편집자별 이미지
주요 요점
- t-테스트는 두 개의 독립적인 데이터 샘플의 평균 사이에 유의한 차이가 있는지 확인하는 데 사용할 수 있는 통계 테스트입니다.
- iris 데이터 세트와 Python의 Scipy 라이브러리를 사용하여 t-테스트를 적용하는 방법을 설명합니다.
t-테스트는 두 개의 독립적인 데이터 샘플의 평균 사이에 유의한 차이가 있는지 확인하는 데 사용할 수 있는 통계 테스트입니다. 이 자습서에서는 두 샘플의 분산이 같다고 가정하는 가장 기본적인 t-테스트 버전을 설명합니다. t-검정의 다른 고급 버전에는 t-검정을 개조한 Welch의 t-검정이 포함되며 두 표본의 분산이 다르고 표본 크기가 같지 않을 때 더 신뢰할 수 있습니다.
t 통계 또는 t-값은 다음과 같이 계산됩니다.
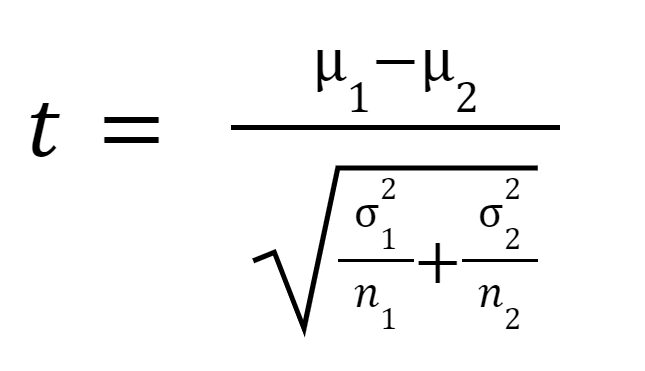
어디에
샘플 1의 평균,
샘플 2의 평균,
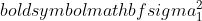 샘플 1의 분산,
샘플 1의 분산, 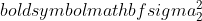 샘플 2의 분산,
샘플 2의 분산, 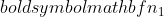 샘플 1의 샘플 크기이고
샘플 1의 샘플 크기이고 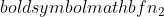 샘플 2의 샘플 크기입니다.
샘플 2의 샘플 크기입니다.
t-테스트의 사용을 설명하기 위해 홍채 데이터셋을 사용하는 간단한 예를 보여드리겠습니다. 예를 들어, 꽃받침 길이와 같은 두 개의 독립적인 샘플을 관찰하고 두 샘플이 동일한 모집단(예: 꽃의 동일한 종 또는 유사한 꽃받침 특성을 가진 두 종) 또는 두 개의 다른 모집단에서 추출되었는지 여부를 고려한다고 가정합니다.
t-테스트는 두 샘플의 산술 평균 간의 차이를 정량화합니다. p-값은 귀무 가설(샘플이 동일한 모집단 평균을 가진 모집단에서 추출됨)이 참이라고 가정하여 관찰된 결과를 얻을 확률을 정량화합니다. 선택한 임계값(예: 5% 또는 0.05)보다 큰 p-값은 우리의 관찰이 우연히 발생했을 가능성이 그리 높지 않음을 나타냅니다. 따라서 모집단 평균이 같다는 귀무가설을 채택합니다. p-값이 임계값보다 작으면 모집단 평균이 같다는 귀무가설에 반하는 증거가 있습니다.
T-테스트 입력
t-검정을 수행하는 데 필요한 입력 또는 매개변수는 다음과 같습니다.
- 두 개의 어레이 a 및 b 샘플 1 및 샘플 2에 대한 데이터를 포함하는
T-테스트 출력
t-테스트는 다음을 반환합니다.
- 계산된 t-통계량
- p- 값
필요한 라이브러리 가져오기
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
홍채 데이터셋 불러오기
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
표본 평균 및 표본 분산 계산
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
t-테스트 구현
stats.ttest_ind(a_1, b_1, equal_var = False)
산출
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
산출
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
산출
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)관측
"equal-var" 매개변수에 "true" 또는 "false"를 사용해도 t-테스트 결과가 크게 변경되지 않는 것을 관찰했습니다. 또한 샘플 배열 a_1 및 b_1의 순서를 교환하면 음의 t-테스트 값이 생성되지만 예상대로 t-테스트 값의 크기는 변경되지 않습니다. 계산된 p-값이 임계값 0.05보다 훨씬 크기 때문에 표본 1과 표본 2의 평균 차이가 유의하다는 귀무가설을 기각할 수 있습니다. 이는 샘플 1과 샘플 2의 꽃받침 길이가 동일한 모집단 데이터에서 추출되었음을 보여줍니다.
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
표본 평균 및 표본 분산 계산
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
t-테스트 구현
stats.ttest_ind(a_1, b_1, equal_var = False)
산출
stats.ttest_ind(a_1, b_1, equal_var = False)관측
크기가 다른 표본을 사용해도 t-통계량과 p-값이 크게 변하지 않는다는 것을 관찰했습니다.
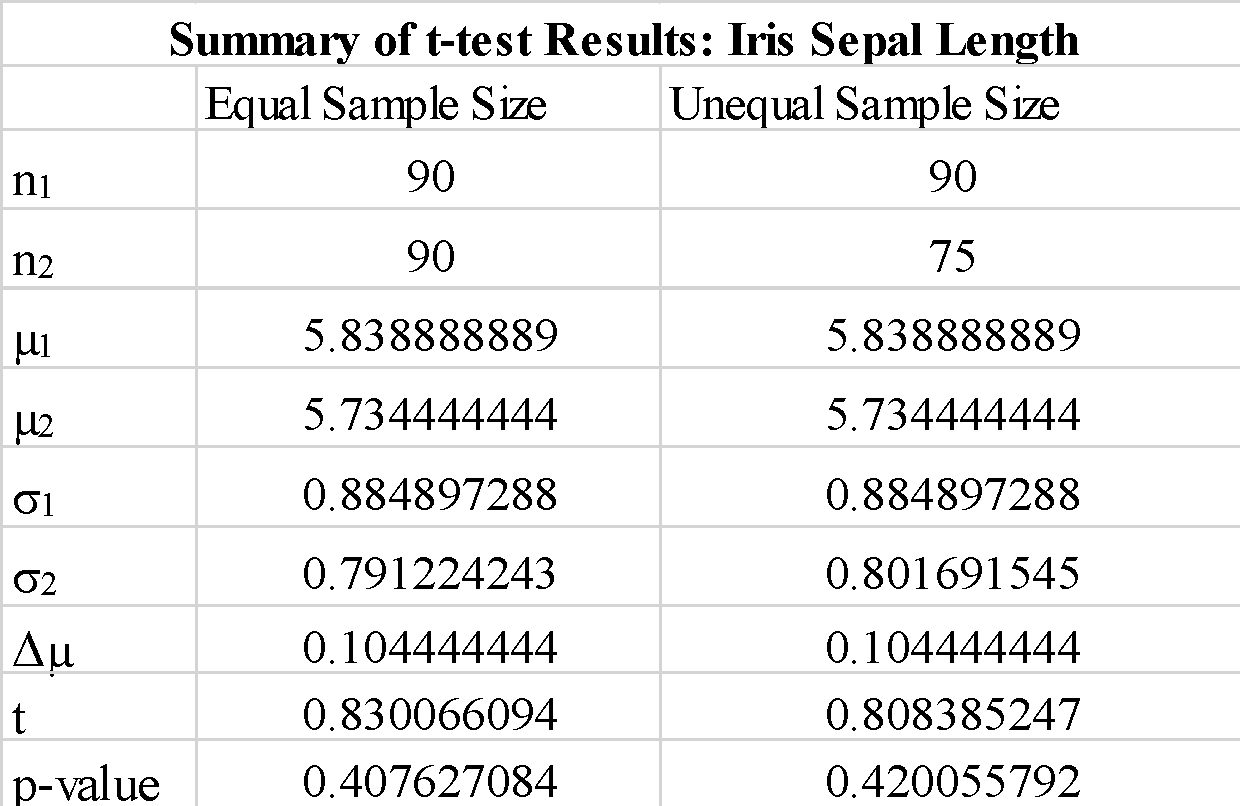
요약하면 파이썬에서 scipy 라이브러리를 사용하여 간단한 t-테스트를 구현하는 방법을 보여주었습니다.
벤자민 오 타요 물리학자, 데이터 과학 교육자 및 작가이며 DataScienceHub의 소유자입니다. 이전에 Benjamin은 U. of Central Oklahoma, Grand Canyon U. 및 Pittsburgh State U.에서 공학 및 물리학을 가르쳤습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- 수락
- 많은
- 반대
- 및
- 적용된
- 기본
- 막내 둥이
- 사이에
- 계산 된
- 중심적인
- 기회
- 이전 단계로 돌아가기
- 특성
- 선택
- 치고는
- 수
- 데이터
- 데이터 과학
- 데이터 세트
- 결정
- 차이
- 다른
- 그린
- 엔지니어링
- 증거
- 예
- 기대하는
- 꽃
- 수행원
- 다음
- 에
- 방법
- HTTPS
- 구현
- import
- in
- 포함
- 독립
- 표시
- 너 겟츠
- 큰
- 도서관
- 링크드인
- 매트플롯립
- 방법
- 배우기
- 가장
- 필요한
- 부정
- numpy
- 관찰
- 획득
- 발생
- 오클라호마
- 주문
- 기타
- 소유자
- 매개 변수
- 매개 변수
- 실행할 수 있는
- 물리학
- 피츠버그
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 인구
- 인구
- 이전에
- 확률
- Python
- 신뢰할 수있는
- 결과
- 반품
- 같은
- 과학
- 표시
- 표시
- 쇼
- 상당한
- 크게
- 비슷한
- 단순, 간단, 편리
- 이후
- 크기
- 크기
- 작은
- So
- 주 정부
- 통계적인
- 통계
- 개요
- 교육
- test
- XNUMXD덴탈의
- 따라서
- 임계값
- 에
- 참된
- 지도 시간
- 사용
- 가치
- 버전
- 여부
- 어느
- 의지
- 작가
- 산출량
- 제퍼 넷