OpenAIウィスパー は、MIT ライセンスを備えた高度な自動音声認識 (ASR) モデルです。 ASR テクノロジーは、文字起こしサービス、音声アシスタント、聴覚障害を持つ個人のアクセシビリティの向上に役立ちます。この最先端のモデルは、Web から収集された多言語およびマルチタスクの教師付きデータの膨大で多様なデータセットでトレーニングされます。その高い精度と適応性により、音声関連のさまざまなタスクにとって貴重な資産となります。
機械学習と人工知能の進化し続ける状況の中で、 アマゾンセージメーカー 包括的なエコシステムを提供します。 SageMaker は、データ サイエンティスト、開発者、組織が機械学習モデルを大規模に開発、トレーニング、展開、管理できるようにします。幅広いツールと機能を提供し、データの前処理やモデル開発から、簡単な導入や監視に至るまで、機械学習のワークフロー全体を簡素化します。 SageMaker のユーザーフレンドリーなインターフェイスは、AI の可能性を最大限に引き出すための極めて重要なプラットフォームとなり、人工知能の分野における革新的なソリューションとして確立されます。
この投稿では、特に Whisper モデルのホスティングに焦点を当てて、SageMaker の機能の探索に着手します。これを行うための 2 つの方法について詳しく説明します。1 つは Whisper PyTorch モデルを使用し、もう 1 つは Whisper モデルの Hugging Face 実装を使用します。さらに、SageMaker の推論オプションの詳細な調査を実施し、速度、コスト、ペイロード サイズ、スケーラビリティなどのパラメータにわたって比較します。この分析により、ユーザーは Whisper モデルを特定のユースケースやシステムに統合する際に、情報に基づいた意思決定を行うことができます。
ソリューションの概要
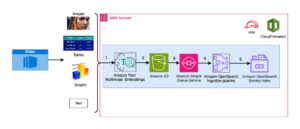
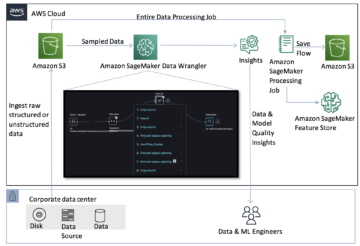
次の図は、このソリューションの主なコンポーネントを示しています。
- Amazon SageMaker でモデルをホストするには、最初のステップはモデルのアーティファクトを保存することです。これらのアーティファクトは、デプロイメントや再トレーニングなど、さまざまなアプリケーションに必要な機械学習モデルの重要なコンポーネントを指します。これらには、モデル パラメーター、構成ファイル、前処理コンポーネントに加えて、バージョンの詳細、作成者、パフォーマンスに関連するメモなどのメタデータを含めることができます。 PyTorch および Hugging Face 実装の Whisper モデルは、異なるモデル アーティファクトで構成されていることに注意することが重要です。
- 次に、カスタム推論スクリプトを作成します。これらのスクリプト内で、モデルのロード方法を定義し、推論プロセスを指定します。ここには、必要に応じてカスタム パラメーターを組み込むこともできます。さらに、必要な Python パッケージを
requirements.txtファイル。モデルのデプロイ中に、これらの Python パッケージが初期化フェーズで自動的にインストールされます。 - 次に、によって提供および保守されている PyTorch または Hugging Face ディープ ラーニング コンテナ (DLC) を選択します。 AWS。これらのコンテナーは、深層学習フレームワークおよびその他の必要な Python パッケージを備えた事前に構築された Docker イメージです。詳細については、これを確認してください .
- モデルアーティファクト、カスタム推論スクリプト、および選択した DLC を使用して、PyTorch と Hugging Face 用の Amazon SageMaker モデルをそれぞれ作成します。
- 最後に、モデルを SageMaker にデプロイし、リアルタイム推論エンドポイント、バッチ変換ジョブ、非同期推論エンドポイントのオプションとともに使用できます。これらのオプションについては、この投稿の後半で詳しく説明します。
このソリューションのサンプル ノートブックとコードは、ここから入手できます。 GitHubリポジトリ.
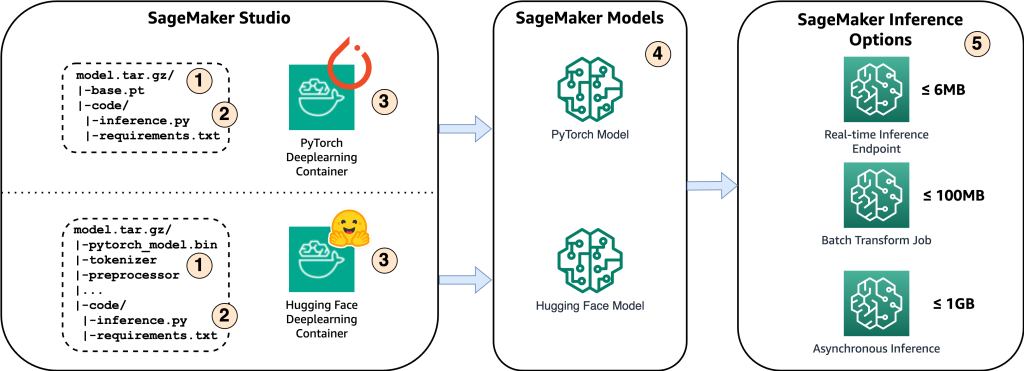
図 1. 主要なソリューション コンポーネントの概要
チュートリアル
Amazon SageMaker での Whisper モデルのホスト
このセクションでは、PyTorch と Hugging Face Frameworks をそれぞれ使用して、Amazon SageMaker で Whisper モデルをホストする手順を説明します。このソリューションを実験するには、AWS アカウントと Amazon SageMaker サービスへのアクセスが必要です。
PyTorchフレームワーク
- モデルアーティファクトを保存する
モデルをホストする最初のオプションは、 Whisper 公式 Python パッケージを使用してインストールできます。 pip install openai-whisper。このパッケージは PyTorch モデルを提供します。モデル アーティファクトをローカル リポジトリに保存する場合、最初のステップは、ニューラル ネットワークの各層のモデルの重みやバイアスなどのモデルの学習可能なパラメーターを「pt」ファイルとして保存することです。 「小型」、「ベース」、「小型」、「中型」、「大型」など、さまざまなモデル サイズから選択できます。モデル サイズが大きいほど、精度の高いパフォーマンスが得られますが、推論のレイテンシが長くなります。さらに、モデル状態ディクショナリとディメンション ディクショナリを保存する必要があります。これらには、PyTorch モデルの各レイヤーまたはパラメータを、他のメタデータやカスタム構成とともに、対応する学習可能なパラメータにマップする Python ディクショナリが含まれています。以下のコードは、Whisper PyTorch アーティファクトを保存する方法を示しています。
- DLCを選択
次のステップは、この中から事前に構築された DLC を選択することです。 。正しいイメージを選択するときは、フレームワーク (PyTorch)、フレームワークのバージョン、タスク (推論)、Python のバージョン、ハードウェア (GPU) の設定を考慮して注意してください。可能な限りフレームワークと Python の最新バージョンを使用することをお勧めします。これにより、パフォーマンスが向上し、以前のリリースの既知の問題やバグに対処できるようになります。
- Amazon SageMaker モデルを作成する
次に活用するのは、 SageMaker Python SDK PyTorch モデルを作成します。 PyTorch モデルを作成するときは、環境変数を忘れずに追加することが重要です。デフォルトでは、TorchServe は、使用される推論タイプに関係なく、最大 6MB のファイル サイズのみを処理できます。
次の表は、さまざまな PyTorch バージョンの設定を示しています。
| フレームワーク | 環境変数 |
| PyTorch 1.8 (TorchServe ベース) | 'TS_MAX_REQUEST_SIZE': '100000000'' TS_MAX_RESPONSE_SIZE': '100000000'' TS_DEFAULT_RESPONSE_TIMEOUT': '1000' |
| PyTorch 1.4 (MMS ベース) | 'MMS_MAX_REQUEST_SIZE': '1000000000'' MMS_MAX_RESPONSE_SIZE': '1000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- inference.pyでモデルの読み込みメソッドを定義します。
カスタムでは inference.py スクリプトでは、まず CUDA 対応 GPU が利用可能かどうかを確認します。そのような GPU が利用可能な場合は、 'cuda' デバイスに DEVICE 変数;それ以外の場合は、 'cpu' デバイス。このステップにより、効率的な計算のためにモデルが利用可能なハードウェアに確実に配置されます。 Whisper Python パッケージを使用して PyTorch モデルを読み込みます。
ハグフェイスフレームワーク
- モデルアーティファクトを保存する
XNUMX 番目のオプションは使用することです ハグフェイスのささやき 実装。モデルは次のコマンドを使用してロードできます。 AutoModelForSpeechSeq2Seq トランスフォーマークラス。学習可能なパラメータは、 save_pretrained 方法。 Hugging Face モデルが適切に動作するように、トークナイザーとプリプロセッサも個別に保存する必要があります。あるいは、2 つの環境変数を設定することで、Hugging Face Hub から Amazon SageMaker にモデルを直接デプロイすることもできます。 HF_MODEL_ID および HF_TASK。詳細については、こちらを参照してください ウェブページ.
- DLCを選択
PyTorch フレームワークと同様に、同じフレームワークから事前に構築された Hugging Face DLC を選択できます。 。最新の Hugging Face トランスフォーマーをサポートし、GPU サポートを含む DLC を必ず選択してください。
- Amazon SageMaker モデルを作成する
同様に、 SageMaker Python SDK ハグフェイスモデルを作成します。ハグ フェイス ウィスパー モデルには、最大 30 秒までのオーディオ セグメントのみを処理できるというデフォルトの制限があります。この制限に対処するには、次のものを含めることができます。 chunk_length_s ハグ顔モデルを作成するときに環境変数のパラメータを指定し、後でモデルをロードするときにこのパラメータをカスタム推論スクリプトに渡します。最後に、Hugging Face コンテナーのペイロード サイズと応答タイムアウトを増やすように環境変数を設定します。
| フレームワーク | 環境変数 |
|
HuggingFace 推論コンテナ (MMSに基づく) |
'MMS_MAX_REQUEST_SIZE': '2000000000'' MMS_MAX_RESPONSE_SIZE': '2000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- inference.pyでモデルの読み込みメソッドを定義します。
Hugging Face モデルのカスタム推論スクリプトを作成するときは、パイプラインを利用して、 chunk_length_s パラメータとして。このパラメーターにより、モデルは推論中に長いオーディオ ファイルを効率的に処理できるようになります。
Amazon SageMaker のさまざまな推論オプションを調べる
推論オプションを選択する手順は、PyTorch モデルと Hugging Face モデルの両方で同じであるため、以下では区別しません。ただし、この記事の執筆時点では、 サーバーレス推論 SageMaker のオプションは GPU をサポートしていないため、このユースケースではこのオプションを除外します。
モデルをリアルタイム エンドポイントとしてデプロイし、ミリ秒単位で応答を返すことができます。ただし、このオプションは 6 MB 未満の入力の処理に限定されることに注意することが重要です。シリアライザーをオーディオ シリアライザーとして定義します。これは、入力データをデプロイされたモデルに適した形式に変換する役割を果たします。推論に GPU インスタンスを利用し、オーディオ ファイルの高速処理を可能にします。推論入力は、ローカル リポジトリからのオーディオ ファイルです。
100 番目の推論オプションはバッチ変換ジョブで、最大 XNUMX MB の入力ペイロードを処理できます。ただし、この方法には数分の待ち時間がかかる場合があります。各インスタンスは一度に XNUMX つのバッチ リクエストのみを処理でき、インスタンスの開始とシャットダウンにも数分かかります。推論結果は Amazon Simple Storage Service (アマゾンS3) バッチ変換ジョブの完了時にバケットに追加されます。
バッチトランスフォーマーを構成するときは、必ず次の内容を含めてください。 max_payload = 100 より大きなペイロードを効果的に処理します。推論入力は、オーディオ ファイルへの Amazon S3 パス、またはオーディオ ファイルのリストを含む Amazon S3 バケット フォルダー (それぞれのサイズが 100 MB 未満) である必要があります。
バッチ変換は、入力内の Amazon S3 オブジェクトをキーによって分割し、Amazon S3 オブジェクトをインスタンスにマップします。たとえば、複数のオーディオ ファイルがある場合、スケーラビリティを高めるために、1 つのインスタンスが input2.wav を処理し、別のインスタンスが inputXNUMX.wav という名前のファイルを処理することがあります。バッチ変換を使用すると、以下を構成できます max_concurrent_transforms 個々のトランスフォーマー コンテナーに対して行われる HTTP リクエストの数を増やします。ただし、( の値) に注意することが重要です。max_concurrent_transforms* max_payload) は 100 MB を超えてはなりません。
最後に、Amazon SageMaker Asynchronous Inference は、複数のリクエストを同時に処理するのに最適で、適度なレイテンシーを提供し、最大 1 GB の入力ペイロードをサポートします。このオプションは優れたスケーラビリティを提供し、エンドポイントの自動スケーリング グループの構成を可能にします。リクエストの急増が発生すると、トラフィックを処理するためにエンドポイントが自動的にスケールアップされ、すべてのリクエストが処理されると、コストを節約するためにエンドポイントが 0 にスケールダウンされます。
非同期推論を使用すると、結果が Amazon S3 バケットに自動的に保存されます。の中に AsyncInferenceConfigでは、成功または失敗の完了に関する通知を構成できます。入力パスは、オーディオ ファイルの Amazon S3 の場所を指します。詳細については、次のコードを参照してください。 GitHubの.
任意: 前述したように、非同期推論エンドポイントの自動スケーリング グループを構成するオプションがあり、これにより推論リクエストの突然の急増に対処できるようになります。コード例は次のとおりです。 GitHubリポジトリ。次の図では、次の 2 つのメトリクスを表示する折れ線グラフを確認できます。 アマゾンクラウドウォッチ: ApproximateBacklogSize および ApproximateBacklogSizePerInstance。当初、1000 個のリクエストがトリガーされたとき、推論を処理できるインスタンスは XNUMX つだけでした。 XNUMX 分間、バックログ サイズが常に XNUMX を超えました (これらの数値は構成可能であることに注意してください)。自動スケーリング グループは、バックログを効率的にクリアするために追加のインスタンスをスピンアップすることで対応しました。これにより、 ApproximateBacklogSizePerInstanceにより、バックログ リクエストを初期フェーズよりもはるかに高速に処理できるようになります。

図 2. Amazon CloudWatch メトリクスの時間的変化を示す折れ線グラフ
推論オプションの比較分析
さまざまな推論オプションの比較は、一般的な音声処理の使用例に基づいています。リアルタイム推論は最速の推論速度を提供しますが、ペイロード サイズは 6 MB に制限されます。この推論タイプは、ユーザーが音声コマンドまたは音声指示を使用してデバイスまたはソフトウェアを制御または対話するオーディオ コマンド システムに適しています。通常、音声コマンドのサイズは小さく、転写されたコマンドが後続のアクションを即座にトリガーできるようにするには、推論遅延が低いことが重要です。バッチ変換は、各オーディオ ファイルのサイズが 100 MB 未満であり、高速推論応答時間に対する特別な要件がない場合、スケジュールされたオフライン タスクに最適です。非同期推論では、最大 1 GB のアップロードが可能で、中程度の推論レイテンシーを実現します。この推論タイプは、より大きな音声ファイルを処理する必要がある映画、テレビ シリーズ、録画された会議の文字起こしに適しています。
リアルタイム推論オプションと非同期推論オプションの両方で自動スケール機能が提供され、リクエストの量に基づいてエンドポイント インスタンスを自動的にスケールアップまたはスケールダウンできます。リクエストがない場合、自動スケーリングによって不要なインスタンスが削除されるため、アクティブに使用されていないプロビジョニングされたインスタンスに関連するコストを回避できます。ただし、リアルタイム推論の場合、少なくとも 0 つの永続インスタンスを保持する必要があるため、エンドポイントが継続的に動作する場合はコストが高くなる可能性があります。対照的に、非同期推論では、使用されていないときはインスタンスのボリュームを XNUMX に減らすことができます。バッチ変換ジョブを構成する場合、複数のインスタンスを使用してジョブを処理し、max_concurrent_transforms を調整して XNUMX つのインスタンスが複数のリクエストを処理できるようにすることができます。したがって、XNUMX つの推論オプションはすべて、優れたスケーラビリティを提供します。
清掃
ソリューションの利用が完了したら、追加コストの発生を防ぐために、必ず SageMaker エンドポイントを削除してください。提供されたコードを使用して、リアルタイム推論エンドポイントと非同期推論エンドポイントをそれぞれ削除できます。
まとめ
この投稿では、音声処理のための機械学習モデルの導入がさまざまな業界でどのように重要になってきているかを説明しました。 Whisper モデルを例として、PyTorch または Hugging Face アプローチを使用して、Amazon SageMaker でオープンソース ASR モデルをホストする方法を示しました。この調査には Amazon SageMaker のさまざまな推論オプションが含まれており、音声データの効率的な処理、予測の実行、およびコストの効果的な管理に関する洞察が得られました。この投稿は、オーディオ関連のタスクに Whisper モデルを活用し、推論戦略について情報に基づいた意思決定を行うことに関心のある研究者、開発者、データ サイエンティストに知識を提供することを目的としています。
SageMaker でのモデルのデプロイに関する詳細については、こちらを参照してください。 開発者ガイド。さらに、Whisper モデルは SageMaker JumpStart を使用してデプロイできます。詳細については、こちらをご確認ください。 自動音声認識用のウィスパーモデルが Amazon SageMaker JumpStart で利用可能になりました 役職。
このプロジェクトのノートブックとコードをぜひチェックしてください。 GitHubの コメントを共有してください。
著者について
 ホウ・イン博士は、AWS の機械学習プロトタイピング アーキテクトです。彼女の主な関心分野は、GenAI、コンピューター ビジョン、NLP、時系列データ予測を中心とした深層学習です。余暇には、家族と充実した時間を過ごしたり、小説に没頭したり、英国の国立公園でハイキングしたりすることを楽しんでいます。
ホウ・イン博士は、AWS の機械学習プロトタイピング アーキテクトです。彼女の主な関心分野は、GenAI、コンピューター ビジョン、NLP、時系列データ予測を中心とした深層学習です。余暇には、家族と充実した時間を過ごしたり、小説に没頭したり、英国の国立公園でハイキングしたりすることを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/host-the-whisper-model-on-amazon-sagemaker-exploring-inference-options/
- :持っている
- :は
- :not
- :どこ
- $UP
- 1
- 10
- 100
- 12
- 14
- 16
- 19
- 30
- 32
- 8
- a
- 加速された
- アクセス
- 接近性
- 精度
- 越えて
- 行動
- 積極的に
- 加えます
- NEW
- さらに
- 住所
- 調整します
- 高度な
- AI
- 目指して
- すべて
- 許可
- ことができます
- 沿って
- また
- Amazon
- アマゾンセージメーカー
- Amazon Webサービス
- an
- 分析
- および
- 別の
- どれか
- アプローチ
- です
- エリア
- 配列
- 人工の
- 人工知能
- AS
- 資産
- アシスタント
- 関連する
- At
- オーディオ
- 原作者
- オートマチック
- 自動的に
- 賃貸条件の詳細・契約費用のお見積り等について
- 利用できます
- 避ける
- AWS
- ベース
- ベース
- BE
- になる
- 以下
- より良いです
- の間に
- バイアス
- BIN
- 両言語で
- バグ
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 缶
- 機能
- できる
- 注意深い
- 例
- 変更
- チャート
- チェック
- 選択する
- 選択する
- class
- クリア
- コード
- 来ます
- コメント
- コマンドと
- 比較
- 比較
- 記入済みの
- 完成
- コンポーネント
- 包括的な
- 計算
- コンピュータ
- Computer Vision
- プロフェッショナルな方法で
- 会議
- 設定された
- 構成する
- 考えると
- 一貫して
- 含む
- コンテナ
- コンテナ
- 連続的に
- コントラスト
- コントロール
- 変換
- 正しい
- 対応する
- 費用
- コスト
- 可能性
- CPU
- 作ります
- 作成
- 重大な
- カスタム
- データ
- 決定
- 減少
- 深いです
- 深い学習
- デフォルト
- 定義します
- 実証
- 展開します
- 展開
- 展開する
- 展開
- 詳細
- 詳細な
- 細部
- 開発する
- 開発者
- 開発
- デバイス
- Devices
- 異なります
- 区別する
- 次元
- 直接に
- 表示
- ダイビング
- 異なる
- デッカー
- そうではありません
- すること
- ダウン
- 間に
- e
- 各
- 前
- エコシステム
- 効果的に
- 効率的な
- 効率良く
- 楽な
- どちら
- ほかに
- 乗り出す
- 力を与える
- enable
- 可能
- 有効にする
- 含む
- エンドポイント
- エンドポイント
- 高めます
- 強化
- 確保
- 確実に
- 全体
- 環境
- 本質的な
- 確立
- エーテル(ETH)
- 検査
- 例
- 超えます
- 超過
- 優れた
- 実験
- 説明する
- 探査
- 探る
- 顔
- Failed:
- false
- 家族
- スピーディー
- 速いです
- 最速
- 少数の
- File
- 発見
- 名
- フォーカス
- 焦点
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- フレームワーク
- フレームワーク
- 無料版
- から
- フル
- GPU
- GPU
- 素晴らしい
- グループ
- ハンドル
- ハンドリング
- Hardware
- 持ってる
- 耳
- 助け
- 彼女の
- ハイ
- より高い
- ハイキング
- host
- ホスティング
- 認定条件
- How To
- しかしながら
- HTML
- HTTP
- HTTPS
- ハブ
- 抱き合う顔
- i
- 理想
- if
- 描く
- 画像
- 画像
- 実装
- 実装
- import
- 重要
- in
- 綿密な
- include
- 含ま
- 含めて
- 組み込む
- 増える
- ますます
- 個人
- 個人
- 産業
- 情報
- 情報に基づく
- 初期
- 当初
- 開始
- 入力
- 洞察
- install
- インスタンス
- 説明書
- 統合
- インテリジェンス
- 対話
- 関心
- 興味がある
- インタフェース
- に
- 問題
- IT
- ITS
- ジョブ
- Jobs > Create New Job
- JPG
- キー
- 知識
- 既知の
- 風景
- より大きい
- 最後に
- レイテンシ
- 後で
- 最新の
- 層
- つながる
- 学習
- 最低
- 活用
- ライセンス
- 制限
- 限定的
- LINE
- リスト
- 負荷
- ローディング
- ローカル
- 場所
- 長い
- より長いです
- ロー
- 機械
- 機械学習
- 製
- メイン
- make
- 作る
- 作成
- 管理します
- 管理する
- ゲレンデマップ
- 五月..
- 言及した
- 方法
- メソッド
- メトリック
- かもしれない
- ミリ秒
- 分
- マサチューセッツ工科大学(MIT)
- ML
- モデル
- 適度な
- モーメント
- モニタリング
- 他には?
- 動画
- ずっと
- の試合に
- しなければなりません
- 名前付き
- 国民
- 国立公園
- 必要
- 必要
- 必要とされる
- ネットワーク
- ニューラル
- ニューラルネットワーク
- 次の
- NLP
- いいえ
- 注意
- ノート
- ノート
- 通知
- 通知
- 注記
- 今
- 数
- 番号
- オブジェクト
- オブジェクト
- 観察する
- of
- 提供
- 提供すること
- オファー
- 公式
- オンライン
- on
- かつて
- ONE
- の
- オープンソース
- 動作
- オプション
- オプション
- or
- 注文
- 組織
- OS
- その他
- さもないと
- でる
- 概要
- パッケージ
- パッケージ
- パラメーター
- パラメータ
- 公園
- パス
- path
- 実行する
- パフォーマンス
- 相
- パイプライン
- 極めて重要な
- 配置
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- お願いします
- ポイント
- 可能
- ポスト
- 潜在的な
- 予測
- 予測
- 防ぐ
- 前
- 主要な
- プロセス
- 処理されました
- 処理
- プロセッサ
- プロジェクト
- 正しく
- プロトタイピング
- 提供します
- 提供
- は、大阪で
- 提供
- Python
- パイトーチ
- 品質
- 範囲
- への
- realm
- 認識
- 推奨される
- 記録された
- 電話代などの費用を削減
- 参照する
- 関係なく
- 関連する
- リリース
- 覚えています
- 削除します
- 除去する
- 倉庫
- 要求
- リクエスト
- 必要とする
- の提出が必要です
- 要件
- 研究者
- それぞれ
- 応答
- 回答
- 責任
- 結果
- 得られました
- 結果
- 保持された
- 再訓練
- return
- セージメーカー
- 同じ
- Save
- 保存されました
- 節約
- スケーラビリティ
- 規模
- 秤
- 予定の
- 科学者たち
- スクリプト
- スクリプト
- 二番
- 秒
- セクション
- セグメント
- select
- 選択
- 選択
- シリーズ
- サービス
- サービス
- セッションに
- 設定
- 設定
- シェアする
- 彼女
- すべき
- 示されました
- 作品
- shutdown
- 重要
- 簡単な拡張で
- 簡素化する
- サイズ
- サイズ
- 小さい
- より小さい
- So
- ソフトウェア
- 溶液
- 特定の
- 特に
- 指定の
- スピーチ
- 音声認識
- スピード
- 支出
- 話
- start
- 都道府県
- 最先端の
- 手順
- ステップ
- ストレージ利用料
- 作戦
- それに続きます
- 成功した
- そのような
- 突然の
- 適当
- サポート
- 支援する
- サポート
- 確か
- 発生します
- システム
- テーブル
- 取る
- 取得
- 仕事
- タスク
- テクノロジー
- より
- それ
- 英国
- アプリ環境に合わせて
- それら
- その後
- そこ。
- したがって、
- ボーマン
- 彼ら
- この
- 三
- 時間
- 時系列
- <font style="vertical-align: inherit;">回数</font>
- 〜へ
- 豊富なツール群
- トーチ
- トラフィック
- トレーニング
- 訓練された
- 最適化の適用
- トランス
- トランスフォーマー
- トリガー
- トリガ
- tv
- TVシリーズ
- 2
- type
- 一般的に
- Uk
- 下
- ロック解除
- に
- us
- つかいます
- 中古
- 「DeckleBenchは非常に使いやすく最適なソリューションを簡単に見つけることができるため、稼働率が向上しコストも削減した。当社の旧システムは良かったが改善は期待していなかった。
- users
- ユーティリティ
- 活用する
- 活用
- 貴重な
- 値
- 変数
- さまざまな
- 広大な
- バージョン
- ビジョン
- ボイス
- 音声コマンド
- ボリューム
- wait
- 欲しいです
- ました
- we
- ウェブ
- Webサービス
- WELL
- した
- いつ
- たびに
- which
- ウィスパー
- ワイド
- 広い範囲
- 以内
- ワークフロー
- 作品
- 価値
- 書き込み
- 貴社
- あなたの
- ゼファーネット