בעולם המודרני, רוב העסקים מסתמכים על הכוח של ביג דאטה ואנליטיקס כדי לתדלק את הצמיחה, ההשקעות האסטרטגיות ומעורבות הלקוחות שלהם. ביג דאטה הוא הקבוע הבסיסי בפרסומת הממוקדת, שיווק מותאם אישית, המלצות למוצרים, יצירת תובנות, אופטימיזציות של מחירים, ניתוח סנטימנטים, ניתוח חזוי ועוד ועוד.
נתונים נאספים לעתים קרובות ממקורות מרובים, עוברים טרנספורמציה, מאוחסנים ומעובדים באגמי נתונים במקום או בענן. בעוד שהקלטת הנתונים הראשונית היא טריוויאלית יחסית וניתן להשיגה באמצעות סקריפטים מותאמים אישית שפותחו בבית או בכלים מסורתיים של ETL (Extract Transform Load), הבעיה הופכת במהרה למורכבת עד בלתי אפשרית ויקרה לפתרון מכיוון שהחברות צריכות:
- נהל את מחזור החיים המלא של הנתונים - למטרות ניקיון ותאימות
- מטב את האחסון - כדי להפחית את העלויות הנלוות
- פשט את האדריכלות - באמצעות שימוש חוזר בתשתית מחשוב
- מעבד נתונים בהדרגה - באמצעות ניהול מדינה רב עוצמה
- החל את אותה מדיניות על נתוני אצווה וזרימה - ללא כפל מאמץ
- העבר בין On-Prem לענן - במינימום מאמץ
זה איפה אפאצ'י גובלין, נכנסת מערכת ניהול נתונים ואינטגרציה בקוד פתוח. Apache Gobblin מספקת יכולות חסרות תקדים שניתן להשתמש בהן בשלמותן או בחלקן בהתאם לצרכי העסק.
בחלק זה, נעמיק ביכולות השונות של Apache Gobblin המסייעות להתמודד עם האתגרים שפורטו קודם לכן.
ניהול מחזור חיים מלא של נתונים
Apache Gobblin מספקת מגוון של יכולות לבניית צינורות נתונים התומכים בחבילה המלאה של פעולות מחזור חיים של נתונים על מערכי נתונים.
- הטמעת נתונים - ממקורות מרובים ועד ל-Sinks החל מבסיסי נתונים, Rest APIs, שרתי FTP/SFTP, Filers, CRMs כמו Salesforce ו- Dynamics, ועוד.
- שכפול נתונים - בין מספר אגמי נתונים עם יכולות מיוחדות עבור Hadoop Distributed File System באמצעות Distcp-NG.
- טיהור נתונים - שימוש במדיניות שמירה כמו מבוסס-זמן, הכי חדש, K, גרסה או שילוב של מדיניות.
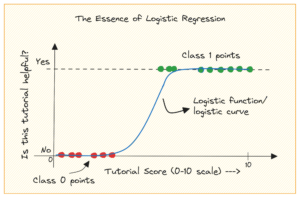
הצינור הלוגי של גובלין מורכב מ'מקור' שקובע את חלוקת העבודה ויוצר 'Workunits'. 'Workunits' אלה נאספים לאחר מכן לביצוע כ'משימות', הכוללות חילוץ, המרה, בדיקת איכות וכתיבת נתונים ליעד. השלב האחרון, 'פרסום נתונים', מאמת את הביצוע המוצלח של הצינור ומחייב את נתוני הפלט באופן אטומי, אם היעד תומך בכך.
תמונה מאת המחבר
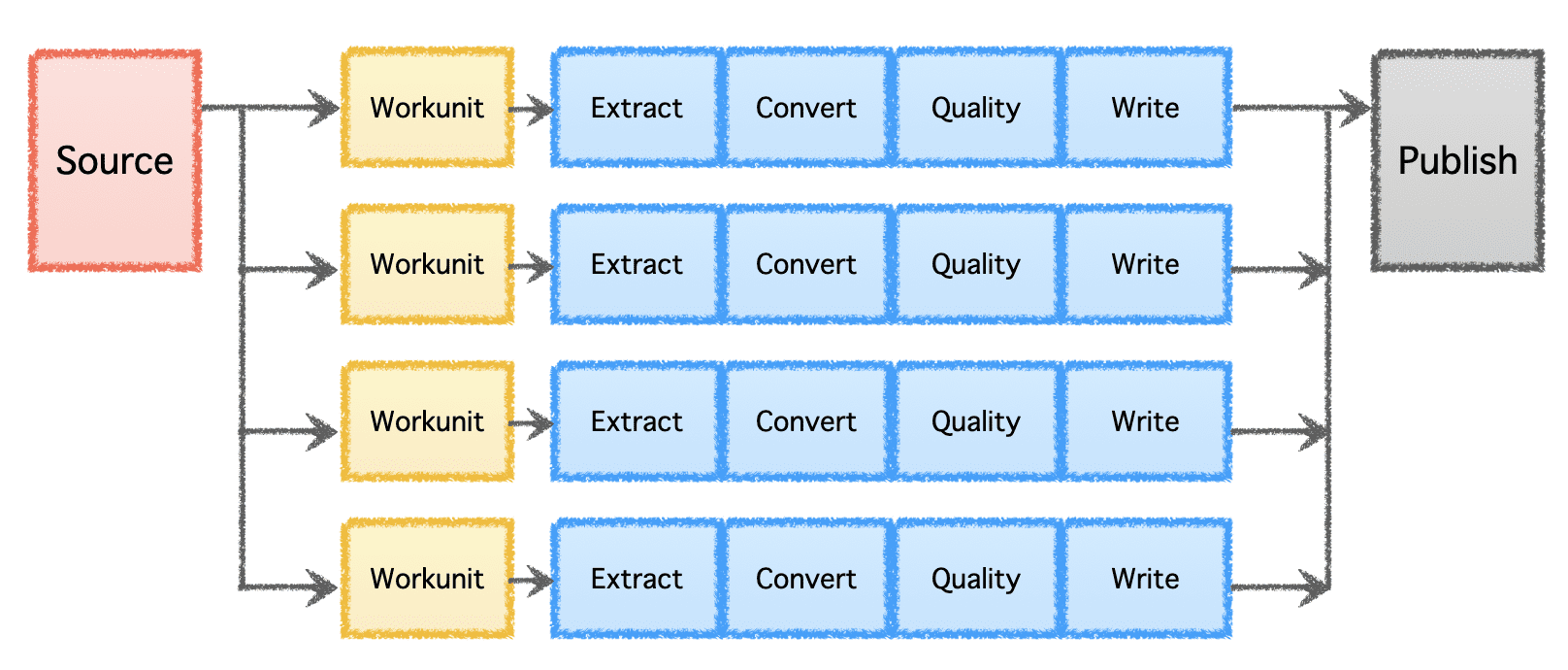
בצע אופטימיזציה של אחסון
Apache Gobblin יכולה לעזור להפחית את כמות האחסון הדרושה לנתונים באמצעות עיבוד נתונים לאחר הקלטה או שכפול באמצעות דחיסה או המרת פורמט.
- דחיסה - עיבוד לאחר עיבוד נתונים לביטול כפילות על סמך כל השדות או שדות המפתח של הרשומות, חיתוך הנתונים כדי לשמור רק רשומה אחת עם חותמת הזמן העדכנית ביותר עם אותו מפתח.
- Avro ל-ORC - כמנגנון המרת פורמטים מיוחד להמרת פורמט Avro הפופולרי מבוסס-שורות לפורמט ORC מבוסס-עמודות מותאם במיוחד.
תמונה מאת המחבר
פשט את האדריכלות
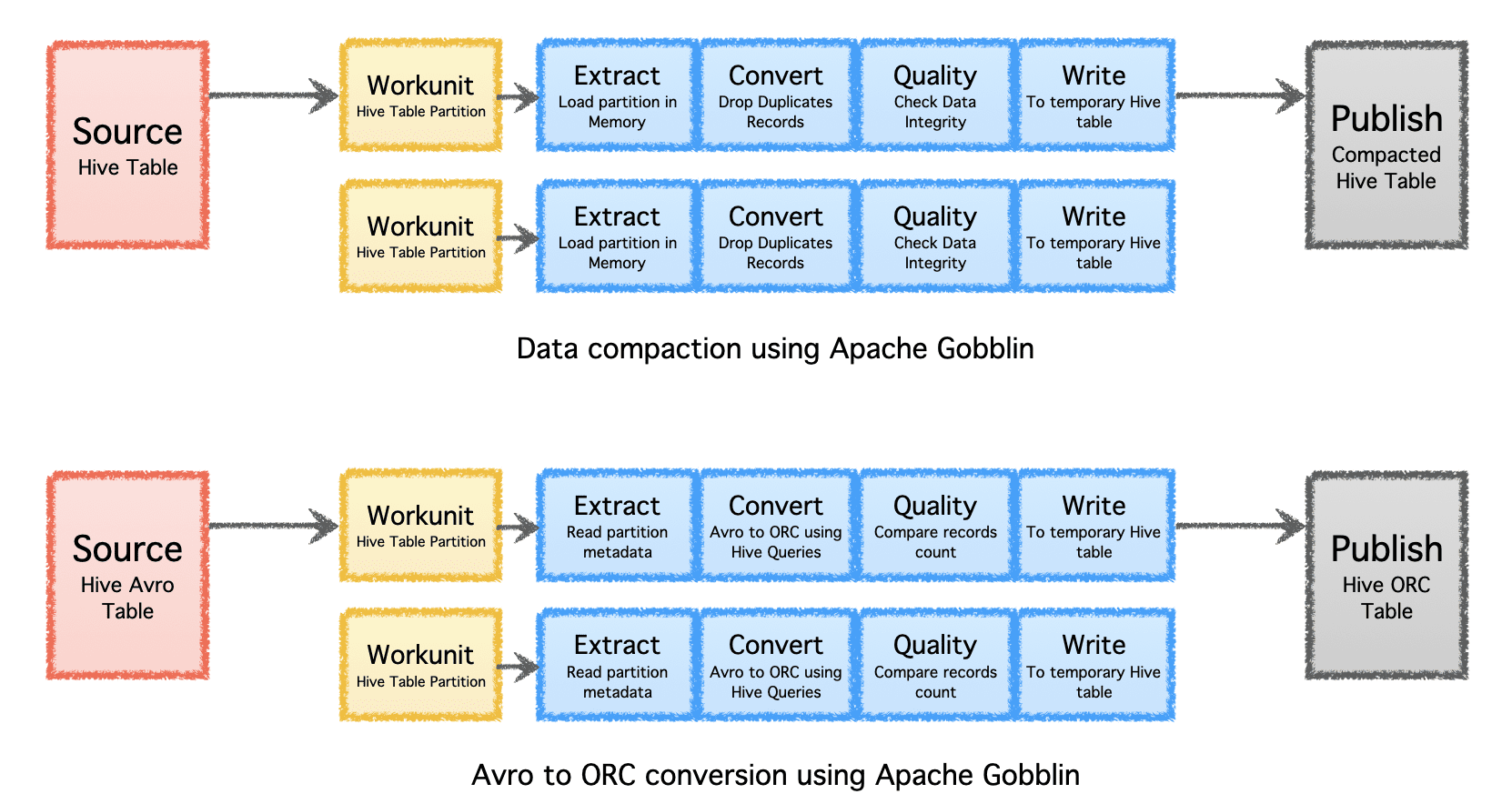
בהתאם לשלב של החברה (סטארט-אפ לארגון), דרישות קנה המידה והארכיטקטורה שלהן, חברות מעדיפות להקים או לפתח את תשתית הנתונים שלהן. Apache Gobblin גמיש מאוד ותומך במספר דגמי ביצוע.
- מצב עצמאי - לפעול כתהליך עצמאי על קופסת מתכת חשופה, כלומר מארח יחיד עבור מקרי שימוש פשוטים ומצבים בעלי דרישה נמוכה.
- מצב MapReduce - לפעול כעבודת MapReduce על תשתית Hadoop עבור מקרי ביג דאטה לטיפול במערכי נתונים הנעים בקנה מידה של Petabytes.
- מצב אשכול: עצמאי - לפעול כאשכול המגובה על ידי Apache Helix ו-Apache Zookeeper על סט של מכונות מתכת חשופות או מארחים לטיפול בקנה מידה גדול ללא תלות במסגרת Hadoop MR.
- מצב Cluster: Yarn - לפעול כאשכול על Yarn מקורי ללא המסגרת של Hadoop MR.
- מצב אשכולות: AWS – לפעול כאשכול בהיצע הענן הציבורי של אמזון, כלומר. AWS לתשתיות המתארחות ב-AWS.
תמונה מאת המחבר
מעבד נתונים בהדרגה
בקנה מידה משמעותי עם צינורות נתונים מרובים ונפח גבוה, יש לעבד נתונים באצוות ולאורך זמן. לכן, זה מחייב בדיקה כדי שצינורות הנתונים יוכלו להתחדש מהמקום שבו הפסיקו בפעם הקודמת ולהמשיך הלאה. Apache Gobblin תומך בסימני מים נמוכים וגבוהים ותומך בסמנטיקה חזקה של ניהול מצבים באמצעות State Store ב-HDFS, AWS S3, MySQL ועוד באופן שקוף.
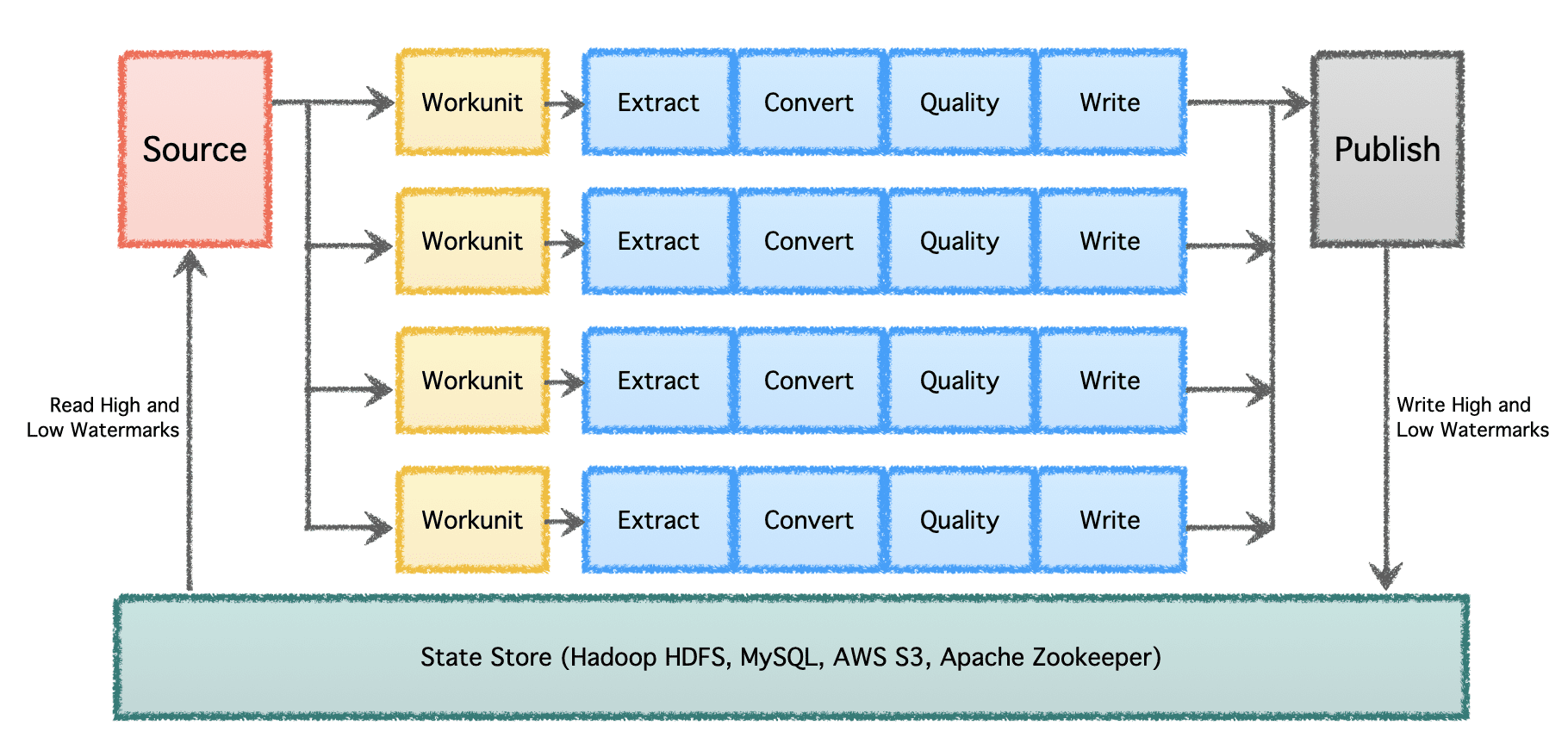
תמונה מאת המחבר
אותה מדיניות לגבי נתוני אצווה וזרם
רוב צינורות הנתונים כיום צריכים להיכתב פעמיים, פעם אחת עבור נתוני אצווה ושוב עבור נתונים קרובים לקו או זרימה. זה מכפיל את המאמץ ומציג חוסר עקביות במדיניות ובאלגוריתמים המיושמים על סוגים שונים של צינורות. Apache Gobblin פותר זאת על ידי מתן אפשרות למשתמשים ליצור צינור פעם אחת ולהריץ אותו על נתוני אצווה וזרימה אם משתמשים במצב Gobblin Cluster, Gobblin במצב AWS או Gobblin on Yarn.
העבר בין On-Prem לענן
בשל המצבים הרב-תכליתיים שלו שיכולים לפעול ב-Prem על קופסה בודדת, על אשכול צמתים או על הענן - ניתן לפרוס את Apache Gobblin ולהשתמש ב-Prem ובענן. לכן, לאפשר למשתמשים לכתוב את צינורות הנתונים שלהם פעם אחת ולהעביר אותם יחד עם פריסות Gobblin בקלות בין On-Prem לענן, בהתבסס על צרכים ספציפיים.
בשל הארכיטקטורה הגמישה ביותר שלה, התכונות החזקות וההיקף הקיצוני של נפחי נתונים שהוא יכול לתמוך ולעבד, Apache Gobblin משמש בתשתית הייצור של חברות טכנולוגיה גדולות והוא הכרחי עבור כל פריסת תשתית ביג דאטה כיום.
פרטים נוספים על Apache Gobblin וכיצד להשתמש בו ניתן למצוא בכתובת https://gobblin.apache.org
אבישק טיווארי הוא מנהל בכיר בלינקדאין, המוביל את ארגון Big Data Pipelines של החברה. הוא גם סגן נשיא Apache Gobblin בקרן Apache Software ועמית באגודת המחשבים הבריטית.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://www.kdnuggets.com/2023/01/scaling-data-management-apache-gobblin.html?utm_source=rss&utm_medium=rss&utm_campaign=scaling-data-management-through-apache-gobblin
- a
- הושג
- פְּנִיָה
- פרסומת
- לאחר
- סיוע
- אלגוריתמים
- תעשיות
- מאפשר
- כמות
- אנליזה
- ניתוח
- ו
- אַפָּשׁ
- ממשקי API
- יישומית
- ארכיטקטורה
- המשויך
- מחבר
- AWS
- מגובה
- מבוסס
- הופך להיות
- בֵּין
- גָדוֹל
- נתונים גדולים
- אריזה מקורית
- בריטי
- עסקים
- עסקים
- יכולות
- מקרים
- האתגרים
- בדיקה
- ענן
- אשכול
- שילוב
- חברות
- חברה
- מורכב
- הענות
- המחשב
- מחשוב
- קבוע
- לבנות
- להמשיך
- המרה
- להמיר
- יוצר
- מנהג
- לקוח
- מעורבות לקוחות
- נתונים
- תשתית נתונים
- ניהול נתונים
- מאגרי מידע
- מערכי נתונים
- תלוי
- פרס
- פריסה
- פריסות
- יעד
- פרטים
- קובע
- מפותח
- אחר
- מופץ
- הפצה
- דינמיקה
- בקלות
- מאמץ
- התעסקות
- מִפְעָל
- Ether (ETH)
- להתפתח
- הוצאת להורג
- יקר
- תמצית
- הוֹצָאָה
- קיצוני
- תכונות
- בחור
- שדות
- שלח
- סופי
- גמיש
- פוּרמָט
- מצא
- קרן
- מסגרת
- החל מ-
- לתדלק
- מלא
- דור
- צמיחה
- Hadoop
- לטפל
- לעזור
- גָבוֹהַ
- מאוד
- המארח
- אירח
- איך
- איך
- HTTPS
- in
- לכלול
- עצמאי
- תשתית
- תשתית
- בתחילה
- תובנות
- השתלבות
- מציג
- השקעות
- IT
- עבודה
- KDnuggets
- שמור
- מפתח
- גָדוֹל
- אחרון
- האחרון
- מוביל
- לינקדין
- לִטעוֹן
- נמוך
- מכונה
- ניהול
- מנהל
- שיווק
- מנגנון
- מתכת
- נודד
- מצב
- מודלים
- מודרני
- מצבי
- יותר
- רוב
- מספר
- חייב
- MySQL
- יליד
- נחוץ
- צרכי
- החדש ביותר
- צמתים
- הצעה
- ONE
- קוד פתוח
- תפעול
- ארגון
- המתואר
- חלקים
- אישית
- הרים
- צינור
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- מדיניות
- פופולרי
- כּוֹחַ
- חזק
- אנליטי חזוי
- לְהַעֲדִיף
- נשיא
- קוֹדֶם
- מחיר
- בעיה
- תהליך
- המוצר
- הפקה
- מספק
- ציבורי
- ענן ציבורי
- לפרסם
- איכות
- מהירות
- טִוּוּחַ
- המלצות
- שיא
- רשום
- להפחית
- יחסית
- שכפול
- דרישות
- אלה
- REST
- קורות חיים
- שייר
- חָסוֹן
- הפעלה
- כוח מכירות
- אותו
- סולם
- דרוג
- סקריפטים
- סעיף
- סמנטיקה
- לחצני מצוקה לפנסיונרים
- רגש
- סט
- משמעותי
- פָּשׁוּט
- יחיד
- מצבים
- So
- חֶברָה
- תוכנה
- לפתור
- פותר
- מָקוֹר
- מקורות
- מיוחד
- ספציפי
- התמחות
- עצמאי
- סטארט - אפ
- מדינה
- שלב
- אחסון
- חנות
- מאוחסן
- אסטרטגי
- זרם
- נהירה
- מוצלח
- מערכת
- תמיכה
- תומך
- מערכת
- ממוקד
- משימות
- טכנולוגיה
- השמיים
- שֶׁלָהֶם
- לכן
- דרך
- זמן
- חותם
- ל
- היום
- כלים
- מסורתי
- לשנות
- טרנספורמציה
- סוגים
- בְּסִיסִי
- ללא תחרות
- להשתמש
- משתמשים
- שונים
- רב צדדי
- באמצעות
- סגן הנשיא
- כֶּרֶך
- כרכים
- אשר
- בזמן
- יצטרך
- לְלֹא
- תיק עבודות
- עוֹלָם
- לכתוב
- כתיבה
- כתוב
- זפירנט