작성자 별 이미지
When you are getting started with machine learning, logistic regression is one of the first algorithms you’ll add to your toolbox. It’s a simple and robust algorithm, commonly used for binary classification tasks.
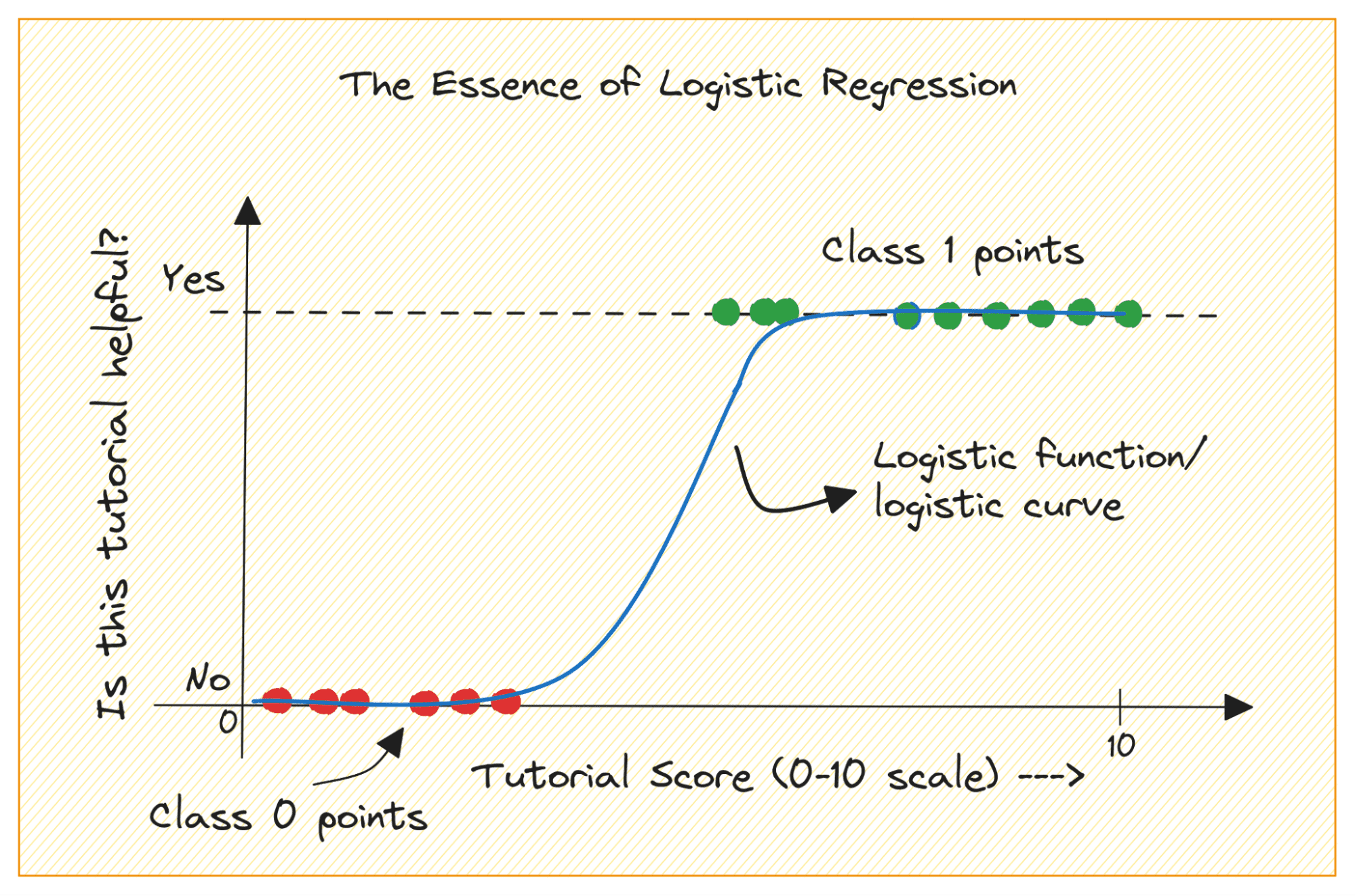
클래스 0과 1의 이진 분류 문제를 생각해 보세요. 로지스틱 회귀는 로지스틱 또는 시그모이드 함수를 입력 데이터에 맞추고 쿼리 데이터 포인트가 클래스 1에 속할 확률을 예측합니다. 흥미롭죠?
이 튜토리얼에서는 다음을 다루는 로지스틱 회귀에 대해 처음부터 배웁니다.
- 로지스틱(또는 시그모이드) 함수
- 선형 회귀에서 로지스틱 회귀로 이동하는 방법
- 로지스틱 회귀의 작동 방식
마지막으로 간단한 로지스틱 회귀 모델을 구축하겠습니다. 전리층에서 RADAR 반환을 분류합니다..
Before we learn more about logistic regression, let’s review how the logistic function works. The logistic (or sigmoid function) is given by:

시그모이드 함수를 그래프로 그리면 다음과 같습니다:
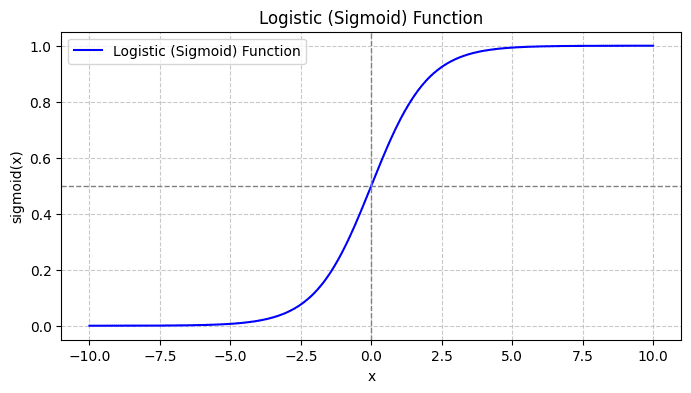
플롯에서 우리는 다음을 볼 수 있습니다.
- x = 0일 때 σ(x)는 0.5의 값을 취합니다.
- x가 +무한대에 가까워지면 σ(x)는 1에 가까워집니다.
- x가 -무한대에 가까워지면 σ(x)는 0에 가까워집니다.
따라서 모든 실제 입력에 대해 시그모이드 함수는 입력을 압축하여 [0, 1] 범위의 값을 취합니다.
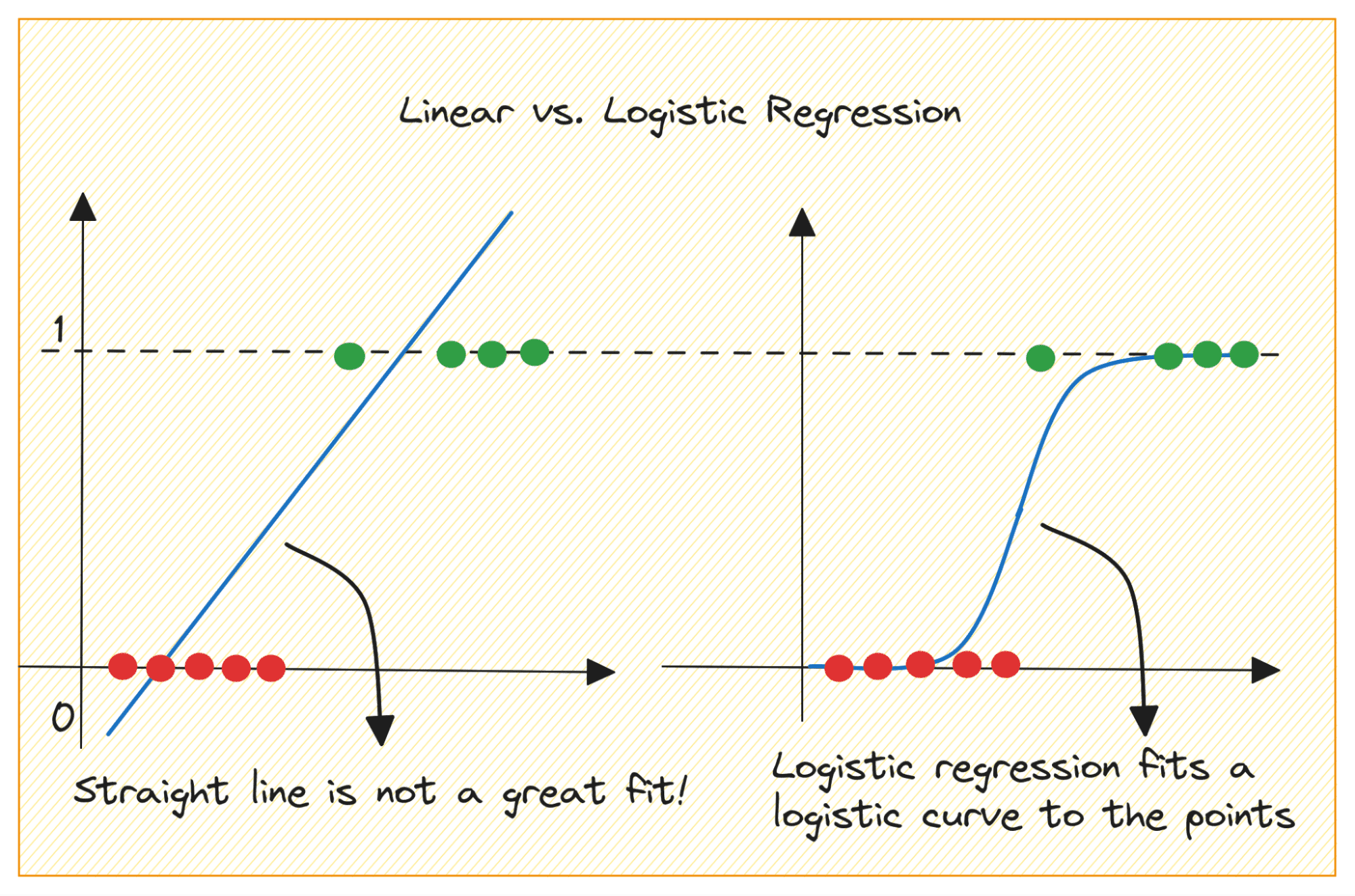
Let’s first discuss why we cannot use linear regression for a binary classification problem.
이진 분류 문제에서 출력은 범주형 레이블(0 또는 1)입니다. 선형 회귀는 0보다 작거나 1보다 클 수 있는 연속 값 출력을 예측하므로 당면한 문제에는 적합하지 않습니다.
또한 출력 레이블이 두 범주 중 하나에 속하는 경우 직선이 가장 적합하지 않을 수 있습니다.
작성자 별 이미지
그렇다면 선형 회귀에서 로지스틱 회귀로 어떻게 이동합니까? 선형 회귀에서 예측 결과는 다음과 같습니다.
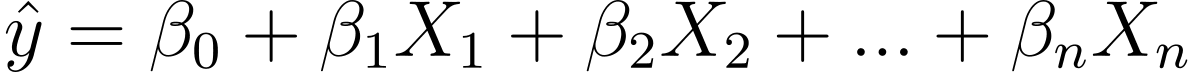
여기서 β는 계수이고 X_is는 예측 변수(또는 특징)입니다.
일반성을 잃지 않고 X_0 = 1이라고 가정해 보겠습니다.

그래서 좀 더 간결한 표현을 할 수 있습니다.
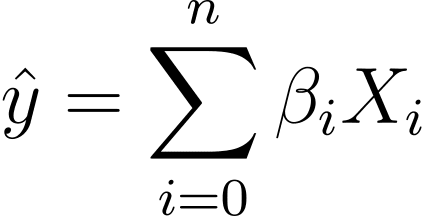
로지스틱 회귀에서는 [0,1] 구간의 예측 확률 p_i가 필요합니다. 우리는 로지스틱 함수가 입력을 압축하여 [0,1] 간격의 값을 취한다는 것을 알고 있습니다.
따라서 이 표현식을 로지스틱 함수에 대입하면 다음과 같은 예측 확률을 얻을 수 있습니다.
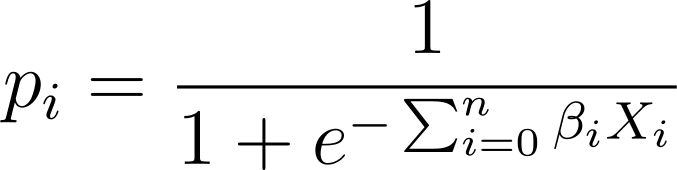
그렇다면 주어진 데이터 세트에 가장 적합한 물류 곡선을 어떻게 찾을 수 있을까요? 이에 답하기 위해 최대 우도 추정을 이해해 보겠습니다.
최대 우도 추정(MLE) is used to estimate the parameters of the logistic regression model by maximizing the likelihood function. Let’s break down the process of MLE in logistic regression and how the cost function is formulated for optimization using gradient descent.
최대 가능성 추정 분석
논의된 바와 같이, 우리는 하나 이상의 예측 변수(또는 특징)의 함수로 이진 결과가 발생할 확률을 모델링합니다.
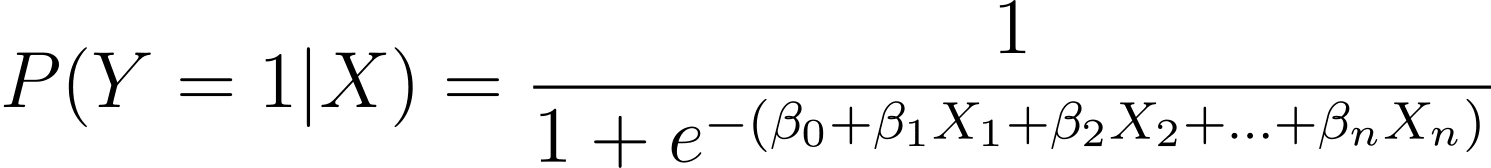
Here, the βs are the model parameters or coefficients. X_1, X_2,…, X_n are the predictor variables.
MLE는 관측된 데이터의 가능성을 최대화하는 β 값을 찾는 것을 목표로 합니다. L(β)로 표시되는 우도 함수는 로지스틱 회귀 모델에서 주어진 예측 변수 값에 대해 주어진 결과를 관찰할 확률을 나타냅니다.
로그 우도 함수 공식화
To simplify the optimization process, it’s common to work with the log-likelihood function. Because it transforms products of probabilities into sums of log probabilities.
로지스틱 회귀에 대한 로그 우도 함수는 다음과 같이 제공됩니다.
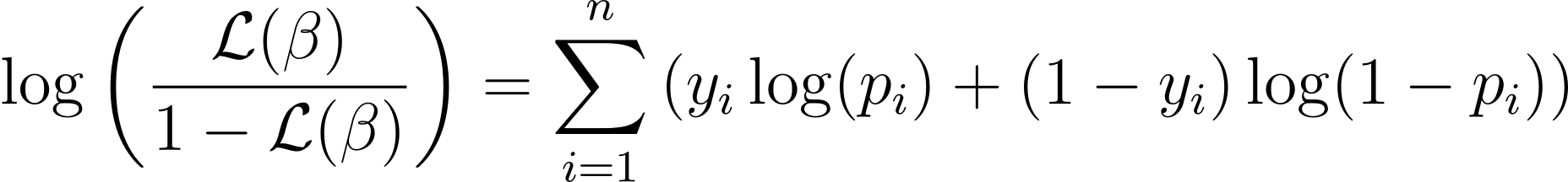
Now that we know the essence of log-likelihood, let’s proceed to formulate the cost function for logistic regression and subsequently gradient descent for finding the best model parameters
로지스틱 회귀의 비용 함수
로지스틱 회귀 모델을 최적화하려면 로그 가능성을 최대화해야 합니다. 따라서 음의 로그 가능성을 비용 함수로 사용하여 훈련 중에 최소화할 수 있습니다. 종종 로지스틱 손실이라고도 하는 음의 로그 우도는 다음과 같이 정의됩니다.
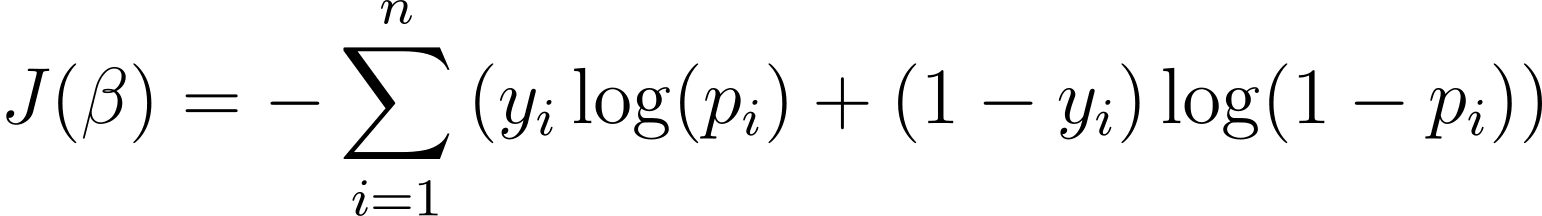
따라서 학습 알고리즘의 목표는 ? 이 비용 함수를 최소화합니다. 경사하강법은 이 비용 함수의 최소값을 찾기 위해 일반적으로 사용되는 최적화 알고리즘입니다.
로지스틱 회귀의 경사하강법
경사 하강 법 β에 대한 비용 함수 기울기의 반대 방향으로 모델 매개변수 β를 업데이트하는 반복 최적화 알고리즘입니다. 경사 하강법을 사용한 로지스틱 회귀에 대한 t+1 단계의 업데이트 규칙은 다음과 같습니다.
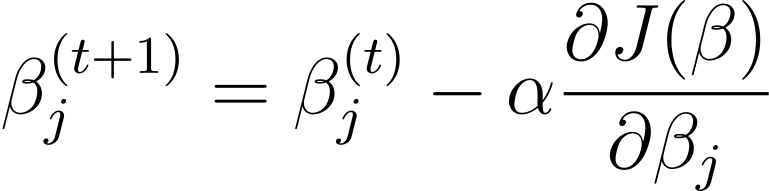
여기서 α는 학습률입니다.
부분 도함수는 체인 규칙을 사용하여 계산할 수 있습니다. 경사하강법은 로지스틱 손실을 최소화하는 것을 목표로 수렴할 때까지 매개변수를 반복적으로 업데이트합니다. 수렴하면서 관측된 데이터의 우도를 최대화하는 최적의 β 값을 찾습니다.
이제 로지스틱 회귀가 어떻게 작동하는지 알았으니 scikit-learn 라이브러리를 사용하여 예측 모델을 구축해 보겠습니다.
우리는 UCI 기계 학습 저장소의 ionosphere 데이터 세트 이 튜토리얼에서는. 데이터 세트는 34개의 숫자 특징으로 구성됩니다. 출력은 '좋음' 또는 '나쁨'('g' 또는 'b'로 표시됨) 중 하나인 이진수입니다. 출력 라벨 '양호'는 전리층에서 일부 구조를 감지한 RADAR 반환을 나타냅니다.
1단계 - 데이터세트 로드
먼저 데이터 세트를 다운로드하여 Pandas 데이터 프레임으로 읽습니다.
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)2단계 - 데이터 세트 탐색
Let’s take a look at the first few rows of the dataframe:
# Display the first few rows of the DataFrame
df.head()
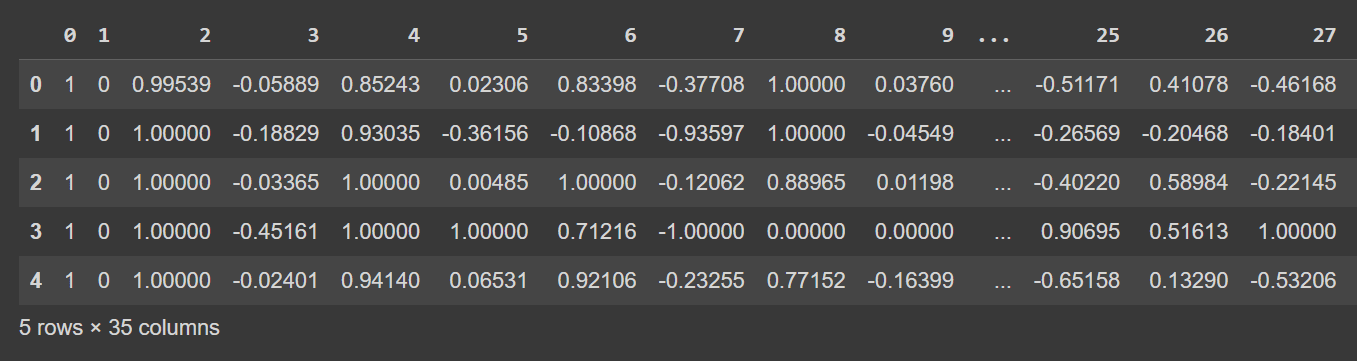
df.head()의 잘린 출력
Let’s get some information about the dataset: the number of non-null values and the data types of each of the columns:
# Get information about the dataset
print(df.info())
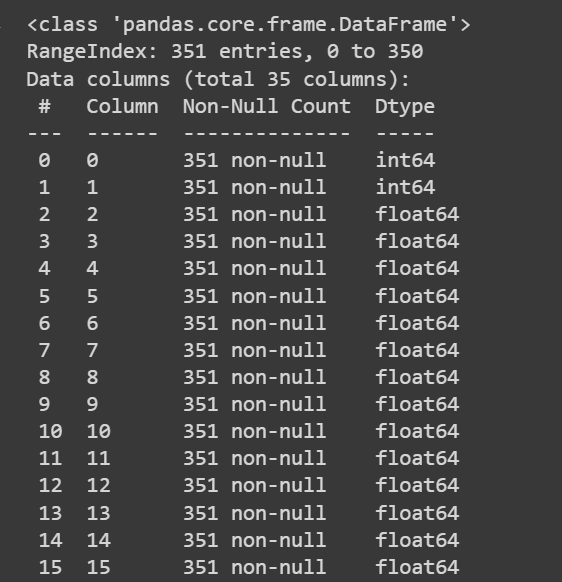 df.info()의 잘린 출력
df.info()의 잘린 출력
우리는 모든 숫자 특징을 가지고 있기 때문에 다음을 사용하여 몇 가지 기술 통계를 얻을 수도 있습니다. describe() 데이터프레임의 메소드:
# Get descriptive statistics of the dataset
print(df.describe())
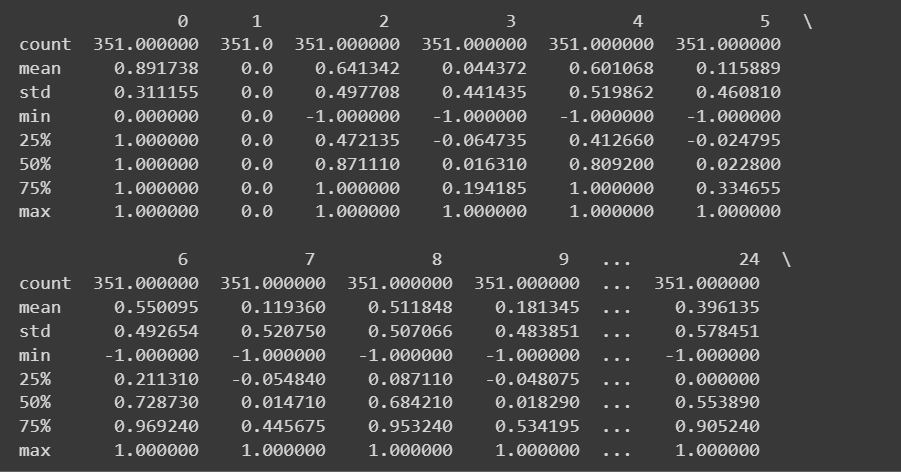
df.describe()의 잘린 출력
열 이름은 현재 레이블을 포함하여 0부터 34까지입니다. 데이터세트는 열에 대해 설명적인 이름을 제공하지 않으므로 다음과 같이 데이터 프레임의 열 이름을 바꿀 수 있는 경우 attribute_1 ~ attribute_34로 참조합니다.
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
참고: 이 단계는 전적으로 선택 사항입니다. 원하는 경우 기본 열 이름을 사용할 수 있습니다.
# Display the first few rows of the DataFrame
df.head()
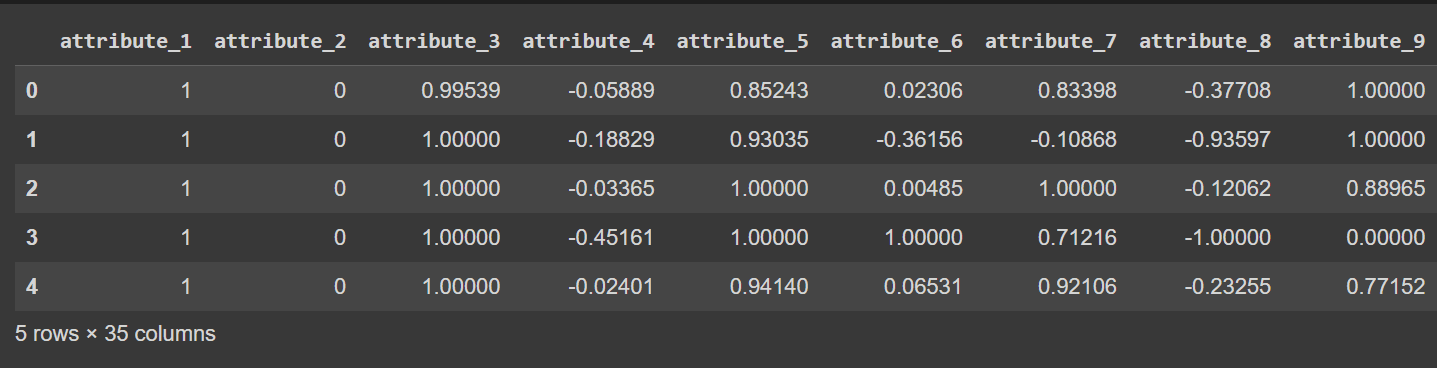
df.head()의 잘린 출력 [열 이름을 바꾼 후]
3단계 - 클래스 레이블 이름 바꾸기 및 클래스 분포 시각화
출력 클래스 레이블은 'g'와 'b'이므로 각각 1과 0에 매핑해야 합니다. 당신은 그것을 사용하여 그것을 할 수 있습니다 map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
클래스 라벨의 분포를 시각화해 보겠습니다.
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
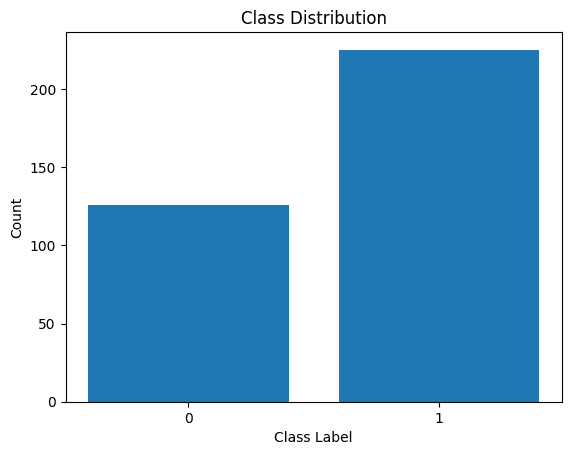
클래스 라벨 배포
분포에 불균형이 있음을 알 수 있습니다. 클래스 1보다 클래스 0에 속하는 레코드가 더 많습니다. 로지스틱 회귀 모델을 구축할 때 이러한 클래스 불균형을 처리하겠습니다.
5단계 – 데이터세트 전처리
다음과 같이 기능과 출력 라벨을 수집해 보겠습니다.
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
데이터 세트를 학습 세트와 테스트 세트로 분할한 후 데이터 세트를 전처리해야 합니다.
숫자 특성이 많을 경우(각각 잠재적으로 서로 다른 규모) 숫자 특성을 전처리해야 합니다. 일반적인 방법은 평균과 단위 분산이 0인 분포를 따르도록 변환하는 것입니다.
XNUMXD덴탈의 StandardScaler scikit-learn의 전처리 모듈이 이를 달성하는 데 도움이 됩니다.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])6단계 - 로지스틱 회귀 모델 구축
이제 로지스틱 회귀 분류기를 인스턴스화할 수 있습니다. 그만큼 LogisticRegression 클래스는 scikit-learn의 선형_모델 모듈의 일부입니다.
우리가 class_weight 매개변수를 '균형'으로 설정합니다. 이는 클래스 불균형을 설명하는 데 도움이 됩니다. 클래스의 레코드 수에 반비례하여 각 클래스에 가중치를 할당합니다.
클래스를 인스턴스화한 후 모델을 교육 데이터 세트에 맞출 수 있습니다.
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)7단계 - 로지스틱 회귀 모델 평가
당신은 predict() 모델의 예측을 얻는 방법.
정확도 점수 외에도 정밀도, 재현율, F1 점수와 같은 측정항목이 포함된 분류 보고서를 얻을 수도 있습니다.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
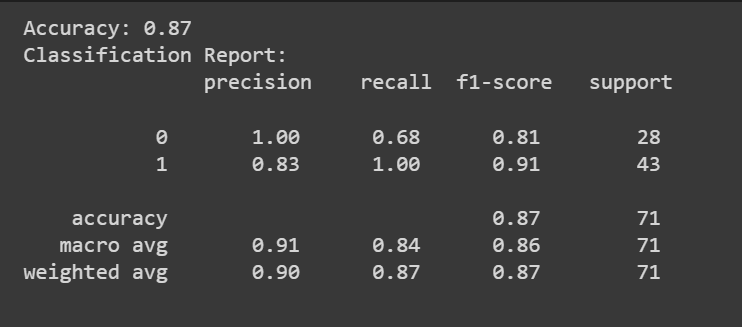
축하합니다. 첫 번째 로지스틱 회귀 모델을 코딩했습니다!
이 튜토리얼에서는 이론과 수학부터 로지스틱 회귀 분류기 코딩까지 로지스틱 회귀에 대해 자세히 배웠습니다.
다음 단계로 선택한 적절한 데이터세트에 대한 로지스틱 회귀 모델을 구축해 보세요.
Ionosphere 데이터세트는 다음에 따라 라이센스가 부여됩니다. 크리에이티브 커먼즈 저작자 표시 4.0 국제 (CC BY 4.0) 라이센스:
Sigillito, V., Wing, S., Hutton, L. 및 Baker, K.. (1989). 전리층. UCI 머신러닝 저장소. https://doi.org/10.24432/C5W01B.
발라 프리야 C 인도 출신의 개발자이자 테크니컬 라이터입니다. 그녀는 수학, 프로그래밍, 데이터 과학 및 콘텐츠 제작의 교차점에서 일하는 것을 좋아합니다. 그녀의 관심 분야와 전문 분야는 DevOps, 데이터 과학 및 자연어 처리입니다. 그녀는 읽기, 쓰기, 코딩, 커피를 즐깁니다! 현재 그녀는 자습서, 사용 방법 가이드, 의견 등을 작성하여 개발자 커뮤니티와 지식을 배우고 공유하는 작업을 하고 있습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :이다
- :아니
- $UP
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- 소개
- 계정
- 달성
- 더하다
- 또한
- 후
- 목표
- 연산
- 알고리즘
- All
- 또한
- an
- 및
- 답변
- 구혼
- 있군요
- 지역
- AS
- 취하다
- At
- 저작
- b
- 빵 굽는 사람
- 균형이 잡힌 자
- 바
- BE
- 때문에
- 귀속
- BEST
- 흩어져
- 빌드
- 건물
- by
- 전화
- CAN
- 카테고리
- 체인
- 선택
- 수업
- 수업
- 분류
- 코드화 된
- 코딩
- 수집
- 단
- 열
- 공통의
- 일반적으로
- 평민
- 커뮤니티
- 구성
- 간결한
- 함유량
- 콘텐츠 제작
- 변하게 하다
- 비용
- 피복
- 만들
- 창조
- 현재
- 곡선
- 데이터
- 데이터 점수
- 데이터 과학
- 데이터 세트
- 태만
- 한정된
- 파생 상품
- 세부 묘사
- 탐지 된
- 개발자
- 개발자
- 다른
- 방향
- 토론
- 논의 된
- 디스플레이
- 분포
- do
- 하지
- 아래 (down)
- 다운로드
- ...동안
- 마다
- 에센스
- 견적
- 평가
- 전문적 지식
- 탐색
- 표현
- 특징
- 를
- Find
- 발견
- finds
- 먼저,
- 맞게
- 따라
- 다음
- 럭셔리
- FRAME
- 에
- 기능
- 얻을
- 점점
- 주어진
- Go
- 골
- 구글
- 큰
- 육로
- 안내서
- 손
- 핸들
- 있다
- 도움
- 도움이
- 그녀의
- 방법
- HTTPS
- ICS
- if
- 불규형
- import
- in
- 포함
- 색인
- 인도
- 색인
- 정보
- 입력
- 입력
- 관심
- 흥미있는
- 교차
- 으로
- IT
- 다만
- 너 겟츠
- 알아
- 지식
- 라벨
- 레이블
- 언어
- 배우다
- 배운
- 배우기
- 적게
- 하자
- 도서관
- 특허
- 라이센스
- 처럼
- 있을 수 있는 일
- 좋아하는
- 라인
- 로드
- 기록
- 보기
- 같이
- 오프
- 기계
- 기계 학습
- 확인
- .
- 지도
- math
- 매트플롯립
- 극대화하다
- 최대화
- 최고
- XNUMX월..
- 평균
- 방법
- 통계
- 최소화
- 최저한의
- 모델
- 모델
- 모듈
- 배우기
- 움직임
- 이름
- 자연의
- 자연어
- 자연 언어 처리
- 필요
- 부정
- 다음 것
- 번호
- 관찰
- of
- 자주
- on
- ONE
- 의견
- 반대
- 최적의
- 최적화
- 최적화
- or
- 결과
- 결과
- 출력
- 출력
- 팬더
- 매개 변수
- 매개 변수
- 부품
- 개
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 포인트 적립
- 전철기
- 잠재적으로
- Precision
- 예측
- 예측
- 예언하는
- Predictor
- 예측
- 취하다
- 확률
- 문제
- 진행
- 방법
- 처리
- 제품
- 프로그램 작성
- 제공
- 전혀
- Python
- 레이더
- 범위
- 율
- 읽기
- 읽기
- 현실
- 기록
- 참조
- 의미
- 되돌아옴
- 신고
- 저장소
- 대표
- 의뢰
- 점
- 각기
- 반품
- 리뷰
- 강력한
- 통치
- s
- 과학
- 사이 킷 학습
- 점수
- 참조
- 감각
- 세트
- 설정
- 공유
- 그녀
- 표시
- 단순, 간단, 편리
- 단순화
- So
- 일부
- 분열
- 시작
- 통계
- 단계
- 직진
- 구조
- 그후
- 이러한
- 적당한
- 합계
- 받아
- 소요
- 목표
- 작업
- 테크니컬
- test
- 지원
- 보다
- 그
- XNUMXD덴탈의
- 그들
- 이론
- 그곳에.
- 따라서
- 그들
- 이
- 을 통하여
- 에
- 도구 상자
- Train
- 훈련 된
- 트레이닝
- 변환
- 변환
- 시도
- 지도 시간
- 자습서
- 두
- 유형
- 아래에
- 이해
- 단위
- 업데이트
- 업데이트
- URL
- us
- 미국 계정
- 사용
- 익숙한
- 사용
- 가치
- 마케팅은:
- 시각화
- we
- 언제
- 어느
- why
- 위키 백과
- 의지
- 비행
- 과
- 작업
- 일하는
- 일
- 겠지
- 작가
- 쓰기
- X
- 예
- 당신
- 너의
- 제퍼 넷
- 제로







