この投稿は、LSEG の Low Latency グループの Pramod Nayak、LakshmiKanth Mannem、Vivek Aggarwal との共著です。
取引コスト分析 (TCA) は、トレーダー、ポートフォリオ マネージャー、ブローカーによって取引前および取引後の分析に広く使用されており、取引コストと取引戦略の有効性を測定および最適化するのに役立ちます。この記事では、オプションの買値と売値のスプレッドを分析します。 LSEG ティック履歴 – PCAP データセットを使用して Apache Spark 用 Amazon Athena。大規模なデータセットであっても、インフラストラクチャのセットアップや Spark の構成を心配することなく、データにアクセスし、データに適用するカスタム関数を定義し、データセットをクエリおよびフィルターし、分析結果を視覚化する方法を示します。
経歴
オプション価格報告局 (OPRA) は、重要な証券情報処理機関として機能し、米国オプションの最終販売レポート、相場、関連情報を収集、統合、配布します。 18 のアクティブな米国オプション取引所と 1.5 万件を超える対象契約を擁する OPRA は、包括的な市場データを提供する上で極めて重要な役割を果たしています。
5 年 2024 月 48 日、Securities Industry Automation Corporation (SIAC) は、OPRA フィードを 96 個のマルチキャスト チャネルから 37.3 個のマルチキャスト チャネルにアップグレードする予定です。この機能強化は、米国オプション市場の取引活動とボラティリティの激化に対応して、シンボルの配布とライン容量の利用を最適化することを目的としています。 SIAC は、最大 XNUMX GBits/秒のピーク データ レートに備えることを企業に推奨しています。
このアップグレードにより公開データの総量は直ちに変更されませんが、OPRA は大幅に速い速度でデータを配布できるようになります。この移行は、ダイナミックなオプション市場の需要に応えるために極めて重要です。
OPRA は最も大量のフィードの 150.4 つとして際立っており、3 年第 2023 四半期には 400 日で XNUMX 億メッセージのピークに達し、XNUMX 日で XNUMX 億メッセージの容量ヘッドルーム要件があります。あらゆるメッセージをキャプチャすることは、取引コスト分析、市場流動性の監視、取引戦略の評価、市場調査にとって重要です。
データについて
LSEG ティック履歴 – PCAP は、30 PB を超えるクラウドベースのリポジトリであり、超高品質の世界市場データが格納されています。このデータは、世界中の主要なプライマリおよびバックアップ エクスチェンジ データ センターに戦略的に配置された冗長キャプチャ プロセスを使用して、エクスチェンジ データ センター内で細心の注意を払って直接キャプチャされます。 LSEG のキャプチャ テクノロジは、ロスレス データ キャプチャを保証し、GPS タイム ソースを使用してナノ秒のタイムスタンプ精度を実現します。さらに、洗練されたデータアービトラージ技術を採用して、データギャップをシームレスに埋めます。キャプチャに続いて、データは細心の注意を払って処理と調停を受け、次に次の方法を使用して Parquet 形式に正規化されます。 LSEGのリアルタイムウルトラダイレクト (RTUD) フィード ハンドラー。
分析用のデータの準備に不可欠な正規化プロセスでは、6 日あたり最大 XNUMX TB の圧縮 Parquet ファイルが生成されます。膨大な量のデータは、複数の取引所にまたがり、多様な属性を特徴とする多数のオプション契約を特徴とする OPRA の包括的な性質に起因すると考えられます。市場のボラティリティの増大とオプション取引所でのマーケットメイク活動により、OPRA で公開されるデータ量がさらに増加しています。
Tick History – PCAP の属性により、企業は次のようなさまざまな分析を行うことができます。
- 取引前分析 – 潜在的な取引への影響を評価し、履歴データに基づいてさまざまな実行戦略を検討します
- 取引後の評価 – ベンチマークと比較して実際の実行コストを測定し、実行戦略のパフォーマンスを評価します
- 最適化 実行 – 過去の市場パターンに基づいて執行戦略を微調整し、市場への影響を最小限に抑え、全体的な取引コストを削減します
- 危機管理 – スリッページパターンを特定し、異常値を特定し、取引活動に関連するリスクを積極的に管理します
- パフォーマンスの帰属 – ポートフォリオのパフォーマンスを分析する際に、取引の決定の影響を投資の決定から分離する
LSEG Tick History – PCAP データセットは、次の場所で入手できます。 AWSデータ交換 でアクセスできます AWS Marketplace Amazon S3 の AWS データ交換、LSEG から直接 PCAP データにアクセスできます。 Amazon シンプル ストレージ サービス (Amazon S3) バケットを利用できるため、企業が独自のデータのコピーを保存する必要がなくなります。このアプローチにより、データの管理とストレージが合理化され、クライアントは使いやすく、統合され、高品質の PCAP または正規化されたデータに即座にアクセスできるようになります。 データストレージの大幅な節約.
Apache Spark 用の Athena
分析の取り組みについては、 Apache Spark 用の Athena は、Athena コンソールまたは Athena API からアクセスできる簡素化されたノートブック エクスペリエンスを提供し、インタラクティブな Apache Spark アプリケーションを構築できます。 Athena は、最適化された Spark ランタイムを使用して、Spark エンジンの数を 1 秒未満で動的にスケーリングすることで、ペタバイト規模のデータの分析を支援します。さらに、pandas や NumPy などの一般的な Python ライブラリがシームレスに統合されているため、複雑なアプリケーション ロジックを作成できます。柔軟性は、ノートブックで使用するカスタム ライブラリのインポートまで拡張されます。 Athena for Spark は、ほとんどのオープンデータ形式に対応しており、 AWSグルー データカタログ。
データセット
この分析では、17 年 2023 月 XNUMX 日の LSEG Tick History – PCAP OPRA データセットを使用しました。このデータセットは次のコンポーネントで構成されています。
- 最高入札価格(BBO) – 特定の取引所における証券の最高買値と最低売値をレポートします。
- 全国最高入札価格 (NBBO) – すべての取引所にわたる証券の最高入札額と最低要求額をレポートします。
- トレード – すべての取引所で完了した取引を記録します
データセットには次のデータ ボリュームが含まれます。
- トレード – 160 MB が約 60 個の圧縮された Parquet ファイルに分散
- BBO – 2.4 TB を約 300 の圧縮された Parquet ファイルに分散
- NBBO – 2.8 TB を約 200 の圧縮された Parquet ファイルに分散
分析の概要
取引コスト分析 (TCA) のために OPRA ティック履歴データを分析するには、特定の取引イベントに関する市場相場と取引を精査する必要があります。この調査の一環として次の指標を使用します。
- 引用スプレッド (QS) – BBOアスクとBBOビッドの差として計算されます
- 実効スプレッド(ES) – 取引価格と BBO の中間点の差として計算されます (BBO ビッド + (BBO アスク – BBO ビッド)/2)
- 実効スプレッド/相場スプレッド (EQF) – (ES / QS) * 100として計算されます。
これらのスプレッドは取引前に計算され、さらに取引後の 1 つの間隔 (取引直後、10 秒、60 秒、XNUMX 秒) で計算されます。
Apache Spark 用に Athena を構成する
Apache Spark 用に Athena を構成するには、次の手順を実行します。
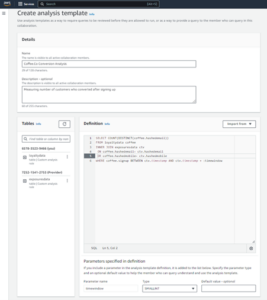
- Athena コンソールの次の場所にあります。 始める選択 PySpark と Spark SQL を使用してデータを分析する.
- Athena Spark を初めて使用する場合は、選択してください ワークグループを作成.

- ワークグループ名¸ ワークグループの名前を入力します。
tca-analysis. - 分析エンジン セクション、選択 Apache Spark.
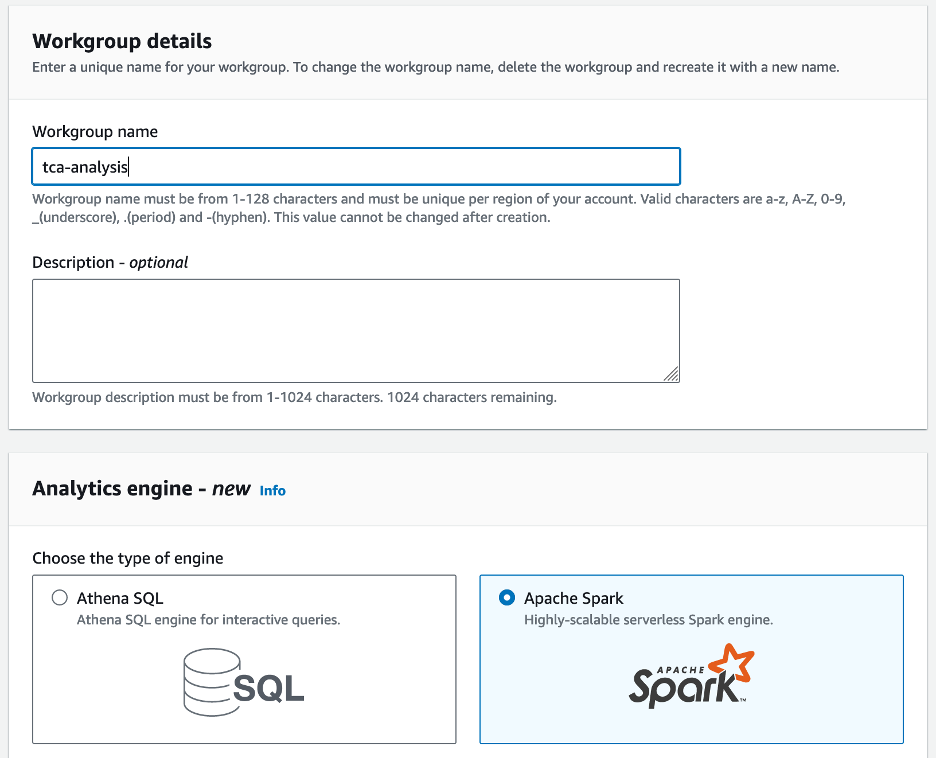
- 追加の構成 セクション、選択できます デフォルトを使用 またはカスタムを提供する AWS IDおよびアクセス管理 (IAM) ロールと計算結果の Amazon S3 の場所。
- 選択する ワークグループを作成.
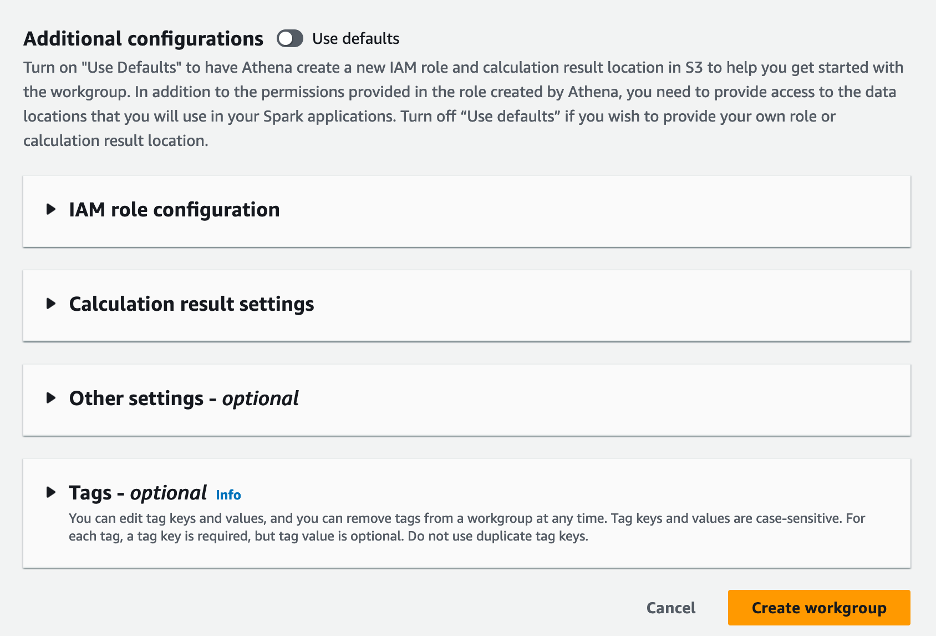
- ワークグループを作成した後、次の場所に移動します。 ノートブック タブを選択して ノートブックを作成.
- ノートブックの名前を入力します。
tca-analysis-with-tick-history. - 選択する 創造する ノートブックを作成します。
ノートブックを起動します
すでに Spark ワークグループを作成している場合は、 ノートブックエディタを起動する 下 始める.
![]()
ノートブックが作成されると、インタラクティブなノートブック エディターにリダイレクトされます。
![]()
これで、次のコードをノートブックに追加して実行できるようになりました。
分析を作成する
分析を作成するには、次の手順を実行します。
- 共通ライブラリをインポートします。
- BBO、NBBO、および取引のデータ フレームを作成します。
- これで、トランザクションコスト分析に使用する取引を特定できます。
次の出力が得られます。
今後は、貿易商品 (tp)、取引価格 (tpr)、および取引時間 (tt) について、強調表示された取引情報を使用します。
- ここでは、分析用に多数のヘルパー関数を作成します。
- 次の関数では、取引前後のすべての相場を含むデータセットを作成します。 Athena Spark は、データセットを処理するために起動する DPU の数を自動的に決定します。
- 次に、選択した取引からの情報を使用して TCA 分析関数を呼び出してみましょう。
分析結果を可視化する
次に、視覚化に使用するデータ フレームを作成しましょう。各データ フレームには、各データ フィード (BBO、NBBO) の 5 つの時間間隔のいずれかの引用符が含まれています。
次のセクションでは、さまざまなビジュアライゼーションを作成するためのサンプル コードを示します。
取引前にQSとNBBOをプロットする
次のコードを使用して、取引前に見積スプレッドと NBBO をプロットします。
![]()
各市場のQSと取引後のNBBOをプロット
次のコードを使用して、取引直後に各市場と NBBO の見積スプレッドをプロットします。
![]()
BBO の各時間間隔および各市場の QS をプロットする
次のコードを使用して、BBO の各時間間隔および各市場の見積スプレッドをプロットします。
![]()
各時間間隔の ES と BBO の市場をプロットする
次のコードを使用して、BBO の各時間間隔と市場の実効スプレッドをプロットします。
各時間間隔と BBO の市場の EQF をプロットします。
次のコードを使用して、BBO の各時間間隔および市場の実効スプレッド/相場スプレッドをプロットします。
Athena Spark の計算パフォーマンス
コード ブロックを実行すると、Athena Spark は計算を完了するために必要な DPU の数を自動的に決定します。最後のコード ブロックで、 tca_analysis 関数を使用すると、実際には Spark にデータを処理するように指示し、結果の Spark データフレームを Pandas データフレームに変換します。これは分析の最も集中的な処理部分を構成し、Athena Spark がこのブロックを実行すると、進行状況バー、経過時間、現在データを処理している DPU の数が表示されます。たとえば、次の計算では、Athena Spark は 18 DPU を利用しています。
![]()
Athena Spark ノートブックを構成するときに、使用できる DPU の最大数を設定するオプションがあります。デフォルトは 20 DPU ですが、この計算を 10、20、および 40 DPU でテストして、Athena Spark が分析を実行するためにどのように自動的にスケーリングするかを実証しました。 Athena Spark は直線的にスケーリングし、ノートブックが最大 15 DPU で構成されている場合は 21 分 10 秒、ノートブックが 8 DPU で構成されている場合は 23 分 20 秒、ノートブックが最大 4 DPU で構成されている場合は 44 分 40 秒かかります。 XNUMX 個の DPU で構成されています。 Athena Spark は DPU 使用量に基づいて XNUMX 秒あたりの粒度で課金するため、これらの計算のコストは同様ですが、より高い最大 DPU 値を設定すると、Athena Spark は分析の結果をより速く返すことができます。 Athena Spark の価格の詳細については、ここをクリックしてください。 こちら.
まとめ
この投稿では、LSEG の Tick History-PCAP からの高忠実度 OPRA データを使用して、Athena Spark を使用してトランザクション コスト分析を実行する方法を説明しました。 OPRA データをタイムリーに利用できるようになり、Amazon S3 向けの AWS Data Exchange のアクセシビリティ革新によって補完され、重要な取引上の意思決定のための実用的な洞察を作成したいと考えている企業の分析にかかる時間が戦略的に短縮されます。 OPRA は毎日約 7 TB の正規化された Parquet データを生成しますが、OPRA データに基づいた分析を提供するインフラストラクチャの管理は困難です。
Tick History – PCAP for OPRA データの大規模なデータ処理を処理する Athena のスケーラビリティにより、AWS で迅速かつスケーラブルな分析ソリューションを求める組織にとって、Athena は魅力的な選択肢となります。この投稿では、AWS エコシステムと Tick History-PCAP データの間のシームレスな相互作用と、金融機関がこの相乗効果を活用して重要な取引および投資戦略においてデータ主導の意思決定を推進する方法を示します。
著者について
![]() プラモド・ナヤック LSEG の低遅延グループの製品管理ディレクターです。 Pramod は金融テクノロジー業界で 10 年以上の経験があり、ソフトウェア開発、分析、データ管理に重点を置いています。 Pramod は元ソフトウェア エンジニアで、市場データと定量的取引に情熱を注いでいます。
プラモド・ナヤック LSEG の低遅延グループの製品管理ディレクターです。 Pramod は金融テクノロジー業界で 10 年以上の経験があり、ソフトウェア開発、分析、データ管理に重点を置いています。 Pramod は元ソフトウェア エンジニアで、市場データと定量的取引に情熱を注いでいます。
![]() ラクシュミカント・マンネム LSEG の低遅延グループのプロダクト マネージャーです。彼は、低遅延市場データ業界向けのデータおよびプラットフォーム製品に焦点を当てています。 LakshmiKanth は、お客様が市場データのニーズに合わせて最適なソリューションを構築できるよう支援します。
ラクシュミカント・マンネム LSEG の低遅延グループのプロダクト マネージャーです。彼は、低遅延市場データ業界向けのデータおよびプラットフォーム製品に焦点を当てています。 LakshmiKanth は、お客様が市場データのニーズに合わせて最適なソリューションを構築できるよう支援します。
![]() ヴィヴェク・アガルワル LSEG の低遅延グループのシニア データ エンジニアです。 Vivek は、取得した市場データ フィードと参照データ フィードの処理と配信のためのデータ パイプラインの開発と維持に取り組んでいます。
ヴィヴェク・アガルワル LSEG の低遅延グループのシニア データ エンジニアです。 Vivek は、取得した市場データ フィードと参照データ フィードの処理と配信のためのデータ パイプラインの開発と維持に取り組んでいます。
![]() アルケット・メムシャジ AWS の金融サービス市場開発チームの主任アーキテクトです。 Alket は技術戦略を担当し、パートナーや顧客と協力して、最も要求の厳しい資本市場のワークロードも AWS クラウドにデプロイします。
アルケット・メムシャジ AWS の金融サービス市場開発チームの主任アーキテクトです。 Alket は技術戦略を担当し、パートナーや顧客と協力して、最も要求の厳しい資本市場のワークロードも AWS クラウドにデプロイします。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- :持っている
- :は
- :not
- :どこ
- $UP
- 1
- 10
- 100
- 12
- 視聴者の38%が
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- 私たちについて
- アクセス
- アクセス
- 接近性
- アクセス可能な
- 越えて
- アクティブ
- アクティビティ
- 実際の
- 実際に
- 加えます
- さらに
- アドレッシング
- 利点
- 後
- に対して
- アガワル
- 目指して
- すべて
- 許可
- 既に
- Amazon
- アマゾンアテナ
- Amazon Webサービス
- an
- 分析
- 分析
- 分析的
- 分析論
- 分析します
- 分析する
- および
- どれか
- アパッチ
- Apache Spark
- API
- 申し込み
- 申し込む
- アプローチ
- 約
- 裁定取引
- 仲裁
- です
- 周りに
- AS
- 頼む
- 評価する
- 関連する
- At
- 属性
- 権威
- 自動的に
- オートメーション
- 賃貸条件の詳細・契約費用のお見積り等について
- 利用できます
- AWS
- バックアップ
- バー
- ベース
- BE
- なぜなら
- ベンチマーク
- BEST
- の間に
- 入札
- 10億
- ブロック
- ブローカー
- ビルド
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 計算する
- 計算された
- 計算
- コール
- 缶
- 容量
- 資本
- 資本市場
- キャプチャー
- 捕捉した
- キャプチャ
- カタログ
- センター
- 挑戦
- チャンネル
- 特徴付けられた
- 課金
- 選択
- 選択する
- クライアント
- クラウド
- コード
- 収集
- コマンドと
- 説得力のある
- コンプリート
- 記入済みの
- コンポーネント
- 包括的な
- 含む
- プロフェッショナルな方法で
- 設定された
- 構成する
- 領事
- 統合
- 含まれています
- 契約
- 貢献する
- 変換
- 株式会社
- 費用
- コスト
- 共著
- 作ります
- 作成した
- 創造
- 重大な
- 重大な
- 現在
- カスタム
- Customers
- ダッシュ
- データ
- データセンター
- データエンジニア
- データ交換
- データ管理
- データ処理
- データストレージ
- データ駆動型の
- データセット
- 中
- 意思決定
- 決定
- デフォルト
- 定義します
- 配達
- 厳しい
- 需要
- 実証します
- 実証
- 展開します
- 細部
- 決定する
- 開発
- 開発
- 開発チーム
- 違い
- 異なります
- 直接に
- 取締役
- 配布
- ディストリビューション
- 異なる
- ドライブ
- ダイナミック
- 動的に
- ダイナミクス
- 各
- 緩和する
- 使いやすさ
- エコシステム
- エディタ
- 効果的な
- 有効
- 適格
- 排除
- 採用
- 採用
- enable
- 可能
- 包含する
- 努力
- エンジン
- エンジニア
- エンジン
- 強化
- 確実に
- 入力します
- 高まる
- エーテル(ETH)
- 評価する
- 評価
- さらに
- イベント
- あらゆる
- 例
- 交換
- 交換について
- 実行
- 体験
- 探る
- 表現します
- 拡張する
- 速いです
- 特色
- 2月
- イチジク
- 埋める
- filter
- ファイナンシャル
- 金融機関
- 金融業務
- 金融技術
- 企業
- 名
- 初回
- 五
- 柔軟性
- 焦点を当てて
- 焦点
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- 前者
- フォワード
- 4
- FRAME
- から
- function
- 機能
- さらに
- ギャップ
- 生成
- 取得する
- 与えられた
- グローバル
- 世界市場
- Go
- 行く
- GPS
- グループ
- ハンドリング
- 持ってる
- 持って
- he
- ヘッドルーム
- ことができます
- 高品質
- より高い
- 最高
- 強調表示された
- 歴史的
- history
- 住宅
- 認定条件
- How To
- HTTP
- HTTPS
- IAM
- 識別する
- アイデンティティ
- if
- 即時の
- 直ちに
- 影響
- import
- in
- 含めて
- 増加した
- 産業を変えます
- 情報
- インフラ
- イノベーション
- 洞察
- 機関
- インテグラル
- 統合された
- 統合
- 相互作用
- 相互作用的
- に
- 複雑な
- 投資
- 関与
- IT
- JPG
- ただ
- 大
- 大規模
- 姓
- レイテンシ
- 起動する
- less
- ライブラリ
- LINE
- 流動性
- 場所
- ロジック
- 探して
- ロー
- 最低
- 保守
- 主要な
- 作る
- 作成
- 管理します
- 管理
- マネージャー
- マネージャー
- 管理する
- 方法
- 多くの
- 市場
- 市場データ
- 市場への影響
- 市場調査
- 市場のボラティリティ
- マーケットメイク
- マーケット
- 大規模な
- マスタリング
- 五月..
- だけど
- メッセージ
- メッセージ
- 細心の注意
- 細心の注意を払って
- メトリック
- 百万
- 最小限に抑えます
- 分
- モニタリング
- 他には?
- さらに
- 最も
- ずっと
- の試合に
- 名
- 自然
- ナビゲート
- 必要
- ニーズ
- なし
- ノート
- ノートPC
- 数
- 多数の
- numpy
- 観測された
- of
- 提供
- オファー
- on
- ONE
- 最適な
- 最適化
- 最適化
- オプション
- オプション
- or
- 組織
- 私たちの
- でる
- 出力
- が
- 全体
- 自分の
- パンダ
- 部
- パートナー
- 情熱的な
- パターン
- ピーク
- 以下のために
- 実行する
- パフォーマンス
- 極めて重要な
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 演劇
- お願いします
- プロット
- ポートフォリオ
- ポートフォリオマネージャー
- 配置された
- ポスト
- 取引後
- 潜在的な
- 精度
- 準備
- 準備中
- ブランド
- 価格設定
- 主要な
- 校長
- プロセス
- ラボレーション
- 処理
- プロセッサ
- プロダクト
- 製品管理
- プロダクトマネージャー
- 製品
- 進捗
- 提供します
- 提供
- 公表
- Python
- Q3
- 量
- クエリー
- 引用
- レート
- 価格表
- 読む
- リアル
- への
- 推奨される
- 記録
- レッド
- 減らします
- 軽減
- 参照
- 再定住
- 各種レポート作成
- レポート
- 倉庫
- 要件
- 必要
- 研究
- 応答
- 責任
- 結果
- 結果として
- 結果
- return
- リスク
- 職種
- ラン
- 実行
- 塩
- スケーラビリティ
- ド電源のデ
- 秤
- スケーリング
- シームレス
- シームレス
- 二番
- 秒
- セクション
- セクション
- 有価証券
- セキュリティ
- を求める
- select
- 選択
- シニア
- 別
- 仕える
- サービス
- セッションに
- 設定
- 表示する
- 作品
- 著しく
- 同様の
- 簡単な拡張で
- 簡略化されました
- スリッページ
- ソフトウェア
- ソフトウェア開発
- ソフトウェアエンジニア
- ソリューション
- 洗練された
- 緊張
- スパーク
- 特定の
- 広がる
- スプレッド
- スタンド
- ステップ
- ストレージ利用料
- 店舗
- 戦略的に
- 作戦
- 戦略
- 流線
- 勉強
- それに続きます
- そのような
- SWIFT
- シンボル
- 相乗効果
- 取る
- 取得
- チーム
- 技術的
- テクニック
- テクノロジー
- テスト
- より
- それ
- 情報
- アプリ環境に合わせて
- それら
- その後
- ボーマン
- この
- 介して
- ダニ
- 時間
- タイムリーな
- タイムスタンプ
- 役職
- 〜へ
- トータル
- tp
- TPR
- トレード
- トレーダー
- トレード
- トレーディング
- 取引戦略
- 取引戦略
- トランザクション
- 取引費用
- 変換
- 遷移
- 超
- 下
- 被災者
- アップグレード
- us
- 使用法
- つかいます
- 中古
- 使用されます
- 活用
- 値
- さまざまな
- 可視化
- 視覚化する
- ボラティリティ(変動性)
- ボリューム
- ボリューム
- ました
- we
- ウェブ
- Webサービス
- いつ
- which
- 広く
- 意志
- 以内
- 無し
- ワークグループ
- ワーキング
- 作品
- 不安
- X
- 年
- 貴社
- あなたの
- ゼファーネット