아마존 레드 시프트 는 표준 SQL과 기존 비즈니스 인텔리전스(BI) 도구를 사용하여 모든 데이터를 간단하고 비용 효율적으로 분석할 수 있는 빠르고 완벽하게 관리되는 페타바이트 규모의 클라우드 데이터 웨어하우스입니다. 현재 수만 명의 고객이 Amazon Redshift를 사용하여 엑사바이트 규모의 데이터를 분석하고 분석 쿼리를 실행함으로써 가장 널리 사용되는 클라우드 데이터 웨어하우스가 되었습니다. Amazon Redshift는 서버리스 구성과 프로비저닝된 구성 모두에서 사용할 수 있습니다.
Amazon Redshift를 사용하면 다음에 저장된 데이터에 직접 액세스할 수 있습니다. 아마존 단순 스토리지 서비스 (Amazon S3) SQL 쿼리를 사용하고 데이터 웨어하우스와 데이터 레이크 전체에서 데이터를 조인합니다. Amazon Redshift를 사용하면 중앙 데이터베이스를 사용하여 S3 데이터 레이크의 데이터를 쿼리할 수 있습니다. AWS 접착제 Redshift 데이터 웨어하우스의 메타스토어.
Amazon Redshift는 CSV, JSON, Parquet, ORC 등의 다양한 데이터 형식과 Apache Hudi, Delta 등의 테이블 형식 쿼리를 지원합니다. Amazon Redshift는 구조체, 배열, 맵과 같은 복잡한 데이터 유형이 포함된 중첩 데이터 쿼리도 지원합니다.
Amazon Redshift는 이 기능을 통해 비용 효율적인 방식으로 페타바이트 규모의 데이터 웨어하우스를 Amazon S3의 엑사바이트 규모 데이터 레이크로 확장합니다.
Apache Iceberg는 현재 Amazon Redshift에서 미리 보기로 지원되는 최신 테이블 형식입니다. 이 게시물에서는 Amazon Redshift를 사용하여 Iceberg 테이블을 쿼리하는 방법과 Iceberg 지원 및 옵션을 살펴보는 방법을 보여줍니다.
솔루션 개요
아파치 빙산 매우 큰 페타바이트 규모의 분석 데이터 세트를 위한 개방형 테이블 형식입니다. Iceberg는 대규모 파일 모음을 테이블로 관리하고 레코드 수준 삽입, 업데이트, 삭제 및 시간 여행 쿼리와 같은 최신 분석 데이터 레이크 작업을 지원합니다. Iceberg 사양은 스키마, 파티션 진화 등 원활한 테이블 진화를 가능하게 하며, 그 디자인은 Amazon S3에서의 사용에 최적화되어 있습니다.
Iceberg는 모든 메타데이터 파일에 대한 메타데이터 포인터를 저장합니다. SELECT 쿼리가 Iceberg 테이블을 읽을 때 쿼리 엔진은 먼저 Iceberg 카탈로그로 이동한 다음 다음 다이어그램과 같이 최신 메타데이터 파일 위치 항목을 검색합니다.
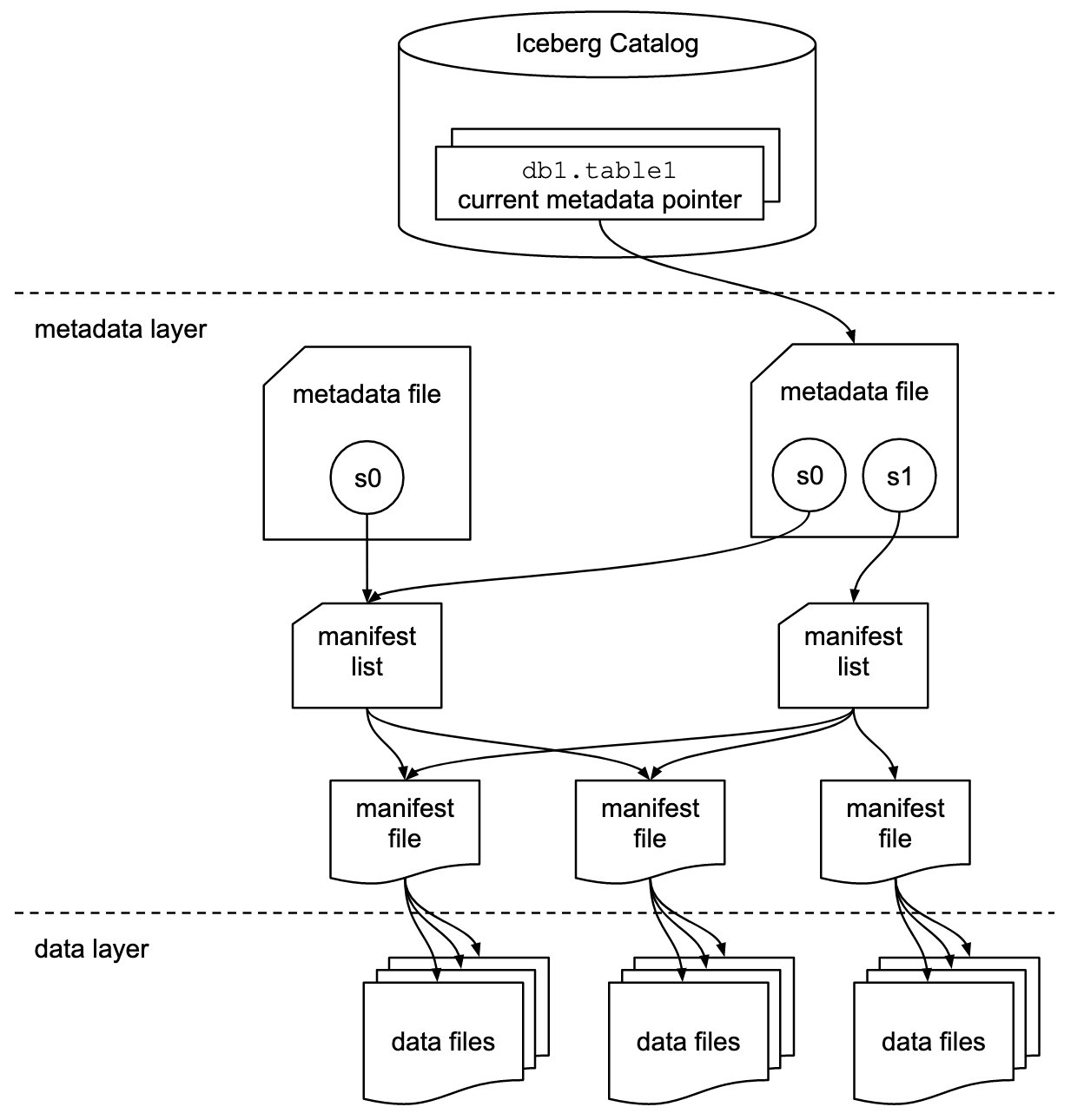
Amazon Redshift는 이제 Apache Iceberg 테이블에 대한 지원을 제공합니다. 이를 통해 데이터 레이크 고객은 트랜잭션에 있어 일관된 방식으로 읽기 전용 분석 쿼리를 실행할 수 있습니다. 이를 통해 트랜잭션 데이터 레이크의 테이블을 쉽게 관리하고 유지할 수 있습니다.
Amazon Redshift는 다음을 사용하여 Apache Iceberg의 기본 스키마 및 파티션 진화 기능을 지원합니다. AWS Glue 데이터 카탈로그, 새 파티션을 추가하거나 기존 데이터 레이크 테이블의 스키마를 변경하기 위해 대량의 데이터를 이동 및 처리하기 위해 테이블 정의를 변경할 필요가 없습니다. Amazon Redshift는 Apache Iceberg 테이블 메타데이터에 저장된 열 통계를 사용하여 쿼리 계획을 최적화하고 쿼리 실행에 필요한 파일 스캔을 줄입니다.
이 게시물에서 우리는 NYC Taxi & Limousine Commission의 노란색 택시 공개 데이터세트 우리의 소스 데이터로. 데이터 세트에는 데이터 파일이 포함되어 있습니다. 아파치 마루 Amazon S3에서 형식을 지정합니다. 우리는 사용 아마존 아테나 이 Parquet 데이터세트를 변환한 다음 아마존 레드시프트 스펙트럼 Redshift 로컬 테이블을 쿼리하고 조인하려면 S3 데이터 레이크의 AWS Glue 데이터 카탈로그를 통해 조정되는 행 수준 삭제, 업데이트 및 파티션 진화를 수행합니다.
사전 조건
다음과 같은 전제 조건이 있어야 합니다.
Parquet 데이터를 Iceberg 테이블로 변환
이 게시물에는 다음이 필요합니다. NYC Taxi & Limousine Commission의 노란색 택시 공개 데이터세트 Iceberg 형식으로 제공됩니다. 파일을 다운로드한 다음 Athena를 사용하여 Parquet 데이터 세트를 Iceberg 테이블로 변환하거나 다음을 참조할 수 있습니다. Amazon Athena, Amazon EMR 및 AWS Glue를 사용하여 Apache Iceberg 데이터 레이크 구축 Iceberg 테이블을 만드는 방법에 대한 블로그 게시물입니다.
이 게시물에서는 Athena를 사용하여 데이터를 변환합니다. 다음 단계를 완료하세요.
- 이전 링크를 사용하여 파일을 다운로드하거나 AWS 명령 줄 인터페이스 (AWS CLI) 다음 명령을 사용하여 3년 및 2020년 퍼블릭 S2021 버킷의 파일을 S3 버킷으로 복사합니다.
자세한 내용은 Amazon Redshift CLI 설정.
- 데이터베이스 만들기
Icebergdb다음 명령문을 사용하여 Parquet 형식 파일을 가리키는 Athena를 사용하여 테이블을 생성합니다. - 다음 SQL을 사용하여 Parquet 테이블의 데이터를 검증합니다.

- 다음 코드를 사용하여 Athena에서 Iceberg 테이블을 생성합니다. 다음에서 Parquet 형식과 빠른 압축을 사용하는 Iceberg 테이블로 테이블 유형 속성을 볼 수 있습니다.
create table성명. SQL을 실행하기 전에 S3 위치를 업데이트해야 합니다. 또한 Iceberg 테이블은 다음과 같이 분할되어 있습니다.Year키. - 테이블을 생성한 후 이전에 로드한 Parquet 테이블을 사용하여 Iceberg 테이블에 데이터를 로드합니다.
nyc_taxi_yellow_parquet다음 SQL을 사용합니다. - SQL 문이 완료되면 Iceberg 테이블의 데이터 유효성을 검사합니다.
nyc_taxi_yellow_iceberg. 이 단계는 다음 단계로 이동하기 전에 필요합니다. - 다음 명령을 사용하면 nyc_taxi_yellow_iceberg 테이블이 Iceberg 형식 테이블이고 Year 열에 분할되어 있는지 확인할 수 있습니다.



Amazon Redshift에서 외부 스키마 생성
이 섹션에서는 Amazon Redshift에서 AWS Glue 데이터베이스를 가리키는 외부 스키마를 생성하는 방법을 보여줍니다. icebergdb Iceberg 테이블을 쿼리하려면 nyc_taxi_yellow_iceberg 이전 섹션에서 Athena를 사용하여 본 것입니다.
다음을 통해 Redshift에 로그인하십시오. 쿼리 편집기 v2 또는 SQL 클라이언트에서 다음 명령을 실행합니다(AWS Glue 데이터베이스는 icebergdb 및 지역 정보가 사용 중임):

Amazon Redshift에서 외부 스키마 생성에 대해 알아보려면 다음을 참조하십시오. 외부 스키마 생성
외부 스키마를 생성한 후 spectrum_iceberg_schema을 사용하면 Amazon Redshift에서 Iceberg 테이블을 쿼리할 수 있습니다.
Amazon Redshift에서 Iceberg 테이블 쿼리
쿼리 편집기 v2에서 다음 쿼리를 실행합니다. 참고하세요 spectrum_iceberg_schema Amazon Redshift에서 생성된 외부 스키마의 이름입니다. nyc_taxi_yellow_iceberg 쿼리에 사용된 AWS Glue 데이터베이스의 테이블입니다.
다음 스크린샷의 쿼리 데이터 출력은 Redshift Spectrum을 사용하여 Iceberg 형식의 AWS Glue 테이블을 쿼리할 수 있음을 보여줍니다.

Iceberg 테이블 쿼리에 대한 설명 계획을 확인하세요.
다음 쿼리를 사용하여 형식을 보여주는 계획 설명 출력을 얻을 수 있습니다. ICEBERG:

데이터 일관성을 위한 업데이트 유효성 검사
Iceberg 테이블에 대한 업데이트가 완료된 후 Amazon Redshift를 쿼리하여 트랜잭션이 일관된 데이터 보기를 확인할 수 있습니다. 다음을 선택하여 쿼리를 실행해 보겠습니다. vendorid 특정 픽업 및 하차의 경우:

다음으로 값을 업데이트합니다. passenger_count 4 및 trip_distance 9.4까지 vendorid Athena의 특정 픽업 및 하차 날짜:

마지막으로 쿼리 편집기 v2에서 다음 쿼리를 실행하여 업데이트된 값을 확인합니다. passenger_count 및 trip_distance:
다음 스크린샷에 표시된 것처럼 Amazon Redshift에서는 Iceberg 테이블에 대한 업데이트 작업을 사용할 수 있습니다.

Amazon Redshift에서 로컬 테이블과 기록 데이터에 대한 통합 보기 생성
최신 데이터 아키텍처 전략으로 기록 데이터나 자주 액세스하지 않는 데이터를 데이터 레이크에 정리하고 자주 액세스하는 데이터를 Redshift 데이터 웨어하우스에 보관할 수 있습니다. 이를 통해 대규모 분석을 관리하고 가장 비용 효율적인 아키텍처 솔루션을 찾을 수 있는 유연성을 제공합니다.
이 예에서는 Redshift 테이블에 2년간의 데이터를 로드합니다. 나머지 데이터는 S3 데이터 레이크에 유지됩니다. 해당 데이터 세트는 쿼리 빈도가 낮기 때문입니다.
- 다음 코드를 사용하여 2년간의 데이터를 로드합니다.
nyc_taxi_yellow_recentIceberg 테이블에서 소싱된 Amazon Redshift의 테이블:
- 다음으로, 이전 단계에서 Redshift 테이블에 데이터를 로드했기 때문에 Athena에서 다음 명령을 사용하여 Iceberg 테이블에서 지난 2년간의 데이터를 제거할 수 있습니다.

이러한 단계를 완료하면 Redshift 테이블에 2년간의 데이터가 있고 나머지 데이터는 Amazon S3의 Iceberg 테이블에 있습니다.
- 다음을 사용하여 뷰를 생성합니다.
nyc_taxi_yellow_iceberg빙산 테이블과nyc_taxi_yellow_recentAmazon Redshift의 테이블: - 이제 뷰를 쿼리하면 필터 조건에 따라 Redshift Spectrum이 Iceberg 데이터, Redshift 테이블 또는 둘 다를 스캔합니다. 다음 예제 쿼리는 두 테이블을 모두 스캔하여 각 원본 테이블에서 여러 레코드를 반환합니다.

파티션 진화
빙산의 용도 숨겨진 파티셔닝즉, Apache Iceberg 테이블에 파티션을 수동으로 추가할 필요가 없습니다. Apache Iceberg 테이블의 새 파티션 값 또는 새 파티션 사양(파티션 열 추가 또는 제거)은 Amazon Redshift에서 자동으로 감지되며 테이블 정의에서 파티션을 업데이트하는 데 수동 작업이 필요하지 않습니다. 다음 예제에서는 이를 보여줍니다.
이 예에서 Iceberg 테이블이 nyc_taxi_yellow_iceberg 원래는 연도별로 분할되었고 나중에는 열이 분할되었습니다. vendorid 추가 파티션 열로 추가된 경우 Amazon Redshift는 Iceberg 테이블을 원활하게 쿼리할 수 있습니다. nyc_taxi_yellow_iceberg 일정 기간 동안 두 가지 다른 파티션 구성표를 사용합니다.

Amazon Redshift를 사용하여 Iceberg 테이블을 쿼리할 때 고려 사항
미리 보기 기간 동안 Amazon Redshift를 Iceberg 테이블과 함께 사용할 때 다음 사항을 고려하십시오.
- AWS Glue 데이터 카탈로그에 정의된 Iceberg 테이블만 지원됩니다.
- CREATE 또는 ALTER 외부 테이블 명령은 지원되지 않습니다. 즉, Iceberg 테이블이 AWS Glue 데이터베이스에 이미 존재해야 함을 의미합니다.
- 시간 이동 쿼리는 지원되지 않습니다.
- Iceberg 버전 1과 2가 지원됩니다. Iceberg 형식 버전에 대한 자세한 내용은 다음을 참조하세요. 형식 버전 관리.
- Iceberg 테이블에서 지원되는 데이터 유형 목록은 다음을 참조하세요. Apache Iceberg 테이블에 지원되는 데이터 유형(미리보기).
- Iceberg 테이블 쿼리 요금은 Amazon Redshift를 사용하여 다른 데이터 형식에 액세스하는 요금과 동일합니다.
Iceberg 형식 테이블 미리보기 고려사항에 대한 자세한 내용은 다음을 참조하세요. Amazon Redshift(평가판)에서 Apache Iceberg 테이블 사용.
고객 피드백
“가장 큰 독립 성과 마케팅 회사인 Tinuiti는 매일 대량의 데이터를 처리하며 시장 정보 팀이 모든 고객 데이터를 쉽고 저렴하며 안전하게 저장하고 분석할 수 있도록 강력한 데이터 레이크 및 데이터 웨어하우스 전략을 보유해야 합니다. , 강력한 방식입니다.”라고 Tinuiti의 최고 기술 책임자인 Justin Manus는 말합니다. “단일 정보 소스인 데이터 레이크의 Apache Iceberg 테이블에 대한 Amazon Redshift의 지원은 성능과 접근성을 최적화하는 데 있어 중요한 과제를 해결하고 데이터 통합 파이프라인을 더욱 단순화하여 다양한 소스에서 수집된 모든 데이터에 액세스하고 고객의 브랜드 잠재력.”
결론
이 게시물에서는 AWS Glue 데이터 카탈로그에 테이블로 분류된 Amazon S3에 저장된 파일을 사용하여 Redshift에서 Iceberg 테이블을 쿼리하는 예를 보여 주며 효율적인 행 수준 업데이트 및 삭제와 같은 몇 가지 주요 기능을 시연했습니다. 그리고 사용자가 Athena를 사용하여 빅 데이터의 힘을 활용할 수 있는 스키마 진화 경험을 제공합니다.
Amazon Redshift를 사용하여 다음과 같은 다양한 파일 및 테이블 형식의 데이터 레이크 테이블에 대한 쿼리를 실행할 수 있습니다. 아파치 후디 및 델타 레이크그리고 지금 Apache Iceberg(미리보기), 최신 데이터 아키텍처 요구 사항에 맞는 추가 옵션을 제공합니다.
이것이 Amazon Redshift에서 Iceberg 테이블을 쿼리하기 위한 훌륭한 출발점이 되기를 바랍니다.
저자에 관하여
 로 히트 반살 AWS의 분석 전문가 솔루션 아키텍트입니다. 그는 Amazon Redshift를 전문으로 하며 고객과 협력하여 다른 AWS 분석 서비스를 사용하여 차세대 분석 솔루션을 구축합니다.
로 히트 반살 AWS의 분석 전문가 솔루션 아키텍트입니다. 그는 Amazon Redshift를 전문으로 하며 고객과 협력하여 다른 AWS 분석 서비스를 사용하여 차세대 분석 솔루션을 구축합니다.
 사티시 사티야 Amazon Redshift의 수석 제품 엔지니어입니다. 그는 성공을 달성하고 데이터 웨어하우징 및 데이터 레이크 아키텍처 요구 사항을 충족하기 위해 전 세계 고객과 협력하는 열렬한 빅 데이터 애호가입니다.
사티시 사티야 Amazon Redshift의 수석 제품 엔지니어입니다. 그는 성공을 달성하고 데이터 웨어하우징 및 데이터 레이크 아키텍처 요구 사항을 충족하기 위해 전 세계 고객과 협력하는 열렬한 빅 데이터 애호가입니다.
 란잔 버먼 AWS의 분석 전문가 솔루션 아키텍트입니다. 그는 Amazon Redshift의 전문가이며 고객이 확장 가능한 분석 솔루션을 구축하도록 돕습니다. 그는 다양한 데이터베이스 및 데이터 웨어하우징 기술 분야에서 16년 이상의 경험을 가지고 있습니다. 그는 클라우드 솔루션으로 고객 문제를 자동화하고 해결하는 데 열정적입니다.
란잔 버먼 AWS의 분석 전문가 솔루션 아키텍트입니다. 그는 Amazon Redshift의 전문가이며 고객이 확장 가능한 분석 솔루션을 구축하도록 돕습니다. 그는 다양한 데이터베이스 및 데이터 웨어하우징 기술 분야에서 16년 이상의 경험을 가지고 있습니다. 그는 클라우드 솔루션으로 고객 문제를 자동화하고 해결하는 데 열정적입니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 자동차 / EV, 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 차트프라임. ChartPrime으로 트레이딩 게임을 향상시키십시오. 여기에서 액세스하십시오.
- BlockOffsets. 환경 오프셋 소유권 현대화. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/query-your-iceberg-tables-in-data-lake-using-amazon-redshift-preview/
- :있다
- :이다
- :아니
- :어디
- $UP
- 1
- 10
- 100
- 16
- 17
- 2020
- 2021
- 22
- 26
- 28
- 30
- 385
- 46
- 500
- 53
- 7
- 8
- 9
- a
- 소개
- ACCESS
- 액세스
- 접근성
- 액세스
- 달성
- 가로질러
- 더하다
- 추가
- 추가
- 구애
- 저렴한
- All
- 수
- 이미
- 또한
- 아마존
- 아마존 아테나
- 아마존 EMR
- Amazon Web Services
- 금액
- an
- 분석
- 분석
- 분석
- 분석하다
- 및
- 어떤
- 아파치
- 아키텍처
- 있군요
- 약
- 배열
- AS
- At
- 자동적으로
- 자동화
- 가능
- AWS
- AWS 접착제
- 기초
- 때문에
- 전에
- 존재
- 큰
- 빅 데이터
- 제본
- 블로그
- 두
- 상표
- 빌드
- 사업
- 비즈니스 인텔리전스
- by
- CAN
- 기능
- 능력
- 목록
- 중심적인
- 어떤
- 도전
- 이전 단계로 돌아가기
- 주요한
- 최고 기술 책임자 (CTO)
- 클라이언트
- 클라우드
- 암호
- 컬렉션
- 단
- 열
- 완전한
- 복잡한
- 조건
- 고려
- 고려 사항
- 일관된
- 이 포함되어 있습니다
- 변하게 하다
- 조정
- 비용 효율적인
- 만들
- 만든
- 만들기
- 임계
- 고객
- 고객 데이터
- 고객
- 매일
- 데이터
- 데이터 통합
- 데이터 레이크
- 데이터웨어 하우스
- 데이터베이스
- 데이터 세트
- 날짜
- 태만
- 한정된
- 정의
- 정의
- 델타
- 보여
- 시연
- 보여줍니다
- 의존
- 디자인
- 세부설명
- 탐지 된
- 데브
- 다른
- 직접
- 말라
- 더블
- 다운로드
- 마다
- 용이하게
- 쉽게
- 편집자
- 효율적인
- 중
- 제거
- 수
- 엔진
- 기사
- 매니아
- 항목
- 에테르 (ETH)
- 진화
- 예
- 있다
- 현존하는
- 경험
- 설명
- 탐험
- 확장하다
- 외부
- 여분의
- FAST
- 특징
- 입양 부모로서의 귀하의 적합성을 결정하기 위해 미국 이민국에
- 파일
- 필터링
- Find
- 굳은
- 먼저,
- 유연성
- 수행원
- 럭셔리
- 체재
- 자주
- 에
- 충분히
- 추가
- 얻을
- 제공
- 공
- 간다
- 큰
- 그룹
- 처리
- 있다
- he
- 도움이
- 역사적인
- 기대
- 방법
- How To
- HTML
- HTTP
- HTTPS
- if
- in
- 독립
- 정보
- 완성
- 인텔리전스
- 으로
- IT
- 그
- 어울리다
- JPG
- JSON
- Justin
- 유지
- 키
- 소금물
- 넓은
- 가장 큰
- 성
- 후에
- 최근
- 배우다
- 적게
- 처럼
- 제한
- 라인
- LINK
- 명부
- 하중
- 지방의
- 위치
- 유지하다
- 제작
- 유튜브 영상을 만드는 것은
- 관리
- 관리
- 관리하다
- 태도
- 조작
- 수동으로
- 지도
- 시장
- 마케팅
- 방법
- 소개
- 메타 데이터
- 현대
- 배우기
- 가장
- 움직임
- 움직이는
- 절대로 필요한 것
- name
- 출신
- 필요
- 필요
- 요구
- 신제품
- 다음 것
- 다음 세대
- 아니
- 주의
- 지금
- 번호
- NYC
- of
- 장교
- on
- 열 수
- 조작
- 행정부
- 최적화
- 최적화
- 최적화
- 옵션
- or
- 원래
- 기타
- 우리의
- 출력
- 위에
- 페이지
- 열렬한
- 수행
- 성능
- 기간
- 계획
- 계획
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 포인트 적립
- 게시하다
- 가능성
- 힘
- 전제 조건
- 시사
- 너무 이른
- 이전에
- 문제
- 방법
- 프로덕트
- 속성
- 제공
- 공개
- 쿼리
- 읽기
- 기록
- 감소
- 지방
- 제거
- 교체
- 필수
- REST
- 반품
- 강력한
- 달리기
- 달리는
- 같은
- 본
- 라고
- 확장성
- 규모
- 주사
- 스캐닝
- 검색
- 계획들
- 원활한
- 완벽하게
- 섹션
- 안전해야합니다.
- 참조
- 연장자
- 서버리스
- 서비스
- 세트
- 영상을
- 표시
- 보여
- 표시
- 쇼
- 단순, 간단, 편리
- 단일
- 해결책
- 솔루션
- 해결
- 일부
- 출처
- 지우면 좋을거같음 . SM
- 소싱
- 전문가
- 전문적으로
- 명세서
- 명세서
- 스펙트럼
- SQL
- 표준
- 시작 중
- 성명서
- 통계
- 단계
- 단계
- 저장
- 저장
- 저장
- 상점
- 전략
- 끈
- 성공
- 이러한
- SUPPORT
- 지원
- 지원
- 테이블
- 팀
- 기술
- Technology
- 수십
- 보다
- 그
- XNUMXD덴탈의
- 소스
- 그들의
- 그때
- Bowman의
- 이
- 수천
- 을 통하여
- 시간
- 시간 여행
- 따라서 오른쪽 하단에
- 에
- 오늘
- 검색을
- 거래상의
- 여행
- 진실
- 두
- 유형
- 유형
- 통일
- 노동 조합
- 잠금을 해제
- 업데이트
- 업데이트
- 업데이트
- 용법
- 사용
- 익숙한
- 사용자
- 사용
- 사용
- 유효 기간
- 가치
- 마케팅은:
- 종류
- 여러
- 대단히
- 를 통해
- 관측
- 볼륨
- 창고
- 창고
- 였다
- 방법..
- we
- 웹
- 웹 서비스
- 언제
- 어느
- 누구
- 넓은
- 크게
- 의지
- 과
- 일
- year
- 년
- 당신
- 너의
- 제퍼 넷