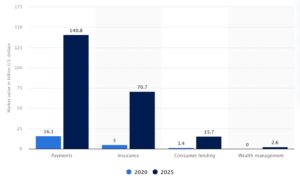
Last year I celebrated two decades of immersion in IT, specifically within the Financial Services sector. During this period I have been a witness to remarkable transformations in banking and technology. The emergence of Fintech companies and their customer-centric
approach, along with significant advancements in software engineering like Agile methodologies, microservices, and cloud computing, have reshaped the landscape. Yet, intriguingly, the back-office operations of many financial service companies have remained
relatively static over these years, still grappling with קידוד ידני, משימות שחוזרות על עצמן והסתמכות רבה על Excel.
תהליך ידני במיוחד ועם זאת ניתן לאוטומטי במגזר השירותים הפיננסיים הוא התאמה ופיוס. This process arises in various forms, i.e. from identifying and addressing discrepancies (typically occurring due to issues
or gaps with the integrations) in master-slave integrations to correcting or removing duplicates and semi-automated updates of operational systems with data from external sources.
למרות הזמינות של תוכנה מתוחכמת (e.g. FIS IntelliMatch, Calypso Confirmation Matching, Misys CMS, Temenos T24 Confirmation Matching…) for specific reconciliation tasks, such as payment and trade confirmation matching
(often based on SWIFT messages), the רוב משימות ההתאמה מסתמכות לרוב על פתרונות מותאמים אישית או ידניים, including Excel or even paper-based methods. Very often automation is also not pertinent, as matching is often involved in one-time actions
like marketing campaigns, data clean-ups, alignment with partners…
הבנת פיוס טוב יותר דורשת מנתח את מרכיביו, כלומר
-
זה מתחיל איסוף ושינוי מערכי הנתונים השונים לצורך השוואה. This consists of recuperating 2 data sets, which can be delivered in different formats, different structures, different scopes and with different names
or enumerations. The data needs to be transformed to make them comparable and loaded into the same tool (e.g. a database or Excel), so that they can be easily compared. -
השלב הבא הוא הגדרת א אלגוריתם התאמה מדויקת. This can be a simple unique key, but it can also a combination of multiple attributes (composite key), a hierarchical rule (i.e. match first on key 1, if no match try on key 2…) or
a fuzzy rule (if key of data set 1 resembles key of data set 2 it is a match). Defining this matching algorithm can be very complex, but it is crucial in the ability to automate the matching and reach a good output quality. -
לאחר הגדרת אלגוריתם ההתאמה, נזין את שלב ההשוואה. For small data sets, this can be done quite simple, but for very large data sets, it can necessitate all kinds of performance optimizations (like indices, segmentation,
parallelism…) in order to execute the comparison in a reasonable time. -
לבסוף, אי-התאמות שזוהו חייבות להיות מתורגמות לתפוקות בר-פעולה, כגון דוחות, תקשורת לעמיתים או צדדים שלישיים או פעולות מתקנות (למשל יצירת קבצים, הודעות או הצהרות SQL כדי לתקן את ההבדלים).
נבכי ההתאמה בשירותים פיננסיים מגוונים. תן לנו לחקור כמה מקרי שימוש טיפוסיים בנוף השירותים הפיננסיים:
-
לרוב הבנקים יש א קובץ מאסטר של ניירות ערך, describing all securities which are in position or can be traded at the bank. This file needs to be integrated with a lot of applications, but also needs to be fed by multiple data sources, like
Telekurs, Reuters, Bloomberg, Moody’s… This means a security needs to be uniquely matched. Unfortunately, there is not 1 unique identifier describing all securities. Publicly traded instruments have a commonly agreed ISIN code, but private and OTC products
like e.g. most derivatives usually do not. Banks have therefore invented internal identifiers, use fake ISIN codes (typically starting with an “X”) or use composite keys to uniquely identify the instrument (e.g. for a derivative this can be combination of
ticker of underlying security, strike price, option type and expiration date). -
בבנקאות קמעונאית זה כמובן חיוני לזהות ולהתאים באופן ייחודי אדם פיזי ספציפי. However even in a developed country like Belgium, this is easier said than done. Every individual in Belgium has a National Register Number,
so this seems the obvious choice for a matching key. Unfortunately, Belgian laws restrict the usage of this number to specific use cases. Additionally this identifier is not existing for foreigners and can change over time (e.g. foreign residents receive first
a temporary National Register number which can change to a definitive, other one later or in case of gender change the National Register Number will change as well). Another option is to use the identity card number, but this is also different for foreigners
and will change every 10 years. Many banks therefore use more complex rules, like a matching based on first name, last name and birth date, but obviously this comes also with all kinds of issues, like duplicates, spelling differences and errors in the names,
use of special characters in the names… -
בעיה מאוד דומה היא התאמה לחברה או ליתר דיוק לחנות. In Belgium, each company has a company number, which is similar to the VAT number (without the “BE” prefix), but this is again very national and 1 VAT number can
have multiple locations (e.g. multiple stores). There exists a concept of a “branch number” (“vestigingsnummer” in Dutch), but this concept is not very well known and rarely used. Similar there exists the LEI code (Legal Entity Identifier) which is a code
of a combination of 20 letters and codes, which uniquely identifies a company worldwide. Unfortunately, only large companies have requested a LEI code, so for smaller companies this is not really an option.
Again more complex matchings are often done, like a combination of VAT number, postal code and house number, but obviously this is far from being ideal. In search for a unique and commonly known identifier, the Google ID becomes also more and more in use, but
the dependency with a commercial company might also poses a big operational risk. -
מקרה מעניין נוסף הוא התאמת הרשאה והודעת הסליקה בתשלום בכרטיס VISA. Normally a unique identifier should match both messages, but due to all kinds of exception cases (e.g. offline authorizations or
incremental authorizations), this will not always be correct. Therefore a more complex rule is required, looking at several identifiers, but also to other matching criteria like acquirer ID, merchant ID, terminal ID, PAN (card number), timestamp and/or amount.
סוג זה של התאמה חל גם על מקרים אחרים של שימוש בתשלום, כמו למשל התאמת השלמת אישור מראש עם האישור הקודם שלו או החזר כספי ברכישה קודמת. -
מקרה שימוש פיננסי הנוגע כמעט לכל עסק התאמת חשבונית ותשלום. When a company issues an invoice, it needs to be able to see when the invoice can be considered as paid. This is important for the accounting, but also
to see if reminders for unpaid invoices should be sent out.
To uniquely match the payment with the invoice, in Belgium typically a structured comment is used in the payment instruction. This unique code with check digit provides a unique matching reference. Unfortunately, customers often forget to put the structured
comment or use the wrong one (e.g. copy/paste of a previous invoice). This means a company needs to have a fallback matching rule in case the unstructured comment is missing or wrong. Typically a combination of payment amount, payment date, IBAN of counterparty
and/or name of counterparty can give an alternative way to match those invoices.
כפי שאתה יכול לראות ההתאמה רחוקה מלהיות קלה, אבל הבנת השלבים הבסיסיים יכולה לעזור בהתאמות טובות יותר. בינתיים, למרות מגבלותיו, Excel נותר כלי רב עוצמה להתאמה (ידנית). לכן א quick reminder for everyone who wants
to do matching in Excel:
-
השתמש VLOOKUP כדי לבצע התאמה. עם זאת, ל-VLOOKUP יש מגבלות מסוימות, כמו העובדה שהוא נותן שגיאה אם אין התאמה וכי אתה יכול לחפש רק בעמודה הראשונה. חלופה חזקה היא להשתמש XLOOKUP, אשר
does not have these limitations. -
אם אתה צריך מפתח חיפוש מורכב, הוסף עמודה במערך נתוני החיפוש שלך, עם מפתח החיפוש המשולב (כלומר שרשרת את התכונות השונות, עם למשל "#" כמפריד) ולאחר מכן השתמש ב-VLOOKUP/XLOOKUP כדי לחפש בעמודה החדשה הזו.
-
כמה נקודות תשומת לב בעת שימוש ב-VLOOKUP:
-
אל תשכח להוסיף "false" כארגומנט האחרון של הפונקציה VLOOKUP כדי להבטיח התאמה מדויקת.
-
Ensure that data formats are the same. E.g. a number “123” and the text “123” will not match, so it is important to convert them to the same format first. Idem for identifiers starting with leading 0’s. Often Excel will convert those to numbers, thus removing
the leading 0’s and not resulting in a match. -
אל תשתמש בערכות נתונים של יותר מ-100.000 שורות ב-Excel. מערכי נתונים גדולים יותר הם בעייתיים עבור הביצועים והיציבות של Excel.
זה גם יכול להיות מעניין לשים את מצב החישוב על "ידני" אם אתה עובד עם VLOOKUP על מערכי נתונים גדולים, אחרת Excel יחשב מחדש את כל ה-VLOOKUP בכל פעם שתבצע שינוי קטן בנתונים. -
ל-VLOOKUP יש את מספר העמודה להחזיר כארגומנט שלישי. מספר זה אינו מותאם באופן דינמי בעת הוספה או הסרה של עמודות, אז זכור להתאים בעת הוספה או הסרה של עמודות.
-
אם אתה רק רוצה התאמה, אתה יכול להשתמש בנוסחה "=IF(ISERROR(VLOOKUP( , ,1,false),"NO MATCH","MATCH")"
-
הטריקים האלה יכולים לעזור להאיץ את ההתאמות הידניות שלך, אבל ברור שאוטומציה אמיתית תמיד טובה יותר.
התאמה בשירותים פיננסיים היא א אתגר רב פנים, but understanding its fundamental steps is key to improving outcomes. While tools like Excel offer temporary solutions, the future lies in intelligent automation, which can significantly
streamline these processes. For those seeking to delve deeper into matching complexities or automation, leveraging advanced tools and platforms, including AI-driven solutions like ChatGPT, can provide both insights and practical solutions.
בדוק את כל הבלוגים שלי ב https://bankloch.blogspot.com/
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://www.finextra.com/blogposting/25297/the-unseen-backbone-of-banking-a-deep-dive-into-matching-and-reconciliation?utm_medium=rssfinextra&utm_source=finextrablogs
- :יש ל
- :הוא
- :לֹא
- $ למעלה
- 000
- 1
- 10
- 100
- 11
- 13
- 14
- 15%
- 20
- 8
- a
- יכולת
- יכול
- חשבונאות
- פעולות
- להסתגל
- מותאם
- להוסיף
- מוסיף
- בנוסף
- פְּנִיָה
- מתקדם
- התקדמות
- שוב
- זריז
- אַלגוֹרִיתְם
- יישור
- תעשיות
- כמעט
- לאורך
- גם
- חלופה
- תמיד
- כמות
- an
- ו
- אחר
- כל
- יישומים
- חל
- גישה
- ARE
- טענה
- AS
- At
- תכונות
- אישור
- אוטומטי
- אוטומציה
- זמינות
- עמוד שדרה
- בנק
- בנקאות
- בנקים
- מבוסס
- בסיסי
- BE
- הופך להיות
- היה
- להיות
- בלגיה
- מוטב
- גָדוֹל
- הולדת
- בלוגים
- בלומברג
- שניהם
- סניף
- עסקים
- אבל
- by
- חישוב
- קמפיינים
- CAN
- כרטיס
- מקרה
- מקרים
- מפורסם
- מסוים
- שינוי
- תווים
- ChatGPT
- לבדוק
- בחירה
- קרחת יער
- ענן
- ענן מחשוב
- CMS
- קוד
- קודים
- עמיתים
- טור
- עמודות
- שילוב
- מגיע
- הערה
- מסחרי
- בדרך כלל
- תקשורת
- חברות
- חברה
- השוואה
- לעומת
- השוואה
- השלמה
- מורכב
- מורכבות
- מחשוב
- מושג
- דאגות
- אישור
- נחשב
- מורכב
- להמיר
- לתקן
- צד נגדי
- מדינה
- הקריטריונים
- מכריע
- מנהג
- לקוחות
- נתונים
- מערך נתונים
- ערכות נתונים
- מסד נתונים
- תַאֲרִיך
- עשרות שנים
- עמוק
- צלילה לעומק
- עמוק יותר
- מוגדר
- הגדרה
- סופי
- נתן
- להתעמק
- תלות
- נגזר
- נגזרים
- המתאר
- למרות
- מפותח
- ההבדלים
- אחר
- ספרות
- שונה
- צלילה
- שונה
- do
- עושה
- עשה
- ראוי
- כפילויות
- בְּמַהֲלָך
- הולנדי
- באופן דינמי
- e
- כל אחד
- קל יותר
- בקלות
- קל
- הִתהַוּוּת
- הַצפָּנָה
- הנדסה
- לְהַבטִיחַ
- זן
- ישות
- שגיאה
- שגיאות
- חיוני
- אֲפִילוּ
- כל
- כולם
- Excel
- יוצא מן הכלל
- לבצע
- קיימים
- קיים
- תפוגה
- חיצוני
- עובדה
- מְזוּיָף
- שקר
- רחוק
- הפד
- שלח
- קבצים
- כספי
- שירות כלכלי
- שירותים פיננסיים
- פינקסטרה
- fintech
- חברות פינטק
- ראשון
- FIS
- לסדר
- בעד
- זר
- פוּרמָט
- צורות
- נוסחה
- החל מ-
- פונקציה
- יסודי
- עתיד
- פערים
- מין
- דור
- לתת
- נותן
- טוב
- מתמודד
- יש
- כבד
- לעזור
- בית
- אולם
- HTTPS
- i
- ID
- אידאל
- מזהה
- מזהים
- מזהה
- לזהות
- זיהוי
- זהות
- if
- טְבִילָה
- חשוב
- שיפור
- in
- כולל
- מצטבר
- מדדים
- בנפרד
- תובנות
- מכשיר
- מכשירים
- משולב
- ואינטגרציות
- אינטליגנטי
- אוטומציה חכמה
- מעניין
- פנימי
- אל תוך
- מורכבויות
- בדוי
- חשבונית
- חשבוניות
- מעורב
- ני"ע
- בעיות
- IT
- שֶׁלָה
- jpg
- רק
- מפתח
- מפתחות
- סוג
- ידוע
- נוף
- גָדוֹל
- גדול יותר
- אחרון
- מאוחר יותר
- חוקים
- מוביל
- משפטי
- ישות משפטית
- לתת
- מינוף
- שקרים
- כמו
- מגבלות
- מקומות
- הסתכלות
- מגרש
- לעשות
- מדריך ל
- רב
- שיווק
- קמפיינים שיווקיים
- אב
- להתאים
- מתאים
- תואם
- אומר
- בינתיים
- סוחר
- הודעה
- הודעות
- מתודולוגיות
- שיטות
- מיקרו
- יכול
- קטין
- חסר
- מצב
- יותר
- רוב
- מספר
- צריך
- my
- שם
- שמות
- לאומי
- צורך
- צרכי
- חדש
- הבא
- לא
- בדרך כלל
- מספר
- מספרים
- ברור
- מתרחש
- of
- הַצָעָה
- לא מחובר
- לעתים קרובות
- on
- ONE
- רק
- מבצעי
- תפעול
- אפשרות
- or
- להזמין
- OTC
- אחר
- אַחֶרֶת
- הַחוּצָה
- תוצאות
- תפוקה
- יותר
- נפרע
- פאן
- מבוסס נייר
- במיוחד
- צדדים
- תשלום
- לבצע
- ביצועים
- תקופה
- גופני
- פלטפורמות
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- תנוחות
- עמדה
- דואר
- חזק
- מעשי
- קודם
- מחיר
- קודם
- פְּרָטִי
- בעיה
- תהליך
- תהליכים
- מוצרים
- לספק
- מספק
- בפומבי
- לִרְכּוֹשׁ
- גם
- איכות
- דַי
- לעתים רחוקות
- לְהַגִיעַ
- ממשי
- בֶּאֱמֶת
- סביר
- לקבל
- פיוס
- הפניה
- החזר
- הירשם
- יחסית
- הסתמכות
- לסמוך
- נשאר
- שְׂרִידִים
- ראוי לציון
- לזכור
- תזכורת
- הסרת
- חוזר על עצמו
- דוחות לדוגמא
- בקשתי
- נדרש
- דומה
- תושבים
- לְהַגבִּיל
- וכתוצאה מכך
- קמעוני
- בנקאות קמעונאית
- לַחֲזוֹר
- רויטרס
- הסיכון
- כלל
- כללי
- אמר
- אותו
- חיפוש
- מגזר
- ניירות ערך
- אבטחה
- לִרְאוֹת
- מחפשים
- נראה
- פילוח
- נשלח
- שרות
- שירותים
- סט
- סטים
- כמה
- צריך
- משמעותי
- באופן משמעותי
- דומה
- פָּשׁוּט
- קטן
- קטן יותר
- So
- תוכנה
- הנדסת תוכנה
- פתרונות
- מקורות
- מיוחד
- ספציפי
- במיוחד
- איות
- SQL
- יציבות
- החל
- התחלות
- הצהרות
- שלב
- צעדים
- עוד
- חנויות
- לייעל
- להכות
- מובנה
- מבנים
- כזה
- SWIFT
- מערכות
- משימות
- טכנולוגיה
- Temenos
- זמני
- מסוף
- טֶקסט
- מֵאֲשֶׁר
- זֶה
- השמיים
- העתיד
- הנוף
- שֶׁלָהֶם
- אותם
- אז
- שם.
- לכן
- אלה
- הֵם
- שְׁלִישִׁי
- צד שלישי
- זֶה
- אלה
- כָּך
- טיקר
- זמן
- חותם
- ל
- כלי
- כלים
- סחר
- נסחר
- טרנספורמציות
- טרנספורמציה
- הפיכה
- לנסות
- שתיים
- סוג
- טיפוסי
- בדרך כלל
- בְּסִיסִי
- הבנה
- לצערי
- ייחודי
- באופן ייחודי
- עדכונים
- us
- נוֹהָג
- להשתמש
- במקרה להשתמש
- מְשׁוּמָשׁ
- באמצעות
- בְּדֶרֶך כְּלַל
- שונים
- מס ערך המוסף
- מאוד
- F-XNUMX
- כרטיס ויזה
- רוצה
- רוצה
- דֶרֶך..
- we
- טוֹב
- מתי
- אשר
- בזמן
- מי
- יצטרך
- עם
- בתוך
- לְלֹא
- עד
- עובד
- עולמי
- טעות
- X
- שנה
- שנים
- עוד
- אתה
- זפירנט