SmugMug は XNUMX つの非常に大規模なオンライン写真プラットフォームを運営しています。 SmugMugの および Flickrのにより、100 億を超える顧客が数百億枚の写真を安全に保存、検索、共有、販売できるようになります。 顧客が数十年分の写真をアップロードして検索することで、検索が重要なインフラストラクチャに変わり、SmugMug が最初に使用されて以来、着実に成長しました。 アマゾン クラウドサーチ 2012では、続けて AmazonOpenSearchサービス 2018 年以来、数十億のドキュメントとテラバイトの検索ストレージに達して以来。
ここでは、SmugMug スタッフ エンジニアの Lee Shepherd が、複数のクラスターへのライブ トラフィックのパブリッシュ、バックフィル、ミラーリングに使用される SmugMug の検索アーキテクチャを共有します。 SmugMug は、これらのパイプラインを使用してベンチマーク、検証を行い、i6xlarge からの Graviton ベースの r2gd.3.2xlarge インスタンスを含む新しい構成への移行とテストを行います。 Amazon OpenSearch サーバーレス。 急激に非現実的なトラフィック パターンを導入することなく、実稼働サービスに影響を与えることなく、パブリッシュ、バックフィル、クエリに使用される XNUMX つのパイプラインについて説明します。
このプロセスには、次の XNUMX つの主要なアーキテクチャ部分が重要です。
- インデックス データの永続的な信頼できる情報源。 ベストプラクティスです OpenSearch インデックスを超えた耐久性のあるストアを用意するというバックアップ戦略の一環です。 Amazon DynamoDB スケーラビリティと統合を提供します AWSラムダ これにより、プロセスの多くが簡素化されます。 私たちは検索以外の他のサービスに DynamoDB を使用しているため、これは自然に適合しました。
- 信頼できる情報源からのデータを OpenSearch に公開するための Lambda 関数。 使用する 関数の別名 同じ Lambda 関数の複数の設定を同時に実行するのに役立ち、データの同期を保つための鍵となります。
出版
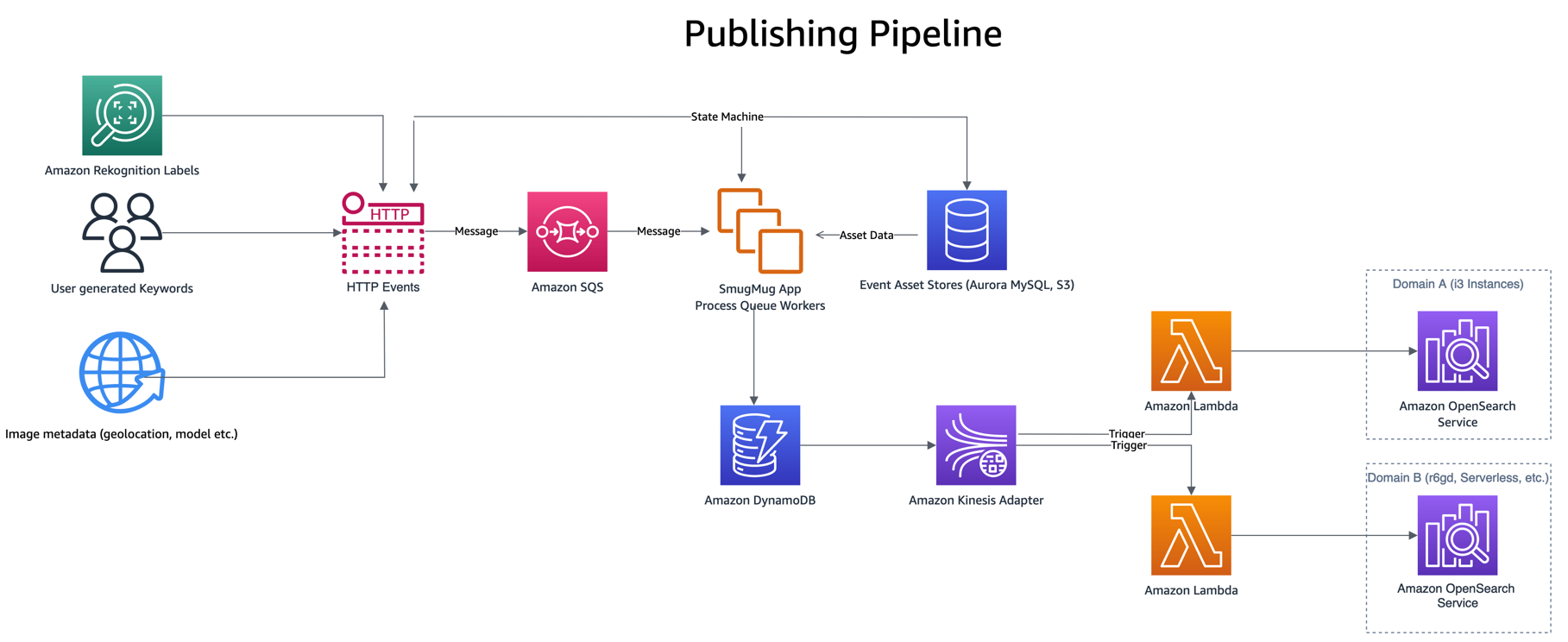
パブリッシング パイプラインは、ユーザーによるキーワードやキャプションの入力、新しいアップロード、ラベル検出などのイベントによって駆動されます。 Amazonの再認識。 これらのイベントは、次のような他のいくつかのアセット ストアからのデータを組み合わせて処理されます。 Amazon Aurora MySQL 互換エディション および Amazon Simple Storage Service(Amazon S3)、単一のアイテムを DynamoDB に書き込む前に。
DynamoDB に書き込むと、Lambda パブリッシング関数が呼び出されます。 DynamoDB ストリーム Kinesis アダプター、DynamoDB から更新された項目のバッチを取得し、OpenSearch にインデックスを作成します。 DynamoDB Streams Kinesis アダプターを使用すると、必要な同時 Lambda の数が減るなど、他の利点もあります。
パブリッシング Lambda 関数は、環境変数を使用して、どの OpenSearch ドメインとインデックスにパブリッシュするかを決定します。 本番エイリアスは、DynamoDB テーブルまたは Kinesis Stream から離れた本番 OpenSearch ドメインに書き込むように設定されています
新しい構成をテストするとき、または移行するとき、移行エイリアスは新しい OpenSearch ドメインに書き込むように構成されますが、運用エイリアスと同じトリガーを使用します。 これにより、両方の OpenSearch Service ドメインへのデータの二重インデックス作成が同時に可能になります。
DynamoDB テーブル スキーマの例を次に示します。
「LastUpdated」値は、インデックス作成時にドキュメントのバージョンとして使用され、OpenSearch が順序どおりでない更新を拒否できるようにします。
バックフィル
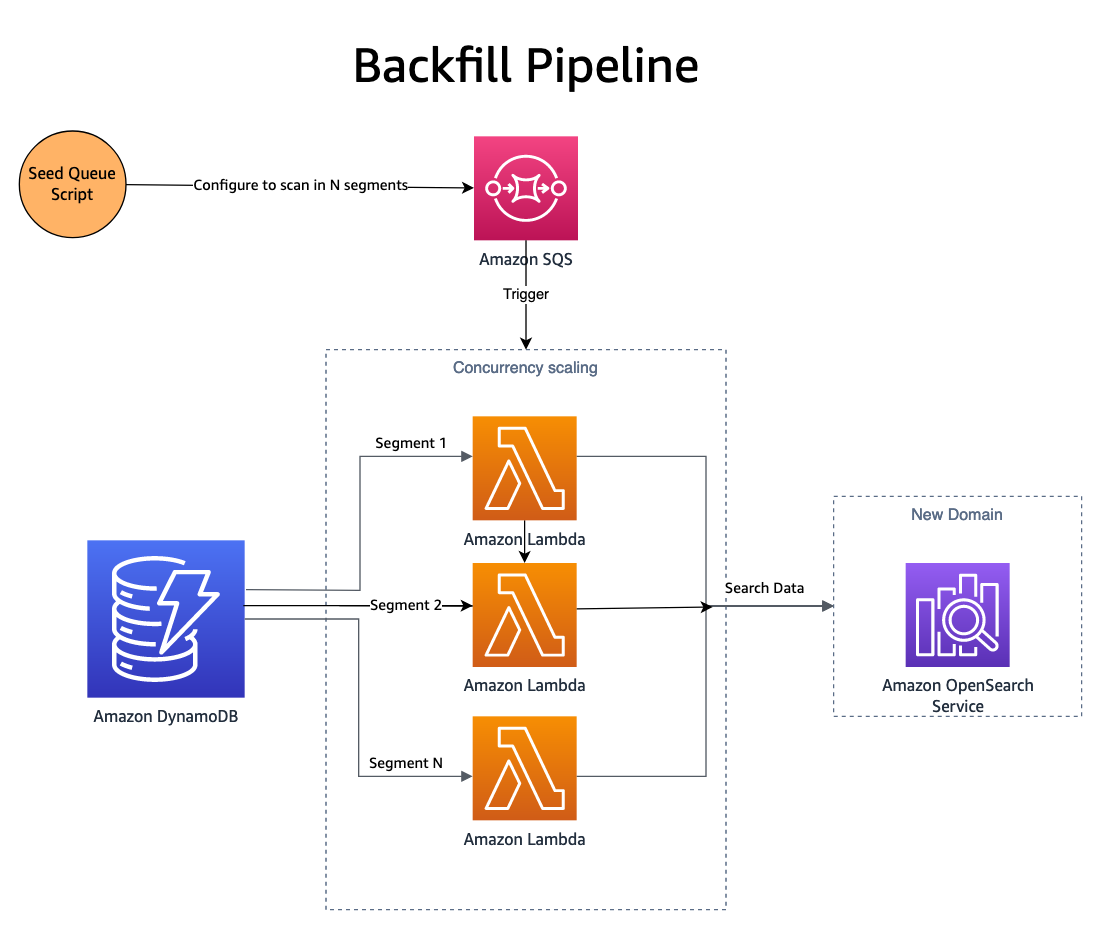
変更が両方のドメインに公開されたので、新しいドメイン (インデックス) に履歴データをバックフィルする必要があります。 新しく作成したインデックスをバックフィルするには、次の組み合わせを使用します。 Amazon Simple Queue Service(Amazon SQS) DynamoDB が使用されます。 スクリプトは、次の手順を含むメッセージを SQS キューに追加します。 並列スキャン DynamoDB テーブルのセグメント。
SQS キューは、メッセージ命令を読み取り、DynamoDB テーブルの対応するセグメントからアイテムのバッチをフェッチし、OpenSearch インデックスにそれらを書き込む Lambda 関数を起動します。 新しいメッセージは SQS キューに書き込まれ、セグメント内の進行状況を追跡します。 セグメントが完了すると、それ以上メッセージは SQS キューに書き込まれなくなり、プロセス自体が停止します。
同時実行性はセグメントの数によって決まり、Lambda 同時実行スケーリングによって追加の制御が提供されます。 SmugMug は、運用ドメインに影響を与えることなく、OpenSearch 構成で 1 時間あたり XNUMX 億件を超えるドキュメントのインデックスを作成できます。
SQS キューのシードには、NodeJS AWS-SDK ベースのスクリプトが使用されます。 SQS 構成スクリプトのオプションのスニペットを次に示します。
結果として得られる SQS メッセージの形式は次のとおりです。
ミラーリング
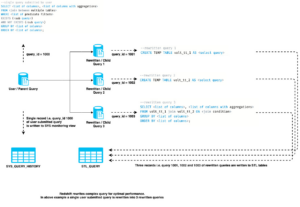
最後に、私たちの ミラーリングされた検索クエリ 結果は、運用ドメインに加えて、OpenSearch クエリを SQS キューに送信することによって実行されます。 SQS キューは、レプリカ ドメインにクエリを再生する Lambda 関数を起動します。 これらのリクエストの検索結果はどのユーザーにも送信されませんが、運用システムや顧客に影響を与えることなく、テスト中の OpenSearch サービス上で運用負荷を複製できます。
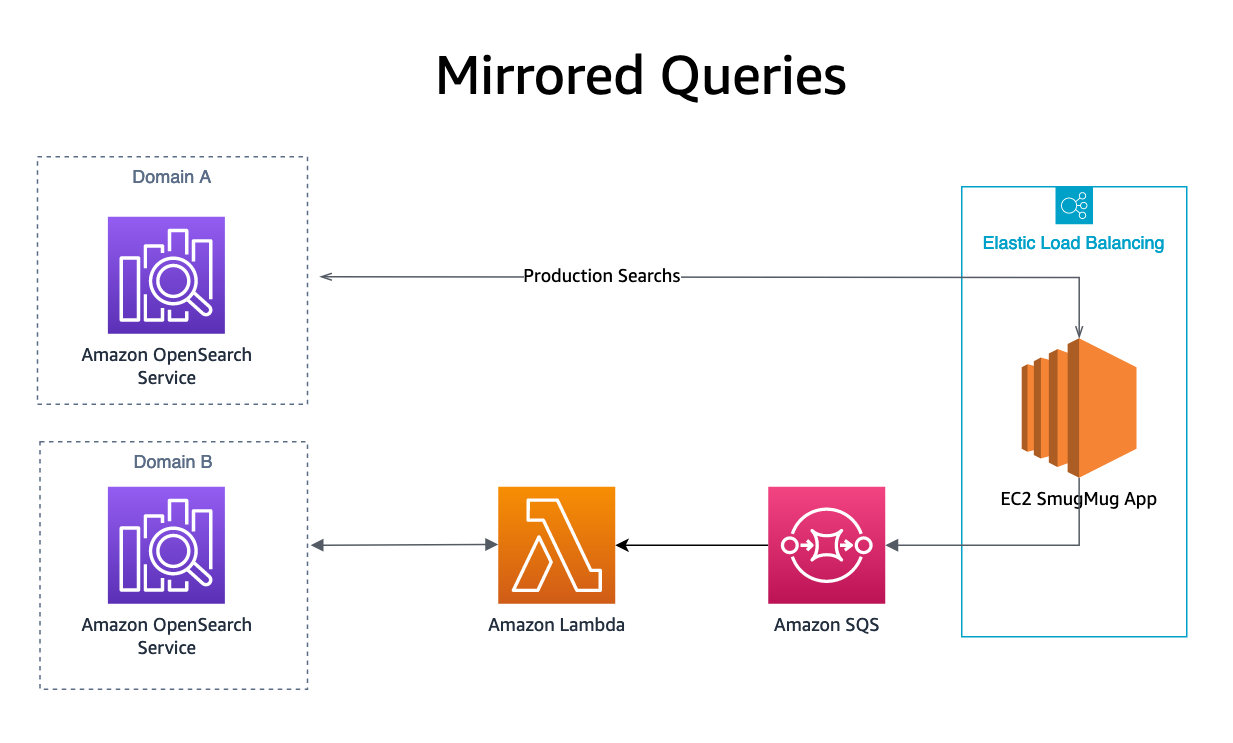
まとめ
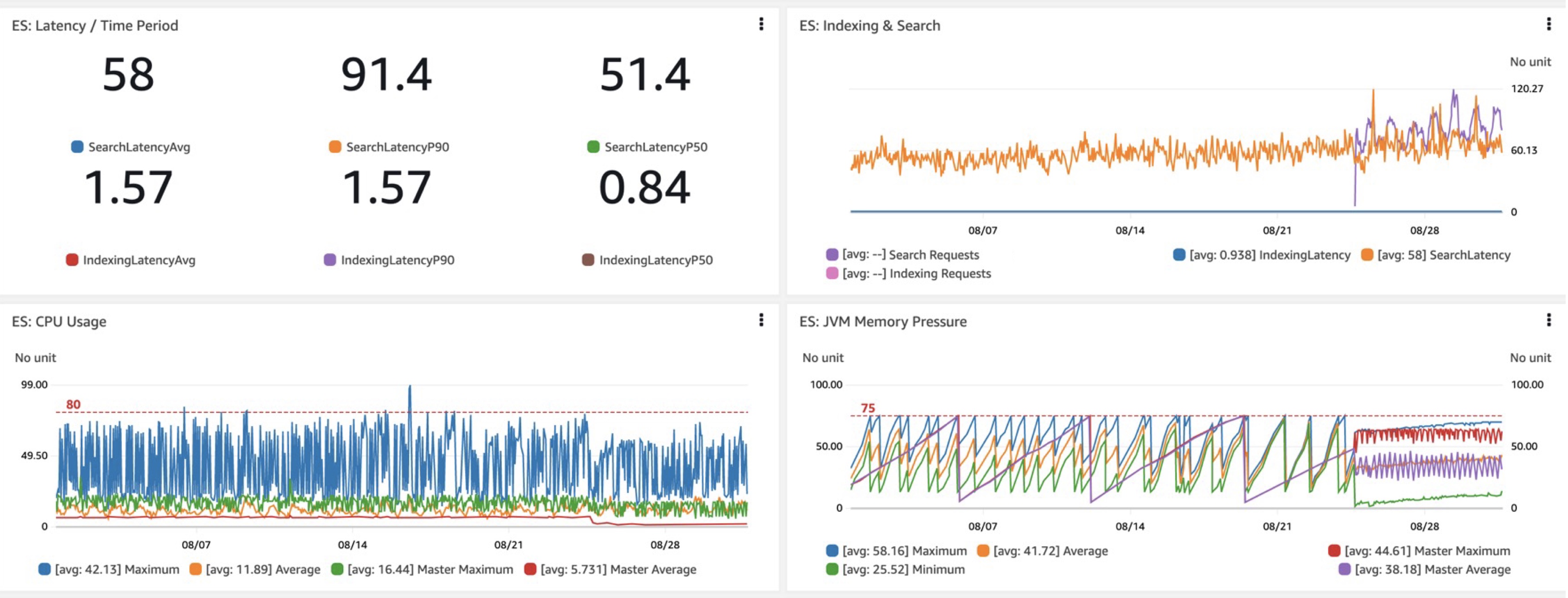
新しい OpenSearch ドメインまたは構成を評価する場合、私たちが関心のある主な指標はクエリ レイテンシのパフォーマンス、つまり所要レイテンシ (時間あたりのレイテンシ)、そして最も重要なのは検索のレイテンシです。 Graviton R6gd への移行では、P40 ~ P50 のレイテンシーが約 99% 低下し、i3 と比較して CPU 使用率も同様に向上しました (Graviton の低コストは無視しています)。 もう 1 つの歓迎すべき利点は、R6gd およびその他の新しいインスタンスへの GXNUMXGC の追加によるガベージ コレクションの変更に伴う JVM メモリ負荷がより予測可能かつ監視可能になったことです。
このパイプラインを使用して、OpenSearch Serverless もテストし、その最良の使用例を見つけています。 私たちはそのサービスに興奮しており、完全にサーバーレスのアーキテクチャをやがて実現するつもりです。 結果をお待ちください。
著者について
リー・シェパード SmugMug スタッフ ソフトウェア エンジニアです
アイドン・ベキロフ アマゾン ウェブ サービスのプリンシパル テクニカル アカウント マネージャーです
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/smugmugs-durable-search-pipelines-for-amazon-opensearch-service/
- :は
- :not
- 1
- 100
- 12
- 14
- 20
- 2012
- 2018
- 40
- 7
- 9
- a
- できる
- 私たちについて
- 追加されました
- 添加
- NEW
- 後
- 許す
- 許可
- 沿って
- また
- Amazon
- Amazon Webサービス
- an
- および
- 別の
- どれか
- 建築の
- 建築
- です
- AS
- 資産
- At
- オーロラ
- AWS
- バックアップ
- ベース
- BE
- さ
- ベンチマーク
- 恩恵
- 利点
- BEST
- 越えて
- 10億
- 億
- 両言語で
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- キャプションが
- 変更
- コレクション
- 組み合わせ
- 結合
- 比べ
- 互換性のあります
- 完了
- 同時
- 設定された
- 含む
- controls
- 対応する
- コスト
- カバー
- CPU
- 作成した
- 重大な
- 重要インフラ
- Customers
- データ
- 数十年
- 検出
- 決定する
- 決定
- ドキュメント
- ドキュメント
- ドメイン
- ドメイン
- ドリブン
- 各
- 可能
- 有効にする
- エンドポイント
- エンジニア
- 入る
- 完全に
- 環境
- エーテル(ETH)
- 評価します
- イベント
- 例
- 興奮した
- 少数の
- フィールズ
- 発見
- 名
- フィット
- 続いて
- 形式でアーカイブしたプロジェクトを保存します.
- から
- 完全に
- function
- 利益
- 成長
- 持ってる
- 高さ
- 助けました
- ことができます
- 歴史的
- 時間
- HTML
- HTTP
- HTTPS
- i
- i3
- ID
- 影響
- 重要なこと
- in
- 含めて
- index
- インデックス
- インフラ
- インスタンス
- 説明書
- 統合
- 予定
- 興味がある
- に
- 導入
- 呼び出す
- リーディングシート
- 繰り返し
- ITS
- 自体
- JPG
- キープ
- 保管
- キー
- キーワード
- ラベル
- 大
- レイテンシ
- 起動
- リー
- ような
- ライブ
- 負荷
- たくさん
- 下側
- メイン
- メモリ
- メッセージ
- メッセージ
- メトリック
- 移動します
- 移行中
- 移行
- 百万
- 百万人の顧客
- ミラー
- 他には?
- 最も
- の試合に
- MySQL
- 名
- すなわち
- ナチュラル
- ニーズ
- 新作
- 新しく
- 次の
- いいえ
- 数
- of
- オフ
- on
- オンライン
- 動作
- オプション
- オプト
- or
- その他
- 私たちの
- 並列シミュレーションの設定
- 部
- パターン
- 以下のために
- パーセント
- パフォーマンス
- 写真
- 写真
- ピース
- パイプライン
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 予測可能な
- 圧力
- 前
- 校長
- プロセス
- 処理されました
- 生産
- 進捗
- 提供
- は、大阪で
- パブリッシュ
- 公表
- 出版
- 到達
- 縮小
- 返信
- リクエスト
- の提出が必要です
- 結果として
- 結果
- ラン
- 安全に
- 同じ
- 見ました
- スケーラビリティ
- スケーリング
- スクリプト
- を検索
- 検索
- シード
- セグメント
- セグメント
- 売る
- 送信
- 送信
- サーバレス
- サービス
- サービス
- シェアする
- 株式
- 同様の
- 簡単な拡張で
- 同時に
- から
- スニペット
- So
- ソフトウェア
- ソース
- スタッフ
- 滞在
- 着実に
- 停止する
- ストレージ利用料
- 店舗
- 店舗
- 戦略
- ストリーム
- そのような
- システム
- テーブル
- 取り
- 技術的
- 十
- test
- テスト
- より
- それ
- ソース
- アプリ環境に合わせて
- それら
- そこ。
- ボーマン
- この
- 三
- 介して
- 時間
- 〜へ
- 取った
- 追跡する
- トラフィック
- トリガー
- 真実
- 順番
- 2
- 下
- 更新しました
- 更新版
- アップロード
- URL
- 使用法
- つかいます
- ユースケース
- 中古
- ユーザー
- 使用されます
- 検証
- 値
- バージョン
- 非常に
- ました
- we
- ウェブ
- Webサービス
- 歓迎
- この試験は
- いつ
- while
- 無し
- 書きます
- 書き込み
- 書かれた
- ゼファーネット
- ゼロ