あらゆる業界の組織には、さまざまな分析システムにわたる分析ユースケースのための複雑なデータ処理要件があります。 AWS 上のデータレイク、データ ウェアハウス (Amazonレッドシフト)、 検索 (AmazonOpenSearchサービス)、NoSQL (Amazon DynamoDB)、機械学習 (アマゾンセージメーカー)、 もっと。 分析専門家は、これらの分散システムに保存されているデータから価値を引き出し、顧客にとってより優れた、安全で、コストが最適化されたエクスペリエンスを生み出すという任務を負っています。 たとえば、デジタル メディア企業は、顧客プロファイルの統一されたビューを構築し、革新的な機能のアイデアを刺激し、プラットフォームのエンゲージメントを高めるために、社内および社外のデータベースのデータセットを組み合わせて処理しようとしています。
これらのシナリオでは、サーバーレス データ統合サービスを探している顧客は、 AWSグルー データの処理とカタログ化のためのコアコンポーネントとして。 AWS Glue は AWS のサービスおよびパートナー製品と適切に統合されており、分析、機械学習 (ML)、またはアプリケーション開発ワークフローを可能にするローコード/ノーコードの抽出、変換、ロード (ETL) オプションを提供します。 AWS Glue ETL ジョブは、より複雑なパイプラインの XNUMX つのコンポーネントである場合があります。 これらのコンポーネントの実行を調整し、コンポーネント間の依存関係を管理することは、データ戦略における重要な機能です。 Apache Airflow の Amazon 管理ワークフロー (Amazon MWAA) は、オンプレミス リソース、AWS サービス、サードパーティ コンポーネントなどの分散テクノロジーを使用してデータ パイプラインを調整します。
この投稿では、Amazon MWAA の最新機能を使用して、Airflow によって調整された AWS Glue ジョブのモニタリングを簡素化する方法を示します。
ソリューションの概要
この投稿では以下について説明します。
- Amazon MWAA 環境をバージョン 2.4.3 にアップグレードする方法。
- Airflow から AWS Glue ジョブをオーケストレートする方法 有向無彩色グラフ (DAG)。
- Amazon MWAA における Airflow Amazon プロバイダー パッケージの可観測性の強化。 AWS Glue ジョブの実行ログを Airflow コンソールに統合して、データ パイプラインのトラブルシューティングを簡素化できるようになりました。 Amazon MWAA コンソールは、AWS Glue ジョブの実行を監視および分析するための単一の参照となります。 以前は、サポート チームがアクセスする必要がありました。 AWSマネジメントコンソール この可視化のために手動の手順を実行します。 この機能は、Amazon MWAA バージョン 2.4.3 からデフォルトで利用可能になります。
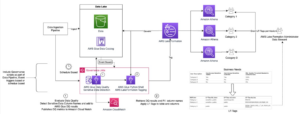
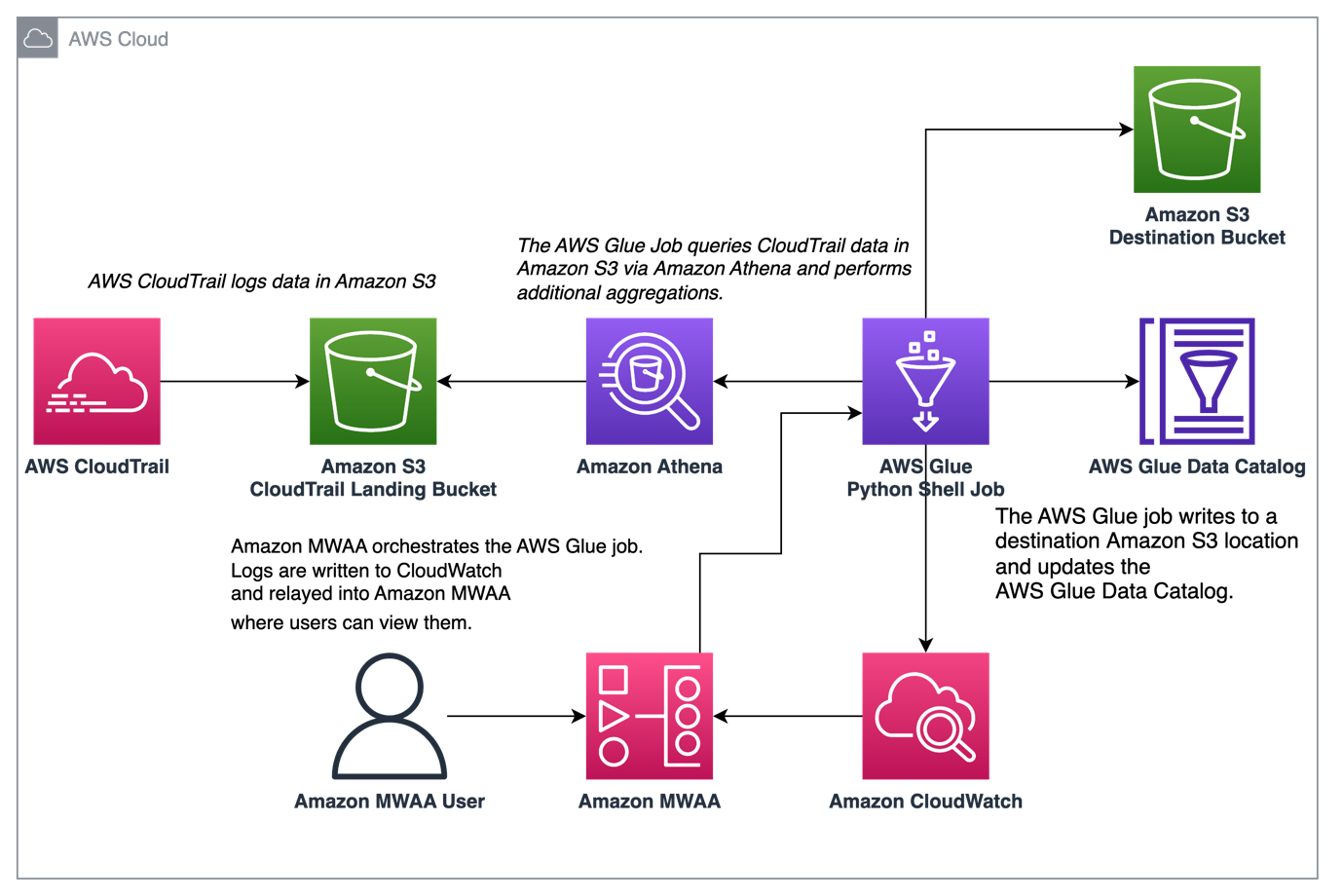
次の図は、ソリューションアーキテクチャを示しています。
前提条件
次の前提条件が必要です。
Amazon MWAA 環境をセットアップする
環境の作成手順については、以下を参照してください。 AmazonMWAA環境を作成する。 既存のユーザーの場合は、この投稿で取り上げた可観測性の強化を活用するために、バージョン 2.4.3 にアップグレードすることをお勧めします。
Amazon MWAA をバージョン 2.4.3 にアップグレードする手順は、現在のバージョンが 1.10.12 か 2.2.2 かによって異なります。 この投稿では両方のオプションについて説明します。
Amazon MWAA 環境をセットアップするための前提条件
次の前提条件を満たす必要があります。
バージョン 1.10.12 から 2.4.3 へのアップグレード
Amazon MWAA バージョンを使用している場合 1.10.12、 参照する 新しい Amazon MWAA 環境への移行 2.4.3 にアップグレードします。
バージョン 2.0.2 または 2.2.2 から 2.4.3 へのアップグレード
Amazon MWAA 環境バージョン 2.2.2 以前を使用している場合は、次の手順を実行します。
- 作る カスタム依存関係については、requirements.txt DAG に必要な特定のバージョンを使用します。
- ファイルを Amazon S3 にアップロードします Amazon MWAA 環境が依存関係をインストールするためのrequirements.txtを指す適切な場所にあります。
- の手順に従ってください 新しい Amazon MWAA 環境への移行 をクリックしてバージョン 2.4.3 を選択します。
DAG を更新する
古い Amazon MWAA 環境からアップグレードしたお客様は、既存の DAG を更新する必要がある場合があります。 Airflow バージョン 2.4.3 では、Airflow 環境はデフォルトで Amazon プロバイダー パッケージ バージョン 6.0.0 を使用します。 このパッケージには、オペレーター名の変更など、破壊的な変更が含まれる可能性があります。 たとえば、 AWSGlueジョブオペレーター は廃止され、次のものに置き換えられました グルージョブオペレーター。 互換性を維持するには、以前のバージョンの非推奨またはサポートされていない演算子を新しい演算子に置き換えて、Airflow DAG を更新します。 次の手順を実行します。
- MFAデバイスに移動する アマゾンAWSオペレーター.
- Amazon MWAA インスタンスにインストールされている適切なバージョン (デフォルトでは 6.0.0) を選択して、サポートされている Airflow オペレーターのリストを見つけます。
- 既存の DAG コードに必要な変更を加え、変更したファイルを Amazon S3 の DAG の場所にアップロードします。
Airflow から AWS Glue ジョブを調整する
このセクションでは、Airflow DAG 内での AWS Glue ジョブのオーケストレーションの詳細について説明します。 Airflow は、オンプレミスのプロセス、外部依存関係、他の AWS サービスなどの異種システム間の依存関係を含むデータ パイプラインの開発を容易にします。
AWS Glue と Amazon MWAA を使用して CloudTrail ログ集約を調整する
この例では、Amazon MWAA を使用して、CloudTrail ログに基づいて集約されたメトリクスを保持する AWS Glue Python Shell ジョブをオーケストレーションするユースケースを説明します。
CloudTrail を使用すると、AWS アカウントで行われる AWS API 呼び出しを可視化できます。 このデータの一般的な使用例は、監査と規制のニーズのためにアカウントのリソースに作用するプリンシパルの使用状況メトリクスを収集することです。
CloudTrail イベントはログに記録されるため、Amazon S3 に JSON ファイルとして配信されますが、分析クエリには理想的ではありません。 このデータを集約し、Parquet ファイルとして保存して、最適なクエリ パフォーマンスを実現したいと考えています。 最初のステップとして、AWS Glue ジョブで追加の集計を行う前に、Athena を使用してデータの初期クエリを実行できます。 AWS Glue データカタログテーブルの作成の詳細については、を参照してください。 パーティションプロジェクションを使用した Athena での CloudTrail ログのテーブルの作成 データ。 Athena 経由でデータを調査し、集計テーブルに保持するメトリクスを決定したら、AWS Glue ジョブを作成できます。
Athena で CloudTrail テーブルを作成する
まず、Athena 経由で CloudTrail データをクエリできるようにするテーブルをデータ カタログに作成する必要があります。 次のサンプル クエリは、リージョンと日付 (snapshot_date と呼ばれる) に関する XNUMX つのパーティションを持つテーブルを作成します。 CloudTrail バケット、AWS アカウント ID、および CloudTrail テーブル名のプレースホルダーを必ず置き換えてください。
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')Athena コンソールで前述のクエリを実行し、テーブル名とテーブルが作成された AWS Glue データ カタログ データベースをメモします。 これらの値は、後の Airflow DAG コードで使用します。
サンプル AWS Glue ジョブコード
次のコードはサンプルです AWS Glue Python シェル ジョブ それは次のことをします:
- どの日のデータを処理するかについての引数 (Amazon MWAA DAG から渡します) を受け取ります
- 使用する パンダ用 AWS SDK Athena クエリを実行して、AWS Glue の外部で CloudTrail JSON データの初期フィルタリングを実行します。
- Pandas を使用して、フィルタリングされたデータに対して単純な集計を実行します。
- 集約されたデータをテーブル内の AWS Glue データカタログに出力します。
- 処理中にログを使用します。これは Amazon MWAA で表示されます。
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
この AWS Glue ジョブの主な利点は次のとおりです。
- Athena クエリを使用して、初期フィルタリングが AWS Glue ジョブの外部で確実に行われるようにします。 そのため、最小限のコンピューティングを備えた Python シェル ジョブでも、大規模な CloudTrail データセットを集約するには十分です。
- 私たちは、 分析ライブラリセットオプション AWS SDK for Pandas ライブラリを使用するために AWS Glue ジョブを作成するときにオンになります。
AWS Glue ジョブを作成する
AWS Glue ジョブを作成するには、次の手順を実行します。
- 前のセクションのスクリプトをコピーし、ローカル ファイルに保存します。 この投稿では、ファイルの名前は次のとおりです。
script.py. - AWS Glue コンソールで、選択します ETL ジョブ ナビゲーションペインに表示されます。
- 新しいジョブを作成し、を選択します Python シェル スクリプト エディタ.
- 選択 既存のスクリプトをアップロードして編集する ローカルに保存したファイルをアップロードします。
- 選択する 創造する.

- ソフトウェア設定ページで、下図のように 仕事の詳細 タブで、AWS Glue ジョブの名前を入力します。
- IAMの役割、既存のロールを選択するか、Amazon S3、AWS Glue、Athena に必要なアクセス許可を持つ新しいロールを作成します。 ロールは、前に作成した CloudTrail テーブルをクエリし、出力場所に書き込む必要があります。
次のサンプル ポリシー コードを使用できます。 プレースホルダーを、CloudTrail ログ バケット、出力テーブル名、出力 AWS Glue データベース、出力 S3 バケット、CloudTrail テーブル名、CloudTrail テーブルを含む AWS Glue データベース、および AWS アカウント ID に置き換えます。
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
Pythonバージョン、選択する Pythonの3.9.
- 選択 共通の分析ライブラリをロードする.
- データ処理装置、選択する 1DPU.
- 他のオプションはデフォルトのままにするか、必要に応じて調整します。

- 選択する Save ジョブ設定を保存します。
AWS Glue ジョブをオーケストレートするように Amazon MWAA DAG を設定する
次のコードは、作成した AWS Glue ジョブをオーケストレートできる DAG 用です。 この DAG では次の主要な機能を利用します。
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
Amazon MWAA での AWS Glue ジョブの可観測性を向上させる
AWS Glue ジョブはログを書き込みます アマゾンクラウドウォッチ。 Airflow の Amazon プロバイダー パッケージに対する最近の可観測性の強化により、これらのログは Airflow タスク ログと統合されるようになりました。 この統合により、Airflow ユーザーは Airflow UI で直接エンドツーエンドの可視性を得ることができ、CloudWatch や AWS Glue コンソールで検索する必要がなくなります。
この機能を使用するには、Amazon MWAA 環境にアタッチされている IAM ロールに、必要なログを取得して書き込むための次のアクセス許可があることを確認してください。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}verbose=true の場合、AWS Glue ジョブの実行ログが Airflow タスク ログに表示されます。 デフォルトは false です。 詳細については、以下を参照してください。 計測パラメータ.
有効にすると、DAG は AWS Glue ジョブの CloudWatch ログ ストリームを読み取り、Airflow DAG AWS Glue ジョブ ステップ ログに中継します。 これにより、DAG ログを介してリアルタイムで AWS Glue ジョブの実行に関する詳細な洞察が得られます。 AWS Glue ジョブは、ジョブの STDOUT と STDERR にそれぞれ基づいて出力とエラー CloudWatch ログ グループを生成することに注意してください。 出力ログ グループ内のすべてのログと、エラー ログ グループからの例外ログまたはエラー ログは、Amazon MWAA に中継されます。
AWS 管理者は、サポート チームのアクセスを Airflow のみに制限できるようになり、Amazon MWAA がジョブ オーケストレーションとジョブの健全性管理の一元管理画面になります。 以前は、ユーザーは Airflow DAG ステップで AWS Glue ジョブの実行ステータスを確認し、ジョブ実行識別子を取得する必要がありました。 次に、AWS Glue コンソールにアクセスしてジョブの実行履歴を見つけ、識別子を使用して目的のジョブを検索し、最後にジョブの CloudWatch ログに移動してトラブルシューティングを行う必要がありました。
DAG を作成する
DAG を作成するには、次の手順を実行します。
- 前述の DAG コードをローカルの .py ファイルに保存し、指定されたプレースホルダーを置き換えます。
AWS アカウント ID、AWS Glue ジョブ名、CloudTrail テーブルを含む AWS Glue データベース、および CloudTrail テーブル名の値はすでにわかっている必要があります。 必要に応じて、出力 S3 バケット、出力 AWS Glue データベース、出力テーブル名を調整できますが、以前に使用した AWS Glue ジョブの IAM ロールがそれに応じて設定されていることを確認してください。
- Amazon MWAA コンソールで、環境に移動して、DAG コードが保存されている場所を確認します。
DAG フォルダーは、DAG ファイルを配置する S3 バケット内のプレフィックスです。
- そこに編集したファイルをアップロードします。

- Amazon MWAA コンソールを開いて、DAG がテーブルに表示されていることを確認します。

DAGを実行する
DAG を実行するには、次の手順を実行します。
- 次のオプションから選択します。
- DAGをトリガーする – これにより、処理するデータとして昨日のデータが使用されます
- 構成付きの DAG をトリガーする – このオプションを使用すると、バックフィル用に別の日付を渡すことができます。これは、次の方法で取得されます。
dag_run.confDAG コード内でパラメータとして AWS Glue ジョブに渡されます。

次のスクリーンショットは、選択した場合の追加の構成オプションを示しています。 構成付きの DAG をトリガーする.

- DAG の実行を監視します。
- DAG が完了したら、実行の詳細を開きます。
右側のペインで、ログを表示するか、 タスクインスタンスの詳細 全体をご覧ください。

- のおかげで、AWS Glue コンソールを使用せずに Amazon MWAA で AWS Glue ジョブ出力ログを表示できます。
GlueJobOperator冗長なフラグ。

AWS Glue ジョブの結果は、指定した出力テーブルに書き込まれます。
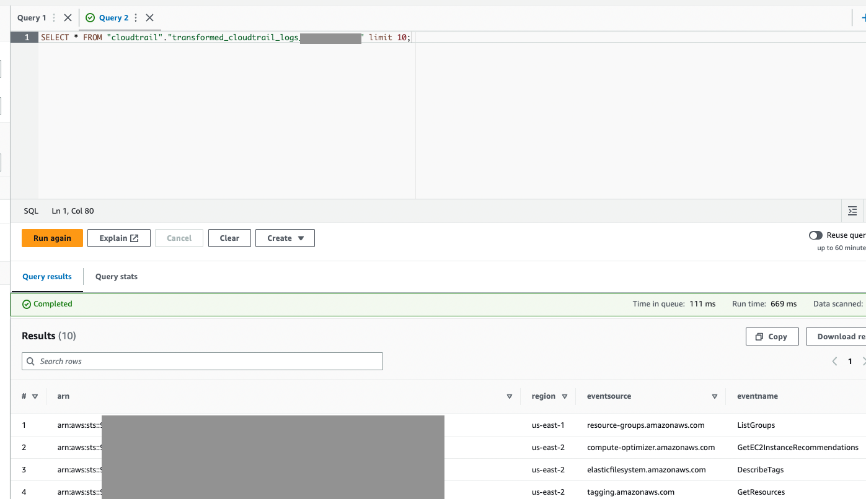
- Athena 経由でこのテーブルにクエリを実行して、成功したことを確認します。
まとめ
Amazon MWAA は、AWS Glue ジョブのステータスを追跡する単一の場所を提供し、ジョブ オーケストレーションとヘルス管理のための単一画面として Airflow コンソールを使用できるようになりました。 この投稿では、Airflow を使用して AWS Glue ジョブをオーケストレーションする手順を説明しました。 GlueJobOperator。 新しい可観測性の強化により、統一されたエクスペリエンスで AWS Glue ジョブのトラブルシューティングをシームレスに行うことができます。 また、Amazon MWAA 環境を互換性のあるバージョンにアップグレードし、依存関係を更新し、それに応じて IAM ロールポリシーを変更する方法も示しました。
一般的なトラブルシューティング手順の詳細については、次を参照してください。 トラブルシューティング: Amazon MWAA 環境の作成と更新。 Amazon MWAA 環境への移行の詳細については、以下を参照してください。 1.10から2へのアップグレード。 Airflow Amazon プロバイダー パッケージの AWS Glue ジョブの可観測性を高めるためのオープンソース コードの変更については、以下を参照してください。 AWS Glue ジョブからのリレーログ.
最後に、次のサイトにアクセスすることをお勧めします。 AWS ビッグデータ ブログ AWS の分析、機械学習、データ ガバナンスに関するその他の資料については、こちらをご覧ください。
著者について
 ルシャブ・ロカンデ は、AWS プロフェッショナル サービス分析プラクティスを担当するデータおよび ML エンジニアです。 彼は、顧客がビッグデータ、機械学習、分析ソリューションを実装するのを支援しています。 仕事以外では、家族と過ごしたり、読書、ランニング、ゴルフを楽しんでいます。
ルシャブ・ロカンデ は、AWS プロフェッショナル サービス分析プラクティスを担当するデータおよび ML エンジニアです。 彼は、顧客がビッグデータ、機械学習、分析ソリューションを実装するのを支援しています。 仕事以外では、家族と過ごしたり、読書、ランニング、ゴルフを楽しんでいます。
 ライアン・ゴメス は、AWS プロフェッショナル サービス分析プラクティスを担当するデータおよび ML エンジニアです。 彼は、クラウドでの分析および機械学習ソリューションを通じて、顧客がより良い成果を達成できるよう支援することに情熱を注いでいます。 仕事以外では、フィットネス、料理、友人や家族と充実した時間を過ごすことを楽しんでいます。
ライアン・ゴメス は、AWS プロフェッショナル サービス分析プラクティスを担当するデータおよび ML エンジニアです。 彼は、クラウドでの分析および機械学習ソリューションを通じて、顧客がより良い成果を達成できるよう支援することに情熱を注いでいます。 仕事以外では、フィットネス、料理、友人や家族と充実した時間を過ごすことを楽しんでいます。
 ヴィシュワ グプタ は、AWS プロフェッショナル サービス分析プラクティスのシニア データ アーキテクトです。 彼は、顧客がビッグデータと分析ソリューションを実装するのを支援しています。 仕事以外では、家族と時間を過ごしたり、旅行したり、新しい食べ物を試したりすることを楽しんでいます。
ヴィシュワ グプタ は、AWS プロフェッショナル サービス分析プラクティスのシニア データ アーキテクトです。 彼は、顧客がビッグデータと分析ソリューションを実装するのを支援しています。 仕事以外では、家族と時間を過ごしたり、旅行したり、新しい食べ物を試したりすることを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 未来を鋳造する w エイドリエン・アシュリー。 こちらからアクセスしてください。
- PREIPO® を使用して PRE-IPO 企業の株式を売買します。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- :持っている
- :は
- :not
- :どこ
- $UP
- 1
- 10
- 100
- 12
- 8
- a
- 私たちについて
- アクセス
- それに応じて
- 達成する
- 越えて
- Action
- 非周期的
- NEW
- 利点
- 利点
- 後
- 凝集
- すべて
- 許す
- ことができます
- 既に
- また
- Amazon
- Amazon Webサービス
- an
- 分析的
- 分析論
- 分析します
- および
- どれか
- アパッチ
- API
- 申し込み
- アプリケーション開発
- 適切な
- 建築
- です
- 引数
- 引数
- AS
- At
- 属性
- 監査
- 利用できます
- AWS
- AWSグルー
- AWSプロフェッショナルサービス
- ベース
- BE
- になる
- き
- さ
- より良いです
- の間に
- ビッグ
- ビッグデータ
- 両言語で
- 破壊
- ビルド
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 呼ばれます
- コール
- 缶
- 場合
- 例
- カタログ
- 原因
- 変化する
- 変更
- チェック
- 選択する
- クラウド
- コード
- COM
- 組み合わせる
- コメント
- コマンドと
- 企業
- 互換性
- 互換性のあります
- コンプリート
- 複雑な
- コンポーネント
- コンポーネント
- 計算
- 確認します
- 領事
- 統合します
- 圧密
- 料理
- 基本
- カバー
- 作ります
- 作成した
- 作成します。
- 作成
- 電流プローブ
- カスタム
- 顧客
- Customers
- DAG
- データ
- データ統合
- データ処理
- データ戦略
- データウェアハウス
- データベース
- データベースを追加しました
- データセット
- 日付
- 試合日
- 日付時刻
- 日
- 決定しました
- デフォルト
- 配信
- 実証
- によっては
- 非推奨の
- 詳細な
- 細部
- 開発
- 異なる
- 異なります
- デジタル
- デジタルメディア
- 直接に
- 話し合います
- 配布
- 分散システム
- do
- ありません
- すること
- 行われ
- 間に
- e
- 前
- 簡単
- 効果
- 排除
- ほかに
- enable
- 使用可能
- 可能
- 端から端まで
- 婚約
- エンジニア
- 強化
- 確保
- 入力します
- 環境
- エラー
- エーテル(ETH)
- イベント
- 例
- 除く
- 例外
- 存在する
- 既存の
- 存在
- 体験
- エクスペリエンス
- 調査済み
- 表現
- 外部
- エキス
- Failed:
- false
- 家族
- 特徴
- 特集
- 特徴
- File
- フィルタリング
- 最後に
- もう完成させ、ワークスペースに掲示しましたか?
- フィットネス
- フォロー中
- フード
- 形式でアーカイブしたプロジェクトを保存します.
- 友達
- から
- フル
- 集める
- 生成する
- ガラス
- Go
- ゴルフ
- ガバナンス
- グループ
- Hadoopの
- 持ってる
- he
- 健康
- 助け
- ことができます
- history
- ハイブ
- 認定条件
- How To
- HTML
- HTTP
- HTTPS
- IAM
- ID
- 理想
- 考え
- 識別子
- if
- 説明する
- 実装する
- import
- in
- 綿密な
- include
- 含めて
- 増える
- 増加した
- 示された
- 産業
- info
- 情報
- 初期
- 革新的な
- 洞察
- インストールする
- 説明書
- 統合された
- 統合
- 関心
- 内部
- に
- IT
- ジョブ
- Jobs > Create New Job
- JPG
- JSON
- キー
- 既知の
- 大
- 後で
- 最新の
- LEARN
- 学習
- 図書館
- LIMIT
- リスト
- 負荷
- ローカル
- 局部的に
- 場所
- ログ
- ログインして
- ロギング
- 探して
- 機械
- 機械学習
- 製
- 維持する
- make
- 作成
- マネージド
- 管理
- 管理する
- マニュアル
- 材料
- 五月..
- メディア
- 大会
- メッセージ
- メトリック
- 移行中
- 最小限の
- ML
- 修正されました
- モジュール
- モニター
- モニタリング
- 他には?
- しなければなりません
- 名
- 名
- ナビゲート
- ナビゲーション
- 必要
- 必要
- 必要とされる
- ニーズ
- 新作
- 何も
- 今
- of
- 提供すること
- on
- ONE
- もの
- の
- 開いた
- オープンソース
- オープンソースコード
- オペレータ
- 演算子
- 最適な
- オプション
- オプション
- or
- 調整された
- 編成
- その他
- 私たちの
- 成果
- 出力
- 外側
- パッケージ
- パンダ
- ペイン
- パラメータ
- パートナー
- パス
- 渡された
- 情熱的な
- パフォーマンス
- パーミッション
- 持続する
- パイプライン
- 場所
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポイント
- 方針
- ポスト
- :
- 練習
- 前提条件
- 前
- 前に
- プロセス
- ラボレーション
- 処理
- 製品
- プロ
- 専門家
- 対応プロファイル
- 投影
- プロバイダー
- プロバイダ
- は、大阪で
- Python
- 品質
- クエリ
- 上げる
- 範囲
- 読む
- リーディング
- リアル
- への
- 最近
- 推奨する
- 地域
- レギュレータ
- リレー
- replace
- 置き換え
- の提出が必要です
- 要件
- リソースを追加する。
- リソース
- それぞれ
- 応答
- 結果
- リテンションを維持
- 右
- 職種
- 行
- ラン
- ランニング
- s
- Save
- シナリオ
- SDDK
- シームレス
- を検索
- セクション
- 安全に
- Seek
- シニア
- サーバレス
- サービス
- 設定
- シェル(Shell)
- すべき
- 表示する
- 作品
- 簡単な拡張で
- 簡素化する
- から
- Snapshot
- 溶液
- ソリューション
- 一部
- 特定の
- 指定の
- 支出
- ステートメント
- Status:
- 手順
- ステップ
- まだ
- ストレージ利用料
- 保存され
- 戦略
- 流れ
- 文字列
- 成功した
- そのような
- 十分な
- サポート
- サポート
- システム
- テーブル
- 取る
- 取得
- 仕事
- チーム
- テクノロジー
- template
- 感謝
- それ
- アプリ環境に合わせて
- それら
- その後
- そこ。
- ボーマン
- 彼ら
- サードパーティ
- この
- 介して
- 時間
- 〜へ
- 追跡する
- 最適化の適用
- 旅行
- true
- 試します
- 火曜日
- オン
- 2
- type
- ui
- 統一
- 単位
- アップデイト
- 更新版
- 更新
- アップグレード
- アップグレード
- アップロード
- 使用法
- つかいます
- 使用事例
- 中古
- users
- 値
- 価値観
- バージョン
- 、
- 詳しく見る
- ビュー
- 視認性
- 目に見える
- walked
- 欲しいです
- ました
- we
- ウェブ
- Webサービス
- WELL
- この試験は
- いつ
- かどうか
- which
- 誰
- 意志
- 以内
- 無し
- 仕事
- ワークフロー
- でしょう
- 書きます
- 書かれた
- 貴社
- あなたの
- ゼファーネット