AWS グルースタジオ と統合されました AWS グルー DataBrew。 AWS Glue Studio は、抽出、変換、ロード (ETL) ジョブの作成、実行、監視を簡単にするグラフィカル インターフェイスです。 AWSグルー。 DataBrew は、コードを書かずにデータをクリーンアップおよび正規化できる視覚的なデータ準備ツールです。 提供される 200 を超える変換は、AWS Glue Studio ビジュアルジョブで使用できるようになりました。
DataBrewでは、 レシピ は、直感的なビジュアル インターフェイスで対話的に作成できる一連のデータ変換ステップです。 この投稿では、DataBrew でレシピをビルドし、それを AWS Glue Studio ビジュアル ETL ジョブの一部として適用する方法を説明します。
既存の DataBrew ユーザーもこの統合の恩恵を受けることができます。高度なジョブ設定と最新の AWS Glue エンジン バージョンを使用できることに加えて、AWS Glue Studio が提供する他のすべてのコンポーネントを使用して、より大規模なビジュアル ワークフローの一部としてレシピを実行できるようになります。 。
この統合により、両方のツールの既存ユーザーに明確なメリットがもたらされます。
- AWS Glue Studio では、全体的な ETL ダイアグラムをエンドツーエンドで一元的に表示できます。
- DataBrew コンソールで値、統計、分布を確認しながらレシピをインタラクティブに定義し、テストおよびバージョン管理された処理ロジックを AWS Glue Studio ビジュアル ジョブで再利用できます。
- AWS Glue ETL ジョブで複数の DataBrew レシピをオーケストレーションしたり、AWS Glue ワークフローを使用して複数のジョブをオーケストレートしたりできます。
- DataBrew レシピでは、増分データ処理のためのブックマーク、自動再試行、自動スケール、小さなファイルのグループ化などの AWS Glue ジョブ機能を使用して効率を向上できるようになりました。
ソリューションの概要
この架空の使用例では、この投稿用に作成された合成医療請求データセットをクリーンアップすることが要件となります。これには、データ準備における DataBrew の機能を実証するために意図的にいくつかのデータ品質の問題が導入されています。 次に、別のソースから取得した、対応する医療提供者に関する関連詳細を追加した後、請求データがカタログに取り込まれます (アナリストが閲覧できるようになります)。
このソリューションは、それぞれクレームとプロバイダーを含む XNUMX つの CSV ファイルを読み取る AWS Glue Studio ビジュアル ジョブで構成されます。 このジョブは、最初のレシピを適用して品質問題に対処し、XNUMX 番目のレシピから列を選択し、両方のデータセットを結合して、最後に結果を保存します。 Amazon シンプル ストレージ サービス (Amazon S3)、出力データを次のような他のツールで使用できるようにカタログ上にテーブルを作成します。 アマゾンアテナ.
DataBrew レシピを作成する
まず、クレーム ファイルのデータ ストアを登録します。 これにより、実際のデータを使用して対話型エディターでレシピを構築できるようになり、変換を定義する際にその結果を評価できるようになります。
- 次のリンクを使用して、クレーム CSV ファイルをダウンロードします。 alabama_claims_data_Jun2023.csv.
- DataBrew コンソールで、 データセット ナビゲーションペインで、を選択します 新しいデータセットを接続.
- オプションを選択してください ファイルアップロード.
- データセット名、 入る
Alabama claims. - アップロードするファイルを選択してください, コンピューターにダウンロードしたファイルを選択します。
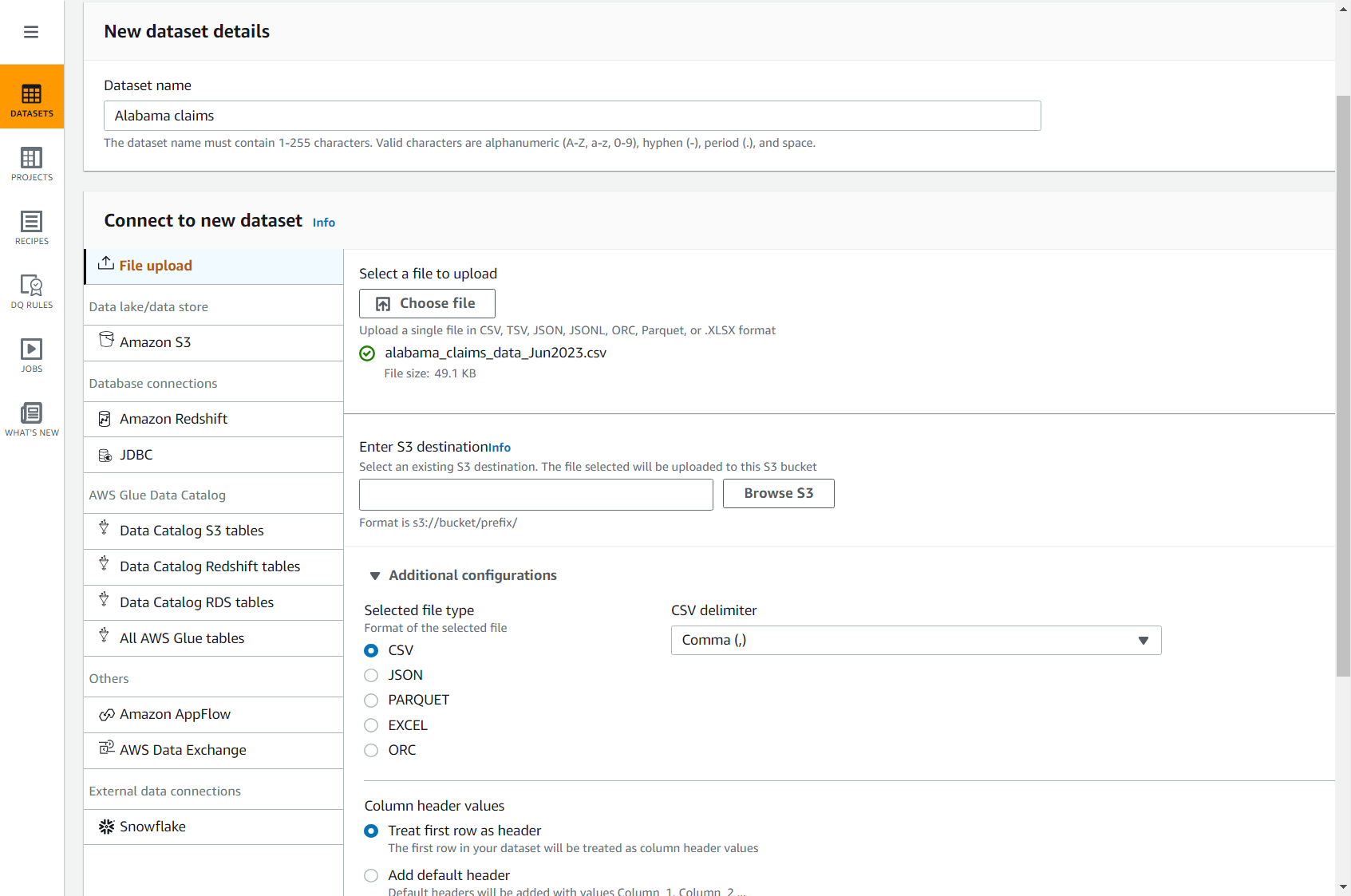
- S3の宛先を入力してください、アカウントとリージョンのバケットを入力または参照します。
- 残りのオプションはデフォルトのままにし (CSV はカンマとヘッダーで区切られます)、データセットの作成を完了します。
- 選択する プロジェクト ナビゲーションペインで、を選択します プロジェクトを作成する.
- プロジェクト名、 それに名前を付けます
ClaimsCleanup. - レシピの詳細、用 添付レシピ、選択する 新しいレシピを作成する、 それに名前を付けます
ClaimsCleanup-recipe、およびAlabama claims作成したばかりのデータセット。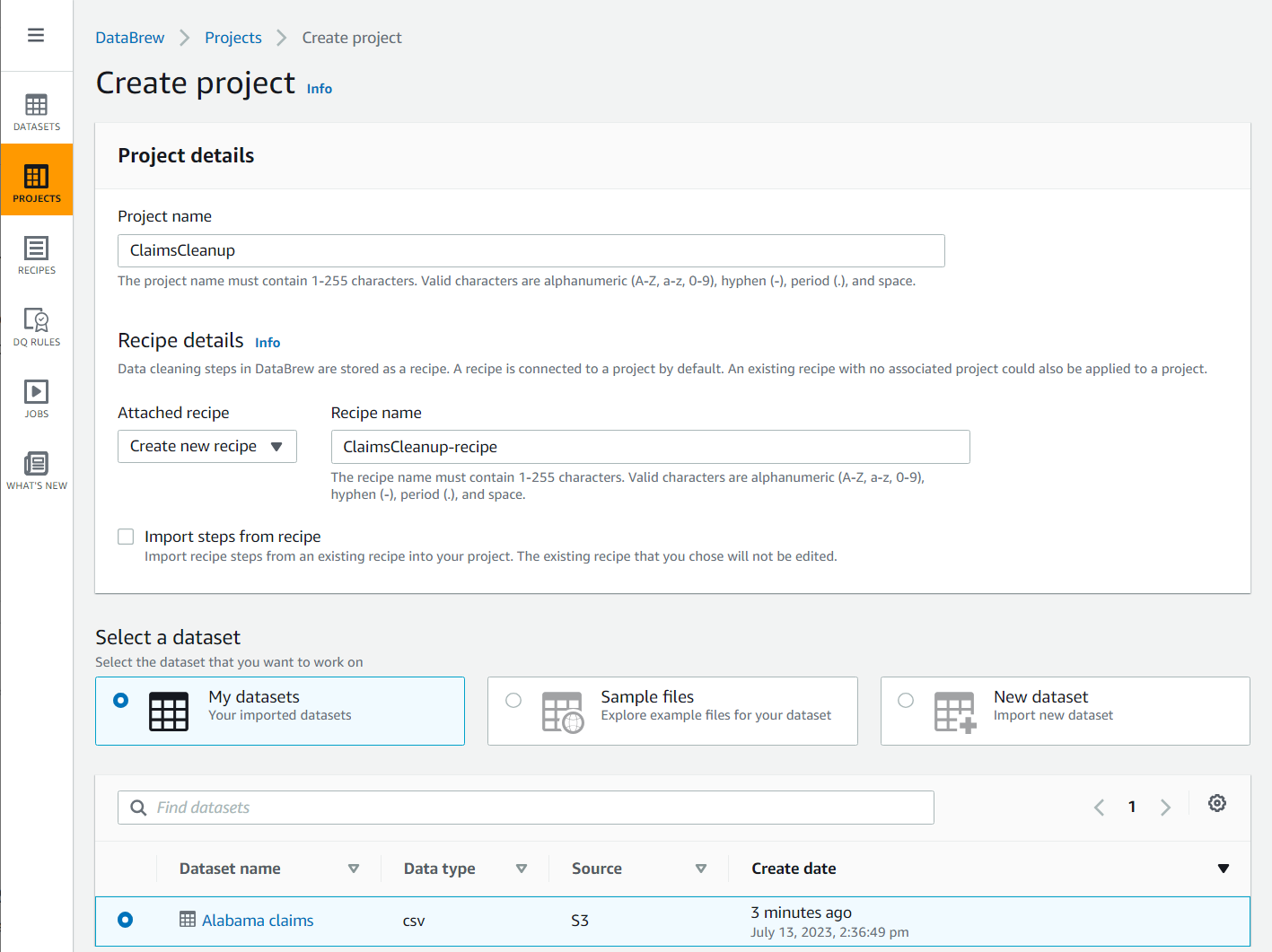
- ドロップダウンリストから DataBrew に適した役割 または新しいものを作成し、プロジェクトの作成を完了します。
これにより、構成可能なデータのサブセットを使用してセッションが作成されます。 セッションが初期化されると、一部のセルに無効な値または欠落した値が含まれていることがわかります。
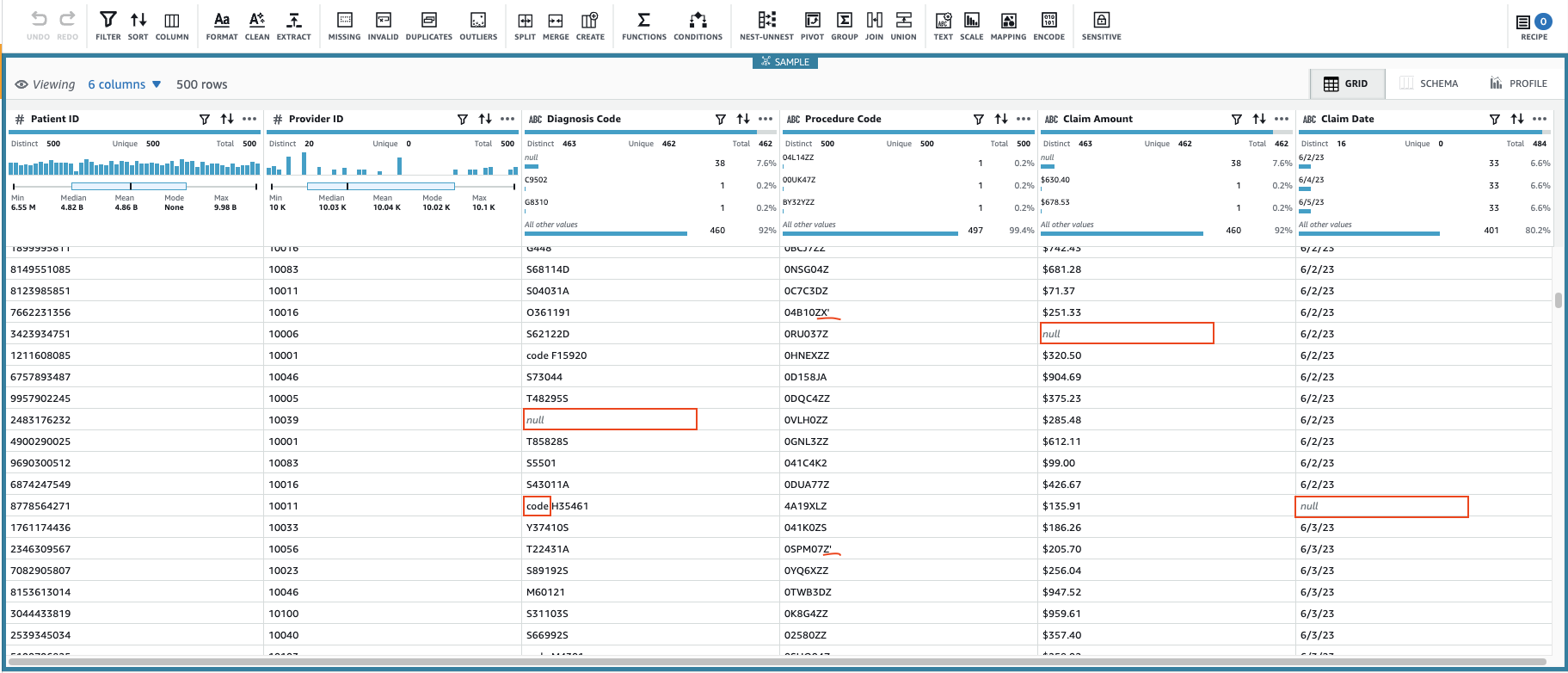
列の欠損値に加えて、 診断コード, 請求額, 請求日、データ内の一部の値には余分な文字が含まれています。 診断コード 値には「code」(スペースを含む)という接頭辞が付く場合があります。 手続きコード 値の後に一重引用符が続く場合があります。
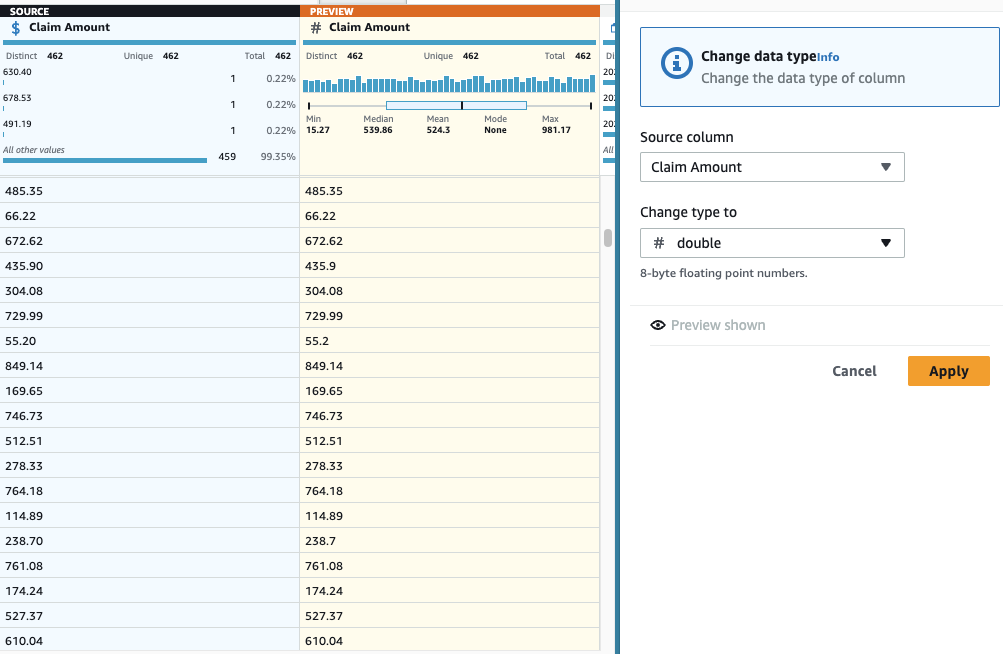
請求額 値は何らかの計算に使用される可能性があるため、数値に変換し、 請求データ 日付型に変換する必要があります。
対処すべきデータ品質の問題を特定したので、各ケースにどのように対処するかを決定する必要があります。
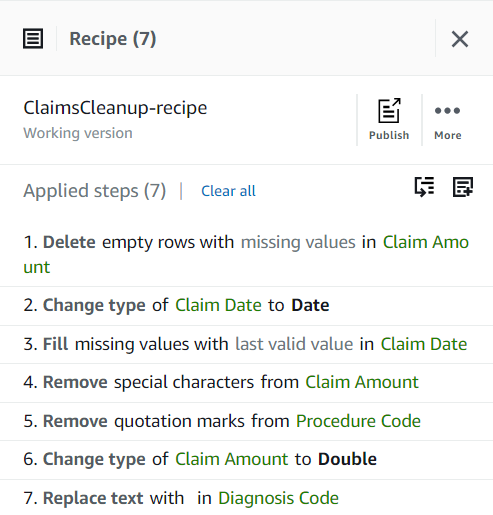
レシピ ステップを追加するには、列のコンテキスト メニュー、上部のツールバー、またはレシピの概要からの使用など、複数の方法があります。 最後の方法を使用すると、指定されたステップ タイプを検索して、この投稿で作成したレシピを複製できます。
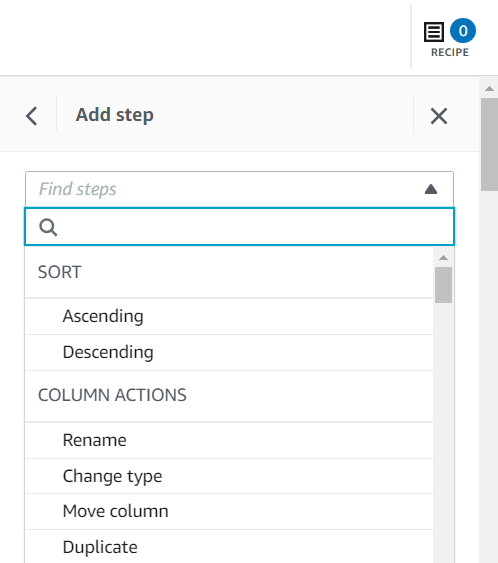
請求額 はこのユースケースには不可欠であるため、そのような行を削除することが決定されます。
- ステップを追加する 欠損値を削除する.
- ソース列、選択する 請求額.
- デフォルトのアクションをそのままにしておきます 欠損値のある行を削除する 選択して 申し込む それを保存します。
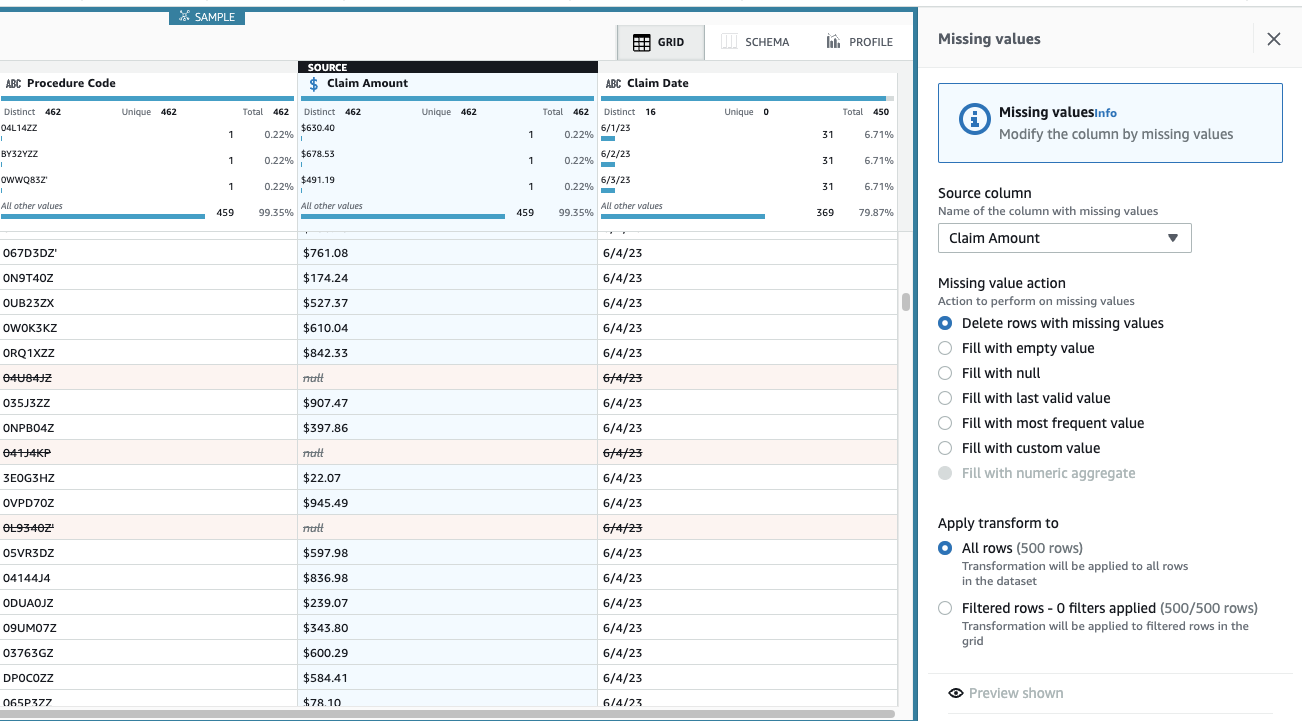
ステップの適用を反映するようにビューが更新され、金額が不足している行はなくなりました。
診断コード 空にすることもできるのでこれは受け入れられますが、 請求日、合理的な見積もりが必要です。 データ内の行は時系列で並べ替えられるため、前の行のプレビューの有効な値を使用して、欠落している日付を代入できます。 毎日に請求があると仮定すると、最大のエラーは、その日の日付が欠落している最初の請求である場合に、それをプレビュー日に割り当てることです。 説明のために、潜在的なエラーは許容できると考えてみましょう。
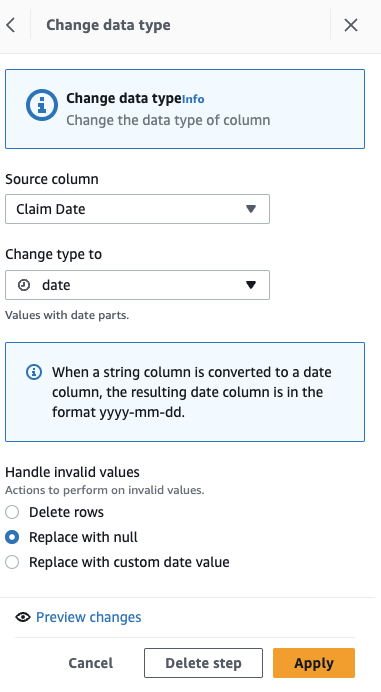
まず、列を文字列型から日付型に変換します。
- ステップを追加する タイプを変更する.
- 選択する 請求日 コラムとして、そして date タイプとして選択します 申し込む.
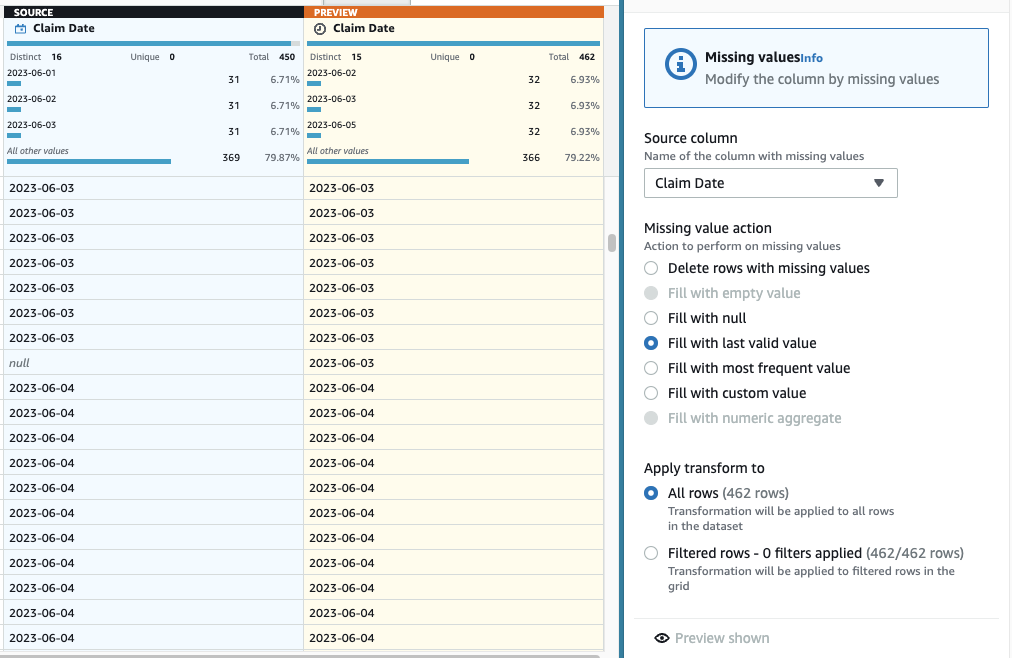
- 次に、欠落している日付の代入を行うために、次のステップを追加します。 欠損値を埋めるか代入する.
- アクションとして「最後の有効な値で埋める」を選択し、 請求日 ソースとして。
- 選択する プレビューの変更 検証してから選択します 申し込む ステップを保存します。
次のスクリーンショットに示すように、ここまでのレシピには XNUMX つのステップがあるはずです。
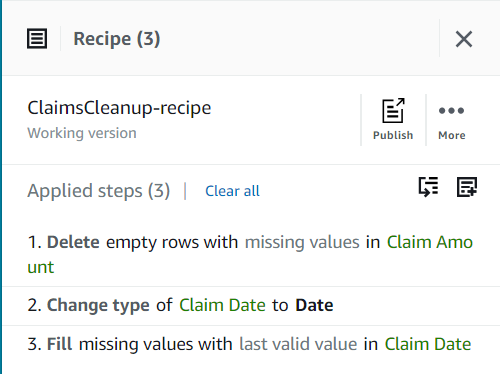
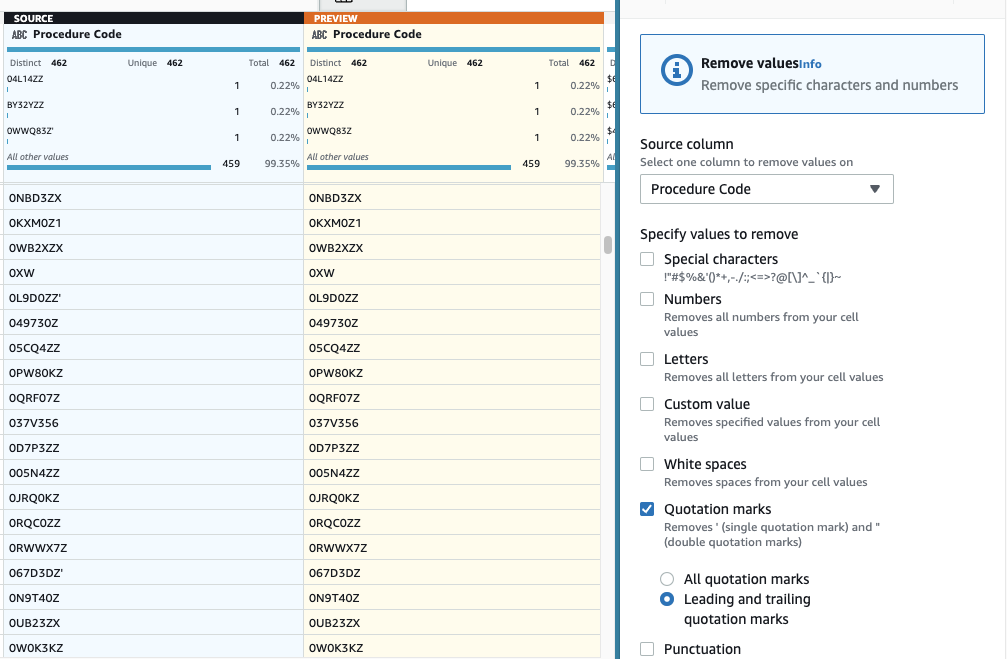
- 次にステップを追加します 引用符を削除する.
- 選択する 手続きコード 列を選択して 先頭と末尾の引用符.
- プレビューして目的の効果があることを確認し、新しいステップを適用します。
- ステップを追加する 特殊文字を削除する.
- 選択する 請求額 列を選択し、より具体的には、 カスタム特殊文字 入力してください
$for カスタム特殊文字を入力してください.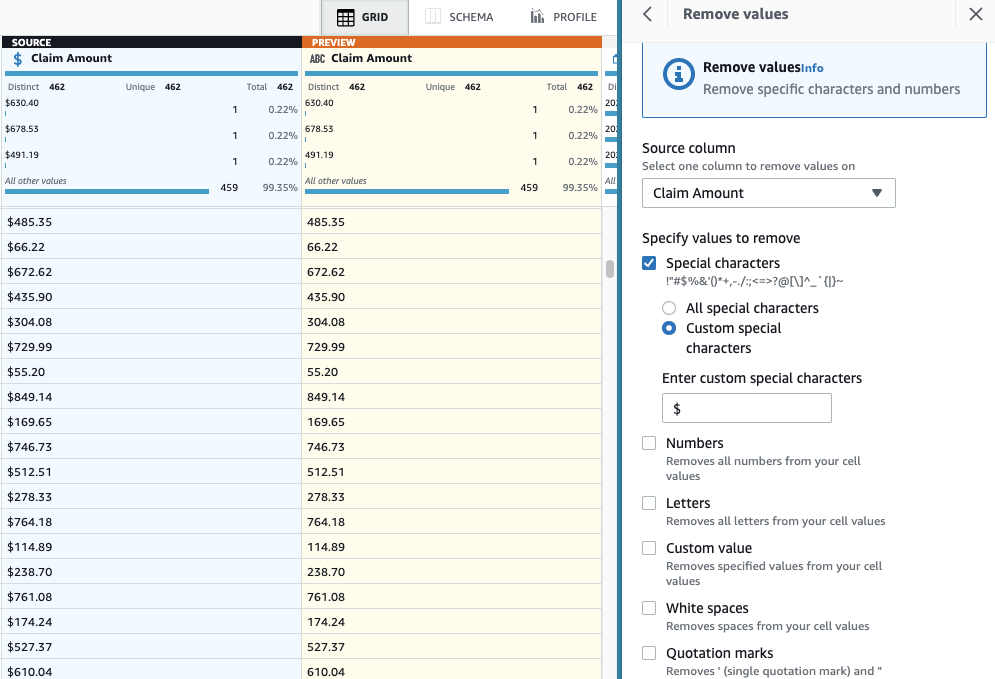
- 加える タイプを変更する 柱を踏む 請求額 選択して タイプとしては。
- 最後のステップとして、余分な「code」プレフィックスを削除するには、 値またはパターンを置換する ステップ。
- 列を選択してください 診断コード、および用 カスタム値を入力してください、 入る
code(末尾にスペースを入れます)。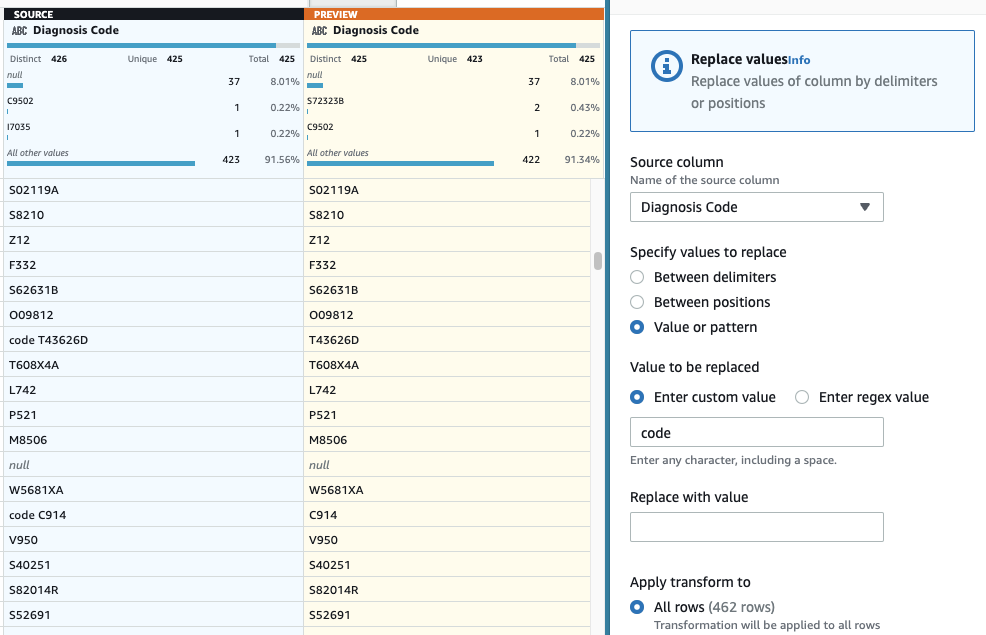
サンプルで特定されたすべてのデータ品質の問題に対処したので、プロジェクトをレシピとして公開します。
- 選択する パブリッシュ セクションに 抽出水のレシピ ペインにオプションの説明を入力し、公開を完了します。
公開するたびに、異なるバージョンのレシピが作成されます。 後で、使用するレシピのバージョンを選択できるようになります。
AWS Glue Studio でビジュアル ETL ジョブを作成する
次に、レシピを使用するジョブを作成します。 次の手順を実行します。
- AWS Glue Studioコンソールで、 ビジュアルETL ナビゲーションペインに表示されます。
- 選択する 真っ白なキャンバスを使ったビジュアル そしてビジュアルジョブを作成します。
- ジョブの先頭にある「無題のジョブ」を任意の名前に置き換えます。
- ソフトウェア設定ページで、下図のように ジョブの詳細 タブで、ジョブが使用するロールを指定します。
これは AWS IDおよびアクセス管理 (わたし) AWS Glue に適したロール Amazon S3 および AWS Glue データカタログへのアクセス許可を持ちます。 以前に DataBrew に使用されていたロールはジョブの実行には使用できないため、 IAMの役割 ここのドロップダウンメニュー。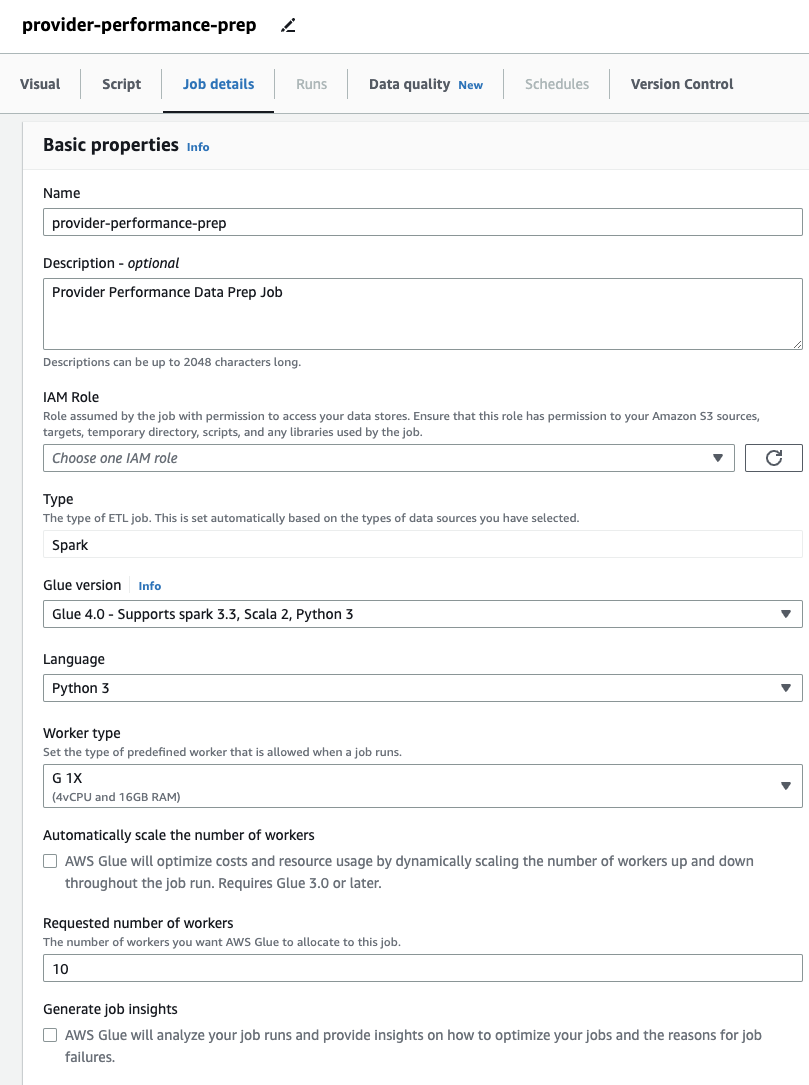
以前に DataBrew ジョブのみを使用したことがある場合は、AWS Glue Studio では、ワーカー サイズ、自動スケーリング、および 柔軟な実行だけでなく、最新の AWS Glue 4.0 ランタイムを使用すると、それによってもたらされる大幅なパフォーマンスの向上の恩恵を受けることができます。 このジョブでは、デフォルト設定を使用できますが、節約のために要求されるワーカーの数を減らします。 この例では、XNUMX 人のワーカーで十分です。 - ソフトウェア設定ページで、下図のように ビジュアル タブで、S3 ソースを追加し、名前を付けます
Providers. - S3 URL、 入る
s3://awsglue-datasets/examples/medicare/Medicare_Hospital_Provider.csv.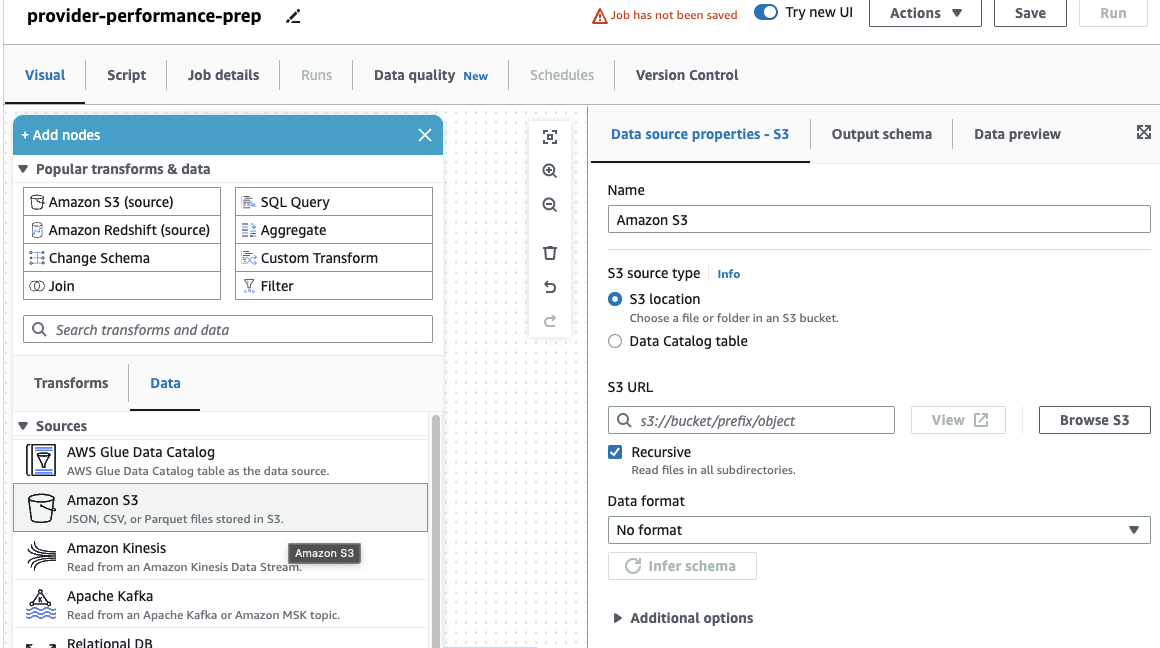
- 次のように形式を選択します CSV 選択して スキーマを推測する.
これで、スキーマが 出力スキーマ ファイルヘッダーを使用したタブ。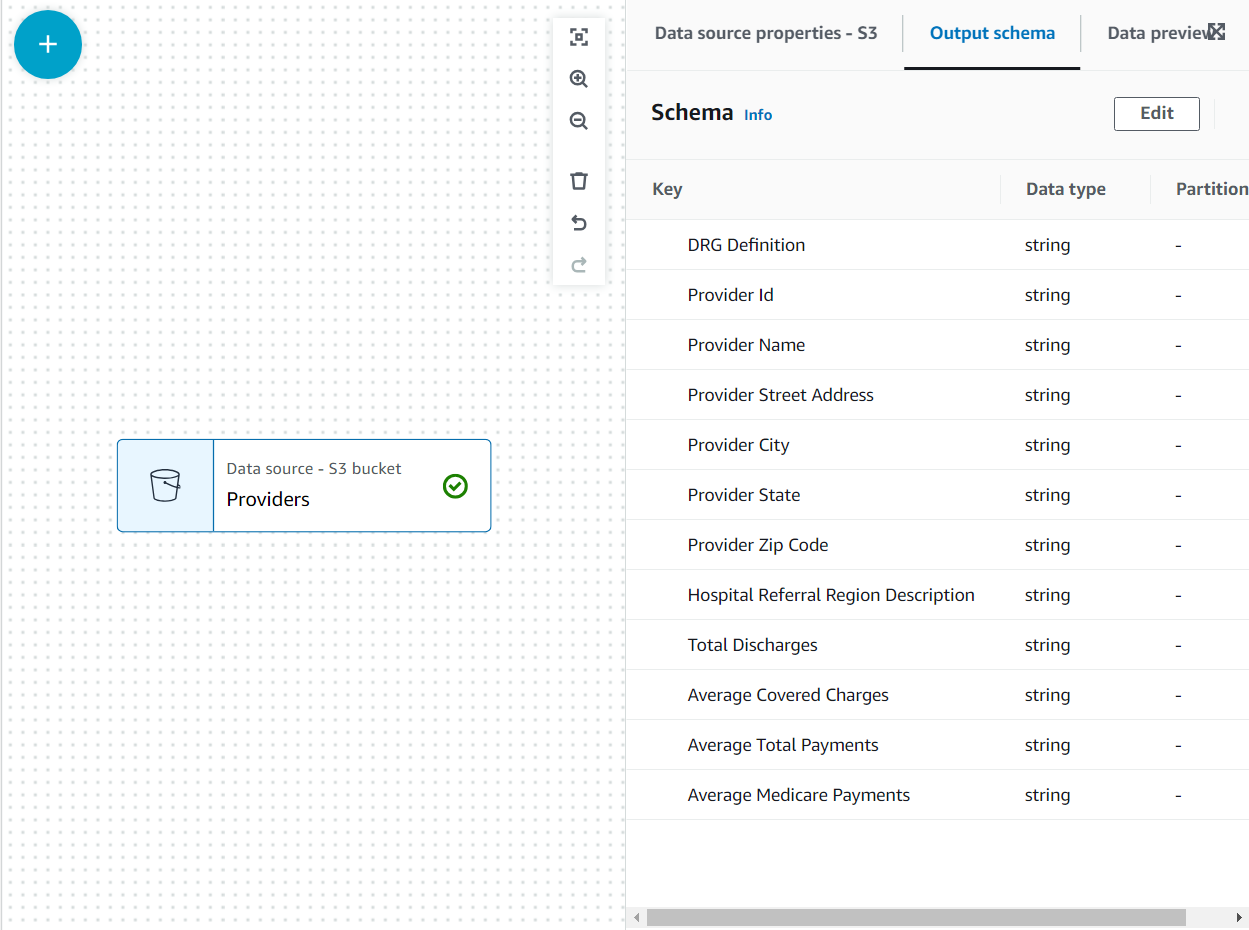
この使用例では、プロバイダー データセット内のすべての列が必要なわけではないため、残りは破棄できます。
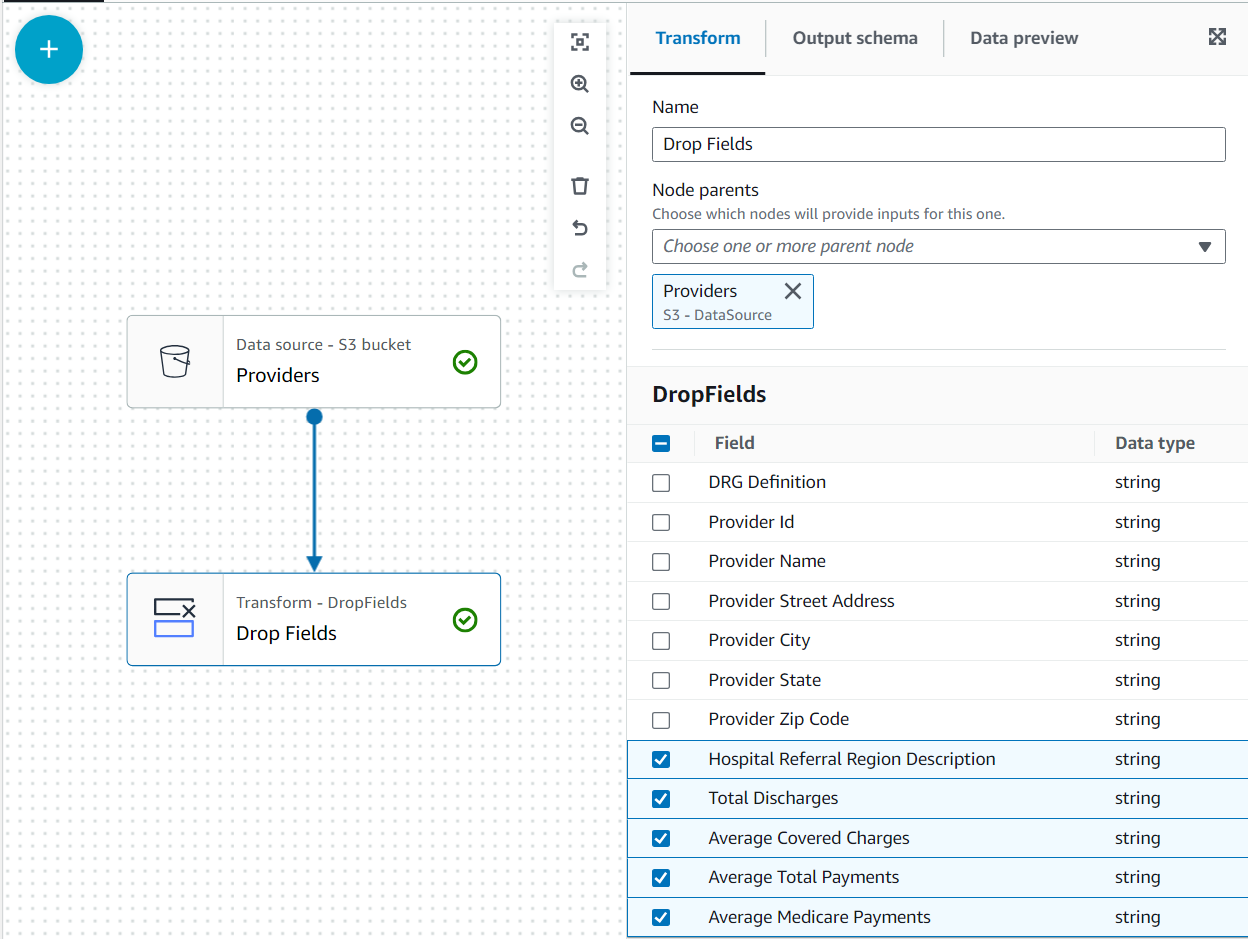
- プロバイダ ノードを選択したら、 ドロップ フィールド 変換 (親ノードを選択しなかった場合、親ノードはありません。その場合は、ノードの親を手動で割り当てます)。
- その後すべてのフィールドを選択します プロバイダーの郵便番号.
その後、このデータはプロバイダーを使用してアラバマ州の請求に結合されます。 ただし、XNUMX 番目のデータセットには状態が指定されていません。 データの知識を利用して、本当に必要なデータをフィルタリングすることで結合を最適化できます。
- 加える フィルタ ~の子として変身する ドロップ フィールド.
- それに名前を付けます
Alabama providers状態が一致する必要があるという条件を追加しますAL.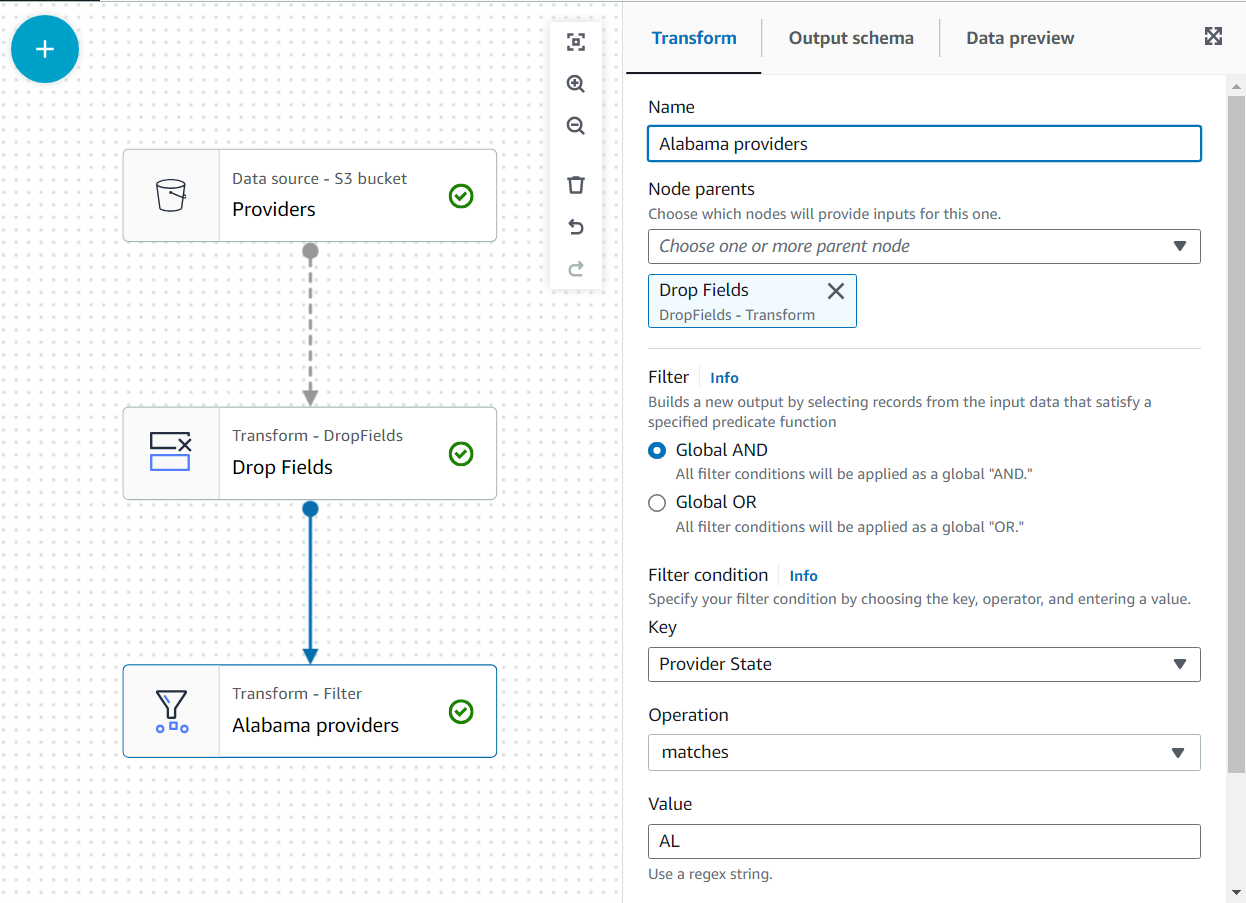
- 3 番目のソース (新しい SXNUMX ソース) を追加し、名前を付けます
Alabama claims. - を入力する S3 URL、別のブラウザー タブで DataBrew を開き、ナビゲーション ペインで [データセット] を選択し、テーブルに表示されている場所をコピーします。 アラバマ州の主張 (関連付けられた http リンクではなく、s3:// で始まるテキストをコピーします)。 次に、ビジュアルジョブに戻り、次のように貼り付けます。 S3 URL; それが正しい場合は、 出力スキーマ タブをクリックして、リストされているデータフィールドを選択します。
- CSV 形式を選択し、他のソースの場合と同様にスキーマを推測します。
- このソースの子として、 ノードの追加 のメニュー
recipe選択して データ準備レシピ.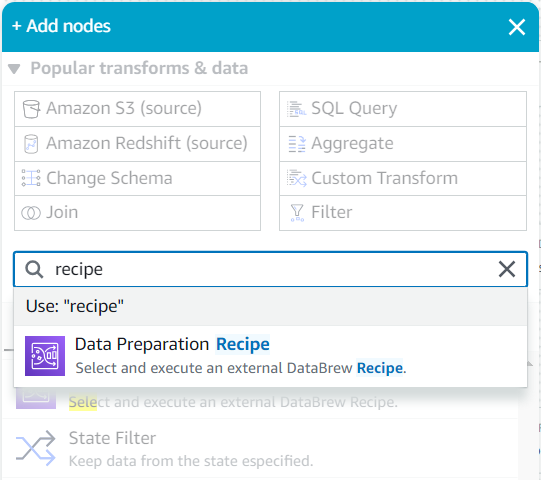
- この新しいノードのプロパティで、名前を付けます。
Claim cleanup recipeをクリックして、以前に公開したレシピとバージョンを選択します。 - ここでレシピの手順を確認し、必要に応じて DataBrew へのリンクを使用して変更を加えることができます。
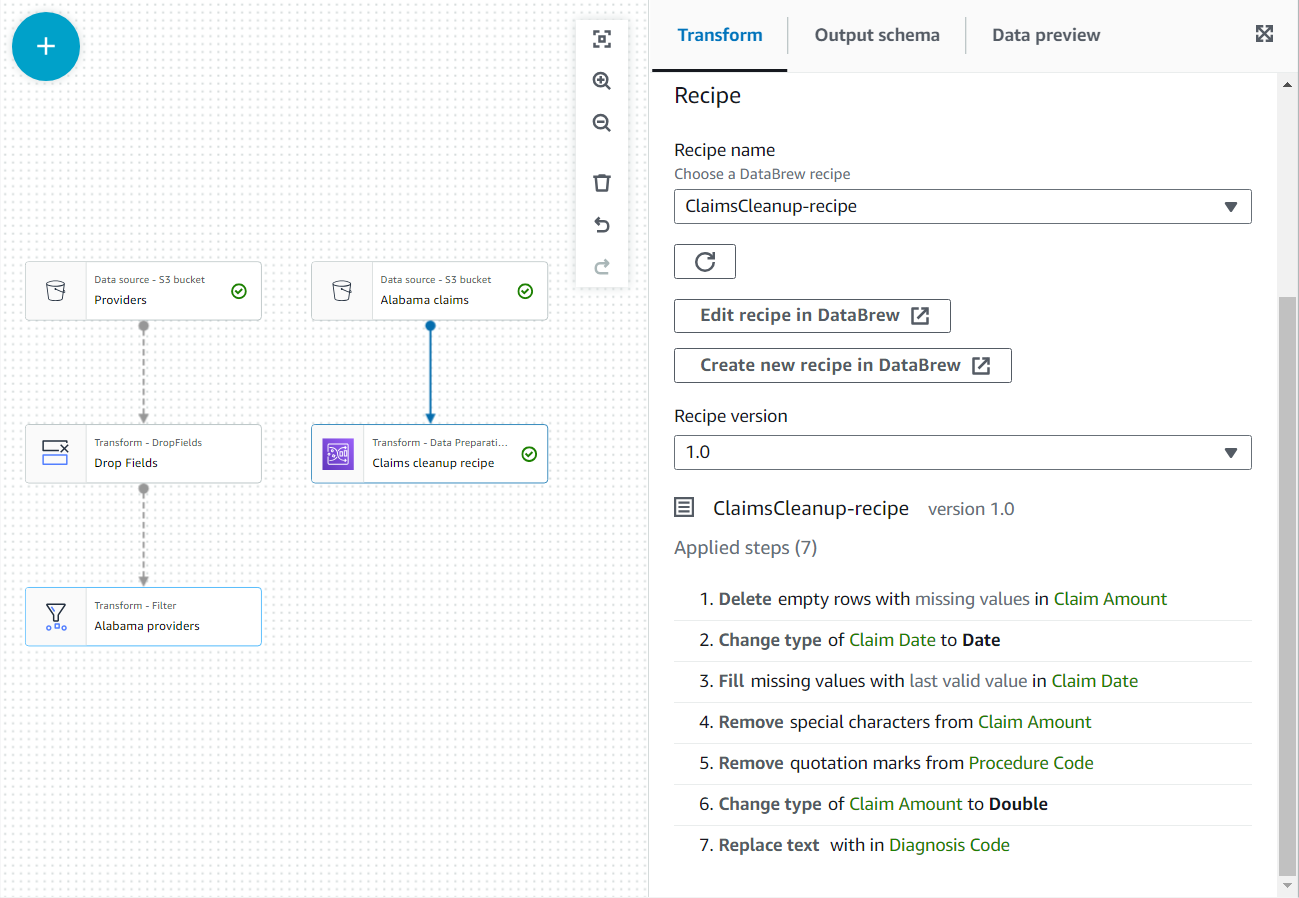
- 加える 加入 ノードを選択して両方を選択します アラバマ州のプロバイダー および クレームクリーンアップレシピ 親として。
- 両方のソースのプロバイダー ID と等しい結合条件を追加します。
- 最後のステップとして、S3 ノードをターゲットとして追加します (検索時にリストされる最初のノードがソースであることに注意してください。ターゲットとしてリストされるバージョンを必ず選択してください)。
- ノード設定では、デフォルト形式の JSON のままにし、ジョブロールが書き込み権限を持つ S3 URL を入力します。
さらに、データ出力をカタログ内のテーブルとして利用できるようにします。
- データカタログの更新オプション セクションで、XNUMX 番目のオプションを選択します Data Catalog にテーブルを作成し、その後の実行でスキーマを更新して新しいパーティションを追加しますをクリックし、テーブルを作成する権限があるデータベースを選択します。
- 割り当てます
alabama_claims名前として選択してください 請求日 パーティション キーとして使用します (これは説明のためです。このような小さなテーブルには、後でデータが追加されない場合、実際にはパーティションは必要ありません)。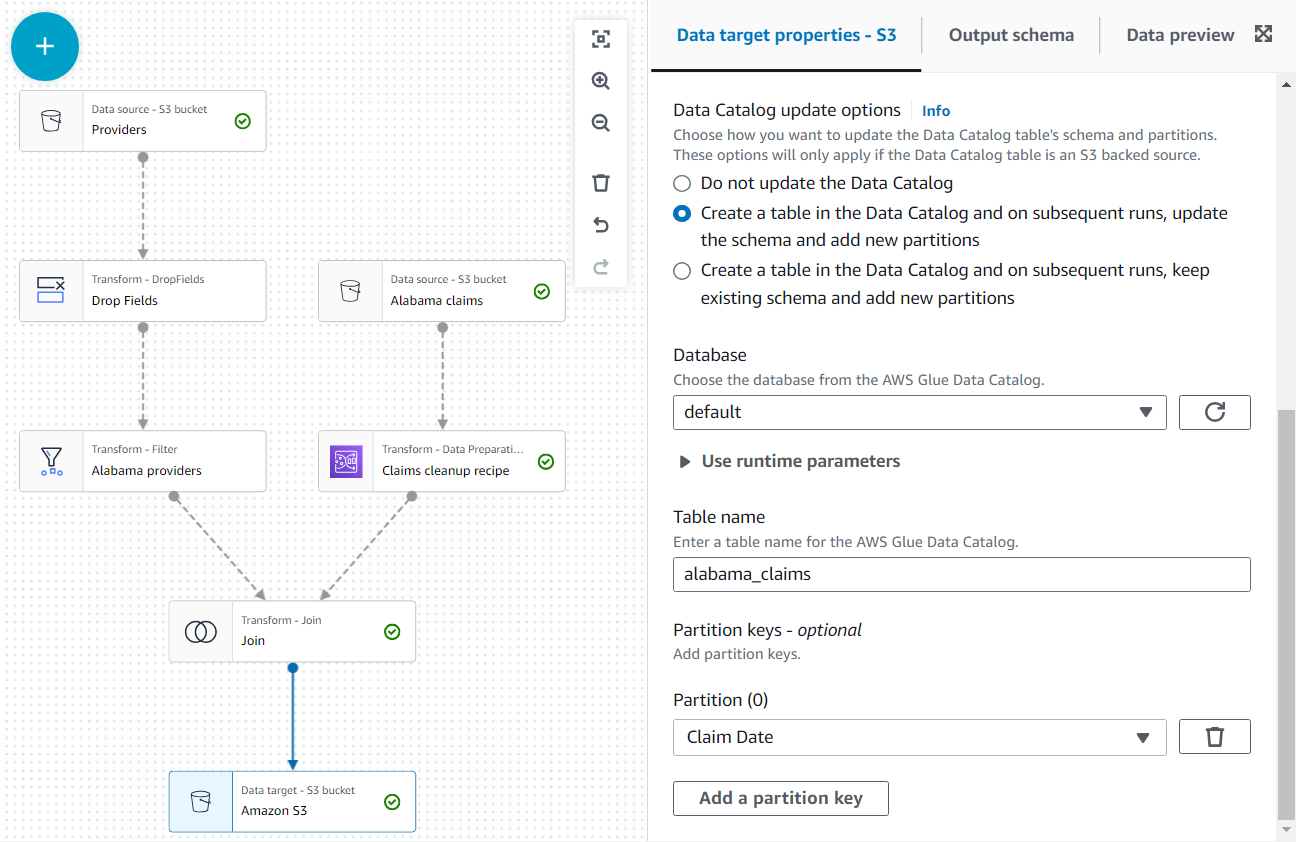
- これで、ジョブを保存して実行できるようになりました。
- ソフトウェア設定ページで、下図のように Active Runs タブでは、ジョブ ID リンクを使用してプロセスを追跡し、詳細なジョブ メトリックを確認できます。
ジョブが完了するまでに数分かかります。
- ジョブが完了したら、Athena コンソールに移動します。
- テーブルを検索する
alabama_claims選択したデータベースで、コンテキスト メニューを使用して、 プレビューテーブルこれにより、テーブルに対して単純な SELECT * SQL ステートメントが実行されます。
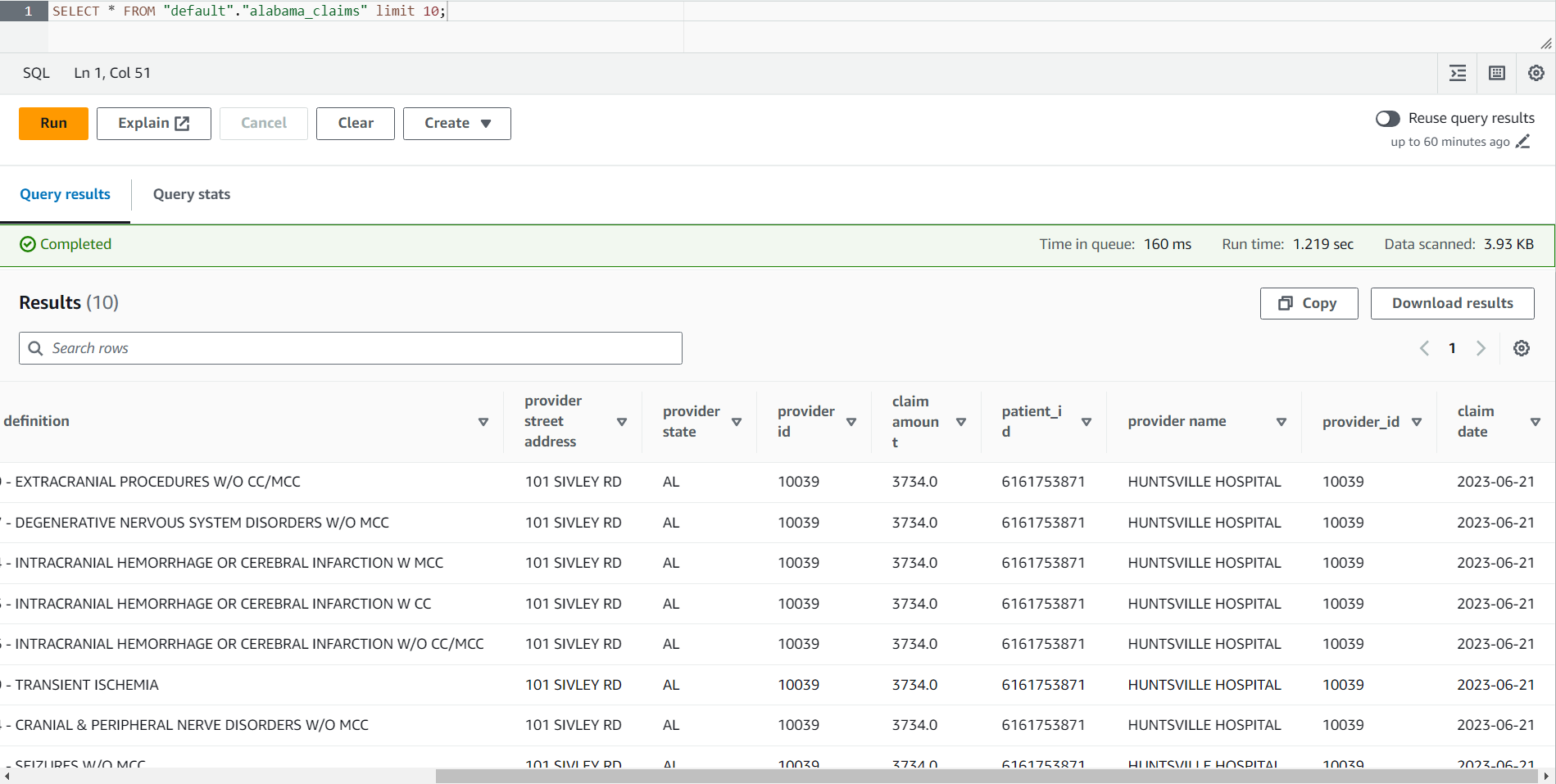
ジョブの結果を見ると、データが DataBrew レシピによってクリーンアップされ、AWS Glue Studio 結合によって強化されたことがわかります。
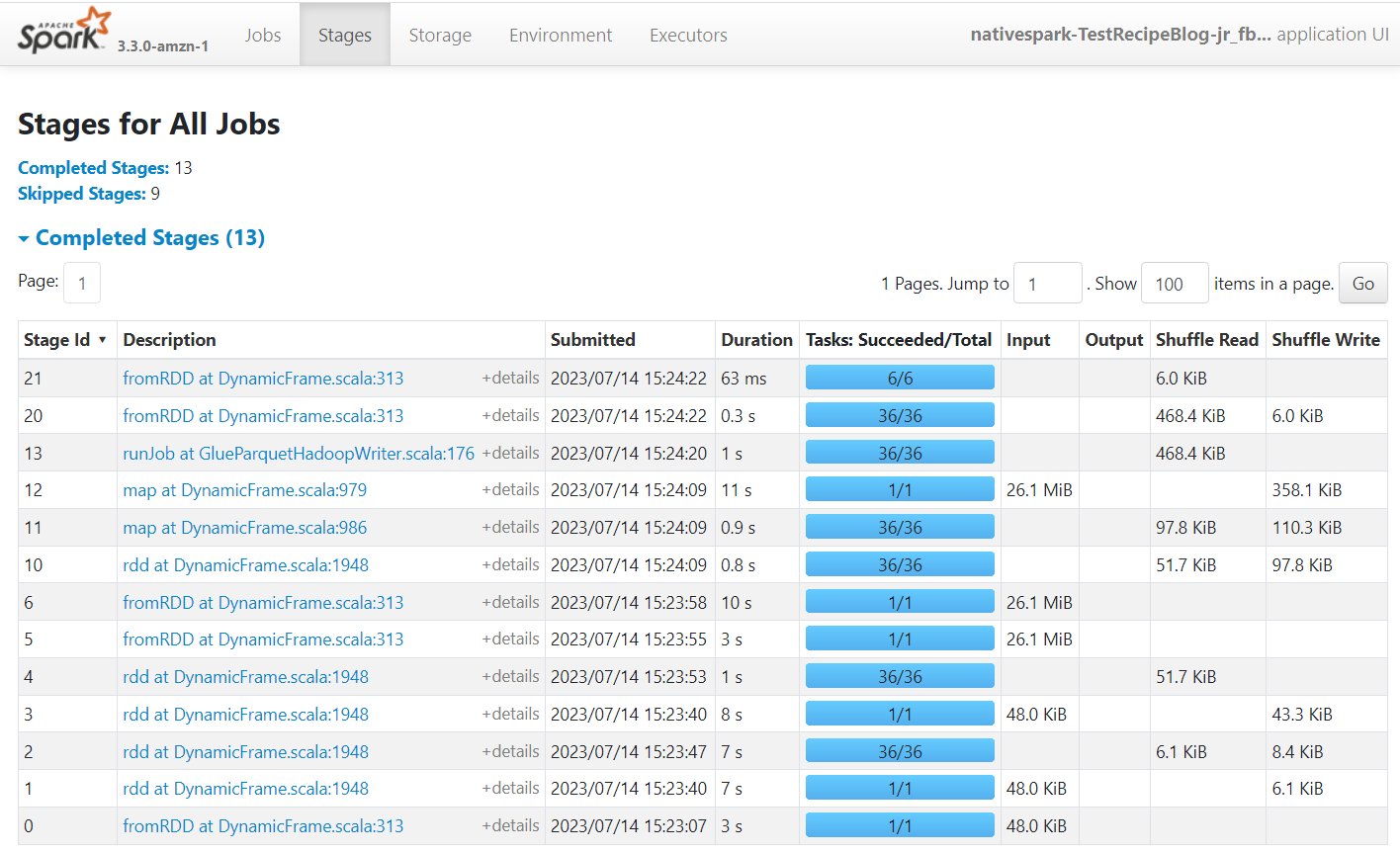
Apache Spark は、AWS Glue Studio で作成されたジョブを実行するエンジンです。 生成されるイベント ログで Spark UI を使用すると、ジョブの計画と実行に関する洞察を表示でき、ジョブのパフォーマンスと潜在的なパフォーマンスのボトルネックを理解するのに役立ちます。 たとえば、大規模なデータセットに対するこのジョブの場合、これを使用して、結合を実行する前にプロバイダーの状態を明示的にフィルタリングすることの影響を比較したり、自動バランス変換を追加して並列処理を改善することでメリットが得られるかどうかを特定したりできます。
デフォルトでは、ジョブは Apache Spark イベント ログを次のパスに保存します。 s3://aws-glue-assets-<your account id>-<your region name>/sparkHistoryLogs/。 ジョブを表示するには、次を使用して履歴サーバーをインストールする必要があります。 利用可能な方法の XNUMX つ.
クリーンアップ
このソリューションが不要になった場合は、Amazon S3 で生成されたファイル、ジョブによって作成されたテーブル、DataBrew レシピ、および AWS Glue ジョブを削除できます。
まとめ
この投稿では、AWS DataBrew を使用して、提供されたインタラクティブエディターを使用してレシピを構築し、公開されたレシピを AWS Glue Studio ビジュアル ETL ジョブの一部として使用する方法を説明しました。 データの準備を実行し、AWS Glue Catalog テーブルにデータを取り込むときに必要な一般的なタスクの例をいくつか含めました。
この例ではビジュアル ジョブで XNUMX つのレシピを使用しましたが、ETL プロセスのさまざまな部分で複数のレシピを使用したり、複数のジョブで同じレシピを再利用したりすることも可能です。
これらの AWS Glue ソリューションを使用すると、コードをまったく記述することなく、構築と維持が簡単な高度な ETL パイプラインを効果的に作成できます。 両方のツールを組み合わせたソリューションの作成を今すぐ開始できます。
著者について
 ミハイル・スミルノフ は、AWS Glue チームのシニア ソフトウェア開発エンジニアであり、AWS Glue DataBrew 開発チームの一員です。 仕事以外では、ギターを習うこと、家族と旅行することなどに興味があります。
ミハイル・スミルノフ は、AWS Glue チームのシニア ソフトウェア開発エンジニアであり、AWS Glue DataBrew 開発チームの一員です。 仕事以外では、ギターを習うこと、家族と旅行することなどに興味があります。
 ゴンザロエレロス は、AWS Glue チームのシニア ビッグデータ アーキテクトです。 アイルランドのダブリンに拠点を置き、AWS Glue をベースとしたビッグデータ ソリューションで顧客の成功を支援しています。 余暇には、ボードゲームやサイクリングを楽しんでいます。
ゴンザロエレロス は、AWS Glue チームのシニア ビッグデータ アーキテクトです。 アイルランドのダブリンに拠点を置き、AWS Glue をベースとしたビッグデータ ソリューションで顧客の成功を支援しています。 余暇には、ボードゲームやサイクリングを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 自動車/EV、 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- ブロックオフセット。 環境オフセット所有権の近代化。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/use-aws-glue-databrew-recipes-in-your-aws-glue-studio-visual-etl-jobs/
- :持っている
- :は
- :not
- $UP
- 10
- 100
- 12
- 視聴者の38%が
- 20
- 200
- 22
- 26
- 28
- 500
- 7
- 8
- a
- できる
- 私たちについて
- ことができます。
- 一般に認められた
- アクセス
- Action
- 実際の
- 加えます
- 追加されました
- 追加
- 添加
- 住所
- 高度な
- 後
- アラバマ州
- すべて
- 許す
- また
- Amazon
- Amazon Webサービス
- 金額
- an
- アナリスト
- および
- どれか
- アパッチ
- Apache Spark
- 申し込み
- 申し込む
- です
- AS
- 関連する
- At
- 著者
- オート
- オートマチック
- 利用できます
- AWS
- AWSグルー
- バック
- ベース
- BE
- さ
- 恩恵
- 利点
- ビッグ
- ビッグデータ
- ブランク
- ボード
- ボードゲーム
- ブックマーク
- 両言語で
- もたらす
- ブラウザ
- ビルド
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 缶
- 機能
- 場合
- カタログ
- 細胞
- 集中型の
- 変化する
- 変更
- 文字
- 子
- 選択
- 選択する
- クレーム
- クレーム
- コード
- コラム
- コラム
- 組み合わせる
- 到来
- コマンドと
- 比較します
- コンプリート
- コンポーネント
- コンピュータ
- 条件
- 検討
- からなる
- 領事
- コンテキスト
- 変換
- 変換
- 正しい
- 対応する
- 費用
- 可能性
- 作ります
- 作成した
- 作成
- 創造
- カスタム
- Customers
- データ
- データの準備
- データ処理
- データ品質
- データベース
- データセット
- 日付
- 試合日
- 中
- 取引
- 決めます
- 決定
- デフォルト
- 実証します
- 説明
- 希望
- 詳細な
- 細部
- デベロッパー
- 開発
- 開発チーム
- DID
- 異なります
- 明確な
- ディストリビューション
- do
- そうではありません
- すること
- ドル
- Drop
- ダブリン
- 各
- 簡単に
- エディタ
- 効果
- 効果的に
- 可能
- end
- エンジン
- エンジニア
- 豊かな
- 濃縮
- 入力します
- エラー
- 本質的な
- エーテル(ETH)
- 評価する
- さらに
- イベント
- あらゆる
- 毎日
- 例
- 例
- 既存の
- 余分な
- エキス
- 家族
- 遠く
- 特徴
- 少数の
- フィールズ
- File
- 埋める
- filter
- フィルタリング
- 最後に
- 名
- 続いて
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- から
- さらに
- Games
- 生成された
- 与える
- 大きい
- 持ってる
- he
- 助けます
- ことができます
- こちら
- 彼の
- history
- 認定条件
- How To
- しかしながら
- HTML
- HTTP
- HTTPS
- IAM
- ID
- 特定され
- 識別する
- アイデンティティ
- if
- 影響
- 改善します
- 改善
- in
- include
- 含まれました
- 含めて
- 示された
- 洞察
- install
- 統合された
- 統合
- 相互作用的
- 関心
- 利益
- インタフェース
- に
- 導入
- 直観的な
- アイルランド
- 問題
- IT
- ITS
- ジョブ
- Jobs > Create New Job
- join
- 参加した
- JPG
- JSON
- ただ
- キープ
- キー
- 知識
- 大
- より大きい
- 最大の
- 姓
- 後で
- 最新の
- 学習
- コメントを残す
- ような
- 可能性が高い
- LINK
- リストされた
- 負荷
- 場所
- ロジック
- より長いです
- 維持する
- make
- 作る
- 手動で
- 一致
- 医療の
- メニュー
- 方法
- メソッド
- メトリック
- 分
- 行方不明
- モニター
- 他には?
- の試合に
- しなければなりません
- 名
- ナビゲート
- ナビゲーション
- 必要
- 必要とされる
- ニーズ
- 新作
- いいえ
- 知らせ..
- 今
- 数
- of
- on
- ONE
- の
- 開いた
- 最適化
- オプション
- オプション
- or
- 注文
- その他
- 私たちの
- 出力
- 外側
- が
- 全体
- ペイン
- 部
- 部品
- path
- パフォーマンス
- 実行
- 許可
- パーミッション
- 計画
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- プレイ
- 可能
- ポスト
- 潜在的な
- 準備
- プレビュー
- プレビュー
- プロセス
- 処理
- 生産する
- プロジェクト
- プロパティ
- 提供
- プロバイダー
- プロバイダ
- は、大阪で
- 出版
- パブリッシュ
- 公表
- 目的
- 目的
- 品質
- 引用
- 本当に
- 合理的な
- レシピ
- レシピ
- 減らします
- 反映する
- 地域
- 登録
- 関連した
- 削除します
- replace
- 要求されました
- の提出が必要です
- 要件
- それぞれ
- REST
- 結果
- 結果
- 再利用
- レビュー
- 職種
- ラン
- runs
- 同じ
- Save
- 規模
- スケーリング
- を検索
- 二番
- セクション
- 見ること
- 選択
- 別
- サービス
- セッション
- セッションに
- 設定
- すべき
- 示されました
- 示す
- 符号
- 重要
- 簡単な拡張で
- サイズ
- 小さい
- So
- これまでのところ
- ソフトウェア
- 溶液
- ソリューション
- 一部
- ソース
- ソース
- スペース
- スパーク
- 特別
- 特定の
- 指定の
- SQL
- start
- 起動
- 都道府県
- ステートメント
- 統計
- 手順
- ステップ
- ストレージ利用料
- 店舗
- 簡単な
- 文字列
- 研究
- それに続きます
- 成功する
- そのような
- 適当
- 概要
- 確か
- 合成
- テーブル
- 取る
- ターゲット
- タスク
- チーム
- テスト
- それ
- ソース
- ステート
- それら
- その後
- そこ。
- この
- 三
- 時間
- 〜へ
- 今日
- ツール
- 豊富なツール群
- top
- 追跡する
- 最適化の適用
- 変換
- 変換
- 旅行
- 2
- type
- ui
- 下
- わかる
- アップデイト
- 更新しました
- URL
- 使用可能な
- つかいます
- 使用事例
- 中古
- users
- 使用されます
- 検証
- 値
- 価値観
- 確認する
- バージョン
- 詳しく見る
- 目に見える
- 欲しいです
- ました
- 方法
- we
- ウェブ
- Webサービス
- WELL
- した
- いつ
- which
- 意志
- 無し
- 仕事
- ワーカー
- 労働者
- ワークフロー
- でしょう
- 書きます
- 書き込み
- 貴社
- あなたの
- ゼファーネット
- 〒