より高機能、より高速、より小型、より低電力なシステムへの行進の中で、ムーアの法則により、純粋に半導体プロセスの進化のみに 30 年以上にわたってソフトウェアがただ乗りされてきました。コンピューティング ハードウェアは、パフォーマンス/面積/電力のメトリクスを毎年向上させ、ソフトウェアの複雑さを拡張し、デメリットなしでより多くの機能を提供できるようになりました。その後、簡単に勝つことは簡単ではなくなりました。より高度なプロセスにより、単位面積あたりのゲート数は引き続き増加しましたが、パフォーマンスと消費電力の向上は横ばいになり始めました。イノベーションへの期待が止まらないため、ハードウェア アーキテクチャの進歩は、その余裕を取り戻す上でより重要になってきています。

コア数を増やすためのドライバー
この方向の初期のステップでは、マルチコア CPU を使用して、コア間で同時タスクの混合をスレッド化または仮想化することで合計スループットを加速し、アイドル状態または非アクティブなコアの電源をオフにすることで必要に応じて電力を削減しました。現在ではマルチコアが標準となっており、AWS、Azure、Alibaba などのクラウド プラットフォームで利用できるサーバー インスタンス オプションではメニーコア (チップ上のさらに多くの CPU) の傾向がすでに明らかです。
マルチ/メニーコア アーキテクチャは前進ですが、CPU クラスタによる並列処理は粒度が粗く、アムダールの法則により、独自のパフォーマンスと電力制限があります。アーキテクチャはより異種混合となり、画像、オーディオ、その他の特殊なニーズに対応するアクセラレータが追加されました。 AI アクセラレータはまた、きめ細かい並列処理を推進し、シストリック アレイやその他のドメイン固有の技術に移行しています。これは、ChatGPT が 175 億のパラメーターを備えて登場し、GPT-3 が 4 兆のパラメーターを備えた GPT-100 に進化するまでは非常にうまく機能していましたが、これは今日の AI システムよりも桁違いに複雑で、AI アクセラレーター内にさらに特化した加速機能が強制されています。
別の面では、自動車アプリケーションのマルチセンサー システムは現在、環境認識の向上と PPA の向上のために単一の SoC に統合されています。ここで、自動車における新たなレベルの自律性は、2X、4X、または 8X で複製されるサブシステム内で、単一デバイス内の複数のセンサー タイプからの入力を融合することにかかっています。
Michał Siwinski (Arteris の CMO) 氏によると、さまざまなアプリケーションにわたる複数の設計チームとの 1 か月にわたる議論のサンプリングにより、これらのチームが機能、パフォーマンス、電力の目標を達成するためにコア数の増加に積極的に取り組んでいることがわかります。同氏は、彼らもこの傾向が加速していると見ていると語った。プロセスの進歩は依然として SoC ゲート数の向上に役立ちますが、パフォーマンスと電力の目標を達成する責任はアーキテクトの手にしっかりと委ねられています。
より多くのコア、より多くの相互接続
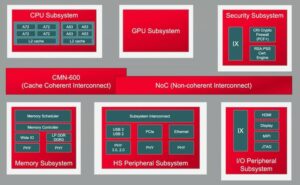
チップ上のコアが増えると、それらのコア間のデータ接続が増えることになります。隣接する処理要素間のアクセラレータ内で、ローカル キャッシュに、スパース行列やその他の特殊な処理用のアクセラレータに。アクセラレータ タイルとシステム レベルのバスの間に階層接続を追加します。オンチップの重量ストレージ、解凍、ブロードキャスト、収集、再圧縮のための接続を追加します。作業キャッシュ用の HBM 接続を追加します。必要に応じてフュージョン エンジンを追加します。
CPU ベースの制御クラスターは、これらの複製されたサブシステムのそれぞれと、必要に応じてコーデック、メモリ管理、セーフティ アイランド、および信頼のルート、マルチチップレット実装の場合は UCIe、高帯域幅 I/O の場合は PCIe など、すべての通常の機能に接続する必要があります。 、ネットワーク用のイーサネットまたはファイバー。
これは大量の相互接続であり、製品の市場性に直接影響します。 16nm 未満のプロセスでは、NoC インフラストラクチャが面積で 10 ~ 12% を占めるようになりました。さらに重要なのは、コア間の通信ハイウェイとして、パフォーマンスと電力に大きな影響を与える可能性があることです。最適化されていない実装では、期待されるアーキテクチャのパフォーマンスと電力ゲインが浪費され、さらに悪いことに、収束するために多数の再設計ループが発生するという現実の危険があります。しかし、複雑な SoC フロアプランで適切な実装を見つけるには、すでに厳しい設計スケジュールの中で最適化をゆっくりと試行錯誤する必要があります。複雑な NoC 階層からの完全なパフォーマンスと電力サポートを保証するには、物理的に認識した NoC 設計に移行する必要があり、これらの最適化を高速化する必要があります。
物理的に意識した NoC 設計によりムーアの法則を軌道に乗せます
ムーアの法則は死んだわけではないかもしれませんが、今日のパフォーマンスと消費電力の進歩は、プロセスではなくアーキテクチャと NoC インターコネクトによってもたらされています。アーキテクチャは、より多くのアクセラレータ コア、より多くのアクセラレータ内のアクセラレータ、およびより多くのサブシステム レプリケーションをオンチップで推進しています。いずれもオンチップ相互接続の複雑さを増大させます。設計のコア数が増加し、16nm 以下のプロセス ジオメトリに移行するにつれて、SoC とそのサブシステムにまたがる多数の NoC 相互接続は、物理的およびタイミングの制約に対して、物理的に認識されたネットワークを通じて最適に実装された場合にのみ、これらの複雑な設計の可能性を最大限にサポートできます。オンチップ設計。
これらの傾向についても心配している場合は、Arteris FlexNoC 5 IP テクノロジーについて詳しく学ぶことをお勧めします。 こちら.
この投稿を共有する:
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://semiwiki.com/artificial-intelligence/326727-interconnect-under-the-spotlight-as-core-counts-accelerate/
- :は
- $UP
- 100
- a
- 私たちについて
- 加速する
- 加速している
- 加速
- 加速器
- 加速器
- 越えて
- 積極的に
- 高度な
- 進歩
- に対して
- AI
- AIシステム
- アリババ
- すべて
- 許可
- 既に
- および
- 登場
- 適切な
- 建築
- です
- AREA
- AS
- At
- オーディオ
- 自動車
- 利用できます
- 認知度
- AWS
- Azure
- 帯域幅
- BE
- になる
- 以下
- の間に
- 10億
- 放送
- バス
- by
- キャッシュ
- 缶
- できる
- AI言語モデルを活用してコードのデバッグからデータの異常検出まで、
- チップ
- クラウド
- クラスタ
- 最高マーケティング責任者
- 来ます
- コミュニケーション
- 複雑な
- 複雑さ
- 計算
- 同時
- お問合せ
- Connections
- 接続性
- 結果
- 制約
- 継続します
- コントロール
- 収束する
- 基本
- CPU
- 危険
- データ
- 死んだ
- 配信する
- 配信
- 依存
- 設計
- デザイン
- デバイス
- 異なります
- 直接
- 方向
- 議論
- ダウン
- 欠点
- 各
- 早い
- 要素は
- エンジン
- 環境
- さらに
- あらゆる
- 進化
- 進化
- 詳細
- 期待
- 予想される
- 速いです
- 特徴
- 発見
- 固く
- フォワード
- 無料版
- から
- フロント
- フル
- 機能
- 融合
- 利益
- 目標
- 良い
- 保証
- ハンドリング
- ハンド
- Hardware
- 持ってる
- 助けます
- こちら
- ハイ
- より高い
- 高速道路
- HTTPS
- 画像
- 影響
- 実装
- 実装
- 重要
- 改善されました
- in
- 非アクティブな
- 増える
- の増加
- インフラ
- 革新的手法
- 統合
- IP
- 島
- IT
- ITS
- ジャンプ
- 法律
- LEARN
- レベル
- レベル
- 制限
- ローカル
- たくさん
- make
- 管理
- 3月
- マトリックス
- 最大幅
- 大会
- ご相談
- メモリ
- メトリック
- かもしれない
- 月
- 他には?
- 移動する
- の試合に
- 必要
- 必要とされる
- ニーズ
- ネットワーク
- ネットワーキング
- 新作
- 多数の
- of
- on
- オプション
- 受注
- その他
- その他
- 自分の
- パラメータ
- パフォーマンス
- 物理的な
- 物理的に
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポスト
- 潜在的な
- 電力
- 電源
- かなり
- プロセス
- ラボレーション
- 処理
- プロダクト
- 純粋に
- プッシュ
- 押す
- 範囲
- むしろ
- リアル
- 縮小
- 複製された
- レプリケーション
- 責任
- 結果
- Ride
- ルート
- 安全性
- 半導体
- 重要
- から
- スラック
- 遅く
- より小さい
- So
- ソフトウェア
- スパース行列
- 専門の
- スポットライト
- 標準
- 開始
- 手順
- まだ
- Force Stop
- ストレージ利用料
- 提案する
- サポート
- システム
- タスク
- チーム
- テクニック
- テクノロジー
- 伝える
- それ
- ボーマン
- 介して
- スループット
- タイミング
- 〜へ
- 今日
- 今日の
- トータル
- トレンド
- トレンド
- 1兆
- 信頼
- ターニング
- 下
- 単位
- 、
- 重量
- WELL
- which
- ワイド
- 広い範囲
- 意志
- 勝
- 以内
- ワーキング
- 年
- 年
- ゼファーネット