Amazon SageMakerスタジオ は、データ サイエンティストが機械学習 (ML) モデルを対話的に構築、トレーニング、デプロイできるフルマネージド ソリューションを提供します。 Amazon SageMaker ノートブックのジョブ データ サイエンティストは、SageMaker Studio で数回クリックするだけで、オンデマンドまたはスケジュールに従ってノートブックを実行できるようになります。今回のリリースにより、提供される API を使用してノートブックをプログラムでジョブとして実行できるようになります。 AmazonSageMakerパイプラインの ML ワークフロー オーケストレーション機能 アマゾンセージメーカー。さらに、これらの API を使用して、複数の依存ノートブックを含むマルチステップ ML ワークフローを作成できます。
SageMaker Pipelines は、SageMaker の直接統合を利用する ML パイプラインを構築するためのネイティブ ワークフロー オーケストレーション ツールです。各 SageMaker パイプラインは次のもので構成されます。 ステップ、処理、トレーニング、データ処理などの個別のタスクに対応します。 アマゾンEMR。 SageMaker ノートブック ジョブは、SageMaker パイプラインの組み込みステップ タイプとして利用できるようになりました。このノートブック ジョブ ステップを使用すると、わずか数行のコードでノートブックをジョブとして簡単に実行できます。 Amazon SageMaker Python SDK。さらに、複数の依存ノートブックを結合して、有向非巡回グラフ (DAG) の形式でワークフローを作成できます。その後、これらのノートブック ジョブまたは DAG を実行し、SageMaker Studio を使用してそれらを管理および視覚化できます。
データ サイエンティストは現在、SageMaker Studio を使用して Jupyter ノートブックを対話的に開発し、SageMaker ノートブック ジョブを使用してこれらのノートブックをスケジュールされたジョブとして実行します。これらのジョブは、データ ワーカーがコードを Python モジュールとしてリファクタリングする必要がなく、すぐに実行することも、定期的なタイム スケジュールで実行することもできます。これを行うための一般的な使用例には次のようなものがあります。
- バックグラウンドでの長時間実行ノートブックの実行
- モデル推論を定期的に実行してレポートを生成する
- 小さなサンプル データセットの準備からペタバイト規模のビッグ データの操作へのスケールアップ
- 一定のリズムでモデルを再トレーニングしてデプロイする
- モデル品質またはデータドリフト監視のためのジョブのスケジュール設定
- より良いモデルを得るためにパラメーター空間を探索する
この機能により、データ ワーカーはスタンドアロン ノートブックを簡単に自動化できますが、ML ワークフローは多くの場合、複数のノートブックで構成され、それぞれが複雑な依存関係を持つ特定のタスクを実行します。たとえば、モデル データのドリフトを監視するノートブックには、新しいデータの抽出、変換、ロード (ETL) と処理を可能にする前ステップと、重大なドリフトが見つかった場合に備えたモデルの更新とトレーニングの後ステップが必要です。 。さらに、データ サイエンティストは、このワークフロー全体を定期的なスケジュールでトリガーして、新しいデータに基づいてモデルを更新したい場合があります。ノートブックを簡単に自動化し、このような複雑なワークフローを作成できるようにするために、SageMaker ノートブック ジョブが SageMaker Pipelines のステップとして利用できるようになりました。この投稿では、数行のコードで次のユースケースを解決する方法を示します。
- スタンドアロン ノートブックをプログラムで即時または定期的なスケジュールで実行します。
- SageMaker Studio UI 経由で管理できる継続的インテグレーションおよび継続的デリバリー (CI/CD) を目的として、ノートブックの複数ステップのワークフローを DAG として作成します。
ソリューションの概要
次の図は、ソリューション アーキテクチャを示しています。 SageMaker Python SDK を使用して、単一のノートブック ジョブまたはワークフローを実行できます。この機能は、ノートブックを実行するための SageMaker トレーニング ジョブを作成します。
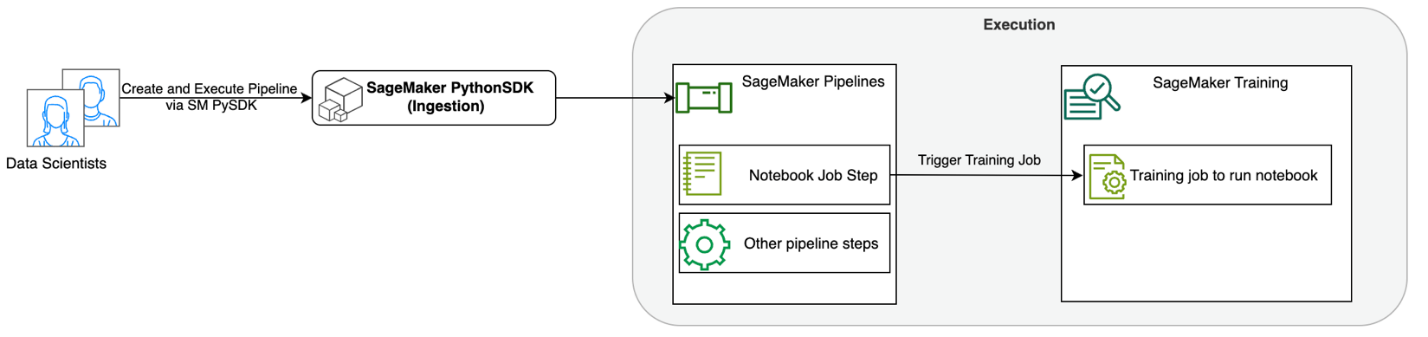
次のセクションでは、サンプル ML ユースケースを説明し、ノートブック ジョブのワークフローを作成する手順、さまざまなノートブック ステップ間でパラメーターを渡す手順、ワークフローのスケジュール設定方法、および SageMaker Studio を介した監視手順を紹介します。
この例の ML 問題では、テキスト分類タスクの一種である感情分析モデルを構築しています。感情分析の最も一般的な用途には、ソーシャル メディアの監視、顧客サポート管理、顧客フィードバックの分析などがあります。この例で使用されているデータセットは、Stanford Sentiment Treebank (SST2) データセットです。このデータセットは、映画レビューと、そのレビューの肯定的または否定的な感情を示す整数 (0 または 1) で構成されています。
以下は、 data.csv SST2 データセットに対応するファイルで、最初の XNUMX 列に値が表示されます。ファイルにはヘッダーがないことに注意してください。
| 列1 | 列2 |
| 0 | 親機からの新しい分泌物を隠す |
| 0 | ウィットはなく、苦労したギャグだけが含まれています |
| 1 | 登場人物を愛し、人間の本性についてかなり美しいものを伝えます |
| 0 | ずっと変わらないことに完全に満足している |
| 0 | 映画製作者たちが考えた最悪のオタクへの復讐の常套句について |
| 0 | それはそのような表面的な扱いに値しないほど悲劇的です |
| 1 | パトリオット・ゲームのようなハリウッド大作の監督でも、感情を揺さぶる小規模で個人的な映画を制作できることを証明しています。 |
この ML の例では、いくつかのタスクを実行する必要があります。
- 特徴量エンジニアリングを実行して、モデルが理解できる形式でこのデータセットを準備します。
- 特徴量エンジニアリングの後、Transformers を使用するトレーニング ステップを実行します。
- 微調整されたモデルを使用してバッチ推論を設定し、受信する新しいレビューに対するセンチメントを予測できるようにします。
- データ監視ステップを設定して、モデルの重みの再トレーニングが必要になる可能性のある品質の変動がないか新しいデータを定期的に監視できるようにします。
SageMaker パイプラインのステップとしてノートブック ジョブを開始することで、3 つの異なるステップで構成されるこのワークフローを調整できます。ワークフローの各ステップは異なるノートブックで開発され、その後、独立したノートブック ジョブ ステップに変換され、パイプラインとして接続されます。
- 前処理 – 公開 SST2 データセットを次からダウンロードします。 Amazon シンプル ストレージ サービス (Amazon S3) を実行し、ステップ 2 でノートブックを実行するための CSV ファイルを作成します。 SST2 データセットは、0 つのラベル (1 と XNUMX) と分類するテキストの列を持つテキスト分類データセットです。
- トレーニング – 整形された CSV ファイルを取得し、Transformers ライブラリを利用してテキスト分類のために BERT で微調整を実行します。このステップの一部としてテスト データ準備ノートブックを使用します。これは、微調整およびバッチ推論ステップの依存関係です。微調整が完了すると、このノートブックは実行マジックを使用して実行され、微調整されたモデルによるサンプル推論用のテスト データセットが準備されます。
- 変換と監視 – バッチ推論を実行し、モデル監視を使用してデータ品質を設定して、ベースライン データセットの提案を行います。
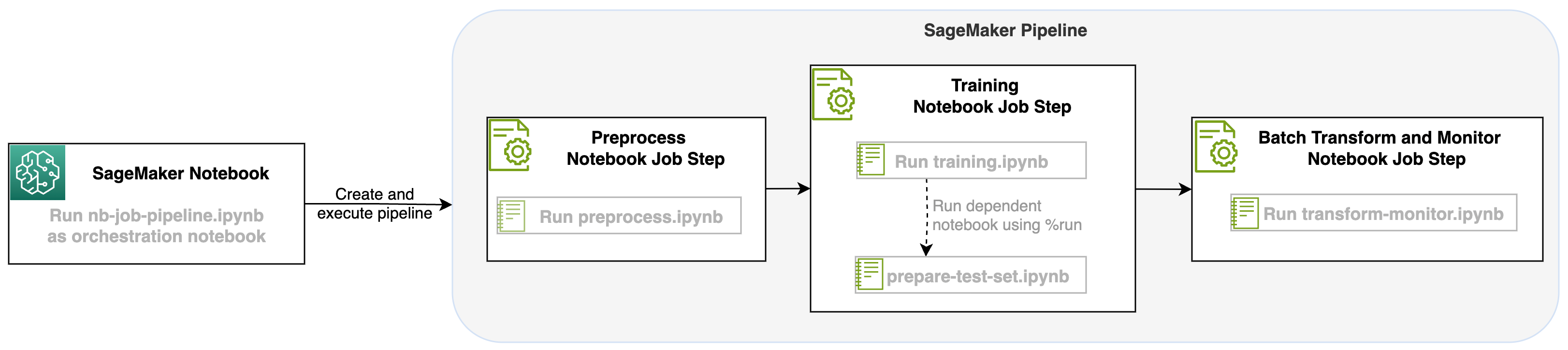
ノートブックを実行する
このソリューションのサンプル コードは、次の場所から入手できます。 GitHubの.
SageMaker ノートブック ジョブ ステップの作成は、他の SageMaker Pipeline ステップの作成と似ています。このノートブックの例では、SageMaker Python SDK を使用してワークフローを調整します。 SageMaker Pipelines でノートブック ステップを作成するには、次のパラメータを定義できます。
- 入力ノート – このノートブック ステップがオーケストレーションするノートブックの名前。ここで、入力ノートブックへのローカル パスを渡すことができます。オプションで、このノートブックに実行中の他のノートブックがある場合は、これらを
AdditionalDependenciesノートブック ジョブ ステップのパラメータ。 - 画像URI – ノートブック ジョブ ステップの背後にある Docker イメージ。これは、SageMaker がすでに提供している事前定義されたイメージ、または定義してプッシュしたカスタム イメージです。 Amazon エラスティック コンテナ レジストリ (アマゾンECR)。サポートされているイメージについては、この投稿の最後にある考慮事項セクションを参照してください。
- カーネル名 – SageMaker Studio で使用しているカーネルの名前。このカーネル仕様は、提供されたイメージに登録されています。
- インスタンスタイプ (オプション) - アマゾン エラスティック コンピューティング クラウド 定義して実行するノートブック ジョブの背後にある (Amazon EC2) インスタンス タイプ。
- パラメータ (オプション) – ノートブックでアクセスできる、渡すことができるパラメーター。これらはキーと値のペアで定義できます。さらに、これらのパラメーターは、さまざまなノートブック ジョブの実行間またはパイプラインの実行間で変更できます。
この例には合計 5 つのノートブックがあります。
- nb-ジョブ-パイプライン.ipynb – これはパイプラインとワークフローを定義するメインのノートブックです。
- 前処理.ipynb – このノートブックはワークフローの最初のステップであり、パブリック AWS データセットを取得し、そこから CSV ファイルを作成するコードが含まれています。
- トレーニング.ipynb – このノートブックはワークフローの 2 番目のステップであり、前のステップから CSV を取得してローカル トレーニングと微調整を行うためのコードが含まれています。このステップには、
prepare-test-set.ipynbノートブックを使用して、微調整されたモデルによるサンプル推論用のテスト データセットをプルダウンします。 - 準備-テスト-セット.ipynb – このノートブックは、トレーニング ノートブックが 2 番目のパイプライン ステップで使用し、微調整されたモデルによるサンプル推論に使用するテスト データセットを作成します。
- 変換モニター.ipynb – このノートブックはワークフローの 3 番目のステップであり、基本 BERT モデルを使用して SageMaker バッチ変換ジョブを実行すると同時に、モデル監視によるデータ品質も設定します。
次に、メインのノートブックについて説明します。 nb-job-pipeline.ipynb、すべてのサブノートブックをパイプラインに結合し、エンドツーエンドのワークフローを実行します。次の例ではノートブックを 1 回だけ実行しますが、ノートブックを繰り返し実行するようにパイプラインをスケジュールすることもできます。参照する SageMakerのドキュメント 詳細な手順については、
最初のノートブック ジョブ ステップでは、デフォルトの S3 バケットを含むパラメーターを渡します。このバケットを使用して、他のパイプライン ステップで使用できるアーティファクトをダンプできます。最初のノートブックの場合 (preprocess.ipynb)、AWS パブリック SST2 トレーニング データセットをプルダウンし、そこからトレーニング CSV ファイルを作成し、この S3 バケットにプッシュします。次のコードを参照してください。
次に、このノートブックを次のように変換できます。 NotebookJobStep メインノートブックに次のコードを追加します。
サンプル CSV ファイルが完成したので、トレーニング ノートブックでモデルのトレーニングを開始できます。私たちのトレーニング ノートブックは、S3 バケットと同じパラメーターを受け取り、その場所からトレーニング データセットをプルダウンします。次に、次のコード スニペットで Transformers トレーナー オブジェクトを使用して微調整を実行します。
微調整した後、バッチ推論を実行してモデルのパフォーマンスを確認したいと思います。これは別のノートブック (prepare-test-set.ipynb) トレーニング済みモデルを使用して推論を実行するテスト データセットを作成する同じローカル パス内にあります。次のマジック セルを使用して、トレーニング ノートブック内の追加のノートブックを実行できます。
この追加のノートブック依存関係を AdditionalDependencies 2 番目のノートブック ジョブ ステップのパラメータ:
また、トレーニング ノートブック ジョブ ステップ (ステップ 2) がノートブックの前処理ジョブ ステップ (ステップ 1) に依存することも指定する必要があります。 add_depends_on 次のようなAPI呼び出し:
最後のステップでは、BERT モデルで SageMaker バッチ変換を実行し、同時に SageMaker モデル モニターを介してデータ キャプチャと品質を設定します。これは組み込みの使用とは異なることに注意してください。 最適化の適用 or キャプチャ パイプライン経由のステップ。このステップのノートブックは同じ API を実行しますが、ノートブック ジョブ ステップとして追跡されます。このステップは、以前に定義したトレーニング ジョブ ステップに依存しているため、depends_on フラグを使用してそれもキャプチャします。
ワークフローのさまざまなステップを定義したら、エンドツーエンドのパイプラインを作成して実行できます。
パイプラインの実行を監視する
次のスクリーンショットに示すように、SageMaker Pipelines DAG を介してノートブック ステップの実行を追跡および監視できます。
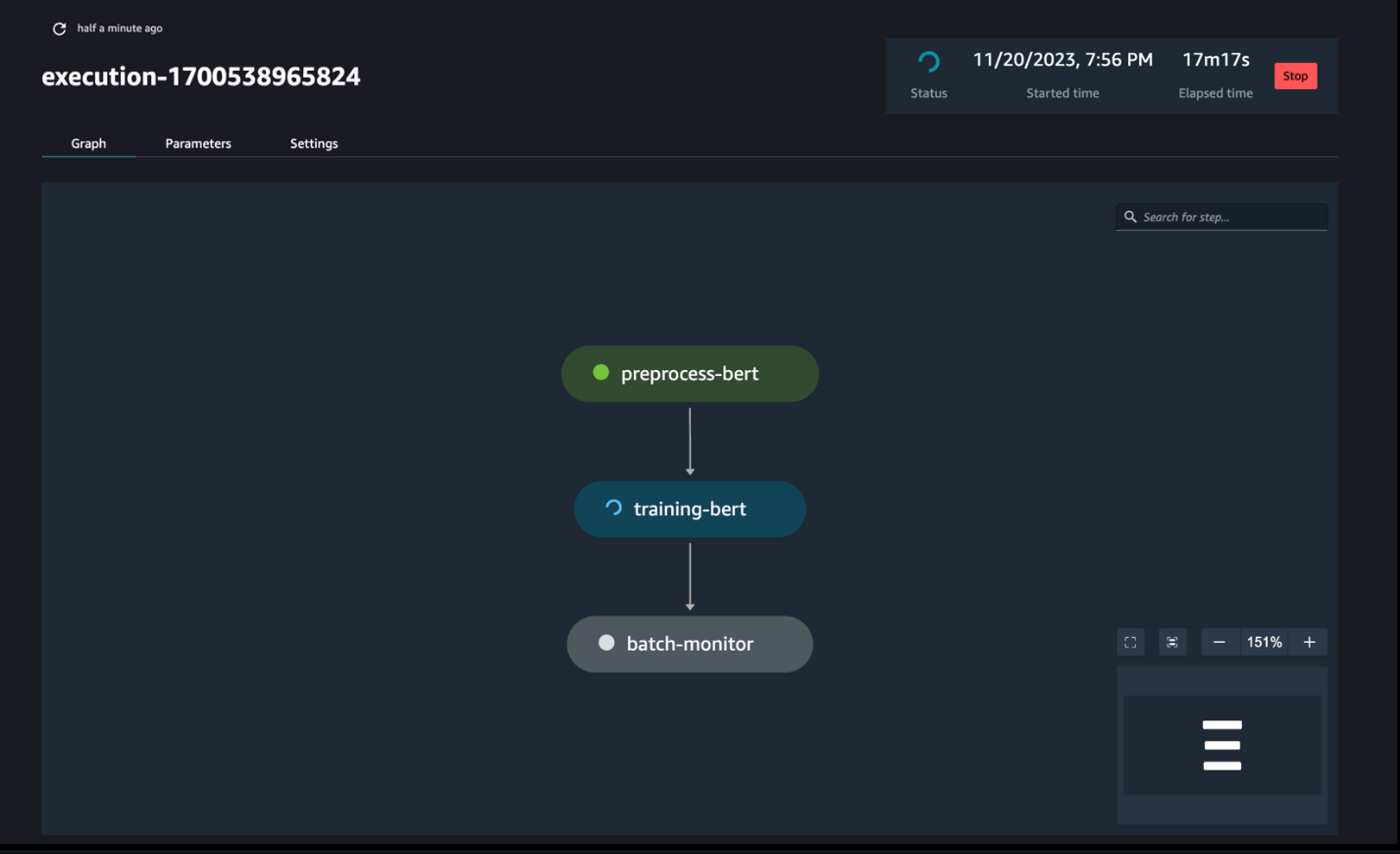
オプションで、ノートブック ジョブ ダッシュボードで個々のノートブックの実行を監視し、SageMaker Studio UI を介して作成された出力ファイルを切り替えることもできます。 SageMaker Studio の外部でこの機能を使用する場合、タグを使用してノートブック ジョブ ダッシュボードで実行ステータスを追跡できるユーザーを定義できます。含めるタグの詳細については、「 Studio UI ダッシュボードでノートブック ジョブを表示し、出力をダウンロードします.
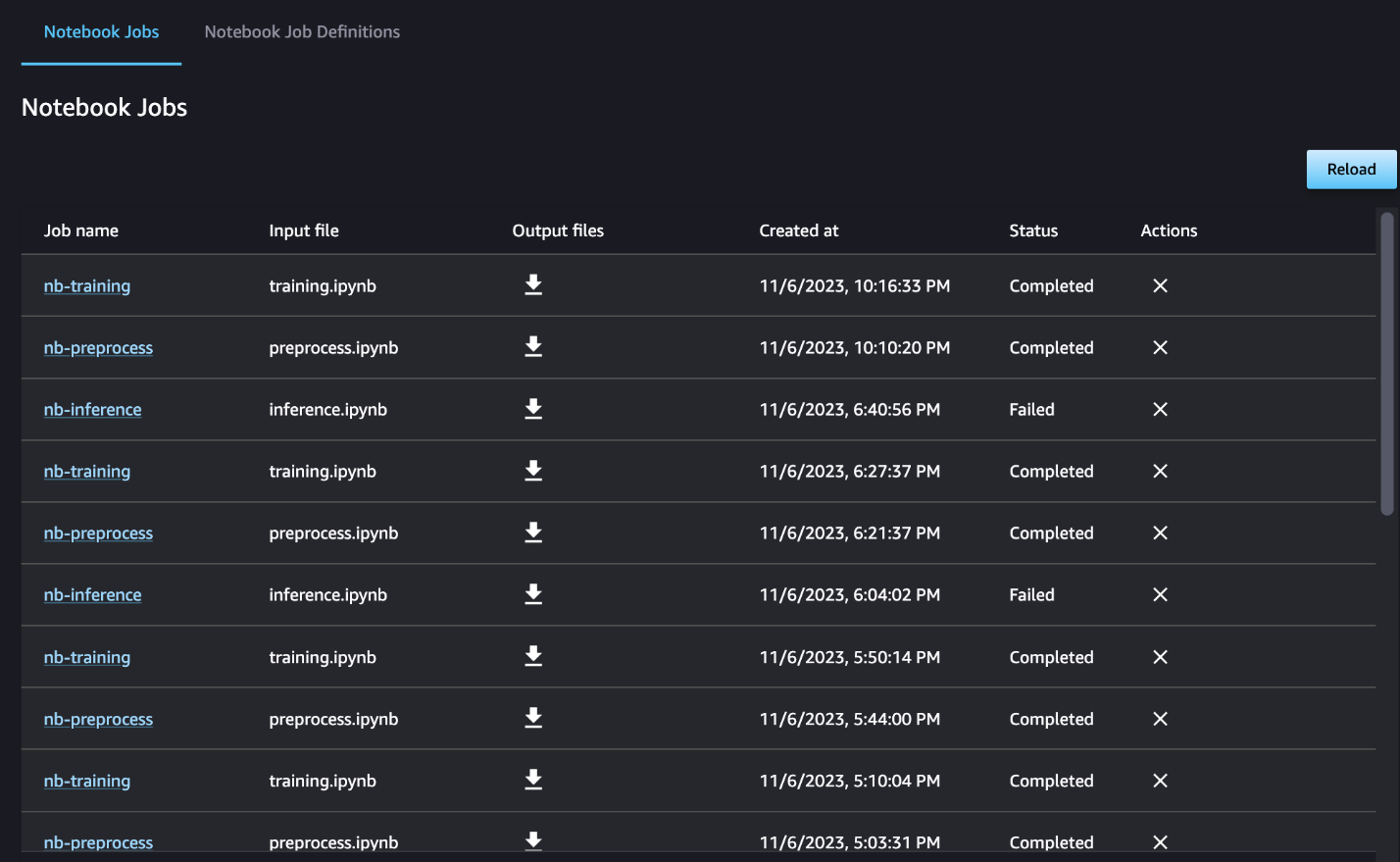
この例では、結果のノートブック ジョブを というディレクトリに出力します。 outputs ローカルパスにパイプライン実行コードを含めます。次のスクリーンショットに示すように、ここでは入力ノートブックの出力と、そのステップで定義したパラメーターを確認できます。
クリーンアップ
この例に従った場合は、作成されたパイプライン、ノートブック ジョブ、およびサンプル ノートブックによってダウンロードされた s3 データを必ず削除してください。
考慮事項
この機能に関する重要な考慮事項は次のとおりです。
- SDKの制約 – ノートブック ジョブ ステップは、SageMaker Python SDK を介してのみ作成できます。
- 画像の制約 –ノートブックのジョブ ステップは、次のイメージをサポートします。
まとめ
今回のリリースにより、データ ワーカーは、 SageMaker Python SDK。さらに、ノートブックを使用して複雑な複数ステップのワークフローを作成できるため、ノートブックから CI/CD パイプラインへの移行に必要な時間を大幅に短縮できます。パイプラインを作成した後、SageMaker Studio を使用してパイプラインの DAG を表示および実行し、実行を管理および比較できます。エンドツーエンドの ML ワークフローまたはその一部をスケジュールしているかどうかにかかわらず、試してみることをお勧めします。 ノートブックベースのワークフロー.
著者について
 アンチット・グプタ Amazon SageMaker Studio のシニアプロダクトマネージャーです。彼女は、SageMaker Studio IDE 内からインタラクティブなデータ サイエンスとデータ エンジニアリングのワークフローを実現することに重点を置いています。余暇には、料理、ボード/カード ゲーム、読書を楽しんでいます。
アンチット・グプタ Amazon SageMaker Studio のシニアプロダクトマネージャーです。彼女は、SageMaker Studio IDE 内からインタラクティブなデータ サイエンスとデータ エンジニアリングのワークフローを実現することに重点を置いています。余暇には、料理、ボード/カード ゲーム、読書を楽しんでいます。
 ラム・ベギラージュ SageMaker サービスチームの ML アーキテクトです。 彼は、お客様が Amazon SageMaker で AI/ML ソリューションを構築および最適化するのを支援することに重点を置いています。 余暇には、旅行と執筆が大好きです。
ラム・ベギラージュ SageMaker サービスチームの ML アーキテクトです。 彼は、お客様が Amazon SageMaker で AI/ML ソリューションを構築および最適化するのを支援することに重点を置いています。 余暇には、旅行と執筆が大好きです。
 エドワードサン アマゾン ウェブ サービスの SageMaker Studio で働くシニア SDE です。 彼は、インタラクティブな ML ソリューションを構築し、カスタマー エクスペリエンスを簡素化して、SageMaker Studio をデータ エンジニアリングおよび ML エコシステムの一般的なテクノロジーと統合することに重点を置いています。 余暇には、エドワードはキャンプ、ハイキング、釣りの大ファンで、家族と過ごす時間を楽しんでいます。
エドワードサン アマゾン ウェブ サービスの SageMaker Studio で働くシニア SDE です。 彼は、インタラクティブな ML ソリューションを構築し、カスタマー エクスペリエンスを簡素化して、SageMaker Studio をデータ エンジニアリングおよび ML エコシステムの一般的なテクノロジーと統合することに重点を置いています。 余暇には、エドワードはキャンプ、ハイキング、釣りの大ファンで、家族と過ごす時間を楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/schedule-amazon-sagemaker-notebook-jobs-and-manage-multi-step-notebook-workflows-using-apis/
- :持っている
- :は
- :どこ
- $UP
- 1
- 100
- 116
- 125
- 視聴者の38%が
- 17
- 20
- 500
- 7
- 8
- a
- 私たちについて
- アクセス可能な
- 非周期的
- NEW
- さらに
- 利点
- 後
- AI / ML
- すべて
- ことができます
- 沿って
- 既に
- また
- しかし
- Amazon
- Amazon EC2
- アマゾンセージメーカー
- Amazon SageMakerスタジオ
- Amazon Webサービス
- an
- 分析
- 分析する
- および
- どれか
- API
- API
- 建築
- です
- AS
- At
- 自動化する
- 利用できます
- AWS
- ベース
- ベース
- ベースライン
- BE
- 美しい
- き
- 背後に
- さ
- より良いです
- の間に
- ビッグ
- ビルド
- 建物
- 内蔵
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- コール
- 呼ばれます
- キャンプ
- 缶
- キャプチャー
- 場合
- 例
- セル
- 文字
- 分類
- コード
- コラム
- コラム
- 組み合わせ
- 来ます
- コマンドと
- 比較します
- コンプリート
- 複雑な
- 構成
- 構成
- 計算
- プロフェッショナルな方法で
- 交流
- 検討事項
- からなる
- コンテナ
- 含まれています
- 連続的な
- 変換
- 変換
- 料理
- 対応する
- 可能性
- 作ります
- 作成した
- 作成します。
- 作成
- 現在
- カスタム
- 顧客
- 顧客満足体験
- カスタマーサービス
- Customers
- DAG
- ダッシュボード
- データ
- データ監視
- データの準備
- データ処理
- データ品質
- データサイエンス
- データセット
- デフォルト
- 定義します
- 定義済みの
- 配達
- 需要
- 依存関係
- 依存関係
- 依存
- 依存
- 展開します
- 展開する
- 詳細な
- 細部
- 開発する
- 発展した
- 異なります
- 直接
- 指示された
- 取締役
- 明確な
- デッカー
- すること
- 行われ
- ダウン
- ダウンロード
- ダンプ
- 各
- 簡単に
- エコシステム
- エドワード
- enable
- 有効にする
- 奨励する
- end
- 端から端まで
- エンジニアリング
- 全体
- 時代
- エーテル(ETH)
- 例
- 実行します
- 実行
- 体験
- 余分な
- エキス
- 家族
- ファン
- 遠く
- 特徴
- フィードバック
- 少数の
- File
- 膜
- 映画製作者
- 名
- 釣り
- 五
- 焦点を当て
- 焦点を当てて
- 続いて
- フォロー中
- 次
- フォーム
- 形式でアーカイブしたプロジェクトを保存します.
- から
- 完全に
- 機能性
- さらに
- Games
- 生成する
- グラフ
- 持ってる
- he
- 助けます
- 助け
- 彼女の
- こちら
- ハイキング
- 彼の
- ハリウッド
- 認定条件
- HTML
- HTTP
- HTTPS
- 人間
- if
- 説明する
- 画像
- 画像
- 直ちに
- import
- 重要
- in
- include
- 独立しました
- を示し
- 個人
- 説明書
- 統合する
- 統合
- 相互作用的
- に
- IT
- ITS
- ジョブ
- Jobs > Create New Job
- JPG
- ただ
- ラベル
- ラベル
- 姓
- 起動する
- 学習
- ライブラリ
- LINE
- ライン
- 負荷
- ローカル
- 場所
- 長い
- で
- 機械
- 機械学習
- マジック
- メイン
- 作る
- 管理します
- マネージド
- 管理
- マネージャー
- メディア
- メリット
- かもしれない
- ML
- モデル
- 修正されました
- モジュール
- モニター
- モニタリング
- モニター
- 他には?
- 最も
- 映画
- の試合に
- しなければなりません
- 名
- ネイティブ
- 必要
- 必要とされる
- 負
- 新作
- いいえ
- 注意
- ノート
- ノートPC
- 今
- オブジェクト
- of
- 頻繁に
- on
- ONE
- の
- 最適化
- or
- 編成
- その他
- 私たちの
- でる
- 出力
- outputs
- 外側
- 足
- パラメーター
- パラメータ
- 部
- パス
- 通過
- path
- 実行する
- 実行
- 個人的な
- パイプライン
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 再生
- 人気
- 正の
- ポスト
- 予測する
- 準備
- 準備
- 準備する
- 準備中
- 前
- 前に
- 問題
- 処理
- プロダクト
- プロダクトマネージャー
- 提供します
- 提供
- は、大阪で
- 公共
- 引っ張る
- 目的
- プッシュ
- プッシュ
- Python
- 品質
- より速い
- R
- むしろ
- 読む
- リーディング
- 繰り返し
- 縮小
- リファクタリング
- 参照する
- 登録された
- 定期的に
- 残る
- 繰り返し
- 必要とする
- 結果として
- レビュー
- レビュー
- ラン
- ランニング
- runs
- セージメーカー
- SageMakerパイプライン
- 同じ
- 満足
- スケジュール
- 予定の
- スケジュールされたジョブ
- スケジューリング
- 科学
- 科学者たち
- SDDK
- 二番
- セクション
- セクション
- 見て
- シニア
- 感情
- 別
- サービス
- サービス
- セッション
- セッションに
- 設定
- いくつかの
- 形
- 彼女
- すべき
- 表示する
- ショーケース
- 示す
- 作品
- 重要
- 著しく
- 同様の
- 簡単な拡張で
- 単純化
- 小さい
- より小さい
- スニペット
- So
- 社会
- ソーシャルメディア
- 溶液
- ソリューション
- 解決する
- 一部
- 何か
- スペース
- 特定の
- 支出
- スタンドアロン
- スタンフォード
- start
- Status:
- 手順
- ステップ
- まだ
- ストレージ利用料
- 簡単な
- 研究
- そのような
- 日
- サポート
- サポート
- サポート
- 確か
- 取る
- 取り
- 仕事
- タスク
- チーム
- テクノロジー
- test
- 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO 많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다.
- テキスト分類
- それ
- アプリ環境に合わせて
- それら
- その後
- ボーマン
- 三番
- この
- それらの
- 三
- 介して
- 時間
- 〜へ
- 一緒に
- あまりに
- ツール
- トータル
- 追跡する
- トレーニング
- 訓練された
- トレーニング
- 最適化の適用
- トランスフォーマー
- 旅行
- トリガー
- 順番
- 2
- type
- ui
- わかる
- アップデイト
- us
- つかいます
- 使用事例
- 中古
- users
- 使用されます
- 活用
- 価値観
- さまざまな
- 、
- 詳しく見る
- 視覚化する
- 歩く
- 欲しいです
- we
- ウェブ
- Webサービス
- いつ
- かどうか
- which
- while
- 誰
- 意志
- 以内
- 無し
- 労働者
- ワークフロー
- ワークフロー
- ワーキング
- 最悪
- 書き込み
- 貴社
- あなたの
- ゼファーネット