תמונה מאת המחבר
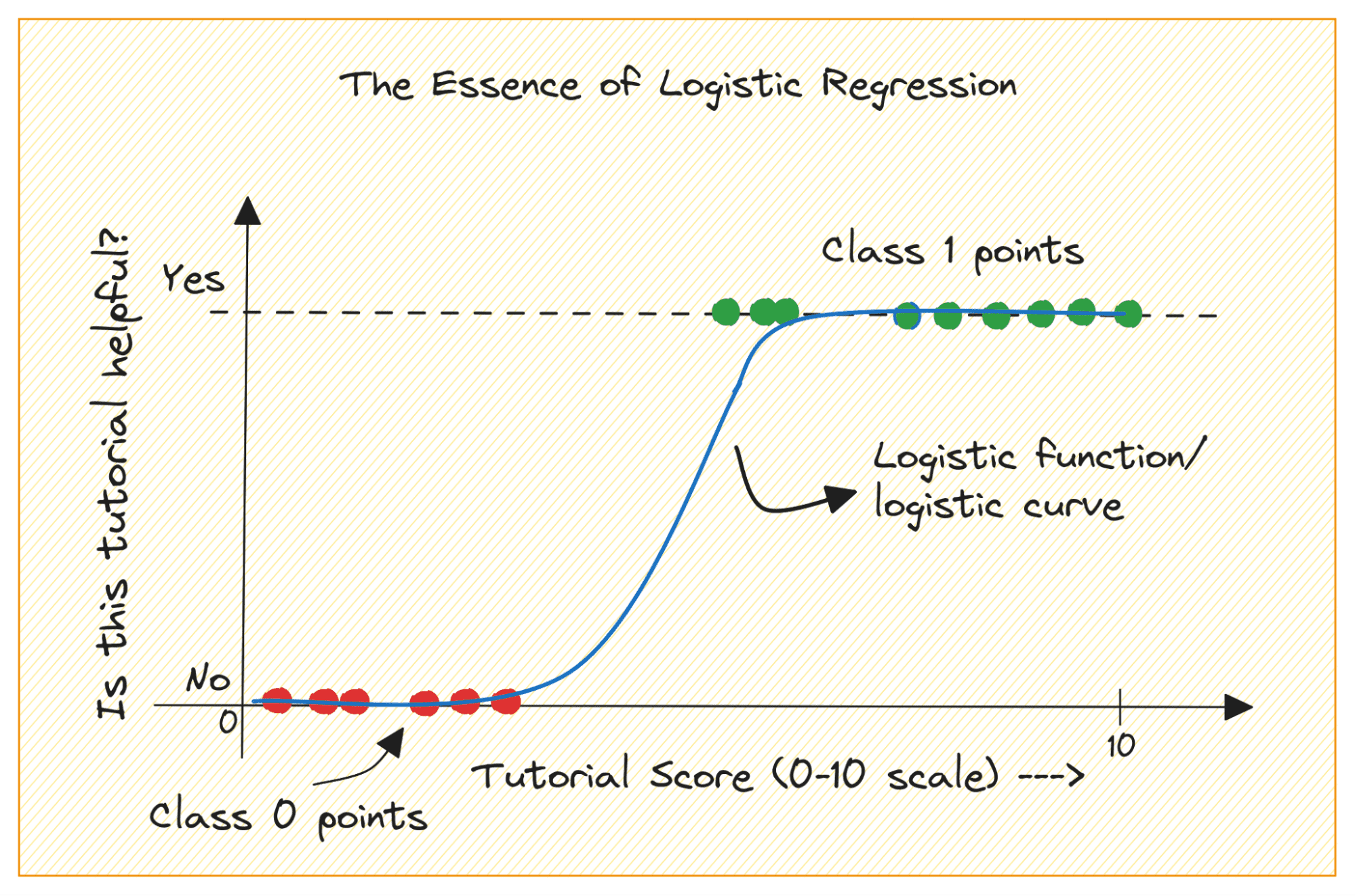
כשאתה מתחיל עם למידת מכונה, רגרסיה לוגיסטית היא אחד האלגוריתמים הראשונים שתוסיף לארגז הכלים שלך. זהו אלגוריתם פשוט וחזק, המשמש בדרך כלל למשימות סיווג בינארי.
שקול בעיית סיווג בינארי עם מחלקות 0 ו-1. רגרסיה לוגיסטית מתאימה פונקציה לוגיסטית או סיגמואידית לנתוני הקלט וחוזה את ההסתברות לנקודת נתוני שאילתה השייכת למחלקה 1. מעניין, כן?
במדריך זה, נלמד על רגרסיה לוגיסטית מהיסוד:
- הפונקציה הלוגיסטית (או הסיגמואידית).
- כיצד אנו עוברים מרגרסיה לינארית לרגרסיה לוגיסטית
- איך עובדת רגרסיה לוגיסטית
לבסוף, נבנה מודל רגרסיה לוגיסטי פשוט לסווג RADAR חוזר מהיונוספירה.
לפני שנלמד עוד על רגרסיה לוגיסטית, בואו נסקור כיצד פועלת הפונקציה הלוגיסטית. הפונקציה הלוגיסטית (או הסיגמואידית) ניתנת על ידי:

כאשר אתה מתווה את פונקציית הסיגמואיד, זה ייראה כך:
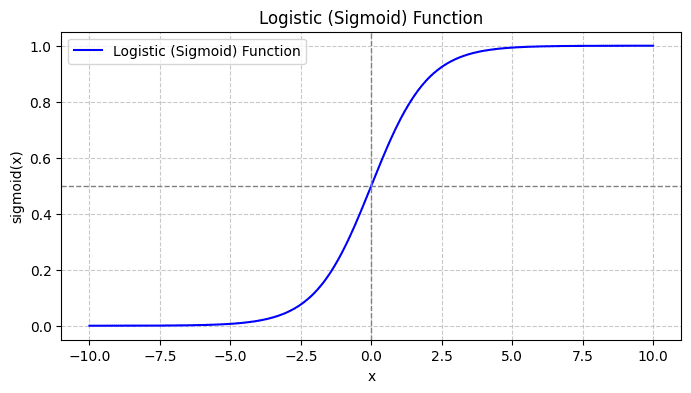
מהעלילה אנו רואים כי:
- כאשר x = 0, σ(x) מקבל ערך של 0.5.
- כאשר x מתקרב ל-+∞, σ(x) מתקרב ל-1.
- כאשר x מתקרב ל-∞, σ(x) מתקרב ל-0.
אז עבור כל התשומות האמיתיות, הפונקציה הסיגמואידית מוחקת אותם כדי לקבל ערכים בטווח [0, 1].
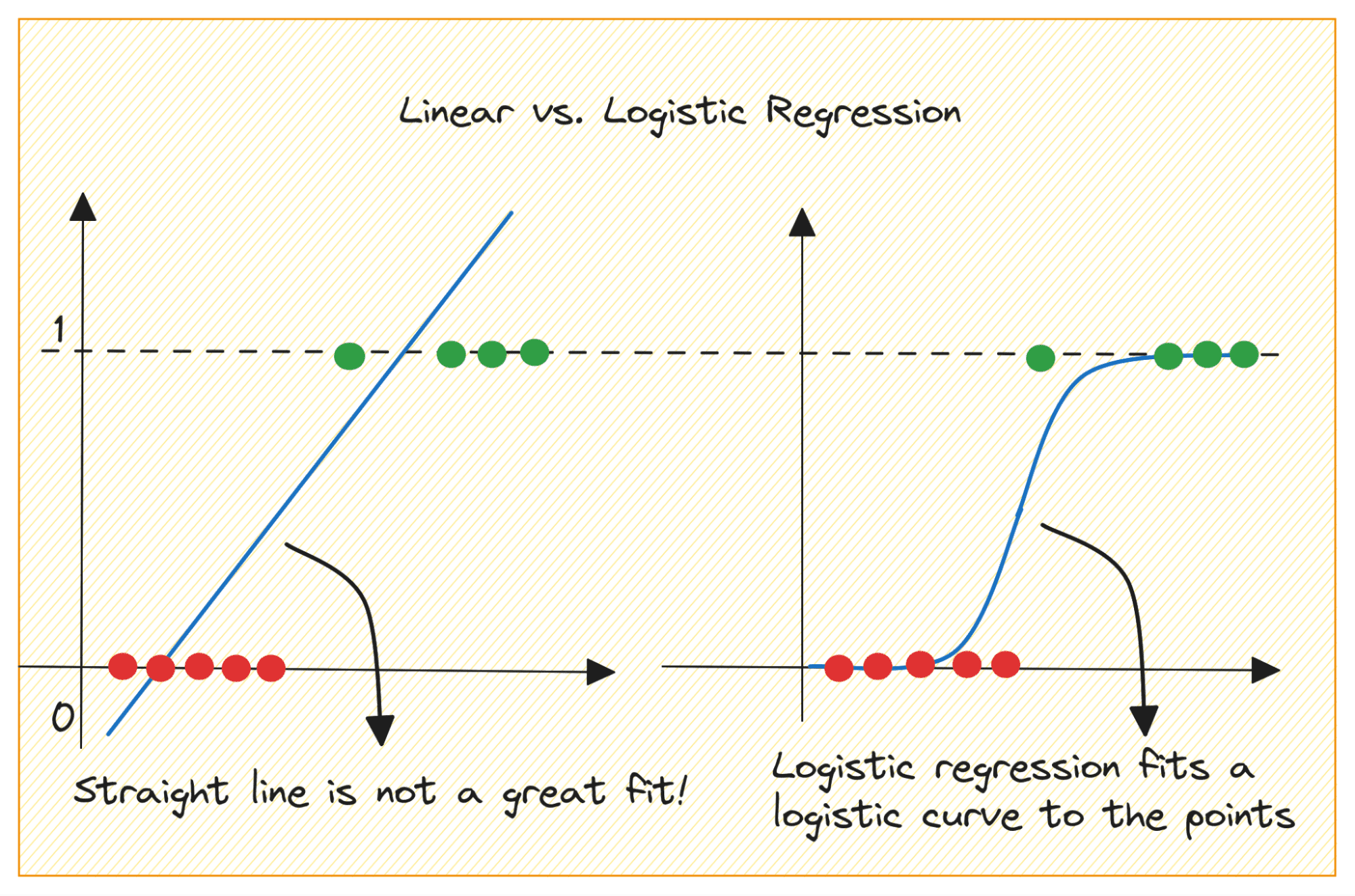
תחילה נדון מדוע איננו יכולים להשתמש ברגרסיה ליניארית עבור בעיית סיווג בינארי.
בבעיית סיווג בינארי, הפלט הוא תווית קטגורית (0 או 1). מכיוון שרגרסיה ליניארית מנבאת תפוקות בעלות ערך רציף שיכולות להיות פחות מ-0 או גדולות מ-1, זה לא הגיוני לבעיה שעל הפרק.
כמו כן, קו ישר עשוי שלא להתאים בצורה הטובה ביותר כאשר תוויות הפלט שייכות לאחת משתי הקטגוריות.
תמונה מאת המחבר
אז איך עוברים מרגרסיה לינארית לרגרסיה לוגיסטית? ברגרסיה ליניארית הפלט החזוי ניתן על ידי:
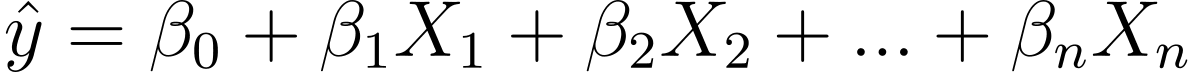
כאשר ה-βs הם המקדמים ו-X_is הם המנבאים (או התכונות).
ללא אובדן כלליות, נניח X_0 = 1:

אז נוכל לקבל ביטוי תמציתי יותר:
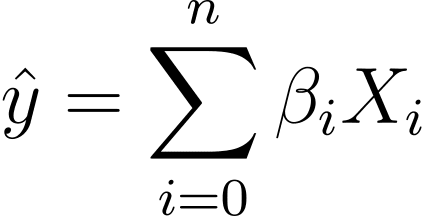
ברגרסיה לוגיסטית, אנו צריכים את ההסתברות החזויה p_i במרווח [0,1]. אנו יודעים שהפונקציה הלוגיסטית מוחקת תשומות כך שהם מקבלים ערכים במרווח [0,1].
אז אם נחבר את הביטוי הזה לפונקציה הלוגיסטית, יש לנו את ההסתברות החזויה כ:
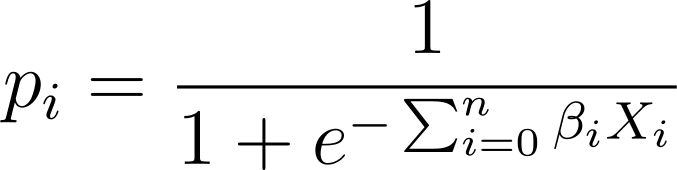
אז איך נמצא את העקומה הלוגיסטית המתאימה ביותר למערך הנתונים הנתון? כדי לענות על זה, בואו נבין את הערכת הסבירות המקסימלית.
הערכת סבירות מקסימלית (MLE) משמש להערכת הפרמטרים של מודל הרגרסיה הלוגיסטית על ידי מקסום פונקציית הסבירות. בואו נפרק את תהליך ה-MLE ברגרסיה לוגיסטית וכיצד מנוסחת פונקציית העלות לאופטימיזציה באמצעות ירידה בשיפוע.
פירוק הערכת סבירות מרבית
כפי שנדון, אנו מדגמים את ההסתברות שתוצאה בינארית מתרחשת כפונקציה של משתנה מנבא אחד או יותר (או תכונות):
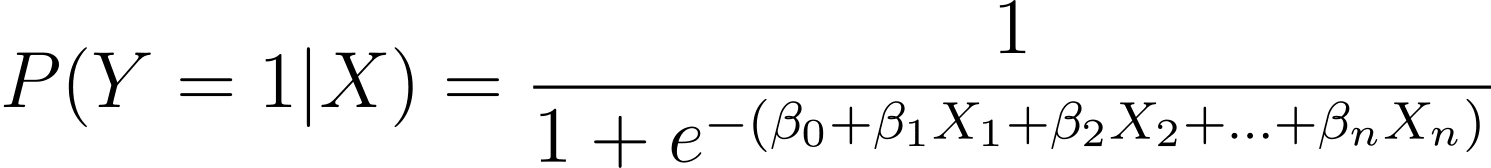
כאן, ה-βs הם הפרמטרים או המקדמים של המודל. X_1, X_2,..., X_n הם המשתנים המנבאים.
MLE שואף למצוא את הערכים של β שממקסמים את הסבירות של הנתונים שנצפו. פונקציית הסבירות, המסומנת כ-L(β), מייצגת את ההסתברות לצפייה בתוצאות הנתונות עבור ערכי המנבאים הנתונים תחת מודל הרגרסיה הלוגיסטית.
ניסוח הפונקציה Log-Likelihood
כדי לפשט את תהליך האופטימיזציה, מקובל לעבוד עם פונקציית סבירות היומן. מכיוון שהוא הופך תוצרי הסתברויות לסכומים של הסתברויות יומן.
פונקציית הסבירות היומן עבור רגרסיה לוגיסטית ניתנת על ידי:
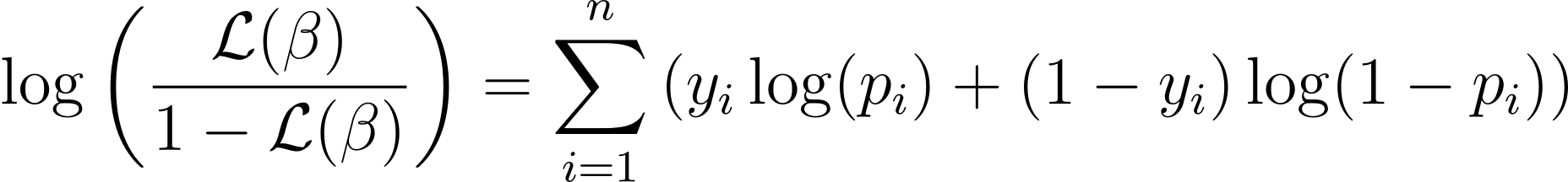
כעת, כאשר אנו יודעים את המהות של סבירות יומן, הבה נמשיך לנסח את פונקציית העלות עבור רגרסיה לוגיסטית ולאחר מכן ירידה בשיפוע למציאת פרמטרי המודל הטובים ביותר
פונקציית עלות עבור רגרסיה לוגיסטית
כדי לייעל את מודל הרגרסיה הלוגיסטית, עלינו למקסם את סבירות היומן. אז נוכל להשתמש בסבירות היומן השליליות כפונקציית העלות כדי למזער במהלך האימון. סבירות היומן השלילי, המכונה לעתים קרובות הפסד לוגיסטי, מוגדרת כ:
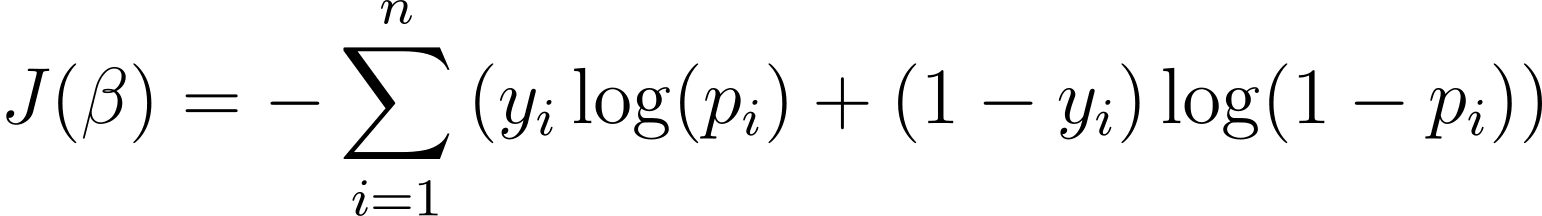
המטרה של אלגוריתם הלמידה, אם כן, היא למצוא את הערכים של ? שממזערים את פונקציית העלות הזו. ירידה בשיפוע הוא אלגוריתם אופטימיזציה נפוץ למציאת המינימום של פונקציית עלות זו.
ירידה בשיפוע ברגרסיה לוגיסטית
ירידת מעבר הוא אלגוריתם אופטימיזציה איטרטיבי שמעדכן את פרמטרי המודל β בכיוון ההפוך לשיפוע של פונקציית העלות ביחס ל-β. כלל העדכון בשלב t+1 עבור רגרסיה לוגיסטית באמצעות ירידה בשיפוע הוא כדלקמן:
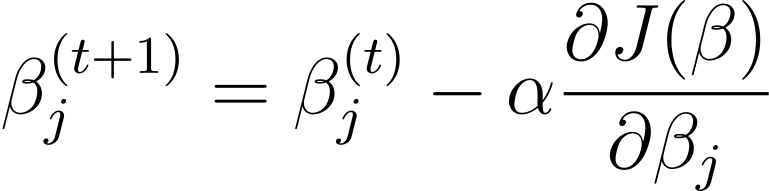
כאשר α הוא קצב הלמידה.
ניתן לחשב את הנגזרות החלקיות באמצעות כלל השרשרת. ירידה בשיפוע מעדכנת באופן איטרטיבי את הפרמטרים - עד להתכנסות - במטרה למזער את ההפסד הלוגיסטי. כשהיא מתכנסת, היא מוצאת את הערכים האופטימליים של β שממקסמים את הסבירות של הנתונים הנצפים.
עכשיו כשאתה יודע איך עובדת רגרסיה לוגיסטית, בואו נבנה מודל חיזוי באמצעות ספריית scikit-learn.
אנו נשתמש ב- מערך נתונים של ionosphere ממאגר למידת מכונה של UCI עבור הדרכה זו. מערך הנתונים כולל 34 מאפיינים מספריים. הפלט הוא בינארי, אחד של 'טוב' או 'רע' (מסומן ב-'g' או 'b'). תווית הפלט 'טוב' מתייחסת להחזרות RADAR שזיהו מבנה כלשהו ביונוספירה.
שלב 1 - טעינת מערך הנתונים
ראשית, הורד את מערך הנתונים וקרא אותו לתוך מסגרת נתונים של פנדה:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)שלב 2 - חקר מערך הנתונים
בואו נסתכל על השורות הראשונות של מסגרת הנתונים:
# Display the first few rows of the DataFrame
df.head()
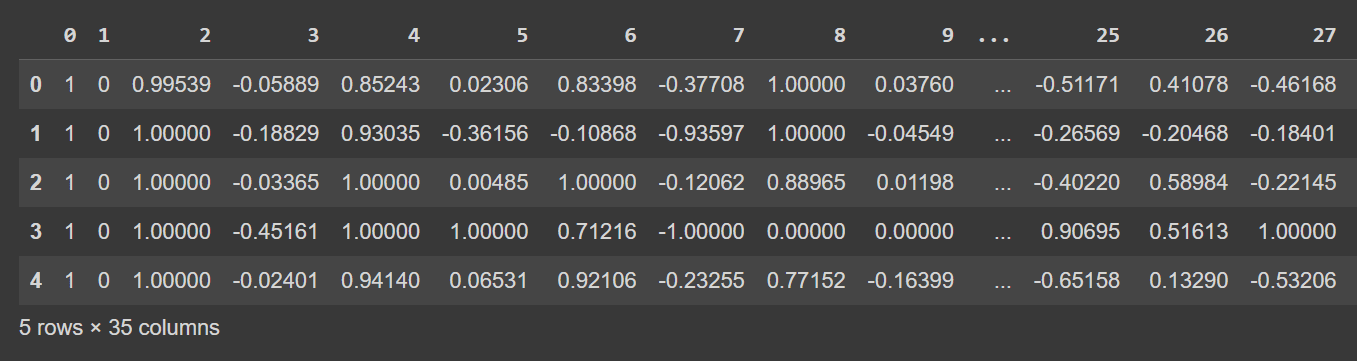
פלט קטוע של df.head()
בואו לקבל קצת מידע על מערך הנתונים: מספר הערכים שאינם אפס וסוגי הנתונים של כל אחת מהעמודות:
# Get information about the dataset
print(df.info())
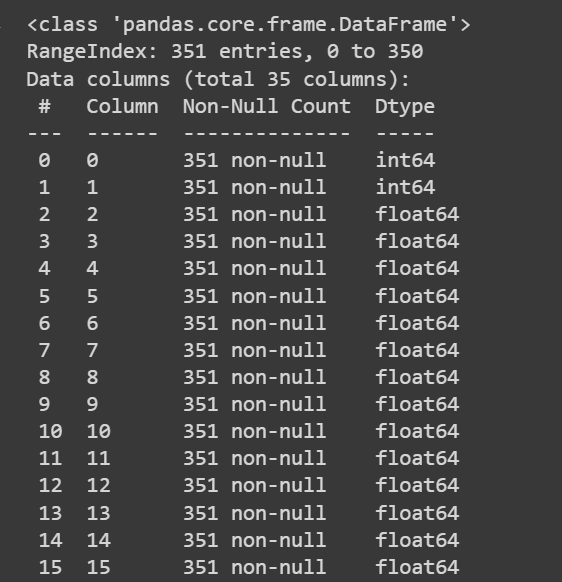 פלט קטוע של df.info()
פלט קטוע של df.info()
מכיוון שיש לנו את כל התכונות המספריות, נוכל גם לקבל כמה סטטיסטיקות תיאוריות באמצעות ה describe() שיטה על מסגרת הנתונים:
# Get descriptive statistics of the dataset
print(df.describe())
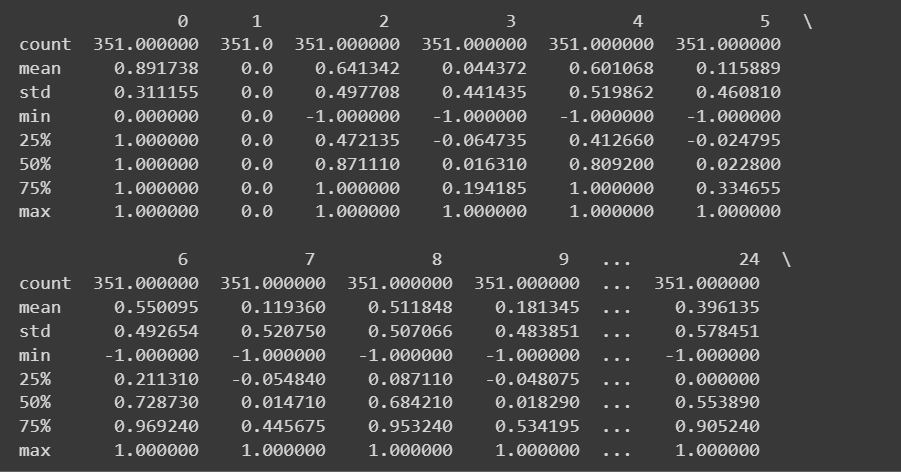
פלט קטוע של df.describe()
שמות העמודות הם כרגע 0 עד 34 - כולל התווית. מכיוון שמערך הנתונים אינו מספק שמות תיאוריים עבור העמודות, הוא רק מתייחס אליהם כאל attribute_1 to attribute_34 אם תרצה, תוכל לשנות את שמות העמודות של מסגרת הנתונים כפי שמוצג:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
הערה: שלב זה הוא אופציונלי בלבד. אתה יכול להמשיך עם שמות העמודות המוגדרים כברירת מחדל אם אתה מעדיף.
# Display the first few rows of the DataFrame
df.head()
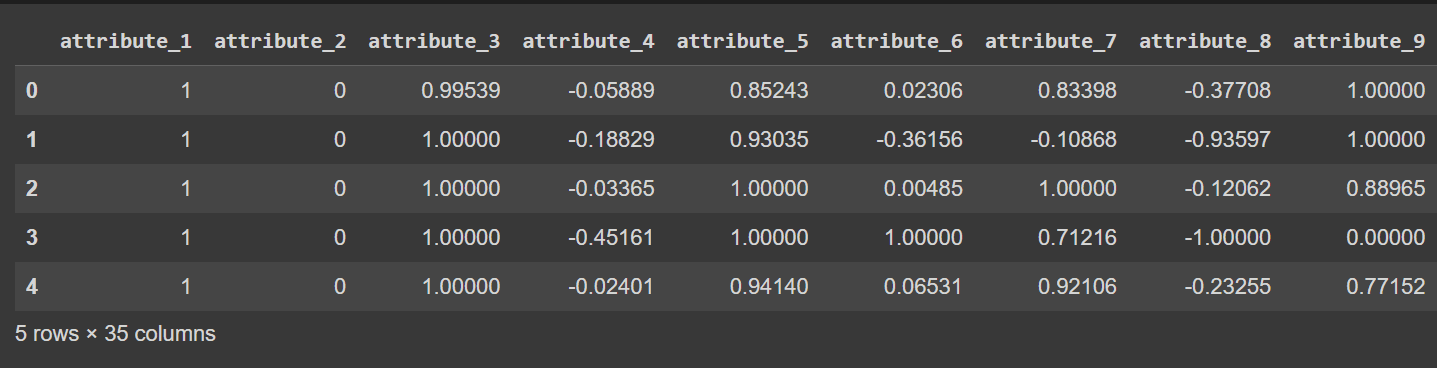
פלט קטוע של df.head() [לאחר שינוי שם עמודות]
שלב 3 - שינוי שמות של תוויות מחלקות והצגה של הפצת מחלקות
מכיוון שתוויות מחלקות הפלט הן 'g' ו-'b', עלינו למפות אותן ל-1 ול-0, בהתאמה. אתה יכול לעשות את זה באמצעות map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
בואו נראה גם את התפלגות תוויות הכיתה:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
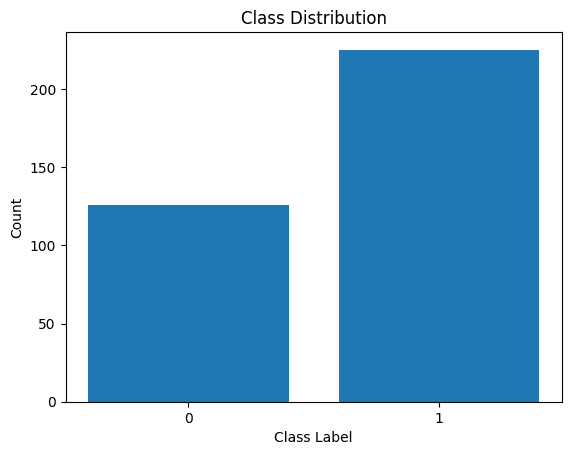
הפצת תוויות כיתות
אנחנו רואים שיש חוסר איזון בהתפלגות. יש יותר רשומות השייכות למחלקה 1 מאשר למחלקה 0. אנו נטפל בחוסר איזון מחלקה זה בעת בניית מודל הרגרסיה הלוגיסטית.
שלב 5 - עיבוד מוקדם של ערכת הנתונים
בואו נאסוף את התכונות ואת תוויות הפלט כך:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
לאחר פיצול מערך הנתונים למערכות הרכבת והבדיקה, עלינו לעבד מראש את מערך הנתונים.
כאשר ישנן תכונות מספריות רבות - כל אחת בקנה מידה שונה - עלינו לעבד מראש את התכונות המספריות. שיטה נפוצה היא להפוך אותם כך שהם עוקבים אחר התפלגות עם אפס ממוצע ושונות יחידה.
השמיים StandardScaler ממודול העיבוד המקדים של scikit-learn עוזר לנו להשיג זאת.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])שלב 6 – בניית מודל רגרסיה לוגיסטי
כעת אנו יכולים ליצור מיון רגרסיה לוגיסטית. ה LogisticRegression class הוא חלק מהמודול linear_model של scikit-learn.
שימו לב שקבענו את class_weight פרמטר ל'מאוזן'. זה יעזור לנו להסביר את חוסר האיזון בכיתה. על ידי הקצאת משקלים לכל מחלקה - ביחס הפוך למספר הרשומות במחלקות.
לאחר הפעלת השיעור, נוכל להתאים את המודל למערך ההדרכה:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)שלב 7 – הערכת מודל הרגרסיה הלוגיסטית
אתה יכול להתקשר אל predict() שיטה לקבל את התחזיות של המודל.
בנוסף לציון הדיוק, נוכל לקבל גם דוח סיווג עם מדדים כמו דיוק, ריקול וציון F1.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
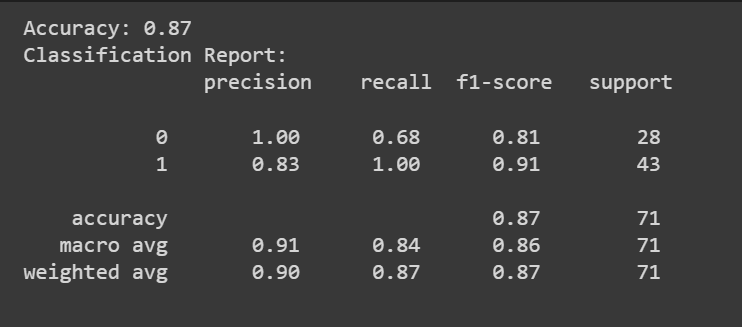
מזל טוב, קודדת את מודל הרגרסיה הלוגיסטית הראשון שלך!
במדריך זה, למדנו על רגרסיה לוגיסטית בפירוט: מתיאוריה ומתמטיקה ועד לקידוד סיווג רגרסיה לוגיסטית.
כשלב הבא, נסה לבנות מודל רגרסיה לוגיסטי עבור מערך נתונים מתאים לבחירתך.
מערך הנתונים של Ionosphere מורשה תחת א Creative Commons Attribution 4.0 בינלאומי רישיון (CC BY 4.0):
Sigillito, V., Wing, S., Hutton, L., and Baker, K.. (1989). יונוספירה. UCI Machine Learning Repository. https://doi.org/10.24432/C5W01B.
באלה פריה סי הוא מפתח וכותב טכני מהודו. היא אוהבת לעבוד בצומת של מתמטיקה, תכנות, מדעי נתונים ויצירת תוכן. תחומי העניין והמומחיות שלה כוללים DevOps, מדעי נתונים ועיבוד שפה טבעית. היא נהנית לקרוא, לכתוב, לקוד ולקפה! נכון לעכשיו, היא עובדת על למידה ומשתפת את הידע שלה עם קהילת המפתחים על ידי יצירת מדריכים, מדריכים, מאמרי דעה ועוד.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :הוא
- :לֹא
- $ למעלה
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- אודות
- חֶשְׁבּוֹן
- דיוק
- להשיג
- להוסיף
- תוספת
- לאחר
- מטרות
- אַלגוֹרִיתְם
- אלגוריתמים
- תעשיות
- גם
- an
- ו
- לענות
- גישות
- ARE
- אזורים
- AS
- לְהַנִיחַ
- At
- מחבר
- b
- אופה
- מאוזן
- בָּר
- BE
- כי
- שייכות
- הטוב ביותר
- לשבור
- לִבנוֹת
- בִּניָן
- by
- שיחה
- CAN
- לא יכול
- קטגוריות
- שרשרת
- בחירה
- בכיתה
- כיתות
- מיון
- מקודד
- סִמוּל
- לגבות
- טור
- עמודות
- Common
- בדרך כלל
- המון עם
- קהילה
- כולל
- תמציתית
- תוכן
- יצירת תוכן
- להמיר
- עלות
- כיסוי
- לִיצוֹר
- יצירה
- כיום
- זונה
- נתונים
- נקודות מידע
- מדע נתונים
- מערך נתונים
- בְּרִירַת מֶחדָל
- מוגדר
- נגזרים
- פרט
- זוהה
- מפתח
- דופים
- אחר
- כיוון
- לדון
- נָדוֹן
- לְהַצִיג
- הפצה
- do
- עושה
- מטה
- להורדה
- בְּמַהֲלָך
- כל אחד
- מַהוּת
- לְהַעֲרִיך
- הערכה
- מומחיות
- היכרות
- ביטוי
- תכונות
- מעטים
- מציאת
- ממצאים
- ראשון
- מתאים
- לעקוב
- כדלקמן
- בעד
- מסגרת
- החל מ-
- פונקציה
- לקבל
- מקבל
- נתן
- Go
- מטרה
- יותר
- קרקע
- מדריך
- יד
- לטפל
- יש
- לעזור
- עוזר
- לה
- איך
- HTTPS
- ICS
- if
- חוסר איזון
- לייבא
- in
- לכלול
- מדד
- הודו
- מדדים
- מידע
- קלט
- תשומות
- אינטרס
- מעניין
- הִצטַלְבוּת
- אל תוך
- IT
- רק
- KDnuggets
- לדעת
- ידע
- תווית
- תוויות
- שפה
- לִלמוֹד
- למד
- למידה
- פחות
- לתת
- סִפְרִיָה
- רישיון
- מורשה
- כמו
- סְבִירוּת
- אוהב
- קו
- טוען
- היכנס
- נראה
- נראה כמו
- את
- מכונה
- למידת מכונה
- לעשות
- רב
- מַפָּה
- מתמטיקה
- matplotlib
- לְהַגדִיל
- מקסום
- מקסימום
- מאי..
- אומר
- שיטה
- מדדים
- לצמצם
- מינימום
- מודל
- מודלים
- מודול
- יותר
- המהלך
- שמות
- טבעי
- שפה טבעית
- עיבוד שפה טבעית
- צורך
- שלילי
- הבא
- מספר
- שנצפה
- of
- לעתים קרובות
- on
- ONE
- דעה
- מול
- אופטימלי
- אופטימיזציה
- מטב
- or
- תוֹצָאָה
- תוצאות
- תפוקה
- פלטים
- דובי פנדה
- פרמטר
- פרמטרים
- חלק
- חתיכות
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- נקודה
- נקודות
- פוטנציאל
- דיוק
- חזה
- התחזיות
- מנבא
- חיזוי
- תחזית
- לְהַעֲדִיף
- הסתברות
- בעיה
- להמשיך
- תהליך
- תהליך
- מוצרים
- תכנות
- לספק
- אַך וְרַק
- פיתון
- מכ"ם
- רכס
- ציון
- חומר עיוני
- קריאה
- ממשי
- רשום
- מכונה
- מתייחס
- נסיגה
- לדווח
- מאגר
- מייצג
- לבקש
- כבוד
- בהתאמה
- החזרות
- סקירה
- חָסוֹן
- כלל
- s
- מדע
- סקיקיט-לימוד
- ציון
- לִרְאוֹת
- תחושה
- סט
- סטים
- שיתוף
- היא
- הראה
- פָּשׁוּט
- לפשט
- So
- כמה
- לפצל
- החל
- סטטיסטיקה
- שלב
- ישר
- מִבְנֶה
- כתוצאה מכך
- כזה
- מַתְאִים
- סכומים
- לקחת
- לוקח
- יעד
- משימות
- טכני
- מבחן
- בדיקות
- מֵאֲשֶׁר
- זֶה
- השמיים
- אותם
- התאוריה
- שם.
- לכן
- הֵם
- זֶה
- דרך
- ל
- ארגז כלים
- רכבת
- מְאוּמָן
- הדרכה
- לשנות
- התמרות
- לנסות
- הדרכה
- הדרכות
- שתיים
- סוגים
- תחת
- להבין
- יחידה
- עדכון
- עדכונים
- כתובת האתר
- us
- חשבון ארה"ב
- להשתמש
- מְשׁוּמָשׁ
- באמצעות
- ערך
- ערכים
- לחזות
- we
- מתי
- אשר
- למה
- ויקיפדיה
- יצטרך
- אגף
- עם
- תיק עבודות
- עובד
- עובד
- היה
- סופר
- כתיבה
- X
- כן
- אתה
- זפירנט
- אפס







