アマゾンケンドラ は使いやすいインテリジェントな検索サービスであり、検索機能をアプリケーションに統合できるため、ユーザーは次のようなデータ ソースに保存されている情報を見つけることができます。 Amazon シンプル ストレージ サービス 、OneDrive および Google ドライブ。 SalesForce、SharePoint、Service Now などのアプリケーション。 などのリレーショナル データベース Amazon リレーショナル データベース サービス (アマゾン RDS)。 Amazon Kendra コネクタを使用すると、複数のコンテンツ リポジトリからのデータを Amazon Kendra インデックスと同期できます。 エンドユーザーが自然言語で質問すると、Amazon Kendra は機械学習 (ML) アルゴリズムを使用してコンテキストを理解し、最も関連性の高い回答を返します。
Amazon Kendra の S3 コネクタは、S3 バケットに保存されているドキュメントとそれに関連するメタデータのインデックス作成をサポートしています。 多くの場合、VPC 内で実行されているアプリケーションが特定の S3 バケットにのみアクセスできるようにする必要があり、多くの場合、接続がインターネットを経由してパブリック エンドポイントに到達してはなりません。 ただし、多くのお客様は複数の S3 バケットを所有しており、その一部は Amazon S3 の VPC エンドポイント. この投稿では、VPC エンドポイントを使用するための VPC サポートで更新された Amazon Kendra S3 コネクタを使用する方法について説明します。
この投稿では、VPC 内からのみアクセス可能な S3 バケットに保存されたドキュメントを接続することにより、Amazon Kendra を使用して AWS でエンタープライズ検索エンジンを作成するのに役立つ手順を説明します。 詳細については、次を参照してください。 Amazon Kendra によるエンタープライズ検索の強化. この投稿では、Amazon S3 用にコネクタを構成する方法と、データ ソースのコンテンツが変更されたときにインデックスをデータ ソースと同期する方法を構成する方法も示しています。
ソリューションの概要
主な改良点はXNUMXつ Amazon ケンドラ S3 コネクタ :
- VPC サポート – コネクタは、 アマゾン バーチャル プライベート クラウド (Amazon VPC) ネットワーク。 を使用して Amazon S3 に安全に接続できるようになりました Amazon S3 の VPC エンドポイント VPC 接続、サブネット、セキュリティ グループを指定します。
- XNUMX つの同期モード – Amazon S3 のデータ ソースの Amazon Kendra インデックスへの同期をスケジュールするときに、完全同期モードまたは新規、変更、および削除されたドキュメントの同期モードで実行することを選択できるようになりました。 完全同期モードでは、同期が実行されるたびに、クロールするように構成されたルート パスの下にあるすべてのフォルダー内のオブジェクトがスキャンされ、すべてのドキュメントが再取り込みされます。 完全更新により、新しいデータ ソースを削除して作成する必要なく、インデックスをリセットできます。 新規、変更、および削除されたドキュメントの同期モードでは、同期ジョブが実行されるたびに、最後のクロール以降に追加、変更、または削除されたオブジェクトのみが処理されます。 増分クロールは、新しいオブジェクトを既存のデータ ソースに定期的に追加するデータセットで使用すると、実行時間とコストを削減できます。
- ドキュメントの追加の包含パターンと除外パターン: プレフィックスに加えて、ドキュメントをインデックスに含めたり除外したりするためのパターンを導入しています。 サポートされている XNUMX つのパターン タイプは、Unix スタイルの glob またはファイル タイプです。 正規表現パターンを追加して、特定のフォルダーを含めたり、フォルダー、ファイルの種類、または特定のファイルをデータ ソースから除外したりできるようになりました。 これは、さまざまなカテゴリ、分類、およびファイル タイプに属するコンテンツを含む共有データ リポジトリに役立ちます。
前提条件
このチュートリアルでは、次の前提条件を満たしている必要があります。
ドキュメント リポジトリを作成して構成する
Amazon Kendraでインデックスを作成する前に、ドキュメントをS3バケットにロードする必要があります。 このセクションでは、S3バケットを作成し、ファイルを取得して、バケットにロードする手順について説明します。 このセクションのすべての手順を完了すると、Amazon Kendraが使用できるデータソースが作成されます。
- ソフトウェア設定ページで、下図のように AWSマネジメントコンソールの [リージョン] リストで、[米国東部 (バージニア北部)] または任意のリージョンを選択します。 アマゾンケンドラはで利用可能です.
- 選択する サービス.
- Storage、選択する S3.
- Amazon S3コンソールで、 バケットを作成する.
- 一般的な設定、次の情報を提供します。
- バケット名について, 入力します
kendrapost-{your account id}. - リージョンには、Amazon Kendra インデックスのデプロイに使用するのと同じリージョンを選択します (この記事では
us-east-1). - バケット設定、 for パブリック アクセスをブロックする、すべてデフォルト値のままにします。
- バケット名について, 入力します
- 詳細設定、すべてデフォルト値のままにします。
- 選択する バケットを作成する.
- ダウンロード AWS_ホワイトペーパー.zip そしてファイルを解凍します。
- Amazon S3コンソールで、作成したバケットを選択し、 アップロード.
- フォルダをアップロードする
Best Practices,Databases,General,Machine Learning解凍したファイルから。
バケット内に、XNUMX つのフォルダーが表示されます。
データ ソースを追加する
A 情報元 インデックスを作成するためのドキュメントを保存する場所です。 データソースをAmazon Kendraインデックスと自動的に同期して、検索がソースリポジトリの新しいドキュメント、更新されたドキュメント、または削除されたドキュメントを正しく反映していることを確認できます。
このセクションのすべてのステップを完了すると、データ ソースが Amazon Kendra にリンクされます。 詳細については、次を参照してください。 データソースからのドキュメントの追加.
続行する前に、インデックスの作成が完了し、インデックスが次のように表示されていることを確認してください。 アクティブ。 詳細については、を参照してください。 索引の作成.
- Amazon Kendra コンソールで、インデックスに移動します (この投稿では、
kendra-blog-index). - ソフトウェア設定ページで、下図のように
kendra-blog-indexページ、選択 データソースを追加する.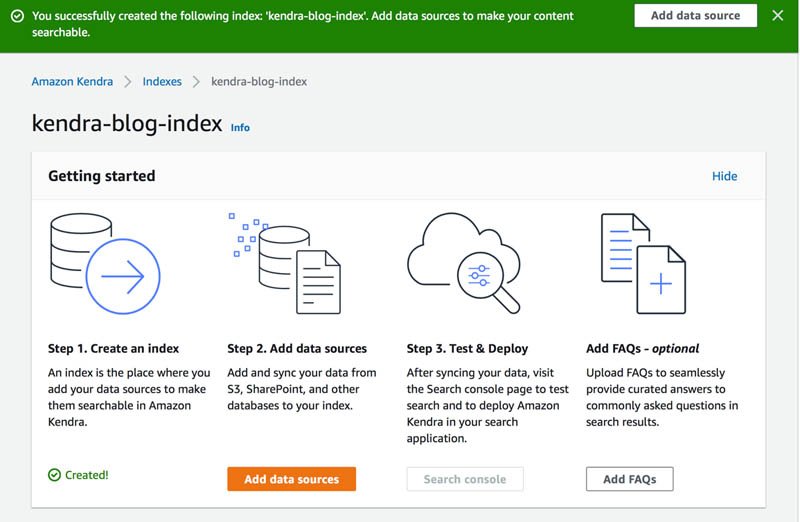
- Amazon S3 の下で、選択します コネクタを追加.
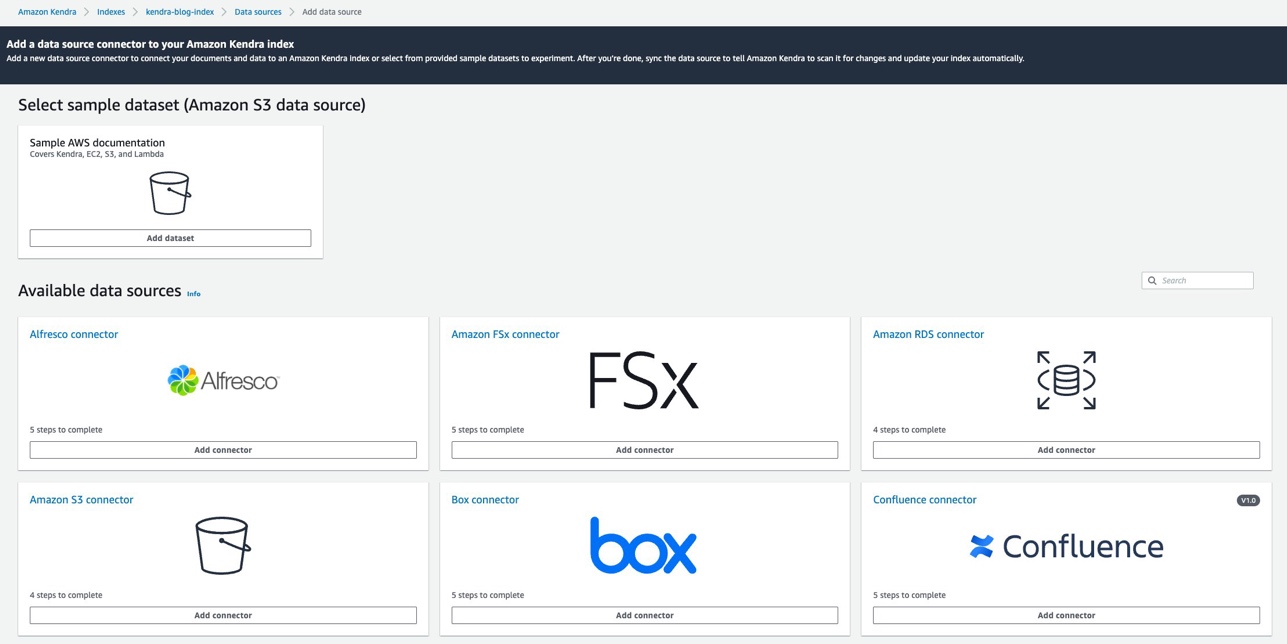
Amazon Kendraがサポートするさまざまなデータソースの詳細については、 データソースからのドキュメントの追加.
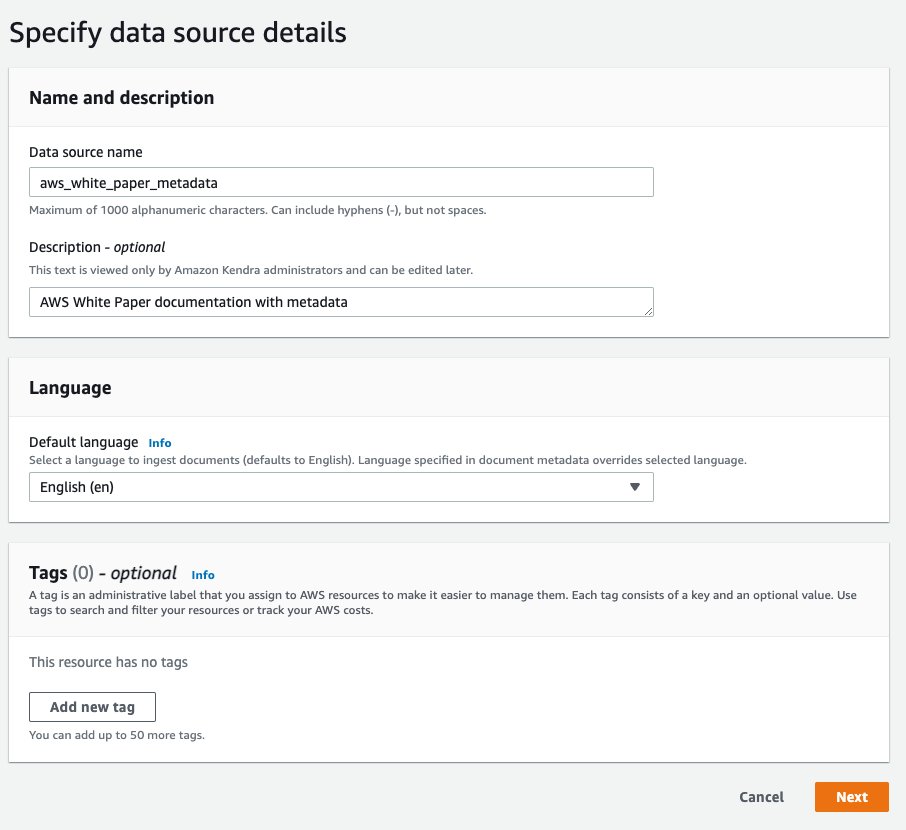
- データソースの詳細を指定する セクション、 データソース名、 入る
aws_white_paper. - Description、 入る
AWS White Paper documentation. - 選択する Next.
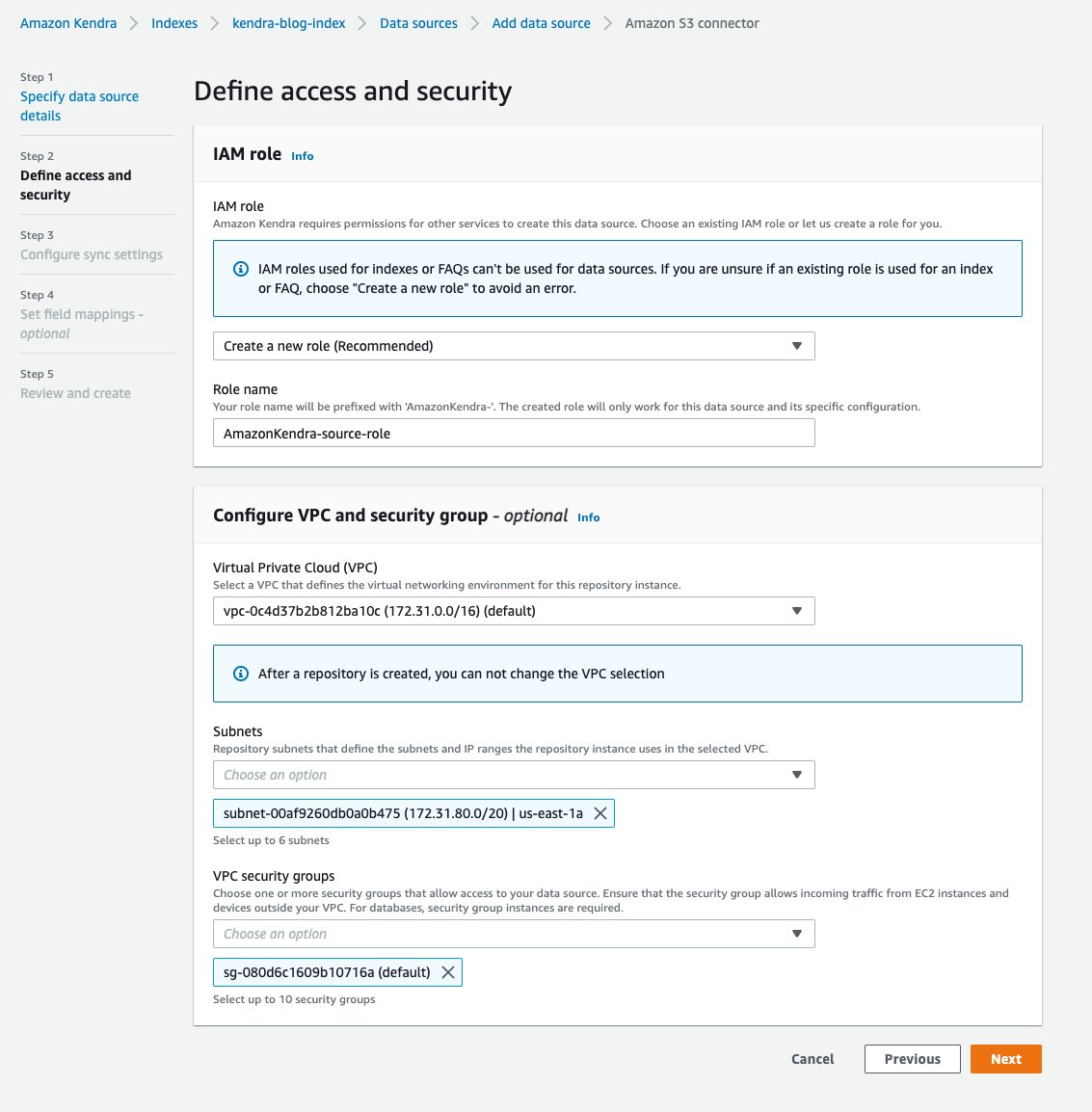
次に、 AWS IDおよびアクセス管理 Amazon Kendra の (IAM) ロール。
- アクセスとセキュリティを定義する ページ、 IAMの役割 セクションでは、選択 新しい役割を作成する.
- [ロール名] に入力します
source-role(ロール名の前にAmazonKendra-). - VPC とセキュリティの構成 セクションで、 VPC、 そしてあなたの サブネットと VPC セキュリティ グループ.
Amazon Kendra を Amazon Virtual Private Cloud に接続する方法の詳細については、次を参照してください。 VPC を使用するように Amazon Kendra を設定する.
- 選択する Next.
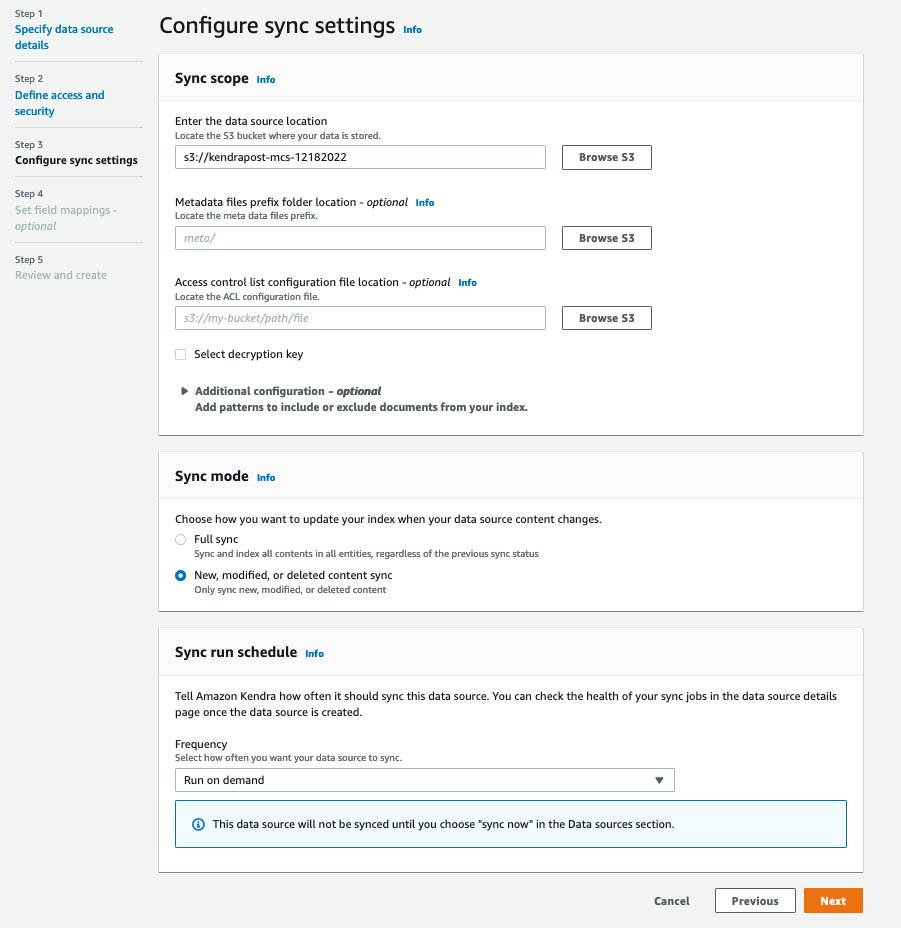
- 同期設定を構成する ページ、 データソースの場所を入力してください、作成したS3バケットを入力します。
kendrapost-{your account id}. - コメントを残す メタデータファイルのプレフィックスフォルダーの場所 ブランク。
デフォルトでは、メタデータファイルはドキュメントと同じディレクトリに保存されます。 これらのファイルを別のフォルダに配置する場合は、プレフィックスを追加できます。 詳細については、 Amazon S3 ドキュメントのメタデータ.
- 復号化キーを選択、選択を解除したままにします。
- 追加の構成、パターンを追加して、特定のフォルダまたはファイルを含めたり除外したりできます。 この投稿では、デフォルト値を保持します。
- 同期モード 選ぶ 新規、変更、または削除されたドキュメントの同期.
- 周波数、選択する オンデマンドで実行.
このステップでは、データ ソースが Amazon Kendra インデックスと同期される頻度を定義します。
- 選択する Next.
- フィールドマッピングを設定する ページで、デフォルト値をそのまま使用します。
- 選択する Next.

- ソフトウェア設定ページで、下図のように 確認して作成する ページ、選択 データソースを追加する.
- Kendra インデックスに戻ります。
- あなたの選択します。 情報元、を選択します 今すぐ同期 ドキュメントをAmazon Kendraインデックスと同期します。
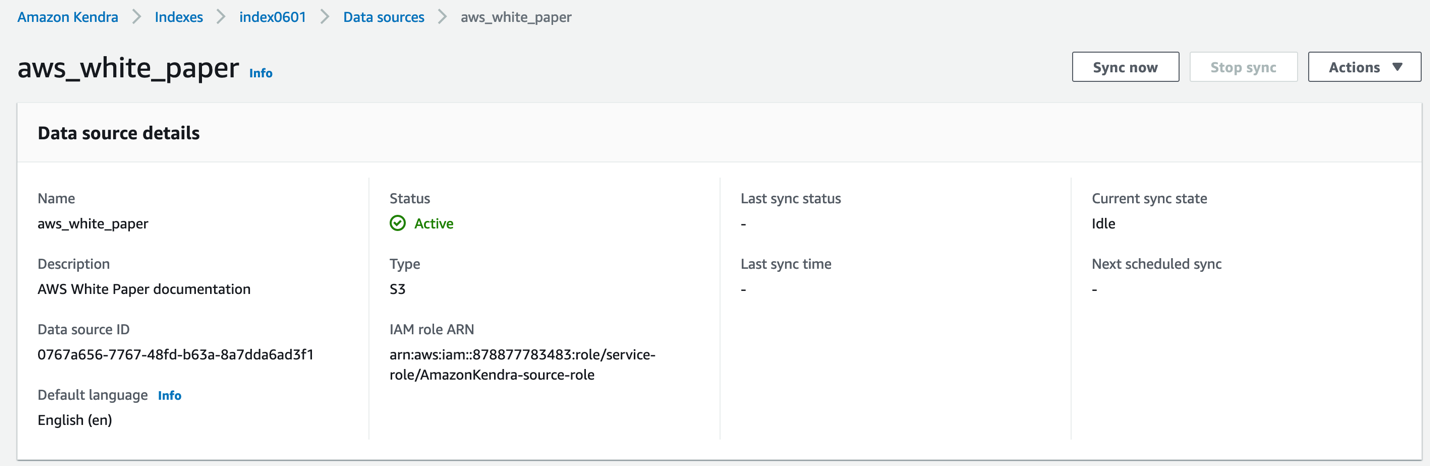
このプロセスにかかる時間は、インデックスを作成するドキュメントの数によって異なります。 この使用例では、15 分かかる場合があります。その後、同期が成功したというメッセージが表示されます。 [同期の実行履歴] セクションで、40 個のドキュメントが同期されたことがわかります。

Amazon Kendra インデックスで自然言語クエリを実行できるようになりました。 インデックスを検索すると、Amazon Kendra は提供されたすべてのデータとメタデータを使用して、検索クエリに対して最も正確な回答を返します。 Amazon Kendra コンソールで、 インデックス付きコンテンツを検索. クエリ フィールドで、「どの AWS サービスにイレブン ナインの耐久性があるか?」などのクエリから始めます。
インデックスのクエリの詳細については、次を参照してください。 インデックスのクエリ
データ ソースの変更を同期してインデックスを検索する
データ ソースは、新しいデータ、変更されたデータ、または削除されたデータを同期するように設定されています。 データ ソースを Amazon Kendra のインデックスと段階的に同期する前に、新しいドキュメントを S3 バケットにロードする必要があります。
- Amazon S3コンソールで、作成したバケットを選択し、 アップロード.
- フォルダをアップロードする
SecurityおよびWell_Architected解凍したファイルから。
これで、S3 バケットに追加された新しいドキュメントを同期できます。
- Amazon Kendraコンソールで、 データソース 次に、S3 データ ソースを選択します。
- 選択する 今すぐ同期
このプロセスの期間は、インデックスを作成するドキュメントの数によって異なります。 この使用例の場合、15分かかることがあります。その後、同期が成功したというメッセージが表示されます。
同期の実行履歴 セクションでは、20個のドキュメントが同期されていることがわかります。

データ ソースの再インデックス
データ ソースに古い情報があるシナリオでは、新しいデータ ソースを削除して作成することなく、データ ソースのインデックスを再作成できるようになりました。 同期モードを変更してデータ ソースのインデックスを再作成するには、次の手順を実行します。
- Amazon Kendra コンソールで、 データソース 次に、S3 データ ソースを選択します。
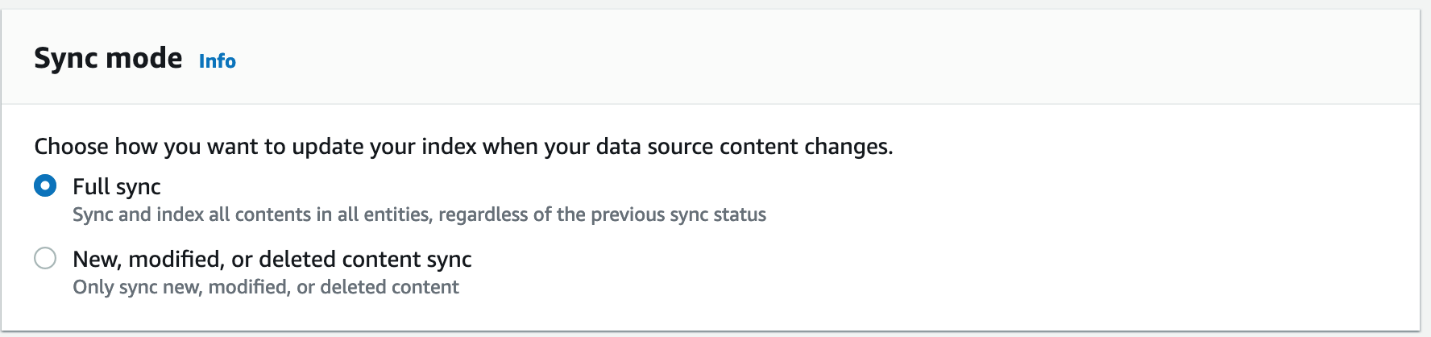
- ソフトウェア設定ページで、下図のように メニュー、選択 編集する。
- 選択する Next に移動する ステップ 3 – 同期設定ページの構成.
- 同期モードの場合は、 完全同期。
- 周波数、選択する オンデマンドで実行.
- 選択する Next.
- フィールドマッピングを設定する ページで、デフォルト値をそのまま使用します。
- 選択する Next.
- ソフトウェア設定ページで、下図のように 確認して作成する ページ、選択 アップデイト.
これで、S3 バケットに追加された新しいドキュメントを同期できます。
- Amazon Kendraコンソールで、 データソース 次に、S3 データ ソースを選択します。
- 選択する 今すぐ同期
同期の実行履歴 セクションで、変更された列の下の以前の同期ステータスに関係なく、すべてのドキュメントが同期されたことがわかります。

クリーンアップ
将来の課金を回避し、未使用のロールとポリシーを一掃するには、作成したリソースを削除します。
- Amazon Kendra インデックスで、選択します インデックス ナビゲーションペインに表示されます。
- 作成したインデックスを選択し、 メニュー、選択 削除.
- 削除を確認するには、プロンプトが表示されたら「削除」と入力し、 削除.
確認メッセージが表示されるまで待ちます。 このプロセスには最大15分かかります。
- Amazon S3コンソールでは、 S3 バケットを削除する.
- IAMコンソールで、 対応する IAM ロールを削除します.
まとめ
この投稿では、Amazon Kendra を使用して、インターネット ゲートウェイやネットワーク アドレス変換 (NAT) デバイスを必要としない Amazon S3 への安全な接続を使用して、エンタープライズ検索サービスをデプロイする方法を学びました。 同期モードを使用して、ドキュメントのより迅速な同期を有効にすることができます。
取り上げなかった多くの追加機能があります。 例えば:
- Amazon Kendra インデックスに対してユーザーベースのアクセス制御を有効にし、構成済みのアクセス制御に基づいてドキュメントへのアクセスを制限できます。
- オブジェクト属性を Amazon Kendra インデックス属性にマッピングし、ファセット、検索、および検索結果での表示を有効にすることができます。
- Amazon Kendra 表形式検索を使用して、ウェブページ (HTML テーブル) から情報をすばやく見つけることができます
Amazon Kendra の詳細については、以下を参照してください。 AmazonKendra開発者ガイド.
著者について
 マラン・チャンドラセカラン は、アマゾン ウェブ サービスのシニア ソリューション アーキテクトであり、企業顧客と協力しています。 仕事以外では、彼は旅行が大好きです。
マラン・チャンドラセカラン は、アマゾン ウェブ サービスのシニア ソリューション アーキテクトであり、企業顧客と協力しています。 仕事以外では、彼は旅行が大好きです。
 アルジュン・アグラワル AWS のソフトウェア エンジニアであり、現在はエンタープライズ検索エンジンで Amazon Kendra チームと協力しています。 彼は、新しいテクノロジーと現実世界の問題の解決に情熱を注いでいます。 仕事以外では、ハイキングや旅行が大好きです。
アルジュン・アグラワル AWS のソフトウェア エンジニアであり、現在はエンタープライズ検索エンジンで Amazon Kendra チームと協力しています。 彼は、新しいテクノロジーと現実世界の問題の解決に情熱を注いでいます。 仕事以外では、ハイキングや旅行が大好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/search-for-answers-accurately-using-amazon-kendra-s3-connector-with-vpc-support/
- 10
- 100
- 11
- 7
- a
- 私たちについて
- アクセス
- アクセス可能な
- 正確な
- 正確にデジタル化
- 越えて
- 追加されました
- 添加
- NEW
- 住所
- 後
- アルゴリズム
- すべて
- ことができます
- 既に
- Amazon
- アマゾンケンドラ
- アマゾンRDS
- Amazon Webサービス
- および
- 回答
- 関連する
- 属性
- 自動的に
- 利用できます
- AWS
- バック
- ベース
- 基礎
- 機能
- 場合
- 例
- カテゴリ
- 一定
- 変更
- 課金
- 選択
- 選択する
- 分類
- クラウド
- コラム
- コンプリート
- 完了
- 確認します
- お問合せ
- 接続する
- 接続
- 領事
- 含まれています
- コンテンツ
- コンテキスト
- 連続
- コントロール
- controls
- 対応する
- 費用
- カバー
- 作ります
- 作成した
- 創造
- 現在
- Customers
- データ
- データベース
- データベースを追加しました
- データセット
- デフォルト
- 定義する
- 実証
- 依存
- 展開します
- 説明する
- Developer
- デバイス
- 異なります
- ディスプレイ
- ドキュメント
- ドキュメント
- そうではありません
- ドライブ
- 耐久性
- 東
- 使いやすい
- enable
- 可能
- エンジン
- エンジニア
- 入力します
- Enterprise
- 企業顧客
- エンタープライズ検索
- エーテル(ETH)
- あらゆる
- すべてのもの
- 例
- 既存の
- 特徴
- フィールド
- File
- もう完成させ、ワークスペースに掲示しましたか?
- フォロー中
- 周波数
- から
- フル
- 未来
- ゲートウェイ
- 取得する
- でログイン
- グループの
- 持って
- 助けます
- ハイキング
- history
- 認定条件
- How To
- しかしながら
- HTML
- HTTPS
- IAM
- アイデンティティ
- 改善
- in
- include
- 包含
- index
- 情報
- 説明書
- 統合する
- インテリジェント-
- インターネット
- 導入
- 無関係に
- IT
- ジョブ
- キープ
- 言語
- 姓
- LEARN
- 学んだ
- 学習
- コメントを残す
- リンク
- リスト
- 負荷
- 場所
- 機械
- 機械学習
- メイン
- make
- 管理
- 多くの
- 地図
- メニュー
- メッセージ
- 分
- ML
- モード
- モード
- 修正されました
- 修正する
- 他には?
- 最も
- の試合に
- 名
- ナチュラル
- 自然言語
- ナビゲート
- ナビゲーション
- 必要
- ネットワーク
- ネットワーク
- 新作
- 数
- オブジェクト
- オブジェクト
- OneDrive
- 外側
- 自分の
- ペイン
- 紙素材
- 情熱的な
- path
- パターン
- パターン
- 場所
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポリシー
- ポスト
- 前提条件
- 前
- プライベート
- 問題
- プロセス
- ラボレーション
- 提供します
- 提供
- は、大阪で
- 公共
- 質問
- より速い
- すぐに
- リーチ
- 準備
- 現実の世界
- 減らします
- 反映する
- 地域
- レギュラー
- 関連した
- 必要とする
- リソース
- 制限する
- 結果
- return
- 職種
- 役割
- ルート
- ラン
- ランニング
- salesforce
- 同じ
- シナリオ
- スケジュール
- を検索
- 検索エンジン
- セクション
- 安全に
- しっかりと
- セキュリティ
- シニア
- サービス
- サービス
- セッションに
- 設定
- shared
- SharePointの
- すべき
- 作品
- 簡単な拡張で
- から
- So
- ソフトウェア
- ソフトウェアエンジニア
- ソリューション
- 解決
- 一部
- ソース
- ソース
- 特定の
- start
- Status:
- 手順
- ステップ
- ストレージ利用料
- 保存され
- 店舗
- サブネット
- サブネット
- 成功した
- そのような
- サポート
- サポート
- サポート
- 同期
- 取る
- チーム
- テクノロジー
- ソース
- アプリ環境に合わせて
- 三
- 時間
- 〜へ
- インタビュー
- 旅行
- 下
- わかる
- UNIX
- 未使用
- 更新しました
- us
- つかいます
- 使用事例
- users
- 価値観
- バージニア州
- バーチャル
- ウォークスルー
- ウェブ
- Webサービス
- which
- 白
- ホワイトペーパー
- 以内
- 無し
- 仕事
- ワーキング
- あなたの
- ゼファーネット
- 〒