현대 사회에서 대부분의 비즈니스는 빅 데이터 및 분석의 힘에 의존하여 성장, 전략적 투자 및 고객 참여를 촉진합니다. 빅 데이터는 대상 광고, 개인화된 마케팅, 제품 추천, 인사이트 생성, 가격 최적화, 정서 분석, 예측 분석 등의 기본 상수입니다.
데이터는 종종 여러 소스에서 수집되어 온프레미스 또는 온클라우드 데이터 레이크에서 변환, 저장 및 처리됩니다. 데이터의 초기 수집은 비교적 사소하고 사내에서 개발한 사용자 정의 스크립트 또는 기존 ETL(Extract Transform Load) 도구를 통해 수행할 수 있지만 회사에서 다음과 같은 작업을 수행해야 하므로 문제가 빠르게 복잡해지고 비용이 많이 듭니다.
- 하우스키핑 및 규정 준수를 위해 전체 데이터 수명 주기 관리
- 스토리지 최적화 - 관련 비용 절감
- 아키텍처 단순화 – 컴퓨팅 인프라 재사용을 통해
- 강력한 상태 관리를 통해 점진적으로 데이터 처리
- 중복 작업 없이 배치 및 스트림 데이터에 동일한 정책 적용
- 최소한의 노력으로 온프레미스와 클라우드 간 마이그레이션
그것은 어디 아파치 고블린, 오픈 소스 데이터 관리 및 통합 시스템이 제공됩니다. Apache Gobblin은 비즈니스 요구에 따라 전체 또는 부분적으로 사용할 수 있는 탁월한 기능을 제공합니다.
이 섹션에서는 앞에서 설명한 문제를 해결하는 데 도움이 되는 Apache Gobblin의 다양한 기능을 자세히 살펴봅니다.
전체 데이터 수명 주기 관리
Apache Gobblin은 데이터 세트에서 전체 데이터 수명 주기 작업을 지원하는 데이터 파이프라인을 구성하는 다양한 기능을 제공합니다.
- 데이터 수집 - 데이터베이스, Rest API, FTP/SFTP 서버, 파일러, Salesforce 및 Dynamics와 같은 CRM 등 여러 소스에서 싱크까지.
- 데이터 복제 – Distcp-NG를 통해 Hadoop 분산 파일 시스템을 위한 특수 기능을 사용하여 여러 데이터 레이크 간에 데이터를 복제합니다.
- 데이터 제거 – 시간 기반, 최신 K, 버전 지정 또는 정책 조합과 같은 보존 정책을 사용합니다.
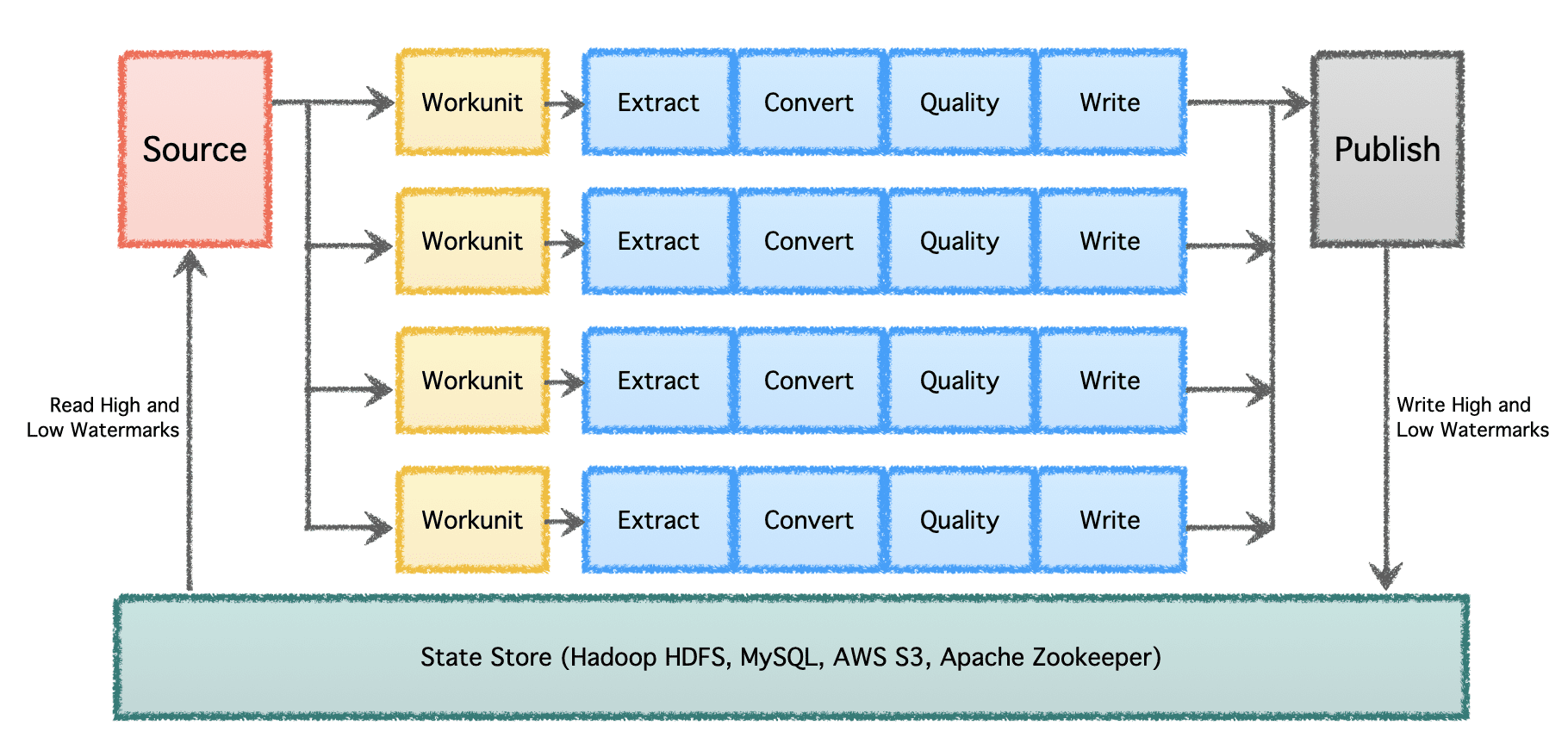
Gobblin의 논리적 파이프라인은 작업의 분포를 결정하고 'Workunits'를 생성하는 'Source'로 구성됩니다. 이러한 '작업 단위'는 추출, 변환, 품질 검사 및 대상에 대한 데이터 쓰기를 포함하는 '작업'으로 실행을 위해 선택됩니다. 마지막 단계인 '데이터 게시'는 파이프라인의 성공적인 실행을 확인하고 대상에서 지원하는 경우 출력 데이터를 원자적으로 커밋합니다.
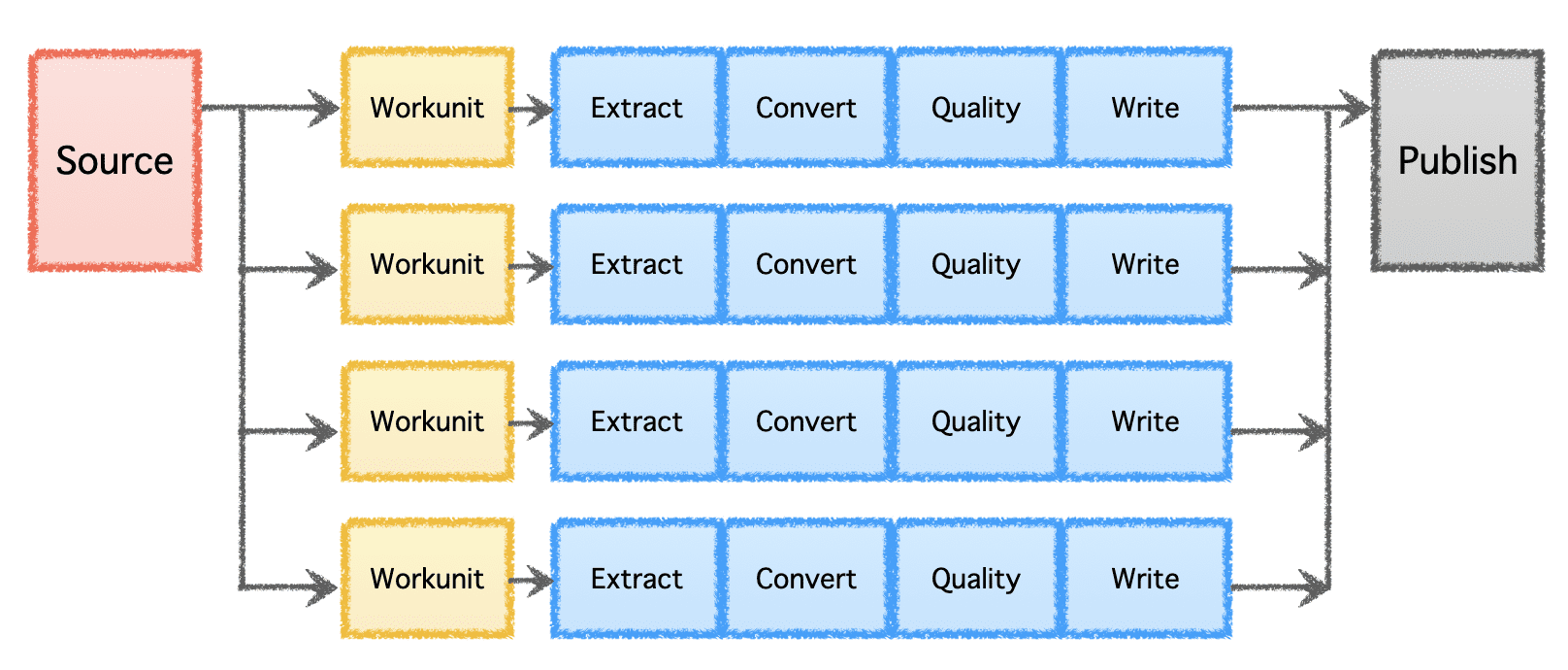
작성자 별 이미지
스토리지 최적화
Apache Gobblin은 수집 후 데이터 후처리 또는 압축 또는 형식 변환을 통한 복제를 통해 데이터에 필요한 스토리지 양을 줄이는 데 도움을 줄 수 있습니다.
- 압축 – 레코드의 모든 필드 또는 키 필드를 기반으로 중복 제거할 데이터 후처리, 동일한 키를 가진 최신 타임스탬프가 있는 하나의 레코드만 유지하도록 데이터를 트리밍합니다.
- Avro에서 ORC로 – 널리 사용되는 행 기반 Avro 형식을 고도로 최적화된 열 기반 ORC 형식으로 변환하는 특수 형식 변환 메커니즘입니다.
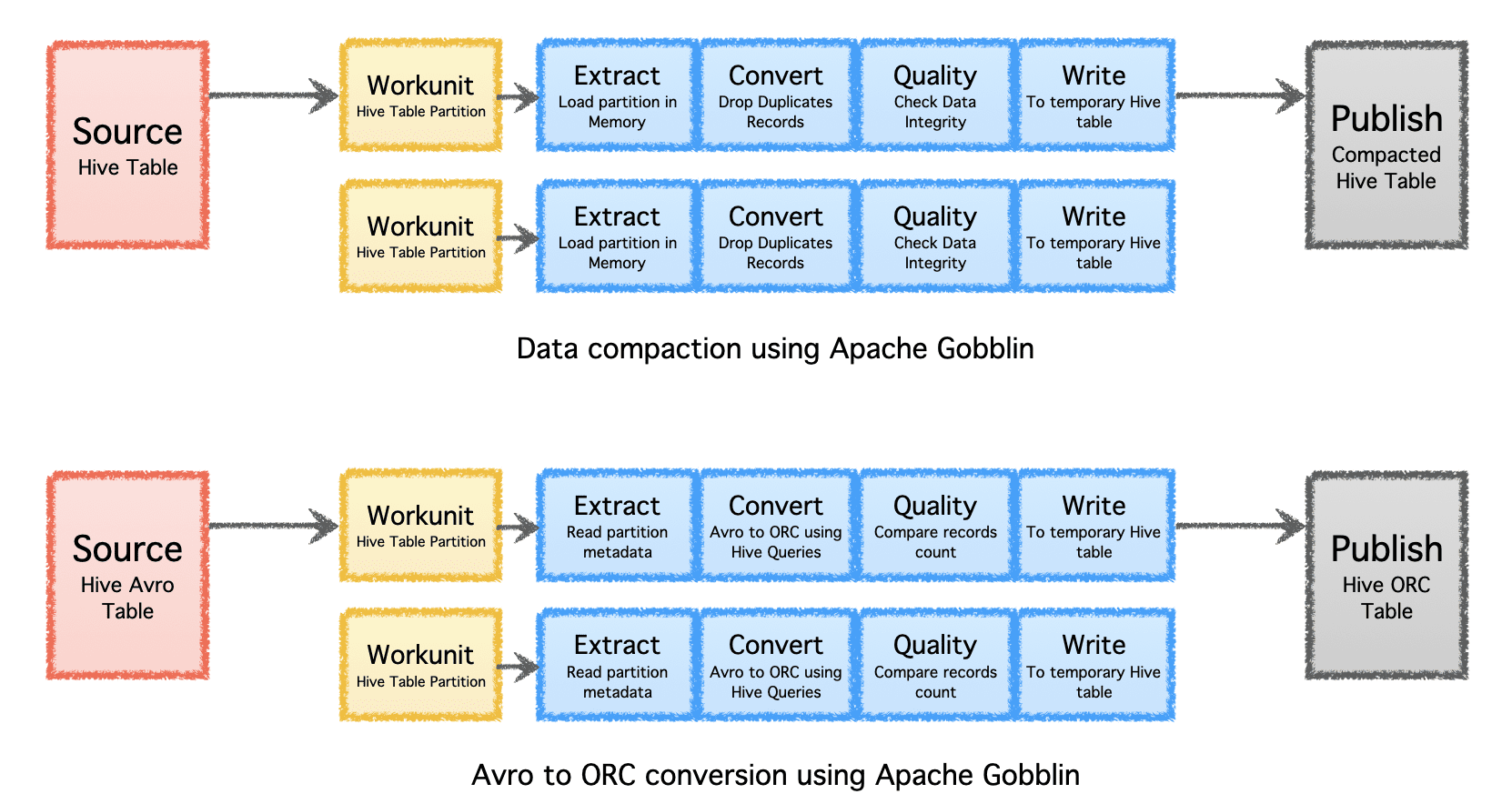
작성자 별 이미지
아키텍처 단순화
회사의 단계(스타트업에서 엔터프라이즈까지), 확장 요구 사항 및 해당 아키텍처에 따라 회사는 데이터 인프라를 설정하거나 발전시키는 것을 선호합니다. Apache Gobblin은 매우 유연하며 여러 실행 모델을 지원합니다.
- 독립 실행형 모드 - 베어 메탈 박스에서 독립 실행형 프로세스로 실행합니다.
- MapReduce 모드 – 대용량 데이터 사례를 위해 Hadoop 인프라에서 MapReduce 작업으로 실행하여 페타바이트 규모의 데이터 세트를 처리합니다.
- 클러스터 모드: 독립 실행형 – Hadoop MR 프레임워크와 독립적으로 대규모를 처리하기 위해 일련의 베어 메탈 머신 또는 호스트에서 Apache Helix 및 Apache Zookeeper가 지원하는 클러스터로 실행합니다.
- 클러스터 모드: Yarn – Hadoop MR 프레임워크 없이 기본 Yarn에서 클러스터로 실행합니다.
- 클러스터 모드: AWS – Amazon의 퍼블릭 클라우드 오퍼링에서 클러스터로 실행합니다. AWS에서 호스팅되는 인프라용 AWS.
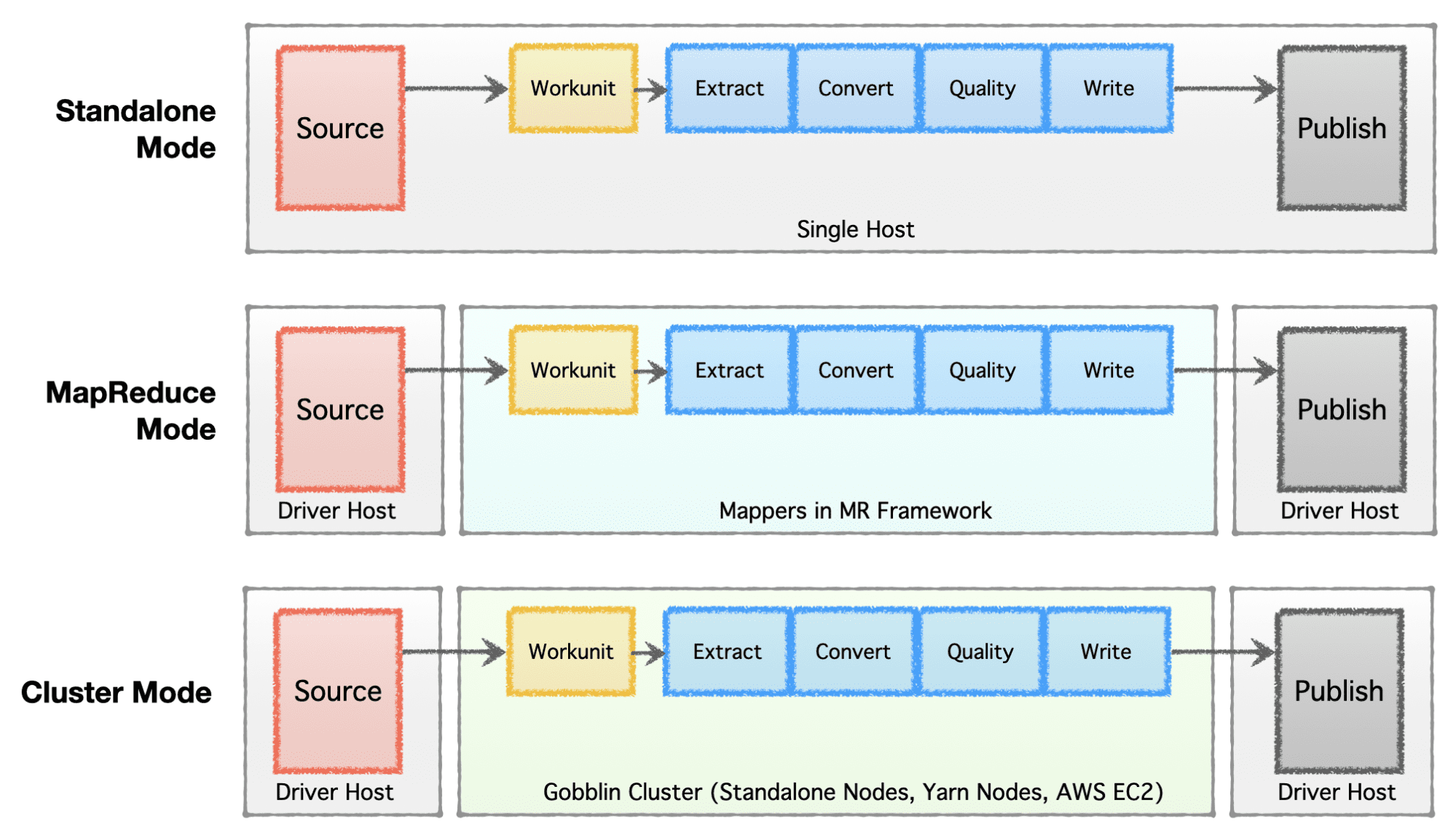
작성자 별 이미지
점진적으로 데이터 처리
여러 데이터 파이프라인과 대용량으로 상당한 규모에서 데이터는 시간이 지남에 따라 배치로 처리되어야 합니다. 따라서 데이터 파이프라인이 마지막으로 중단된 위치에서 다시 시작하여 계속 진행할 수 있도록 체크포인트가 필요합니다. Apache Gobblin은 로우 및 하이 워터마크를 지원하고 HDFS, AWS S3, MySQL 등의 State Store를 통해 보다 투명하게 강력한 상태 관리 의미 체계를 지원합니다.
작성자 별 이미지
배치 및 스트림 데이터에 대한 동일한 정책
오늘날 대부분의 데이터 파이프라인은 배치 데이터용으로 한 번, 니어라인 또는 스트리밍 데이터용으로 두 번 작성해야 합니다. 이는 노력을 두 배로 늘리고 다양한 유형의 파이프라인에 적용되는 정책 및 알고리즘에 불일치를 도입합니다. Apache Gobblin은 사용자가 파이프라인을 한 번 작성하고 Gobblin Cluster 모드, Gobblin on AWS 모드 또는 Gobblin on Yarn 모드에서 사용되는 경우 배치 및 스트림 데이터 모두에서 실행할 수 있도록 허용하여 이 문제를 해결합니다.
온프레미스와 클라우드 간 마이그레이션
단일 상자, 노드 클러스터 또는 클라우드에서 온프레미스를 실행할 수 있는 다목적 모드로 인해 Apache Gobblin을 온프레미스 및 클라우드에서 배포하고 사용할 수 있습니다. 따라서 사용자가 데이터 파이프라인을 한 번 작성하고 특정 요구 사항에 따라 온프레미스와 클라우드 간에 쉽게 Gobblin 배포와 함께 마이그레이션할 수 있습니다.
매우 유연한 아키텍처, 강력한 기능 및 지원하고 처리할 수 있는 엄청난 규모의 데이터로 인해 Apache Gobblin은 주요 기술 회사 오늘날 모든 빅 데이터 인프라 배포를 위한 필수 요소입니다.
Apache Gobblin 및 사용 방법에 대한 자세한 내용은 다음에서 확인할 수 있습니다. https://gobblin.apache.org
아비섹 티와리 LinkedIn의 선임 관리자로서 회사의 빅 데이터 파이프라인 조직을 이끌고 있습니다. Apache Software Foundation의 Apache Gobblin 부사장이자 British Computer Society의 회원이기도 합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/2023/01/scaling-data-management-apache-gobblin.html?utm_source=rss&utm_medium=rss&utm_campaign=scaling-data-management-through-apache-gobblin
- a
- 달성
- 주소 지정
- 광고
- 후
- 도움
- 알고리즘
- All
- 허용
- 양
- 분석
- 분석
- 및
- 아파치
- API
- 적용된
- 아키텍처
- 관련
- 저자
- AWS
- 뒷받침 된
- 기반으로
- 된다
- 사이에
- 큰
- 빅 데이터
- 보물상자
- 영국의
- 사업
- 사업
- 기능
- 가지 경우
- 과제
- 확인
- 클라우드
- 클러스터
- 결합
- 기업
- 회사
- 복잡한
- compliance
- 컴퓨터
- 컴퓨팅
- 상수
- 구축
- 계속
- 매출 상승
- 변하게 하다
- 생성
- 관습
- 고객
- 고객 참여
- 데이터
- 데이터 인프라
- 데이터 관리
- 데이터베이스
- 데이터 세트
- 의존
- 배포
- 전개
- 배포
- 목적지
- 세부설명
- 결정하다
- 개발
- 다른
- 분산
- 분포
- 역학
- 용이하게
- 노력
- 약혼
- Enterprise
- 에테르 (ETH)
- 진화시키다
- 실행
- 비싼
- 추출물
- 추출
- 극단
- 특징
- 사람
- Fields
- 입양 부모로서의 귀하의 적합성을 결정하기 위해 미국 이민국에
- 최후의
- 융통성있는
- 체재
- 발견
- Foundation
- 뼈대
- 에
- 연료
- 가득 찬
- 세대
- 성장
- 하둡
- 핸들
- 도움
- 높은
- 고도로
- 주인
- 호스팅
- 방법
- How To
- HTTPS
- in
- 포함
- 독립
- 인프라
- 하부 구조
- 처음에는
- 통찰력
- 완성
- 소개합니다
- 투자
- IT
- 일
- 너 겟츠
- 유지
- 키
- 넓은
- 성
- 최근
- 지도
- 링크드인
- 하중
- 낮은
- 기계
- 구축
- 매니저
- 마케팅
- 기구
- 금속
- 이전
- 모드
- 모델
- 현대
- 모드
- 배우기
- 가장
- 여러
- 가지고 있어야
- MySQL의
- 출신
- 필요
- 요구
- 최신
- 노드
- 제공
- ONE
- 오픈 소스
- 행정부
- 조직
- 설명
- 부품
- 맞춤형 교육 플랫폼
- 뽑힌
- 관로
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 정책
- 인기 문서
- 힘
- 강한
- 예측 분석
- 취하다
- 대통령
- 이전에
- 가격
- 문제
- 방법
- 프로덕트
- 생산
- 제공
- 공개
- 공공 클라우드
- 게시
- 품질
- 빨리
- 이르기까지
- 추천
- 기록
- 기록
- 감소
- 상대적으로
- 복제
- 요구조건 니즈
- 그
- REST
- 이력서
- 보유
- 강력한
- 달리기
- 영업
- 같은
- 규모
- 스케일링
- 스크립트
- 섹션
- 의미론
- 연장자
- 감정
- 세트
- 상당한
- 단순, 간단, 편리
- 단일
- 상황
- So
- 사회
- 소프트웨어
- 풀다
- 해결
- 출처
- 지우면 좋을거같음 . SM
- 전문
- 구체적인
- 단계
- 독립
- 시작
- 주 정부
- 단계
- 저장
- 저장
- 저장
- 전략의
- 흐름
- 스트리밍
- 성공한
- 스위트
- SUPPORT
- 지원
- 체계
- 대상
- 작업
- Technology
- XNUMXD덴탈의
- 그들의
- 따라서
- 을 통하여
- 시간
- 따라서 오른쪽 하단에
- 에
- 오늘
- 검색을
- 전통적인
- 변환
- 변환
- 유형
- 밑에 있는
- 견줄 나위없는
- 사용
- 사용자
- 여러
- 다양한
- 를 통해
- 부통령
- 음량
- 볼륨
- 어느
- 동안
- 의지
- 없이
- 작업
- 세계
- 쓰다
- 쓰기
- 쓴
- 제퍼 넷