돕는 일에 열정적입니다. 직장 밖에서는 피트니스, 요리, 친구 및 가족과 함께 좋은 시간을 보내는 것을 즐깁니다.
라이언 고메스 AWS Professional Services Analytics Practice의 데이터 및 ML 엔지니어입니다. 그는 고객이 클라우드에서 분석 및 기계 학습 솔루션을 통해 더 나은 결과를 얻을 수 있도록 돕는 일에 열정적입니다. 직장 밖에서는 피트니스, 요리, 친구 및 가족과 함께 좋은 시간을 보내는 것을 즐깁니다.
 비슈와 굽타 AWS Professional Services Analytics Practice의 선임 데이터 설계자입니다. 그는 고객이 빅 데이터 및 분석 솔루션을 구현하도록 돕습니다. 직장 밖에서는 가족과 함께 시간을 보내고, 여행하고, 새로운 음식을 맛보는 것을 즐깁니다.
비슈와 굽타 AWS Professional Services Analytics Practice의 선임 데이터 설계자입니다. 그는 고객이 빅 데이터 및 분석 솔루션을 구현하도록 돕습니다. 직장 밖에서는 가족과 함께 시간을 보내고, 여행하고, 새로운 음식을 맛보는 것을 즐깁니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoAiStream. Web3 데이터 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 미래 만들기 w Adryenn Ashley. 여기에서 액세스하십시오.
- PREIPO®로 PRE-IPO 회사의 주식을 사고 팔 수 있습니다. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- :있다
- :이다
- :아니
- :어디
- $UP
- 1
- 10
- 100
- 12
- 8
- a
- 소개
- ACCESS
- 따라서
- 계정
- 달성
- 가로질러
- 동작
- 비 환식
- 추가
- 이점
- 장점
- 후
- 집합
- All
- 수
- 수
- 이미
- 또한
- 아마존
- Amazon Web Services
- an
- 분석
- 분석
- 분석하다
- 및
- 어떤
- 아파치
- API를
- 어플리케이션
- 애플리케이션 개발
- 적당한
- 아키텍처
- 있군요
- 논의
- 인수
- AS
- At
- 속성
- 감사
- 가능
- AWS
- AWS 접착제
- AWS 전문 서비스
- 기반으로
- BE
- 된다
- 된
- 전에
- 존재
- 더 나은
- 사이에
- 큰
- 빅 데이터
- 두
- 파괴
- 빌드
- 비자 면제 프로그램에 해당하는 국가의 시민권을 가지고 있지만
- by
- 라는
- 통화
- CAN
- 케이스
- 가지 경우
- 목록
- 원인
- 이전 단계로 돌아가기
- 변경
- 검사
- 왼쪽 메뉴에서
- 클라우드
- 암호
- COM
- 결합
- 본문
- 공통의
- 기업
- 호환성
- 호환
- 완전한
- 복잡한
- 구성 요소
- 구성 요소들
- 계산
- 구성
- 확인하기
- 콘솔에서
- 합병하다
- 강화
- 요리
- 핵심
- 커버
- 만들
- 만든
- 생성
- 만들기
- Current
- 관습
- 고객
- 고객
- DAG
- 데이터
- 데이터 통합
- 데이터 처리
- 데이터 전략
- 데이터웨어 하우스
- 데이터베이스
- 데이터베이스
- 데이터 세트
- 날짜
- 날짜
- 날짜 시간
- 일
- 결정된
- 태만
- 전달
- 시연
- 의존
- 사용되지 않는
- 상세한
- 세부설명
- 개발
- 다르다
- 다른
- 디지털
- 디지털 미디어
- 직접
- 토론
- 분산
- 분산 시스템
- do
- 하지
- 하기
- 한
- ...동안
- e
- 이전
- 용이함
- 효과
- 제거
- 그렇지 않으면
- 가능
- 사용 가능
- 수
- 끝으로 종료
- 약혼
- 기사
- 향상
- 확인
- 엔터 버튼
- 환경
- 오류
- 에테르 (ETH)
- 이벤트
- 예
- 외
- 예외
- 있다
- 현존하는
- 존재
- 경험
- 체험
- 탐험 한
- 표현
- 외부
- 추출물
- 실패한
- 그릇된
- 가족
- 특색
- 추천
- 특징
- 입양 부모로서의 귀하의 적합성을 결정하기 위해 미국 이민국에
- 파일
- 필터링
- 최종적으로
- Find
- 피트니스
- 수행원
- 식품
- 럭셔리
- 체재
- 친구
- 에
- 가득 찬
- 수집
- 생성
- 유리
- Go
- 골프
- 통치
- 그룹
- 하둡
- 있다
- he
- 건강
- 도움이
- 도움이
- history
- 하이브
- 방법
- How To
- HTML
- HTTP
- HTTPS
- IAM
- ID
- 이상
- 아이디어
- 식별자
- if
- 설명하다
- 구현
- import
- in
- 심도
- 포함
- 포함
- 증가
- 증가
- 표시된
- 산업
- 정보
- 정보
- 처음에는
- 혁신적인
- 통찰력
- 설치
- 예
- 명령
- 통합 된
- 완성
- 관심
- 내부의
- 으로
- IT
- 일
- 작업
- JPG
- JSON
- 키
- 알려진
- 넓은
- 후에
- 최근
- 배우다
- 배우기
- 도서관
- 제한
- 명부
- 하중
- 지방의
- 장소 상에서
- 위치
- 기록
- 로그인
- 로깅
- 찾고
- 기계
- 기계 학습
- 만든
- 유지하다
- 확인
- 유튜브 영상을 만드는 것은
- 관리
- 구축
- 관리
- 조작
- 자료
- XNUMX월..
- 미디어
- 소개
- 메시지
- 통계
- 이주하는
- 최소의
- ML
- 수정
- 모듈
- 모니터
- 모니터링
- 배우기
- 절대로 필요한 것
- name
- 이름
- 이동
- 카테고리
- 필요한
- 필요
- 필요
- 요구
- 신제품
- 아무것도
- 지금
- of
- 제공
- on
- ONE
- 사람
- 만
- 열 수
- 오픈 소스
- 오픈 소스 코드
- 연산자
- 운영자
- 최적의
- 선택권
- 옵션
- or
- 조율 된
- 오케스트레이션
- 기타
- 우리의
- 결과
- 출력
- 외부
- 꾸러미
- 팬더
- 빵
- 매개 변수
- 파트너
- 패스
- 합격
- 열렬한
- 성능
- 권한
- 지속되는
- 관로
- 장소
- 플랫폼
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 전철기
- 정책
- 게시하다
- 잠재적으로
- 연습
- 전제 조건
- 너무 이른
- 이전에
- 방법
- 프로세스
- 처리
- 제품
- 링크를
- 전문가
- 프로필
- 투영
- 공급자
- 제공
- 제공
- Python
- 품질
- 쿼리
- 모집
- 범위
- 읽기
- 읽기
- 현실
- 실시간
- 최근
- 권하다
- 지방
- 규정하는
- 계전기
- 교체
- 대체
- 필수
- 요구조건 니즈
- 의지
- 제품 자료
- 각기
- 응답
- 결과
- 유지
- 연락해주세요
- 직위별
- 열
- 달리기
- 달리는
- s
- 찜하기
- 시나리오
- SDK
- 완벽하게
- 검색
- 섹션
- 안전해야합니다.
- 참조
- 찾으라
- 연장자
- 서버리스
- 서비스
- 설정
- 설치
- 껍질
- 영상을
- 표시
- 쇼
- 단순, 간단, 편리
- 단순화
- 이후
- 단일
- 스냅 사진
- 해결책
- 솔루션
- 일부
- 구체적인
- 지정
- 지출
- 성명서
- Status
- 단계
- 단계
- 아직도
- 저장
- 저장
- 전략
- 흐름
- 끈
- 성공한
- 이러한
- 충분한
- SUPPORT
- 지원
- 시스템은
- 테이블
- 받아
- 복용
- 태스크
- 팀
- 기술
- 이 템플릿
- 감사
- 그
- XNUMXD덴탈의
- 그들의
- 그들
- 그때
- 그곳에.
- Bowman의
- 그들
- 타사
- 이
- 을 통하여
- 시간
- 에
- 선로
- 변환
- 여행
- 참된
- 시도
- 화요일
- 돌린
- 두
- 유형
- ui
- 통일
- 단위
- 업데이트
- 업데이트
- 업데이트
- 업그레이드
- 업그레이드
- 업로드
- 용법
- 사용
- 유스 케이스
- 익숙한
- 사용자
- 사용
- 가치
- 마케팅은:
- 버전
- 를 통해
- 관측
- 보기
- 가시성
- 눈에 보이는
- 걸었다
- 필요
- 였다
- we
- 웹
- 웹 서비스
- 잘
- 뭐
- 언제
- 여부
- 어느
- 누구
- 의지
- 과
- 이내
- 없이
- 작업
- 워크 플로우
- 겠지
- 쓰다
- 쓴
- 당신
- 너의
- 제퍼 넷