מבוא
בעולם המהיר של היום, שירות לקוחות הוא היבט מכריע בכל עסק. בוט לתשובות של Zendesk, המופעל על ידי מודלים של שפה גדולה (LLMs) כמו GPT-4, יכול לשפר משמעותית את היעילות והאיכות של תמיכת הלקוחות על ידי אוטומציה של תגובות. פוסט זה בבלוג ידריך אותך בבניית ופריסה של Zendesk Auto Responder משלך באמצעות LLMs ויישום זרימות עבודה מבוססות RAG ב- GenAI כדי לייעל את התהליך.

מהן זרימות עבודה מבוססות RAG ב-GenAI
זרימות עבודה מבוססות RAG (Retrieval Augmented Generation) ב-GenAI (Generative AI) משלבות את היתרונות של אחזור ויצירת כדי לשפר את היכולות של מערכת ה-AI, במיוחד בטיפול בנתונים ספציפיים לתחום בעולם האמיתי. במילים פשוטות, RAG מאפשרת ל-AI למשוך מידע רלוונטי ממסד נתונים או ממקורות אחרים כדי לתמוך ביצירת תגובות מדויקות ומושכלות יותר. זה מועיל במיוחד בהגדרות עסקיות שבהן דיוק והקשר הם קריטיים.
מהם הרכיבים בזרימת עבודה מבוססת RAG
- בסיס ידע: מאגר הידע הוא מאגר מידע מרכזי שהמערכת מתייחסת אליו בעת מענה לשאילתות. זה יכול לכלול שאלות נפוצות, מדריכים ומסמכים רלוונטיים אחרים.
- טריגר/שאילתה: רכיב זה אחראי על התחלת זרימת העבודה. בדרך כלל שאלה או בקשה של לקוח דורשות מענה או פעולה.
- משימה/פעולה: בהתבסס על ניתוח הטריגר/שאילתה, המערכת מבצעת משימה או פעולה ספציפית, כמו יצירת תגובה או ביצוע פעולת אחורי.
כמה דוגמאות לזרימות עבודה מבוססות RAG
- זרימת עבודה של אינטראקציה עם לקוחות בבנקאות:
- צ'טבוטים המופעלים על ידי GenAI ו-RAG יכולים לשפר משמעותית את שיעורי המעורבות בתעשיית הבנקאות על ידי התאמה אישית של אינטראקציות.
- באמצעות RAG, הצ'אטבוטים יכולים לאחזר ולנצל מידע רלוונטי ממסד נתונים כדי ליצור תשובות מותאמות אישית לפניות לקוחות.
- לדוגמה, במהלך פגישת צ'אט, מערכת GenAI מבוססת RAG יכולה למשוך את היסטוריית העסקאות של הלקוח או פרטי חשבון ממסד נתונים כדי לספק תשובות מושכלות ומותאמות אישית יותר.
- זרימת עבודה זו לא רק משפרת את שביעות רצון הלקוחות, אלא גם מגדילה את שיעור השימור על ידי מתן חווית אינטראקציה אישית ואינפורמטיבית יותר.
- זרימת עבודה של קמפיינים בדוא"ל:
- בשיווק ומכירות, יצירת קמפיינים ממוקדים היא קריטית.
- ניתן להשתמש ב-RAG כדי למשוך את המידע העדכני ביותר על המוצר, משוב לקוחות או מגמות שוק ממקורות חיצוניים כדי לעזור ליצור חומר שיווקי/מכירות מושכל ואפקטיבי יותר.
- לדוגמה, בעת יצירת מסע פרסום בדוא"ל, זרימת עבודה מבוססת RAG יכולה לאחזר ביקורות חיוביות אחרונות או תכונות מוצר חדשות שייכללו בתוכן הקמפיין, ובכך עשויות לשפר את שיעורי המעורבות ותוצאות המכירה.
- תיעוד קוד אוטומטי וזרימת עבודה:
- בתחילה, מערכת RAG יכולה למשוך תיעוד קוד קיים, בסיס קוד ותקני קידוד ממאגר הפרויקט.
- כאשר מפתח צריך להוסיף תכונה חדשה, RAG יכול ליצור קטע קוד בהתאם לתקני הקידוד של הפרויקט על ידי הפניה למידע שאוחזר.
- אם יש צורך בשינוי בקוד, מערכת RAG יכולה להציע שינויים על ידי ניתוח הקוד והתיעוד הקיימים, תוך הבטחת עקביות ועמידה בתקני קידוד.
- שינוי או הוספה של מיקוד, RAG יכול לעדכן אוטומטית את תיעוד הקוד כדי לשקף את השינויים, תוך משיכת מידע הכרחי מבסיס הקוד ומהתיעוד הקיים.
כיצד להוריד ולאינדקס את כל הכרטיסים של Zendesk לאחזור
כעת נתחיל עם המדריך. נבנה בוט שיענה על כרטיסים נכנסים של Zendesk תוך שימוש במסד נתונים מותאם אישית של כרטיסים ותגובות בעבר של Zendesk כדי ליצור את התשובה בעזרת LLMs.
- גישה ל-Zendesk API: השתמש ב-Zendesk API כדי לגשת ולהוריד את כל הכרטיסים. ודא שיש לך את ההרשאות ומפתחות ה-API הדרושים כדי לגשת לנתונים.
תחילה אנו יוצרים את מפתח ה-API של Zendesk. ודא שאתה משתמש Admin ובקר בקישור הבא כדי ליצור את מפתח ה-API שלך - https://YOUR_SUBDOMAIN.zendesk.com/admin/apps-integrations/apis/zendesk-api/settings/tokens
צור מפתח API והעתק אותו ללוח שלך.

הבה נתחיל כעת במחברת פיתון.
אנו מזינים את האישורים של Zendesk שלנו, כולל מפתח ה-API שהשגנו זה עתה.
subdomain = YOUR_SUBDOMAIN
username = ZENDESK_USERNAME
password = ZENDESK_API_KEY
username = '{}/token'.format(username)כעת אנו מאחזרים את נתוני הכרטיסים. בקוד שלהלן, שלפנו שאילתות ותשובות מכל כרטיס, ומאחסנים כל קבוצה [שאילתה, מערך תשובות] המייצגת כרטיס לתוך מערך שנקרא נתוני כרטיסים.
אנחנו מביאים רק את 1000 הכרטיסים האחרונים. אתה יכול לשנות את זה לפי הצורך.
import requests ticketdata = []
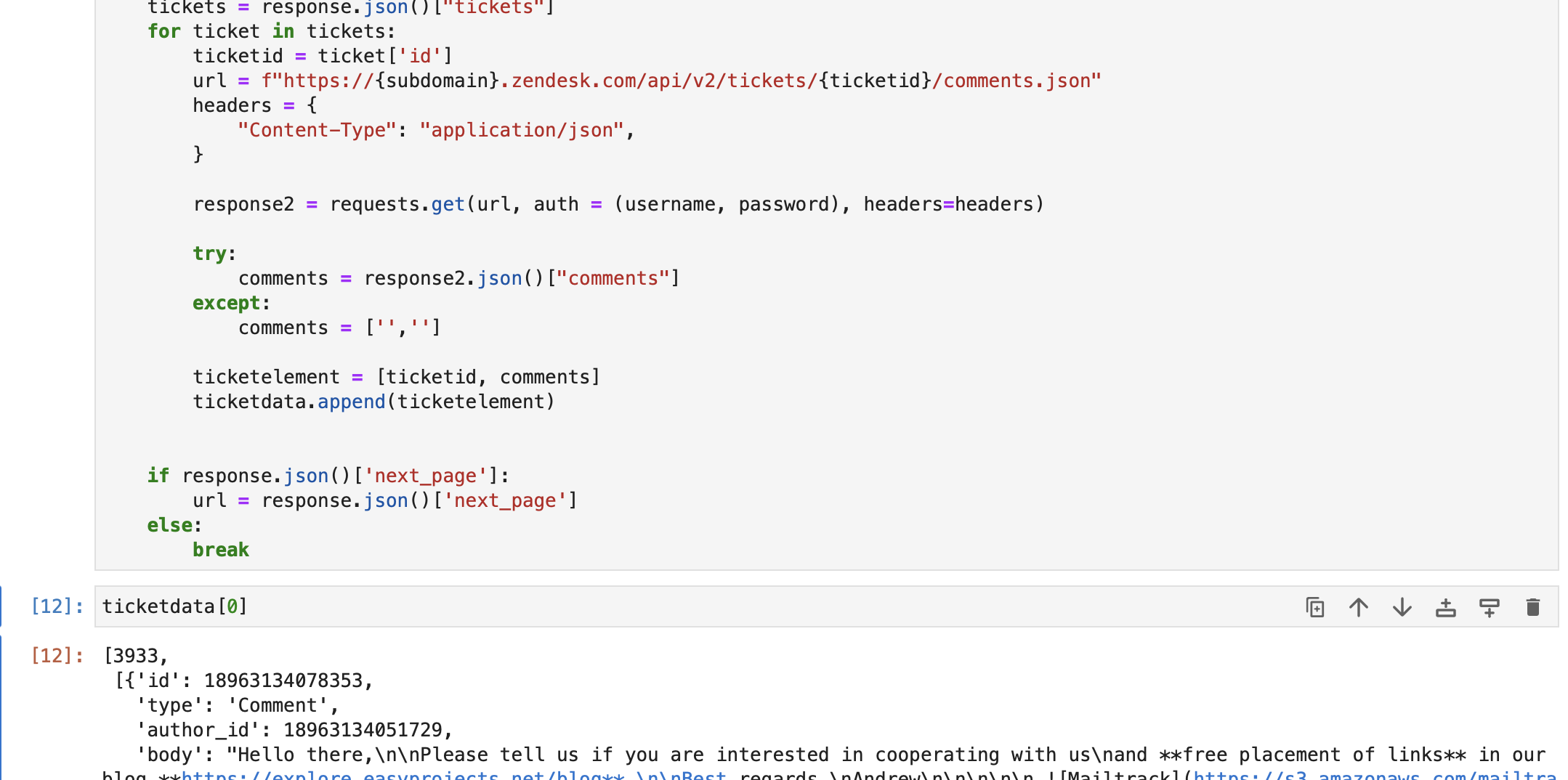
url = f"https://{subdomain}.zendesk.com/api/v2/tickets.json" params = {"sort_by": "created_at", "sort_order": "desc"} headers = {"Content-Type": "application/json"} tickettext = "" while len(ticketdata) <= 1000: response = requests.get( url, auth=(username, password), params=params, headers=headers ) tickets = response.json()["tickets"] for ticket in tickets: ticketid = ticket["id"] url = f"https://{subdomain}.zendesk.com/api/v2/tickets/{ticketid}/comments.json" headers = { "Content-Type": "application/json", } response2 = requests.get(url, auth=(username, password), headers=headers) try: comments = response2.json()["comments"] except: comments = ["", ""] ticketelement = [ticketid, comments] ticketdata.append(ticketelement) if response.json()["next_page"]: url = response.json()["next_page"] else: breakכפי שניתן לראות להלן, שלפנו נתוני כרטיסים מ-Zendesk db. כל אלמנט ב נתוני כרטיסים מכיל –
א. מזהה כרטיס
ב. כל ההערות / התשובות בכרטיס.
לאחר מכן נמשיך ליצור מחרוזת מבוססת טקסט הכוללת את השאילתות והתגובות הראשונות מכל הכרטיסים שאוחזרו, באמצעות נתוני כרטיסים מערך.
for ticket in ticketdata: try: text = ( "nnn" + "Question - " + ticket[1][0]["body"] + "n" + "Answer - " + ticket[1][1]["body"] ) tickettext = tickettext + text except: passהשמיים טקסט כרטיס מחרוזת מכילה כעת את כל הכרטיסים והתגובות הראשונות, כאשר הנתונים של כל כרטיס מופרדים על ידי תווים בשורה חדשה.

אופציונאלי : אתה יכול גם להביא נתונים ממאמרי התמיכה של Zendesk כדי להרחיב את בסיס הידע עוד יותר, על ידי הפעלת הקוד שלהלן.
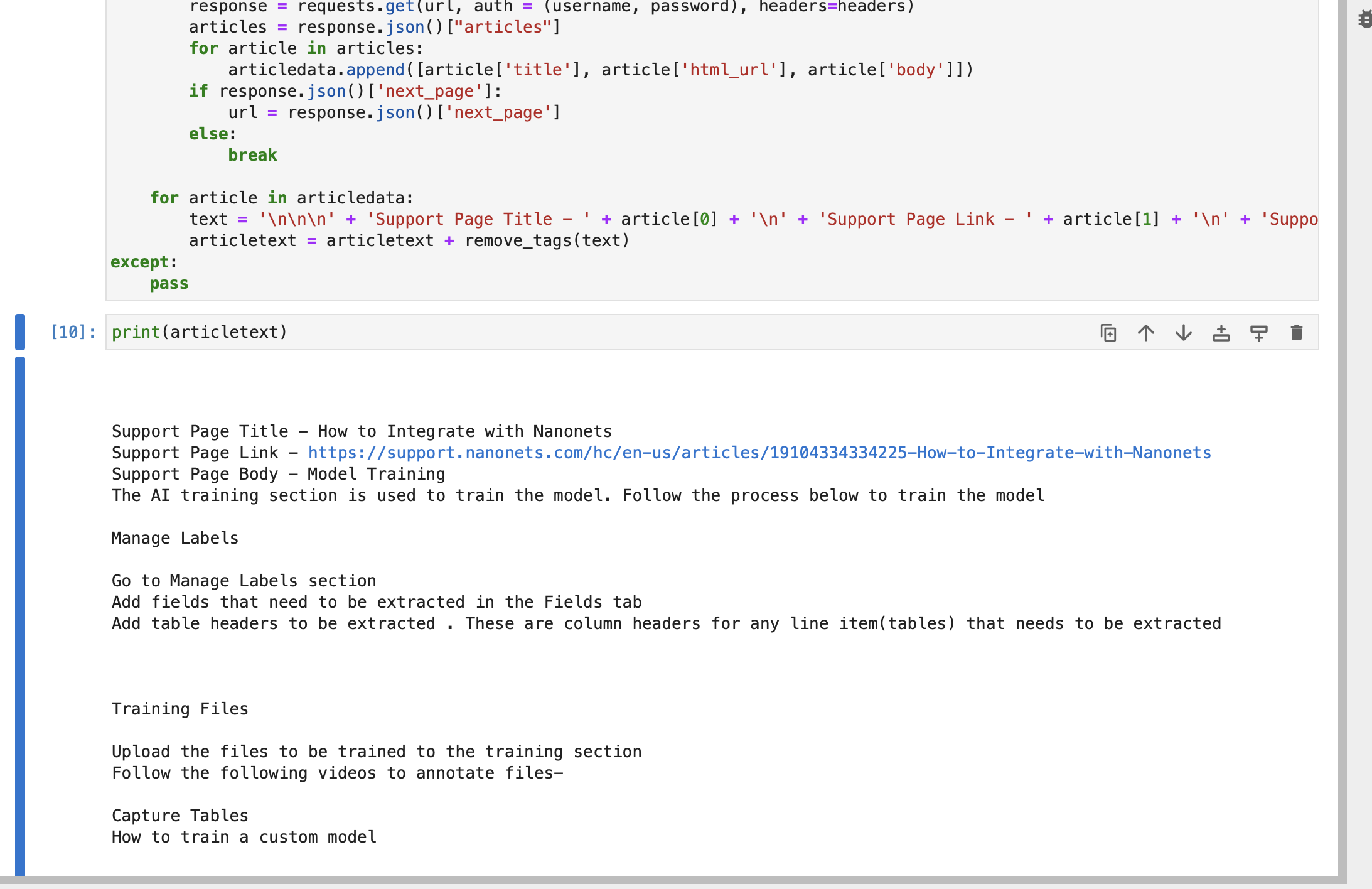
import re def remove_tags(text): clean = re.compile("<.*?>") return re.sub(clean, "", text) articletext = ""
try: articledata = [] url = f"https://{subdomain}.zendesk.com/api/v2/help_center/en-us/articles.json" headers = {"Content-Type": "application/json"} while True: response = requests.get(url, auth=(username, password), headers=headers) articles = response.json()["articles"] for article in articles: articledata.append([article["title"], article["html_url"], article["body"]]) if response.json()["next_page"]: url = response.json()["next_page"] else: break for article in articledata: text = ( "nnn" + "Support Page Title - " + article[0] + "n" + "Support Page Link - " + article[1] + "n" + "Support Page Body - " + article[2] ) articletext = articletext + remove_tags(text)
except: passהמיתר טקסט מאמר מכיל כותרת, קישור וגוף של כל מאמר מעמודי התמיכה שלך ב-Zendesk.
אופציונלי : אתה יכול לחבר את מסד הנתונים של הלקוחות שלך או כל מסד נתונים רלוונטי אחר, ולאחר מכן להשתמש בו בזמן יצירת חנות האינדקס.
שלב את הנתונים שהובאו.
knowledge = tickettext + "nnn" + articletext- כרטיסי אינדקס: לאחר ההורדה, אינדקס את הכרטיסים באמצעות שיטת אינדקס מתאימה כדי להקל על שליפה מהירה ויעילה.
לשם כך, אנו מתקינים תחילה את התלות הנדרשות ליצירת מאגר הווקטור.
pip install langchain openai pypdf faiss-cpuצור מאגר אינדקס באמצעות הנתונים שהובאו. זה ישמש כבסיס הידע שלנו כאשר ננסה לענות על כרטיסים חדשים באמצעות GPT.
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY" from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from transformers import GPT2TokenizerFast
import os
import pandas as pd
import numpy as np tokenizer = GPT2TokenizerFast.from_pretrained("gpt2") def count_tokens(text: str) -> int: return len(tokenizer.encode(text)) text_splitter = RecursiveCharacterTextSplitter( chunk_size=512, chunk_overlap=24, length_function=count_tokens,
) chunks = text_splitter.create_documents([knowledge]) token_counts = [count_tokens(chunk.page_content) for chunk in chunks]
df = pd.DataFrame({"Token Count": token_counts})
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(chunks, embeddings)
path = "zendesk-index"
db.save_local(path)
האינדקס שלך נשמר במערכת המקומית שלך.

- עדכן את האינדקס באופן קבוע: עדכן באופן קבוע את האינדקס כדי לכלול כרטיסים חדשים ושינויים לקיימים, כדי להבטיח שלמערכת תהיה גישה לנתונים העדכניים ביותר.
אנו יכולים לתזמן את הסקריפט הנ"ל להפעלה מדי שבוע, ולעדכן את ה-'zendesk-index' שלנו או כל תדירות רצויה אחרת.
כיצד לבצע שליפה כאשר נכנס כרטיס חדש
- מעקב אחר כרטיסים חדשים: הגדר מערכת לניטור Zendesk עבור כרטיסים חדשים באופן רציף.
ניצור ממשק API בסיסי של Flask ונארח אותו. להתחיל,
- צור תיקיה חדשה בשם 'Zendesk Answer Bot'.
- הוסף את תיקיית FAISS db 'zendesk-index' לתיקיית 'Zendesk Answer Bot'.
- צור קובץ פיתון חדש zendesk.py והעתק לתוכו את הקוד שלהלן.
from flask import Flask, request, jsonify app = Flask(__name__) @app.route('/zendesk', methods=['POST'])
def zendesk(): return 'dummy response' if __name__ == '__main__': app.run(port=3001, debug=True)- הפעל את קוד הפיתון.

- הורד והגדר את ngrok באמצעות ההוראות כאן. הקפד להגדיר את ngrok Authtoken בטרמינל שלך לפי ההנחיות בקישור.
- פתח מופע מסוף חדש והפעל מתחת לפקודה.
ngrok http 3001- כעת יש לנו את שירות ה-Flask שלנו חשוף באמצעות IP חיצוני באמצעותו נוכל לבצע קריאות API לשירות שלנו מכל מקום.

- לאחר מכן, הגדרנו Zendesk Webhook, על ידי ביקור בקישור הבא - https://YOUR_SUBDOMAIN.zendesk.com/admin/apps-integrations/webhooks/webhooks או הפעלה ישירה של הקוד שלהלן במחברת Jupyter המקורית שלנו.
הערה: חשוב לציין שבעוד השימוש ב-ngrok טוב למטרות בדיקה, מומלץ מאוד להעביר את שירות ה-Flask API למופע שרת. במקרה זה, ה-IP הסטטי של השרת הופך לנקודת הקצה של Zendesk Webhook ותצטרך להגדיר את נקודת הקצה ב-Zendesk Webhook שלך כך שתצביע לעבר כתובת זו - https://YOUR_SERVER_STATIC_IP:3001/zendesk
zendesk_workflow_endpoint = "HTTPS_NGROK_FORWARDING_ADDRESS" url = "https://" + subdomain + ".zendesk.com/api/v2/webhooks"
payload = { "webhook": { "endpoint": zendesk_workflow_endpoint, "http_method": "POST", "name": "Nanonets Workflows Webhook v1", "status": "active", "request_format": "json", "subscriptions": ["conditional_ticket_events"], }
}
headers = {"Content-Type": "application/json"} auth = (username, password) response = requests.post(url, json=payload, headers=headers, auth=auth)
webhook = response.json() webhookid = webhook["webhook"]["id"]
- כעת הגדרנו Zendesk Trigger, שיפעיל את ה-webhook הנ"ל שיצרנו זה עתה לפעול בכל פעם שיופיע כרטיס חדש. אנו יכולים להגדיר את הטריגר של Zendesk על ידי ביקור בקישור הבא - https://YOUR_SUBDOMAIN.zendesk.com/admin/objects-rules/rules/triggers או על ידי הפעלת הקוד שלהלן ישירות במחברת Jupyter המקורית שלנו.
url = "https://" + subdomain + ".zendesk.com/api/v2/triggers.json" trigger_payload = { "trigger": { "title": "Nanonets Workflows Trigger v1", "active": True, "conditions": {"all": [{"field": "update_type", "value": "Create"}]}, "actions": [ { "field": "notification_webhook", "value": [ webhookid, json.dumps( { "ticket_id": "{{ticket.id}}", "org_id": "{{ticket.url}}", "subject": "{{ticket.title}}", "body": "{{ticket.description}}", } ), ], } ], }
} response = requests.post(url, auth=(username, password), json=trigger_payload)
trigger = response.json()
- אחזר מידע רלוונטי: כאשר נכנס כרטיס חדש, השתמש במאגר הידע המאונדקס כדי לאחזר מידע רלוונטי וכרטיסי עבר שיכולים לעזור ביצירת תגובה.
לאחר הגדרת הטריגר וה-webhook, Zendesk תבטיח ששירות Flask הפועל כעת שלנו יקבל קריאת API במסלול /zendesk עם מזהה הכרטיס, הנושא והגוף בכל פעם שיגיע כרטיס חדש.
כעת עלינו להגדיר את שירות הבקבוקים שלנו ל
א. ליצור תגובה באמצעות חנות הווקטור שלנו 'zendesk-index'.
ב. עדכן את הכרטיס עם התגובה שנוצרה.
אנו מחליפים את קוד השירות הנוכחי שלנו ב-zendesk.py בקוד שלהלן -
from flask import Flask, request, jsonify
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from transformers import GPT2TokenizerFast
import os
import pandas as pd
import numpy as np app = Flask(__name__) @app.route('/zendesk', methods=['POST'])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson['body'] zendb = FAISS.load_local('zendesk-index', zenembeddings) docs = zendb.similarity_search(query) if __name__ == '__main__': app.run(port=3001, debug=True)כפי שאתה יכול לראות, הרצנו חיפוש דמיון באינדקס הווקטור שלנו ואחזרנו את הכרטיסים והמאמרים הרלוונטיים ביותר כדי לעזור ליצור תגובה.
כיצד ליצור תגובה ולפרסם ב-Zendesk
- צור תגובה: השתמש ב- LLM כדי ליצור תגובה קוהרנטית ומדויקת בהתבסס על המידע שאוחזר וההקשר המנותח.
הבה נמשיך כעת בהגדרת נקודת הקצה של ה-API שלנו. אנו משנים עוד את הקוד כפי שמוצג להלן כדי ליצור תגובה על סמך המידע הרלוונטי שאוחזר.
@app.route("/zendesk", methods=["POST"])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson["body"] zendb = FAISS.load_local("zendesk-index", zenembeddings) docs = zendb.similarity_search(query) zenchain = load_qa_chain(OpenAI(temperature=0.7), chain_type="stuff") answer = zenchain.run(input_documents=docs, question=query)
השמיים לענות המשתנה יכיל את התגובה שנוצרה.
- תגובת ביקורת: לחלופין, בקש מסוכן אנושי לבדוק את התגובה שנוצרה על דיוק והתאמה לפני הפרסום.
הדרך שבה אנו מבטיחים זאת היא על ידי אי פרסום התגובה שנוצרה על ידי GPT ישירות כתשובת Zendesk. במקום זאת, ניצור פונקציה לעדכון כרטיסים חדשים עם הערה פנימית המכילה את התגובה שנוצרה על ידי GPT.
הוסף את הפונקציה הבאה לשירות הבקבוקים zendesk.py -
def update_ticket_with_internal_note( subdomain, ticket_id, username, password, comment_body
): url = f"https://{subdomain}.zendesk.com/api/v2/tickets/{ticket_id}.json" email = username headers = {"Content-Type": "application/json"} comment_body = "Suggested Response - " + comment_body data = {"ticket": {"comment": {"body": comment_body, "public": False}}} response = requests.put(url, json=data, headers=headers, auth=(email, password))
- פרסם ב-Zendesk: השתמש ב-Zendesk API כדי לפרסם את התגובה שנוצרה לכרטיס המתאים, תוך הבטחת תקשורת בזמן עם הלקוח.
הבה נשלב כעת את הפונקציה הפנימית של יצירת הערות בנקודת הקצה של ה-API שלנו.
@app.route("/zendesk", methods=["POST"])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson["body"] zendb = FAISS.load_local("zendesk-index", zenembeddings) docs = zendb.similarity_search(query) zenchain = load_qa_chain(OpenAI(temperature=0.7), chain_type="stuff") answer = zenchain.run(input_documents=docs, question=query) update_ticket_with_internal_note(subdomain, ticket, username, password, answer) return answer
זה משלים את זרימת העבודה שלנו!
תן לנו לשנות את זרימת העבודה שהקמנו -
- Zendesk Trigger שלנו מתחיל את זרימת העבודה כאשר מופיע כרטיס Zendesk חדש.
- הטריגר שולח את נתוני הכרטיס החדש ל-Webhook שלנו.
- ה-Webhook שלנו שולח בקשה לשירות הבקבוקים שלנו.
- שירות הבקבוקים שלנו מבצע שאילתות בחנות הווקטורית שנוצרה באמצעות נתוני Zendesk בעבר כדי לאחזר כרטיסים ומאמרים רלוונטיים בעבר כדי לענות על הכרטיס החדש.
- הכרטיסים והכתבות הרלוונטיים בעבר מועברים ל-GPT יחד עם נתוני הכרטיס החדש כדי ליצור תגובה.
- הכרטיס החדש מתעדכן בהערה פנימית המכילה את התגובה שנוצרה על ידי GPT.
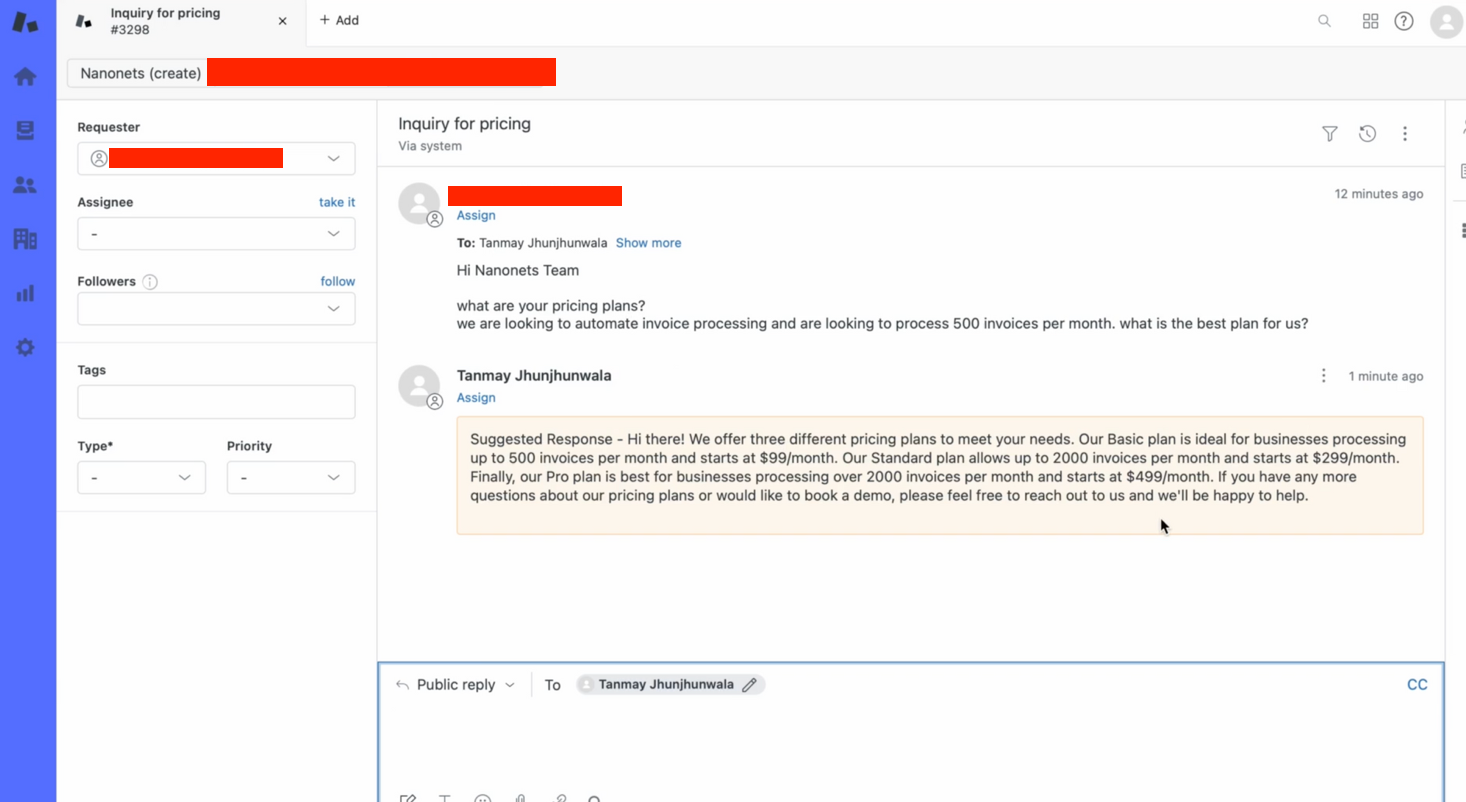
אנחנו יכולים לבדוק זאת ידנית -
- אנו יוצרים כרטיס ב-Zendesk באופן ידני כדי לבדוק את הזרימה.
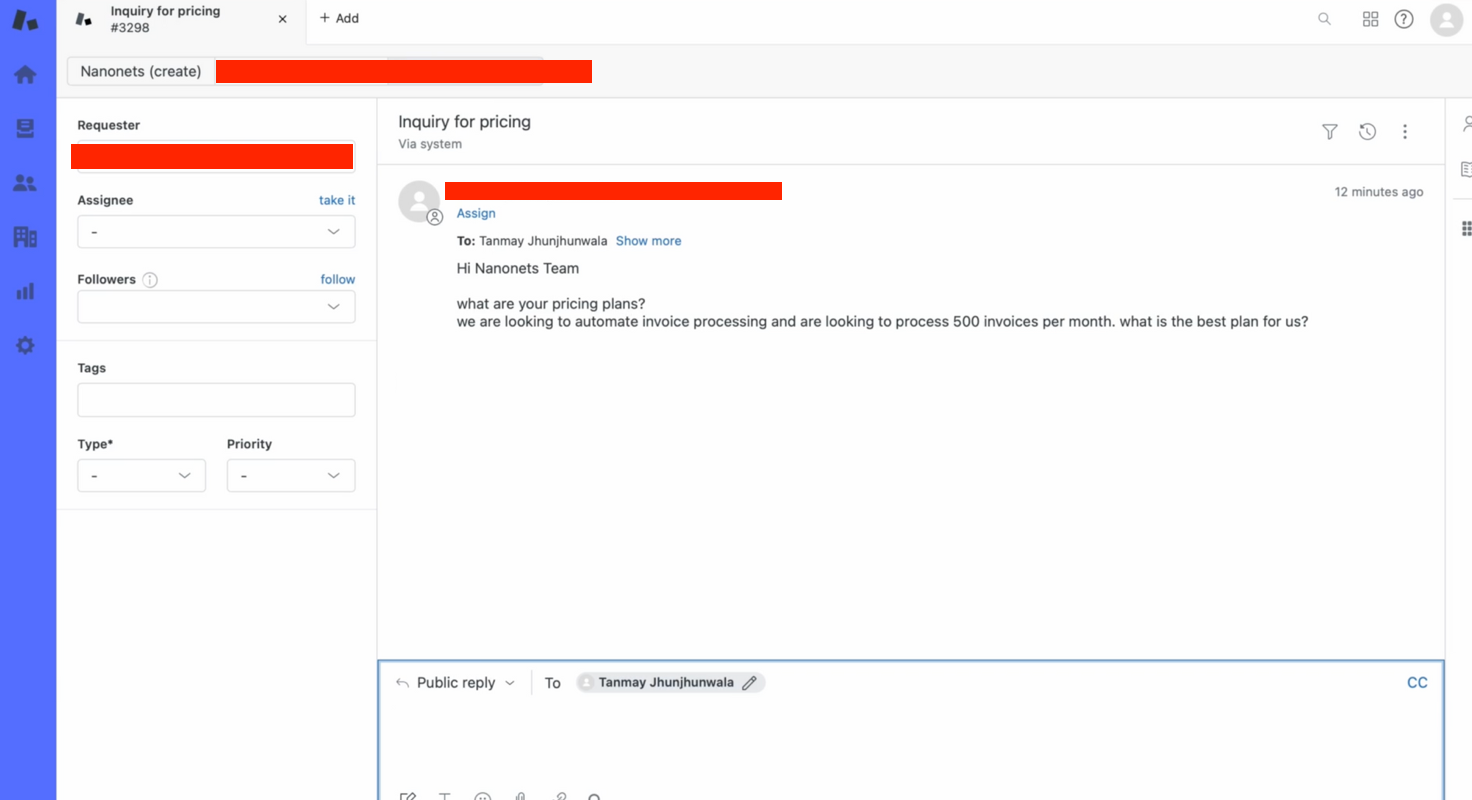
- תוך שניות, הבוט שלנו מספק מענה רלוונטי לשאילתת הכרטיסים!
איך לעשות את כל זרימת העבודה הזו עם Nanonets
Nanonets מציעה פלטפורמה רבת עוצמה ליישום וניהול זרימות עבודה מבוססות RAG בצורה חלקה. כך תוכל למנף Nanonets עבור זרימת עבודה זו:
- שילוב עם Zendesk: חבר את Nanonets עם Zendesk כדי לנטר ולאחזר כרטיסים ביעילות.
- בנה ואימון דגמים: השתמש ב-Nanonets כדי לבנות ולהכשיר LLMs ליצירת תגובות מדויקות וקוהרנטיות בהתבסס על בסיס הידע וההקשר המנותח.
- אוטומציה של תגובות: הגדר כללי אוטומציה ב- Nanonets כדי לפרסם באופן אוטומטי תגובות שנוצרו ל- Zendesk או להעביר אותן לסוכנים אנושיים לבדיקה.
- לפקח ולבצע אופטימיזציה: לפקח באופן רציף על ביצועי זרימת העבודה ולבצע אופטימיזציה של המודלים והכללים כדי לשפר את הדיוק והיעילות.
על ידי שילוב של LLMs עם זרימות עבודה מבוססות RAG ב-GenAI ומינוף היכולות של Nanonets, עסקים יכולים לשפר באופן משמעותי את פעולות תמיכת הלקוחות שלהם, לספק מענה מהיר ומדויק לשאלות לקוחות ב-Zendesk.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://nanonets.com/blog/build-your-own-zendesk-answer-bot-with-llms/
- :יש ל
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 06
- 08
- 1
- 2000
- 28
- 32
- 40
- 7
- a
- מֵעַל
- גישה
- חֶשְׁבּוֹן
- דיוק
- מדויק
- לפעול
- פעולה
- פעולות
- פעיל
- להוסיף
- תוספת
- כתובת
- דבקות
- מנהל
- סוֹכֵן
- סוכנים
- AI
- תעשיות
- לאורך
- גם
- an
- אנליזה
- מְנוּתָח
- ניתוח
- ו
- לענות
- כל
- בְּכָל מָקוֹם
- API
- האפליקציה
- מופיע
- ARE
- מערך
- מגיע
- מאמר
- מאמרים
- AS
- אספקט
- At
- ניסיון
- מוגבר
- תודה
- המכונית
- באופן אוטומטי
- אוטומציה
- אוטומציה
- קצה אחורי
- בנקאות
- בענף הבנקאות
- בסיס
- מבוסס
- בסיסי
- BE
- הופך להיות
- היה
- לפני
- להלן
- מועיל
- הטבות
- בלוג
- גוּף
- בוט
- לשבור
- לִבנוֹת
- בִּניָן
- עסקים
- עסקים
- אבל
- by
- שיחה
- נקרא
- שיחות
- מבצע
- קמפיינים
- CAN
- יכולות
- מקרה
- מְרוּכָּז
- שרשראות
- שינויים
- תווים
- chatbot
- chatbots
- קוד
- בסיס קוד
- סִמוּל
- קוהרנטי
- COM
- לשלב
- מגיע
- הערה
- הערות
- תקשורת
- הושלם
- רְכִיב
- רכיבים
- תנאים
- לְחַבֵּר
- להכיל
- מכיל
- תוכן
- הקשר
- להמשיך
- ברציפות
- תוֹאֵם
- יכול
- לִיצוֹר
- נוצר
- יוצרים
- יצירה
- אישורים
- קריטי
- מכריע
- נוֹכְחִי
- כיום
- מנהג
- לקוח
- שביעות רצון של לקוח
- שירות לקוחות
- שירות לקוחות
- נתונים
- מסד נתונים
- תלות
- פריסה
- רצוי
- מפתח
- מְכוּוָן
- ישירות
- do
- תיעוד
- מסמכים
- להורדה
- בְּמַהֲלָך
- כל אחד
- אפקטיבי
- יְעִילוּת
- יעיל
- יעילות
- או
- אלמנט
- אחר
- אמייל
- מוטבע
- מוּעֳסָק
- מאפשר
- נקודת קצה
- התעסקות
- להגביר את
- משפר
- לְהַבטִיחַ
- הבטחתי
- שלם
- Ether (ETH)
- כל
- דוגמה
- דוגמאות
- אלא
- קיימים
- לְהַרְחִיב
- חשוף
- חיצוני
- לְהַקֵל
- שקר
- מהיר
- מאפיין
- תכונות
- מָשׁוֹב
- הושג
- שדה
- שלח
- ראשון
- תזרים
- הבא
- בעד
- קדימה
- תדר
- החל מ-
- פונקציה
- נוסף
- ליצור
- נוצר
- יצירת
- דור
- גנרטטיבית
- AI Generative
- לקבל
- gif
- טוב
- מדריך
- טיפול
- יש
- יש
- כותרות
- לעזור
- היסטוריה
- המארח
- איך
- http
- HTTPS
- בן אנוש
- ID
- if
- ליישם
- יישום
- לייבא
- חשוב
- לשפר
- שיפור
- in
- לכלול
- כולל
- נכנס
- בע"מ
- עליות
- מדד
- -
- תעשייה
- מידע
- אִינפוֹרמָטִיבִי
- הודעה
- ייזום
- קלט
- פניות
- להתקין
- למשל
- במקום
- הוראות
- שילוב
- אינטראקציה
- יחסי גומלין
- פנימי
- אל תוך
- מבוא
- IP
- IT
- ג'סון
- מחברת צדק
- רק
- מפתח
- מפתחות
- ידע
- שפה
- גָדוֹל
- האחרון
- תנופה
- מינוף
- כמו
- קשר
- מקומי
- לעשות
- לנהל
- באופן ידני
- שוק
- טרנדים בשוק
- שיווק
- חוֹמֶר
- שיטה
- מודלים
- שינויים
- לשנות
- צג
- יותר
- רוב
- המהלך
- שם
- הכרחי
- צורך
- נחוץ
- צרכי
- חדש
- תכונה חדשה
- מוצר חדש
- הערות
- מחברה
- עַכשָׁיו
- קהות
- מושג
- of
- המיוחדות שלנו
- on
- פעם
- יחידות
- רק
- OpenAI
- מבצע
- תפעול
- מטב
- or
- מְקוֹרִי
- OS
- אחר
- שלנו
- יותר
- שֶׁלוֹ
- עמוד
- דפים
- דובי פנדה
- חלק
- במיוחד
- עבר
- סיסמה
- עבר
- נתיב
- לבצע
- ביצועים
- ביצוע
- מבצע
- הרשאות
- אישית
- פלטפורמה
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- נקודה
- חיובי
- הודעה
- פוטנציאל
- מופעל
- חזק
- תהליך
- המוצר
- מידע על מוצר
- פּרוֹיֶקט
- פרויקטים
- להציע
- לספק
- מספק
- מתן
- ציבורי
- מושך
- למטרות
- פיתון
- איכות
- שאילתות
- שאלה
- מָהִיר
- ציון
- תעריפים
- RE
- עולם אמיתי
- לאחרונה
- מוּמלָץ
- התייחסות
- מתייחס
- לשקף
- באופן קבוע
- רלוונטי
- להחליף
- תשובה
- מאגר
- המייצג
- לבקש
- בקשות
- נדרש
- תגובה
- תגובות
- אחראי
- שייר
- לַחֲזוֹר
- סקירה
- חוות דעת של לקוחותינו
- לְהַגִיהַ
- מסלול
- כללי
- הפעלה
- ריצה
- s
- מכירות
- שביעות רצון
- הציל
- לוח זמנים
- תסריט
- בצורה חלקה
- חיפוש
- שניות
- לִרְאוֹת
- שולח
- שרת
- שרות
- מושב
- סט
- הצבה
- הגדרות
- משמרת
- הראה
- באופן משמעותי
- פָּשׁוּט
- קטע
- מקורות
- ספציפי
- תקנים
- החל
- התחלות
- מצב
- חנות
- לייעל
- מחרוזת
- בְּתוֹקֶף
- תת-דומיין
- נושא
- מנוי
- כזה
- מַתְאִים
- תמיכה
- בטוח
- SWIFT
- מערכת
- ממוקד
- המשימות
- מסוף
- מונחים
- מבחן
- בדיקות
- טֶקסט
- זֶה
- השמיים
- שֶׁלָהֶם
- אותם
- אז
- זֶה
- דרך
- כָּך
- כרטיס
- כרטיסים
- אקטואלי
- כותרת
- ל
- של היום
- אסימון
- לקראת
- רכבת
- עסקה
- רוֹבּוֹטרִיקִים
- מגמות
- להפעיל
- נָכוֹן
- לנסות
- הדרכה
- עדכון
- מְעוּדכָּן
- כתובת האתר
- us
- להשתמש
- משתמש
- באמצעות
- בְּדֶרֶך כְּלַל
- לנצל
- v1
- ערך
- באמצעות
- Vimeo
- לְבַקֵר
- דֶרֶך..
- we
- שבוע
- מתי
- בכל פעם
- אשר
- בזמן
- יצטרך
- עם
- זרימת עבודה
- זרימות עבודה
- עוֹלָם
- אתה
- Zendesk
- זפירנט