ポストで AWS ProServe Hadoop Migration Delivery Kit TCO ツールの紹介では、AWS ProServe Hadoop Migration Delivery Kit (HMDK) TCO ツールと、オンプレミスの Hadoop ワークロードを アマゾンEMR. この投稿では、ログの取り込み、変換、視覚化、アーキテクチャ設計から TCO を計算するまでのすべての手順を説明しながら、ツールを深く掘り下げます。
ソリューションの概要
HMDK TCO ツールの主な機能を簡単に見てみましょう。 このツールは、Hadoop Resource Manager に接続して YARN ログを収集するための YARN ログ コレクターを提供します。 YARN ログ アナライザーと呼ばれる Python ベースの Hadoop ワークロード アナライザーは、Hadoop アプリケーションを精査します。 アマゾンクイックサイト ダッシュボードには、アナライザーからの結果が表示されます。 同じ結果により、将来の EMR インスタンスの設計も加速します。 さらに、TCO 計算機は、移行を容易にするために最適化された EMR クラスターの TCO 見積もりを生成します。
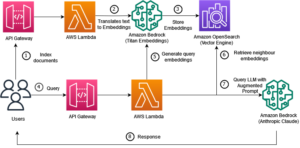
それでは、ツールがどのように機能するかを見てみましょう。 次の図は、エンド ツー エンドのワークフローを示しています。

次のセクションでは、ツールの XNUMX つの主な手順について説明します。
- YARN ジョブ履歴ログを収集します。
- ジョブ履歴ログを JSON から CSV に変換します。
- ジョブ履歴ログを分析します。
- 移行用の EMR クラスターを設計します。
- TCO を計算します。
前提条件
開始する前に、次の前提条件を満たしていることを確認してください。
- クローン hadoop-migration-assessment-tco リポジトリ.
- ローカル マシンに Python 3 をインストールします。
- アクセス許可のある AWS アカウントを持っている AWSラムダ、QuickSight (エンタープライズ版)、および AWS CloudFormation.
YARN ジョブ履歴ログを収集する
まず、実行します YARN ログコレクター、start-collector.sh、ローカル マシン上。 このステップでは、Hadoop YARN ログを収集し、ログをローカル マシンに配置します。 このスクリプトは、ローカル マシンを Hadoop プライマリ ノードに接続し、Resource Manager と通信します。 次に、YARN ResourceManager アプリケーション API を呼び出して、ジョブ履歴情報 (アプリケーション マネージャーからの YARN ログ) を取得します。
YARN ログ コレクターを実行する前に、接続 (HTTP: 8088 または HTTPS: 8090; 後者を推奨) を構成して確立し、YARN ResourceManager と有効な YARN Timeline Server (Timeline Server v1 以降がサポートされている) のアクセス可能性を確認する必要があります。 )。 YARN ログの収集間隔と保持ポリシーを定義する必要がある場合があります。 連続した YARN ログを確実に収集するには、cron ジョブを使用して、適切な時間間隔でログ コレクターをスケジュールします。 たとえば、毎日 2,000 個のアプリケーションがあり、yarn.resourcemanager.max-completed-applications が 1,000 に設定されている Hadoop クラスターの場合、理論的には、ログ コレクターを少なくとも 7 回実行して、すべての YARN ログを取得する必要があります。 さらに、全体的なワークロードを分析するために、少なくとも XNUMX 日間の YARN ログを収集することをお勧めします。
ログ コレクターの構成およびスケジュール方法の詳細については、 yarn-log-collector GitHub リポジトリ.
YARN ジョブ履歴ログを JSON から CSV に変換する
YARN ログを取得したら、YARN ログ オーガナイザである yarn-log-organizer.py を実行します。これは、JSON ベースのログを CSV ファイルに変換するパーサーです。 これらの出力 CSV ファイルは、YARN ログ アナライザーの入力です。 パーサーには、時間によるイベントの並べ替え、専用の削除、複数のログのマージなど、他の機能もあります。
YARN ログ オーガナイザーの使用方法の詳細については、 yarn-log-organizer GitHub リポジトリ.
YARN ジョブ履歴ログを分析する
次に、YARN ログ アナライザーを起動して、YARN ログを CSV 形式で分析します。
QuickSight を使用すると、YARN ログ データを視覚化し、事前に構築されたダッシュボード テンプレートとウィジェットによって生成されたデータセットに対して分析を実行できます。 ウィジェットは、CloudFormation テンプレートで設定されたターゲット AWS アカウントに QuickSight ダッシュボードを自動的に作成します。
次の図は、HMDK TCO アーキテクチャを示しています。

YARN ログ アナライザーは、次の XNUMX つの主要な機能を提供します。
- 変換された YARN ジョブ履歴ログを CSV 形式でアップロードします (たとえば、
cluster_yarn_logs_*.csv)へ Amazon シンプル ストレージ サービス (Amazon S3) バケット。 これらの CSV ファイルは、YARN ログ オーガナイザーからの出力です。 - マニフェスト JSON ファイルを作成します (たとえば、
yarn-log-manifest.json) を QuickSight 用に作成し、S3 バケットにアップロードします。 - YAML 形式の CloudFormation テンプレートを使用して、QuickSight ダッシュボードをデプロイします。 デプロイ後、スタックのステータスが次のように表示されるまで、更新アイコンを選択します。
CREATE_COMPLETE. このステップでは、AWS ターゲット アカウントの QuickSight ダッシュボードにデータセットを作成します。
- QuickSight ダッシュボードでは、分析された Hadoop ワークロードの洞察をさまざまなグラフから見つけることができます。 これらの洞察は、次のステップで示すように、移行を加速するための将来の EMR インスタンスを設計するのに役立ちます。

移行用の EMR クラスターを設計する
YARN ログ アナライザーの結果は、既存のシステムの実際の Hadoop ワークロードを理解するのに役立ちます。 このステップは、 Excelテンプレート. テンプレートには、ワークロード分析とキャパシティ プランニングを実施するためのチェックリストが含まれています。
- クラスターで実行されているアプリケーションは、現在の容量で適切に使用されていますか?
- 特定の時間にクラスターに負荷がかかっているかどうか。 もしそうなら、いつですか?
- クラスターで実行されているアプリケーションとエンジン (MR、TEZ、Spark など) の種類と、各種類のリソース使用量は?
- 異なるジョブの実行サイクル (リアルタイム、バッチ、アドホック) が XNUMX つのクラスターで実行されていますか?
- 定期的なバッチで実行されているジョブはありますか? その場合、これらのスケジュール間隔はどのくらいですか? (例: 10 分ごと、1 時間ごと、1 日ごと) 長時間にわたって多くのリソースを使用するジョブはありませんか?
- パフォーマンスの改善が必要なジョブはありますか?
- クラスターを独占している特定の組織または個人はいますか?
- XNUMX つのクラスター内で開発と運用が混在するジョブはありますか?
チェックリストを完了すると、将来のアーキテクチャを設計する方法をよりよく理解できるようになります。 EMR クラスターの費用対効果を最適化するために、次の表は適切なタイプの EMR クラスターを選択するための一般的なガイドラインを示しています。 アマゾン エラスティック コンピューティング クラウド (Amazon EC2) ファミリー。

適切なクラスター タイプとインスタンス ファミリーを選択するには、さまざまな基準に基づいて YARN ログに対して数回の分析を実行する必要があります。 いくつかの重要な指標を見てみましょう。
タイムライン
時間枠内で実行される Hadoop アプリケーションの数に基づいて、ワークロード パターンを見つけることができます。 たとえば、日別または時間別のチャート「Count of Records by Startedtime」は、次の洞察を提供します。
- 日次時系列グラフでは、稼働日と休日の間、および暦日間のアプリケーション実行数を比較します。 数値が類似している場合は、クラスターの XNUMX 日あたりの使用率が同等であることを意味します。 一方、偏差が大きい場合は、アドホック ジョブの割合が大きくなります。 また、特定の日に可能な週次または月次のジョブを把握することもできます。 このような状況では、ワークロードが集中している週または月の特定の日を簡単に確認できます。
- 時間単位の時系列グラフでは、時間単位のウィンドウでアプリケーションがどのように実行されるかをさらに理解できます。 XNUMX 日のピーク時間とオフピーク時間を見つけることができます。
ユーザー
YARN ログには、各アプリケーションのユーザー ID が含まれています。 この情報は、誰がアプリケーションをキューに送信したかを理解するのに役立ちます。 キューごとおよびユーザーごとの個別および集約されたアプリケーション実行の統計に基づいて、ユーザーごとの既存のワークロード分散を判断できます。 通常、同じチームのユーザーはキューを共有しています。 複数のチームがキューを共有している場合があります。 ユーザーのキューを設計するときに、以前よりもキュー間でよりバランスの取れたアプリケーション ワークロードを設計および分散するのに役立つ洞察が得られます。
アプリケーションの種類
さまざまなアプリケーション タイプ (Hive、Spark、Presto、HBase など) に基づいてワークロードをセグメント化し、エンジン (MR、Spark、Tez など) を実行できます。 MapReduce や Hive-on-MR ジョブなどのコンピューティング負荷の高いワークロードには、CPU 最適化インスタンスを使用します。 Hive-on-TEZ、Presto、Spark ジョブなどのメモリ集約型ワークロードの場合は、メモリ最適化インスタンスを使用します。
経過時間
アプリケーションをランタイム別に分類できます。 埋め込まれた CloudFormation テンプレートは、QuickSight ダッシュボードに経過グループ フィールドを自動的に作成します。 これにより、QuickSight ダッシュボードの XNUMX つのグラフのいずれかで長時間実行ジョブを観察できる重要な機能が有効になります。 したがって、これらの大規模なジョブに合わせた将来のアーキテクチャを設計できます。
対応する QuickSight ダッシュボードには XNUMX つのグラフが含まれています。 XNUMX つのグループに関連付けられている各グラフをドリルダウンできます。
| グループ 数 |
ジョブの実行時間/経過時間 |
| 1 | 10分未満 |
| 2 | 10分から30分の間 |
| 3 | 30分から1時間の間 |
| 4 | 1時間以上 |
グループ 4 のグラフでは、ユーザー、キュー、アプリケーションの種類、タイムライン、リソースの使用状況など、さまざまなメトリックに基づいて大規模なジョブを精査することに集中できます。 この考慮事項に基づいて、クラスターまたは大規模なジョブ専用の EMR クラスターに専用のキューを設定できます。 その間、小さなジョブを共有キューに送信できます。
リソース
リソース (CPU、メモリ) の消費パターンに基づいて、パフォーマンスと費用対効果のために EC2 インスタンスの適切なサイズとファミリーを選択します。 計算負荷の高いアプリケーションについては、CPU 最適化ファミリーのインスタンスをお勧めします。 メモリを集中的に使用するアプリケーションの場合は、メモリ最適化インスタンス ファミリーをお勧めします。
さらに、アプリケーションのワークロードの性質と経時的なリソース使用率に基づいて、永続的または一時的な EMR クラスターを選択できます。 EKS上のAmazonEMRまたは Amazon EMR サーバーレス.
YARN ログをさまざまなメトリクスで分析したら、将来の EMR アーキテクチャを設計する準備が整います。 次の表に、提案されている EMR クラスターの例を示します。 詳細については、 optimized-tco-calculator GitHub リポジトリ.

TCO の計算
最後に、ローカル マシンで tco-input-generator.py を実行して YARN ジョブ履歴ログを XNUMX 時間ごとに集計してから、Excel テンプレートを使用して最適化された TCO を計算します。 結果は将来の EMR インスタンスの Hadoop ワークロードをシミュレートするため、このステップは非常に重要です。
TCO シミュレーションの前提条件は、実行することです。 tco-input-generator.py、2 時間ごとに集計されたログを生成します。 次に、Excel テンプレート ファイルを開いてマクロを有効にし、TCO を計算するために緑色のセルに入力を提供します。 入力データについては、レプリケーションなしの実際のデータ サイズと、Hadoop のプライマリ ノードとデータ ノードのハードウェア仕様 (vCore、mem) を入力します。 また、以前に生成された時間ごとの集計ログを選択してアップロードする必要があります。 リージョン、EC2 タイプ、Amazon EMR 高可用性、エンジン効果、Amazon EC3 および Amazon EBS 割引 (EDP)、Amazon S2 ボリューム割引、現地通貨レート、EMR EC2 タスク/コア料金比率などの TCO シミュレーション変数を設定した後TCO シミュレーターは、Amazon ECXNUMX の将来の EMR インスタンスの最適なコストを自動的に計算します。 次のスクリーンショットは、HMDK TCO の結果の例を示しています。

HMDK TCO 計算の追加情報と手順については、 optimized-tco-calculator GitHub リポジトリ.
クリーンアップ
すべての手順を完了してテストを終了したら、次の手順を実行してリソースを削除し、コストが発生しないようにします。
- AWS CloudFormation コンソールで、作成したスタックを選択します。
- 選択する 削除.
- 選択する スタックを削除.
- ステータスが表示されるまでページを更新します
DELETE_COMPLETE. - Amazon S3 コンソールで、作成した S3 バケットを削除します。
まとめ
AWS ProServe HMDK TCO ツールは、Hadoop ワークロードを評価するための時間のかかる困難なタスクである移行計画の作業を大幅に削減します。 HMDK TCO ツールを使用した場合、評価には通常 2 ~ 3 週間かかります。 また、将来の EMR アーキテクチャの計算された TCO を決定することもできます。 HMDK TCO ツールを使用すると、ワークロードとリソースの使用パターンをすばやく理解できます。 ツールによって生成された洞察により、最適な将来の EMR アーキテクチャを設計する準備が整います。 多くのユースケースでは、最適化されたリファクタリングされたアーキテクチャの 1 年間の TCO は、リフトアンドシフトの Hadoop 移行と比較して、コンピューティングとストレージの大幅なコスト削減 (64 ~ 80% の削減) を提供します。
Hadoop の Amazon EMR および HMDK CTO ツールへの移行を加速する方法の詳細については、 Hadoop 移行デリバリー キット TCO GitHub リポジトリ、または連絡先 AWS-HMDK@amazon.com.
著者について
 ソンギョル公園 AWS ProServe のシニア プラクティス マネージャーです。 彼は、AWS アナリティクス、IoT、および AI/ML サービスを使用して顧客がビジネスを革新するのを支援しています。 彼はビッグデータ サービスとテクノロジを専門とし、顧客のビジネス成果を一緒に構築することに関心を持っています。
ソンギョル公園 AWS ProServe のシニア プラクティス マネージャーです。 彼は、AWS アナリティクス、IoT、および AI/ML サービスを使用して顧客がビジネスを革新するのを支援しています。 彼はビッグデータ サービスとテクノロジを専門とし、顧客のビジネス成果を一緒に構築することに関心を持っています。
 キム・ジソン AWS ProServe のシニア データ アーキテクトです。 彼は主に企業顧客と協力してデータ レイクの移行とモダナイゼーションを支援し、Hadoop、Spark、データ ウェアハウジング、リアルタイム データ処理、大規模な機械学習などのビッグ データ プロジェクトに関するガイダンスと技術支援を提供しています。 また、テクノロジーを適用してビッグデータの問題を解決し、適切に設計されたデータ アーキテクチャを構築する方法も理解しています。
キム・ジソン AWS ProServe のシニア データ アーキテクトです。 彼は主に企業顧客と協力してデータ レイクの移行とモダナイゼーションを支援し、Hadoop、Spark、データ ウェアハウジング、リアルタイム データ処理、大規模な機械学習などのビッグ データ プロジェクトに関するガイダンスと技術支援を提供しています。 また、テクノロジーを適用してビッグデータの問題を解決し、適切に設計されたデータ アーキテクチャを構築する方法も理解しています。
 ジョージ・チャオ AWS ProServe のシニア データ アーキテクトです。 彼は、AWS のお客様と協力して最新のデータ ソリューションを提供する経験豊富な分析リーダーです。 彼は ProServe Amazon EMR ドメインスペシャリストでもあり、Hadoop から Amazon EMR への移行のベストプラクティスと配信キットについて ProServe コンサルタントをサポートしています。 彼の関心分野は、データ レイクとクラウドの最新データ アーキテクチャ配信です。
ジョージ・チャオ AWS ProServe のシニア データ アーキテクトです。 彼は、AWS のお客様と協力して最新のデータ ソリューションを提供する経験豊富な分析リーダーです。 彼は ProServe Amazon EMR ドメインスペシャリストでもあり、Hadoop から Amazon EMR への移行のベストプラクティスと配信キットについて ProServe コンサルタントをサポートしています。 彼の関心分野は、データ レイクとクラウドの最新データ アーキテクチャ配信です。
 カレン・チャン AWS のパートナー データおよび分析のグローバル セグメント テック リードでした。 データと分析の信頼できるアドバイザーとして、彼女はデータ変換のための戦略的イニシアチブをキュレートし、データと分析のワークロードの移行とモダナイゼーション プログラムを主導し、大規模なパートナーとの顧客移行プロセスを加速しました。 彼女は、分散システム、エンタープライズ データ管理、高度な分析、および大規模な戦略的イニシアチブを専門としています。
カレン・チャン AWS のパートナー データおよび分析のグローバル セグメント テック リードでした。 データと分析の信頼できるアドバイザーとして、彼女はデータ変換のための戦略的イニシアチブをキュレートし、データと分析のワークロードの移行とモダナイゼーション プログラムを主導し、大規模なパートナーとの顧客移行プロセスを加速しました。 彼女は、分散システム、エンタープライズ データ管理、高度な分析、および大規模な戦略的イニシアチブを専門としています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/deep-dive-into-the-aws-proserve-hadoop-migration-delivery-kit-tco-tool/
- 000
- 1
- 10
- 100
- 7
- a
- できる
- 私たちについて
- 加速する
- 加速された
- 加速する
- 加速している
- 加速
- 接近性
- 越えて
- Ad
- 添加
- NEW
- 追加情報
- さらに
- 高度な
- 顧問
- 後
- に対して
- AI / ML
- すべて
- Amazon
- Amazon EC2
- アマゾンEMR
- 間で
- 分析
- 分析論
- 分析します
- 分析する
- および
- API
- 申し込み
- 申し込む
- 適切に
- 建築
- AREA
- 評価
- 援助
- 関連する
- 自動的に
- 賃貸条件の詳細・契約費用のお見積り等について
- AWS
- AWS CloudFormation
- ベース
- 基礎
- なぜなら
- さ
- 利点
- BEST
- ベストプラクティス
- より良いです
- の間に
- ビッグ
- ビッグデータ
- 簡潔に
- ビルド
- 建物
- ビジネス
- 計算する
- 計算された
- 計算する
- 計算
- カレンダー
- 呼ばれます
- 呼び出し
- 機能
- 容量
- 例
- 細胞
- 一定
- 挑戦
- チャート
- チャート
- 選択する
- 選択する
- クラウド
- クラスタ
- 収集する
- 収集
- コレクション
- コレクタ
- 集める
- COM
- 匹敵します
- 比較します
- 比べ
- コンプリート
- 計算
- 濃度
- プロフェッショナルな方法で
- 導電性
- お問合せ
- 接続
- コネクト
- 連続した
- 考慮
- 領事
- コンサルタント
- 消費
- 含まれています
- 対応する
- 費用
- コスト削減
- コスト
- CPU
- 作成した
- 作成します。
- 基準
- 重大な
- CTO
- キュレーション
- 通貨
- 電流プローブ
- 顧客
- Customers
- サイクル
- daily
- ダッシュボード
- データ
- データレイク
- データ管理
- データ処理
- データセット
- 中
- 日
- 専用の
- 深いです
- ディープダイブ
- 配信する
- 配達
- 実証
- 展開する
- 設計
- 設計
- 細部
- 決定する
- 開発
- 偏差
- 異なります
- お得な商品
- 分配します
- 配布
- 分散システム
- ディストリビューション
- ドメイン
- ダウン
- 間に
- 各
- 簡単に
- EBS
- エディション
- 効果
- 有効
- 努力
- 埋め込まれた
- enable
- 使用可能
- 可能
- 端から端まで
- エンジン
- エンジン
- 確保
- 入力します
- Enterprise
- 企業顧客
- 装備
- 確立する
- エーテル(ETH)
- イベント
- あらゆる
- 例
- 例
- Excel
- 既存の
- 経験豊かな
- 容易化する
- 家族
- 家族
- 特徴
- 特徴
- フィールド
- フィギュア
- File
- もう完成させ、ワークスペースに掲示しましたか?
- 仕上げ
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- から
- 機能性
- さらに
- 未来
- 生成された
- 生成
- 取得する
- 受け
- GitHubの
- グローバル
- グリーン
- グループ
- ガイドライン
- Hadoopの
- Hardware
- 助けます
- ことができます
- ハイ
- history
- ハイブ
- 休日
- 包括的な
- HOURS
- 認定条件
- How To
- HTML
- HTTPS
- ICON
- 改善
- in
- include
- 含めて
- 個人
- 個人
- 情報
- イニシアチブ
- 革新します
- 洞察
- 説明書
- 関心
- 利益
- 導入
- IOT
- IT
- ジョブ
- Jobs > Create New Job
- 旅
- JSON
- キー
- キット
- 湖
- 大
- 大規模
- 起動する
- つながる
- リーダー
- LEARN
- 学習
- ツェッペリン
- 導かれたデータ
- リスト
- 負荷
- ローカル
- 長い
- 長い時間
- 見て
- たくさん
- 機械
- 機械学習
- マクロ
- メイン
- make
- 管理
- マネージャー
- マネージャー
- 多くの
- 手段
- その間
- メモリ
- マージ
- メトリック
- 移行
- 分
- 混合
- モダン
- 近代化
- 月
- monthly
- 他には?
- の試合に
- 自然
- 必要
- 次の
- ノード
- 数
- 番号
- 観察する
- 入手
- ONE
- 開いた
- オペレーティング
- 操作
- 最適な
- 最適化
- 最適化
- 最適な
- 組織
- その他
- 特定の
- パートナー
- パートナー
- パターン
- ピーク
- 実行する
- パフォーマンス
- 期間
- 許可
- 場所
- 計画
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 方針
- 可能
- ポスト
- 練習
- プラクティス
- 前提条件
- 前に
- 価格設定
- 主要な
- 事前の
- 問題
- 処理
- プログラム
- プロジェクト(実績作品)
- 適切な
- 提案された
- 提供します
- は、大阪で
- Python
- すぐに
- レート
- 比
- リーチ
- 準備
- への
- リアルタイムデータ
- 推奨する
- 推奨される
- 記録
- 軽減
- に対する
- 地域
- レギュラー
- 除去
- レプリケーション
- リソースを追加する。
- リソース
- 結果
- 保持
- ラウンド
- ラン
- ランニング
- 同じ
- 貯蓄
- 規模
- スケジュール
- スクリーンショット
- セクション
- セグメント
- シニア
- シリーズ
- サービス
- セッションに
- 設定
- いくつかの
- shared
- 表示する
- ショーケース
- 重要
- 著しく
- 同様の
- 簡単な拡張で
- シミュレータ
- 状況
- サイズ
- 小さい
- So
- ソリューション
- 解決する
- 一部
- スパーク
- 専門家
- 専門にする
- 専門
- 特定の
- 仕様
- スタック
- 開始
- 統計
- Status:
- 手順
- ステップ
- ストレージ利用料
- 戦略的
- 提出する
- そのような
- サポート
- システム
- テーブル
- テーラード
- 取り
- ターゲット
- タスク
- チーム
- チーム
- テク
- 技術的
- テクノロジー
- template
- テンプレート
- テスト
- 未来
- アプリ環境に合わせて
- したがって、
- 介して
- 時間
- 時系列
- 時間がかかる
- タイムライン
- 〜へ
- 一緒に
- ツール
- 最適化の適用
- 変換
- 変換
- true
- 信頼されている
- 下
- わかる
- 理解する
- 理解する
- 使用法
- つかいます
- ユーザー
- users
- 通常
- さまざまな
- 確認する
- 可視化
- ボリューム
- ウォーキング
- 倉庫保管
- 週間
- weekly
- ウィークス
- この試験は
- 何ですか
- which
- 誰
- ウィンドウズ
- 無し
- ワークフロー
- ワーキング
- 作品
- ヤムル
- あなたの
- ゼファーネット