생성적 AI 워크로드에 가장 유용한 애플리케이션 패턴 중 하나는 RAG(Retrieval Augmented Generation)입니다. RAG 패턴에서는 임베딩에 대한 유사성 검색을 수행하여 입력 프롬프트와 관련된 참조 콘텐츠를 찾습니다. 임베딩은 텍스트 본문의 정보 콘텐츠를 캡처하여 NLP(자연어 처리) 모델이 숫자 형식의 언어와 함께 작동할 수 있도록 합니다. 임베딩은 단지 부동 소수점 숫자의 벡터이므로 이를 분석하여 세 가지 중요한 질문에 답할 수 있습니다. 참조 데이터가 시간이 지남에 따라 변경됩니까? 시간이 지남에 따라 사용자가 묻는 질문이 바뀌나요? 마지막으로, 우리의 참조 데이터가 질문을 얼마나 잘 다루고 있습니까?
이 게시물에서는 임베딩 벡터 분석 및 임베딩 드리프트 신호 감지에 대한 몇 가지 고려 사항에 대해 알아봅니다. 임베딩은 일반 NLP 모델과 특히 생성 AI 솔루션의 중요한 데이터 소스이기 때문에 임베딩이 시간에 따라 변하는지(드리프트) 여부를 측정하는 방법이 필요합니다. 이 게시물에서는 다음에서 배포된 대규모 언어 모델(LLMS)을 사용하여 클러스터링 기술을 사용하여 임베딩 벡터에 대한 드리프트 감지를 수행하는 예를 볼 수 있습니다. Amazon SageMaker 점프스타트. 또한 엔드투엔드 샘플 애플리케이션 또는 선택적으로 애플리케이션의 하위 집합을 포함하여 제공된 두 가지 예제를 통해 이러한 개념을 탐색할 수도 있습니다.
RAG 개요
XNUMXD덴탈의 RAG 패턴 PDF 문서, Wiki 기사 또는 통화 기록과 같은 외부 소스에서 지식을 검색한 다음 해당 지식을 사용하여 LLM으로 전송된 지침 프롬프트를 강화할 수 있습니다. 이를 통해 LLM은 응답을 생성할 때 더 관련성 있는 정보를 참조할 수 있습니다. 예를 들어 LLM에게 초콜릿 칩 쿠키 만드는 방법을 묻는 경우 자신의 레시피 라이브러리에 있는 정보가 포함될 수 있습니다. 이 패턴에서는 레시피 텍스트가 임베딩 모델을 사용하여 임베딩 벡터로 변환되고 벡터 데이터베이스에 저장됩니다. 들어오는 질문은 임베딩으로 변환된 후 벡터 데이터베이스가 유사성 검색을 실행하여 관련 콘텐츠를 찾습니다. 그런 다음 질문과 참조 데이터가 LLM 프롬프트로 이동됩니다.
생성된 임베딩 벡터와 해당 벡터에 대한 드리프트 분석을 수행하는 방법을 자세히 살펴보겠습니다.
임베딩 벡터 분석
임베딩 벡터는 데이터를 숫자로 표현한 것이므로 이러한 벡터를 분석하면 나중에 드리프트의 잠재적 신호를 감지하는 데 사용할 수 있는 참조 데이터에 대한 통찰력을 얻을 수 있습니다. 임베딩 벡터는 n차원 공간의 항목을 나타냅니다. 여기서 n은 대개 큰 경우가 있습니다. 예를 들어, 이 게시물에 사용된 GPT-J 6B 모델은 크기 4096의 벡터를 생성합니다. 드리프트를 측정하려면 애플리케이션이 참조 데이터와 수신 프롬프트 모두에 대한 임베딩 벡터를 캡처한다고 가정합니다.
먼저 PCA(Principal Component Analysis)를 사용하여 차원 축소를 수행합니다. PCA는 데이터의 분산을 대부분 유지하면서 차원 수를 줄이려고 합니다. 이 경우, 우리는 분산의 95%를 유지하는 차원의 수를 찾으려고 노력합니다. 이는 두 표준 편차 내의 모든 것을 포착해야 합니다.
그런 다음 K-평균을 사용하여 클러스터 중심 집합을 식별합니다. K-평균은 각 클러스터가 상대적으로 작고 클러스터가 가능한 한 서로 멀리 떨어져 있도록 포인트를 클러스터로 그룹화하려고 합니다.
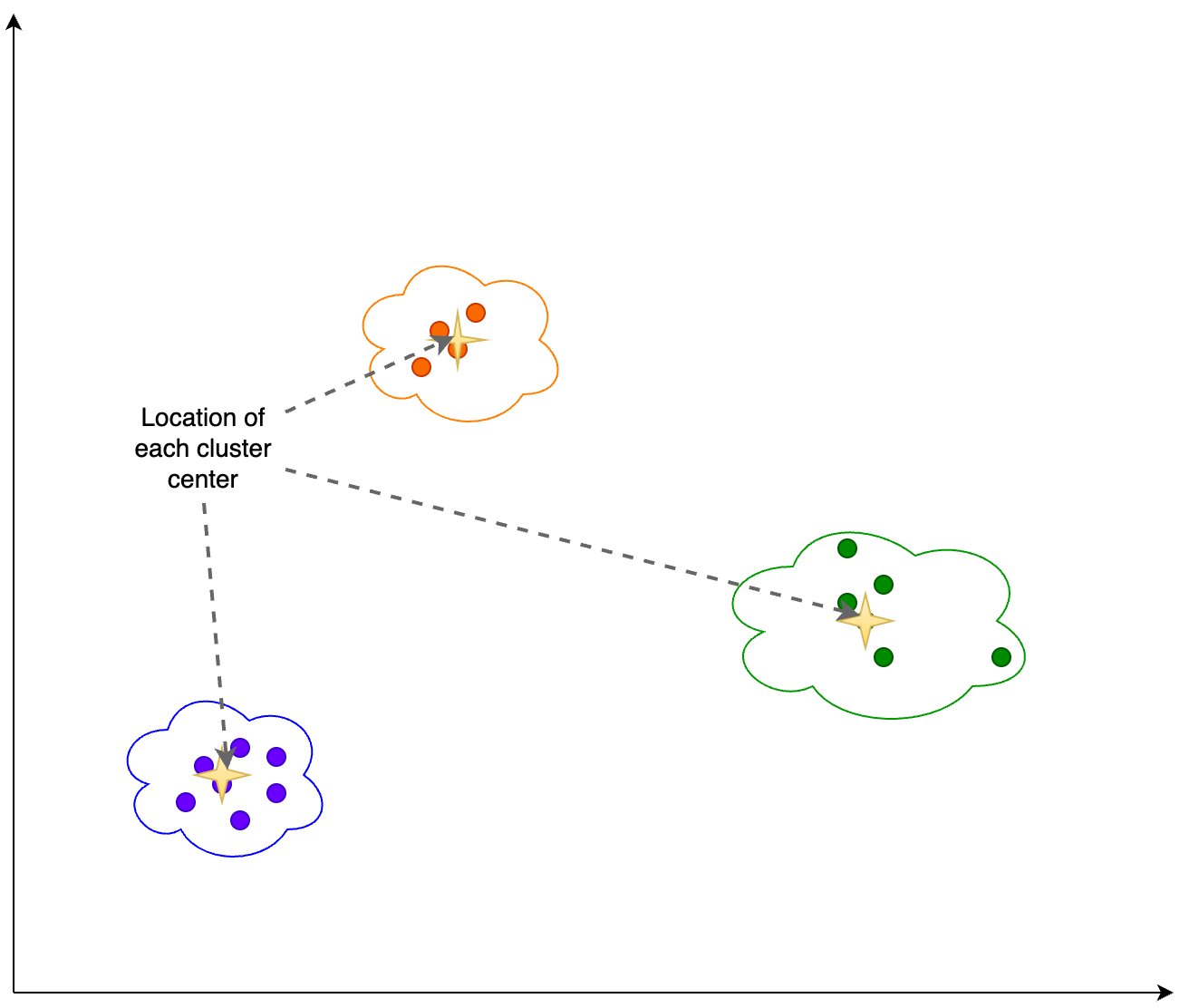
다음 그림에 표시된 클러스터링 출력을 기반으로 다음 정보를 계산합니다.
- 분산의 95%를 설명하는 PCA의 차원 수
- 각 클러스터 중심 또는 중심의 위치
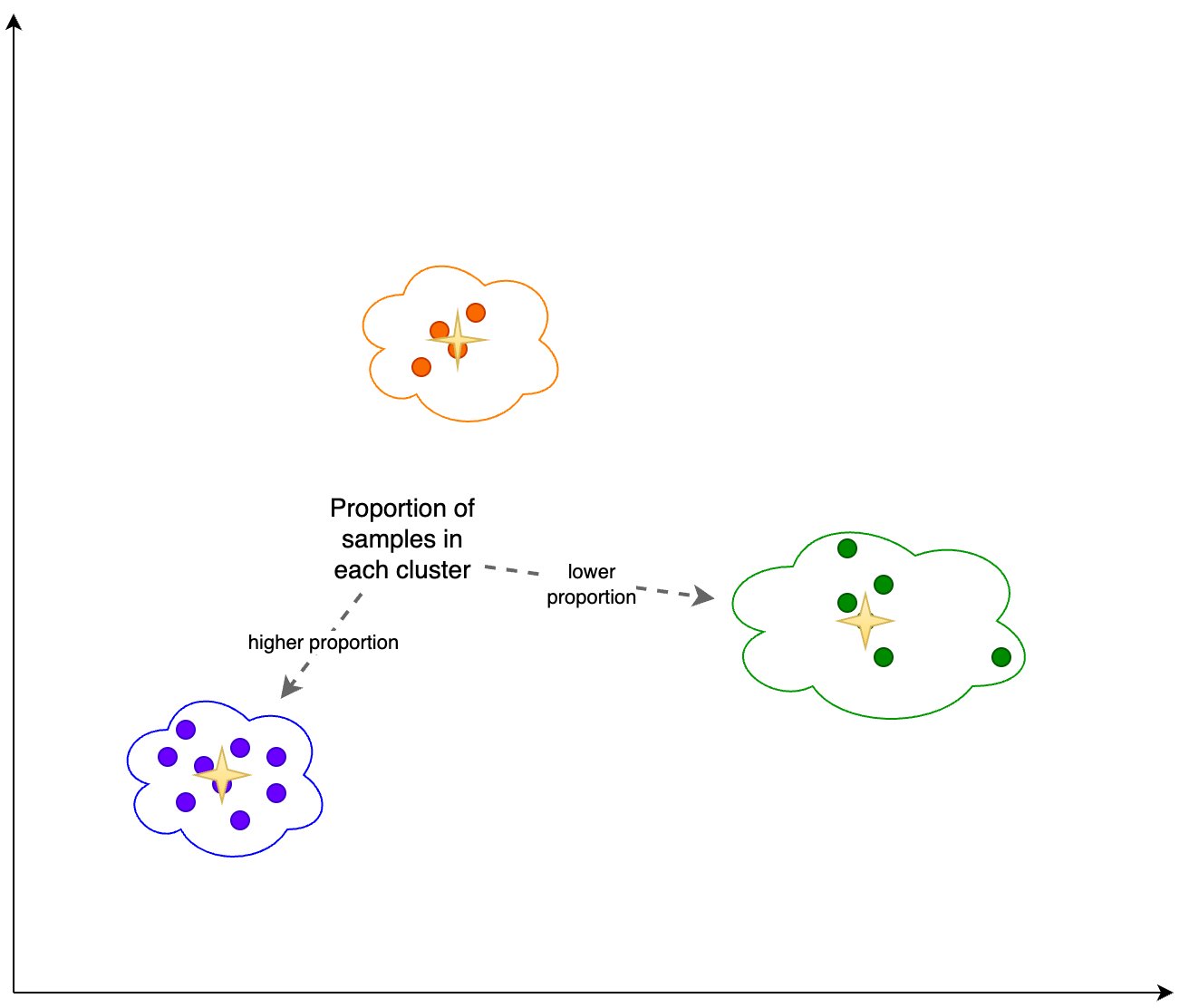
또한 다음 그림과 같이 각 클러스터의 샘플 비율(더 높거나 더 낮음)을 살펴봅니다.
마지막으로 이 분석을 사용하여 다음을 계산합니다.
- 관성 – 관성은 클러스터 중심까지의 거리 제곱의 합으로, K-평균을 사용하여 데이터가 얼마나 잘 클러스터링되었는지 측정합니다.
- 실루엣 점수 – 실루엣 점수는 군집 내 일관성을 검증하는 척도이며 범위는 -1~1입니다. 값이 1에 가까울수록 군집 내 포인트가 동일한 군집 내 다른 포인트와 가깝고 멀리 떨어져 있음을 의미합니다. 다른 클러스터의 포인트. 실루엣 점수의 시각적 표현은 다음 그림에서 볼 수 있습니다.

소스 참조 데이터와 프롬프트 모두에 대한 임베딩 스냅샷을 위해 이 정보를 주기적으로 캡처할 수 있습니다. 이 데이터를 캡처하면 임베딩 드리프트의 잠재적인 신호를 분석할 수 있습니다.
임베딩 드리프트 감지
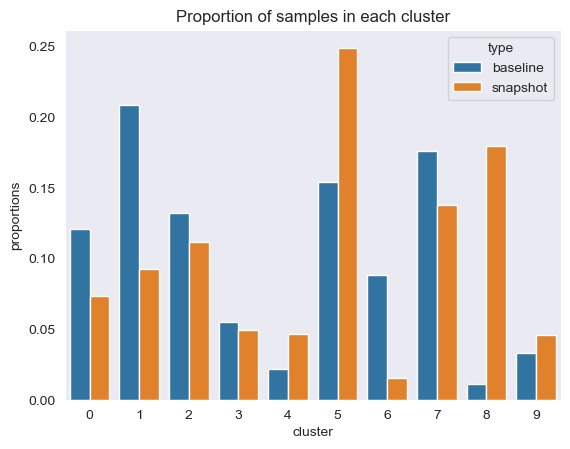
주기적으로 참조 데이터 임베딩과 프롬프트 임베딩이 포함된 데이터의 스냅샷을 통해 클러스터링 정보를 비교할 수 있습니다. 먼저, 임베딩 데이터 변동의 95%, 관성 및 클러스터링 작업의 실루엣 점수를 설명하는 데 필요한 차원 수를 비교할 수 있습니다. 다음 표에서 볼 수 있듯이, 기준선과 비교하여 임베딩의 최신 스냅샷에는 분산을 설명하기 위해 39개의 차원이 더 필요하며 이는 데이터가 더 분산되어 있음을 나타냅니다. 관성이 증가하여 샘플이 클러스터 중심에서 더 멀리 떨어져 있음을 나타냅니다. 또한 실루엣 점수가 낮아져 클러스터가 제대로 정의되지 않았음을 나타냅니다. 신속한 데이터의 경우 이는 시스템에 들어오는 질문 유형이 더 많은 주제를 다루고 있음을 나타낼 수 있습니다.
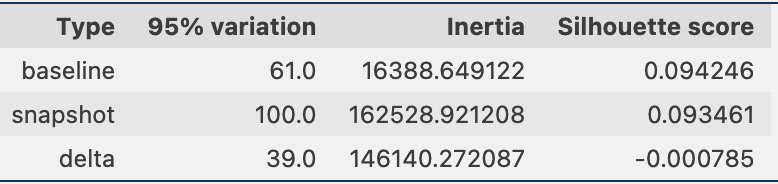
다음으로, 다음 그림에서는 시간이 지남에 따라 각 클러스터의 샘플 비율이 어떻게 변했는지 확인할 수 있습니다. 이를 통해 최신 참조 데이터가 이전 세트와 대체로 유사한지, 아니면 새로운 영역을 포괄하는지 확인할 수 있습니다.
마지막으로 다음 표와 같이 클러스터 중심이 이동하는지 확인할 수 있으며, 이는 클러스터 정보에 드리프트를 표시합니다.

들어오는 질문에 대한 참조 데이터 범위
또한 참조 데이터가 들어오는 질문과 얼마나 잘 일치하는지 평가할 수도 있습니다. 이를 위해 각 프롬프트 임베딩을 참조 데이터 클러스터에 할당합니다. 각 프롬프트에서 해당 중심까지의 거리를 계산하고 해당 거리의 평균, 중앙값 및 표준 편차를 확인합니다. 우리는 해당 정보를 저장하고 시간이 지남에 따라 어떻게 변하는지 확인할 수 있습니다.
다음 그림은 시간에 따라 프롬프트 임베딩과 참조 데이터 센터 사이의 거리를 분석하는 예를 보여줍니다.

보시다시피 프롬프트 임베딩과 참조 데이터 센터 간의 평균, 중앙값 및 표준 편차 거리 통계는 초기 기준과 최신 스냅샷 사이에서 감소하고 있습니다. 거리의 절대값을 해석하기는 어렵지만 추세를 사용하여 참조 데이터와 들어오는 질문 간의 의미적 중첩이 시간이 지남에 따라 좋아지는지 악화되는지 확인할 수 있습니다.
샘플 애플리케이션
이전 섹션에서 논의한 실험 결과를 수집하기 위해 SageMaker JumpStart를 통해 배포되고 호스팅되는 임베딩 및 생성 모델을 사용하여 RAG 패턴을 구현하는 샘플 애플리케이션을 구축했습니다. 아마존 세이지 메이커 실시간 엔드포인트.
애플리케이션에는 세 가지 핵심 구성 요소가 있습니다.
- 우리는 LangChain을 사용하여 RAG 오케스트레이션 레이어와 결합된 프롬프트 캡처용 사용자 인터페이스를 포함하는 대화형 흐름을 사용합니다.
- 데이터 처리 흐름은 PDF 문서에서 데이터를 추출하고 PDF 문서에 저장되는 임베딩을 생성합니다. 아마존 오픈서치 서비스. 또한 애플리케이션의 최종 임베딩 드리프트 분석 구성 요소에서도 이를 사용합니다.
- 임베딩은 다음에서 캡처됩니다. 아마존 단순 스토리지 서비스 (아마존 S3)을 통해 아마존 키네 시스 데이터 파이어 호스, 그리고 우리는 다음의 조합을 실행합니다 AWS 접착제 ETL(추출, 변환, 로드) 작업과 Jupyter Notebook을 사용하여 임베딩 분석을 수행합니다.
다음 다이어그램은 엔드투엔드 아키텍처를 보여줍니다.
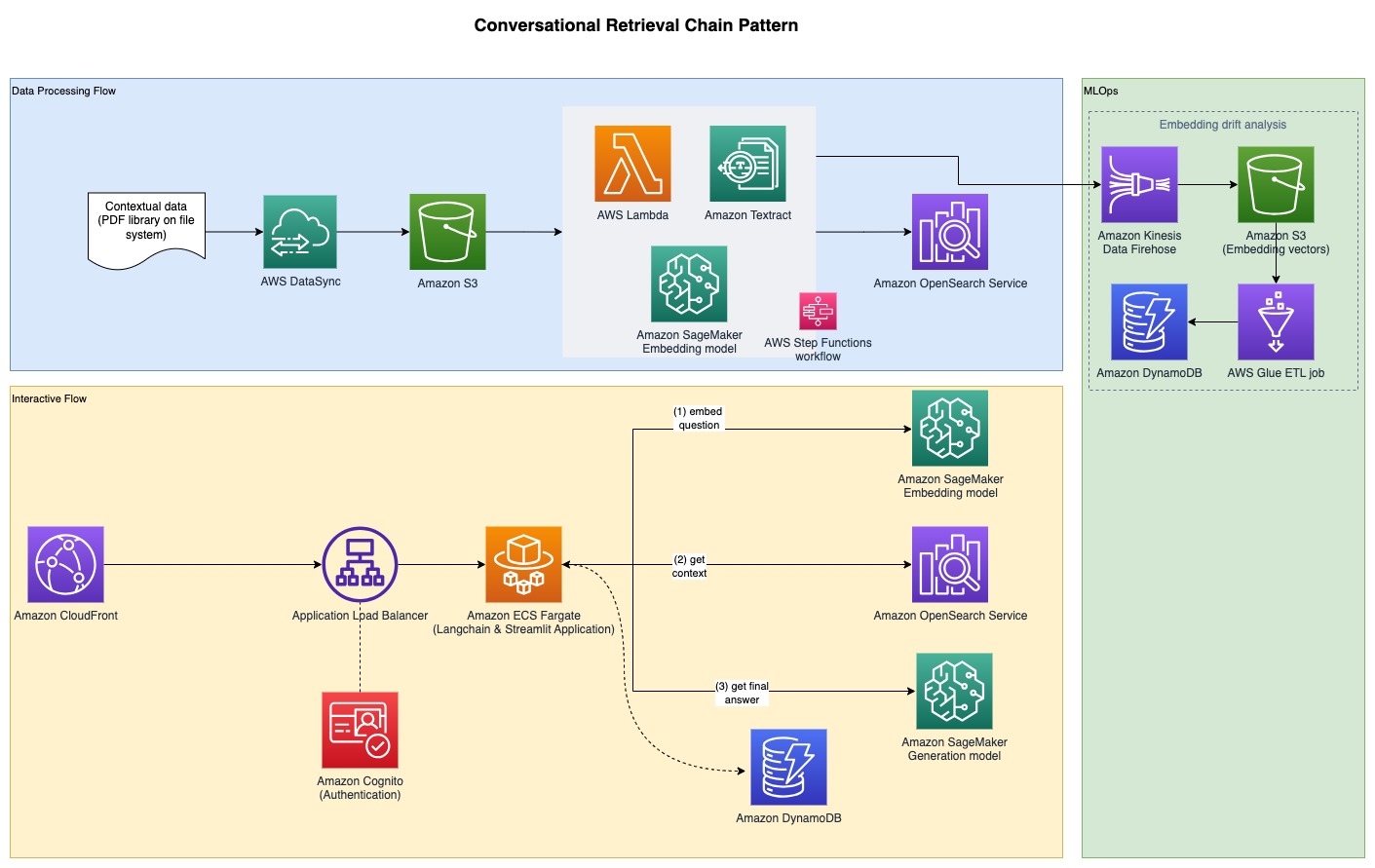
전체 샘플 코드는 다음에서 확인할 수 있습니다. GitHub의. 제공된 코드는 두 가지 패턴으로 제공됩니다.
- Streamlit 프런트엔드를 사용한 샘플 풀 스택 애플리케이션 – 이는 프롬프트 캡처를 위해 Streamlit을 사용하는 사용자 인터페이스를 포함하고 RAG 오케스트레이션 레이어와 결합되어 다음에서 실행되는 LangChain을 사용하여 엔드투엔드 애플리케이션을 제공합니다. Amazon 탄력적 컨테이너 서비스 (아마존 ECS) AWS 파게이트
- 백엔드 애플리케이션 – 전체 애플리케이션 스택을 배포하고 싶지 않은 경우 선택적으로 백엔드만 배포하도록 선택할 수 있습니다. AWS 클라우드 개발 키트 (AWS CDK) 스택을 만든 다음 제공된 Jupyter 노트북을 사용하여 LangChain을 사용하여 RAG 오케스트레이션을 수행합니다.
제공된 패턴을 생성하려면 생성 및 텍스트 임베딩 모델 배포부터 시작하여 추가 전제 조건으로 넘어가는 다음 섹션에 자세히 설명된 몇 가지 전제 조건이 있습니다.
SageMaker JumpStart를 통해 모델 배포
두 패턴 모두 임베딩 모델과 생성 모델의 배포를 가정합니다. 이를 위해 SageMaker JumpStart에서 두 가지 모델을 배포합니다. 첫 번째 모델인 GPT-J 6B는 임베딩 모델로 사용되었으며 두 번째 모델인 Falcon-40b는 텍스트 생성에 사용되었습니다.
SageMaker JumpStart를 통해 이러한 각 모델을 배포할 수 있습니다. AWS 관리 콘솔, 아마존 세이지 메이커 스튜디오또는 프로그래밍 방식으로. 자세한 내용은 다음을 참조하세요. JumpStart 기초 모델을 사용하는 방법. 배포를 단순화하기 위해 다음을 사용할 수 있습니다. 제공된 노트북 SageMaker JumpStart에서 자동으로 생성된 노트북에서 파생됩니다. 이 노트북은 SageMaker JumpStart ML 허브에서 모델을 가져와 두 개의 별도 SageMaker 실시간 엔드포인트에 배포합니다.
샘플 노트북에는 정리 섹션도 있습니다. 방금 배포한 엔드포인트가 삭제되므로 해당 섹션을 아직 실행하지 마세요. 연습이 끝나면 정리가 완료됩니다.
엔드포인트가 성공적으로 배포되었음을 확인한 후에는 전체 샘플 애플리케이션을 배포할 준비가 된 것입니다. 그러나 백엔드 및 분석 노트북만 탐색하는 데 더 관심이 있는 경우 선택적으로 해당 노트북만 배포할 수 있으며 이에 대해서는 다음 섹션에서 설명합니다.
옵션 1: 백엔드 애플리케이션만 배포
이 패턴을 사용하면 백엔드 솔루션만 배포하고 Jupyter 노트북을 사용하여 솔루션과 상호 작용할 수 있습니다. 전체 프런트엔드 인터페이스를 구축하지 않으려면 이 패턴을 사용하세요.
사전 조건
다음과 같은 전제 조건이 있어야 합니다.
- SageMaker JumpStart 모델 엔드포인트 배포 – 이전에 설명한 대로 SageMaker JumpStart를 사용하여 SageMaker 실시간 엔드포인트에 모델을 배포합니다.
- 배포 매개변수 – 다음을 기록하십시오.
- 텍스트 모델 끝점 이름 – SageMaker JumpStart로 배포된 텍스트 생성 모델의 엔드포인트 이름
- 임베딩 모델 엔드포인트 이름 – SageMaker JumpStart로 배포된 임베딩 모델의 엔드포인트 이름
AWS CDK를 사용하여 리소스 배포
이전 섹션에서 언급한 배포 매개변수를 사용하여 AWS CDK 스택을 배포합니다. AWS CDK 설치에 대한 자세한 내용은 다음을 참조하세요. AWS CDK 시작하기.
AWS CDK 배포에 사용될 워크스테이션에 Docker가 설치되어 실행되고 있는지 확인하십시오. 인용하다 도커 가져오기 추가 안내를 위해.
또는 다음과 같은 파일에 컨텍스트 값을 입력할 수 있습니다. cdk.context.json FBI 증오 범죄 보고서 pattern1-rag/cdk 디렉토리 및 실행 cdk deploy BackendStack --exclusively.
배포는 출력을 인쇄하며, 그 중 일부는 노트북을 실행하는 데 필요합니다. 질문과 답변을 시작하기 전에 다음 섹션에 표시된 대로 참조 문서를 포함하세요.
참조 문서 삽입
이 RAG 접근 방식의 경우 참조 문서는 먼저 텍스트 임베딩 모델에 포함되고 벡터 데이터베이스에 저장됩니다. 이 솔루션에서는 PDF 문서를 수집하는 수집 파이프라인이 구축되었습니다.
An 아마존 엘라스틱 컴퓨트 클라우드 (Amazon EC2) 인스턴스가 PDF 문서 수집을 위해 생성되었으며 아마존 탄성 파일 시스템 (Amazon EFS) 파일 시스템은 PDF 문서를 저장하기 위해 EC2 인스턴스에 탑재됩니다. 안 AWS 데이터싱크 작업은 매시간 실행되어 EFS 파일 시스템 경로에 있는 PDF 문서를 가져와 S3 버킷에 업로드하여 텍스트 포함 프로세스를 시작합니다. 이 프로세스는 참조 문서를 포함하고 OpenSearch 서비스에 포함을 저장합니다. 또한 나중에 분석할 수 있도록 Kinesis Data Firehose를 통해 임베딩 아카이브를 S3 버킷에 저장합니다.
참조 문서를 수집하려면 다음 단계를 완료하세요.
- 생성된 샘플 EC2 인스턴스 ID를 검색합니다(AWS CDK 출력 참조).
JumpHostId) 다음을 사용하여 연결합니다. 세션 관리자, 능력 AWS 시스템 관리자. 지침은 다음을 참조하십시오. AWS Systems Manager Session Manager를 사용하여 Linux 인스턴스에 연결. - 디렉토리로 이동
/mnt/efs/fs1, EFS 파일 시스템이 마운트된 위치에 다음과 같은 폴더를 생성합니다.ingest: - 참조 PDF 문서를
ingest디렉토리.
DataSync 작업은 포함 프로세스를 시작하기 위해 이 디렉터리에 있는 모든 파일을 Amazon S3에 업로드하도록 구성되어 있습니다.
DataSync 작업은 매시간 일정에 따라 실행됩니다. 선택적으로 작업을 수동으로 시작하여 추가한 PDF 문서에 대한 포함 프로세스를 즉시 시작할 수 있습니다.
- 작업을 시작하려면 AWS CDK 출력에서 작업 ID를 찾으세요.
DataSyncTaskID및 작업을 시작하다 기본값으로.
임베딩이 생성되면 다음 섹션에 표시된 대로 Jupyter 노트북을 통해 RAG 질문과 답변을 시작할 수 있습니다.
Jupyter 노트북을 사용한 질문과 답변
다음 단계를 완료하십시오.
- AWS CDK 출력에서 SageMaker 노트북 인스턴스 이름을 검색합니다.
NotebookInstanceNameSageMaker 콘솔에서 JupyterLab에 연결합니다. - 디렉토리로 이동
fmops/full-stack/pattern1-rag/notebooks/. - 노트북을 열고 실행하세요.
query-llm.ipynb노트북 인스턴스에서 RAG를 사용하여 질문과 답변을 수행합니다.
꼭 사용하세요 conda_python3 노트북용 커널.
이 패턴은 전체 스택 애플리케이션에 필요한 추가 필수 구성 요소를 프로비저닝할 필요 없이 백엔드 솔루션을 탐색하는 데 유용합니다. 다음 섹션에서는 생성적 AI 애플리케이션과 상호 작용하기 위한 사용자 인터페이스를 제공하기 위해 프런트엔드 및 백엔드 구성 요소를 모두 포함하는 풀 스택 애플리케이션의 구현을 다룹니다.
옵션 2: Streamlit 프런트엔드를 사용하여 전체 스택 샘플 애플리케이션 배포
이 패턴을 사용하면 질문과 답변을 위한 사용자 프런트엔드 인터페이스를 사용하여 솔루션을 배포할 수 있습니다.
사전 조건
샘플 애플리케이션을 배포하려면 다음 필수 구성 요소가 있어야 합니다.
- SageMaker JumpStart 모델 엔드포인트 배포됨 – 제공된 노트북을 사용하여 이전 섹션에 설명된 대로 SageMaker JumpStart를 사용하여 SageMaker 실시간 엔드포인트에 모델을 배포합니다.
- Amazon Route 53 호스팅 영역 – 만들기 아마존 경로 53 퍼블릭 호스팅 영역 이 솔루션에 사용합니다. 다음과 같은 기존 Route 53 퍼블릭 호스팅 영역을 사용할 수도 있습니다.
example.com. - AWS 인증서 관리자 인증서 – 프로비저닝 AWS 인증서 관리자 (ACM) Route 53 호스팅 영역 도메인 이름 및 해당 하위 도메인에 대한 TLS 인증서(예:
example.com및*.example.com모든 하위 도메인에 대해. 지침은 다음을 참조하세요. 공개 인증서 요청. 이 인증서는 HTTPS를 구성하는 데 사용됩니다. 아마존 CloudFront를 및 오리진 로드 밸런서. - 배포 매개변수 – 다음을 기록하십시오.
- 프런트엔드 애플리케이션 사용자 정의 도메인 이름 – 프런트엔드 샘플 애플리케이션에 액세스하는 데 사용되는 사용자 정의 도메인 이름입니다. 제공된 도메인 이름은 프런트엔드 CloudFront 배포를 가리키는 Route 53 DNS 레코드를 생성하는 데 사용됩니다. 예를 들어,
app.example.com. - 로드 밸런서 원본 사용자 정의 도메인 이름 – CloudFront 배포 로드 밸런서 원본에 사용되는 사용자 지정 도메인 이름입니다. 제공된 도메인 이름은 원본 로드 밸런서를 가리키는 Route 53 DNS 레코드를 생성하는 데 사용됩니다. 예를 들어,
app-lb.example.com. - Route 53 호스팅 영역 ID – 제공된 사용자 지정 도메인 이름을 호스팅하기 위한 Route 53 호스팅 영역 ID. 예를 들어,
ZXXXXXXXXYYYYYYYYY. - Route 53 호스팅 영역 이름 – 제공된 사용자 지정 도메인 이름을 호스팅할 Route 53 호스팅 영역의 이름. 예를 들어,
example.com. - ACM 인증서 ARN – 제공된 사용자 지정 도메인과 함께 사용할 ACM 인증서의 ARN입니다.
- 텍스트 모델 끝점 이름 – SageMaker JumpStart로 배포된 텍스트 생성 모델의 엔드포인트 이름입니다.
- 임베딩 모델 엔드포인트 이름 – SageMaker JumpStart로 배포된 임베딩 모델의 엔드포인트 이름입니다.
- 프런트엔드 애플리케이션 사용자 정의 도메인 이름 – 프런트엔드 샘플 애플리케이션에 액세스하는 데 사용되는 사용자 정의 도메인 이름입니다. 제공된 도메인 이름은 프런트엔드 CloudFront 배포를 가리키는 Route 53 DNS 레코드를 생성하는 데 사용됩니다. 예를 들어,
AWS CDK를 사용하여 리소스 배포
AWS CDK 스택을 배포하려면 사전 조건에서 기록한 배포 매개변수를 사용하십시오. 자세한 내용은 다음을 참조하세요. AWS CDK 시작하기.
AWS CDK 배포에 사용될 워크스테이션에 Docker가 설치되어 실행되고 있는지 확인하세요.
앞의 코드에서 -c는 입력 시 제공되는 필수 전제조건 형식의 컨텍스트 값을 나타냅니다. 또는 다음과 같은 파일에 컨텍스트 값을 입력할 수 있습니다. cdk.context.json FBI 증오 범죄 보고서 pattern1-rag/cdk 디렉토리 및 실행 cdk deploy --all.
파일에 지역을 지정합니다. bin/cdk.ts. ALB 액세스 로그를 구성하려면 지정된 지역이 필요합니다. 배포하기 전에 이 지역을 변경할 수 있습니다.
배포는 Streamlit 애플리케이션에 액세스하기 위한 URL을 인쇄합니다. 질문과 답변을 시작하기 전에 다음 섹션에 표시된 대로 참조 문서를 포함해야 합니다.
참조 문서 삽입
RAG 접근 방식의 경우 참조 문서는 먼저 텍스트 임베딩 모델에 포함되고 벡터 데이터베이스에 저장됩니다. 이 솔루션에서는 PDF 문서를 수집하는 수집 파이프라인이 구축되었습니다.
첫 번째 배포 옵션에서 논의한 것처럼 PDF 문서 수집을 위해 예제 EC2 인스턴스가 생성되었으며 PDF 문서를 저장하기 위해 EFS 파일 시스템이 EC2 인스턴스에 탑재되었습니다. DataSync 작업은 매시간 실행되어 EFS 파일 시스템 경로에 있는 PDF 문서를 가져오고 이를 S3 버킷에 업로드하여 텍스트 포함 프로세스를 시작합니다. 이 프로세스는 참조 문서를 포함하고 OpenSearch 서비스에 포함을 저장합니다. 또한 나중에 분석할 수 있도록 Kinesis Data Firehose를 통해 임베딩 아카이브를 S3 버킷에 저장합니다.
참조 문서를 수집하려면 다음 단계를 완료하세요.
- 생성된 샘플 EC2 인스턴스 ID를 검색합니다(AWS CDK 출력 참조).
JumpHostId) 세션 관리자를 사용하여 연결합니다. - 디렉토리로 이동
/mnt/efs/fs1, EFS 파일 시스템이 마운트된 위치에 다음과 같은 폴더를 생성합니다.ingest: - 참조 PDF 문서를
ingest디렉토리.
DataSync 작업은 포함 프로세스를 시작하기 위해 이 디렉터리에 있는 모든 파일을 Amazon S3에 업로드하도록 구성되어 있습니다.
DataSync 작업은 매시간 일정으로 실행됩니다. 선택적으로 작업을 수동으로 시작하여 추가한 PDF 문서에 대한 포함 프로세스를 즉시 시작할 수 있습니다.
- 작업을 시작하려면 AWS CDK 출력에서 작업 ID를 찾으세요.
DataSyncTaskID및 작업을 시작하다 기본값으로.
질문과 답변
참조 문서가 포함된 후 Streamlit 애플리케이션에 액세스하기 위해 URL을 방문하여 RAG 질문과 답변을 시작할 수 있습니다. 안 아마존 코 그니 토 인증 계층이 사용되므로 애플리케이션에 처음 액세스하려면 AWS CDK(사용자 풀 이름은 AWS CDK 출력 참조)를 통해 배포된 Amazon Cognito 사용자 풀에 사용자 계정을 생성해야 합니다. Amazon Cognito 사용자 생성에 대한 지침은 다음을 참조하십시오. AWS Management 콘솔에서 새 사용자 생성.
드리프트 분석 포함
이 섹션에서는 먼저 참조 데이터 임베딩과 프롬프트 임베딩의 기준선을 생성한 다음 시간 경과에 따른 임베딩의 스냅샷을 생성하여 드리프트 분석을 수행하는 방법을 보여줍니다. 이를 통해 기준 임베딩을 스냅샷 임베딩과 비교할 수 있습니다.
참조 데이터에 대한 임베딩 기준선을 생성하고 프롬프트를 표시합니다.
참조 데이터의 임베딩 기준선을 생성하려면 AWS Glue 콘솔을 열고 ETL 작업을 선택하십시오. embedding-drift-analysis. ETL 작업에 대한 매개변수를 다음과 같이 설정하고 작업을 실행합니다.
- 세트
--job_type에BASELINE. - 세트
--out_table~로 아마존 DynamoDB 참조 임베딩 데이터에 대한 테이블입니다. (AWS CDK 출력 참조DriftTableReference테이블 이름에 대한 것입니다.) - 세트
--centroid_table참조 중심 데이터를 위해 DynamoDB 테이블로 이동합니다. (AWS CDK 출력 참조CentroidTableReference테이블 이름에 대한 것입니다.) - 세트
--data_path접두사가 있는 S3 버킷에 예를 들어,s3:///embeddingarchive/. (AWS CDK 출력 참조BucketName버킷 이름에 사용됩니다.)
마찬가지로 ETL 작업을 사용하여 embedding-drift-analysis, 프롬프트의 포함 기준선을 만듭니다. ETL 작업에 대한 매개변수를 다음과 같이 설정하고 작업을 실행합니다.
- 세트
--job_type에BASELINE - 세트
--out_table프롬프트 데이터 삽입을 위해 DynamoDB 테이블에 추가합니다. (AWS CDK 출력 참조DriftTablePromptsName테이블 이름에 대한 것입니다.) - 세트
--centroid_table프롬프트 중심 데이터를 위해 DynamoDB 테이블로 이동합니다. (AWS CDK 출력 참조CentroidTablePrompts테이블 이름에 대한 것입니다.) - 세트
--data_path접두사가 있는 S3 버킷에 예를 들어,s3:///promptarchive/. (AWS CDK 출력 참조BucketName버킷 이름에 사용됩니다.)
참조 데이터 및 프롬프트에 대한 임베딩 스냅샷 생성
OpenSearch Service에 추가 정보를 수집한 후 ETL 작업을 실행합니다. embedding-drift-analysis 다시 참조 데이터 임베딩의 스냅샷을 찍습니다. 매개변수는 이전 섹션에 표시된 대로 참조 데이터의 임베딩 기준선을 생성하기 위해 실행한 ETL 작업과 동일합니다. --job_type 에 매개 변수 SNAPSHOT.
마찬가지로 프롬프트 임베딩의 스냅샷을 보려면 ETL 작업을 실행하세요. embedding-drift-analysis 다시. 매개변수는 이전 섹션에 표시된 대로 프롬프트에 대한 포함 기준선을 생성하기 위해 실행한 ETL 작업과 동일합니다. --job_type 에 매개 변수 SNAPSHOT.
기준선과 스냅샷 비교
참조 데이터 및 프롬프트에 대한 임베딩 기준선과 스냅샷을 비교하려면 제공된 노트북을 사용하세요. pattern1-rag/notebooks/drift-analysis.ipynb.
참조 데이터 또는 프롬프트에 대한 내장 비교를 보려면 DynamoDB 테이블 이름 변수(tbl 및 c_tbl)를 노트북의 각 실행에 대해 적절한 DynamoDB 테이블로 복사합니다.
노트북 변수 tbl 적절한 드리프트 테이블 이름으로 변경해야 합니다. 다음은 노트북에서 변수를 구성하는 위치의 예입니다.

테이블 이름은 다음과 같이 검색할 수 있습니다.
- 참조 임베딩 데이터의 경우 AWS CDK 출력에서 드리프트 테이블 이름을 검색합니다.
DriftTableReference - 데이터를 삽입하라는 메시지를 받으려면 AWS CDK 출력에서 드리프트 테이블 이름을 검색하세요.
DriftTablePromptsName
또한 노트북 변수 c_tbl 적절한 중심 테이블 이름으로 변경해야 합니다. 다음은 노트북에서 변수를 구성하는 위치의 예입니다.

테이블 이름은 다음과 같이 검색할 수 있습니다.
- 참조 임베딩 데이터의 경우 AWS CDK 출력에서 중심 테이블 이름을 검색합니다.
CentroidTableReference - 데이터 삽입 메시지를 보려면 AWS CDK 출력에서 중심 테이블 이름을 검색하세요.
CentroidTablePrompts
참조 데이터와의 신속한 거리 분석
먼저 AWS Glue 작업을 실행합니다. embedding-distance-analysis. 이 작업은 참조 데이터 임베딩의 K-Means 평가에서 각 프롬프트가 속한 클러스터를 찾습니다. 그런 다음 각 프롬프트에서 해당 클러스터의 중심까지 거리의 평균, 중앙값 및 표준 편차를 계산합니다.
노트북을 실행할 수 있습니다. pattern1-rag/notebooks/distance-analysis.ipynb 시간 경과에 따른 거리 측정항목의 추세를 확인합니다. 이를 통해 프롬프트 임베딩 거리 분포의 전반적인 추세를 파악할 수 있습니다.
노트북 pattern1-rag/notebooks/prompt-distance-outliers.ipynb 참조 데이터와 관련되지 않은 메시지가 더 많이 표시되는지 여부를 식별하는 데 도움이 될 수 있는 이상값을 찾는 AWS Glue 노트북입니다.
유사성 점수 모니터링
OpenSearch Service의 모든 유사성 점수가 로그인됩니다. 아마존 클라우드 워치 아래 rag 네임스페이스. 대시보드 RAG_Scores 평균 점수와 수집된 총 점수 수를 표시합니다.
정리
향후 요금이 발생하지 않도록 생성한 모든 리소스를 삭제하세요.
배포된 SageMaker 모델 삭제
정리 섹션을 참조하세요. 예제 노트북 제공 배포된 SageMaker JumpStart 모델을 삭제하거나 다음을 수행할 수 있습니다. SageMaker 콘솔에서 모델 삭제.
AWS CDK 리소스 삭제
매개변수를 입력한 경우 cdk.context.json 파일을 다음과 같이 정리합니다.
명령줄에 매개변수를 입력하고 백엔드 애플리케이션(백엔드 AWS CDK 스택)만 배포한 경우 다음과 같이 정리합니다.
명령줄에 매개변수를 입력하고 전체 솔루션(프런트엔드 및 백엔드 AWS CDK 스택)을 배포한 경우 다음과 같이 정리하십시오.
결론
이 게시물에서는 생성 AI를 위한 RAG 패턴의 참조 데이터와 프롬프트 모두에 대한 임베딩 벡터를 캡처하는 애플리케이션의 작업 예제를 제공했습니다. 우리는 참조 또는 프롬프트 데이터가 시간에 따라 표류하는지 여부와 참조 데이터가 사용자가 묻는 질문 유형을 얼마나 잘 다루는지 확인하기 위해 클러스터링 분석을 수행하는 방법을 보여주었습니다. 드리프트를 감지하면 환경이 변경되었으며 모델이 처리하기에 최적화되지 않은 새로운 입력을 받고 있다는 신호를 제공할 수 있습니다. 이를 통해 입력 변경에 대해 현재 모델을 사전에 평가할 수 있습니다.
저자에 관하여
 압둘라히 올라오예 Amazon Web Services(AWS)의 수석 솔루션 아키텍트입니다. Abdullahi는 위치타 주립대학교에서 컴퓨터 네트워킹 석사 학위를 취득했으며 DevOps, 인프라 현대화, AI 등 다양한 기술 영역에서 역할을 맡은 출판 작가입니다. 그는 현재 Generative AI에 중점을 두고 있으며 기업이 Generative AI를 기반으로 하는 최첨단 솔루션을 설계하고 구축할 수 있도록 지원하는 데 핵심적인 역할을 하고 있습니다. 그는 기술의 영역을 넘어 탐험의 예술에서 기쁨을 찾습니다. AI 솔루션을 개발하지 않을 때에는 가족과 함께 새로운 장소를 탐험하기 위해 여행하는 것을 즐깁니다.
압둘라히 올라오예 Amazon Web Services(AWS)의 수석 솔루션 아키텍트입니다. Abdullahi는 위치타 주립대학교에서 컴퓨터 네트워킹 석사 학위를 취득했으며 DevOps, 인프라 현대화, AI 등 다양한 기술 영역에서 역할을 맡은 출판 작가입니다. 그는 현재 Generative AI에 중점을 두고 있으며 기업이 Generative AI를 기반으로 하는 최첨단 솔루션을 설계하고 구축할 수 있도록 지원하는 데 핵심적인 역할을 하고 있습니다. 그는 기술의 영역을 넘어 탐험의 예술에서 기쁨을 찾습니다. AI 솔루션을 개발하지 않을 때에는 가족과 함께 새로운 장소를 탐험하기 위해 여행하는 것을 즐깁니다.
 랜디 드포 AWS의 선임 수석 솔루션 아키텍트입니다. 그는 University of Michigan에서 MSEE를 취득하고 자율 차량용 컴퓨터 비전을 연구했습니다. 그는 또한 콜로라도 주립 대학에서 MBA를 취득했습니다. Randy는 소프트웨어 엔지니어링에서 제품 관리에 이르기까지 기술 분야에서 다양한 직책을 맡았습니다. In은 2013년에 Big Data 영역에 진출했으며 계속해서 해당 영역을 탐색합니다. 그는 ML 공간에서 프로젝트에 적극적으로 참여하고 있으며 Strata 및 GlueCon을 포함한 수많은 컨퍼런스에서 발표했습니다.
랜디 드포 AWS의 선임 수석 솔루션 아키텍트입니다. 그는 University of Michigan에서 MSEE를 취득하고 자율 차량용 컴퓨터 비전을 연구했습니다. 그는 또한 콜로라도 주립 대학에서 MBA를 취득했습니다. Randy는 소프트웨어 엔지니어링에서 제품 관리에 이르기까지 기술 분야에서 다양한 직책을 맡았습니다. In은 2013년에 Big Data 영역에 진출했으며 계속해서 해당 영역을 탐색합니다. 그는 ML 공간에서 프로젝트에 적극적으로 참여하고 있으며 Strata 및 GlueCon을 포함한 수많은 컨퍼런스에서 발표했습니다.
 쉘비 아이겐브로드 Amazon Web Services(AWS)의 수석 AI 및 기계 학습 전문가 솔루션 아키텍트입니다. 그녀는 24년 동안 다양한 산업, 기술 및 역할에 걸쳐 기술 분야에서 일해 왔습니다. 그녀는 현재 DevOps 및 ML 배경을 MLOps 도메인에 결합하여 고객이 ML 워크로드를 대규모로 제공하고 관리할 수 있도록 하는 데 집중하고 있습니다. 다양한 기술 영역에 걸쳐 35개 이상의 특허를 부여받은 그녀는 지속적인 혁신과 데이터 사용에 대한 열정을 갖고 있습니다. Shelbee는 Coursera의 Practical Data Science 전문 분야의 공동 창시자이자 강사입니다. 그녀는 또한 덴버 챕터의 WiBD(Women In Big Data) 공동 이사이기도 합니다. 여가 시간에는 가족, 친구, 활동적인 개와 시간을 보내는 것을 좋아합니다.
쉘비 아이겐브로드 Amazon Web Services(AWS)의 수석 AI 및 기계 학습 전문가 솔루션 아키텍트입니다. 그녀는 24년 동안 다양한 산업, 기술 및 역할에 걸쳐 기술 분야에서 일해 왔습니다. 그녀는 현재 DevOps 및 ML 배경을 MLOps 도메인에 결합하여 고객이 ML 워크로드를 대규모로 제공하고 관리할 수 있도록 하는 데 집중하고 있습니다. 다양한 기술 영역에 걸쳐 35개 이상의 특허를 부여받은 그녀는 지속적인 혁신과 데이터 사용에 대한 열정을 갖고 있습니다. Shelbee는 Coursera의 Practical Data Science 전문 분야의 공동 창시자이자 강사입니다. 그녀는 또한 덴버 챕터의 WiBD(Women In Big Data) 공동 이사이기도 합니다. 여가 시간에는 가족, 친구, 활동적인 개와 시간을 보내는 것을 좋아합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/monitor-embedding-drift-for-llms-deployed-from-amazon-sagemaker-jumpstart/
- :있다
- :이다
- :아니
- :어디
- $UP
- 1
- 10
- 100
- 2%
- 2013
- 24
- 35%
- 39
- 4
- 53
- 62
- 7
- 9
- 90
- 95%
- a
- 할 수 있는
- 소개
- 절대
- ACCESS
- 계정
- ACM
- 가로질러
- 활발히
- 추가
- 또한
- 추가
- 추가 정보
- 또한
- 다시
- 반대
- 골재
- AI
- 정렬
- All
- 허용
- 수
- 또한
- 이기는하지만
- 아마존
- 아마존 코 그니 토
- Amazon EC2
- 아마존 세이지 메이커
- Amazon SageMaker 점프스타트
- Amazon Web Services
- Amazon Web Services (AWS)
- an
- 분석
- 분석하다
- 분석하는
- 및
- 답변
- 응답
- 아무것도
- 응용할 수 있는
- 어플리케이션
- 접근
- 적당한
- 아키텍처
- 아카이브
- 있군요
- 지역
- 지역
- 미술
- 기사
- AS
- 문의
- 질문
- 돕는
- 취하다
- At
- 증가하다
- 증강 된
- 인증
- 저자
- 자동적으로
- 자발적인
- 자치 차량
- 가능
- 평균
- 피하기
- 떨어져
- AWS
- AWS 접착제
- 백엔드
- 배경
- 그네
- 기반으로
- 기준
- BE
- 때문에
- 된
- 전에
- 존재
- 속
- 더 나은
- 사이에
- 그 너머
- 큰
- 빅 데이터
- 기관
- 두
- 대체로
- 빌드
- 내장
- 사업
- by
- 계산하다
- ~를 계산하다
- 전화
- 라는
- CAN
- 능력
- 포착
- 캡처
- 캡처
- 캡처
- 케이스
- CD
- 센터
- 센터
- 증명서
- 이전 단계로 돌아가기
- 변경
- 변경
- 변화
- 장
- 요금
- 칩
- 초콜릿
- 왼쪽 메뉴에서
- 황어 무리
- 닫기
- 자세히
- 클라우드
- 클러스터
- 클러스터링
- 암호
- 콜로라도
- 결합
- 결합 된
- 결합
- 오는
- 팩트
- 비교
- 비교
- 비교
- 완전한
- 구성 요소
- 구성 요소들
- 계산
- 컴퓨터
- 컴퓨터 비전
- 개념
- 회의
- 구성
- 구성
- 연결하기
- 고려 사항
- 일관성
- 콘솔에서
- 컨테이너
- 함유량
- 문맥
- 계속
- 끊임없는
- 변환
- 쿠키
- 핵심
- 동
- Coursera
- 적용 범위
- 적용
- 피복
- 커버
- 만들
- 만든
- 생성
- 만들기
- Current
- 현재
- 관습
- 고객
- 최첨단
- 계기반
- 데이터
- 데이터 센터
- 데이터 처리
- 데이터 과학
- 데이터베이스
- 감소
- 기본값
- 한정된
- 삭제
- 배달하다
- 덴버
- 배포
- 배포
- 배치
- 전개
- 배치하다
- 파생
- 파괴
- 상세한
- 검색
- Detection System
- 결정
- 개발
- 일탈
- 개발자
- 도표
- 다른
- 어려운
- 외형 치수
- 치수
- 논의 된
- 분산
- 거리
- 먼
- 분포
- DNS
- do
- 도커
- 문서
- 서류
- 개
- 도메인
- 도메인 이름
- 도메인 이름
- 도메인
- 말라
- 아래 (down)
- 드라이브
- 마다
- 포함
- 임베디드
- 임베딩
- end
- 끝으로 종료
- 종점
- 엔드 포인트
- 엔지니어링
- 엔터 버튼
- 입력 된
- 기업
- 환경
- 에테르 (ETH)
- 평가
- 평가
- 모든
- 예
- 예
- 예외
- 현존하는
- 실험
- 설명
- 탐구
- 탐험
- 탐색
- 외부
- 추출물
- 추출물
- 가족
- 멀리
- 그림
- 입양 부모로서의 귀하의 적합성을 결정하기 위해 미국 이민국에
- 파일
- 최후의
- 최종적으로
- Find
- finds
- 먼저,
- 떠 있는
- 흐름
- 집중
- 초점
- 수행원
- 다음
- 럭셔리
- 형태
- 발견
- Foundation
- 친구
- 에
- 프런트 엔드
- 가득 찬
- 미래
- 수집
- 일반
- 생성
- 세대
- 생성적인
- 제너레이티브 AI
- 생성 모델
- 얻을
- 점점
- 주기
- Go
- 사라
- 부여
- 그룹
- 지도
- 핸들
- 있다
- he
- 개최
- 도움
- 그녀의
- 더 높은
- 그의
- 보유
- 주인
- 호스팅
- 시간
- 방법
- How To
- 그러나
- HTML
- HTTP
- HTTPS
- 허브
- ID
- 확인
- if
- 설명하다
- 바로
- 이행
- 구현하다
- 중대한
- in
- 포함
- 포함
- 포함
- 들어오는
- 표시
- 표시
- 산업
- 관성
- 정보
- 인프라
- 처음에는
- 혁신
- 입력
- 입력
- 통찰력
- 설치
- 예
- 명령
- 상호 작용하는
- 상호 작용
- 대화형
- 관심있는
- 인터페이스
- 으로
- IT
- 그
- 일
- 작업
- 즐거움
- JPG
- 주피터 수첩
- 다만
- 키
- Kinesis 데이터 Firehose
- 지식
- 언어
- 넓은
- 후에
- 최근
- 층
- 배우다
- 배우기
- 수
- 도서관
- 좋아하는
- 라인
- 리눅스
- llm
- 하중
- 위치
- 로그인
- 보기
- 봐라.
- 절감
- 기계
- 기계 학습
- 확인
- 관리
- 구축
- 매니저
- 수동으로
- XNUMX월..
- MBA
- 평균
- 방법
- 측정
- 조치들
- 통계
- 미시간
- 수도
- ML
- MLOps
- 모델
- 모델
- 현대화
- 모니터
- 배우기
- 가장
- 움직이는
- 여러
- 절대로 필요한 것
- name
- 이름
- 자연의
- 자연어
- 자연 언어 처리
- 필요
- 필요
- 필요
- 네트워킹
- 신제품
- 더 새로운
- 다음 것
- nlp
- 수첩
- 노트북
- 유명한
- 번호
- 숫자
- 다수의
- of
- 자주
- on
- 만
- 열 수
- 최적화
- 선택권
- or
- 오케스트레이션
- 주문
- 유래
- 기타
- 우리의
- 아웃
- 결과
- 설명
- 출력
- 출력
- 위에
- 전체
- 중첩하다
- 자신의
- 매개 변수
- 매개 변수
- 특별한
- 열정
- 특허
- 통로
- 무늬
- 패턴
- 수행
- 실행할 수 있는
- 개
- 관로
- 장소
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 재생
- 포인트 적립
- 전철기
- 풀
- 위치
- 가능한
- 게시하다
- 가능성
- powered
- 실용적인
- 선행
- 전제 조건
- 제시
- 보존
- 보존
- 너무 이른
- 이전에
- 교장
- 인쇄
- 사전
- 방법
- 처리
- 프로덕트
- 제품 관리
- 프로젝트
- 프롬프트
- 비율
- 제공
- 제공
- 제공
- 규정
- 공개
- 출판
- 했었어요
- 문제
- 문의
- 조각
- 범위
- 이르기까지
- 준비
- 실시간
- 왕국
- 조리법
- 기록
- 감소
- 축소
- 참조
- 참고
- 지방
- 관련
- 상대적으로
- 관련된
- 대표
- 대표
- 대표
- 필수
- 필요
- 제품 자료
- 응답
- 결과
- 검색
- 직위별
- 역할
- 길
- 달리기
- 달리는
- 실행
- 현자
- 같은
- 찜하기
- 규모
- 예정
- 과학
- 점수
- 점수
- 검색
- 검색
- 둘째
- 섹션
- 섹션
- 참조
- 본
- 고르다
- 시맨틱
- 연장자
- 감각
- 전송
- 별도의
- 서비스
- 서비스
- 세션
- 세트
- 설정
- 몇몇의
- 그녀
- 영상을
- 표시
- 보여
- 표시
- 쇼
- 신호
- 신호
- 비슷한
- 단순, 간단, 편리
- 단순화
- 크기
- 스냅 사진
- So
- 소프트웨어
- 소프트웨어 공학
- 해결책
- 솔루션
- 일부
- 출처
- 지우면 좋을거같음 . SM
- 스페이스 버튼
- 스패닝
- 전문가
- 지정
- 지출
- 제곱 한
- 스택
- 스택
- 표준
- 스타트
- 시작
- 시작 중
- 주 정부
- 통계
- 단계
- 저장
- 저장
- 저장
- 성공한
- 이러한
- 합
- 확인
- 체계
- 시스템은
- 테이블
- 받아
- 태스크
- 기술
- 기술
- Technology
- 본문
- 텍스트 생성
- 그
- XNUMXD덴탈의
- 정보
- 소스
- 그들의
- 그들
- 그때
- 그곳에.
- Bowman의
- 이
- 그
- 세
- 을 통하여
- 시간
- TLS
- 에
- 함께
- 이상의 주제
- 금액
- 변환
- 여행
- 경향
- 트렌드
- 시도하다
- 시도
- 두
- 유형
- 아래에
- 대학
- 미시간 대학
- URL
- us
- 사용
- 익숙한
- 유용
- 사용자
- 시간을 아껴주는 인터페이스
- 사용자
- 사용
- 확인
- 가치
- 마케팅은:
- 변수
- 변수
- 종류
- 여러
- 벡터
- 벡터
- 차량
- 를 통해
- 시력
- 시각
- 연습
- 필요
- 였다
- 방법..
- we
- 웹
- 웹 서비스
- 잘
- 언제
- 여부
- 어느
- 동안
- 의지
- 과
- 이내
- 없이
- 여성 컬렉션
- 작업
- 일
- 일하는
- 워크 스테이션
- 악화되는
- 겠지
- 년
- 아직
- 당신
- 너의
- 제퍼 넷
- 지역