これでチュートリアルはすべて見終わりました。 これで、ニューラル ネットワークがどのように機能するかが理解できました。 猫と犬の分類器が構築されました。 中途半端なキャラクターレベルの RNN に挑戦しました。 あなたはただの一人です pip install tensorflow ターミネーターを作ることからは離れますよね? 間違い。

深層学習の非常に重要な部分は、適切なハイパーパラメータを見つけることです。 これらはモデルが示す数値です 学ぶ。
この記事では、Kaggle リーダーボードでナンバー 1 の座を目指す過程で遭遇する最も一般的な (そして重要な) ハイパーパラメーターのいくつかについて説明します。 さらに、ハイパーパラメータを賢く選択するのに役立つ強力なアルゴリズムもいくつか紹介します。
深層学習のハイパーパラメータ
ハイパーパラメータは、モデルの調整ノブと考えることができます。
人間の可聴範囲を超える低音を生成するサブウーファーを備えた豪華な 7.1 Dolby Atmos ホーム シアター システムは、AV レシーバーをステレオに設定している場合は役に立ちません。

同様に、ハイパーパラメータがオフの場合、3 兆個のパラメータを持つ inception_vXNUMX では MNIST を通過することさえできません。
それでは、正しい設定をダイヤルする方法を説明する前に、調整するノブを見てみましょう。
学習率
おそらく最も重要なハイパーパラメータである学習率は、大まかに言えば、ニューラル ネットワークが「学習」する速度を制御します。
それなら、これをさらに強化して、追い越し車線で人生を生きてみませんか?

そんなに単純ではありません。 ディープラーニングにおける私たちの目標は次のとおりであることを忘れないでください。 損失関数を最小化する。 学習率が高すぎると、損失があちこちに飛び始めて収束しません。

また、学習率が小さすぎる場合、上に示したように、モデルが収束するまでに時間がかかりすぎます。
弾み
この記事はハイパーパラメータの最適化に焦点を当てているため、その概念全体を説明するつもりはありません。 勢い。 しかし、要するに、運動量定数は、損失関数の表面を転がるボールの質量と考えることができます。
ボールが重ければ重いほど、落ちる速度は速くなります。 ただし、重すぎると、引っかかったり、ターゲットをオーバーシュートしたりする可能性があります。

ドロップアウト
ここでテーマを感じたら、次のことをご案内します。 アマール・ブディラジャのドロップアウトに関する記事。

ただし、簡単におさらいすると、ドロップアウトはジェフ ヒントンによって提案された正則化手法であり、ニューラル ネットワーク内の活性化を (p) の確率でランダムに 0 に設定します。 これは、ニューラル ネットワークがデータを学習するのではなく、データを過剰適合 (記憶) するのを防ぐのに役立ちます。
(p) はハイパーパラメータです。
アーキテクチャ — レイヤー数、レイヤーごとのニューロンなど
もう XNUMX つの (かなり最近の) アイデアは、ニューラル ネットワーク自体のアーキテクチャをハイパーパラメーターにすることです。
通常、機械にモデルのアーキテクチャを理解させることはありませんが(そうしないと、AI 研究者が職を失うことになります)、次のような新しい技術がいくつかあります。 ニューラルアーキテクチャ検索 このアイデアはさまざまな程度の成功を収めて実装されています。
聞いたことがあるなら AutoML、これは基本的に Google のやり方です。すべてをハイパーパラメータにしてから、 問題に XNUMX 億 TPU を投入し、自動的に解決する.
しかし、ブラック フライデー セールの後に、石畳み合わせた低価格の機械を使って犬と猫を分類したいだけの私たちの大多数にとっては、そろそろそれらの深層学習モデルを実際に機能させる方法を理解する時期に来ています。
ハイパーパラメータ最適化アルゴリズム
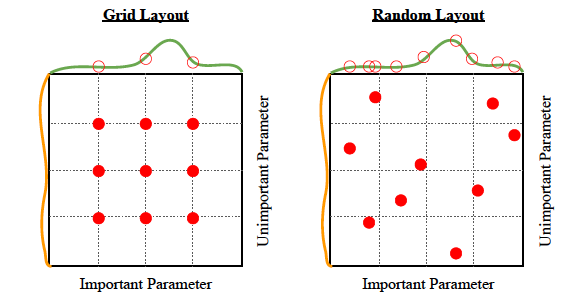
グリッド検索
これは、適切なハイパーパラメータを取得する最も簡単な方法です。 文字通りただの暴力です。
アルゴリズム: 指定されたハイパーパラメータのセットから多数のハイパーパラメータを試し、何が最も効果的かを確認します。
長所: XNUMX年生でも簡単に実践できます。 簡単に並列化できる。
短所: おそらくご想像のとおり、これは (すべてのブルート フォース手法と同様に) 非常に計算コストがかかります。
それを使用する必要があります: おそらくそうではありません。 グリッド検索は非常に非効率的です。 シンプルにしたい場合でも、ランダム検索を使用することをお勧めします。
ランダム検索
それはすべて名前にあります - ランダム検索。 無作為に。
アルゴリズム: ハイパーパラメータ空間上で一様分布からランダムなハイパーパラメータを大量に試して、何が最も効果的かを確認してください。
長所: 簡単に並列化できる。 グリッド検索と同じくらい簡単ですが、少しだけ 優れたパフォーマンス、以下に示すように:

短所: グリッド検索よりも優れたパフォーマンスが得られますが、それでも同様に計算量が多くなります。
それを使用する必要があります: 単純な並列化と簡素化が最も重要である場合は、それを選択してください。 しかし、時間と労力を惜しまないことができるのであれば、ベイズ最適化を使用することで大きな利益が得られるでしょう。
ベイジアン最適化
これまでに見てきた他の方法とは異なり、ベイズ最適化ではアルゴリズムの以前の反復の知識が使用されます。 グリッド検索とランダム検索では、各ハイパーパラメーターの推測は独立しています。 しかし、ベイジアン手法では、さまざまなハイパーパラメータを選択して試すたびに、完璧に向かって少しずつ進んでいきます。

ベイジアン ハイパーパラメータ調整の背後にあるアイデアは長く、詳細が豊富です。 したがって、あまりにも多くのウサギの穴を避けるために、ここで要点を説明します。 ただし、必ず読んでください ガウス過程 および ベイズ最適化一般, そういうことに興味があるなら。
これらのハイパーパラメータ調整アルゴリズムを使用している理由は、複数のハイパーパラメータの選択肢を個別に実際に評価することが不可能であるためです。 たとえば、適切な学習率を手動で見つけたいとします。 これには、学習率の設定、モデルのトレーニング、評価、別の学習率の選択、モデルの再度最初からのトレーニング、再評価が含まれ、このサイクルが継続します。
問題は、「モデルのトレーニング」が完了するまでに (問題の複雑さに応じて) 最大で数日かかる場合があることです。 したがって、カンファレンスの論文提出期限が来るまでに、いくつかの学習率しか試すことができません。 そして、あなたは何を知っていますか、あなたはまだ勢いに乗ってプレーを始めていません。 おっと。

アルゴリズム: ベイジアン手法では、モデルがどの程度優れているかを推定する関数 (より正確には、考えられる関数に対する確率分布) を構築しようとします。 かもしれない 特定のハイパーパラメータを選択するためのものです。 この近似関数 (文献ではサロゲート関数と呼ばれています) を使用すると、ハイパーパラメータをサロゲート関数に最適化するだけで済むため、設定、トレーニング、評価ループを何度も繰り返す必要がなくなります。
例として、この関数を最小化したいとします (モデルの損失関数のプロキシのように考えてください)。

サロゲート関数は、ガウス プロセスと呼ばれるものに由来します (注: サロゲート関数をモデル化する方法は他にもありますが、ここではガウス プロセスを使用します)。 先ほども述べたように、数学的な複雑な導出は行いませんが、ベイジアンとガウスについての話は要約すると次のようになります。
$$ mathbb{P} (F_n(X)|X_n) = frac{e^{-frac12 F_n^T Sigma_n^{-1} F_n}}{sqrt{(2pi)^n |Sigma_n|}} $$
確かに、それは一口です。 しかし、それを分解してみましょう。
左側は、確率分布が関係していることを示しています (派手な見た目 ( mathbb{P} ) が存在することを前提としています)。 括弧内を見ると、これは ( F_n(X) ) の確率分布であり、任意の関数であることがわかります。 なぜ? 特定の関数だけではなく、考えられるすべての関数にわたる確率分布を定義していることを覚えておいてください。 本質的に、左辺は、サンプル データが与えられた場合に、ハイパーパラメータをモデルのメトリック (検証精度、対数尤度、テスト エラー率など) にマッピングする真の関数が ( F_n(X) ) である確率が ( F_n(X) ) であることを示しています。 (X_n) は右辺にあるものと同じです。
最適化する関数ができたので、それを最適化します。
最適化プロセスを開始する前のガウス プロセスは次のようになります。

好みのオプティマイザーを使用します (プロは期待される改善を最大化することを好みます) が、どういうわけかただ標識 (または勾配) に従うだけで、いつの間にか極小値に到達することになります。
数回の反復の後、ガウス プロセスはターゲット関数をより適切に近似できるようになります。

使用した方法に関係なく、「argmin」が見つかりました。 サロゲート関数の。 答えは、驚くべきことに、サロゲート関数を最小化する引数が最適なハイパーパラメータ (の推定値) です。 わーい。
最終結果は次のようになります。

これらの「最適な」ハイパーパラメータを使用してニューラル ネットワークでトレーニングを実行すると、ある程度の改善が見られるはずです。 ただし、この新しい情報を使用して、ベイジアン最適化プロセス全体を何度も何度もやり直すこともできます。 ベイジアン ループは何度でも自由に実行できますが、注意してください。 あなたは実際に何かを計算しています。 これらの AWS クレジットは無料ではありません。 それとも彼らは…
長所: ベイジアン最適化では、グリッド検索やランダム検索よりも優れた結果が得られます。
短所: 並列化はそれほど簡単ではありません。
使用すべきか: ほとんどの場合、そうです! 唯一の例外は次の場合です
- あなたは深層学習の専門家なので、微近似アルゴリズムの助けは必要ありません。
- 膨大な計算リソースにアクセスでき、グリッド検索とランダム検索を大規模に並列化できます。
- あなたが頻度主義者/反ベイズ統計オタクなら。
良好な学習率を見つけるための別のアプローチ
これまで見てきたすべての方法には、機械学習エンジニアの仕事を自動化するという 4 つの根本的なテーマがあります。 それは素晴らしいことです。 あなたの上司がこれを知り、あなたを XNUMX 枚の RTX Titan カードと置き換えることを決定するまで。 は。 手動検索に固執するべきだったと思います。

しかし、絶望しないでください。研究者の仕事を減らし、同時により多くの報酬を得るという分野では、積極的な研究が行われています。 そして、非常にうまく機能したアイデアの XNUMX つは、学習率範囲テストです。私の知る限り、これは最初に出版されたものです。 レスリー・スミスによる論文.
この論文は実際には、時間の経過とともに学習率をスケジュールする (変更する) 方法に関するものです。 LR (学習率) 範囲テストは、著者が何気なく脇に落とした金塊でした。
次のように、学習率を最小値から最大値まで変化させる学習率スケジュールを使用している場合。 循環学習率 or ウォーム リスタートによる確率的勾配降下法、著者は、各反復後の学習率を小さい値から大きい値まで線形的に増加させることを提案しています (たとえば、 1e-7 〜へ 1e-1)、各反復での損失を評価し、損失 (またはテスト誤差または精度) を学習率に対して対数スケールでプロットします。 プロットは次のようになります。

プロット上でマークされているように、学習率スケジュールを最小学習率と最大学習率の間でバウンスするように設定します。学習率は、プロットを見て最も急な勾配を持つ領域に注目することで見つかります。
これは、Colab のサンプル LR 範囲テスト プロット (CIFAR10 でトレーニングされた DenseNet) です。 ノート:

経験則として、派手な学習率スケジュールを実行していない場合は、一定の学習率をプロットの最小値よりも XNUMX 桁低く設定するだけです。 この場合、それはおおよそ次のようになります 1e-2.
この方法の最も優れた点は、非常にうまく機能し、他のアルゴリズムで適切なハイパーパラメータを見つけるために必要な時間、精神的労力、および計算を節約できることを除けば、追加の計算コストが実質的にかからないことです。
一方、他のアルゴリズム、つまりグリッド検索、ランダム検索、 ベイジアン最適化、優れたニューラル ネットワークをトレーニングするという目標に沿ったプロジェクト全体を実行する必要がありますが、LR 範囲テストは単純な定期的なトレーニング ループを実行し、途中でいくつかの変数を追跡するだけです。
最適な学習率を使用した場合に期待できる収束速度のタイプは次のとおりです (次の例から) ノート):

LR 範囲テストは、次のチームによって実装されました。 高速.aiそして、LR 範囲テスト (彼らはそれを 学習率ファインダー) だけでなく、他の多くのアルゴリズムも簡単に使用できます。
より洗練されたディープラーニング実践者向け
興味のある方は、純正で書かれたノートもあります パイトーチ 上記を実装したものです。 これにより、舞台裏のトレーニング プロセスをよりよく理解できるようになります。 見てみな こちら.
努力を節約しましょう

もちろん、これらすべてのアルゴリズムは、どれも優れていますが、実際には常に機能するとは限りません。 ニューラル ネットをトレーニングするときに考慮すべき要素は他にもたくさんあります。たとえば、データを前処理する方法、モデルを定義する方法、実際にこのようなことを実行するのに十分強力なコンピューターを用意する方法などです。
ナノネット 使いやすい API を提供します カスタムディープラーニングのトレーニングとデプロイ モデル。 データ拡張、転移学習、そしてハイパーパラメータの最適化など、面倒な作業はすべて引き受けてくれます。
ナノネット 広大な GPU クラスター上でベイジアン検索を利用して、最新のグラフィックス カードにお金がかかることを心配することなく、適切なハイパーパラメータのセットを見つけます。 out of bounds for axis 0.
最適なモデルが見つかったら、 ナノネット はクラウド上でそれを提供し、Web インターフェイスを使用してモデルをテストしたり、2 行のコードを使用してモデルをプログラムに統合したりできます。
完璧とは言えないモデルに別れを告げましょう。
まとめ
この記事では、ハイパーパラメータとそれらを最適化するいくつかの方法について説明しました。 しかし、それは一体何を意味するのでしょうか?
AI テクノロジーの民主化に向けて私たちがますます努力する中で、自動ハイパーパラメータ調整はおそらく正しい方向への一歩となるでしょう。 これにより、あなたや私のような普通の人でも、数学の博士号がなくても、素晴らしい深層学習アプリケーションを構築できます。
モデルをコンピューティング能力に飢えさせると、そのコンピューティング能力に余裕のある人の手に最高のモデルが残るという意見もあるかもしれませんが、AWS や Nanonets のようなクラウド サービスは、強力なマシンへのアクセスの民主化に役立ち、ディープ ラーニングをはるかにアクセスしやすくします。
しかし、より根本的に、私たちは何なのか 実際に ここでは数学を使ってさらに数学を解いています。 これが興味深いのは、それがどれほどメタ的に聞こえるかだけでなく、それがどれほど誤解されやすいかという点でもあります。

私たちは確かに、パンチカードやトレーステーブルの時代から、機能を最適化する機能を最適化する時代へと、長い道のりを歩んできました。 しかし、私たちは自ら「考える」ことができる機械の構築には程遠いのです。
そして、それは決して落胆するものではありません。なぜなら、人類がこれほど少ないもので多くのことができるのであれば、私たちのビジョンが実際に見えるものになったとき、どんな未来が待っているのかを想像してみてください。
そこで私たちは、クッション付きのメッシュ椅子に座って、空白の端末画面を見つめながら、キーを打つたびに、 sudo ディスクを完全に消去できるスーパーパワー。
それで私たちは座って、一日中そこに座ってます、なぜなら次の大きな進歩はたった一つかもしれないからです pip install 離れました。
コードを書くのが面倒ですか? コンピューティング リソースに費やしたくないですか? に向かいます ナノネット および モデルの構築を開始する 今!
あなたは私たちの最新の投稿に興味があるかもしれません:
- 7
- 9
- アクセス
- アクティブ
- AI
- アルゴリズム
- アルゴリズム
- すべて
- amp
- API
- 建築
- 引数
- 記事
- 聞こえる
- 自動化
- AV
- AWS
- BEST
- 10億
- ビット
- ブラック
- ブラック・フライデイ
- ビルド
- 建物
- 束
- コール
- これ
- 例
- 現金
- 猫
- クラウド
- クラウドサービス
- コード
- コマンドと
- 計算
- コンピューティング
- コンピューティングパワー
- 講演
- 続ける
- コスト
- Applied Deposits
- データ
- 中
- 深い学習
- 犬
- 落とした
- エンジニア
- 見積もり
- 等
- スピーディー
- フィギュア
- 発見
- 名
- フィット
- 無料版
- 金曜日
- FS
- function
- 未来
- GIF
- GitHubの
- 与え
- ゴールド
- 良い
- でログイン
- GPU
- 素晴らしい
- グリッド
- こちら
- ハイ
- ホーム
- 認定条件
- How To
- HTTPS
- 飢えました
- アイデア
- インチ
- 含めて
- 情報
- 関係する
- IT
- ジョブ
- Jobs > Create New Job
- 保管
- 知識
- 大
- 最新の
- LEARN
- 学習
- 図書館
- レポート
- ローカル
- ロゴ
- 長い
- 機械学習
- マシン
- 大多数
- 作成
- ゲレンデマップ
- math
- メディア
- ミディアム
- ミーム
- Meta
- メトリック
- 弾み
- すなわち
- net
- ネットワーク
- ニューラル
- ニューラルネットワーク
- 番号
- 注文
- その他
- 紙素材
- パフォーマンス
- 投稿
- 電力
- 演奏曲目
- プロジェクト
- 代理
- パンチ
- 範囲
- 価格表
- RE
- 研究
- リソース
- 結果
- ラン
- 塩
- 規模
- 画面
- を検索
- サービス
- セッションに
- 設定
- ショート
- サイン
- 簡単な拡張で
- 小さい
- So
- 解決する
- スペース
- スピード
- 過ごす
- Spot
- start
- 開始
- 統計
- 成功
- 表面
- 驚き
- ターゲット
- テクノロジー
- test
- 未来
- 劇場
- テーマ
- 時間
- 追跡する
- トレーニング
- チュートリアル
- Unsplash
- us
- ユーティリティ
- 値
- よく見る
- ウェブ
- 誰
- 風
- 仕事
- 作品
- X







{kind=link}
{kind=link}
{kind=link}