業界全体での LLM の導入は一見止められないように見えますが、LLM は新しい AI の波を推進する広範なテクノロジー エコシステムの 2 つのコンポーネントです。 会話型 AI のユースケースの多くでは、ユーザーのクエリに応答するために Llama 5、Flan TXNUMX、Bloom などの LLM が必要です。 これらのモデルは、パラメトリックな知識に依存して質問に答えます。 モデルはトレーニング中にこの知識を学習し、それをモデル パラメーターにエンコードします。 この知識を更新するには、LLM を再トレーニングする必要があり、これには多大な時間と費用がかかります。
幸いなことに、ソースの知識を使用して LLM に情報を提供することもできます。 ソース知識は、入力プロンプトを通じて LLM に入力される情報です。 ソース知識を提供する一般的なアプローチの XNUMX つは、検索拡張生成 (RAG) です。 RAG を使用して、外部データ ソースから関連情報を取得し、その情報を LLM にフィードします。
このブログ投稿では、Amazon Sagemaker JumpStart を使用して Llama-2 などの LLM をデプロイし、AI 幻覚を防ぐために、Pinecone ベクター データベースを使用した検索拡張生成 (RAG) を通じて LLM を関連情報で最新の状態に保つ方法を説明します。 。
Amazon SageMaker の検索拡張生成 (RAG)
Pinecone は RAG の取得コンポーネントを処理しますが、さらに XNUMX つの重要なコンポーネントが必要です。LLM 推論を実行する場所と、埋め込みモデルを実行する場所です。
Amazon SageMaker Studio は、単一の Web ベースのビジュアルインターフェイスを提供する統合開発環境 (IDE) で、専用ツールにアクセスしてすべての機械学習 (ML) 開発を実行できます。 これは、ユーザーが自分の SageMaker アカウントで特定のモデルを検索、プレビュー、起動できるモデル ハブである SageMaker JumpStart を提供します。 基礎モデルを含む幅広い問題タイプに対応する、事前トレーニング済みの公開されている独自のモデルを提供します。
Amazon SageMaker Studio は、RAG 対応の LLM パイプラインを開発するための理想的な環境を提供します。 まず、AWS コンソールを使用して、Amazon SageMaker に移動し、SageMaker Studio ドメインを作成し、Jupyter Studio ノートブックを開きます。
前提条件
次の前提条件の手順を実行します。
- Amazon SageMaker Studio をセットアップします。
- Amazon SageMaker ドメインにオンボードします。
- 無料枠の松ぼっくりベクトル データベースにサインアップしてください。
- 前提条件ライブラリ: SageMaker Python SDK、Pinecone クライアント
ソリューションウォークスルー
SageMaker Studio ノートブックを使用して、まず前提条件のライブラリをインストールする必要があります。
LLM の導入
この投稿では、LLM を展開する XNUMX つのアプローチについて説明します。 XNUMXつ目は、 HuggingFaceModel 物体。 これは、Hugging Face モデル ハブから直接 LLM (および埋め込みモデル) をデプロイするときに使用できます。
たとえば、デプロイ可能な構成を作成できます。 google/flan-t5-xl 次のスクリーン キャプチャに示すようにモデルを作成します。
Hugging Face からモデルを直接デプロイする場合は、 my_model_configuration 次のように:
- An
envconfig は、どのモデルをどのタスクに使用するかを示します。 - SageMaker の実行
roleモデルをデプロイする権限を与えます。 - An
image_uriは、Hugging Face から LLM を展開するための専用のイメージ構成です。
あるいは、SageMaker には、より単純なモデルと直接互換性のある一連のモデルがあります。 JumpStartModel 物体。 Llama 2 などの多くの人気のある LLM がこのモデルでサポートされており、次のスクリーン キャプチャに示すように初期化できます。
両方のバージョンの場合、 my_model、次のスクリーン キャプチャに示すように、それらをデプロイします。
初期化された LLM エンドポイントを使用して、クエリを開始できます。 クエリの形式は (特に会話型 LLM と非会話型 LLM の間で) 異なる場合がありますが、プロセスは一般に同じです。 ハグ顔モデルの場合は、次の手順を実行します。
解決策は次のとおりです。 GitHubリポジトリ.
ここで私たちが受け取っている生成された答えはあまり意味がありません - それは幻覚です。
LLM への追加コンテキストの提供
Llama 2 は、内部パラメトリック知識のみに基づいて私たちの質問に答えようとします。 明らかに、モデル パラメーターには、SageMaker のマネージド スポット トレーニングでどのインスタンスが使用できるかについての情報は保存されていません。
この質問に正しく答えるには、情報源の知識を使用する必要があります。 つまり、プロンプトを介して追加情報を LLM に提供します。 その情報をモデルの追加コンテキストとして直接追加しましょう。
これで、質問に対する正しい答えがわかりました。 それは簡単でした! ただし、ユーザーはプロンプトにコンテキストを挿入する可能性は低く、質問に対する答えをすでに知っているはずです。
単一のコンテキストを手動で挿入するのではなく、より広範な情報データベースから関連する情報を自動的に識別します。 そのためには、検索拡張生成が必要です。
検索拡張生成
検索拡張生成を使用すると、情報のデータベースをベクトル空間にエンコードでき、ベクトル間の近接性が関連性/意味論的な類似性を表します。 このベクトル空間を知識ベースとして使用すると、新しいユーザー クエリを変換し、同じベクトル空間にエンコードして、以前にインデックス付けされた最も関連性の高いレコードを取得できます。
これらの関連レコードを取得した後、それらのレコードをいくつか選択し、追加のコンテキストとして LLM プロンプトに含めて、LLM に関連性の高いソースの知識を提供します。 これは XNUMX 段階のプロセスであり、次のとおりです。
- インデックス付けでは、データセットからの情報をベクトル インデックスに入力します。
- 検索はクエリ中に行われ、ベクトル インデックスから関連情報を取得します。
どちらのステップでも、人間が読めるプレーン テキストをセマンティック ベクトル空間に変換するための埋め込みモデルが必要です。 次のスクリーン キャプチャに示すように、Hugging Face の高効率 MiniLM センテンス トランスフォーマーを使用します。 このモデルは LLM ではないため、Llama 2 モデルと同じ方法では初期化されません。
hub_configでは、上のスクリーン キャプチャに示されているようにモデル ID を指定しますが、LLM のようなテキストではなくベクトル埋め込みを生成しているため、タスクでは特徴抽出を使用します。 これに続いて、モデル構成を次のように初期化します。 HuggingFaceModel 前と同様ですが、今回は LLM イメージを使用せず、いくつかのバージョン パラメーターを使用します。
次のようにモデルを再度デプロイできます。 deploy、より小さい (CPU のみ) インスタンスを使用します。 ml.t2.large。 MiniLM モデルは小さいため、大量のメモリを必要とせず、CPU 上でもエンベディングをすばやく作成できるため、GPU も必要ありません。 必要に応じて、GPU でモデルをより高速に実行できます。
埋め込みを作成するには、 predict メソッドを使用し、エンコードするコンテキストのリストを、 inputs 図に示すようにキー:
XNUMX つの入力コンテキストが渡され、次に示すように XNUMX つのコンテキスト ベクトル埋め込みが返されます。
len(out)
2
MiniLM モデルの埋め込み次元は次のとおりです。 384 つまり、MiniLM 出力を埋め込む各ベクトルの次元は次のようになります。 384。 ただし、埋め込みの長さに注目すると、次のことがわかります。
len(out[0]), len(out[1])
(8, 8)
XNUMX つのリストにはそれぞれ XNUMX つの項目が含まれます。 MiniLM は、最初にトークン化ステップでテキストを処理します。 このトークン化により、人間が判読可能なプレーン テキストがモデルが判読可能なトークン ID のリストに変換されます。 モデルの出力特徴では、トークンレベルの埋め込みを確認できます。 これらの埋め込みの XNUMX つは、予想される次元を示しています。 384 示されているように:
len(out[0][0])
384
次の図に示すように、各ベクトル次元の平均値を使用して、これらのトークン レベルの埋め込みをドキュメント レベルの埋め込みに変換します。
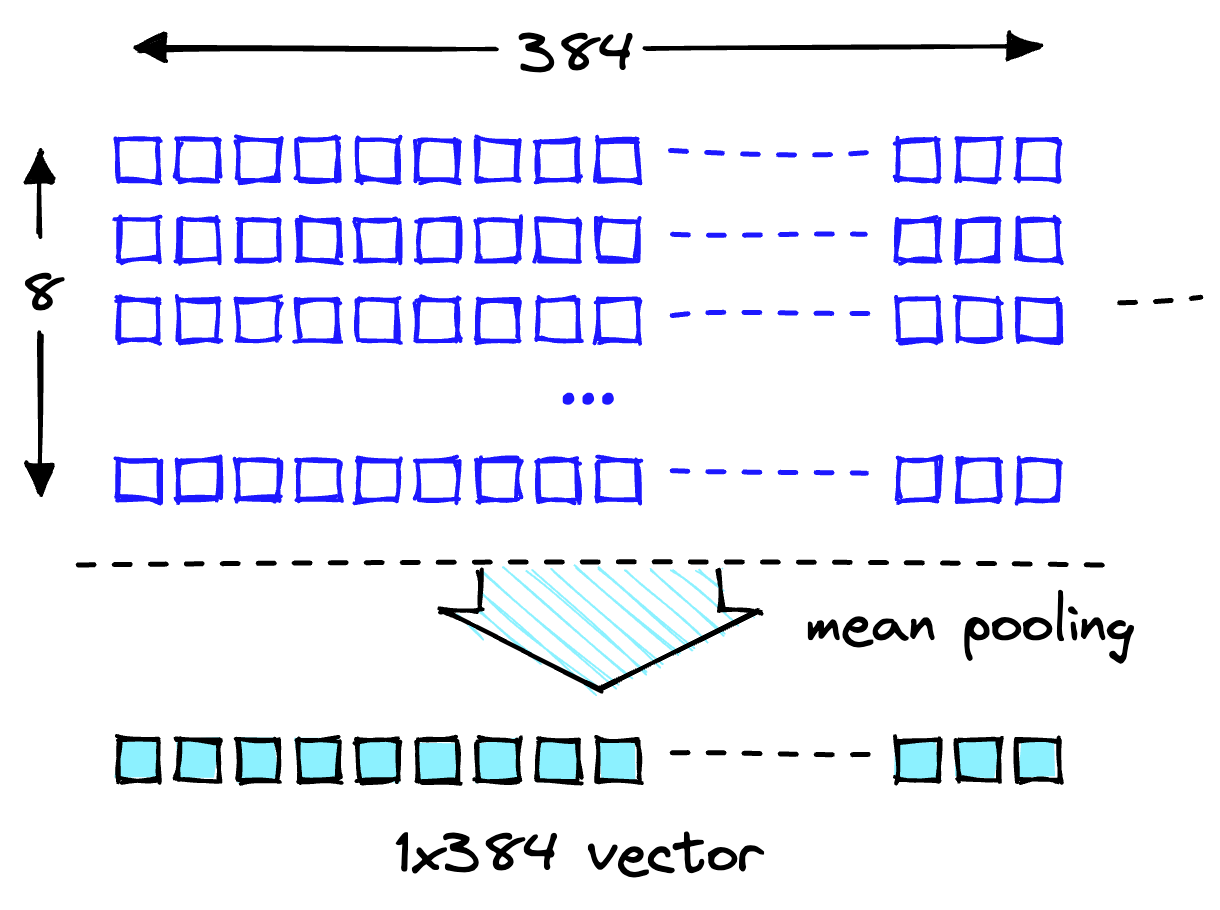
単一の 384 次元ベクトルを取得するための平均プーリング操作。
384 つの XNUMX 次元ベクトル埋め込み (入力テキストごとに XNUMX つ) を使用します。 作業を容易にするために、次のスクリーン キャプチャに示すように、エンコード プロセスを XNUMX つの関数にラップします。
データセットのダウンロード
Amazon SageMaker FAQ をナレッジベースとしてダウンロードして、質問列と回答列の両方を含むデータを取得します。

Amazon SageMaker FAQ をダウンロードする
検索を実行するときは、[質問] 列を削除できるように、[回答] のみを探します。 詳細についてはノートブックを参照してください.
データセットと埋め込みパイプラインの準備が整いました。 ここで必要なのは、それらの埋め込みを保存する場所だけです。
インデキシング
Pinecone ベクトル データベースは、ベクトルの埋め込みを保存し、大規模に効率的に検索します。 データベースを作成するには、Pinecone からの無料の API キーが必要です。
Pinecone ベクトル データベースに接続した後、単一のベクトル インデックス (従来の DB のテーブルと同様) を作成します。 インデックスに名前を付けます retrieval-augmentation-aws そしてインデックスを揃えます dimension および metric パラメータを、埋め込みモデル (この場合は MiniLM) で必要なパラメータと組み合わせます。
データの挿入を開始するには、次のコマンドを実行します。
この投稿の前半の質問を使用して、インデックスのクエリを開始できます。
上記の出力は、質問への回答に役立つ関連コンテキストを返していることを示しています。 私たち以来 top_k = 1, index.query 以下のメタデータとともにトップの結果を返しました。 Managed Spot Training can be used with all instances supported in Amazon.
プロンプトの拡張
取得したコンテキストを使用してプロンプトを拡張し、LLM に供給するコンテキストの最大量を決定します。 使用 1000 コンテンツの長さを超えるまで、返された各コンテキストをプロンプトに繰り返し追加できる文字数制限があります。
プロンプトの拡張
フィード context_str 次のスクリーン キャプチャに示すように、LLM プロンプトに入力します。
[入力]: SageMaker のマネージド スポット トレーニングで使用できるインスタンスはどれですか? [出力]: 提供されたコンテキストに基づいて、Amazon SageMaker でサポートされているすべてのインスタンスでマネージド スポット トレーニングを使用できます。 したがって、答えは次のとおりです。Amazon SageMaker ではすべてのインスタンスがサポートされています。
ロジックは機能するため、処理をきれいに保つために単一の関数にラップします。
次のような質問ができるようになりました。
クリーンアップ
不要な料金が発生しないようにするには、モデルとエンドポイントを削除します。
まとめ
この投稿では、SageMaker 上のオープンアクセス LLM を使用した RAG について紹介しました。 また、Llama 2 を使用した Amazon SageMaker Jumpstart モデル、Flan T5 を使用した Hugging Face LLM、および MiniLM を使用した埋め込みモデルをデプロイする方法も示しました。
オープンアクセス モデルと Pinecone ベクトル インデックスを使用して、完全なエンドツーエンドの RAG パイプラインを実装しました。 これを使用して、幻覚を最小限に抑え、LLM の知識を最新の状態に保ち、最終的にシステムに対するユーザー エクスペリエンスと信頼性を高める方法を示しました。
この例を自分で実行するには、この GitHub リポジトリのクローンを作成し、次のコマンドを使用して前の手順を実行します。 GitHub の質問応答ノートブック.
著者について
 ヴェダントジャイン はシニア AI/ML スペシャリストであり、戦略的な生成 AI イニシアチブに取り組んでいます。 AWS に入社する前、Vedant は Databricks、Hortonworks (現 Cloudera)、JP Morgan Chase などのさまざまな企業で ML/データ サイエンスの専門職を歴任してきました。 仕事以外では、ヴェダントは音楽制作、ロック クライミング、科学を利用して有意義な生活を送ること、世界中の料理を探求することに情熱を注いでいます。
ヴェダントジャイン はシニア AI/ML スペシャリストであり、戦略的な生成 AI イニシアチブに取り組んでいます。 AWS に入社する前、Vedant は Databricks、Hortonworks (現 Cloudera)、JP Morgan Chase などのさまざまな企業で ML/データ サイエンスの専門職を歴任してきました。 仕事以外では、ヴェダントは音楽制作、ロック クライミング、科学を利用して有意義な生活を送ること、世界中の料理を探求することに情熱を注いでいます。
 ジェームズ・ブリッグス Pinecone のスタッフ開発者アドボケートであり、ベクトル検索と AI/ML を専門としています。 彼は、オンライン教育を通じて開発者や企業が独自の GenAI ソリューションを開発できるよう指導しています。 Pinecone に入社する前は、James は小規模なテクノロジー関連の新興企業から既存の金融会社まで AI の開発に取り組んでいました。 仕事以外では、ジェームズは旅行に情熱を持っており、サーフィンやスキューバからムエタイやブラジリアン柔術に至るまで、新しい冒険を楽しむことに情熱を持っています。
ジェームズ・ブリッグス Pinecone のスタッフ開発者アドボケートであり、ベクトル検索と AI/ML を専門としています。 彼は、オンライン教育を通じて開発者や企業が独自の GenAI ソリューションを開発できるよう指導しています。 Pinecone に入社する前は、James は小規模なテクノロジー関連の新興企業から既存の金融会社まで AI の開発に取り組んでいました。 仕事以外では、ジェームズは旅行に情熱を持っており、サーフィンやスキューバからムエタイやブラジリアン柔術に至るまで、新しい冒険を楽しむことに情熱を持っています。
 シンファン Amazon SageMaker JumpStart および Amazon SageMaker 組み込みアルゴリズムの上級応用科学者です。 スケーラブルな機械学習アルゴリズムの開発に注力しています。 彼の研究対象は、自然言語処理、表形式データの説明可能なディープ ラーニング、およびノンパラメトリック時空クラスタリングの堅牢な分析の分野です。 彼は、ACL、ICDM、KDD カンファレンス、Royal Statistical Society: Series A で多くの論文を発表しています。
シンファン Amazon SageMaker JumpStart および Amazon SageMaker 組み込みアルゴリズムの上級応用科学者です。 スケーラブルな機械学習アルゴリズムの開発に注力しています。 彼の研究対象は、自然言語処理、表形式データの説明可能なディープ ラーニング、およびノンパラメトリック時空クラスタリングの堅牢な分析の分野です。 彼は、ACL、ICDM、KDD カンファレンス、Royal Statistical Society: Series A で多くの論文を発表しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/mitigate-hallucinations-through-retrieval-augmented-generation-using-pinecone-vector-database-llama-2-from-amazon-sagemaker-jumpstart/
- :持っている
- :は
- :not
- :どこ
- $UP
- 1
- 10
- 100
- 11
- 12
- 14
- 視聴者の38%が
- 16
- 17
- 19
- 23
- 32
- 7
- 8
- 9
- 90
- a
- 私たちについて
- 上記の.
- アクセス
- 従った
- 越えて
- 加えます
- NEW
- 追加情報
- 養子縁組
- 冒険
- 支持者
- 再び
- AI
- aiのユースケース
- AI / ML
- アルゴリズム
- 整列する
- すべて
- 沿って
- 既に
- また
- Amazon
- アマゾンセージメーカー
- Amazon SageMaker ジャンプスタート
- Amazon SageMakerスタジオ
- Amazon Webサービス
- 量
- an
- 分析
- および
- 回答
- 回答
- どれか
- API
- アプリ
- 適用された
- アプローチ
- アプローチ
- です
- AREA
- 周りに
- AS
- 頼む
- At
- 試み
- 増強
- 増強された
- オート
- 自動的に
- 利用できます
- AWS
- ベース
- ベース
- BE
- なぜなら
- 始まる
- の間に
- ブログ
- ブルーム
- 両言語で
- より広い
- ビルド
- 内蔵
- ビジネス
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 缶
- キャプチャー
- 場合
- 例
- 文字
- 課金
- チェイス
- はっきりと
- クライミング
- クルデラ
- クラスタリング
- コラム
- コラム
- 企業
- 互換性のあります
- コンプリート
- コンポーネント
- コンポーネント
- 会議
- 交流
- 領事
- 含む
- 含まれています
- コンテンツ
- コンテキスト
- 文脈
- 会話
- 会話型AI
- 変換
- 法人
- 正しい
- CPU
- 作ります
- 重大な
- 現在
- データ
- データベース
- データブリック
- 日付
- DBS
- 決めます
- 深いです
- 深い学習
- 展開します
- 展開する
- Developer
- 開発者
- 開発
- 開発
- 次元
- 直接に
- 話し合います
- do
- ありません
- doesnの
- そうではありません
- ドメイン
- ドン
- Drop
- 間に
- 各
- 前
- 容易
- エコシステム
- 教育
- 効率的な
- 効率良く
- 埋め込み
- 受け入れ
- エンコーディング
- end
- 端から端まで
- エンドポイント
- 高めます
- 環境
- 設立
- エーテル(ETH)
- さらに
- 例
- 超えます
- 実行
- 予想される
- 体験
- 探る
- 探る
- 広範囲
- 外部
- エキス
- 顔
- 速いです
- 特徴
- FRBは
- 少数の
- ファイナンス
- もう完成させ、ワークスペースに掲示しましたか?
- 仕上げ
- 名
- フロート
- 焦点を当てて
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- Foundation
- 無料版
- から
- function
- 一般に
- 生成された
- 生成
- 世代
- 生々しい
- 生成AI
- 取得する
- GitHubの
- 与える
- 与えられた
- 与える
- Go
- ゴエス
- GPU
- ガイド
- ハンドル
- 起こります
- 持ってる
- he
- ヒーロー
- 助けます
- こちら
- 非常に
- 彼の
- 認定条件
- How To
- しかしながら
- HTTPS
- 黄
- ハブ
- 抱き合う顔
- 人間が読める
- i
- IAM
- ID
- 理想
- 識別する
- イド
- if
- 画像
- 実装
- import
- in
- include
- 含めて
- 増える
- index
- 索引付けされた
- 産業
- 知らせます
- 情報
- イニシアチブ
- 入力
- install
- インスタンス
- 統合された
- 利益
- インタフェース
- 内部
- に
- 導入
- IT
- リーディングシート
- ジェームズ
- 参加
- JPモルガン
- JPモルガン·チェース
- JPG
- キープ
- キー
- 知っている
- 知識
- 言語
- 大
- より大きい
- 起動する
- つながる
- 学習
- 長さ
- ライブラリ
- 生活
- ような
- LIMIT
- リスト
- リスト
- 命
- ラマ
- ロジック
- 見て
- 探して
- たくさん
- 機械
- 機械学習
- make
- 作成
- マネージド
- 手動で
- 多くの
- 一致
- マッチ
- 最大額
- 五月..
- 意味する
- 意味のある
- 手段
- メモリ
- 方法
- 最小限に抑えます
- 軽減する
- ML
- モデル
- お金
- 他には?
- モーガン
- 最も
- ずっと
- の試合に
- 音楽を聴く際のスピーカーとして
- しなければなりません
- 名
- ナチュラル
- 自然言語
- 自然言語処理
- 必要
- ニーズ
- 新作
- 次の
- NLP
- ノート
- 今
- numpy
- オブジェクト
- of
- on
- ONE
- オンライン
- オンライン教育
- の
- 開いた
- 操作
- or
- 注文
- OS
- さもないと
- 私たちの
- でる
- 出力
- outputs
- 外側
- 自分の
- 論文
- パラメータ
- 特定の
- 特に
- パス
- 渡された
- 情熱
- 情熱的な
- 実行する
- 実行
- パーミッション
- 画像
- パイプライン
- シンプルスタイル
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 人気
- ポジション
- ポスト
- 電源
- 予測
- 予測
- Predictor
- 優先
- 防ぐ
- プレビュー
- 前
- 前に
- 事前の
- 問題
- プロセス
- ラボレーション
- 処理
- プロフィール
- プロンプト
- 所有権
- 提供
- は、大阪で
- 提供
- 公然と
- 公表
- Python
- パイトーチ
- クエリ
- 質問
- 質問
- すぐに
- 範囲
- 測距
- 準備
- 受け入れ
- 記録
- 地域
- 関連した
- 頼る
- 倉庫
- 表し
- 必要とする
- の提出が必要です
- 研究
- 反応します
- 結果
- 結果
- return
- 返す
- 堅牢な
- 岩
- 職種
- ロイヤル
- ラン
- runs
- セージメーカー
- 同じ
- 言う
- ド電源のデ
- 規模
- 科学
- 科学者
- スコア
- 画面
- SDDK
- を検索
- 検索
- select
- シニア
- センス
- 文
- シリーズ
- シリーズA
- サービス
- セッションに
- すべき
- 表示する
- 示されました
- 示す
- 作品
- 側
- 同様の
- から
- サイズ
- 小さい
- より小さい
- So
- 社会
- もっぱら
- 溶液
- ソリューション
- 一部
- どこか
- ソース
- スペース
- 専門家
- 特化
- 専門
- 特に
- Spot
- スタッフ
- スタートアップ
- 統計的
- 手順
- ステップ
- Force Stop
- 店舗
- 店舗
- 戦略的
- 文字列
- 研究
- そのような
- サポート
- サポート
- サポート
- システム
- T
- テーブル
- 取り
- 仕事
- テク
- ハイテクスタートアップ
- テクノロジー
- 伝える
- 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO 많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다.
- タイ
- より
- それ
- エリア
- 世界
- アプリ環境に合わせて
- それら
- したがって、
- ボーマン
- 彼ら
- 物事
- この
- それらの
- 介して
- 時間
- 〜へ
- トークン
- トークン化
- あまりに
- 豊富なツール群
- top
- 伝統的な
- トレーニング
- トランス
- トランスフォーマー
- トランスフォーム
- 翻訳する
- 旅行
- 信頼
- 2
- 最終的に
- ありそうもない
- 止められない。
- まで
- 不要な
- アップデイト
- URI
- us
- つかいます
- 中古
- ユーザー
- 操作方法
- users
- 価値観
- さまざまな
- バージョン
- 、
- ビジュアル
- wait
- ウォークスルー
- 欲しいです
- ました
- ウェーブ
- 仕方..
- we
- ウェブ
- Webサービス
- ウェブベースの
- この試験は
- いつ
- which
- while
- ワイド
- 広い範囲
- 意志
- 無し
- 仕事
- 働いていました
- ワーキング
- 作品
- 世界
- でしょう
- ラップ
- X
- はい
- 貴社
- あなたの
- ゼファーネット